Uzyskiwanie zaleceń platformy Azure dotyczących migrowania bazy danych programu SQL Server
Rozszerzenie Azure SQL Migration dla usługi Azure Data Studio pomaga ocenić wymagania bazy danych, uzyskać zalecenia dotyczące jednostki SKU o odpowiednim rozmiarze dla zasobów platformy Azure i przeprowadzić migrację bazy danych programu SQL Server na platformę Azure.
Dowiedz się, jak używać tego ujednoliconego środowiska, zbierając dane wydajności ze źródłowego wystąpienia programu SQL Server, aby uzyskać odpowiednie zalecenia dotyczące platformy Azure dla celów usługi Azure SQL.
Omówienie
Przed migracją do usługi Azure SQL możesz użyć rozszerzenia SQL Migration w narzędziu Azure Data Studio, aby ułatwić generowanie zaleceń o odpowiednim rozmiarze dla usług Azure SQL Database, Azure SQL Managed Instance i SQL Server na docelowych maszynach wirtualnych platformy Azure. Narzędzie pomaga zbierać dane wydajności ze źródłowego wystąpienia SQL (uruchomionego lokalnie lub w innej chmurze) i zaleca konfigurację obliczeniową i magazynową, aby spełnić potrzeby obciążenia.
Diagram przedstawia przepływ pracy zaleceń platformy Azure w rozszerzeniu Azure SQL Migration dla usługi Azure Data Studio:

Uwaga
Funkcja oceny i rekomendacji platformy Azure w rozszerzeniu Azure SQL Migration dla usługi Azure Data Studio obsługuje źródłowe wystąpienia programu SQL Server działające w systemie Windows lub Linux.
Wymagania wstępne
Aby rozpocząć pracę z zaleceniami platformy Azure dotyczącymi migracji bazy danych programu SQL Server, musisz spełnić następujące wymagania wstępne:
Zainstaluj rozszerzenie Azure SQL Migration z witryny Azure Data Studio Marketplace.
Upewnij się, że identyfikator logowania używany do łączenia źródłowego wystąpienia programu SQL Server ma minimalne uprawnienia.
Obsługiwane źródła i obiekty docelowe
Zalecenia dotyczące platformy Azure można wygenerować dla następujących wersji programu SQL Server:
- Obsługiwane są wersje programu SQL Server 2008 i nowszych w systemie Windows lub Linux.
- Program SQL Server działający w innych chmurach może być obsługiwany, ale dokładność wyników może się różnić
Zalecenia dotyczące platformy Azure można wygenerować dla następujących celów usługi Azure SQL:
- Azure SQL Database
- Rodziny sprzętu: seria Standardowa (Gen5)
- Warstwy usług: Ogólnego przeznaczenia, Krytyczne dla działania firmy, Hiperskala
- Azure SQL Managed Instance
- Rodziny sprzętowe: seria Standardowa (Gen5), seria Premium, zoptymalizowane pod kątem pamięci serii Premium
- Warstwy usług: ogólnego przeznaczenia, Krytyczne dla działania firmy
- Program SQL Server na maszynie wirtualnej platformy Azure
- Rodziny maszyn wirtualnych: ogólnego przeznaczenia, zoptymalizowane pod kątem pamięci
- Rodziny magazynów: SSD w warstwie Premium
Zbieranie danych wydajności
Przed wygenerowaniem zaleceń należy zebrać dane dotyczące wydajności ze źródłowego wystąpienia programu SQL Server. Podczas tego kroku zbierania danych wiele dynamicznych widoków systemowych (DMV) z wystąpienia programu SQL Server jest odpytywane w celu przechwycenia właściwości wydajności obciążenia. Narzędzie przechwytuje metryki, w tym użycie procesora CPU, pamięci, magazynu i operacji we/wy co 30 sekund, i zapisuje liczniki wydajności lokalnie na maszynie jako zestaw plików CSV.
Poziom wystąpienia
Te dane wydajności są zbierane raz na wystąpienie programu SQL Server:
| Wymiar wydajności | opis | Dynamiczny widok zarządzania (DMV) |
|---|---|---|
SqlInstanceCpuPercent |
Ilość procesora CPU używanego przez proces programu SQL Server jako wartość procentowa | sys.dm_os_ring_buffers |
PhysicalMemoryInUse |
Całkowity ślad pamięci procesu programu SQL Server | sys.dm_os_process_memory |
MemoryUtilizationPercentage |
Wykorzystanie pamięci programu SQL Server | sys.dm_os_process_memory |
Poziom bazy danych
| Wymiar wydajności | opis | Dynamiczny widok zarządzania (DMV) |
|---|---|---|
DatabaseCpuPercent |
Całkowity procent użycia procesora PRZEZ bazę danych | sys.dm_exec_query_stats |
CachedSizeInMb |
Całkowity rozmiar w megabajtach pamięci podręcznej używanej przez bazę danych | sys.dm_os_buffer_descriptors |
Poziom pliku
| Wymiar wydajności | opis | Dynamiczny widok zarządzania (DMV) |
|---|---|---|
ReadIOInMb |
Całkowita liczba megabajtów odczytanych z tego pliku | sys.dm_io_virtual_file_stats |
WriteIOInMb |
Całkowita liczba megabajtów zapisanych w tym pliku | sys.dm_io_virtual_file_stats |
NumOfReads |
Całkowita liczba odczytów wystawionych w tym pliku | sys.dm_io_virtual_file_stats |
NumOfWrites |
Całkowita liczba zapisów wystawionych w tym pliku | sys.dm_io_virtual_file_stats |
ReadLatency |
Opóźnienie odczytu we/wy dla tego pliku | sys.dm_io_virtual_file_stats |
WriteLatency |
Opóźnienie zapisu we/wy w tym pliku | sys.dm_io_virtual_file_stats |
Przed wygenerowaniem zalecenia wymagane jest co najmniej 10 minut zbierania danych, ale aby dokładnie ocenić obciążenie, zaleca się uruchomienie zbierania danych przez wystarczająco długi czas trwania, aby przechwycić zarówno użycie szczytowe, jak i poza szczytowe.
Aby zainicjować proces zbierania danych, rozpocznij od nawiązania połączenia ze źródłowym wystąpieniem SQL w narzędziu Azure Data Studio, a następnie uruchom kreatora migracji SQL. W kroku 2 wybierz pozycję "Pobierz zalecenie dotyczące platformy Azure". Wybierz pozycję "Zbieraj dane wydajności teraz" i wybierz folder na komputerze, w którym zostaną zapisane zebrane dane.
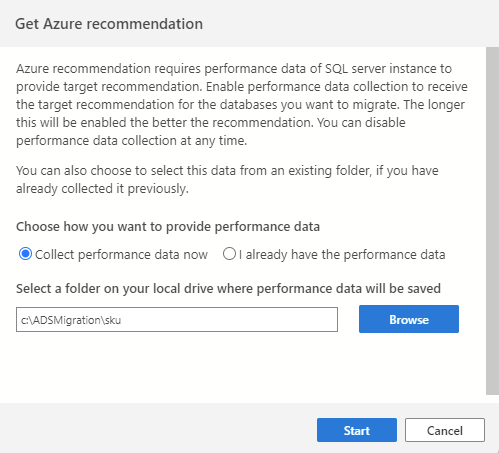
Proces zbierania danych jest uruchamiany przez 10 minut, aby wygenerować pierwsze zalecenie. Ważne jest, aby rozpocząć proces zbierania danych, gdy aktywne obciążenie bazy danych odzwierciedla użycie podobne do scenariuszy produkcyjnych.
Po wygenerowaniu pierwszego zalecenia można kontynuować proces zbierania danych w celu uściślenia zaleceń. Ta opcja jest szczególnie przydatna, jeśli wzorce użycia różnią się w czasie.
Proces zbierania danych rozpoczyna się po wybraniu pozycji Rozpocznij. Co 10 minut zebrane punkty danych są agregowane, a maksymalna, średnia i wariancja każdego licznika zostaną zapisane na dysku w zestawie trzech plików CSV.
Zazwyczaj w wybranym folderze jest wyświetlany zestaw plików CSV z następującymi sufiksami:
SQLServerInstance_CommonDbLevel_Counters.csv: zawiera statyczne dane konfiguracji dotyczące układu i metadanych pliku bazy danych.SQLServerInstance_CommonInstanceLevel_Counters.csv: zawiera dane statyczne dotyczące konfiguracji sprzętowej wystąpienia serwera.SQLServerInstance_PerformanceAggregated_Counters.csv: zawiera zagregowane dane wydajności, które są często aktualizowane.
W tym czasie pozostaw otwarte narzędzie Azure Data Studio, ale możesz kontynuować wykonywanie innych operacji. W dowolnym momencie możesz zatrzymać proces zbierania danych, wracając do tej strony i wybierając pozycję Zatrzymaj zbieranie danych.
Generowanie zaleceń o odpowiednich rozmiarach
Jeśli już zebrano dane wydajności z poprzedniej sesji lub za pomocą innego narzędzia (takiego jak Baza danych Asystent migracji), możesz zaimportować wszystkie istniejące dane wydajności, wybierając opcję Mam już dane wydajności. Przejdź do folderu, w którym są zapisywane dane dotyczące wydajności (trzy pliki .csv), a następnie wybierz pozycję Rozpocznij , aby zainicjować proces rekomendacji.
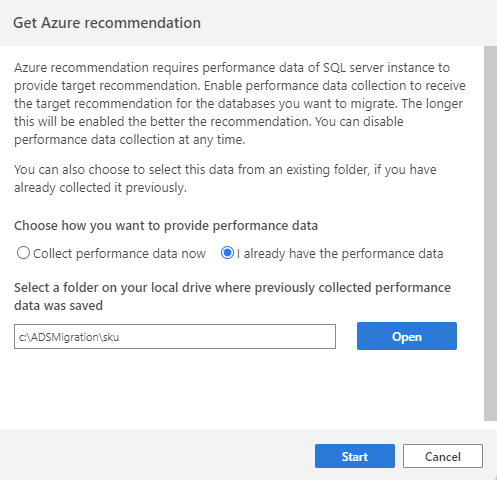
Krok jeden z kreatora migracji SQL prosi o wybranie zestawu baz danych do oceny, a są to jedyne bazy danych, które zostaną uwzględnione podczas procesu rekomendacji.
Jednak proces zbierania danych wydajności zbiera liczniki wydajności dla wszystkich baz danych ze źródłowego wystąpienia programu SQL Server, a nie tylko tych, które zostały wybrane.
Oznacza to, że wcześniej zebrane dane wydajności mogą służyć do wielokrotnego ponownego generowania rekomendacji dla innego podzestawu baz danych, określając inną listę w kroku 1.
Parametry rekomendacji
Istnieje wiele konfigurowalnych ustawień, które mogą mieć wpływ na zalecenia.

Wybierz opcję Edytuj parametry, aby dostosować te parametry zgodnie z potrzebami.
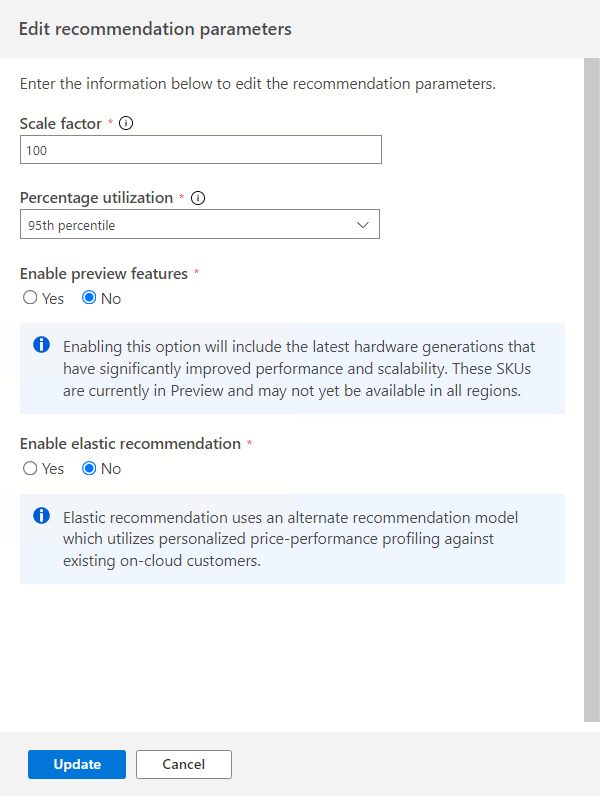
Współczynnik skalowania:
Ta opcja umożliwia podanie buforu, który ma być stosowany do każdego wymiaru wydajności. Ta opcja dotyczy problemów, takich jak użycie sezonowe, krótka historia wydajności i prawdopodobne wzrosty użycia w przyszłości. Jeśli na przykład ustalisz, że wymaganie dotyczące procesora CPU z czterema rdzeniami wirtualnymi ma współczynnik skalowania 150%, rzeczywiste wymaganie dotyczące procesora CPU wynosi sześć rdzeni wirtualnych.
Domyślny wolumin współczynnika skalowania wynosi 100%.
Procentowe wykorzystanie:
Percentyl punktów danych, które mają być używane jako dane wydajności, są agregowane.
Wartość domyślna to 95. percentyl.
Włącz funkcje w wersji zapoznawczej:
Ta opcja umożliwia zalecane konfiguracje, które mogą nie być jeszcze ogólnie dostępne dla wszystkich użytkowników we wszystkich regionach.
Ta opcja jest domyślnie wyłączona.
Włącz zalecenie elastyczne:
Ta opcja korzysta z alternatywnego modelu rekomendacji, który korzysta z spersonalizowanego profilowania wydajności cen dla istniejących klientów w chmurze.
Ta opcja jest domyślnie wyłączona.
Proces zbierania danych kończy się po zamknięciu programu Azure Data Studio. Dane, które zostały zebrane do tego punktu, są zapisywane w folderze.
Jeśli zamkniesz program Azure Data Studio, gdy zbieranie danych jest w toku, użyj jednej z następujących opcji, aby ponownie uruchomić zbieranie danych:
Otwórz ponownie program Azure Data Studio i zaimportuj pliki danych zapisane w folderze lokalnym. Następnie wygeneruj zalecenie na podstawie zebranych danych.
Otwórz ponownie program Azure Data Studio i ponownie uruchom zbieranie danych przy użyciu kreatora migracji.
Minimalne uprawnienia
Aby wykonać zapytanie dotyczące niezbędnych widoków systemu do zbierania danych wydajności, do logowania programu SQL Server używanego w tym zadaniu są wymagane określone uprawnienia. Aby zebrać dane oceny i wydajności, można utworzyć minimalnego uprzywilejowanego użytkownika przy użyciu następującego skryptu:
-- Create a login to run the assessment
USE master;
GO
CREATE LOGIN [assessment]
WITH PASSWORD = '<STRONG PASSWORD>';
-- Create user in every database other than TempDB and model and provide minimal read-only permissions
EXECUTE sp_MSforeachdb '
USE [?];
IF (''?'' NOT IN (''TempDB'',''model''))
BEGIN TRY
CREATE USER [assessment] FOR LOGIN [assessment]
END TRY
BEGIN CATCH
PRINT ERROR_MESSAGE()
END CATCH';
EXECUTE sp_MSforeachdb '
USE [?];
IF (''?'' NOT IN (''tempdb'',''model''))
BEGIN TRY
GRANT SELECT ON sys.sql_expression_dependencies TO [assessment]
END TRY
BEGIN CATCH
PRINT ERROR_MESSAGE()
END CATCH';
EXECUTE sp_MSforeachdb '
USE [?];
IF (''?'' NOT IN (''tempdb'',''model''))
BEGIN TRY
GRANT VIEW DATABASE STATE TO [assessment]
END TRY
BEGIN CATCH
PRINT ERROR_MESSAGE()
END CATCH';
-- Provide server level read-only permissions
GRANT SELECT ON sys.sql_expression_dependencies TO [assessment];
GRANT SELECT ON sys.sql_expression_dependencies TO [assessment];
GRANT EXECUTE ON OBJECT::sys.xp_regenumkeys TO [assessment];
GRANT VIEW DATABASE STATE TO assessment;
GRANT VIEW SERVER STATE TO assessment;
GRANT VIEW ANY DEFINITION TO assessment;
-- Provide msdb specific permissions
USE msdb;
GO
GRANT EXECUTE ON [msdb].[dbo].[agent_datetime] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysjobsteps] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[syssubsystems] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysjobhistory] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[syscategories] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysjobs] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmaintplan_plans] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[syscollector_collection_sets] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmail_profile] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmail_profileaccount] TO [assessment];
GRANT SELECT ON [msdb].[dbo].[sysmail_account] TO [assessment];
-- USE master;
-- GO
-- EXECUTE sp_MSforeachdb 'USE [?]; BEGIN TRY DROP USER [assessment] END TRY BEGIN CATCH SELECT ERROR_MESSAGE() END CATCH';
-- DROP LOGIN [assessment];
Nieobsługiwane scenariusze i ograniczenia
Rekomendacje platformy Azure nie obejmują oszacowań cen, ponieważ ta sytuacja może się różnić w zależności od regionu, waluty i rabatów, takich jak Korzyść użycia hybrydowego platformy Azure. Aby uzyskać oszacowania cen, użyj kalkulatora cen platformy Azure lub utwórz ocenę SQL w usłudze Azure Migrate.
Rekomendacje dotyczące usługi Azure SQL Database z modelem zakupów opartym na jednostkach DTU nie są obsługiwane.
Obecnie rekomendacje platformy Azure dotyczące bezserwerowej warstwy obliczeniowej usługi Azure SQL Database i elastycznych pul nie są obsługiwane.
Rozwiązywanie problemów
- Nie wygenerowano żadnych zaleceń
- Jeśli nie wygenerowano żadnych zaleceń, taka sytuacja może oznaczać, że nie zidentyfikowano żadnych konfiguracji, które mogą w pełni spełniać wymagania dotyczące wydajności wystąpienia źródłowego. Aby zobaczyć przyczyny dyskwalifikacji określonego rozmiaru, warstwy usług lub rodziny sprzętu:
- Uzyskaj dostęp do dzienników z narzędzia Azure Data Studio, przechodząc do obszaru Pomoc > Pokaż wszystkie polecenia Otwórz folder dzienników rozszerzeń >
- Przejdź do pozycji Microsoft.mssql > SqlAssessmentLogs > open SkuRecommendationEvent.log
- Dziennik zawiera ślad każdej potencjalnej konfiguracji, która została oceniona i przyczyna, dla którego była/nie została uznana za kwalifikującą się konfigurację:
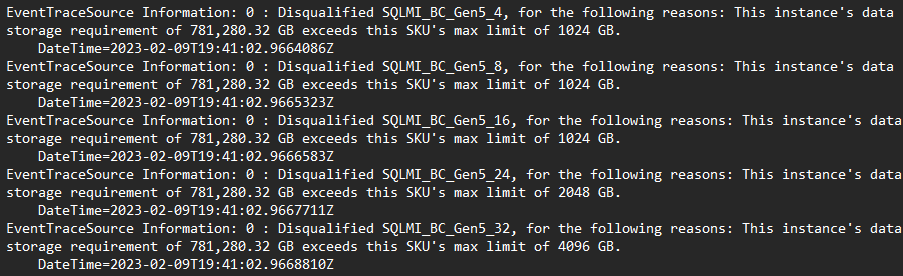
- Spróbuj ponownie wygenerować zalecenie z włączonym zaleceniem elastycznym . Ta opcja korzysta z alternatywnego modelu rekomendacji, który korzysta z spersonalizowanego profilowania wydajności cen dla istniejących klientów w chmurze.
- Jeśli nie wygenerowano żadnych zaleceń, taka sytuacja może oznaczać, że nie zidentyfikowano żadnych konfiguracji, które mogą w pełni spełniać wymagania dotyczące wydajności wystąpienia źródłowego. Aby zobaczyć przyczyny dyskwalifikacji określonego rozmiaru, warstwy usług lub rodziny sprzętu:
