Optymalizowanie zapytań technologii Apache Hive w usłudze Azure HDInsight
W tym artykule opisano niektóre z najbardziej typowych optymalizacji wydajności, których można użyć do poprawy wydajności zapytań Apache Hive.
Wybór typu klastra
W usłudze Azure HDInsight można uruchamiać zapytania apache Hive na kilku różnych typach klastrów.
Wybierz odpowiedni typ klastra, aby pomóc zoptymalizować wydajność pod kątem potrzeb związanych z obciążeniem:
- Wybierz typ klastra Interakcyjne zapytanie , aby zoptymalizować pod kątem
ad hoczapytań interakcyjnych. - Wybierz typ klastra Apache Hadoop , aby zoptymalizować zapytania Hive używane jako proces wsadowy.
- Typy klastrów Spark i HBase mogą również uruchamiać zapytania hive i mogą być odpowiednie, jeśli uruchamiasz te obciążenia.
Aby uzyskać więcej informacji na temat uruchamiania zapytań Hive w różnych typach klastrów usługi HDInsight, zobacz Co to jest apache Hive i HiveQL w usłudze Azure HDInsight?.
Skalowanie węzłów roboczych w poziomie
Zwiększenie liczby węzłów roboczych w klastrze usługi HDInsight umożliwia równoległe uruchamianie zadań przy użyciu większej liczby maperów i reduktorów. Istnieją dwa sposoby zwiększania skali w poziomie w usłudze HDInsight:
Podczas tworzenia klastra można określić liczbę węzłów procesu roboczego przy użyciu witryny Azure Portal, programu Azure PowerShell lub interfejsu wiersza polecenia. Więcej informacji można znaleźć w artykule Create HDInsight clusters (Tworzenie klastrów usługi HDInsight). Poniższy zrzut ekranu przedstawia konfigurację węzła procesu roboczego w witrynie Azure Portal:
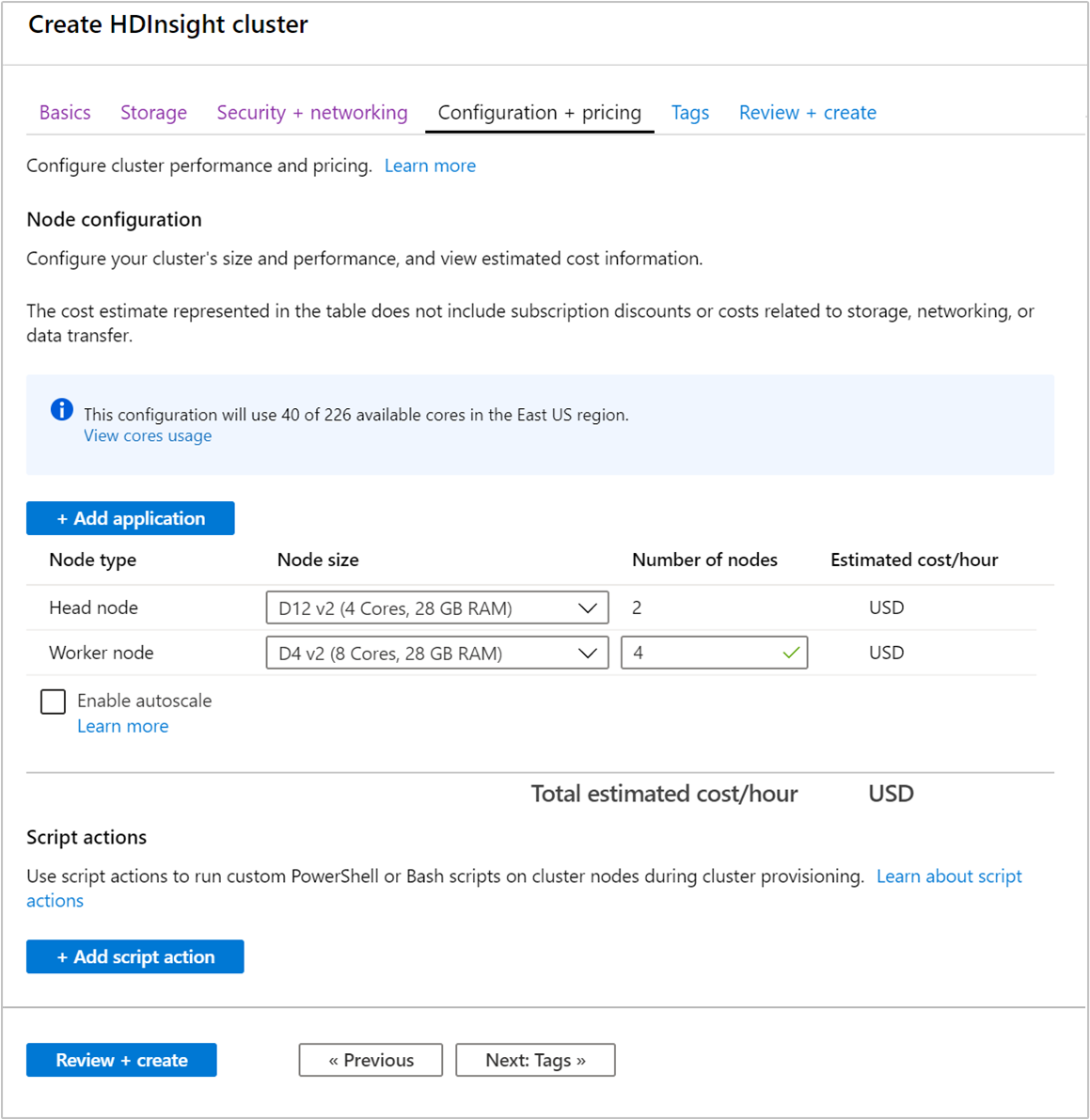
Po utworzeniu można również edytować liczbę węzłów procesu roboczego w celu dalszego skalowania klastra w poziomie bez ponownego utworzenia:
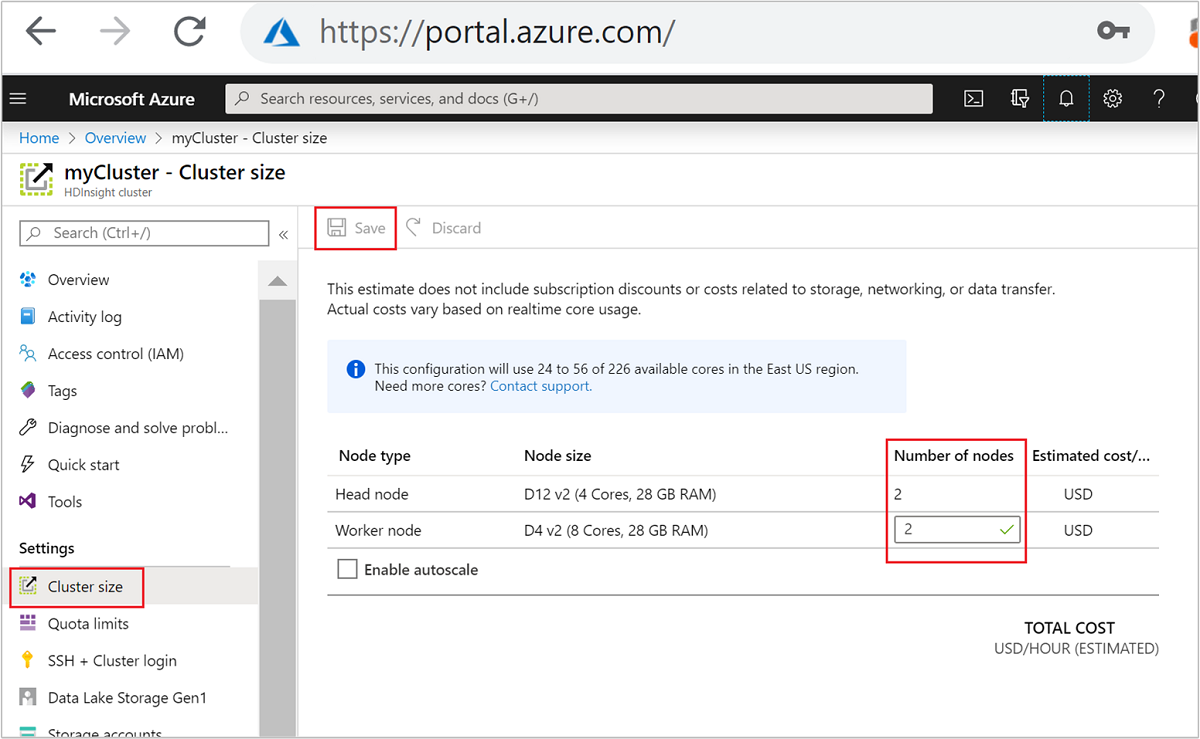
Aby uzyskać więcej informacji na temat skalowania usługi HDInsight, zobacz Skalowanie klastrów usługi HDInsight
Używanie platformy Apache Tez zamiast redukcji mapy
Apache Tez to alternatywny aparat wykonywania aparatu MapReduce. Klastry usługi HDInsight oparte na systemie Linux domyślnie mają włączone narzędzie Tez.
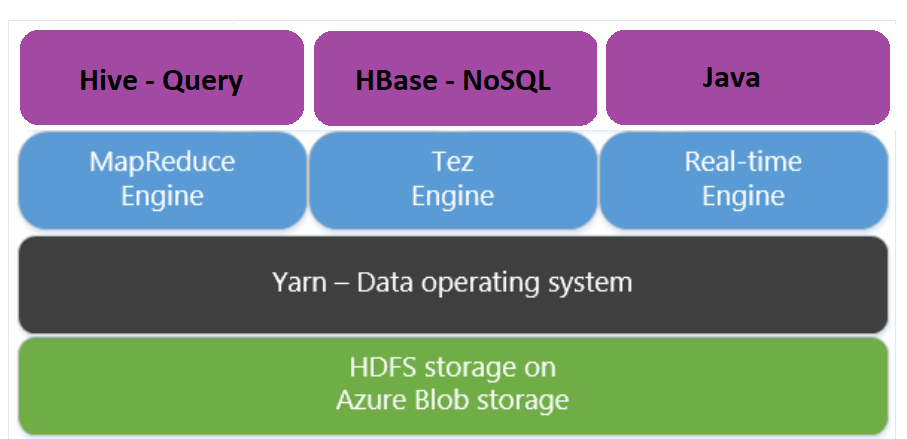
Aplikacja Tez jest szybsza, ponieważ:
- Wykonaj w acyklicznym grafie Acyklicznym (DAG) jako jedno zadanie w aucie MapReduce. DaG wymaga, aby każdy zestaw maperów był obserwowany przez jeden zestaw reduktorów. To wymaganie powoduje wyłączenie wielu zadań MapReduce dla każdego zapytania Hive. Tez nie ma takiego ograniczenia i może przetwarzać złożoną grupę DAG jako jedno zadanie minimalizujące obciążenie uruchamiania zadania.
- Unika niepotrzebnych zapisów. Wiele zadań służy do przetwarzania tego samego zapytania Hive w aparacie MapReduce. Dane wyjściowe każdego zadania MapReduce są zapisywane w systemie plików HDFS dla danych pośrednich. Ponieważ usługa Tez minimalizuje liczbę zadań dla każdego zapytania Hive, jest w stanie uniknąć niepotrzebnych zapisów.
- Minimalizuje opóźnienia uruchamiania. Tez jest lepiej w stanie zminimalizować opóźnienie uruchamiania, zmniejszając liczbę maperów, których potrzebuje do rozpoczęcia, a także poprawy optymalizacji w całym czasie.
- Ponownie używa kontenerów. Zawsze, gdy możliwe jest ponowne użycie kontenerów w usłudze Tez, aby zapewnić zmniejszenie opóźnienia podczas uruchamiania kontenerów.
- Techniki optymalizacji ciągłej. Tradycyjnie optymalizacja została wykonana podczas fazy kompilacji. Jednak więcej informacji na temat danych wejściowych jest dostępnych, które umożliwiają lepszą optymalizację w czasie wykonywania. Tez używa technik optymalizacji ciągłej, które umożliwiają optymalizację planu w fazie wykonywania.
Aby uzyskać więcej informacji na temat tych pojęć, zobacz Apache TEZ.
Możesz włączyć dowolne zapytanie Hive, prefiksując zapytanie za pomocą następującego polecenia zestawu:
set hive.execution.engine=tez;
Partycjonowanie programu Hive
Operacje we/wy są głównym wąskim gardłem wydajności w przypadku uruchamiania zapytań Hive. Wydajność można poprawić, jeśli można zmniejszyć ilość danych, które należy odczytać. Domyślnie zapytania hive skanują całe tabele programu Hive. Jednak w przypadku zapytań, które muszą skanować niewielką ilość danych (na przykład zapytania z filtrowaniem), to zachowanie powoduje niepotrzebne obciążenie. Partycjonowanie hive umożliwia wykonywanie zapytań Hive w celu uzyskania dostępu tylko do niezbędnej ilości danych w tabelach programu Hive.
Partycjonowanie hive jest implementowane przez reorganizację danych pierwotnych w nowych katalogach. Każda partycja ma własny katalog plików. Użytkownik definiuje partycjonowanie. Na poniższym diagramie przedstawiono partycjonowanie tabeli Programu Hive według kolumny Year. Nowy katalog jest tworzony dla każdego roku.
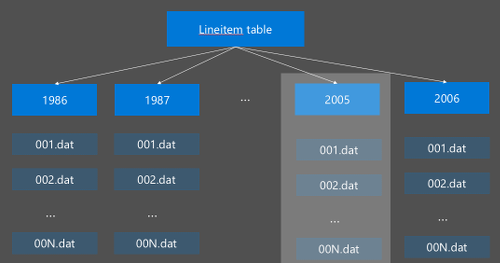
Niektóre zagadnienia dotyczące partycjonowania:
- Nie należy partycjonować — partycjonowanie kolumn z zaledwie kilkoma wartościami może spowodować kilka partycji. Na przykład partycjonowanie według płci powoduje utworzenie tylko dwóch partycji (mężczyzn i kobiet), więc zmniejsz opóźnienie o maksymalnie połowę.
- Nie przedziel partycji — w drugiej skrajnej sytuacji utworzenie partycji w kolumnie z unikatową wartością (na przykład userid) powoduje wiele partycji. Nadmierna partycja powoduje duże obciążenie węzła namenode klastra, ponieważ musi obsługiwać dużą liczbę katalogów.
- Unikaj niesymetryczności danych — odpowiednio wybierz klucz partycjonowania, aby wszystkie partycje mają równomierny rozmiar. Na przykład partycjonowanie w kolumnie State może wypaczyć rozkład danych. Ponieważ stan Kalifornii ma populację prawie 30x, rozmiar partycji jest potencjalnie niesymetryczny, a wydajność może się znacznie różnić.
Aby utworzyć tabelę partycji, użyj klauzuli Partitioned By :
CREATE TABLE lineitem_part
(L_ORDERKEY INT, L_PARTKEY INT, L_SUPPKEY INT,L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE;
Po utworzeniu tabeli partycjonowanej można utworzyć partycjonowanie statyczne lub partycjonowanie dynamiczne.
Partycjonowanie statyczne oznacza, że dane zostały już podzielone na fragmenty w odpowiednich katalogach. W przypadku partycji statycznych można ręcznie dodawać partycje Programu Hive na podstawie lokalizacji katalogu. Poniższy fragment kodu jest przykładem.
INSERT OVERWRITE TABLE lineitem_part PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') SELECT * FROM lineitem WHERE lineitem.L_SHIPDATE = '5/23/1996 12:00:00 AM' ALTER TABLE lineitem_part ADD PARTITION (L_SHIPDATE = '5/23/1996 12:00:00 AM') LOCATION 'wasb://sampledata@ignitedemo.blob.core.windows.net/partitions/5_23_1996/'Partycjonowanie dynamiczne oznacza, że program Hive ma automatycznie tworzyć partycje. Ponieważ tabela partycjonowania została już utworzona z tabeli przejściowej, wystarczy wstawić dane do tabeli partycjonowanej:
SET hive.exec.dynamic.partition = true; SET hive.exec.dynamic.partition.mode = nonstrict; INSERT INTO TABLE lineitem_part PARTITION (L_SHIPDATE) SELECT L_ORDERKEY as L_ORDERKEY, L_PARTKEY as L_PARTKEY, L_SUPPKEY as L_SUPPKEY, L_LINENUMBER as L_LINENUMBER, L_QUANTITY as L_QUANTITY, L_EXTENDEDPRICE as L_EXTENDEDPRICE, L_DISCOUNT as L_DISCOUNT, L_TAX as L_TAX, L_RETURNFLAG as L_RETURNFLAG, L_LINESTATUS as L_LINESTATUS, L_SHIPDATE as L_SHIPDATE_PS, L_COMMITDATE as L_COMMITDATE, L_RECEIPTDATE as L_RECEIPTDATE, L_SHIPINSTRUCT as L_SHIPINSTRUCT, L_SHIPMODE as L_SHIPMODE, L_COMMENT as L_COMMENT, L_SHIPDATE as L_SHIPDATE FROM lineitem;
Aby uzyskać więcej informacji, zobacz Partycjonowane tabele.
Używanie formatu ORCFile
Program Hive obsługuje różne formaty plików. Na przykład:
- Tekst: domyślny format pliku i działa z większością scenariuszy.
- Avro: dobrze sprawdza się w scenariuszach współdziałania.
- ORC/Parquet: najlepiej nadaje się do wydajności.
Format ORC (Zoptymalizowany kolumnowy wiersz) to wysoce wydajny sposób przechowywania danych hive. W porównaniu z innymi formatami usługa ORC ma następujące zalety:
- obsługa typów złożonych, w tym typu DateTime i złożonego i częściowo ustrukturyzowanego.
- do 70% kompresji.
- indeksuje co 10 000 wierszy, co umożliwia pomijanie wierszy.
- znaczący spadek wykonywania w czasie wykonywania.
Aby włączyć format ORC, należy najpierw utworzyć tabelę z klauzulą Stored as ORC:
CREATE TABLE lineitem_orc_part
(L_ORDERKEY INT, L_PARTKEY INT,L_SUPPKEY INT, L_LINENUMBER INT,
L_QUANTITY DOUBLE, L_EXTENDEDPRICE DOUBLE, L_DISCOUNT DOUBLE,
L_TAX DOUBLE, L_RETURNFLAG STRING, L_LINESTATUS STRING,
L_SHIPDATE_PS STRING, L_COMMITDATE STRING, L_RECEIPTDATE STRING,
L_SHIPINSTRUCT STRING, L_SHIPMODE STRING, L_COMMENT STRING)
PARTITIONED BY(L_SHIPDATE STRING)
STORED AS ORC;
Następnie wstawisz dane do tabeli ORC z tabeli przejściowej. Na przykład:
INSERT INTO TABLE lineitem_orc
SELECT L_ORDERKEY as L_ORDERKEY,
L_PARTKEY as L_PARTKEY ,
L_SUPPKEY as L_SUPPKEY,
L_LINENUMBER as L_LINENUMBER,
L_QUANTITY as L_QUANTITY,
L_EXTENDEDPRICE as L_EXTENDEDPRICE,
L_DISCOUNT as L_DISCOUNT,
L_TAX as L_TAX,
L_RETURNFLAG as L_RETURNFLAG,
L_LINESTATUS as L_LINESTATUS,
L_SHIPDATE as L_SHIPDATE,
L_COMMITDATE as L_COMMITDATE,
L_RECEIPTDATE as L_RECEIPTDATE,
L_SHIPINSTRUCT as L_SHIPINSTRUCT,
L_SHIPMODE as L_SHIPMODE,
L_COMMENT as L_COMMENT
FROM lineitem;
Więcej informacji na temat formatu ORC można przeczytać w podręczniku języka Apache Hive.
Wektoryzacja
Wektoryzacja umożliwia programowi Hive przetwarzanie partii 1024 wierszy razem zamiast przetwarzania jednego wiersza naraz. Oznacza to, że proste operacje są wykonywane szybciej, ponieważ należy uruchomić mniej kodu wewnętrznego.
Aby włączyć prefiks wektoryzacji zapytania Hive z następującym ustawieniem:
set hive.vectorized.execution.enabled = true;
Aby uzyskać więcej informacji, zobacz Wektoryzowane wykonywanie zapytań.
Inne metody optymalizacji
Istnieje więcej metod optymalizacji, które można wziąć pod uwagę, na przykład:
- Zasobniki Hive: technika umożliwiająca klastrowanie lub segmentowanie dużych zestawów danych w celu optymalizacji wydajności zapytań.
- Optymalizacja sprzężenia: optymalizacja planowania wykonywania zapytań programu Hive w celu zwiększenia wydajności sprzężeń i zmniejszenia zapotrzebowania na wskazówki użytkownika. Aby uzyskać więcej informacji, zobacz Optymalizacja dołączania.
- Zwiększ reduktory.
Następne kroki
W tym artykule przedstawiono kilka typowych metod optymalizacji zapytań hive. Więcej informacji można znaleźć w następujących artykułach:
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla