Przewodnik rozwiązywania problemów z migracją obciążeń Hive z usługi HDInsight 3.6 do usługi HDInsight 4.0
Ten artykuł zawiera odpowiedzi na niektóre z najczęstszych problemów napotykanych przez klientów podczas migrowania obciążeń programu Hive z usługi HDInsight 3.6 do usługi HDInsight 4.0.
Zmniejszanie opóźnienia podczas uruchamiania DESCRIBE TABLE_NAME
Obejście:
Zwiększ maksymalną liczbę obiektów (tabel/partycji), które można pobrać z magazynu metadanych w jednej partii. Ustaw ją na dużą liczbę (wartość domyślna to 300) do momentu osiągnięcia zadowalających poziomów opóźnień. Im większa liczba, tym mniej rund jest potrzebnych do serwera magazynu metadanych Hive, ale może również spowodować wyższe wymaganie dotyczące pamięci po stronie klienta.
hive.metastore.batch.retrieve.max=2000Uruchom ponownie usługę Hive i wszystkie nieaktualne usługi
Nie można wykonać zapytania względem pliku tekstowego Gzipped, jeśli dla tabeli ustawiono parametr skip.header.line.count i skip.footer.line.count
Problem został rozwiązany w zapytaniu interakcyjnym 4.0, ale nadal nie w interakcyjnym zapytaniu 3.1.0
Obejście:
- Utwórz tabelę bez użycia poleceń
"skip.header.line.count"="1"i"skip.footer.line.count"="1", a następnie utwórz widok z oryginalnej tabeli, która wyklucza wiersz nagłówka/stopki w zapytaniu.
Nie można użyć znaków Unicode
Obejście:
Połączenie do bazy danych magazynu metadanych hive dla klastra.
Wykonaj kopię zapasową
TBLStabel iTABLE_PARAMSprzy użyciu następującego polecenia:select * into tbls_bak from tbls; select * into table_params_bak from table_params;Ręcznie zmień typy kolumn, których dotyczy problem, na
nvarchar(max).alter table TABLE_PARAMS alter column PARAM_VALUE nvarchar(max); alter table TBLS alter column VIEW_EXPANDED_TEXT nvarchar(max) null; alter table TBLS alter column VIEW_ORIGINAL_TEXT nvarchar(max) null;
Utwórz tabelę podczas wybierania (CTAS) tworzy nową tabelę z tym samym identyfikatorem UUID
Hive 3.1 (HDInsight 4.0) oferuje wbudowaną funkcję UDF do generowania unikatowych identyfikatorów UUID. Metoda UUID() programu Hive generuje unikatowe identyfikatory nawet w przypadku funkcji CTAS. Można go użyć w następujący sposób.
create table rhive as
select uuid() as UUID
from uuid_test
Format danych wyjściowych zadania Hive różni się od formatu danych wyjściowych zadania hive w usłudze HDInsight 3.6
Jest to spowodowane różnicą między serwerem WebHCat(Templeton) między usługą HDInsight 3.6 i usługą HDInsight 4.0.
Interfejs API REST programu Hive — dodawanie
arg=--showHeader=false -d arg=--outputformat=tsv2 -dZestaw SDK platformy .NET — inicjowanie args of
HiveJobSubmissionParametersList<string> args = new List<string> { { "--showHeader=false" }, { "--outputformat=tsv2" } }; var parameters = new HiveJobSubmissionParameters { Query = "SELECT clientid,market from hivesampletable LIMIT 10", Defines = defines, Arguments = args };
Zmniejszanie opóźnienia tworzenia tabeli wewnętrznej programu Hive
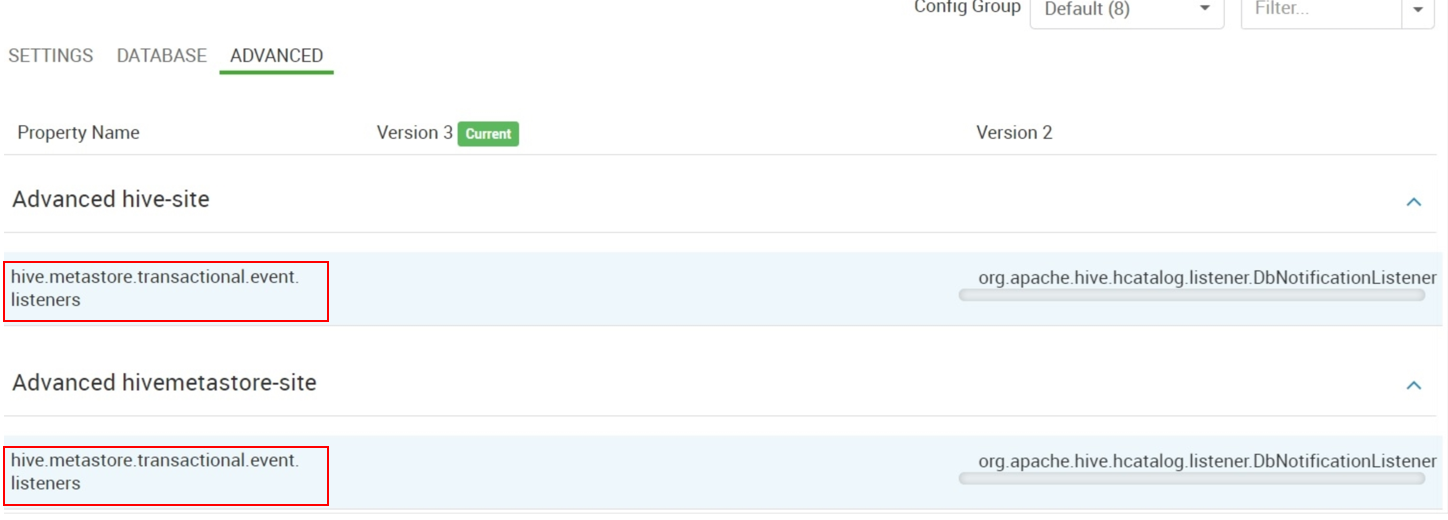
W obszarze Zaawansowane hive-site i Advanced hivemetastore-site usuń wartość
org.apache.hive.hcatalog.listener.DbNotificationListener.hive.metastore.transactional.event.listenersJeśli
hive.metastore.event.listenersma wartość, usuń ją.Element DbNotificationListener jest wymagany tylko wtedy, gdy używasz poleceń REPL, a jeśli nie, można go bezpiecznie usunąć.
Zmienianie domyślnej lokalizacji tabeli programu Hive
Ta zmiana zachowania jest zaprojektowana w usłudze HDInsight 4.0 (Hive 3.1). Główną przyczyną tej zmiany jest kontrola uprawnień do plików.
Aby utworzyć tabele zewnętrzne w lokalizacji niestandardowej, określ lokalizację w instrukcji create table.
Wyłączanie funkcji ACID w usłudze HDInsight 4.0
Zalecamy włączenie funkcji ACID w usłudze HDInsight 4.0. Większość najnowszych ulepszeń, zarówno funkcjonalnych, jak i wydajności, w programie Hive jest dostępna tylko dla tabel ACID.
Kroki wyłączania acid w usłudze HDInsight 4.0:
Zmień następujące konfiguracje gałęzi w systemie Ambari:
hive.strict.managed.tables=false hive.support.concurrency=false; hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DummyTxnManager; hive.enforce.bucketing=false; hive.compactor.initiator.on=false; hive.compactor.worker.threads=0; hive.create.as.insert.only=false; metastore.create.as.acid=false;
Uwaga
Jeśli właściwość hive.strict.managed.tables jest ustawiona na wartość domyślną true<>, tworzenie tabeli zarządzanej i niezwiązanej z transakcjami zakończy się niepowodzeniem z powodu następującego błędu:
java.lang.Exception: java.sql.SQLException: Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. Unable to alter table. Table <Table name> failed strict managed table checks due to the following reason: Table is marked as a managed table but is not transactional.
- Uruchom ponownie usługę hive.
Ważne
Firma Microsoft zaleca udostępnianie tych samych danych/magazynu przy użyciu tabel zarządzanych przez usługi HDInsight 3.6 i HDInsight 4.0 Hive. Jest to nieobsługiwany scenariusz.
Zwykle powyższe konfiguracje należy ustawić jeszcze przed utworzeniem wszystkich tabel programu Hive w klastrze usługi HDInsight 4.0. Nie należy wyłączać acid po utworzeniu zarządzanych tabel. Potencjalnie może to spowodować utratę danych lub niespójne wyniki. Dlatego zaleca się skonfigurowanie go raz podczas tworzenia nowego klastra i nie zmieniania go później.
Wyłączenie funkcji ACID po utworzeniu tabel jest ryzykowne, jednak jeśli chcesz to zrobić, wykonaj poniższe kroki, aby uniknąć potencjalnej utraty lub niespójności danych:
- Utwórz tabelę zewnętrzną z tym samym schematem i skopiuj dane z oryginalnej tabeli zarządzanej przy użyciu polecenia
create external table e_t1 select * from m_t1CTAS . - Upuść zarządzaną tabelę przy użyciu polecenia
drop table m_t1. - Wyłącz metodę ACID przy użyciu sugerowanych konfiguracji.
- Utwórz ponownie m_t1 i skopiuj dane z tabeli zewnętrznej przy użyciu polecenia
create table m_t1 select * from e_t1CTAS . - Upuść tabelę zewnętrzną przy użyciu polecenia
drop table e_t1.
- Utwórz tabelę zewnętrzną z tym samym schematem i skopiuj dane z oryginalnej tabeli zarządzanej przy użyciu polecenia
Przed wyłączeniem funkcji ACID upewnij się, że wszystkie tabele zarządzane są konwertowane na tabele zewnętrzne i porzucane. Porównaj również schemat i dane po każdym kroku, aby uniknąć rozbieżności.
Tworzenie tabeli zewnętrznej programu Hive z uprawnieniami 755
Ten problem można rozwiązać za pomocą jednej z następujących dwóch opcji:
Ręcznie ustaw uprawnienie do folderu 757 lub 777, aby umożliwić użytkownikowi hive zapisywanie w katalogu.
Zmień wartość "Menedżer autoryzacji programu Hive" z
org.apache.hadoop.hive.ql.security.authorization.StorageBasedAuthorizationProvidernaorg.apache.hadoop.hive.ql.security.authorization.MetaStoreAuthzAPIAuthorizerEmbedOnly.
MetaStoreAuthzAPIAuthorizerEmbedOnly skutecznie wyłącza sprawdzanie zabezpieczeń, ponieważ magazyn metadanych Hive nie jest osadzony w usłudze HDInsight 4.0. Może to jednak spowodować inne potencjalne problemy. Zachowaj ostrożność podczas korzystania z tej opcji.
Błędy uprawnień w zadaniu hive po uaktualnieniu do usługi HDInsight 4.0
W usłudze HDInsight 4.0 wszystkie kształty klastra ze składnikami programu Hive są konfigurowane przy użyciu nowego dostawcy autoryzacji:
org.apache.hadoop.hive.ql.security.authorization.StorageBasedAuthorizationProviderUprawnienia do plików HDFS należy przypisać do użytkownika hive w celu uzyskania dostępu do pliku. Komunikat o błędzie zawiera szczegółowe informacje potrzebne do rozwiązania problemu.
Możesz również przełączyć się na dostawcę
MetaStoreAuthzAPIAuthorizerEmbedOnlyużywanego w klastrach Hive usługi HDInsight 3.6.org.apache.hadoop.hive.ql.security.authorization.MetaStoreAuthzAPIAuthorizerEmbedOnly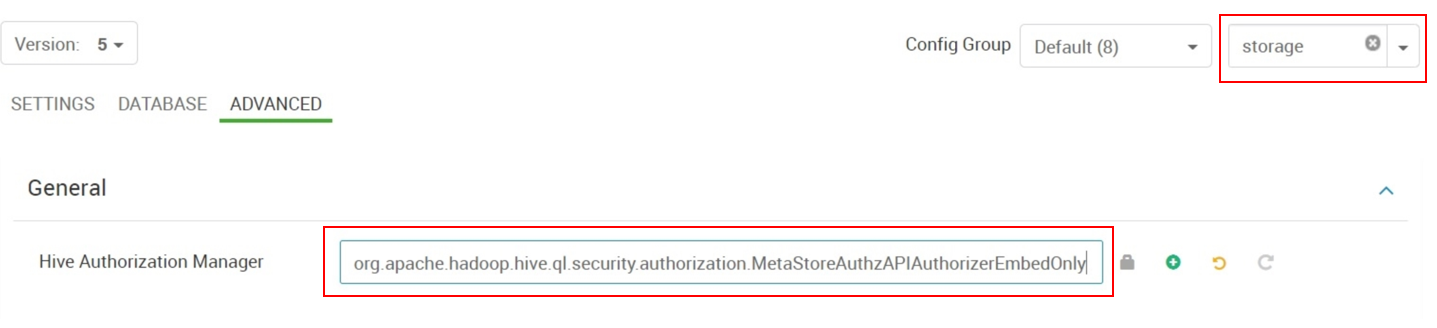
Nie można wykonać kwerendy w tabeli za pomocą interfejsu OpenCSVSerde
Odczytywanie danych z csv tabeli formatu może zgłaszać wyjątek, na przykład:
MetaException(message:java.lang.UnsupportedOperationException: Storage schema reading not supported)
Obejście:
Dodawanie konfiguracji
metastore.storage.schema.reader.impl=org.apache.hadoop.hive.metastore.SerDeStorageSchemaReaderzaCustom hive-sitepośrednictwem interfejsu użytkownika systemu AmbariUruchom ponownie wszystkie nieaktualne usługi hive
Następne kroki
Jeśli problem nie został wyświetlony lub nie możesz go rozwiązać, odwiedź jeden z następujących kanałów, aby uzyskać więcej pomocy technicznej:
Uzyskaj odpowiedzi od ekspertów platformy Azure za pośrednictwem pomocy technicznej społeczności platformy Azure.
Połączenie za pomocą @AzureSupport — oficjalne konto platformy Microsoft Azure w celu poprawy jakości obsługi klienta. Połączenie społeczności platformy Azure do odpowiednich zasobów: odpowiedzi, pomocy technicznej i ekspertów.
Jeśli potrzebujesz dodatkowej pomocy, możesz przesłać wniosek o pomoc techniczną w witrynie Azure Portal. Wybierz pozycję Pomoc techniczna na pasku menu lub otwórz centrum Pomoc i obsługa techniczna . Aby uzyskać bardziej szczegółowe informacje, zobacz How to create an pomoc techniczna platformy Azure request (Jak utworzyć żądanie pomoc techniczna platformy Azure). Dostęp do pomocy technicznej dotyczącej zarządzania subskrypcjami i rozliczeniami jest oferowany w ramach subskrypcji platformy Microsoft Azure, a pomoc techniczna jest świadczona w ramach jednego z planów pomocy technicznej platformy Azure.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla