Co to jest apache Flink® w usłudze Azure HDInsight w usłudze AKS? (wersja zapoznawcza)
Uwaga
Wycofamy usługę Azure HDInsight w usłudze AKS 31 stycznia 2025 r. Przed 31 stycznia 2025 r. należy przeprowadzić migrację obciążeń do usługi Microsoft Fabric lub równoważnego produktu platformy Azure, aby uniknąć nagłego zakończenia obciążeń. Pozostałe klastry w ramach subskrypcji zostaną zatrzymane i usunięte z hosta.
Tylko podstawowa pomoc techniczna będzie dostępna do daty wycofania.
Ważne
Ta funkcja jest aktualnie dostępna jako funkcja podglądu. Dodatkowe warunki użytkowania dla wersji zapoznawczych platformy Microsoft Azure obejmują więcej warunków prawnych, które dotyczą funkcji platformy Azure, które znajdują się w wersji beta, w wersji zapoznawczej lub w inny sposób nie zostały jeszcze wydane w wersji ogólnodostępnej. Aby uzyskać informacje o tej konkretnej wersji zapoznawczej, zobacz Informacje o wersji zapoznawczej usługi Azure HDInsight w usłudze AKS. W przypadku pytań lub sugestii dotyczących funkcji prześlij żądanie w usłudze AskHDInsight , aby uzyskać szczegółowe informacje i postępuj zgodnie z nami, aby uzyskać więcej aktualizacji w społeczności usługi Azure HDInsight.
Apache Flink to platforma i aparat przetwarzania rozproszonego na potrzeby obliczeń stanowych za pośrednictwem niezwiązanych i ograniczonych strumieni danych. Funkcja Flink została zaprojektowana do uruchamiania we wszystkich typowych środowiskach klastra, wykonywania obliczeń i stanowych aplikacji przesyłania strumieniowego z szybkością w pamięci i w dowolnej skali. Aplikacje są równoległe do prawdopodobnie tysięcy zadań, które są dystrybuowane i wykonywane współbieżnie w klastrze. W związku z tym aplikacja może używać nieograniczonej liczby procesorów wirtualnych, pamięci głównej, dysku i operacji we/wy sieci. Ponadto funkcja Flink łatwo utrzymuje duży stan aplikacji. Algorytm asynchronicznego i przyrostowego tworzenia punktów kontrolnych zapewnia minimalny wpływ na opóźnienia przetwarzania przy jednoczesnym zagwarantowaniu dokładnie jednej spójności stanu.
Apache Flink to wysoce skalowalny aparat analityczny do przetwarzania strumieniowego.
Oto niektóre z najważniejszych funkcji oferowanych przez funkcję Flink:
- Operacje na strumieniach ograniczonych i niezwiązanych
- Wydajność pamięci
- Możliwość przesyłania strumieniowego i obliczeń wsadowych
- Małe opóźnienia, operacje o wysokiej przepływności
- Dokładnie jednokrotne przetwarzanie
- Wysoka dostępność
- Stan i odporność na uszkodzenia
- W pełni zgodne z ekosystemem usługi Hadoop
- Ujednolicone interfejsy API SQL dla strumienia i partii
Dlaczego apache Flink?
Apache Flink to doskonały wybór do tworzenia i uruchamiania wielu różnych typów aplikacji ze względu na rozbudowany zestaw funkcji. Funkcje Flink obejmują obsługę przetwarzania strumieniowego i wsadowego, zaawansowane zarządzanie stanem, semantyka przetwarzania czasu zdarzeń i dokładnie raz gwarancje spójności dla stanu. Flink nie ma jednego punktu awarii. Flink został sprawdzony do skalowania do tysięcy rdzeni i terabajtów stanu aplikacji, zapewnia wysoką przepływność i małe opóźnienia oraz obsługuje niektóre z najbardziej wymagających aplikacji przetwarzania strumieni na świecie.
- Wykrywanie oszustw: Flink może służyć do wykrywania fałszywych transakcji lub działań w czasie rzeczywistym przez zastosowanie złożonych reguł i modeli uczenia maszynowego na danych przesyłanych strumieniowo.
- Wykrywanie anomalii: funkcja Flink może służyć do identyfikowania wartości odstających lub nietypowych wzorców w danych przesyłanych strumieniowo, takich jak odczyty czujników, ruch sieciowy lub zachowanie użytkownika.
- Alerty oparte na regułach: Link może służyć do wyzwalania alertów lub powiadomień na podstawie wstępnie zdefiniowanych warunków lub progów danych przesyłanych strumieniowo, takich jak temperatura, ciśnienie lub ceny akcji.
- Monitorowanie procesów biznesowych: link Flink może służyć do śledzenia i analizowania stanu i wydajności procesów biznesowych lub przepływów pracy w czasie rzeczywistym, takich jak realizacja zamówienia, dostawa lub obsługa klienta.
- Aplikacja internetowa (sieć społecznościowa): link Flink może służyć do obsługi aplikacji internetowych, które wymagają przetwarzania danych generowanych przez użytkownika w czasie rzeczywistym, takich jak wiadomości, polubienia, komentarze lub rekomendacje.
Przeczytaj więcej na temat typowych przypadków użycia opisanych w temacie Przypadki użycia narzędzia Apache Flink
Klastry Apache Flink w usłudze HDInsight w usłudze AKS to w pełni zarządzana usługa. Zalety tworzenia klastra Flink w usłudze HDInsight w usłudze AKS są wymienione tutaj.
| Funkcja | opis |
|---|---|
| Łatwość tworzenia | Nowy klaster Flink można utworzyć w usłudze HDInsight w ciągu kilku minut przy użyciu witryny Azure Portal, programu Azure PowerShell lub zestawu SDK. Zobacz Wprowadzenie do klastra Apache Flink w usłudze HDInsight w usłudze AKS. |
| Łatwość użycia | Klastry Flink w usłudze HDInsight w usłudze AKS obejmują zarządzanie konfiguracją opartą na portalu i skalowanie. Oprócz tego w przypadku interfejsu API zarządzania zadaniami używasz interfejsu API REST lub witryny Azure Portal do zarządzania zadaniami. |
| Interfejsy API REST | Klastry Flink w usłudze HDInsight w usłudze AKS obejmują interfejs API zarządzania zadaniami, metodę przesyłania zadań Flink opartą na interfejsie API REST w celu zdalnego przesyłania i monitorowania zadań w witrynie Azure Portal. |
| Typ wdrożenia programu | Flink może wykonywać aplikacje w trybie sesji lub w trybie aplikacji. Obecnie usługa HDInsight w usłudze AKS obsługuje tylko klastry sesji. W klastrze sesji można uruchomić wiele zadań Flink. Tryb aplikacji znajduje się w harmonogramie działania usługi HDInsight w klastrach usługi AKS |
| Obsługa magazynu metadanych | Klastry Flink w usłudze HDInsight w usłudze AKS mogą obsługiwać katalogi z magazynem metadanych Hive w różnych formatach otwartych plików ze zdalnymi punktami kontrolnymi w usłudze Azure Data Lake Storage Gen2. |
| Obsługa usługi Azure Storage | Klastry Flink w usłudze HDInsight mogą używać usługi Azure Data Lake Storage Gen2 jako ujścia plików. Aby uzyskać więcej informacji na temat usługi Data Lake Storage Gen2, zobacz Azure Data Lake Storage Gen2. |
| Integracja z usługami Azure | Klaster Flink w usłudze HDInsight w usłudze AKS jest dostarczany z integracją z platformą Kafka wraz z usługami Azure Event Hubs i Azure HDInsight. Aplikacje przesyłania strumieniowego można tworzyć przy użyciu usługi Event Hubs lub USŁUGI HDInsight. |
| Adaptacji | Usługa HDInsight w usłudze AKS umożliwia skalowanie węzłów klastra Flink na podstawie harmonogramu za pomocą funkcji autoskalowania. Zobacz Automatyczne skalowanie usługi Azure HDInsight w klastrach usługi AKS. |
| Zaplecze stanu | Usługa HDInsight w usłudze AKS używa bazy danych RocksDB jako domyślnego elementu StateBackend. RocksDB to osadzony trwały magazyn par klucz-wartość na potrzeby szybkiego przechowywania. |
| Punkty kontrolne | Tworzenie punktów kontrolnych jest domyślnie włączone w usłudze HDInsight w klastrach usługi AKS. Ustawienia domyślne w usłudze HDInsight w usłudze AKS utrzymują pięć ostatnich punktów kontrolnych w magazynie trwałym. W przypadku niepowodzenia zadania zadanie można uruchomić ponownie z najnowszego punktu kontrolnego. |
| Przyrostowe punkty kontrolne | Baza danych RocksDB obsługuje przyrostowe punkty kontrolne. Zachęcamy do korzystania z przyrostowych punktów kontrolnych dla dużego stanu. Należy włączyć tę funkcję ręcznie. Ustawienie wartości domyślnej w flink-conf.yaml: state.backend.incremental: true punktach kontrolnych przyrostowych, chyba że aplikacja zastąpi to ustawienie w kodzie. Ta instrukcja jest domyślnie prawdziwa. Alternatywnie tę wartość można skonfigurować bezpośrednio w kodzie (zastępuje domyślną konfigurację). EmbeddedRocksDBStateBackend` backend = new `EmbeddedRocksDBStateBackend(true); Domyślnie zachowujemy pięć ostatnich punktów kontrolnych w skonfigurowanym dir punktów kontrolnych. Tę wartość można zmienić, zmieniając konfigurację w sekcji zarządzania konfiguracją state.checkpoints.num-retained: 5 |
Klastry Apache Flink w usłudze HDInsight w usłudze AKS obejmują następujące składniki. Są one domyślnie dostępne w klastrach.
Zapoznaj się z planem działania, aby dowiedzieć się, co będzie wkrótce!
Zarządzanie zadaniami apache Flink
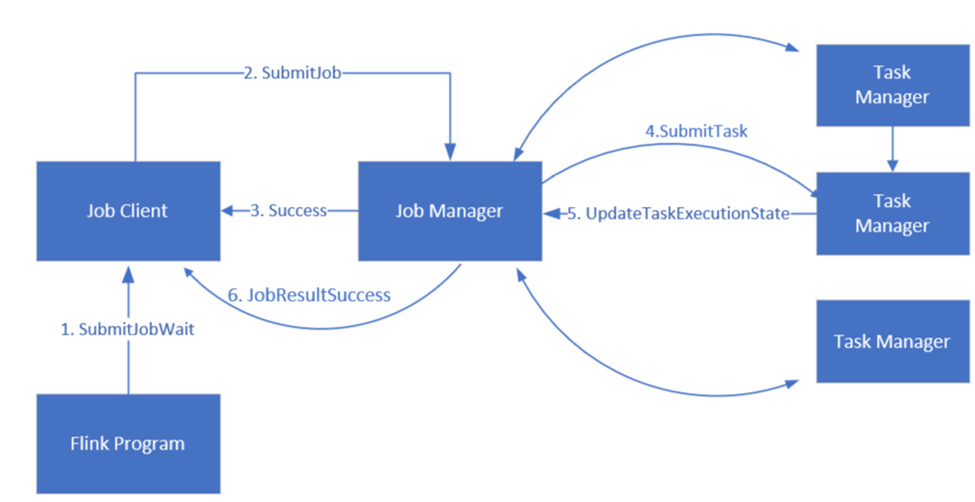
Flink planuje zadania przy użyciu trzech składników rozproszonych, Menedżera zadań, Menedżera zadań i Klienta zadań, które są ustawiane we wzorcu programu Leader-Follower.
Zadanie flink: zadanie lub program flink składa się z wielu zadań. Zadania są podstawową jednostką wykonywania w języku Flink. Każde zadanie Flink ma wiele wystąpień w zależności od poziomu równoległości, a każde wystąpienie jest wykonywane na menedżerze zadań.
Menedżer zadań: Menedżer zadań działa jako harmonogram i planuje zadania menedżerów zadań.
Menedżer zadań: Menedżerowie zadań mają co najmniej jedno gniazdo do równoległego wykonywania zadań.
Klient zadania: klient zadań komunikuje się z menedżerem zadań w celu przesłania zadań Flink
Flink Web UI: Flink oferuje internetowy interfejs użytkownika do inspekcji, monitorowania i debugowania uruchomionych aplikacji.
Odwołanie
- Witryna internetowa platformy Apache Flink
- Apache, Apache Kafka, Kafka, Apache Flink, Flink i skojarzone nazwy projektów typu open source są znakami towarowymi platformy Apache Software Foundation (ASF).