Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Tworzenie inteligentnego asystenta kadr przy użyciu LangChain.js i usług platformy Azure. Ten agent pomaga pracownikom fikcyjnej firmy NorthWind znaleźć odpowiedzi na pytania dotyczące zasobów ludzkich, wyszukując dokumentację firmy.
Użyjesz usługi Azure AI Search , aby znaleźć odpowiednie dokumenty i interfejs Azure OpenAI w celu wygenerowania dokładnych odpowiedzi. Struktura LangChain.js obsługuje złożoność aranżacji agentów, co pozwala skupić się na konkretnych wymaganiach biznesowych.
Zawartość:
- Wdrażanie zasobów platformy Azure przy użyciu interfejsu wiersza polecenia dla deweloperów platformy Azure
- Tworzenie agenta LangChain.js zintegrowanego z usługami platformy Azure
- Implementacja generacji wspomaganej wyszukiwaniem (RAG) na potrzeby wyszukiwania dokumentów
- Testowanie i debugowanie agenta lokalnie i na platformie Azure
Po ukończeniu tego samouczka masz działający interfejs API REST, który odpowiada na pytania dotyczące kadr przy użyciu dokumentacji firmy.
Przegląd architektury
NorthWind opiera się na dwóch źródłach danych:
- Dokumentacja kadr dostępna dla wszystkich pracowników
- Poufne bazy danych kadr zawierające poufne dane pracowników.
Ten samouczek koncentruje się na tworzeniu agenta LangChain.js, który określa, czy można odpowiedzieć na pytanie pracownika przy użyciu publicznych dokumentów kadrowych. Jeśli tak, agent LangChain.js zapewnia bezpośrednią odpowiedź.
Wymagania wstępne
Aby użyć tego przykładu w środowisku Codespace lub lokalnym kontenerze deweloperów, w tym kompilowania i uruchamiania agenta LangChain.js, potrzebne są następujące elementy:
- Aktywne konto platformy Azure. Utwórz bezpłatne konto , jeśli go nie masz.
Jeśli przykładowy kod jest uruchamiany lokalnie bez kontenera deweloperskiego, potrzebne są również następujące elementy:
- Node.js LTS zainstalowane w systemie.
- TypeScript do pisania i kompilowania kodu TypeScript.
- Zainstalowany i skonfigurowany interfejs wiersza polecenia dla deweloperów platformy Azure (azd).
- LangChain.js bibliotekę do kompilowania agenta.
- Opcjonalnie: LangSmith do monitorowania użycia sztucznej inteligencji. Potrzebujesz nazwy projektu, klucza i punktu końcowego.
- Opcjonalnie: LangGraph Studio do debugowania łańcuchów LangGraph i agentów LangChain.js.
Zasoby platformy Azure
Wymagane są następujące zasoby platformy Azure. Są one tworzone dla Ciebie w tym artykule przy użyciu interfejsu wiersza polecenia dla deweloperów platformy Azure i szablonów Bicep przy użyciu modułów zweryfikowanych platformy Azure (AVM). Zasoby są tworzone z dostępem bez hasła i kluczem do celów szkoleniowych. W tym samouczku używane jest lokalne konto dewelopera do uwierzytelniania bez hasła:
- Tożsamość zarządzana na potrzeby uwierzytelniania bez hasła w usługach platformy Azure.
- Azure Container Registry do przechowywania obrazu Docker dla serwera Fastify API w Node.js.
- Aplikacja kontenera platformy Azure w celu hostowania serwera interfejsu API Fastify Node.js.
- Zasób usługi Azure AI Search na potrzeby wyszukiwania wektorowego.
-
Zasób usługi Azure OpenAI z następującymi modelami:
- Model osadzania, taki jak
text-embedding-3-small. - Duży model językowy (LLM), taki jak
'gpt-4.1-mini.
- Model osadzania, taki jak

Architektura agenta
Struktura LangChain.js zapewnia przepływ decyzji do tworzenia inteligentnych agentów jako LangGraph. W tym samouczku utworzysz agenta LangChain.js, który integruje się z usługą Azure AI Search i usługą Azure OpenAI, aby odpowiedzieć na pytania związane z hr. Architektura agenta została zaprojektowana w celu:
- Ustal, czy pytanie ma zastosowanie do ogólnej dokumentacji kadrowej dostępnej dla wszystkich pracowników.
- Pobierz odpowiednie dokumenty z usługi Azure AI Search na podstawie zapytania użytkownika.
- Użyj usługi Azure OpenAI, aby wygenerować odpowiedź na podstawie pobranych dokumentów i modelu LLM.
Kluczowe składniki:
Struktura grafu: agent LangChain.js jest reprezentowany jako graf, gdzie:
- Węzły wykonują określone zadania, takie jak podejmowanie decyzji lub pobieranie danych.
- Krawędzie definiują przepływ między węzłami, co określa kolejność operacji.
Integracja usługi Azure AI Search:
- Używa modelu osadzania do tworzenia wektorów.
- Wstawia dokumenty HR (*.md, *.pdf) do przechowalni wektorów.
Dokumenty obejmują:
- Informacje o firmie
- Podręcznik pracownika
- Podręcznik korzyści
- Biblioteka ról pracowników
- Pobiera odpowiednie dokumenty na podstawie monitu użytkownika.
-
Integracja z usługą Azure OpenAI:
- Używa dużego modelu językowego do:
- Określa, czy na pytanie można odpowiedzieć w oparciu o bezosobowe dokumenty kadrowe.
- Generuje odpowiedź na podstawie polecenia przy użyciu kontekstu z dokumentów i pytania użytkownika.
- Używa dużego modelu językowego do:
W poniższej tabeli przedstawiono przykłady pytań użytkowników, które są i nie są istotne oraz odpowiadające na podstawie ogólnych dokumentów dotyczących zasobów ludzkich.
| Pytanie | Istotny | Explanation |
|---|---|---|
Does the NorthWind Health Plus plan cover eye exams? |
Tak | Dokumenty kadr, takie jak podręcznik pracownika, powinny dostarczyć odpowiedź. |
How much of my perks + benefits have I spent? |
Nie. | To pytanie wymaga dostępu do poufnych danych pracowników, które wykraczają poza zakres tego agenta. |
Korzystając z frameworku LangChain.js, można uniknąć większości kodu szablonowego zwykle wymaganego dla integracji agentów i usług Azure, co pozwala skoncentrować się na potrzebach biznesowych.
Klonowanie przykładowego repozytorium kodu
W nowym katalogu sklonuj przykładowe repozytorium kodu i przejdź do nowego katalogu:
git clone https://github.com/Azure-Samples/azure-typescript-langchainjs.git
cd azure-typescript-langchainjs
Ten przykład zawiera kod potrzebny do utworzenia bezpiecznych zasobów platformy Azure, skompilowania agenta LangChain.js za pomocą usługi Azure AI Search i usługi Azure OpenAI oraz użycia agenta z serwera interfejsu API fastify Node.js.
Uwierzytelnij się w Azure CLI i CLI dla deweloperów platformy Azure
Zaloguj się do platformy Azure przy użyciu interfejsu wiersza polecenia dla deweloperów platformy Azure, utwórz zasoby platformy Azure i wdróż kod źródłowy. Ponieważ proces wdrażania używa interfejsu wiersza polecenia platformy Azure i interfejsu wiersza polecenia dla deweloperów platformy Azure, zaloguj się do interfejsu wiersza polecenia platformy Azure, a następnie skonfiguruj interfejs wiersza polecenia dla deweloperów platformy Azure do korzystania z uwierzytelniania z poziomu interfejsu wiersza polecenia platformy Azure:
az login
azd config set auth.useAzCliAuth true
Tworzenie zasobów i wdrażanie kodu za pomocą interfejsu wiersza polecenia dla deweloperów platformy Azure
Rozpocznij proces wdrażania, uruchamiając azd up polecenie :
azd up
azd up Podczas wykonywania polecenia odpowiedz na pytania:
-
Nazwa nowego środowiska: wprowadź unikatową nazwę środowiska, taką jak
langchain-agent. Ta nazwa środowiska jest używana jako część grupy zasobów platformy Azure. - Wybierz subskrypcję platformy Azure: wybierz subskrypcję, w której są tworzone zasoby.
-
Wybierz region, na przykład
eastus2.
Wdrożenie trwa około 10–15 minut. CLI platformy Azure organizuje proces przy użyciu faz i haków zdefiniowanych w pliku azure.yaml.
Faza provisioning (równoważna do azd provision):
- Tworzy zasoby platformy Azure zdefiniowane w pliku
infra/main.bicep:- Aplikacja kontenera platformy Azure
- OpenAI
- Wyszukiwanie AI
- Rejestr Kontenerów
- Tożsamość zarządzana
-
Punkt zaczepienia po aprowizacji: sprawdza, czy indeks
northwindusługi Azure AI Search już istnieje- Jeśli indeks nie istnieje: uruchamia
npm installinpm run load_dataprzesyła dokumenty HR przy użyciu ładowarki PDF LangChain.js i klienta do osadzania. - Jeśli indeks istnieje: pomija ładowanie danych, aby uniknąć duplikatów (można ręcznie przeładować przez usunięcie indeksu lub uruchomienie
npm run load_data) Faza wdrażania (odpowiednik doazd deploy):
- Jeśli indeks nie istnieje: uruchamia
- Hook przed wdrożeniem: Buduje obraz Docker dla serwera API Fastify i wypycha go do Azure Container Registry
- Wdraża konteneryzowany serwer interfejsu API w usłudze Azure Container Apps
Po zakończeniu wdrażania zmienne środowiskowe oraz informacje o zasobach są zapisywane do pliku .env w katalogu głównym repozytorium. Zasoby można wyświetlić w witrynie Azure Portal.
Zasoby są tworzone z dostępem bez hasła i kluczem do celów szkoleniowych. Ten samouczek wprowadzający używa lokalnego konta dewelopera do uwierzytelniania bez hasła. W przypadku aplikacji produkcyjnych należy używać tylko uwierzytelniania bez hasła z tożsamościami zarządzanymi. Dowiedz się więcej o uwierzytelnianiu bez hasła.
Użyj lokalnie przykładowego kodu
Po utworzeniu zasobów platformy Azure możesz uruchomić agenta LangChain.js lokalnie.
Instalowanie zależności
Zainstaluj pakiety Node.js dla tego projektu.
npm installTo polecenie instaluje zależności zdefiniowane w dwóch
package.jsonplikach wpackages-v1katalogu, w tym:-
./packages-v1/server-api:- Fastify dla serwera internetowego
-
./packages-v1/langgraph-agent:- LangChain.js do kompilowania agenta
- Biblioteka
@azure/search-documentsklienta zestawu Azure SDK do integracji z zasobem usługi Azure AI Search. Dokumentacja referencyjna znajduje się tutaj.
-
Skompiluj dwa pakiety: serwer interfejsu API i agent AI.
npm run buildTo polecenie tworzy połączenie między dwoma pakietami, aby serwer interfejsu API mógł wywołać agenta sztucznej inteligencji.
Uruchamianie serwera interfejsu API lokalnie
Interfejs wiersza polecenia dla deweloperów platformy Azure utworzył wymagane zasoby platformy Azure i skonfigurował zmienne środowiskowe w pliku głównym .env . Ta konfiguracja zawierała hak po aprowizacji do przesyłania danych do magazynu wektorowego. Teraz możesz uruchomić serwer interfejsu API Fastify hostujący agenta LangChain.js. Uruchom serwer interfejsu API Fastify.
npm run dev
Serwer uruchamia się i nasłuchuje na porcie 3000. Serwer można przetestować, przechodząc do strony [http://localhost:3000] w przeglądarce internetowej. Powinien zostać wyświetlony komunikat powitalny wskazujący, że serwer jest uruchomiony.
Zadawanie pytań przy użyciu interfejsu API
Możesz użyć narzędzia takiego jak klient REST lub curl wysłać żądanie POST do /ask punktu końcowego z treścią JSON zawierającą pytanie.
Zapytania klienta REST są dostępne w packages-v1/server-api/http katalogu.
Przykład użycia curl:
curl -X POST http://localhost:3000/answer -H "Content-Type: application/json" -d "{\"question\": \"Does the NorthWind Health Plus plan cover eye exams?\"}"
Powinnaś otrzymać odpowiedź w formacie JSON od agenta LangChain.js.
{
"answer": "Yes, the NorthWind Health Plus plan covers eye exams. According to the Employee Handbook, employees enrolled in the Health Plus plan are eligible for annual eye exams as part of their vision benefits."
}
W katalogu packages-v1/server-api/http znajduje się kilka przykładowych pytań. Otwórz pliki w programie Visual Studio Code za pomocą klienta REST , aby szybko je przetestować.
Omówienie kodu aplikacji
W tej sekcji wyjaśniono, jak agent LangChain.js integruje się z usługami platformy Azure. Aplikacja repozytorium jest zorganizowana jako obszar roboczy npm z dwoma głównymi pakietami:
Project Root
│
├── packages-v1/
│ │
│ ├── langgraph-agent/ # Core LangGraph agent implementation
│ │ ├── src/
│ │ │ ├── azure/ # Azure service integrations
│ │ │ │ ├── azure-credential.ts # Centralized auth with DefaultAzureCredential
│ │ │ │ ├── embeddings.ts # Azure OpenAI embeddings + PDF loading + rate limiting
│ │ │ │ ├── llm.ts # Azure OpenAI chat completion (key-based & passwordless)
│ │ │ │ └── vector_store.ts # Azure AI Search vector store + indexing + similarity search
│ │ │ │
│ │ │ ├── langchain/ # LangChain agent logic
│ │ │ │ ├── node_get_answer.ts # RAG: retrieves docs + generates answers
│ │ │ │ ├── node_requires_hr_documents.ts # Determines if HR docs needed
│ │ │ │ ├── nodes.ts # LangGraph node definitions + state management
│ │ │ │ └── prompt.ts # System prompts + conversation templates
│ │ │ │
│ │ │ └── scripts/ # Utility scripts
│ │ │ └── load_vector_store.ts # Uploads PDFs to Azure AI Search
│ │ │
│ │ └── data/ # Source documents (PDFs) for vector store
│ │
│ └── server-api/ # Fastify REST API server
│ └── src/
│ └── server.ts # HTTP server with /answer endpoint
│
├── infra/ # Infrastructure as Code
│ └── main.bicep # Azure resources: Container Apps, OpenAI, AI Search, ACR, managed identity
│
├── azure.yaml # Azure Developer CLI config + deployment hooks
├── Dockerfile # Multi-stage Docker build for containerized deployment
└── package.json # Workspace configuration + build scripts
Kluczowe decyzje dotyczące architektury:
- Struktura monorepo: obszary robocze npm umożliwiają współdzielone zależności i połączone pakiety
-
Separacja problemów: logika agenta (
langgraph-agent) jest niezależna od serwera interfejsu API (server-api) -
Scentralizowane uwierzytelnianie: pliki obsługujące
./langgraph-agent/src/azurezarówno uwierzytelnianie oparte na kluczach, jak i bez hasła oraz integrację z usługą platformy Azure
Uwierzytelnianie w usługach platformy Azure
Aplikacja obsługuje zarówno metody uwierzytelniania opartego na kluczach, jak i bez hasła, kontrolowane przez zmienną środowiskową SET_PASSWORDLESS .
Domyślny interfejs APIAzureCredential z biblioteki tożsamości platformy Azure jest używany do uwierzytelniania bez hasła, dzięki czemu aplikacja może bezproblemowo działać w lokalnych środowiskach deweloperskich i platformy Azure. To uwierzytelnianie można zobaczyć w następującym fragmencie kodu:
import { DefaultAzureCredential } from "@azure/identity";
export const CREDENTIAL = new DefaultAzureCredential();
export const SCOPE_OPENAI = "https://cognitiveservices.azure.com/.default";
export async function azureADTokenProvider_OpenAI() {
const tokenResponse = await CREDENTIAL.getToken(SCOPE_OPENAI);
return tokenResponse.token;
}
W przypadku korzystania z bibliotek innych firm, takich jak LangChain.js lub biblioteka OpenAI w celu uzyskania dostępu do usługi Azure OpenAI, potrzebujesz funkcji dostawcy tokenów zamiast bezpośredniego przekazywania obiektu poświadczeń. Funkcja getBearerTokenProvider z biblioteki tożsamości platformy Azure rozwiązuje ten problem, tworząc dostawcę tokenów, który automatycznie pobiera i odświeża tokeny elementu nośnego OAuth 2.0 dla określonego zakresu zasobów platformy Azure (na przykład "https://cognitiveservices.azure.com/.default"). Zakres można skonfigurować raz podczas instalacji, a dostawca tokenów automatycznie obsługuje zarządzanie tokenami. Można zastosować to podejście z dowolnymi poświadczeniami biblioteki tożsamości Azure, w tym zarządzaną tożsamością i poświadczeniami Azure CLI. Chociaż biblioteki zestawu Azure SDK akceptują DefaultAzureCredential bezpośrednio, biblioteki innych firm, takie jak LangChain.js, wymagają tego wzorca dostawcy tokenów, aby wypełnić lukę uwierzytelniania.
Integracja usługi Azure AI Search
Zasób usługi Azure AI Search przechowuje osadzanie dokumentów i umożliwia semantyczne wyszukiwanie odpowiedniej zawartości. Aplikacja używa biblioteki LangChain AzureAISearchVectorStore do zarządzania magazynem wektorów bez konieczności definiowania schematu indeksu.
Magazyn wektorów jest tworzony z konfiguracją zarówno dla operacji administratora (zapisu), jak i zapytania (odczytu), aby ładowanie dokumentów i wykonywanie zapytań mogło używać różnych konfiguracji. Jest to ważne niezależnie od tego, czy używasz kluczy, czy uwierzytelniania bez hasła z tożsamościami zarządzanymi.
Wdrożenie interfejsu wiersza polecenia dla deweloperów platformy Azure obejmuje hak post-deployment, który przesyła dokumenty do magazynu wektorów za pomocą modułu ładującego LangChain.js PDF i klienta do osadzania. Ten haczyk post-wdrożeniowy jest ostatnim krokiem polecenia
postdeploy:
posix:
sh: bash
run: |
echo "Checking if vector store data needs to be loaded..."
# Check if already loaded
INDEX_CREATED=$(azd env get-values | grep INDEX_CREATED | cut -d'=' -f2 || echo "false")
if [ "$INDEX_CREATED" = "true" ]; then
echo "Index already created. Skipping data load."
echo "Current document count: $(azd env get-values | grep INDEX_DOCUMENT_COUNT | cut -d'=' -f2)"
else
echo "Loading vector store data..."
npm install
npm run build
npm run load_data
# Get document count from the index
SEARCH_SERVICE=$(azd env get-values | grep AZURE_AISEARCH_ENDPOINT | cut -d'/' -f3 | cut -d'.' -f1)
DOC_COUNT=$(az search index show --service-name $SEARCH_SERVICE --name northwind --query "documentCount" -o tsv 2>/dev/null || echo "0")
# Mark as loaded
azd env set INDEX_CREATED true
azd env set INDEX_DOCUMENT_COUNT $DOC_COUNT
echo "Data loading complete! Indexed $DOC_COUNT documents."
fi
Użyj głównego pliku .env utworzonego przez Azure Developer CLI, aby uwierzytelnić się w zasobie Azure AI Search i utworzyć klienta AzureAISearchVectorStore.
const endpoint = process.env.AZURE_AISEARCH_ENDPOINT;
const indexName = process.env.AZURE_AISEARCH_INDEX_NAME;
const adminKey = process.env.AZURE_AISEARCH_ADMIN_KEY;
const queryKey = process.env.AZURE_AISEARCH_QUERY_KEY;
export const QUERY_DOC_COUNT = 3;
const MAX_INSERT_RETRIES = 3;
const shared_admin = {
endpoint,
indexName,
};
export const VECTOR_STORE_ADMIN_KEY: AzureAISearchConfig = {
...shared_admin,
key: adminKey,
};
export const VECTOR_STORE_ADMIN_PASSWORDLESS: AzureAISearchConfig = {
...shared_admin,
credentials: CREDENTIAL,
};
export const VECTOR_STORE_ADMIN_CONFIG: AzureAISearchConfig =
process.env.SET_PASSWORDLESS == "true"
? VECTOR_STORE_ADMIN_PASSWORDLESS
: VECTOR_STORE_ADMIN_KEY;
const shared_query = {
endpoint,
indexName,
search: {
type: AzureAISearchQueryType.Similarity,
},
};
// Key-based config
export const VECTOR_STORE_QUERY_KEY: AzureAISearchConfig = {
key: queryKey,
...shared_query,
};
export const VECTOR_STORE_QUERY_PASSWORDLESS: AzureAISearchConfig = {
credentials: CREDENTIAL,
...shared_query,
};
export const VECTOR_STORE_QUERY_CONFIG =
process.env.SET_PASSWORDLESS == "true"
? VECTOR_STORE_QUERY_PASSWORDLESS
: VECTOR_STORE_QUERY_KEY;
Podczas wykonywania zapytań magazyn wektorów konwertuje zapytanie użytkownika na osadzanie, wyszukuje dokumenty z podobnymi reprezentacjami wektorów i zwraca najbardziej istotne fragmenty.
export function getReadOnlyVectorStore(): AzureAISearchVectorStore {
const embeddings = getEmbeddingClient();
return new AzureAISearchVectorStore(embeddings, VECTOR_STORE_QUERY_CONFIG);
}
export async function getDocsFromVectorStore(
query: string,
): Promise<Document[]> {
const store = getReadOnlyVectorStore();
// @ts-ignore
//return store.similaritySearchWithScore(query, QUERY_DOC_COUNT);
return store.similaritySearch(query, QUERY_DOC_COUNT);
}
Ponieważ magazyn wektorów jest oparty na LangChain.js, upraszcza złożoność bezpośredniej interakcji z magazynem wektorów. Po zapoznaniu się z interfejsem magazynu wektorów LangChain.js można łatwo przełączyć się na inne implementacje magazynu wektorów w przyszłości.
Integracja z usługą Azure OpenAI
Aplikacja używa usługi Azure OpenAI do osadzania i dużych możliwości modelu językowego (LLM). Klasa AzureOpenAIEmbeddings z LangChain.js służy do generowania osadzeń dla dokumentów i zapytań. Po utworzeniu klienta osadzania LangChain.js używa go do tworzenia osadzania.
Integracja z usługą Azure OpenAI na potrzeby osadzania
Użyj pliku głównego .env utworzonego przez interfejs wiersza polecenia dewelopera platformy Azure, aby uwierzytelnić się w zasobie usługi Azure OpenAI i utworzyć klienta azureOpenAIEmbeddings :
const shared = {
azureOpenAIApiInstanceName: instance,
azureOpenAIApiEmbeddingsDeploymentName: model,
azureOpenAIApiVersion: apiVersion,
azureOpenAIBasePath,
dimensions: 1536, // for text-embedding-3-small
batchSize: EMBEDDING_BATCH_SIZE,
maxRetries: 7,
timeout: 60000,
};
export const EMBEDDINGS_KEY_CONFIG = {
azureOpenAIApiKey: key,
...shared,
};
export const EMBEDDINGS_CONFIG_PASSWORDLESS = {
azureADTokenProvider: azureADTokenProvider_OpenAI,
...shared,
};
export const EMBEDDINGS_CONFIG =
process.env.SET_PASSWORDLESS == "true"
? EMBEDDINGS_CONFIG_PASSWORDLESS
: EMBEDDINGS_KEY_CONFIG;
export function getEmbeddingClient(): AzureOpenAIEmbeddings {
return new AzureOpenAIEmbeddings({ ...EMBEDDINGS_CONFIG });
}
Integracja usługi Azure OpenAI dla usługi LLM
Użyj pliku głównego .env utworzonego przez interfejs wiersza polecenia dewelopera platformy Azure, aby uwierzytelnić się w zasobie usługi Azure OpenAI i utworzyć klienta AzureChatOpenAI :
const shared = {
azureOpenAIApiInstanceName: instance,
azureOpenAIApiDeploymentName: model,
azureOpenAIApiVersion: apiVersion,
azureOpenAIBasePath,
maxTokens: maxTokens ? parseInt(maxTokens, 10) : 1000,
maxRetries: 7,
timeout: 60000,
temperature: 0,
};
export const LLM_KEY_CONFIG = {
azureOpenAIApiKey: key,
...shared,
};
export const LLM_CONFIG_PASSWORDLESS = {
azureADTokenProvider: azureADTokenProvider_OpenAI,
...shared,
};
export const LLM_CONFIG =
process.env.SET_PASSWORDLESS == "true"
? LLM_CONFIG_PASSWORDLESS
: LLM_KEY_CONFIG;
Aplikacja używa AzureChatOpenAI klasy z LangChain.js @langchain/openai do interakcji z modelami usługi Azure OpenAI.
export const callChatCompletionModel = async (
state: typeof StateAnnotation.State,
_config: RunnableConfig,
): Promise<typeof StateAnnotation.Update> => {
const llm = new AzureChatOpenAI({
...LLM_CONFIG,
});
const completion = await llm.invoke(state.messages);
completion;
return {
messages: [
...state.messages,
{
role: "assistant",
content: completion.content,
},
],
};
};
Przepływ pracy agenta LangGraph
Agent używa języka LangGraph do zdefiniowania przepływu pracy podejmowania decyzji, który określa, czy pytanie można odpowiedzieć przy użyciu dokumentów kadrowych.
Struktura grafu:
import { StateGraph } from "@langchain/langgraph";
import {
START,
ANSWER_NODE,
DECISION_NODE,
route as endRoute,
StateAnnotation,
} from "./langchain/nodes.js";
import { getAnswer } from "./langchain/node_get_answer.js";
import {
requiresHrResources,
routeRequiresHrResources,
} from "./langchain/node_requires_hr_documents.js";
const builder = new StateGraph(StateAnnotation)
.addNode(DECISION_NODE, requiresHrResources)
.addNode(ANSWER_NODE, getAnswer)
.addEdge(START, DECISION_NODE)
.addConditionalEdges(DECISION_NODE, routeRequiresHrResources)
.addConditionalEdges(ANSWER_NODE, endRoute);
export const hr_documents_answer_graph = builder.compile();
hr_documents_answer_graph.name = "Azure AI Search + Azure OpenAI";
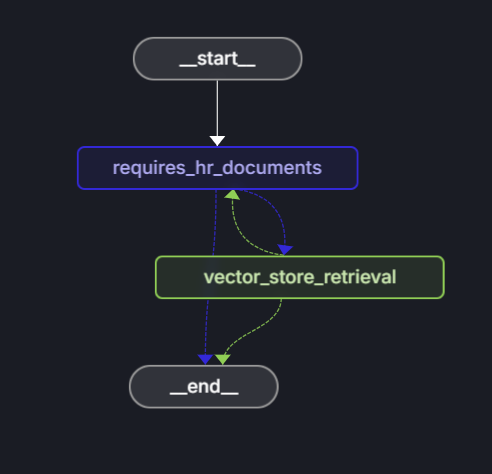
Przepływ pracy składa się z następujących kroków:
- Początek: użytkownik przesyła pytanie.
- requires_hr_documents node: LLM określa, czy na pytanie można odpowiedzieć na podstawie ogólnych dokumentów kadrowych.
-
Routing warunkowy:
- Jeśli tak, przechodzi do
get_answerwęzła. - Jeśli nie, zwraca komunikat, że pytanie wymaga danych osobowych kadr.
- Jeśli tak, przechodzi do
- węzeł get_answer: pobiera dokumenty i generuje odpowiedź.
- Koniec: zwraca odpowiedź użytkownikowi.
Ta kontrola istotności jest ważna, ponieważ nie wszystkie pytania kadrowe można odpowiedzieć na podstawie ogólnych dokumentów. Pytania osobiste, takie jak "Ile mam PTO?" wymagają dostępu do baz danych pracowników, które zawierają dane poszczególnych pracowników. Najpierw sprawdzając istotność, agent unika halucynacji odpowiedzi na pytania, które wymagają informacji osobistych, do których nie ma dostępu.
Zdecyduj, czy pytanie wymaga dokumentów kadrowych
Węzeł requires_hr_documents używa modułu LLM, aby określić, czy pytanie użytkownika można odpowiedzieć przy użyciu ogólnych dokumentów kadrowych. Używa szablonu monitu, który instruuje model, aby odpowiedział YES lub NO na podstawie istotności pytania. Zwraca odpowiedź w wiadomości ustrukturyzowanej, którą można przekazać w ramach przepływu pracy. W następnym węźle użyto tej odpowiedzi, aby skierować przepływ pracy do elementu END lub ANSWER_NODE.
// @ts-nocheck
import { getLlmChatClient } from "../azure/llm.js";
import { StateAnnotation } from "../langchain/state.js";
import { RunnableConfig } from "@langchain/core/runnables";
import { BaseMessage } from "@langchain/core/messages";
import { ANSWER_NODE, END } from "./nodes.js";
const PDF_DOCS_REQUIRED = "Answer requires HR PDF docs.";
export async function requiresHrResources(
state: typeof StateAnnotation.State,
_config: RunnableConfig,
): Promise<typeof StateAnnotation.Update> {
const lastUserMessage: BaseMessage = [...state.messages].reverse()[0];
let pdfDocsRequired = false;
if (lastUserMessage && typeof lastUserMessage.content === "string") {
const question = `Does the following question require general company policy information that could be found in HR documents like employee handbooks, benefits overviews, or company-wide policies, then answer yes. Answer no if this requires personal employee-specific information that would require access to an individual's private data, employment records, or personalized benefits details: '${lastUserMessage.content}'. Answer with only "yes" or "no".`;
const llm = getLlmChatClient();
const response = await llm.invoke(question);
const answer = response.content.toLocaleLowerCase().trim();
console.log(`LLM question (is HR PDF documents required): ${question}`);
console.log(`LLM answer (is HR PDF documents required): ${answer}`);
pdfDocsRequired = answer === "yes";
}
// If HR documents (aka vector store) are required, append an assistant message to signal this.
if (!pdfDocsRequired) {
const updatedState = {
messages: [
...state.messages,
{
role: "assistant",
content:
"Not a question for our HR PDF resources. This requires data specific to the asker.",
},
],
};
return updatedState;
} else {
const updatedState = {
messages: [
...state.messages,
{
role: "assistant",
content: `${PDF_DOCS_REQUIRED} You asked: ${lastUserMessage.content}. Let me check.`,
},
],
};
return updatedState;
}
}
export const routeRequiresHrResources = (
state: typeof StateAnnotation.State,
): typeof END | typeof ANSWER_NODE => {
const lastMessage: BaseMessage = [...state.messages].reverse()[0];
if (lastMessage && !lastMessage.content.includes(PDF_DOCS_REQUIRED)) {
console.log("go to end");
return END;
}
console.log("go to llm");
return ANSWER_NODE;
};
Pobieranie wymaganych dokumentów kadrowych
Po ustaleniu, że pytanie wymaga dokumentów HR, proces roboczy używa getAnswer do pobrania odpowiednich dokumentów z magazynu wektorów, dodania ich do kontekstu zapytania i przekazania całego zapytania do LLM.
import { ChatPromptTemplate } from "@langchain/core/prompts";
import { getLlmChatClient } from "../azure/llm.js";
import { StateAnnotation } from "./nodes.js";
import { AIMessage } from "@langchain/core/messages";
import { getReadOnlyVectorStore } from "../azure/vector_store.js";
const EMPTY_STATE = { messages: [] };
export async function getAnswer(
state: typeof StateAnnotation.State = EMPTY_STATE,
): Promise<typeof StateAnnotation.Update> {
const vectorStore = getReadOnlyVectorStore();
const llm = getLlmChatClient();
// Extract the last user message's content from the state as input
const lastMessage = state.messages[state.messages.length - 1];
const userInput =
lastMessage && typeof lastMessage.content === "string"
? lastMessage.content
: "";
const docs = await vectorStore.similaritySearch(userInput, 3);
if (docs.length === 0) {
const noDocMessage = new AIMessage(
"I'm sorry, I couldn't find any relevant information to answer your question.",
);
return {
messages: [...state.messages, noDocMessage],
};
}
const formattedDocs = docs.map((doc) => doc.pageContent).join("\n\n");
const prompt = ChatPromptTemplate.fromTemplate(`
Use the following context to answer the question:
{context}
Question: {question}
`);
const ragChain = prompt.pipe(llm);
const result = await ragChain.invoke({
context: formattedDocs,
question: userInput,
});
const assistantMessage = new AIMessage(result.text);
return {
messages: [...state.messages, assistantMessage],
};
}
Jeśli nie znaleziono żadnych odpowiednich dokumentów, agent zwraca komunikat wskazujący, że nie może znaleźć odpowiedzi w dokumentach działu kadr.
Rozwiązywanie problemów
W przypadku wszelkich problemów z procedurą utwórz problem w repozytorium przykładowego kodu
Uprzątnij zasoby
Możesz usunąć grupę zasobów zawierającą zasób usługi Azure AI Search i zasób usługi Azure OpenAI lub użyć interfejsu wiersza polecenia dewelopera platformy Azure, aby natychmiast usunąć wszystkie zasoby utworzone w tym samouczku.
azd down --purge