Usługi wysokiej dostępności obsługiwane przez usługę Azure HDInsight
Aby zapewnić optymalny poziom dostępności składników analitycznych, usługa HDInsight została opracowana z unikatową architekturą zapewniającą wysoką dostępność krytycznych usług. Firma Microsoft opracowała niektóre składniki tej architektury, aby zapewnić automatyczne przejście w tryb failover. Inne składniki to standardowe składniki apache wdrożone w celu obsługi określonych usług. W tym artykule opisano architekturę modelu usługi wysokiej dostępności w usłudze HDInsight, sposób obsługi trybu failover dla usług wysokiej dostępności oraz najlepsze rozwiązania dotyczące odzyskiwania po innych przerwach w działaniu usługi.
Uwaga
Ten artykuł zawiera odwołania do terminu slave (element podrzędny), który nie jest już używany przez firmę Microsoft. Po usunięciu terminu z oprogramowania usuniemy go z tego artykułu.
Infrastruktura wysokiej dostępności
Usługa HDInsight zapewnia dostosowaną infrastrukturę, aby zapewnić wysoką dostępność czterech podstawowych usług dzięki automatycznym funkcjom trybu failover:
- Serwer Apache Ambari
- Serwer osi czasu aplikacji dla usługi Apache YARN
- Serwer historii zadań dla usługi Hadoop MapReduce
- Apache Livy
Ta infrastruktura składa się z wielu usług i składników oprogramowania, z których część została zaprojektowana przez firmę Microsoft. Następujące składniki są unikatowe dla platformy usługi HDInsight:
- Kontroler trybu failover podrzędnego
- Główny kontroler trybu failover
- Usługa wysokiej dostępności podrzędnej
- Główna usługa wysokiej dostępności
Istnieją również inne usługi wysokiej dostępności, które są obsługiwane przez składniki niezawodności apache typu open source. Te składniki są również obecne w klastrach usługi HDInsight:
- Węzeł nazw systemu plików Hadoop (HDFS)
- YARN ResourceManager
- Wzorzec bazy danych HBase
W poniższych sekcjach opisano bardziej szczegółowo sposób współpracy tych usług.
Usługi wysokiej dostępności w usłudze HDInsight
Firma Microsoft zapewnia obsługę czterech usług Apache w poniższej tabeli w klastrach usługi HDInsight. Aby odróżnić je od usług wysokiej dostępności obsługiwanych przez składniki z platformy Apache, są one nazywane usługami HDInsight HA.
| Usługa | Węzły klastra | Typy klastrów | Purpose |
|---|---|---|---|
| Serwer Apache Ambari | Aktywny węzeł główny | wszystkie | Monitoruje klaster i zarządza nim. |
| Serwer osi czasu aplikacji dla usługi Apache YARN | Aktywny węzeł główny | Wszystkie z wyjątkiem platformy Kafka | Utrzymuje informacje o debugowaniu dotyczące zadań usługi YARN uruchomionych w klastrze. |
| Serwer historii zadań dla usługi Hadoop MapReduce | Aktywny węzeł główny | Wszystkie z wyjątkiem platformy Kafka | Obsługuje debugowanie danych dla zadań MapReduce. |
| Apache Livy | Aktywny węzeł główny | platforma Spark | Umożliwia łatwą interakcję z klastrem Spark za pośrednictwem interfejsu REST |
Uwaga
Klastry pakietu HDInsight Enterprise Security (ESP) obecnie zapewniają wysoką dostępność serwera Ambari. Serwer osi czasu aplikacji, serwer historii zadań i usługa Livy są uruchomione tylko w węźle głównym i nie są w trybie failover do węzła headnode1 w przypadku przejścia w tryb failover systemu Ambari. Baza danych osi czasu aplikacji znajduje się również w węźle headnode0, a nie w programie Ambari SQL Server.
Architektura
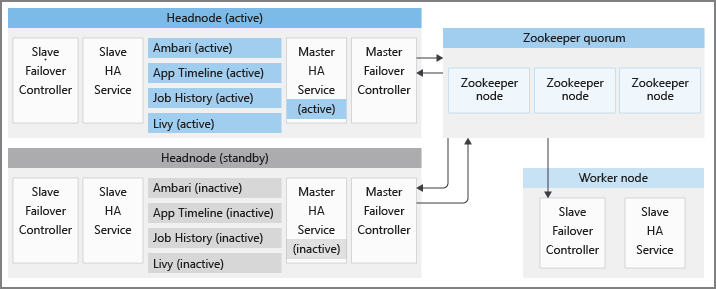
Każdy klaster usługi HDInsight ma odpowiednio dwa węzły główne w trybach aktywnych i rezerwowych. Usługi HDInsight HA działają tylko w węzłach głównych. Te usługi powinny być zawsze uruchomione w aktywnym węźle głównym i zatrzymane i umieszczone w trybie konserwacji w węźle głównym rezerwowym.
Aby zachować prawidłowe stany usług wysokiej dostępności i zapewnić szybki tryb failover, usługa HDInsight korzysta z usługi Apache ZooKeeper, która jest usługą koordynacji dla aplikacji rozproszonych, do przeprowadzania aktywnych wyborów węzłów głównych. Usługa HDInsight aprowizuje również kilka procesów Java w tle, które koordynują procedurę trybu failover dla usług HDInsight HA. Te usługi to: główny kontroler trybu failover, podrzędny kontroler trybu failover, master-ha-service i slave-ha-service.
Apache ZooKeeper
Apache ZooKeeper to usługa koordynacji o wysokiej wydajności dla aplikacji rozproszonych. W środowisku produkcyjnym usługa ZooKeeper zwykle działa w trybie replikowanym, w którym zreplikowana grupa serwera ZooKeeper tworzy kworum. Każdy klaster usługi HDInsight ma trzy węzły zooKeeper, które umożliwiają trzem serwerom usługi ZooKeeper utworzenie kworum. Usługa HDInsight ma dwa kworum usługi ZooKeeper działające równolegle ze sobą. Jeden kworum decyduje o aktywnym węźle głównym w klastrze, w którym powinny być uruchamiane usługi HDInsight HA. Inny kworum służy do koordynowania usług wysokiej dostępności udostępnianych przez platformę Apache, zgodnie z opisem w kolejnych sekcjach.
Kontroler trybu failover podrzędnego
Kontroler trybu failover podrzędnego działa w każdym węźle w klastrze usługi HDInsight. Ten kontroler jest odpowiedzialny za uruchomienie agenta Ambari i slave-ha-service w każdym węźle. Okresowo wykonuje zapytanie o pierwsze kworum zooKeeper dotyczące aktywnego węzła głównego. Po zmianie aktywnych i rezerwowych węzłów głównych podrzędny kontroler trybu failover wykonuje następujące kroki:
- Aktualizacje pliku konfiguracji hosta.
- Uruchamia ponownie agenta systemu Ambari.
Usługa slave-ha-service jest odpowiedzialna za zatrzymywanie usług HDInsight HA (z wyjątkiem serwera Ambari) w węźle głównym rezerwowym.
Główny kontroler trybu failover
Główny kontroler trybu failover działa w obu węzłach głównych. Oba główne kontrolery trybu failover komunikują się z pierwszym kworum zooKeeper w celu nominowania węzła głównego, na którym działają jako aktywny węzeł główny.
Jeśli na przykład główny kontroler trybu failover na węźle głównym 0 wygra wybory, mają miejsce następujące zmiany:
- Węzeł główny 0 staje się aktywny.
- Główny kontroler trybu failover uruchamia serwer Ambari i master-ha-service w węźle głównym 0.
- Drugi główny kontroler trybu failover zatrzymuje serwer Ambari i master-ha-service w węźle głównym 1.
Usługa master-ha-service działa tylko w aktywnym węźle głównym, zatrzymuje usługi HDInsight HA (z wyjątkiem serwera Ambari) w węźle głównym rezerwowym i uruchamia je w aktywnym węźle głównym.
Proces trybu failover
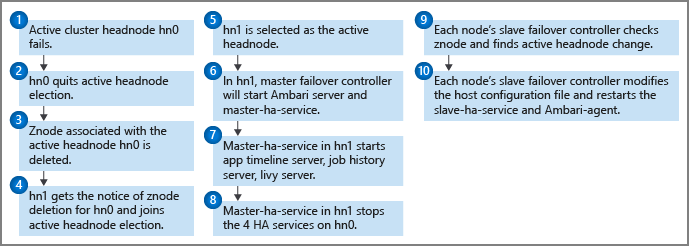
Monitor kondycji jest uruchamiany na każdym węźle głównym wraz z głównym kontrolerem trybu failover w celu wysyłania powiadomień pulsu do kworum zookeeper. W tym scenariuszu węzeł główny jest uważany za usługę wysokiej dostępności. Monitor kondycji sprawdza, czy każda usługa wysokiej dostępności jest w dobrej kondycji i czy jest gotowa dołączyć do wyborów przywódczych. Jeśli tak, ten węzeł główny konkuruje w wyborach. Jeśli nie, rezygnuje z wyborów, dopóki nie stanie się gotowy ponownie.
Jeśli rezerwowy węzeł główny kiedykolwiek osiągnie przywództwo i stanie się aktywny (na przykład w przypadku awarii z poprzednim aktywnym węzłem), jego główny kontroler trybu failover uruchamia wszystkie usługi HDInsight HA na nim. Główny kontroler trybu failover zatrzymuje te usługi w drugim węźle głównym.
W przypadku awarii usługi HDInsight HA, takich jak awaria usługi lub zła kondycja, główny kontroler trybu failover powinien automatycznie ponownie uruchomić lub zatrzymać usługi zgodnie ze stanem węzła głównego. Użytkownicy nie powinni ręcznie uruchamiać usług HDInsight HA w obu węzłach głównych. Zamiast tego zezwól na automatyczne lub ręczne przejście w tryb failover, aby ułatwić odzyskiwanie usługi.
Niezamierzona interwencja ręczna
Usługi WYSOKIEJ dostępności usługi HDInsight powinny być uruchamiane tylko w aktywnym węźle głównym i w razie potrzeby automatycznie uruchamiane ponownie. Ponieważ poszczególne usługi wysokiej dostępności nie mają własnego monitora kondycji, nie można wyzwolić trybu failover na poziomie poszczególnych usług. Tryb failover jest zapewniany na poziomie węzła, a nie na poziomie usługi.
Niektóre znane problemy
Ręczne uruchamianie usługi wysokiej dostępności w węźle głównym rezerwowym nie zostanie zatrzymane, dopóki nie nastąpi następne przejście w tryb failover. Jeśli usługi wysokiej dostępności są uruchomione w obu węzłach głównych, niektóre potencjalne problemy obejmują: interfejs użytkownika systemu Ambari jest niedostępny, system Ambari zgłasza błędy, YARN, Spark i Oozie zadania mogą zostać zablokowane.
Gdy usługa wysokiej dostępności w aktywnym węźle głównym zostanie zatrzymana, nie zostanie uruchomiona ponownie, dopóki nie nastąpi następne przejście w tryb failover lub główny kontroler trybu failover/master-ha-service zostanie ponownie uruchomiony. Gdy co najmniej jedna usługa wysokiej dostępności zostanie zatrzymana w aktywnym węźle głównym, zwłaszcza gdy serwer Ambari zostanie zatrzymany, interfejs użytkownika systemu Ambari jest niedostępny, inne potencjalne problemy obejmują błędy zadań YARN, Spark i Oozie.
Usługi wysokiej dostępności platformy Apache
Platforma Apache zapewnia wysoką dostępność węzłów NameNode systemu plików HDFS, YARN ResourceManager i HBase Master, które są również dostępne w klastrach usługi HDInsight. W przeciwieństwie do usług HDInsight HA są one obsługiwane w klastrach ESP. Usługi Apache HA komunikują się z drugim kworum zooKeeper (opisanym w powyższej sekcji), aby wybrać stany aktywne/rezerwowe i przeprowadzić automatyczne przejście w tryb failover. W poniższych sekcjach opisano sposób działania tych usług.
Węzeł nazw rozproszonego systemu plików Hadoop (HDFS)
Klastry usługi HDInsight oparte na usłudze Apache Hadoop 2.0 lub nowszym zapewniają wysoką dostępność węzła NameNode. W węzłach głównych są uruchomione dwa węzły NameNode, które są skonfigurowane do automatycznego przejścia w tryb failover. Węzły NameNodes używają kontrolera ZKFailoverController do komunikowania się z usługą Zookeeper w celu wybrania stanu aktywne/wstrzymania. Kontroler ZKFailoverController działa w obu węzłach głównych i działa w taki sam sposób jak główny kontroler trybu failover.
Drugi kworum zookeeper jest niezależny od pierwszego kworum, więc aktywny węzeł NameNode może nie działać w aktywnym węźle głównym. Gdy aktywny węzeł NameNode nie działa lub jest w złej kondycji, rezerwowy węzeł NameNode wygrywa wybory i staje się aktywny.
YARN ResourceManager
Klastry usługi HDInsight oparte na usłudze Apache Hadoop 2.4 lub nowszym obsługują wysoką dostępność usługi YARN ResourceManager. Istnieją dwa elementy ResourceManagers, rm1 i rm2, uruchomione odpowiednio w węźle głównym 0 i węźle głównym 1. Podobnie jak NameNode, menedżer zasobów YARN jest również skonfigurowany do automatycznego przejścia w tryb failover. Inny element ResourceManager jest automatycznie wybierany jako aktywny, gdy bieżący aktywny menedżer zasobów ulegnie awarii lub nie odpowiada.
Menedżer zasobów YARN używa osadzonego elementu ActiveStandbyElector jako detektora awarii i selektora lidera. W przeciwieństwie do węzła NameNode systemu plików HDFS, menedżer zasobów usługi YARN nie potrzebuje oddzielnego demona ZKFC. Aktywny element ResourceManager zapisuje swoje stany w usłudze Apache Zookeeper.
Wysoka dostępność menedżera zasobów YARN jest niezależna od węzła NameNode i innych usług WYSOKIEJ dostępności usługi HDInsight. Aktywny element ResourceManager może nie działać w aktywnym węźle głównym lub w węźle głównym, w którym jest uruchomiony aktywny węzeł NameNode. Aby uzyskać więcej informacji na temat wysokiej dostępności YARN ResourceManager, zobacz ResourceManager High Availability (Wysoka dostępność menedżera zasobów).
Wzorzec bazy danych HBase
Klastry HBase usługi HDInsight obsługują wysoką dostępność bazy danych HBase. W przeciwieństwie do innych usług wysokiej dostępności, które działają w węzłach głównych, wzorce HBase działają w trzech węzłach zookeeper, gdzie jeden z nich jest aktywnym serwerem głównym, a pozostałe dwa są w stanie wstrzymania. Podobnie jak NameNode, wzorzec HBase koordynuje się z usługą Apache Zookeeper w celu wyboru lidera i wykonuje automatyczne przejście w tryb failover, gdy bieżący aktywny serwer główny ma problemy. W dowolnym momencie istnieje tylko jeden aktywny wzorzec HBase.
Następne kroki
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla