Definiowanie zmiennych
Azure DevOps Services | Azure DevOps Server 2022 — Azure DevOps Server 2019
Zmienne umożliwiają wygodne uzyskiwanie kluczowych danych w różnych częściach potoku. Najczęstszym zastosowaniem zmiennych jest definiowanie wartości, których można następnie używać w potoku. Wszystkie zmienne są ciągami i są modyfikowalne. Wartość zmiennej może ulec zmianie między poszczególnymi przebiegami lub zadaniami potoku.
Podczas definiowania tej samej zmiennej w wielu miejscach o tej samej nazwie pierwszeństwo ma najbardziej lokalnie ograniczona zmienna. Dlatego zmienna zdefiniowana na poziomie zadania może zastąpić zmienną ustawioną na poziomie etapu. Zmienna zdefiniowana na poziomie etapu zastępuje zmienną ustawioną na poziomie głównym potoku. Zmienna ustawiona na poziomie głównym potoku zastępuje zmienną ustawioną w interfejsie użytkownika ustawień potoku. Aby dowiedzieć się więcej na temat pracy ze zmiennymi zdefiniowanymi na poziomie zadania, etapu i katalogu głównego, zobacz Zakres zmiennych.
Zmienne z wyrażeniami umożliwiają warunkowe przypisywanie wartości i dalsze dostosowywanie potoków.
Zmienne różnią się od parametrów środowiska uruchomieniowego. Parametry środowiska uruchomieniowego są wpisywane i są dostępne podczas analizowania szablonu.
Zmienne zdefiniowane przez użytkownika
Podczas definiowania zmiennej można użyć różnych składni (makra, wyrażenia szablonu lub środowiska uruchomieniowego) i składni, która określa, gdzie w potoku jest renderowana zmienna.
W potokach YAML można ustawić zmienne na poziomie głównym, etapu i zadania. Można również określić zmienne poza potokiem YAML w interfejsie użytkownika. Po ustawieniu zmiennej w interfejsie użytkownika ta zmienna może być zaszyfrowana i ustawiona jako wpis tajny.
Zmienne zdefiniowane przez użytkownika można ustawić jako tylko do odczytu. Istnieją ograniczenia nazewnictwa zmiennych (na przykład: nie można użyć secret na początku nazwy zmiennej).
Możesz użyć grupy zmiennych, aby udostępnić zmienne w wielu potokach.
Użyj szablonów , aby zdefiniować zmienne w jednym pliku, który jest używany w wielu potokach.
Zmienne wielowierszowe zdefiniowane przez użytkownika
Usługa Azure DevOps obsługuje zmienne wielowierszowe, ale istnieje kilka ograniczeń.
Składniki podrzędne, takie jak zadania potoku, mogą nie obsługiwać poprawnie wartości zmiennych.
Usługa Azure DevOps nie zmieni wartości zmiennych zdefiniowanych przez użytkownika. Wartości zmiennych muszą być poprawnie sformatowane przed przekazaniem ich jako zmiennych wielowierszowych. Podczas formatowania zmiennej unikaj znaków specjalnych, nie używaj nazw z ograniczeniami i upewnij się, że używasz formatu końcowego wiersza, który działa dla systemu operacyjnego agenta.
Zmienne wielowierszowe zachowują się inaczej w zależności od systemu operacyjnego. Aby tego uniknąć, upewnij się, że poprawnie formatujesz zmienne wielowierszowe dla docelowego systemu operacyjnego.
Usługa Azure DevOps nigdy nie zmienia wartości zmiennych, nawet jeśli udostępniasz nieobsługiwane formatowanie.
Zmienne systemowe
Oprócz zmiennych zdefiniowanych przez użytkownika usługa Azure Pipelines ma zmienne systemowe ze wstępnie zdefiniowanymi wartościami. Na przykład wstępnie zdefiniowana zmienna Build.BuildId podaje identyfikator każdej kompilacji i może służyć do identyfikowania różnych przebiegów potoku. Możesz użyć zmiennej Build.BuildId w skryptach lub zadaniach, gdy zachodzi potrzeba unikatowej wartości.
Jeśli używasz potoków YAML lub klasycznych potoków kompilacji, zobacz wstępnie zdefiniowane zmienne , aby uzyskać pełną listę zmiennych systemowych.
Jeśli używasz klasycznych potoków wydania, zobacz zmienne wydania.
Zmienne systemowe są ustawiane z ich bieżącą wartością podczas uruchamiania potoku. Niektóre zmienne są ustawiane automatycznie. Jako autor potoku lub użytkownik końcowy zmienia wartość zmiennej systemowej przed uruchomieniem potoku.
Zmienne systemowe są tylko do odczytu.
Zmienne środowiskowe
Zmienne środowiskowe są specyficzne dla używanego systemu operacyjnego. Są one wstrzykiwane do potoku w sposób specyficzny dla platformy. Format odpowiada sposobie formatowania zmiennych środowiskowych dla określonej platformy skryptów.
W systemach UNIX (macOS i Linux) zmienne środowiskowe mają format $NAME. W systemie Windows format jest %NAME% przeznaczony dla partii i $env:NAME w programie PowerShell.
Zmienne systemowe i zdefiniowane przez użytkownika również są wstrzykiwane jako zmienne środowiskowe dla platformy. Gdy zmienne są konwertowane na zmienne środowiskowe, nazwy zmiennych stają się wielkimi literami, a kropki zamieniają się w podkreślenia. Na przykład nazwa any.variable zmiennej staje się nazwą $ANY_VARIABLEzmiennej .
Istnieją ograniczenia nazewnictwa zmiennych zmiennych środowiskowych (na przykład: nie można użyć secret na początku nazwy zmiennej).
Ograniczenia nazewnictwa zmiennych
Zmienne środowiskowe zdefiniowane przez użytkownika mogą składać się z liter, cyfr, .i _ znaków. Nie używaj prefiksów zmiennych zarezerwowanych przez system. Oto: endpoint, , inputsecret, path, i securefile. Każda zmienna rozpoczynająca się od jednego z tych ciągów (niezależnie od wielkich liter) nie będzie dostępna dla zadań i skryptów.
Omówienie składni zmiennych
Usługa Azure Pipelines obsługuje trzy różne sposoby odwoływania się do zmiennych: makro, wyrażenie szablonu i wyrażenie środowiska uruchomieniowego. Każdą składnię można używać do innego celu, a każda z nich ma pewne ograniczenia.
W potoku zmienne wyrażeń szablonu (${{ variables.var }}) są przetwarzane w czasie kompilacji przed uruchomieniem środowiska uruchomieniowego. Zmienne składni makr ($(var)) są przetwarzane podczas wykonywania przed uruchomieniem zadania. Wyrażenia środowiska uruchomieniowego ($[variables.var]) również są przetwarzane podczas wykonywania, ale mają być używane z warunkami i wyrażeniami. Gdy używasz wyrażenia środowiska uruchomieniowego, musi ono obejmować całą prawą stronę definicji.
W tym przykładzie widać, że wyrażenie szablonu nadal ma początkową wartość zmiennej po zaktualizowaniu zmiennej. Wartość zmiennej składni makra jest aktualizowana. Wartość wyrażenia szablonu nie zmienia się, ponieważ wszystkie zmienne wyrażeń szablonu są przetwarzane w czasie kompilacji przed uruchomieniem zadań. Z kolei zmienne składni makr są obliczane przed każdym uruchomieniem zadania.
variables:
- name: one
value: initialValue
steps:
- script: |
echo ${{ variables.one }} # outputs initialValue
echo $(one)
displayName: First variable pass
- bash: echo "##vso[task.setvariable variable=one]secondValue"
displayName: Set new variable value
- script: |
echo ${{ variables.one }} # outputs initialValue
echo $(one) # outputs secondValue
displayName: Second variable pass
Zmienne składni makr
Większość przykładów dokumentacji używa składni makr ($(var)). Składnia makr została zaprojektowana tak, aby interpolować wartości zmiennych do danych wejściowych zadań i innych zmiennych.
Zmienne ze składnią makr są przetwarzane przed wykonaniem zadania w czasie wykonywania. Środowisko uruchomieniowe odbywa się po rozszerzeniu szablonu. Gdy system napotka wyrażenie makra, zastępuje wyrażenie zawartością zmiennej. Jeśli nie ma zmiennej o tej nazwie, wyrażenie makra nie zmienia się. Jeśli na przykład $(var) nie można go zamienić, $(var) nie zostanie zastąpiony przez nic.
Zmienne składni makr pozostają niezmienione bez wartości, ponieważ pusta wartość $() może oznaczać coś do uruchomionego zadania, a agent nie powinien zakładać, że ta wartość została zamieniona. Jeśli na przykład używasz $(foo) metody do odwoływania się do zmiennej w zadaniu powłoki foo Bash, zastąpienie wszystkich $() wyrażeń w danych wejściowych do zadania może spowodować przerwanie skryptów powłoki Bash.
Zmienne makr są rozszerzane tylko wtedy, gdy są używane dla wartości, a nie jako słowa kluczowego. Wartości są wyświetlane po prawej stronie definicji potoku. Następujące elementy są prawidłowe: key: $(value). Następujące elementy nie są prawidłowe: $(key): value. Zmienne makr nie są rozszerzane, gdy są używane do wyświetlania wbudowanej nazwy zadania. Zamiast tego należy użyć displayName właściwości .
Uwaga
Zmienne składni makra są rozszerzane tylko dla stages, jobsi steps.
Nie można na przykład użyć składni makr wewnątrz elementu resource lub trigger.
W tym przykładzie użyto składni makr z powłoką Bash, programem PowerShell i zadaniem skryptu. Składnia wywoływania zmiennej ze składnią makr jest taka sama dla wszystkich trzech.
variables:
- name: projectName
value: contoso
steps:
- bash: echo $(projectName)
- powershell: echo $(projectName)
- script: echo $(projectName)
Składnia wyrażenia szablonu
Składnia wyrażeń szablonu umożliwia rozwinięcie parametrów szablonu i zmiennych (${{ variables.var }}). Zmienne szablonu są przetwarzane w czasie kompilacji i są zastępowane przed uruchomieniem środowiska uruchomieniowego. Wyrażenia szablonów są przeznaczone do ponownego użytku części YAML jako szablonów.
Zmienne szablonu w trybie dyskretnym łączą się z pustymi ciągami, gdy nie można odnaleźć wartości zastępczej. Wyrażenia szablonu, w przeciwieństwie do wyrażeń makr i środowiska uruchomieniowego, mogą być wyświetlane jako klucze (po lewej stronie) lub wartości (po prawej stronie). Następujące elementy są prawidłowe: ${{ variables.key }} : ${{ variables.value }}.
Składnia wyrażeń środowiska uruchomieniowego
Składnię wyrażeń środowiska uruchomieniowego można użyć dla zmiennych, które są rozwinięte w czasie wykonywania ($[variables.var]). Zmienne wyrażeń środowiska uruchomieniowego w trybie dyskretnym łączą się z pustymi ciągami, gdy nie można odnaleźć wartości zastępczej. Użyj wyrażeń środowiska uruchomieniowego w warunkach zadania, aby obsługiwać warunkowe wykonywanie zadań lub całych etapów.
Zmienne wyrażeń środowiska uruchomieniowego są rozszerzane tylko wtedy, gdy są używane dla wartości, a nie jako słowa kluczowego. Wartości są wyświetlane po prawej stronie definicji potoku. Następujące elementy są prawidłowe: key: $[variables.value]. Następujące elementy nie są prawidłowe: $[variables.key]: value. Wyrażenie środowiska uruchomieniowego musi podjąć całą prawą stronę pary klucz-wartość. Na przykład jest prawidłowy, key: $[variables.value] ale key: $[variables.value] foo nie.
| Składnia | Przykład | Kiedy jest przetwarzany? | Gdzie rozszerza się w definicji potoku? | Jak jest renderowany po znalezieniu? |
|---|---|---|---|---|
| Makro | $(var) |
środowisko uruchomieniowe przed wykonaniem zadania | wartość (po prawej stronie) | Drukuje $(var) |
| wyrażenie szablonu | ${{ variables.var }} |
czas kompilacji | klucz lub wartość (po lewej lub prawej stronie) | pusty ciąg |
| wyrażenie środowiska uruchomieniowego | $[variables.var] |
środowisko uruchomieniowe | wartość (po prawej stronie) | pusty ciąg |
Jakiej składni należy użyć?
Użyj składni makr, jeśli udostępniasz bezpieczny ciąg lub wstępnie zdefiniowaną zmienną wejściową dla zadania.
Wybierz wyrażenie środowiska uruchomieniowego, jeśli pracujesz z warunkami i wyrażeniami. Nie używaj jednak wyrażenia środowiska uruchomieniowego, jeśli nie chcesz, aby pusta zmienna drukowała (na przykład: $[variables.var]). Jeśli na przykład masz logikę warunkową, która opiera się na zmiennej o określonej wartości lub bez wartości. W takim przypadku należy użyć wyrażenia makra.
Zazwyczaj zmienna szablonu jest standardem do użycia. Korzystając ze zmiennych szablonu, potok w pełni wstrzykuje wartość zmiennej do potoku podczas kompilacji potoku. Jest to przydatne podczas próby debugowania potoków. Możesz pobrać pliki dziennika i ocenić w pełni rozszerzoną wartość, która jest zastępowana. Ponieważ zmienna jest zastępowana, nie należy używać składni szablonu dla wartości poufnych.
Ustawianie zmiennych w potoku
W najczęstszym przypadku należy ustawić zmienne i użyć ich w pliku YAML. Dzięki temu można śledzić zmiany w zmiennej w systemie kontroli wersji. Zmienne można również zdefiniować w interfejsie użytkownika ustawień potoku (zobacz kartę Klasyczna) i odwołać się do nich w języku YAML.
Oto przykład pokazujący, jak ustawić dwie zmienne configuration i platform, i użyć ich w dalszej części kroków. Aby użyć zmiennej w instrukcji YAML, zawijaj ją w pliku $(). Zmienne nie mogą służyć do definiowania repository w instrukcji YAML.
# Set variables once
variables:
configuration: debug
platform: x64
steps:
# Use them once
- task: MSBuild@1
inputs:
solution: solution1.sln
configuration: $(configuration) # Use the variable
platform: $(platform)
# Use them again
- task: MSBuild@1
inputs:
solution: solution2.sln
configuration: $(configuration) # Use the variable
platform: $(platform)
Zmienna zakresów
W pliku YAML można ustawić zmienną w różnych zakresach:
- Na poziomie głównym, aby udostępnić go wszystkim zadaniam w potoku.
- Na poziomie etapu, aby udostępnić go tylko do określonego etapu.
- Na poziomie zadania, aby udostępnić je tylko określonemu zadaniu.
Podczas definiowania zmiennej w górnej części kodu YAML zmienna jest dostępna dla wszystkich zadań i etapów w potoku i jest zmienną globalną. Zmienne globalne zdefiniowane w języku YAML nie są widoczne w interfejsie użytkownika ustawień potoku.
Zmienne na poziomie zadania zastępują zmienne na poziomie głównym i etapowym. Zmienne na poziomie etapu zastępują zmienne na poziomie głównym.
variables:
global_variable: value # this is available to all jobs
jobs:
- job: job1
pool:
vmImage: 'ubuntu-latest'
variables:
job_variable1: value1 # this is only available in job1
steps:
- bash: echo $(global_variable)
- bash: echo $(job_variable1)
- bash: echo $JOB_VARIABLE1 # variables are available in the script environment too
- job: job2
pool:
vmImage: 'ubuntu-latest'
variables:
job_variable2: value2 # this is only available in job2
steps:
- bash: echo $(global_variable)
- bash: echo $(job_variable2)
- bash: echo $GLOBAL_VARIABLE
Dane wyjściowe z obu zadań wyglądają następująco:
# job1
value
value1
value1
# job2
value
value2
value
Określanie zmiennych
W poprzednich przykładach variables słowo kluczowe następuje po nim lista par klucz-wartość.
Klucze są nazwami zmiennych, a wartości są wartościami zmiennych.
Istnieje inna składnia, przydatna, gdy chcesz użyć szablonów dla zmiennych lub grup zmiennych.
Za pomocą szablonów zmienne można zdefiniować w jednym yaml i uwzględnić w innym pliku YAML.
Grupy zmiennych to zestaw zmiennych, których można używać w wielu potokach. Umożliwiają one zarządzanie zmiennymi i ich organizowanie, które są wspólne dla różnych etapów w jednym miejscu.
Użyj tej składni dla szablonów zmiennych i grup zmiennych na poziomie głównym potoku.
W tej alternatywnej składni variables słowo kluczowe przyjmuje listę specyfikatorów zmiennych.
Specyfikatory zmiennych są name dla zmiennej regularnej, group dla grupy zmiennych i template do uwzględnienia szablonu zmiennej.
W poniższym przykładzie pokazano wszystkie trzy.
variables:
# a regular variable
- name: myvariable
value: myvalue
# a variable group
- group: myvariablegroup
# a reference to a variable template
- template: myvariabletemplate.yml
Dowiedz się więcej o ponownym użyciu zmiennych za pomocą szablonów.
Uzyskiwanie dostępu do zmiennych za pośrednictwem środowiska
Zwróć uwagę, że zmienne są również udostępniane skryptom za pośrednictwem zmiennych środowiskowych. Składnia używania tych zmiennych środowiskowych zależy od języka skryptowego.
Nazwa jest wielkie litery, a element . jest zastępowany ciągiem _. Jest to automatycznie wstawione do środowiska przetwarzania. Oto kilka przykładów:
- Skrypt usługi Batch:
%VARIABLE_NAME% - Skrypt programu PowerShell:
$env:VARIABLE_NAME - Skrypt powłoki Bash:
$VARIABLE_NAME
Ważne
Wstępnie zdefiniowane zmienne zawierające ścieżki plików są tłumaczone na odpowiedni styl (styl systemu Windows C:\foo\ a styl systemu Unix /foo/) na podstawie typu hosta agenta i typu powłoki. Jeśli uruchamiasz zadania skryptu powłoki bash w systemie Windows, należy użyć metody zmiennej środowiskowej do uzyskiwania dostępu do tych zmiennych, a nie metody zmiennej potoku, aby upewnić się, że masz poprawny styl ścieżki pliku.
Ustawianie zmiennych tajnych
Napiwek
Zmienne tajne nie są automatycznie eksportowane jako zmienne środowiskowe. Aby użyć zmiennych tajnych w skryptach, jawnie zamapuj je na zmienne środowiskowe. Aby uzyskać więcej informacji, zobacz Ustawianie zmiennych tajnych.
Nie ustawiaj zmiennych tajnych w pliku YAML. Systemy operacyjne często rejestrują polecenia dla uruchomionych procesów i nie chcesz, aby dziennik zawierał wpis tajny przekazany jako dane wejściowe. Użyj środowiska skryptu lub zamapuj zmienną w variables bloku, aby przekazać wpisy tajne do potoku.
Uwaga
Usługa Azure Pipelines podejmuje próbę maskowania wpisów tajnych podczas emitowania danych do dzienników potoku, dzięki czemu mogą być widoczne dodatkowe zmienne i dane maskowane w danych wyjściowych i dziennikach, które nie są ustawione jako wpisy tajne.
Musisz ustawić zmienne tajne w interfejsie użytkownika ustawień potoku dla potoku. Te zmienne są ograniczone do potoku, w którym są ustawione. Można również ustawić zmienne tajne w grupach zmiennych.
Aby ustawić wpisy tajne w interfejsie internetowym, wykonaj następujące kroki:
- Przejdź do strony Potoki , wybierz odpowiedni potok, a następnie wybierz pozycję Edytuj.
- Znajdź zmienne dla tego potoku.
- Dodaj lub zaktualizuj zmienną.
- Wybierz opcję Zachowaj ten wpis tajny wartości, aby przechowywać zmienną w zaszyfrowany sposób.
- Zapisz potok.
Zmienne tajne są szyfrowane w spoczynku przy użyciu 2048-bitowego klucza RSA. Wpisy tajne są dostępne w agencie dla zadań i skryptów do użycia. Uważaj, kto ma dostęp do zmiany potoku.
Ważne
Staramy się maskować wpisy tajne przed pojawieniem się w danych wyjściowych usługi Azure Pipelines, ale nadal trzeba podjąć środki ostrożności. Nigdy nie powtarzaj wpisów tajnych jako danych wyjściowych. Niektóre argumenty wiersza polecenia dziennika systemów operacyjnych. Nigdy nie przekazuj wpisów tajnych w wierszu polecenia. Zamiast tego sugerujemy mapowania wpisów tajnych na zmienne środowiskowe.
Nigdy nie maskujemy podciągów wpisów tajnych. Jeśli na przykład "abc123" jest ustawiony jako wpis tajny, "abc" nie jest maskowany z dzienników. Jest to unikanie maskowania wpisów tajnych na zbyt szczegółowym poziomie, dzięki czemu dzienniki są nieczytelne. Z tego powodu wpisy tajne nie powinny zawierać danych strukturalnych. Jeśli na przykład "{ "foo": "bar" }" jest ustawiony jako wpis tajny, "pasek" nie jest maskowany z dzienników.
W przeciwieństwie do zmiennej normalnej nie są one automatycznie odszyfrowywane do zmiennych środowiskowych dla skryptów. Musisz jawnie mapować zmienne tajne.
W poniższym przykładzie pokazano, jak mapować i używać zmiennej tajnej o nazwie mySecret w skryptach programu PowerShell i powłoki Bash. Definiowane są dwie zmienne globalne. GLOBAL_MYSECRET jest przypisywana wartość zmiennej mySecrettajnej i GLOBAL_MY_MAPPED_ENV_VAR jest przypisywana wartość zmiennej nonSecretVariableinnej niż wpis tajny . W przeciwieństwie do standardowej zmiennej potoku nie ma zmiennej środowiskowej o nazwie MYSECRET.
Zadanie programu PowerShell uruchamia skrypt, aby wydrukować zmienne.
$(mySecret): Jest to bezpośrednie odwołanie do zmiennej tajnej i działa.$env:MYSECRET: Próbuje uzyskać dostęp do zmiennej tajnej jako zmiennej środowiskowej, która nie działa, ponieważ zmienne tajne nie są automatycznie mapowane na zmienne środowiskowe.$env:GLOBAL_MYSECRET: Próbuje uzyskać dostęp do zmiennej tajnej za pośrednictwem zmiennej globalnej, która również nie działa, ponieważ zmienne tajne nie mogą być mapowane w ten sposób.$env:GLOBAL_MY_MAPPED_ENV_VAR: uzyskuje dostęp do zmiennej innej niż wpis tajny za pośrednictwem zmiennej globalnej, która działa.$env:MY_MAPPED_ENV_VAR: uzyskuje dostęp do zmiennej tajnej za pośrednictwem zmiennej środowiskowej specyficznej dla zadania, która jest zalecanym sposobem mapowania zmiennych tajnych na zmienne środowiskowe.
variables:
GLOBAL_MYSECRET: $(mySecret) # this will not work because the secret variable needs to be mapped as env
GLOBAL_MY_MAPPED_ENV_VAR: $(nonSecretVariable) # this works because it's not a secret.
steps:
- powershell: |
Write-Host "Using an input-macro works: $(mySecret)"
Write-Host "Using the env var directly does not work: $env:MYSECRET"
Write-Host "Using a global secret var mapped in the pipeline does not work either: $env:GLOBAL_MYSECRET"
Write-Host "Using a global non-secret var mapped in the pipeline works: $env:GLOBAL_MY_MAPPED_ENV_VAR"
Write-Host "Using the mapped env var for this task works and is recommended: $env:MY_MAPPED_ENV_VAR"
env:
MY_MAPPED_ENV_VAR: $(mySecret) # the recommended way to map to an env variable
- bash: |
echo "Using an input-macro works: $(mySecret)"
echo "Using the env var directly does not work: $MYSECRET"
echo "Using a global secret var mapped in the pipeline does not work either: $GLOBAL_MYSECRET"
echo "Using a global non-secret var mapped in the pipeline works: $GLOBAL_MY_MAPPED_ENV_VAR"
echo "Using the mapped env var for this task works and is recommended: $MY_MAPPED_ENV_VAR"
env:
MY_MAPPED_ENV_VAR: $(mySecret) # the recommended way to map to an env variable
Dane wyjściowe z obu zadań w poprzednim skry skrycie będą wyglądać następująco:
Using an input-macro works: ***
Using the env var directly does not work:
Using a global secret var mapped in the pipeline does not work either:
Using a global non-secret var mapped in the pipeline works: foo
Using the mapped env var for this task works and is recommended: ***
Można również używać zmiennych tajnych poza skryptami. Na przykład można mapować zmienne tajne na zadania przy użyciu variables definicji. W tym przykładzie pokazano, jak używać zmiennych tajnych $(vmsUser) i $(vmsAdminPass) w zadaniu kopiowania plików platformy Azure.
variables:
VMS_USER: $(vmsUser)
VMS_PASS: $(vmsAdminPass)
pool:
vmImage: 'ubuntu-latest'
steps:
- task: AzureFileCopy@4
inputs:
SourcePath: 'my/path'
azureSubscription: 'my-subscription'
Destination: 'AzureVMs'
storage: 'my-storage'
resourceGroup: 'my-rg'
vmsAdminUserName: $(VMS_USER)
vmsAdminPassword: $(VMS_PASS)
Odwoływania się do zmiennych tajnych w grupach zmiennych
W tym przykładzie pokazano, jak odwoływać się do grupy zmiennych w pliku YAML, a także jak dodawać zmienne w pliku YAML. Istnieją dwie zmienne używane z grupy zmiennych: user i token. Zmienna token jest wpisem tajnym i jest mapowana na zmienną środowiskową $env:MY_MAPPED_TOKEN , aby można było odwoływać się do niej w języku YAML.
Ten kod YAML wykonuje wywołanie REST w celu pobrania listy wydań i zwraca wynik.
variables:
- group: 'my-var-group' # variable group
- name: 'devopsAccount' # new variable defined in YAML
value: 'contoso'
- name: 'projectName' # new variable defined in YAML
value: 'contosoads'
steps:
- task: PowerShell@2
inputs:
targetType: 'inline'
script: |
# Encode the Personal Access Token (PAT)
# $env:USER is a normal variable in the variable group
# $env:MY_MAPPED_TOKEN is a mapped secret variable
$base64AuthInfo = [Convert]::ToBase64String([Text.Encoding]::ASCII.GetBytes(("{0}:{1}" -f $env:USER,$env:MY_MAPPED_TOKEN)))
# Get a list of releases
$uri = "https://vsrm.dev.azure.com/$(devopsAccount)/$(projectName)/_apis/release/releases?api-version=5.1"
# Invoke the REST call
$result = Invoke-RestMethod -Uri $uri -Method Get -ContentType "application/json" -Headers @{Authorization=("Basic {0}" -f $base64AuthInfo)}
# Output releases in JSON
Write-Host $result.value
env:
MY_MAPPED_TOKEN: $(token) # Maps the secret variable $(token) from my-var-group
Ważne
Domyślnie w przypadku repozytoriów GitHub zmienne tajne skojarzone z potokiem nie są udostępniane kompilacjom rozwidlenia żądań ściągnięcia. Aby uzyskać więcej informacji, zobacz Współautorzy z rozwidlenia.
Udostępnianie zmiennych między potokami
Aby udostępnić zmienne w wielu potokach w projekcie, użyj interfejsu internetowego. W obszarze Biblioteka użyj grup zmiennych.
Używanie zmiennych wyjściowych z zadań
Niektóre zadania definiują zmienne wyjściowe, które można używać w krokach podrzędnych, zadaniach i etapach. W języku YAML można uzyskiwać dostęp do zmiennych między zadaniami i etapami przy użyciu zależności.
Podczas odwoływania się do zadań macierzy w podrzędnych zadaniach należy użyć innej składni. Zobacz Ustawianie zmiennej wyjściowej z wieloma zadaniami. Należy również użyć innej składni dla zmiennych w zadaniach wdrażania. Zobacz Obsługa zmiennych wyjściowych w zadaniach wdrażania.
Niektóre zadania definiują zmienne wyjściowe, które można używać w krokach podrzędnych i zadaniach w ramach tego samego etapu. W języku YAML można uzyskiwać dostęp do zmiennych między zadaniami przy użyciu zależności.
- Aby odwołać się do zmiennej z innego zadania w ramach tego samego zadania, użyj polecenia
TASK.VARIABLE. - Aby odwołać się do zmiennej z zadania innego zadania, użyj polecenia
dependencies.JOB.outputs['TASK.VARIABLE'].
Uwaga
Domyślnie każdy etap w potoku zależy od tego, który jest tuż przed nim w pliku YAML. Jeśli musisz odwołać się do etapu, który nie jest bezpośrednio przed bieżącym etapem, możesz zastąpić tę automatyczną wartość domyślną, dodając sekcję dependsOn do etapu.
Uwaga
W poniższych przykładach użyto standardowej składni potoku. Jeśli używasz potoków wdrażania, składnia zmiennych i zmiennych warunkowych będzie się różnić. Aby uzyskać informacje o określonej składni do użycia, zobacz Zadania wdrażania.
W tych przykładach załóżmy, że mamy zadanie o nazwie MyTask, które ustawia zmienną wyjściową o nazwie MyVar.
Dowiedz się więcej o składni w temacie Wyrażenia — zależności.
Użyj danych wyjściowych w tym samym zadaniu
steps:
- task: MyTask@1 # this step generates the output variable
name: ProduceVar # because we're going to depend on it, we need to name the step
- script: echo $(ProduceVar.MyVar) # this step uses the output variable
Używanie danych wyjściowych w innym zadaniu
jobs:
- job: A
steps:
# assume that MyTask generates an output variable called "MyVar"
# (you would learn that from the task's documentation)
- task: MyTask@1
name: ProduceVar # because we're going to depend on it, we need to name the step
- job: B
dependsOn: A
variables:
# map the output variable from A into this job
varFromA: $[ dependencies.A.outputs['ProduceVar.MyVar'] ]
steps:
- script: echo $(varFromA) # this step uses the mapped-in variable
Używanie danych wyjściowych na innym etapie
Aby użyć danych wyjściowych z innego etapu, format odwołujące się do zmiennych to stageDependencies.STAGE.JOB.outputs['TASK.VARIABLE']. Na poziomie etapu, ale nie na poziomie zadania, można użyć tych zmiennych w warunkach.
Zmienne wyjściowe są dostępne tylko w następnym etapie podrzędnym. Jeśli wiele etapów używa tej samej zmiennej wyjściowej, użyj dependsOn warunku .
stages:
- stage: One
jobs:
- job: A
steps:
- task: MyTask@1 # this step generates the output variable
name: ProduceVar # because we're going to depend on it, we need to name the step
- stage: Two
dependsOn:
- One
jobs:
- job: B
variables:
# map the output variable from A into this job
varFromA: $[ stageDependencies.One.A.outputs['ProduceVar.MyVar'] ]
steps:
- script: echo $(varFromA) # this step uses the mapped-in variable
- stage: Three
dependsOn:
- One
- Two
jobs:
- job: C
variables:
# map the output variable from A into this job
varFromA: $[ stageDependencies.One.A.outputs['ProduceVar.MyVar'] ]
steps:
- script: echo $(varFromA) # this step uses the mapped-in variable
Można również przekazywać zmienne między etapami przy użyciu danych wejściowych pliku. W tym celu należy zdefiniować zmienne na drugim etapie na poziomie zadania, a następnie przekazać zmienne jako env: dane wejściowe.
## script-a.sh
echo "##vso[task.setvariable variable=sauce;isOutput=true]crushed tomatoes"
## script-b.sh
echo 'Hello file version'
echo $skipMe
echo $StageSauce
## azure-pipelines.yml
stages:
- stage: one
jobs:
- job: A
steps:
- task: Bash@3
inputs:
filePath: 'script-a.sh'
name: setvar
- bash: |
echo "##vso[task.setvariable variable=skipsubsequent;isOutput=true]true"
name: skipstep
- stage: two
jobs:
- job: B
variables:
- name: StageSauce
value: $[ stageDependencies.one.A.outputs['setvar.sauce'] ]
- name: skipMe
value: $[ stageDependencies.one.A.outputs['skipstep.skipsubsequent'] ]
steps:
- task: Bash@3
inputs:
filePath: 'script-b.sh'
name: fileversion
env:
StageSauce: $(StageSauce) # predefined in variables section
skipMe: $(skipMe) # predefined in variables section
- task: Bash@3
inputs:
targetType: 'inline'
script: |
echo 'Hello inline version'
echo $(skipMe)
echo $(StageSauce)
Dane wyjściowe z etapów w poprzednim potoku wyglądają następująco:
Hello inline version
true
crushed tomatoes
Wyświetlanie listy zmiennych
Wszystkie zmienne w potoku można wyświetlić za pomocą polecenia az pipelines variable list . Aby rozpocząć, zobacz Wprowadzenie do interfejsu wiersza polecenia usługi Azure DevOps.
az pipelines variable list [--org]
[--pipeline-id]
[--pipeline-name]
[--project]
Parametry
- org: Adres URL organizacji usługi Azure DevOps. Domyślną organizację można skonfigurować przy użyciu polecenia
az devops configure -d organization=ORG_URL. Wymagane, jeśli wartość domyślna nie jest skonfigurowana lub została wybrana przy użyciu poleceniagit config. Przykład:--org https://dev.azure.com/MyOrganizationName/. - pipeline-id: wymagane, jeśli nie podano nazwy potoku. Identyfikator potoku.
- nazwa potoku: wymagane, jeśli nie podano identyfikatora potoku, ale jest ignorowane, jeśli podano identyfikator potoku. Nazwa potoku.
- projekt: nazwa lub identyfikator projektu. Projekt domyślny można skonfigurować przy użyciu polecenia
az devops configure -d project=NAME_OR_ID. Wymagane, jeśli ustawienie nie zostało skonfigurowane jako domyślne lub odebrane przy użyciu poleceniagit config.
Przykład
Poniższe polecenie wyświetla listę wszystkich zmiennych w potoku o identyfikatorze 12 i pokazuje wynik w formacie tabeli.
az pipelines variable list --pipeline-id 12 --output table
Name Allow Override Is Secret Value
------------- ---------------- ----------- ------------
MyVariable False False platform
NextVariable False True platform
Configuration False False config.debug
Ustawianie zmiennych w skryptach
Skrypty mogą definiować zmienne, które są później używane w kolejnych krokach potoku. Wszystkie zmienne ustawione przez tę metodę są traktowane jako ciągi. Aby ustawić zmienną ze skryptu, należy użyć składni polecenia i wyświetlić wartość stdout.
Ustawianie zmiennej o zakresie zadania na podstawie skryptu
Aby ustawić zmienną ze skryptu, należy użyć polecenia rejestrowania.task.setvariable Spowoduje to zaktualizowanie zmiennych środowiskowych dla kolejnych zadań. Kolejne zadania mają dostęp do nowej zmiennej ze składnią makr i w zadaniach jako zmiennych środowiskowych.
Jeśli issecret wartość ma wartość true, wartość zmiennej zostanie zapisana jako wpis tajny i zamaskowana z dziennika. Aby uzyskać więcej informacji na temat zmiennych tajnych, zobacz polecenia rejestrowania.
steps:
# Create a variable
- bash: |
echo "##vso[task.setvariable variable=sauce]crushed tomatoes" # remember to use double quotes
# Use the variable
# "$(sauce)" is replaced by the contents of the `sauce` variable by Azure Pipelines
# before handing the body of the script to the shell.
- bash: |
echo my pipeline variable is $(sauce)
Kolejne kroki będą również miały zmienną potoku dodaną do środowiska. Nie można użyć zmiennej w kroku, który został zdefiniowany.
steps:
# Create a variable
# Note that this does not update the environment of the current script.
- bash: |
echo "##vso[task.setvariable variable=sauce]crushed tomatoes"
# An environment variable called `SAUCE` has been added to all downstream steps
- bash: |
echo "my environment variable is $SAUCE"
- pwsh: |
Write-Host "my environment variable is $env:SAUCE"
Dane wyjściowe z poprzedniego potoku.
my environment variable is crushed tomatoes
my environment variable is crushed tomatoes
Ustawianie zmiennej wyjściowej z wieloma zadaniami
Jeśli chcesz udostępnić zmienną w przyszłych zadaniach, musisz oznaczyć ją jako zmienną wyjściową przy użyciu polecenia isOutput=true. Następnie możesz zamapować go na przyszłe zadania przy użyciu $[] składni i włącznie z nazwą kroku, która ustawiła zmienną. Zmienne wyjściowe z wieloma zadaniami działają tylko dla zadań na tym samym etapie.
Aby przekazać zmienne do zadań na różnych etapach, użyj składni zależności etapu.
Uwaga
Domyślnie każdy etap w potoku zależy od tego, który jest tuż przed nim w pliku YAML. W związku z tym każdy etap może używać zmiennych wyjściowych z poprzedniego etapu. Aby uzyskać dostęp do dalszych etapów, należy zmienić graf zależności, na przykład jeśli etap 3 wymaga zmiennej z etapu 1, należy zadeklarować jawną zależność od etapu 1.
Podczas tworzenia zmiennej wyjściowej z wieloma zadaniami należy przypisać wyrażenie do zmiennej. W tym yaML $[ dependencies.A.outputs['setvarStep.myOutputVar'] ] jest przypisywany do zmiennej $(myVarFromJobA).
jobs:
# Set an output variable from job A
- job: A
pool:
vmImage: 'windows-latest'
steps:
- powershell: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the value"
name: setvarStep
- script: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable into job B
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromJobA: $[ dependencies.A.outputs['setvarStep.myOutputVar'] ] # map in the variable
# remember, expressions require single quotes
steps:
- script: echo $(myVarFromJobA)
name: echovar
Dane wyjściowe z poprzedniego potoku.
this is the value
this is the value
Jeśli ustawiasz zmienną z jednego etapu na inny, użyj polecenia stageDependencies.
stages:
- stage: A
jobs:
- job: A1
steps:
- bash: echo "##vso[task.setvariable variable=myStageOutputVar;isOutput=true]this is a stage output var"
name: printvar
- stage: B
dependsOn: A
variables:
myVarfromStageA: $[ stageDependencies.A.A1.outputs['printvar.myStageOutputVar'] ]
jobs:
- job: B1
steps:
- script: echo $(myVarfromStageA)
Jeśli ustawiasz zmienną z macierzy lub wycinka, a następnie odwołujesz się do zmiennej podczas uzyskiwania dostępu do niej z zadania podrzędnego, musisz uwzględnić następujące elementy:
- Nazwa zadania.
- Krok.
jobs:
# Set an output variable from a job with a matrix
- job: A
pool:
vmImage: 'ubuntu-latest'
strategy:
maxParallel: 2
matrix:
debugJob:
configuration: debug
platform: x64
releaseJob:
configuration: release
platform: x64
steps:
- bash: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the $(configuration) value"
name: setvarStep
- bash: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable from the debug job
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromJobADebug: $[ dependencies.A.outputs['debugJob.setvarStep.myOutputVar'] ]
steps:
- script: echo $(myVarFromJobADebug)
name: echovar
jobs:
# Set an output variable from a job with slicing
- job: A
pool:
vmImage: 'ubuntu-latest'
parallel: 2 # Two slices
steps:
- bash: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the slice $(system.jobPositionInPhase) value"
name: setvarStep
- script: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable from the job for the first slice
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromJobsA1: $[ dependencies.A.outputs['job1.setvarStep.myOutputVar'] ]
steps:
- script: "echo $(myVarFromJobsA1)"
name: echovar
Pamiętaj, aby prefiks nazwy zadania był poprzedzony zmiennymi wyjściowymi zadania wdrożenia . W takim przypadku nazwa zadania to A:
jobs:
# Set an output variable from a deployment
- deployment: A
pool:
vmImage: 'ubuntu-latest'
environment: staging
strategy:
runOnce:
deploy:
steps:
- bash: echo "##vso[task.setvariable variable=myOutputVar;isOutput=true]this is the deployment variable value"
name: setvarStep
- bash: echo $(setvarStep.myOutputVar)
name: echovar
# Map the variable from the job for the first slice
- job: B
dependsOn: A
pool:
vmImage: 'ubuntu-latest'
variables:
myVarFromDeploymentJob: $[ dependencies.A.outputs['A.setvarStep.myOutputVar'] ]
steps:
- bash: "echo $(myVarFromDeploymentJob)"
name: echovar



Ustawianie zmiennych przy użyciu wyrażeń
Zmienną można ustawić przy użyciu wyrażenia. Napotkaliśmy już jeden przypadek, aby ustawić zmienną na dane wyjściowe innego z poprzedniego zadania.
- job: B
dependsOn: A
variables:
myVarFromJobsA1: $[ dependencies.A.outputs['job1.setvarStep.myOutputVar'] ] # remember to use single quotes
Do ustawiania zmiennej można użyć dowolnego z obsługiwanych wyrażeń. Oto przykład ustawiania zmiennej do działania jako licznika rozpoczynającego się od 100, zwiększa się o 1 dla każdego przebiegu i jest resetowany do 100 każdego dnia.
jobs:
- job:
variables:
a: $[counter(format('{0:yyyyMMdd}', pipeline.startTime), 100)]
steps:
- bash: echo $(a)
Aby uzyskać więcej informacji na temat liczników, zależności i innych wyrażeń, zobacz wyrażenia.
Konfigurowanie zmiennych settable dla kroków
Można zdefiniować settableVariables w ramach kroku lub określić, że nie można ustawić żadnych zmiennych.
W tym przykładzie skrypt nie może ustawić zmiennej.
steps:
- script: echo This is a step
target:
settableVariables: none
W tym przykładzie skrypt zezwala na zmienną sauce , ale nie zmienną secretSauce. Na stronie uruchamiania potoku zostanie wyświetlone ostrzeżenie.

steps:
- bash: |
echo "##vso[task.setvariable variable=Sauce;]crushed tomatoes"
echo "##vso[task.setvariable variable=secretSauce;]crushed tomatoes with garlic"
target:
settableVariables:
- sauce
name: SetVars
- bash:
echo "Sauce is $(sauce)"
echo "secretSauce is $(secretSauce)"
name: OutputVars
Zezwalanie w czasie kolejki
Jeśli zmienna pojawi się w variables bloku pliku YAML, jego wartość jest stała i nie można jej zastąpić w czasie kolejki. Najlepszym rozwiązaniem jest zdefiniowanie zmiennych w pliku YAML, ale czasami nie ma sensu. Możesz na przykład zdefiniować zmienną wpisu tajnego i nie udostępnić zmiennej w pliku YAML. Może też być konieczne ręczne ustawienie wartości zmiennej podczas uruchamiania potoku.
Istnieją dwie opcje definiowania wartości czasu kolejki. Możesz zdefiniować zmienną w interfejsie użytkownika i wybrać opcję Zezwalaj użytkownikom na zastąpienie tej wartości podczas uruchamiania tego potoku lub zamiast tego można użyć parametrów środowiska uruchomieniowego. Jeśli zmienna nie jest wpisem tajnym, najlepszym rozwiązaniem jest użycie parametrów środowiska uruchomieniowego.
Aby ustawić zmienną w czasie kolejki, dodaj nową zmienną w potoku i wybierz opcję zastąpienia.
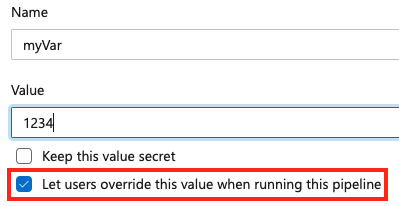
Aby zezwolić na ustawianie zmiennej w czasie kolejki, upewnij się, że zmienna nie jest również wyświetlana w variables bloku potoku lub zadania. Jeśli zdefiniujesz zmienną zarówno w bloku zmiennych YAML, jak i w interfejsie użytkownika, wartość w yaML ma priorytet.

Rozszerzanie zmiennych
Po ustawieniu zmiennej o tej samej nazwie w wielu zakresach ma zastosowanie poniższe hierarchia pierwszeństwa (w kolejności od najwyższego pierwszeństwa).
- Zmienna na poziomie zadania ustawiona w pliku YAML
- Zmienna na poziomie etapu ustawiona w pliku YAML
- Zmienna na poziomie potoku ustawiona w pliku YAML
- Zmienna ustawiona w czasie kolejki
- Zmienna potoku ustawiona w interfejsie użytkownika ustawień potoku
W poniższym przykładzie ta sama zmienna a jest ustawiana na poziomie potoku i na poziomie zadania w pliku YAML. Jest ona również ustawiana w grupie Gzmiennych i jako zmienna w interfejsie użytkownika ustawień potoku.
variables:
a: 'pipeline yaml'
stages:
- stage: one
displayName: one
variables:
- name: a
value: 'stage yaml'
jobs:
- job: A
variables:
- name: a
value: 'job yaml'
steps:
- bash: echo $(a) # This will be 'job yaml'
Po ustawieniu zmiennej o tej samej nazwie w tym samym zakresie pierwszeństwo ma ostatnia ustawiona wartość.
stages:
- stage: one
displayName: Stage One
variables:
- name: a
value: alpha
- name: a
value: beta
jobs:
- job: I
displayName: Job I
variables:
- name: b
value: uno
- name: b
value: dos
steps:
- script: echo $(a) #outputs beta
- script: echo $(b) #outputs dos
Uwaga
Po ustawieniu zmiennej w pliku YAML nie należy go definiować w edytorze internetowym jako możliwego do ustawienia w czasie kolejki. Obecnie nie można zmieniać zmiennych ustawionych w pliku YAML w czasie kolejki. Jeśli chcesz ustawić zmienną w czasie kolejki, nie ustawiaj jej w pliku YAML.
Zmienne są rozszerzane raz po uruchomieniu przebiegu i ponownie na początku każdego kroku. Na przykład:
jobs:
- job: A
variables:
a: 10
steps:
- bash: |
echo $(a) # This will be 10
echo '##vso[task.setvariable variable=a]20'
echo $(a) # This will also be 10, since the expansion of $(a) happens before the step
- bash: echo $(a) # This will be 20, since the variables are expanded just before the step
W poprzednim przykładzie przedstawiono dwa kroki. Rozszerzenie $(a) ma miejsce raz na początku zadania, a raz na początku każdego z tych dwóch kroków.
Ponieważ zmienne są rozszerzane na początku zadania, nie można ich używać w strategii. W poniższym przykładzie nie można użyć zmiennej a do rozwinięcia macierzy zadań, ponieważ zmienna jest dostępna tylko na początku każdego rozwiniętego zadania.
jobs:
- job: A
variables:
a: 10
strategy:
matrix:
x:
some_variable: $(a) # This does not work
Jeśli zmienna a jest zmienną wyjściową z poprzedniego zadania, możesz użyć jej w przyszłym zadaniu.
- job: A
steps:
- powershell: echo "##vso[task.setvariable variable=a;isOutput=true]10"
name: a_step
# Map the variable into job B
- job: B
dependsOn: A
variables:
some_variable: $[ dependencies.A.outputs['a_step.a'] ]
Rozszerzanie cyklicznego
W agencie zmienne, do których odwołuje się $( ) składnia, są rekursywnie rozwinięte.
Na przykład:
variables:
myInner: someValue
myOuter: $(myInner)
steps:
- script: echo $(myOuter) # prints "someValue"
displayName: Variable is $(myOuter) # display name is "Variable is someValue"