Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Azure DevOps Services | Azure DevOps Server | Azure DevOps Server 2022
Możesz organizować swój potok na zadania. Każdy ciąg przetwarzania ma co najmniej jedno zadanie. Zadanie to seria kroków, które są uruchamiane sekwencyjnie jako jednostka. Innymi słowy, zadanie jest najmniejszą jednostką pracy, którą można zaplanować do wykonania.
Aby dowiedzieć się więcej na temat kluczowych pojęć i składników tworzących potok, zobacz Kluczowe pojęcia dotyczące nowych użytkowników usługi Azure Pipelines.
Usługa Azure Pipelines nie obsługuje ustalania priorytetu dla zadań w potokach YAML. Aby kontrolować czas uruchamiania zadań, można określić warunki i zależności.
Definiowanie pojedynczego zadania
W najprostszym przypadku potok ma jedno zadanie. W takim przypadku nie musisz jawnie używać słowa kluczowegojob, chyba że używasz szablonu. Możesz bezpośrednio określić kroki w pliku YAML.
Ten plik YAML zawiera zadanie uruchamiane w agencieprzez firmę Microsoft i zwraca dane wyjściowe .
pool:
vmImage: 'ubuntu-latest'
steps:
- bash: echo "Hello world"
Możesz określić więcej właściwości tego zadania. W takim przypadku możesz użyć słowa kluczowego job .
jobs:
- job: myJob
timeoutInMinutes: 10
pool:
vmImage: 'ubuntu-latest'
steps:
- bash: echo "Hello world"
Potok może mieć wiele zadań. W takim przypadku użyj słowa kluczowego jobs .
jobs:
- job: A
steps:
- bash: echo "A"
- job: B
steps:
- bash: echo "B"
Potok może zawierać wiele etapów, z których każdy ma wiele zadań. W takim przypadku użyj słowa kluczowego stages .
stages:
- stage: A
jobs:
- job: A1
- job: A2
- stage: B
jobs:
- job: B1
- job: B2
Pełna składnia określająca zadanie to:
- job: string # name of the job, A-Z, a-z, 0-9, and underscore
displayName: string # friendly name to display in the UI
dependsOn: string | [ string ]
condition: string
strategy:
parallel: # parallel strategy
matrix: # matrix strategy
maxParallel: number # maximum number simultaneous matrix legs to run
# note: `parallel` and `matrix` are mutually exclusive
# you may specify one or the other; including both is an error
# `maxParallel` is only valid with `matrix`
continueOnError: boolean # 'true' if future jobs should run even if this job fails; defaults to 'false'
pool: pool # agent pool
workspace:
clean: outputs | resources | all # what to clean up before the job runs
container: containerReference # container to run this job inside
timeoutInMinutes: number # how long to run the job before automatically cancelling
cancelTimeoutInMinutes: number # how much time to give 'run always even if cancelled tasks' before killing them
variables: { string: string } | [ variable | variableReference ]
steps: [ script | bash | pwsh | powershell | checkout | task | templateReference ]
services: { string: string | container } # container resources to run as a service container
Pełna składnia określająca zadanie to:
- job: string # name of the job, A-Z, a-z, 0-9, and underscore
displayName: string # friendly name to display in the UI
dependsOn: string | [ string ]
condition: string
strategy:
parallel: # parallel strategy
matrix: # matrix strategy
maxParallel: number # maximum number simultaneous matrix legs to run
# note: `parallel` and `matrix` are mutually exclusive
# you may specify one or the other; including both is an error
# `maxParallel` is only valid with `matrix`
continueOnError: boolean # 'true' if future jobs should run even if this job fails; defaults to 'false'
pool: pool # agent pool
workspace:
clean: outputs | resources | all # what to clean up before the job runs
container: containerReference # container to run this job inside
timeoutInMinutes: number # how long to run the job before automatically cancelling
cancelTimeoutInMinutes: number # how much time to give 'run always even if cancelled tasks' before killing them
variables: { string: string } | [ variable | variableReference ]
steps: [ script | bash | pwsh | powershell | checkout | task | templateReference ]
services: { string: string | container } # container resources to run as a service container
uses: # Any resources (repos or pools) required by this job that are not already referenced
repositories: [ string ] # Repository references to Azure Git repositories
pools: [ string ] # Pool names, typically when using a matrix strategy for the job
Jeśli głównym celem zadania jest wdrożenie aplikacji (w przeciwieństwie do kompilowania lub testowania aplikacji), możesz użyć specjalnego typu zadania o nazwie zadanie wdrożenia.
Składnia zadania wdrożenia to:
- deployment: string # instead of job keyword, use deployment keyword
pool:
name: string
demands: string | [ string ]
environment: string
strategy:
runOnce:
deploy:
steps:
- script: echo Hi!
Mimo że można dodać kroki dla zadań wdrażania w elemecie job, zalecamy użycie zadania wdrożenia. Zadanie wdrożenia ma kilka korzyści. Można na przykład wdrożyć w środowisku, co obejmuje korzyści, takie jak możliwość wyświetlenia historii wdrożonych elementów.

Typy zadań
Zadania mogą być różnego typu, w zależności od tego, gdzie są wykonywane.
- Zadania z puli agentów są wykonywane na agencie znajdującym się w tej puli.
- Zadania serwera są uruchamiane na serwerze Azure DevOps Server.
- Zadania kontenera działają w kontenerze na agencie z puli agentów. Aby uzyskać więcej informacji na temat wybierania kontenerów, zobacz Definiowanie zadań kontenera.
Zadania puli agentów
Zadania w puli agentów to najczęstsze zadania. Te zadania są uruchamiane na agencie w puli agentów. Możesz określić pulę do uruchomienia zadania, a także określić wymagania dotyczące określania możliwości, które musi mieć agent do uruchomienia zadania. Agenci mogą być hostowani przez firmę Microsoft lub hostowani samodzielnie. Aby uzyskać więcej informacji, zobacz agentów usługi Azure Pipelines.
- W przypadku korzystania z agentów hostowanych przez firmę Microsoft każde zadanie w ciągu pobiera nowego agenta.
- Gdy używasz własnych agentów, możesz użyć wymagań, aby określić, jakie możliwości musi mieć agent do uruchomienia zadania. Możesz skorzystać z tego samego agenta dla następnych zadań, w zależności od tego, czy w puli agentów istnieje więcej niż jeden agent, który spełnia wymagania twojego potoku. Jeśli w puli jest tylko jeden agent, który odpowiada wymaganiom potoku, potok poczeka, aż ten agent będzie dostępny.
Uwaga
Wymagania i możliwości są przeznaczone do użytku z samodzielnie hostowanymi agentami, aby zadania mogły być dopasowane do agenta spełniającego wymagania zadania. W przypadku korzystania z agentów hostowanych przez firmę Microsoft należy wybrać obraz agenta, który spełnia wymagania zadania. Chociaż istnieje możliwość dodania możliwości do agenta hostowanego przez firmę Microsoft, nie musisz używać funkcji z agentami hostowanymi przez firmę Microsoft.
pool:
name: myPrivateAgents # your job runs on an agent in this pool
demands: agent.os -equals Windows_NT # the agent must have this capability to run the job
steps:
- script: echo hello world
Lub wiele wymagań:
pool:
name: myPrivateAgents
demands:
- agent.os -equals Darwin
- anotherCapability -equals somethingElse
steps:
- script: echo hello world
Dowiedz się więcej o możliwościach agenta.
Zadania serwera
Serwer organizuje i wykonuje zadania w zadaniu serwera. Zadanie serwera nie wymaga agenta ani żadnych komputerów docelowych. Obecnie w pracy serwera obsługiwanych jest tylko kilka zadań. Maksymalny czas zadania serwera wynosi 30 dni.
Zadania obsługiwane bez agenta
Obecnie w przypadku zadań bez agenta obsługiwane są tylko następujące zadania:
- Opóźnij zadanie
- Wywoływanie zadania funkcji platformy Azure
- Wywoływanie zadania interfejsu API REST
- Zadanie ręcznej weryfikacji
- Zadanie "Publikowanie do Azure Service Bus"
- Zapytywanie zadania alertów w Azure Monitor
- Zadanie wyszukiwania elementów roboczych
Ponieważ zadania są rozszerzalne, można dodać więcej zadań bez agentów przy użyciu rozszerzeń. Domyślny limit czasu dla zadań bez agenta wynosi 60 minut.
Pełna składnia określająca zadanie serwera to:
jobs:
- job: string
timeoutInMinutes: number
cancelTimeoutInMinutes: number
strategy:
maxParallel: number
matrix: { string: { string: string } }
pool: server # note: the value 'server' is a reserved keyword which indicates this is an agentless job
Można również użyć uproszczonej składni:
jobs:
- job: string
pool: server # note: the value 'server' is a reserved keyword which indicates this is an agentless job
Zależności
Podczas definiowania wielu zadań na jednym etapie można określić zależności między nimi. Potoki muszą zawierać co najmniej jedno zadanie bez zależności. Domyślnie zadania potoku YAML platformy Azure DevOps są uruchamiane równolegle, chyba że wartość dependsOn nie jest ustawiona.
Uwaga
Każdy agent może uruchamiać tylko jedno zadanie naraz. Aby uruchomić wiele zadań równolegle, należy skonfigurować wielu agentów. Potrzebne są również wystarczające zadania równoległe.
Składnia definiowania wielu zadań i ich zależności jest następująca:
jobs:
- job: string
dependsOn: string
condition: string
Przykładowe zadania kompilujące sekwencyjnie:
jobs:
- job: Debug
steps:
- script: echo hello from the Debug build
- job: Release
dependsOn: Debug
steps:
- script: echo hello from the Release build
Przykłady zadań wykonywanych równolegle (bez zależności):
jobs:
- job: Windows
pool:
vmImage: 'windows-latest'
steps:
- script: echo hello from Windows
- job: macOS
pool:
vmImage: 'macOS-latest'
steps:
- script: echo hello from macOS
- job: Linux
pool:
vmImage: 'ubuntu-latest'
steps:
- script: echo hello from Linux
Przykład wentylatora:
jobs:
- job: InitialJob
steps:
- script: echo hello from initial job
- job: SubsequentA
dependsOn: InitialJob
steps:
- script: echo hello from subsequent A
- job: SubsequentB
dependsOn: InitialJob
steps:
- script: echo hello from subsequent B
Przykład wentylatora:
jobs:
- job: InitialA
steps:
- script: echo hello from initial A
- job: InitialB
steps:
- script: echo hello from initial B
- job: Subsequent
dependsOn:
- InitialA
- InitialB
steps:
- script: echo hello from subsequent
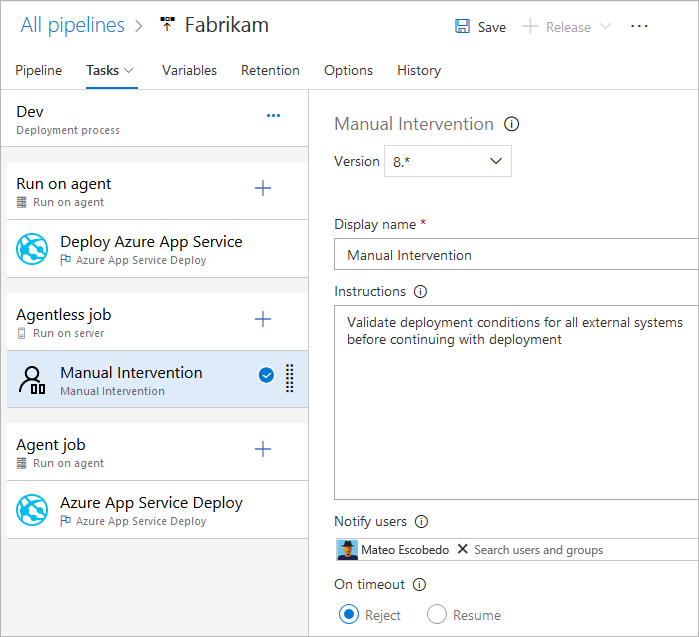
Warunki
Możesz określić warunki, w których każde zadanie jest uruchamiane. Domyślnie zadanie jest uruchamiane, jeśli nie zależy od żadnego innego zadania lub jeśli wszystkie zadania, od których zależy, zakończyły się pomyślnie. To zachowanie można dostosować, wymuszając uruchomienie zadania, nawet jeśli poprzednie zadanie zakończy się niepowodzeniem lub przez określenie warunku niestandardowego.
Przykład uruchamiania zadania na podstawie stanu uruchamiania poprzedniego zadania:
jobs:
- job: A
steps:
- script: exit 1
- job: B
dependsOn: A
condition: failed()
steps:
- script: echo this will run when A fails
- job: C
dependsOn:
- A
- B
condition: succeeded('B')
steps:
- script: echo this will run when B runs and succeeds
Przykład użycia warunku niestandardowego:
jobs:
- job: A
steps:
- script: echo hello
- job: B
dependsOn: A
condition: and(succeeded(), eq(variables['build.sourceBranch'], 'refs/heads/main'))
steps:
- script: echo this only runs for master
Można określić, że zadanie jest uruchamiane na podstawie wartości zmiennej wyjściowej ustawionej w poprzednim zadaniu. W takim przypadku można używać zmiennych ustawionych tylko w zadaniach zależnych bezpośrednio:
jobs:
- job: A
steps:
- script: "echo '##vso[task.setvariable variable=skipsubsequent;isOutput=true]false'"
name: printvar
- job: B
condition: and(succeeded(), ne(dependencies.A.outputs['printvar.skipsubsequent'], 'true'))
dependsOn: A
steps:
- script: echo hello from B
Przerwy czasowe
Aby uniknąć zajmowania zasobów, gdy zadanie nie odpowiada lub czeka zbyt długo, możesz ustawić limit czasu, przez jaki zadanie może działać. Użyj ustawienia limitu czasu zadania, aby określić w minutach limit czasu, w jakim może być wykonywane zadanie. Ustawienie wartości na zero oznacza, że zadanie może zostać uruchomione:
- Zawsze na własnych hostowanych agentach
- Przez 360 minut (6 godzin) na agentach hostowanych przez firmę Microsoft z publicznym projektem i repozytorium publicznym
- Przez 60 minut na agentach hostowanych przez firmę Microsoft dla prywatnego projektu lub repozytorium (chyba że zostanie opłacona dodatkowa pojemność)
Okres limitu czasu rozpoczyna się po uruchomieniu zadania. Nie uwzględnia czasu kolejki zadania ani oczekiwania na agenta.
Parametr timeoutInMinutes umożliwia ustawienie limitu czasu wykonywania zadania. Jeśli nie zostanie określony, wartość domyślna to 60 minut. Gdy 0 jest określone, używa się maksymalnego limitu.
Ustawienie cancelTimeoutInMinutes umożliwia ustawienie limitu czasu anulowania zadania, gdy zadanie wdrożenia ma być uruchomione, jeśli poprzednie zadanie nie powiodło się. Jeśli nie zostanie określony, wartość domyślna to 5 minut. Wartość powinna być w zakresie od 1 do 35790 minut.
Uwaga
Ustawienie timeoutInMinutes lub cancelTimeoutInMinutes wyżej niż maksymalna długość zadania agenta hostowanego przez Microsoft nie ma wpływu na potoki hostowanych agentów, ponieważ te zadania zostaną zatrzymane w oparciu o limity hostowanych agentów. Aby uzyskać więcej informacji, zobacz poprzednią sekcję Limity czasu .
jobs:
- job: Test
timeoutInMinutes: 10 # how long to run the job before automatically cancelling
cancelTimeoutInMinutes: 2 # how much time to give 'run always even if cancelled tasks' before stopping them
Przerwy mają następujący priorytet.
- W przypadku agentów hostowanych przez firmę Microsoft zadania są ograniczone do czasu ich działania na podstawie typu projektu i tego, czy są uruchamiane przy użyciu płatnego zadania równoległego. Gdy upłynie limit czasu zadania prowadzonego przez Microsoft, zadanie zostanie zakończone. W przypadku agentów hostowanych przez firmę Microsoft zadania nie mogą być uruchamiane dłużej niż w tym interwale, niezależnie od limitu czasu na poziomie zadania określonego w zadaniu.
- Limit czasu skonfigurowany na poziomie zadania określa maksymalny czas trwania zadania do uruchomienia. Gdy upłynie limit czasu dla poziomu zadania, zadanie zostanie zakończone. Gdy zadanie jest uruchamiane na agencie hostowanym przez firmę Microsoft, ustawienie limitu czasu na poziomie zadania, który jest większy niż wbudowany limit czasu na poziomie zadania hostowanego przez firmę Microsoft, nie ma żadnego wpływu.
- Możesz również ustawić limit czasu dla każdego zadania indywidualnie — zobacz opcje sterowania zadaniami. Jeśli interwał limitu czasu na poziomie zadania upłynie przed ukończeniem zadania, zadanie uruchomione zostanie zakończone, nawet jeśli zadanie jest skonfigurowane z dłuższym interwałem limitu czasu.
Konfiguracja wielu zadań
Z jednego zadania, które tworzysz, można uruchamiać wiele zadań na wielu agentach równolegle. Przykłady obejmują:
Kompilacje z wieloma konfiguracjami: można równolegle tworzyć wiele konfiguracji. Można na przykład utworzyć aplikację Visual C++ dla obu
debugreleasei konfiguracji na obux86platformach ix64. Aby uzyskać więcej informacji, zobacz Visual Studio Build — wiele konfiguracji dla wielu platform.Wdrożenia z wieloma konfiguracjami: można uruchomić wiele wdrożeń równolegle, na przykład do różnych regionów geograficznych.
Testowanie wielu konfiguracji: można uruchomić równoległe testowanie wielu konfiguracji.
Wiele konfiguracji zawsze generuje co najmniej jedno zadanie, nawet jeśli zmienna z wieloma konfiguracjami jest pusta.
Strategia matrix umożliwia wielokrotne wysyłanie zadania z różnymi zestawami zmiennych. Tag maxParallel ogranicza ilość równoległości. Następujące zadanie jest wysyłane trzy razy z wartościami Location i Browser ustawionymi zgodnie z określonymi. Jednak w tym samym czasie wykonywane są tylko dwa zadania.
jobs:
- job: Test
strategy:
maxParallel: 2
matrix:
US_IE:
Location: US
Browser: IE
US_Chrome:
Location: US
Browser: Chrome
Europe_Chrome:
Location: Europe
Browser: Chrome
Uwaga
Nazwy konfiguracji macierzy (takie jak US_IE w przykładzie) muszą zawierać tylko podstawowe litery alfabetu łacińskiego (A – Z, a – z), cyfry i podkreślenia (_).
Muszą zaczynać się od litery.
Ponadto muszą mieć co najmniej 100 znaków.
Można również użyć zmiennych wyjściowych do wygenerowania macierzy. Ta metoda może być przydatna, jeśli musisz wygenerować macierz przy użyciu skryptu.
matrix akceptuje wyrażenie środowiska uruchomieniowego zawierające ciągyfikowany obiekt JSON.
Ten obiekt JSON po rozwinięciu musi być zgodny ze składnią macierzy.
W poniższym przykładzie kodowaliśmy ciąg JSON, ale można go wygenerować za pomocą języka skryptowego lub programu wiersza polecenia.
jobs:
- job: generator
steps:
- bash: echo "##vso[task.setVariable variable=legs;isOutput=true]{'a':{'myvar':'A'}, 'b':{'myvar':'B'}}"
name: mtrx
# This expands to the matrix
# a:
# myvar: A
# b:
# myvar: B
- job: runner
dependsOn: generator
strategy:
matrix: $[ dependencies.generator.outputs['mtrx.legs'] ]
steps:
- script: echo $(myvar) # echos A or B depending on which leg is running
Krojenie
Zadanie agenta może służyć do równoległego uruchamiania zestawu testów. Na przykład można uruchomić duży pakiet 1000 testów na jednym agencie. Możesz też użyć dwóch agentów i uruchomić 500 testów na każdym z nich równolegle.
Aby zastosować fragmentowanie, zadania w zadaniu powinny być wystarczająco inteligentne, aby zrozumieć fragment, do którego należą.
Zadanie testowe programu Visual Studio to jedno z takich zadań, które obsługuje fragmentowanie testowe. Jeśli zainstalowano wielu agentów, możesz określić, w jaki sposób zadanie testowe programu Visual Studio jest uruchamiane równolegle na tych agentach.
Strategia parallel umożliwia wielokrotne duplikowanie zadania.
Zmienne System.JobPositionInPhase i System.TotalJobsInPhase są dodawane do każdego zadania. Zmienne mogą być następnie używane w skryptach do dzielenia pracy między zadaniami.
Zobacz Równoległe i wiele wykonań przy użyciu zadań agenta.
Następujące zadanie jest wysyłane pięć razy z wartościami System.JobPositionInPhase i System.TotalJobsInPhase ustawionymi odpowiednio.
jobs:
- job: Test
strategy:
parallel: 5
Zmienne zadania
Jeśli używasz języka YAML, zmienne można określić w zadaniu. Zmienne mogą być przekazywane do danych wejściowych zadań przy użyciu składni makr $(variableName) lub uzyskiwane w skrypcie przy użyciu zmiennej etapu.
Oto przykład definiowania zmiennych w zadaniu i używania ich w ramach zadań podrzędnych.
variables:
mySimpleVar: simple var value
"my.dotted.var": dotted var value
"my var with spaces": var with spaces value
steps:
- script: echo Input macro = $(mySimpleVar). Env var = %MYSIMPLEVAR%
condition: eq(variables['agent.os'], 'Windows_NT')
- script: echo Input macro = $(mySimpleVar). Env var = $MYSIMPLEVAR
condition: in(variables['agent.os'], 'Darwin', 'Linux')
- bash: echo Input macro = $(my.dotted.var). Env var = $MY_DOTTED_VAR
- powershell: Write-Host "Input macro = $(my var with spaces). Env var = $env:MY_VAR_WITH_SPACES"
Aby uzyskać informacje na temat używania warunku, zobacz Określanie warunków.
Obszar roboczy
Po uruchomieniu zadania puli agentów program tworzy obszar roboczy na agencie. Obszar roboczy to katalog, w którym pobiera źródło, uruchamia kroki i generuje dane wyjściowe. Do katalogu obszaru roboczego można odwoływać się w zadaniu przy użyciu Pipeline.Workspace zmiennej . W tym celu tworzone są różne podkatalogi:
-
Build.SourcesDirectoryto miejsce, w którym zadania pobierają kod źródłowy aplikacji. -
Build.ArtifactStagingDirectoryto miejsce, w którym zadania pobierają artefakty potrzebne do potoku lub przesyłają artefakty, zanim zostaną opublikowane. -
Build.BinariesDirectoryto miejsce, w którym zadania zapisują swoje dane wyjściowe. -
Common.TestResultsDirectoryto miejsce, w którym zadania przekazują wyniki testów.
$(Build.ArtifactStagingDirectory) i $(Common.TestResultsDirectory) są zawsze usuwane i tworzone ponownie przed każdą kompilacją.
Po uruchomieniu potoku na własnym agencie domyślnie żaden z podkatalogów innych niż $(Build.ArtifactStagingDirectory) i $(Common.TestResultsDirectory) nie jest czyszczony między dwoma kolejnymi przebiegami. W rezultacie możliwe są kompilacje przyrostowe i wdrożenia, jeśli zadania są zaimplementowane w taki sposób, by z nich korzystać. Możesz zastąpić to zachowanie, używając ustawienia workspace w zadaniu.
Ważne
Opcje czyszczenia obszaru roboczego mają zastosowanie tylko dla własnych agentów. Zadania są zawsze uruchamiane na nowym agencie hostowanym przez firmę Microsoft.
- job: myJob
workspace:
clean: outputs | resources | all # what to clean up before the job runs
Po określeniu clean jednej z opcji są one interpretowane w następujący sposób:
-
outputs: UsuńBuild.BinariesDirectoryprzed uruchomieniem nowego zadania. -
resources: UsuńBuild.SourcesDirectoryprzed uruchomieniem nowego zadania. -
all: Usuń całyPipeline.Workspacekatalog przed uruchomieniem nowego zadania.
jobs:
- deployment: MyDeploy
pool:
vmImage: 'ubuntu-latest'
workspace:
clean: all
environment: staging
Uwaga
W zależności od możliwości agentów i wymagań potoku, każde zadanie może być kierowane do innego agenta w puli, którą sam zarządzasz. W wyniku tego możesz otrzymać nowego agenta dla kolejnych przebiegów potoku (lub etapów, lub zadań w tym samym potoku), dlatego brak , a nie czyszczenia, nie gwarantuje, że kolejne przebiegi, zadania lub etapy będą miały dostęp do danych wyjściowych z wcześniejszych przebiegów, zadań lub etapów. Można skonfigurować możliwości agenta i wymagania pipeline'u, aby określić, którzy agenci są używani do uruchamiania zadania pipeline'u. Ale jeśli w puli nie ma tylko jednego agenta spełniającego wymagania, nie ma gwarancji, że kolejne zadania używają tego samego agenta co poprzednie zadania. Aby uzyskać więcej informacji, zobacz Określanie wymagań.
Oprócz czyszczenia obszaru roboczego, można również skonfigurować proces czyszczenia, konfigurując ustawienie Czyszczenie w interfejsie użytkownika ustawień potoku.
Jeśli ustawienie Clean (Czyszczenie) ma wartość true( jest również jego wartością domyślną), jest równoważne określeniu dla każdego kroku wyewidencjonowania clean: true w potoku. Po określeniu clean: trueuruchom git clean -ffdx, a następnie git reset --hard HEAD przed wykonaniem pobrania za pomocą Git. Aby skonfigurować ustawienie Czyszczenie :
Edytuj potok, wybierz ..., a następnie Wyzwalacze.
Wybierz YAML, Pobierz źródła i skonfiguruj preferowane ustawienie Wyczyść. Wartość domyślna to true.
Pobieranie artefaktu
Ten przykładowy plik YAML publikuje artefakt Website , a następnie pobiera artefakt do $(Pipeline.Workspace). Zadanie Wdróż jest uruchamiane tylko wtedy, gdy zadanie kompilacji zakończy się pomyślnie.
# test and upload my code as an artifact named Website
jobs:
- job: Build
pool:
vmImage: 'ubuntu-latest'
steps:
- script: npm test
- task: PublishPipelineArtifact@1
inputs:
artifactName: Website
targetPath: '$(System.DefaultWorkingDirectory)'
# download the artifact and deploy it only if the build job succeeded
- job: Deploy
pool:
vmImage: 'ubuntu-latest'
steps:
- checkout: none #skip checking out the default repository resource
- task: DownloadPipelineArtifact@2
displayName: 'Download Pipeline Artifact'
inputs:
artifactName: Website
targetPath: '$(Pipeline.Workspace)'
dependsOn: Build
condition: succeeded()
Aby uzyskać informacje na temat korzystania z dependsOn i condition, zobacz Określanie warunków.
Dostęp do tokenu OAuth
Skrypty uruchomione w zadaniu umożliwiają dostęp do bieżącego tokenu zabezpieczającego OAuth usługi Azure Pipelines. Token może służyć do uwierzytelniania w interfejsie API REST usługi Azure Pipelines.
Token OAuth jest zawsze dostępny dla potoków YAML.
Musi być jawnie przypisany do zadania lub kroku za pomocą polecenia env.
Oto przykład:
steps:
- powershell: |
$url = "$($env:SYSTEM_TEAMFOUNDATIONCOLLECTIONURI)$env:SYSTEM_TEAMPROJECTID/_apis/build/definitions/$($env:SYSTEM_DEFINITIONID)?api-version=4.1-preview"
Write-Host "URL: $url"
$pipeline = Invoke-RestMethod -Uri $url -Headers @{
Authorization = "Bearer $env:SYSTEM_ACCESSTOKEN"
}
Write-Host "Pipeline = $($pipeline | ConvertTo-Json -Depth 100)"
env:
SYSTEM_ACCESSTOKEN: $(system.accesstoken)