Co to jest platforma Apache Spark™ w usłudze HDInsight w usłudze AKS? (wersja zapoznawcza)
Ważne
Ta funkcja jest aktualnie dostępna jako funkcja podglądu. Dodatkowe warunki użytkowania dla wersji zapoznawczych platformy Microsoft Azure obejmują więcej warunków prawnych, które dotyczą funkcji platformy Azure, które znajdują się w wersji beta, w wersji zapoznawczej lub w inny sposób nie zostały jeszcze wydane w wersji ogólnodostępnej. Aby uzyskać informacje o tej konkretnej wersji zapoznawczej, zobacz Informacje o wersji zapoznawczej usługi Azure HDInsight w usłudze AKS. W przypadku pytań lub sugestii dotyczących funkcji prześlij żądanie w usłudze AskHDInsight , aby uzyskać szczegółowe informacje i postępuj zgodnie z nami, aby uzyskać więcej aktualizacji w społeczności usługi Azure HDInsight.
Apache Spark™ to platforma przetwarzania równoległego, która obsługuje przetwarzanie w pamięci w celu zwiększenia wydajności aplikacji analitycznych big data.
Platforma Apache Spark™ udostępnia elementy pierwotne na potrzeby przetwarzania w klastrze w pamięci. Zadanie Spark może ładować i buforować dane w pamięci, a następnie wielokrotnie wykonywać zapytania względem tych danych. Przetwarzanie w pamięci jest szybsze niż aplikacje oparte na dyskach, takie jak Hadoop, które udostępniają dane za pośrednictwem rozproszonego systemu plików Hadoop (HDFS). Platforma Apache Spark umożliwia integrację z językami programowania Scala i Python, aby umożliwić manipulowanie rozproszonymi zestawami danych, takimi jak kolekcje lokalne. Nie ma potrzeby, aby wszystkie elementy były obejmowane strukturami operacji mapowania i redukcji.
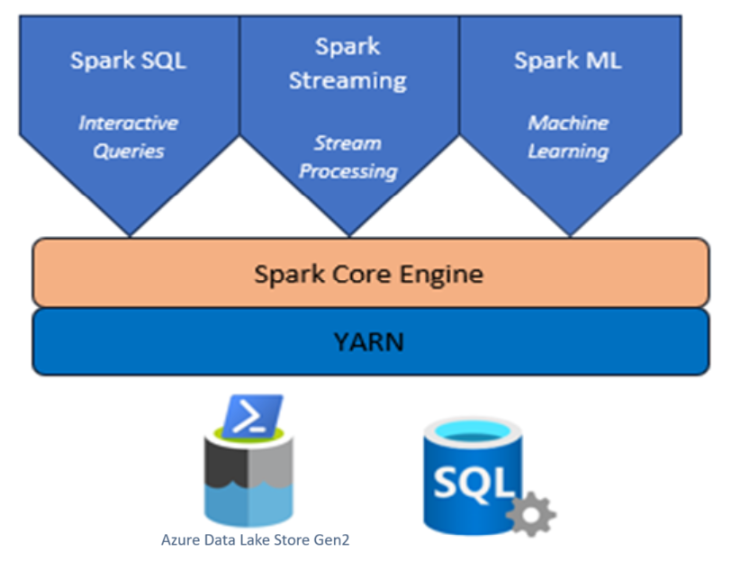
Klaster Apache Spark z usługą HDInsight w usłudze AKS
Azure HDInsight jest zarządzaną usługą analityczną typu „open source” o szerokim zakresie, z przeznaczeniem dla przedsiębiorstw.
Platforma Apache Spark™ w usłudze Azure HDInsight w usłudze AKS to zarządzana usługa spark na platformie Microsoft Azure. Za pomocą platformy Apache Spark w usłudze Azure HDInsight w usłudze AKS możesz przechowywać i przetwarzać dane na platformie Azure. Klastry Spark w usłudze HDInsight są zgodne z usługą Lub Azure Data Lake Storage Gen2, dzięki czemu można zastosować przetwarzanie platformy Spark w istniejących magazynach danych.
Platforma Apache Spark dla usługi HDInsight w usłudze AKS umożliwia szybką analizę danych i przetwarzanie klastrów przy użyciu przetwarzania w pamięci. Notes Jupyter Notebook umożliwia interakcję z danymi, łączenie kodu z tekstem markdown i wykonywanie prostych wizualizacji.
Platforma Apache Spark w usłudze AKS w usłudze HDInsight składa się z wielu składników jako zasobników.
Kontrolery klastra
Kontrolery klastrów są odpowiedzialne za instalowanie odpowiednich usług i zarządzanie nimi. Różne kontrolery są instalowane i zarządzane w klastrze Spark.
Składniki usługi Apache Spark
Usługa zookeeper: trzy węzły klastra zookeeper, służy jako rozproszony koordynator lub magazyn wysokiej dostępności dla innych usług.
Usługa Yarn: klaster usługi Hadoop Yarn, zadania platformy Spark będą zaplanowane w klastrze jako aplikacje usługi Yarn.
Interfejsy klienta: klastry Apache Spark w usłudze HDInsight w usłudze AKS udostępniają różne interfejsy klienta. Livy Server, Jupyter Notebook, Spark History Server, udostępnia usługi Spark dla użytkowników usługi HDInsight w usłudze AKS.
Odwołanie
- Nazwy projektów apache, Apache Spark, Spark i skojarzone z nimi nazwy projektów typu open source są znakami towarowymi platformyApache Software Foundation (ASF).
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla