Zwiększanie wydajności obciążeń platformy Apache Spark przy użyciu pamięci podręcznej we/wy usługi Azure HDInsight
Uwaga
- Pamięć podręczna we/wy była obsługiwana do wersji Spark 2.3 i nie będzie obsługiwana na platformie Spark 2.4 (HDInsight 4.0) i spark 3.1.2 (HDInsight 5.0)
Pamięć podręczna we/wy to usługa buforowania danych dla usługi Azure HDInsight, która poprawia wydajność zadań platformy Apache Spark. Pamięć podręczna we/wy współpracuje również z obciążeniami Apache TEZ i Apache Hive , które można uruchamiać w klastrach Platformy Apache Spark . Usługa IO Cache używa składnika buforowania typu open source o nazwie RubiX. RubiX to lokalna pamięć podręczna dysku do użycia z aparatami analizy danych big data, które uzyskują dostęp do danych z systemów magazynowania w chmurze. Język RubiX jest unikatowy wśród systemów buforowania, ponieważ używa dysków półprzewodnikowych (SSD), a nie rezerwuje pamięci operacyjnej na potrzeby buforowania. Usługa IO Cache uruchamia serwery metadanych RubiX i zarządza nimi w każdym węźle roboczym klastra. Konfiguruje również wszystkie usługi klastra pod kątem przezroczystego użycia pamięci podręcznej RubiX.
Większość dysków SSD zapewnia więcej niż 1 GByte na sekundę przepustowości. Ta przepustowość, uzupełniona przez pamięć podręczną plików systemu operacyjnego, zapewnia wystarczającą przepustowość do ładowania aparatów przetwarzania danych big data, takich jak Apache Spark. Pamięć operacyjna jest dostępna dla platformy Apache Spark w celu przetwarzania zadań zależnych od pamięci, takich jak tasy. Korzystanie wyłącznie z pamięci operacyjnej umożliwia platformie Apache Spark osiągnięcie optymalnego użycia zasobów.
Uwaga
Pamięć podręczna we/wy obecnie używa języka RubiX jako składnika buforowania, ale może to ulec zmianie w przyszłych wersjach usługi. Użyj interfejsów IO Cache i nie używaj żadnych zależności bezpośrednio w implementacji języka RubiX. Pamięć podręczna we/wy jest obecnie obsługiwana tylko w usłudze Azure BLOB Storage.
Zalety pamięci podręcznej we/wy usługi Azure HDInsight
Użycie pamięci podręcznej we/wy zapewnia wzrost wydajności zadań odczytujących dane z usługi Azure Blob Storage.
Nie musisz wprowadzać żadnych zmian w zadaniach platformy Spark, aby zobaczyć wzrost wydajności podczas korzystania z pamięci podręcznej we/wy. Gdy pamięć podręczna we/wy jest wyłączona, ten kod platformy Spark odczytuje dane zdalnie z usługi Azure Blob Storage: spark.read.load('wasbs:///myfolder/data.parquet').count(). Po aktywowaniu pamięci podręcznej we/wy ten sam wiersz kodu powoduje buforowany odczyt za pośrednictwem pamięci podręcznej we/wy. Podczas poniższych operacji odczytu dane są odczytywane lokalnie z dysku SSD. Węzły robocze w klastrze usługi HDInsight są wyposażone w lokalnie dołączone dedykowane dyski SSD. Pamięć podręczna we/wy usługi HDInsight używa tych lokalnych dysków SSD do buforowania, co zapewnia najniższy poziom opóźnienia i maksymalizuje przepustowość.
Wprowadzenie
Usługa Azure HDInsight IO Cache jest domyślnie dezaktywowana w wersji zapoznawczej. Pamięć podręczna we/wy jest dostępna w klastrach Platformy Spark w usłudze Azure HDInsight 3.6 lub nowszym, które uruchamiają platformę Apache Spark 2.3. Aby aktywować pamięć podręczną we/wy w usłudze HDInsight 4.0, wykonaj następujące kroki:
W przeglądarce internetowej przejdź do
https://CLUSTERNAME.azurehdinsight.netlokalizacji , gdzieCLUSTERNAMEjest nazwą klastra.Wybierz usługę IO Cache po lewej stronie.
Wybierz pozycję Akcje (akcje usługi w usłudze HDI 3.6) i aktywuj.
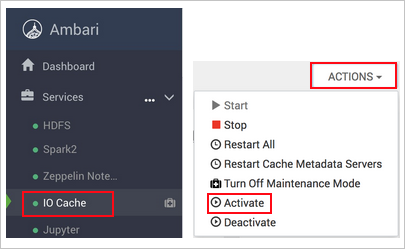
Potwierdź ponowne uruchomienie wszystkich usług, których dotyczy problem w klastrze.
Uwaga
Mimo że pasek postępu jest wyświetlany jako aktywowany, pamięć podręczna we/wy nie jest w rzeczywistości włączona do momentu ponownego uruchomienia innych usług, których dotyczy problem.
Rozwiązywanie problemów
Błędy miejsca na dysku podczas uruchamiania zadań platformy Spark mogą wystąpić po włączeniu pamięci podręcznej we/wy. Te błędy występują, ponieważ platforma Spark używa również magazynu na dysku lokalnym do przechowywania danych podczas operacji mieszania. Platforma Spark może zabrakło miejsca na dysku SSD po włączeniu pamięci podręcznej we/wy i zmniejszeniu miejsca na magazyn Spark. Ilość miejsca używanego przez pamięć podręczną we/wy domyślnie wynosi połowę całkowitego miejsca na dysku SSD. Użycie miejsca na dysku dla pamięci podręcznej we/wy można skonfigurować w systemie Ambari. Jeśli wystąpią błędy miejsca na dysku, zmniejsz ilość miejsca na dysku używanego na potrzeby pamięci podręcznej we/wy i uruchom ponownie usługę. Aby zmienić zestaw miejsca dla pamięci podręcznej we/wy, wykonaj następujące kroki:
W systemie Apache Ambari wybierz usługę HDFS po lewej stronie.
Wybierz karty Konfiguracje i Zaawansowane.
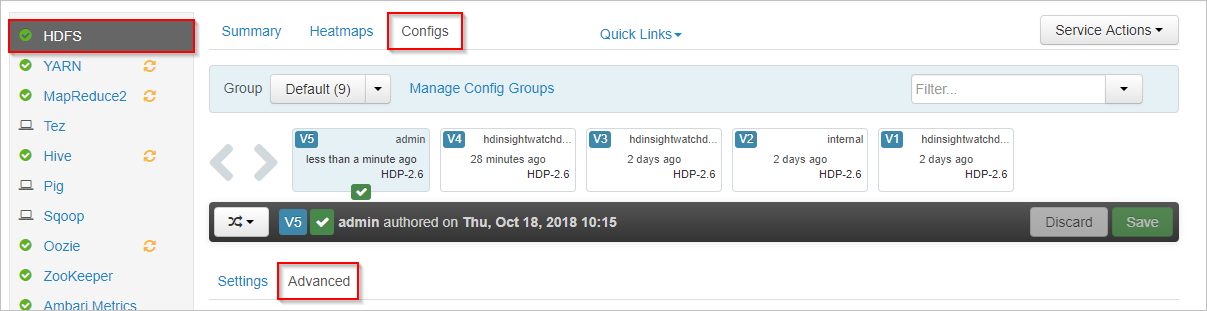
Przewiń w dół i rozwiń obszar Niestandardowe lokacje rdzenia.
Znajdź właściwość hadoop.cache.data.fullness.percentage.
Zmień wartość w polu .
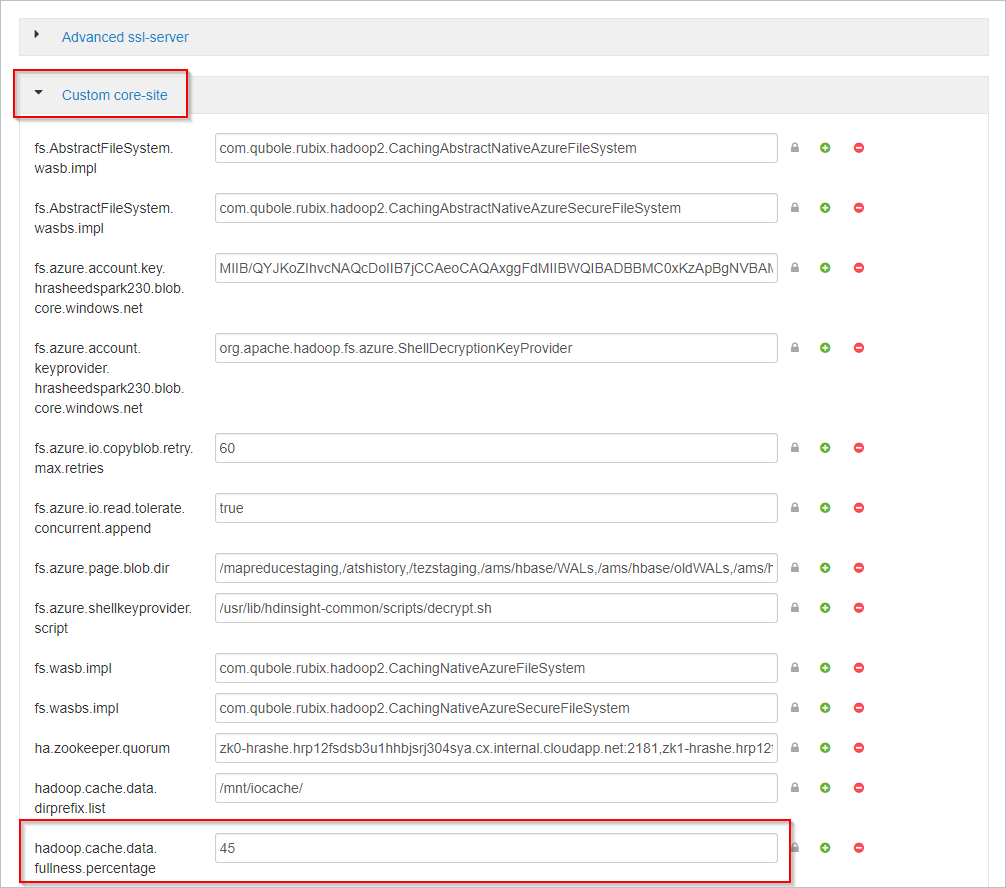
Wybierz pozycję Zapisz w prawym górnym rogu.
Wybierz pozycję Uruchom ponownie>ponownie wszystkie, których dotyczy problem.

Wybierz pozycję Potwierdź ponowne uruchomienie wszystkich.
Jeśli to nie zadziała, wyłącz pamięć podręczną we/wy.
Następne kroki
Przeczytaj więcej na temat pamięci podręcznej we/wy, w tym testów porównawczych wydajności w tym wpisie w blogu: Zadania platformy Apache Spark zyskują maksymalnie 9-krotną szybkość dzięki pamięci podręcznej we/wy usługi HDInsight