Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Mechanizmy replikacji usługi Azure HDInsight można zintegrować z architekturą rozwiązania o wysokiej dostępności. W tym artykule fikcyjne badanie przypadku dla firmy Contoso Retail służy do wyjaśnienia możliwych podejść odzyskiwania po awarii o wysokiej dostępności, zagadnień dotyczących kosztów i odpowiednich projektów.
Rekomendacje dotyczące odzyskiwania po awarii w systemach o wysokiej dostępności mogą mieć wiele permutacji i kombinacji. Te rozwiązania mają zostać dostarczone po zapoznaniu się z zaletami i wadami każdej opcji. W tym artykule omówiono tylko jedno możliwe rozwiązanie.
Architektura klienta
Na poniższej ilustracji przedstawiono podstawową architekturę firmy Contoso Retail. Architektura składa się z obciążenia przesyłania strumieniowego, obciążenia wsadowego, warstwy obsługowej, warstwy zużycia, warstwy składowania i kontroli wersji.
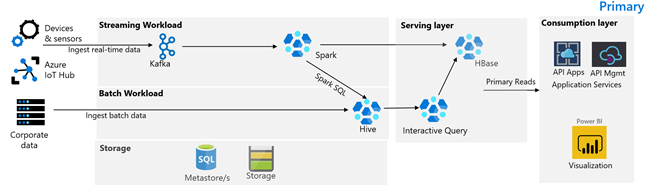
Obciążenie związane z przesyłaniem strumieniowym
Urządzenia i czujniki tworzą dane w usłudze HDInsight Kafka, która stanowi platformę obsługi komunikatów. Konsument Spark na platformie HDInsight odczytuje z tematów Kafki. Platforma Spark przekształca komunikaty przychodzące i zapisuje je w klastrze HBase usługi HDInsight w warstwie obsługującej.
Obciążenie wsadowe
Klaster hadoop usługi HDInsight z uruchomionym programem Hive i usługą MapReduce pozyskuje dane z lokalnych systemów transakcyjnych. Nieprzetworzone dane przekształcone przez Hive i MapReduce są przechowywane w tabelach Hive na logicznej partycji jeziora danych obsługiwanej przez usługę Azure Data Lake Storage Gen2. Dane przechowywane w tabelach Hive są również udostępniane usłudze Spark SQL, która przekształca je wsadowo przed zapisaniem wyselekcjonowanych danych w bazie HBase do obsługi.
Warstwa serwująca
Klaster HBase usługi HDInsight z usługą Apache Phoenix służy do udostępniania danych aplikacjom internetowym i pulpitom nawigacyjnym wizualizacji. Klaster LLAP usługi HDInsight służy do spełnienia wymagań wewnętrznych raportowania.
Warstwa konsumpcji
Usługa Azure API Apps i warstwa API Management obsługują publicznie dostępną stronę internetową. Wewnętrzne wymagania dotyczące raportowania są spełnione przez usługę Power BI.
Warstwa przechowywania
Logiczną partycję Azure Data Lake Storage Gen2 wykorzystuje się jako jezioro danych przedsiębiorstwa. Magazyny metadanych usługi HDInsight są wspierane przez usługę Azure SQL DB.
System kontroli wersji
System kontroli wersji zintegrowany z usługą Azure Pipelines i hostowany poza platformą Azure.
Wymagania dotyczące ciągłości działania klienta
Ważne jest, aby określić minimalną funkcjonalność biznesową, której potrzebujesz, jeśli wystąpi awaria.
Wymagania dotyczące ciągłości działania firmy Contoso Retail
- Musimy być chronieni przed awarią regionalną lub problemem z kondycją usługi regionalnej.
- Moi klienci nigdy nie muszą widzieć błędu 404. Zawartość publiczna musi być zawsze udostępniana. (Cel czasu odzyskiwania = 0)
- Przez większą część roku możemy pokazać zawartość publiczną, która jest nieaktualna o 5 godzin. (Cel punktu odzyskiwania = 5 godzin)
- W okresie świątecznym nasza publiczna zawartość musi być zawsze aktualna. (Cel punktu odzyskiwania = 0)
- Moje wewnętrzne wymagania dotyczące raportowania nie są uważane za krytyczne dla ciągłości działania.
- Optymalizowanie kosztów ciągłości działania.
Proponowane rozwiązanie
Na poniższej ilustracji przedstawiono architekturę wysokiej dostępności odzyskiwania po awarii firmy Contoso Retail.
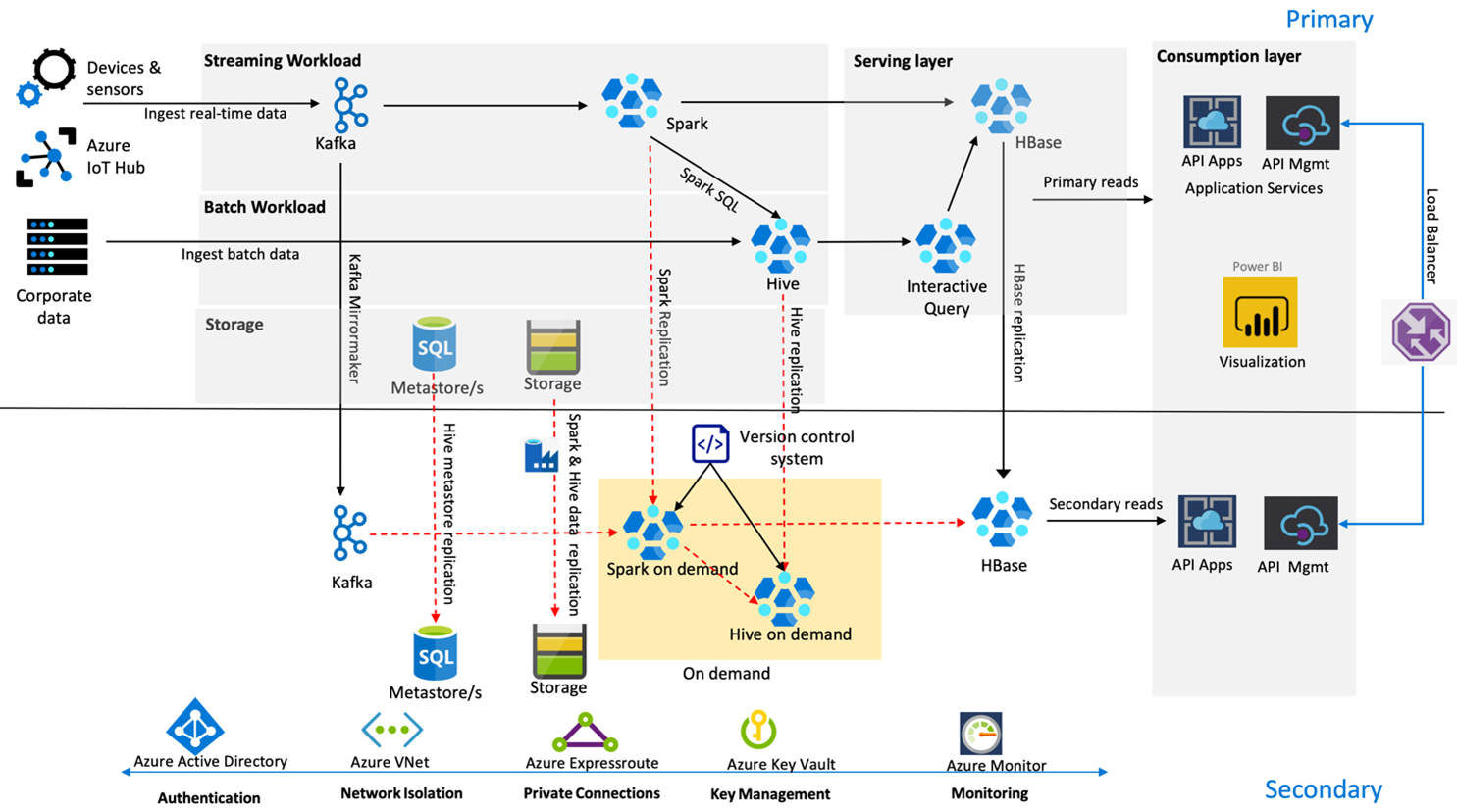
Platforma Kafka używa replikacji aktywnej — pasywnej do dublowania tematów platformy Kafka z regionu podstawowego do regionu pomocniczego. Alternatywą dla replikacji w platformie Kafka może być produkowanie do platformy Kafka w obu regionach.
Usługi Hive i Spark używają aktywnych modeli replikacji podstawowej — pomocniczej na żądanie w normalnych czasach. Proces replikacji programu Hive jest okresowo uruchamiany i towarzyszy replikacji magazynu metadanych Azure SQL hive i konta magazynu Hive. Konto magazynu Spark jest okresowo replikowane przy użyciu narzędzia ADF DistCP. Przejściowy charakter tych klastrów pomaga zoptymalizować koszty. Replikacje są zaplanowane co 4 godziny, aby osiągnąć punkt docelowy czasu odtworzenia co najmniej godzinę przed wymaganym pięciogodzinnym terminem.
Replikacja bazy danych HBase stosuje model Leader – Follower w normalnych warunkach, aby zapewnić, że dane są zawsze dostępne niezależnie od regionu, a cel punktu odzyskiwania (RPO) jest bardzo niski.
Jeśli w regionie podstawowym wystąpi awaria regionalna, strona internetowa i treść zaplecza są obsługiwane z regionu pomocniczego przez 5 godzin z pewnym stopniem opóźnienia. Jeśli pulpit nawigacyjny kondycji usługi platformy Azure nie wskazuje przewidywanego czasu odzyskiwania w pięciogodzinnym oknie, firma Contoso Retail utworzy warstwę transformacji Hive i Spark w regionie zapasowym, a następnie przekieruje wszystkie źródła danych do regionu zapasowego. Uczynienie regionu wtórnego zapisywalnym spowodowałoby proces odtworzenia, który obejmuje replikację z powrotem do regionu podstawowego.
Podczas szczytowego sezonu zakupów cała pomocnicza linia jest zawsze aktywna i działająca. Producenci platformy Kafka tworzą produkty w obu regionach, a replikacja bazy danych HBase zostanie zmieniona z Leader-Follower na Leader-Leader, aby zapewnić, że zawartość publiczna jest zawsze aktualna.
Nie trzeba projektować rozwiązania trybu failover na potrzeby raportowania wewnętrznego, ponieważ nie ma krytycznego wpływu na ciągłość działalności biznesowej.
Następne kroki
Aby dowiedzieć się więcej o elementach omówionych w tym artykule, zobacz: