Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule dowiesz się, jak tworzyć klastry usługi Apache Hadoop w usłudze HDInsight przy użyciu witryny Azure Portal, a następnie uruchamiać zadania usługi Apache Hive w usłudze HDInsight. Większość zadań Hadoop to zadania wsadowe. Tworzysz klaster, uruchamiasz pewne zadania, a następnie usuwasz klaster. W tym artykule wykonasz wszystkie trzy zadania. Aby uzyskać szczegółowe wyjaśnienia dotyczące dostępnych konfiguracji, zobacz Konfigurowanie klastrów w usłudze HDInsight. Aby uzyskać więcej informacji na temat używania portalu do tworzenia klastrów, zobacz Tworzenie klastrów w portalu.
W tym szybkim starcie użyjesz portalu Azure do utworzenia klastra Hadoop w usłudze HDInsight. Klaster możesz utworzyć również przy użyciu szablonu usługi Azure Resource Manager.
Obecnie usługa HDInsight ma siedem różnych typów klastrów. Każdy typ klastra obsługuje inny zestaw składników. Wszystkie typy klastrów obsługują technologię Hive. Aby uzyskać listę składników obsługiwanych w usłudze HDInsight, zobacz artykuł Nowości w wersjach klastra Hadoop dostarczanych z usługą HDInsight.
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Tworzenie klastra Apache Hadoop
W tej sekcji utworzysz klaster usługi Hadoop w usłudze HDInsight przy użyciu witryny Azure Portal.
Zaloguj się w witrynie Azure Portal.
W menu górnym wybierz pozycję + Utwórz zasób.
Wybierz Analytics>Azure HDInsight, aby przejść do stronę Tworzenie klastra HDInsight.
Na karcie Podstawowe podaj następujące informacje:
Nieruchomość Opis Subskrypcja Z listy rozwijanej wybierz subskrypcję platformy Azure używaną dla klastra. Grupa zasobów Z listy rozwijanej wybierz istniejącą grupę zasobów lub wybierz pozycję Utwórz nową. Nazwa klastra Podaj globalnie unikatową nazwę. Nazwa może składać się z maksymalnie 59 znaków, w tym liter, cyfr i łączników. Pierwsze i ostatnie znaki nazwy nie mogą być łącznikami. Region Z listy rozwijanej wybierz region, w którym jest tworzony klaster. Wybierz lokalizację znajdującą się blisko, aby zapewnić lepszą wydajność. Typ klastra Wybierz pozycję Wybierz typ klastra. Następnie wybierz pozycję Hadoop jako typ klastra. Wersja Z listy rozwijanej wybierz wersję. Jeśli nie wiesz, co wybrać, użyj domyślnej wersji. Nazwa użytkownika i hasło logowania klastra Domyślna nazwa logowania to administrator. Hasło musi mieć długość co najmniej 10 znaków i musi zawierać co najmniej jedną cyfrę, jedną wielką literę i jedną małą literę, jeden znak niefanumeryczny (z wyjątkiem znaków ' ` "). Upewnij się, że nie udostępniasz typowych haseł, takich jak "Pass@word1".Nazwa użytkownika protokołu SSH (Secure Shell) Domyślna nazwa użytkownika to sshuser. Możesz podać inną nazwę użytkownika protokołu SSH.Używanie hasła logowania klastra dla protokołu SSH Zaznacz to pole wyboru, aby użyć tego samego hasła dla użytkownika SSH, co hasło podane dla użytkownika logowania do klastra. 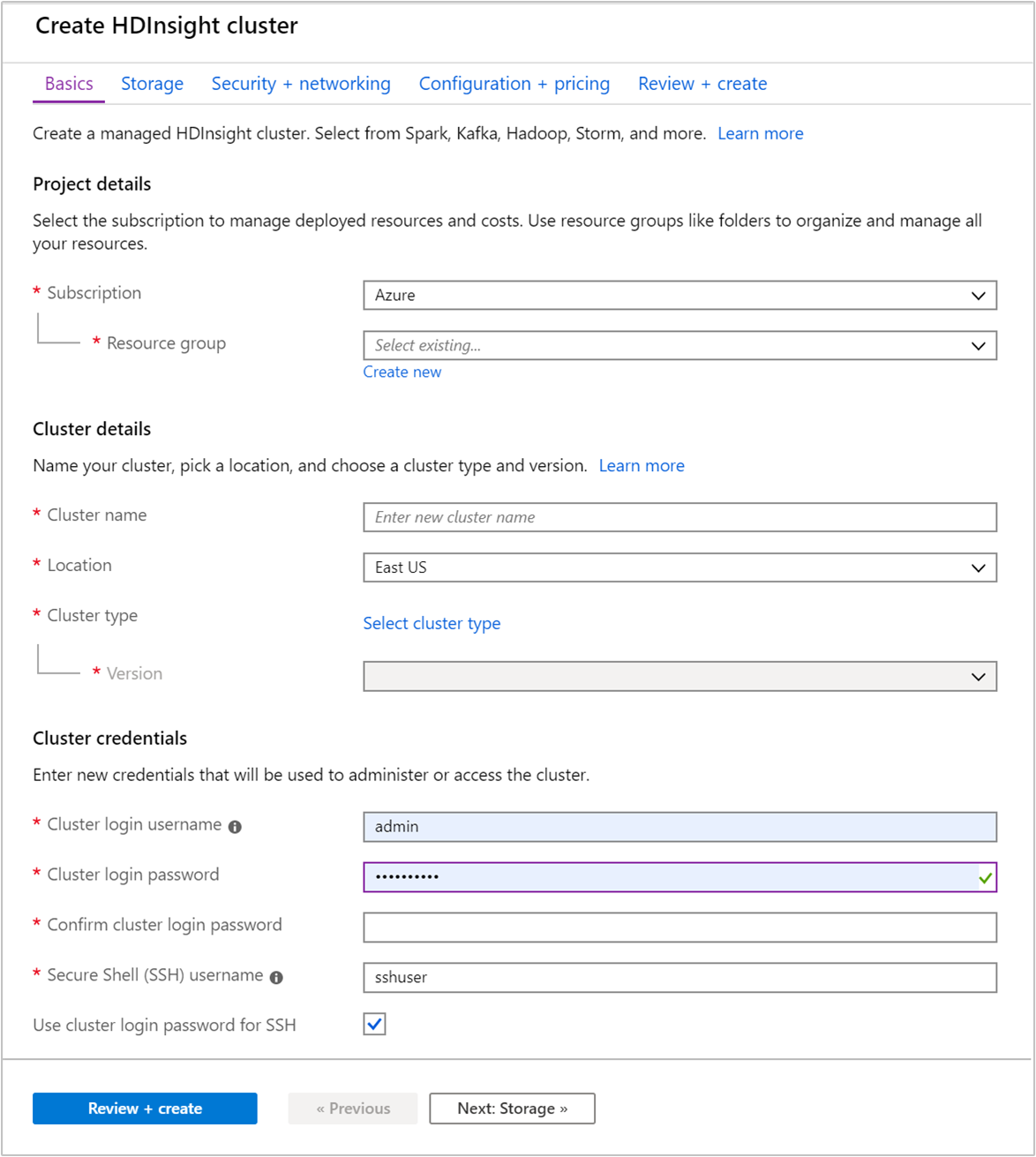
Wybierz pozycję Dalej: Magazyn >> , aby przejść do ustawień magazynu.
Na karcie Magazyn podaj następujące wartości:
Nieruchomość Opis Podstawowy typ magazynu Użyj domyślnej wartości Azure Storage. Metoda wybierania Użyj wartości domyślnej Wybierz z listy. Konto magazynu podstawowego Użyj listy rozwijanej, aby wyselekcjonować istniejące konto magazynowe lub wybierz pozycję Utwórz nowe. Jeśli tworzysz nowe konto, nazwa musi mieć długość od 3 do 24 znaków i może zawierać tylko cyfry i małe litery Kontener Użyj wartości wypełnianej automatycznie. 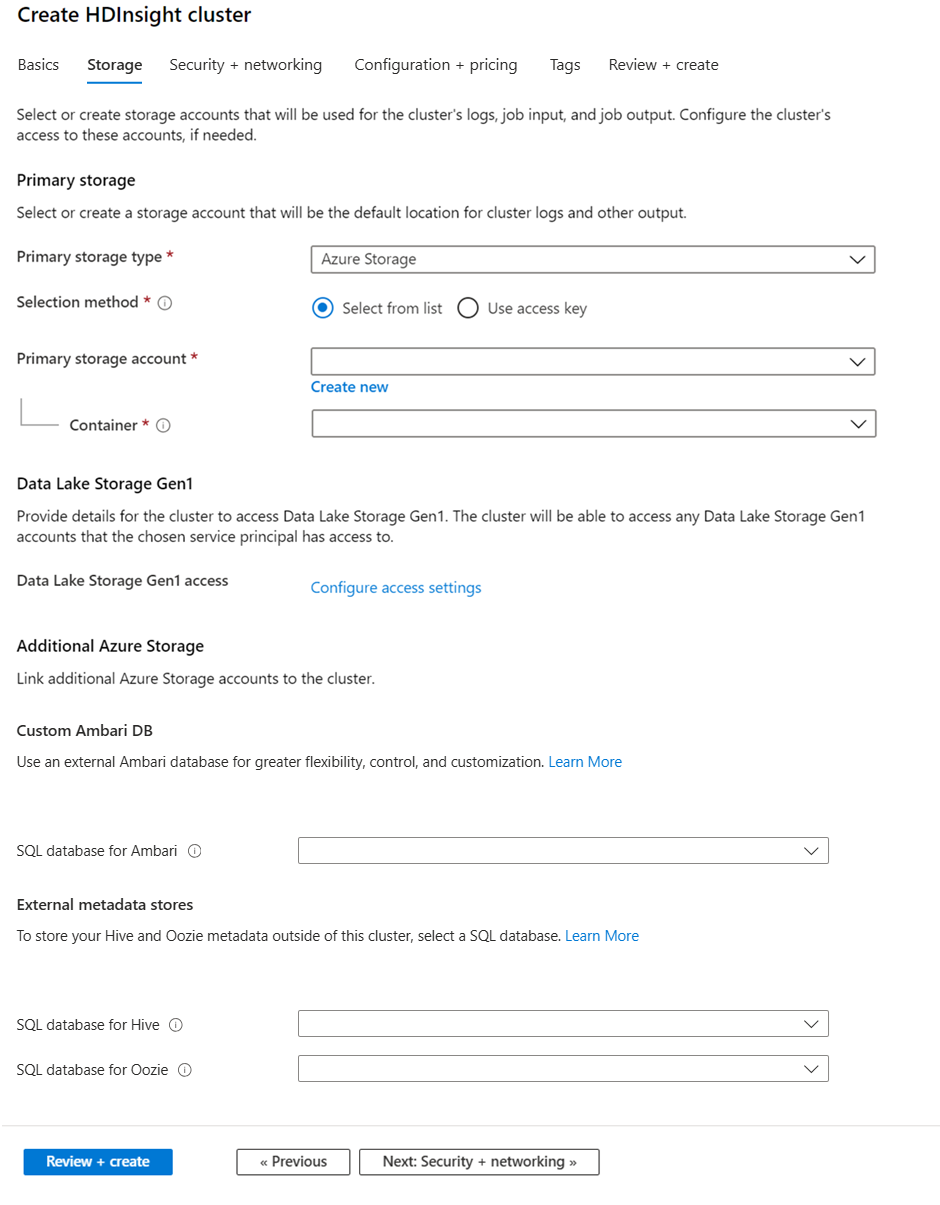
Każdy klaster ma konto usługi Azure Storage lub
Azure Data Lake Storage Gen2zależność. Nazywa się to domyślnym kontem przechowywania. Klaster usługi HDInsight i jego domyślne konto magazynu muszą być kolokowane w tym samym regionie świadczenia usługi Azure. Usunięcie klastrów nie powoduje usunięcia konta przechowywania.Wybierz kartę Przeglądanie i tworzenie .
Na karcie Przeglądanie i tworzenie sprawdź wartości wybrane we wcześniejszych krokach.
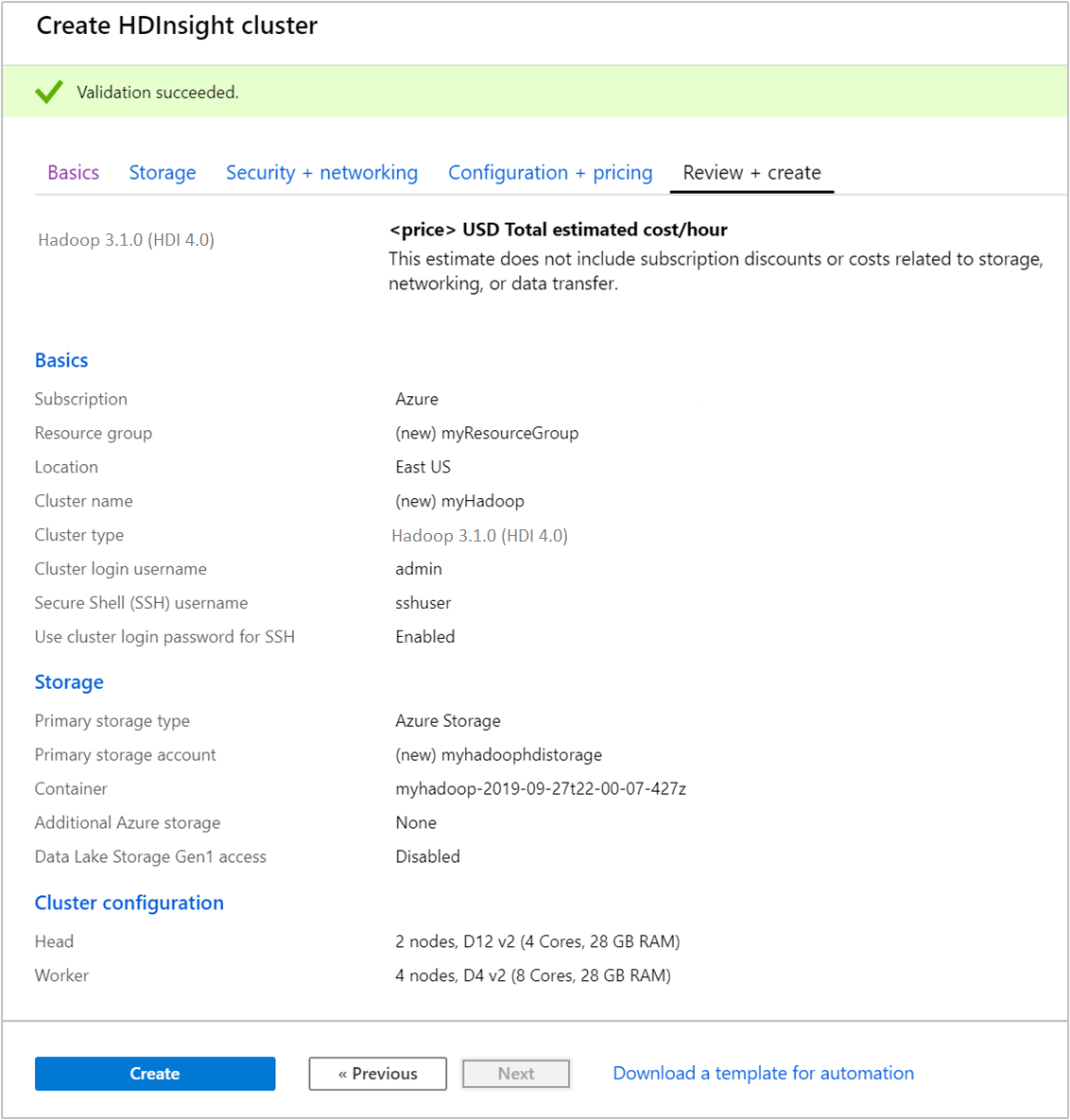
Wybierz pozycję Utwórz. Utworzenie klastra trwa około 20 minut.
Po utworzeniu klastra w witrynie Azure Portal zostanie wyświetlona strona przeglądu klastra.
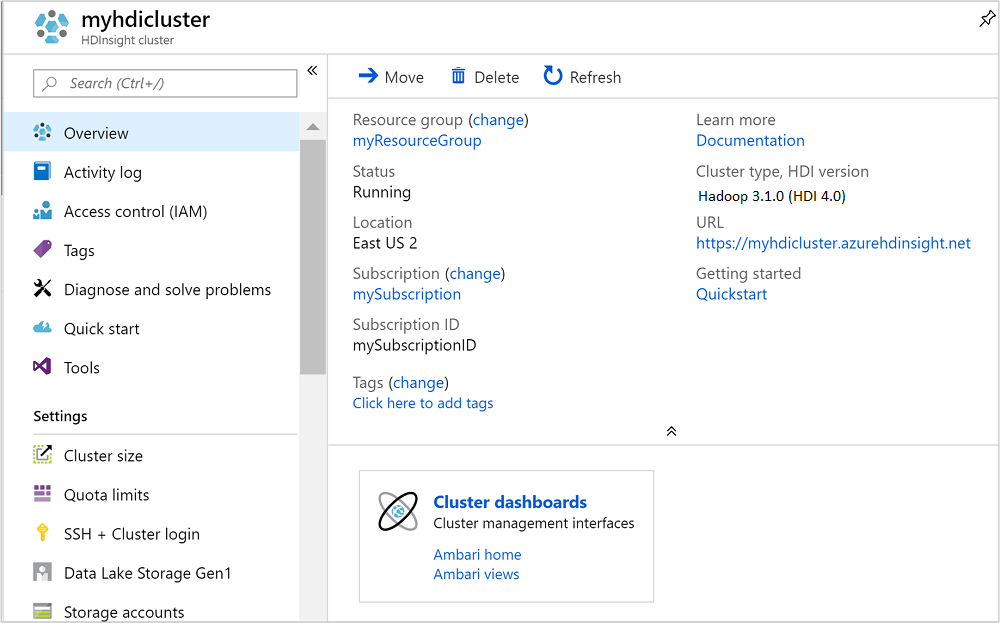
Uruchamianie zapytań technologii Apache Hive
Apache Hive jest najbardziej popularnym składnikiem używanym w usłudze HDInsight Istnieje wiele sposobów uruchamiania zadań Hive w usłudze HDInsight. W tym szybkim starcie użyjesz widoku Ambari Hive z portalu. Aby poznać inne metody przesyłania zadań Hive, zobacz temat Używanie Hive w usłudze HDInsight.
Uwaga
Widok Apache Hive nie jest dostępny w usłudze HDInsight 4.0.
Aby otworzyć narzędzie Ambari, na poprzednim zrzucie ekranu wybierz opcję Pulpit nawigacyjny klastra. Możesz również przejść do
https://ClusterName.azurehdinsight.net, gdzieClusterNamejest klastrem utworzonym w poprzedniej sekcji.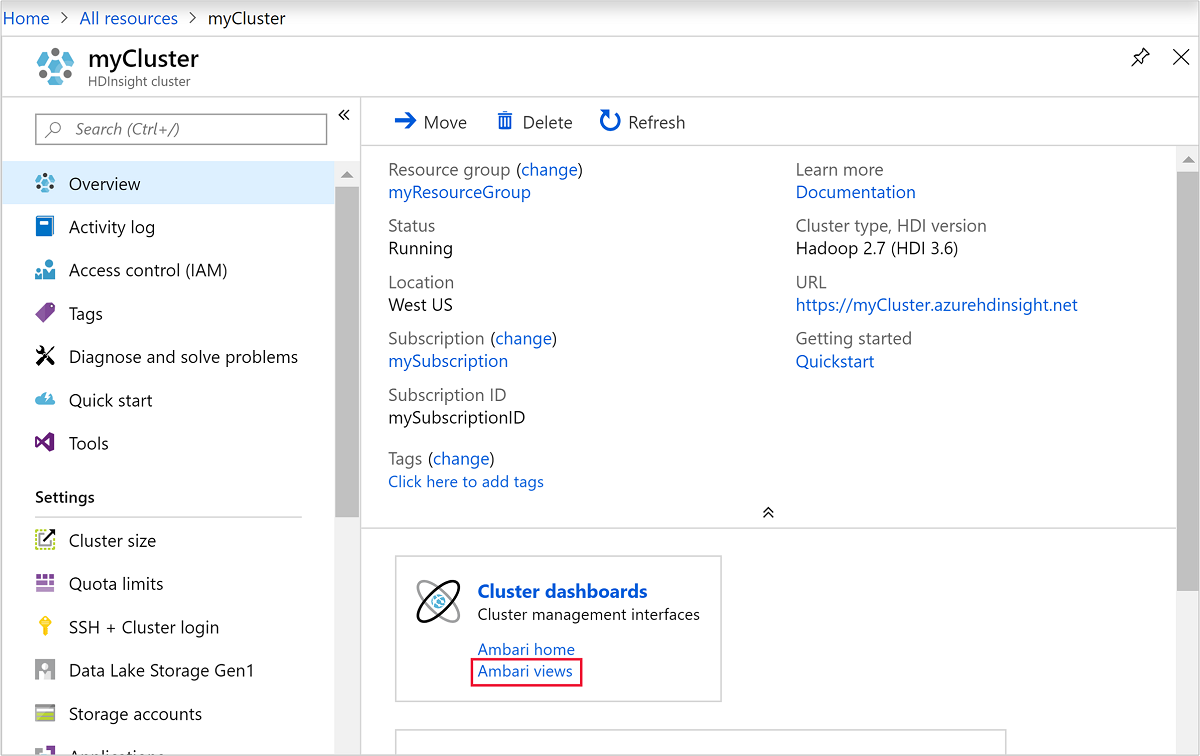
Wprowadź nazwę użytkownika Hadoop i hasło określone w podczas tworzenia klastra. Domyślna nazwa użytkownika to
admin.Otwórz widok Hive View pokazany na poniższym zrzucie ekranu:
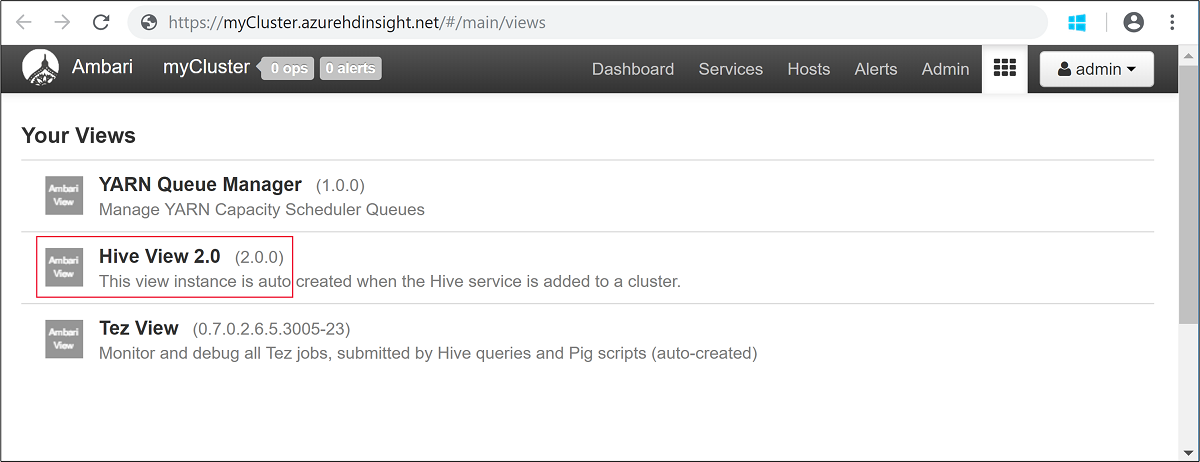
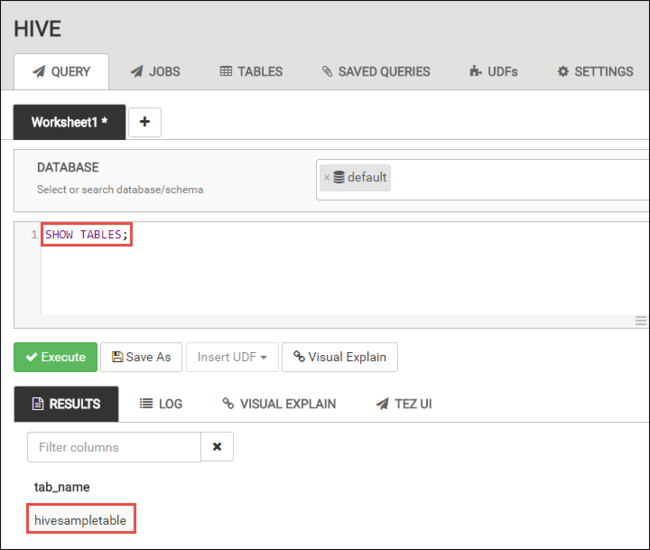
Na karcie QUERY (ZAPYTANIE) wklej poniższe instrukcje HiveQL do arkusza:
SHOW TABLES;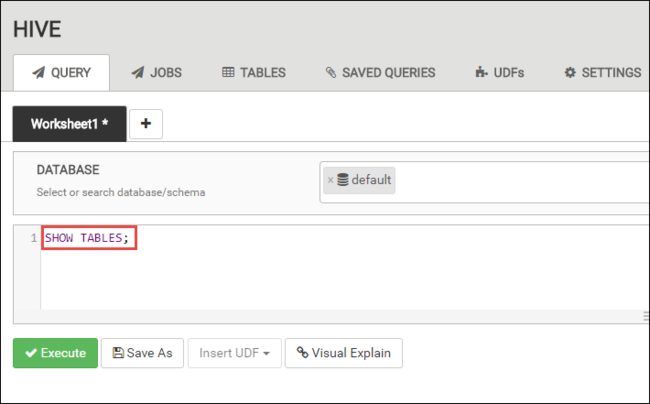
Wybierz polecenie Wykonaj. Poniżej karty QUERY (ZAPYTANIE) zostanie wyświetlona karta RESULTS (WYNIKI) z informacjami o zadaniu.
Po zakończeniu przetwarzania zapytania na karcie QUERY (ZAPYTANIE) są wyświetlane wyniki operacji. Powinna być widoczna jedna tabela o nazwie hivesampletable. Ta przykładowa tabela Hive jest dostępna we wszystkich klastrach usługi HDInsight.
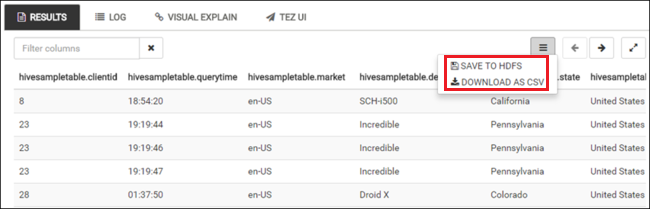
Powtórz kroki 4 i 5, aby uruchomić następujące zapytanie:
SELECT * FROM hivesampletable;Można także zapisać wyniki zapytania. Wybierz przycisk menu z prawej strony i określ, czy chcesz pobrać wyniki jako plik CSV, czy zapisać je na koncie magazynu skojarzonym z klastrem.
Po ukończeniu zadania hive możesz wyeksportować wyniki do bazy danych Azure SQL Database lub SQL Server, a także zwizualizować wyniki przy użyciu programu Excel. Aby uzyskać więcej informacji na temat korzystania z programu Hive w usłudze HDInsight, zobacz Use Apache Hive and HiveQL with Apache Hadoop in HDInsight to analyze a sample Apache Log4j file (Używanie technologii Apache Hive i HiveQL z usługą Apache Hadoop w usłudze HDInsight w celu przeanalizowania przykładowego pliku Apache Log4j).
Czyszczenie zasobów
Po zakończeniu pracy z instrukcją szybkiego uruchomienia możesz usunąć klaster. W usłudze HDInsight dane są przechowywane w usłudze Azure Storage, dzięki czemu można bezpiecznie usunąć klaster, gdy nie jest używany. Opłaty są również naliczane za klaster usługi HDInsight, nawet jeśli nie jest używany. Ponieważ opłaty za klaster są wielokrotnie większe niż opłaty za magazyn, warto usunąć klastry, gdy nie są używane.
Uwaga
Jeśli natychmiast przejdziesz do następnego artykułu, aby dowiedzieć się, jak uruchamiać operacje ETL przy użyciu usługi Hadoop w usłudze HDInsight, warto zachować działanie klastra. Dzieje się tak dlatego, że w samouczku musisz ponownie utworzyć klaster Hadoop. Jeśli jednak nie przejdziesz od razu do następnego artykułu, musisz teraz usunąć klaster.
Usuń klaster i/lub domyślne konto przechowywania
Wróć do karty przeglądarki, na której znajduje się witryna Azure Portal. Znajdujesz się na stronie omówienia klastra. Jeśli chcesz usunąć tylko klaster, a zachować domyślne konto magazynu, wybierz Usuń.
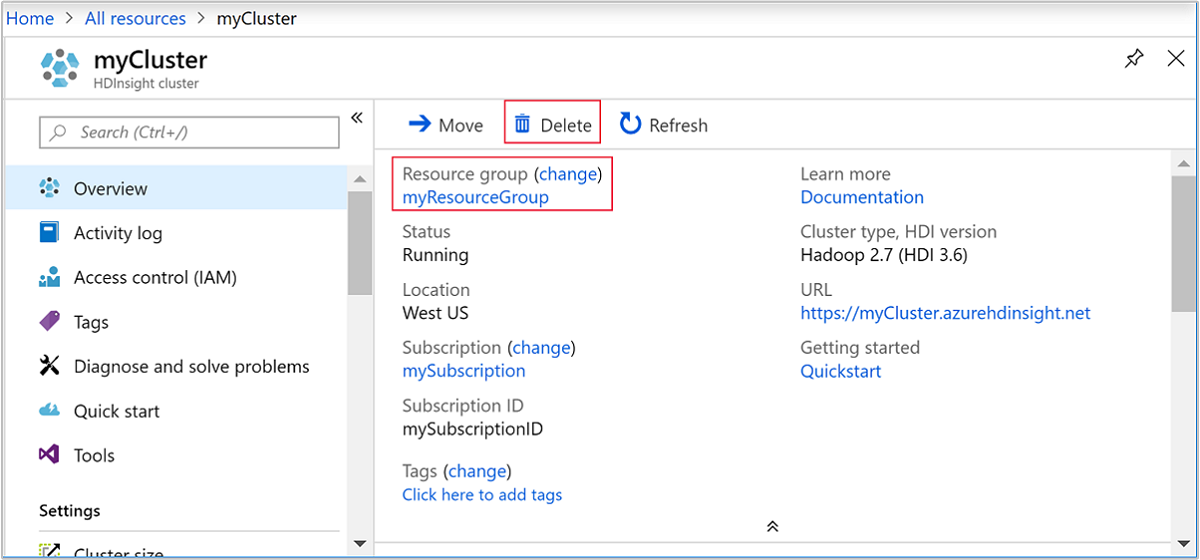
Jeśli chcesz usunąć klaster i domyślne konto przechowywania, wybierz nazwę grupy zasobów (wyróżnioną na poprzednim zrzucie ekranu), aby otworzyć stronę grupy zasobów.
Wybierz opcję Usuń grupę zasobów, aby usunąć grupę zasobów, która zawiera klaster oraz domyślne konto magazynowe. Uwaga: usunięcie grupy zasobów powoduje usunięcie konta magazynu. Jeśli chcesz zachować konto magazynu, wybierz opcję usunięcia tylko klastra.
Następne kroki
W tym przewodniku szybkiego startu przedstawiono sposób tworzenia klastra usługi HDInsight opartego na systemie Linux przy użyciu szablonu Resource Manager oraz wykonywania podstawowych zapytań Hive. W następnym artykule dowiesz się, jak przeprowadzić operację wyodrębniania, transformacji i ładowania (ETL, extract, transform, and load) przy użyciu usługi Hadoop w usłudze HDInsight.