Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Przesyłanie strumieniowe platformy Apache Spark umożliwia implementowanie skalowalnych, odpornych na błędy aplikacji do przetwarzania strumieni danych o wysokiej przepływności. Aplikacje spark streaming można połączyć w klastrze HDInsight Spark z różnymi rodzajami źródeł danych, takimi jak Azure Event Hubs, Azure IoT Hub, Apache Kafka, Apache Flume, X, ZeroMQ, raw TCP sockets lub monitorując system plików Apache Hadoop HDFS pod kątem zmian. Przesyłanie strumieniowe Spark zapewnia odporność na uszkodzenia, gwarantując, że każde zdarzenie jest przetwarzane dokładnie raz, nawet w przypadku awarii węzła.
Spark Streaming tworzy długotrwałe zadania, w których można zastosować przekształcenia do danych, a następnie przekazywać wyniki do systemów plików, baz danych, pulpitów nawigacyjnych i konsoli. Przesyłanie strumieniowe platformy Spark przetwarza mikrobatchy danych, najpierw zbierając dane zdarzeń w zdefiniowanym przedziale czasu. Następnie ta partia jest wysyłana do przetwarzania i produkcji. Interwały czasu wsadowego są zwykle definiowane w ułamkach sekundy.

DStreams
Spark Streaming reprezentuje ciągły strumień danych przy użyciu zdykretyzowanego strumienia (DStream). Ten strumień DStream można utworzyć na podstawie źródeł wejściowych, takich jak Event Hubs lub Kafka, albo stosując przekształcenia w innym strumieniu DStream. Po nadejściu zdarzenia do aplikacji Spark Streaming zdarzenie jest przechowywane w niezawodny sposób. Oznacza to, że dane zdarzenia są replikowane, aby wiele węzłów miało kopię. Dzięki temu awaria żadnego pojedynczego węzła nie spowoduje utraty zdarzenia.
Rdzenie platformy Spark używają odpornych rozproszonych zestawów danych (RDD). RDD dystrybuują dane między wieloma węzłami w klastrze, gdzie każdy węzeł zwykle przechowuje swoje dane całkowicie w pamięci, aby uzyskać najlepszą wydajność. Każdy RDD reprezentuje zdarzenia zbierane w interwałach wsadowych. Po upływie interwału wsadowego usługa Spark Streaming generuje nowy RDD, zawierający wszystkie dane z tego interwału. Ten ciągły zestaw RDD jest zbierany do strumienia DStream. Aplikacja Spark Streaming przetwarza dane przechowywane w RDD dla każdej partii.

Zadania przesyłania strumieniowego ze strukturą platformy Spark
Strukturalne Przesyłanie Strumieniowe Spark zostało wprowadzone w Spark 2.0 jako silnik analityczny do analiz danych strumieniowych o ustrukturyzowanej formie. Interfejsy API aparatu przetwarzania wsadowego SparkSQL są używane przez Spark Structured Streaming. Podobnie jak w przypadku Spark Streaming, strukturalne przesyłanie strumieniowe Spark uruchamia obliczenia na stale przybywających mikropartiach danych. Przesyłanie strumieniowe w ramach struktury Spark reprezentuje strumień danych jako tabela wejściowa zawierająca nieograniczoną liczbę wierszy. Oznacza to, że tabela wejściowa nadal rośnie wraz z nadejściem nowych danych. Ta tabela wejściowa jest stale przetwarzana przez długotrwałe zapytanie, a wyniki są zapisywane w tabeli wyjściowej.
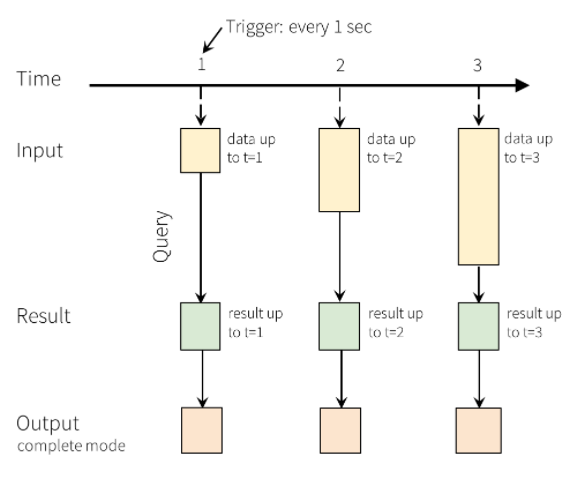
W strumieniowaniu strukturalnym dane docierają do systemu i są natychmiast wprowadzane do tabeli wejściowej. Piszesz zapytania, które wykonują operacje na tej tabeli wejściowej. Dane wyjściowe zapytania dają kolejną tabelę o nazwie Tabela wyników. Tabela Wyników zawiera wyniki zapytania, z którego pobierasz dane do wysyłania do zewnętrznego magazynu danych, takiego jak relacyjna baza danych. Interwał wyzwalacza określa czas przetwarzania danych z tabeli wejściowej. Domyślnie przesyłanie strumieniowe ze strukturą przetwarza dane natychmiast po ich nadejściu. Można jednak również skonfigurować wyzwalacz do uruchamiania w dłuższym interwale, więc dane przesyłane strumieniowo są przetwarzane w partiach opartych na czasie. Dane w tabeli wyników mogą się odświeżać za każdym razem, gdy pojawiają się nowe dane, tak aby zawierały wszystkie dane wyjściowe od momentu rozpoczęcia zapytania strumieniowego (tryb pełny) lub mogą zawierać tylko dane, które są nowe od czasu ostatniego przetworzenia zapytania (tryb dołączania).
Tworzenie odpornych na błędy zadań w strumieniowym przetwarzaniu danych za pomocą Spark.
Aby utworzyć środowisko o wysokiej dostępności dla zadań przesyłania strumieniowego platformy Spark, zacznij od kodowania poszczególnych zadań na potrzeby odzyskiwania w przypadku awarii. Takie samoodzyskiwujące się zadania są odporne na uszkodzenia.
RDD mają kilka właściwości, które pomagają w zadaniach przesyłania strumieniowego Spark o wysokiej dostępności i odporności na awarie.
- Partie danych wejściowych przechowywanych w RDD jako strumień DStream są automatycznie replikowane w pamięci w celu zapewnienia odporności na uszkodzenia.
- Dane utracone z powodu awarii procesu roboczego można ponownie skompilować z replikowanych danych wejściowych dla różnych procesów roboczych, o ile te węzły robocze są dostępne.
- Szybkie odzyskiwanie błędów może wystąpić w ciągu jednej sekundy, ponieważ odzyskiwanie z błędów/maruderów odbywa się za pośrednictwem obliczeń w pamięci.
Semantyka dokładnie raz z użyciem Spark Streaming
Aby utworzyć aplikację, która przetwarza każde zdarzenie raz (i tylko raz), rozważ, jak działają wszystkie punkty ponownego uruchomienia systemu po wystąpieniu problemu i jak można uniknąć utraty danych. Dokładnie raz semantyka wymaga, aby żadne dane nie zostaną utracone w żadnym momencie, a przetwarzanie komunikatów jest możliwe do ponownego uruchomienia, niezależnie od tego, gdzie wystąpi awaria. Zobacz Twórz zadania przesyłania strumieniowego Spark z przetwarzaniem zdarzeń dokładnie jeden raz.
Spark Streaming i Apache Hadoop YARN
W usłudze HDInsight praca klastra jest koordynowana przez jeszcze innego negocjatora zasobów (YARN). Projektowanie wysokiej dostępności na potrzeby przesyłania strumieniowego platformy Spark obejmuje techniki przesyłania strumieniowego platformy Spark, a także dla składników usługi YARN. Poniżej przedstawiono przykładową konfigurację używającą usługi YARN.
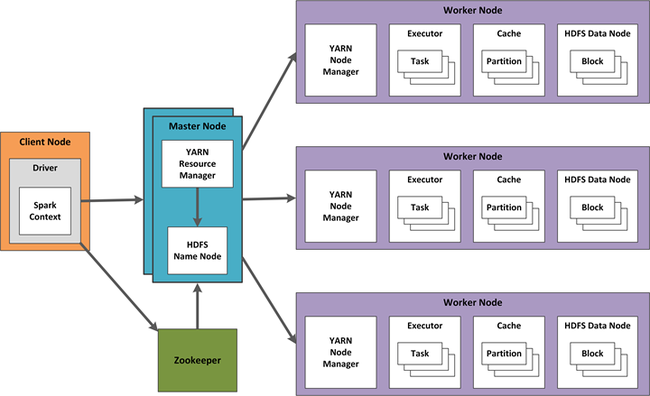
W poniższych sekcjach opisano zagadnienia dotyczące projektowania tej konfiguracji.
Planowanie niepowodzeń
Aby utworzyć konfigurację YARN pod kątem wysokiej dostępności, należy przygotować się na możliwość awarii wykonawcy lub sterownika. Niektóre zadania przesyłania strumieniowego platformy Spark obejmują również wymagania dotyczące gwarancji danych, które wymagają dodatkowej konfiguracji i konfiguracji. Na przykład aplikacja do przesyłania strumieniowego może mieć wymaganie biznesowe dla gwarancji zerowej utraty danych pomimo błędów występujących w systemie hostingu przesyłania strumieniowego lub klastrze usługi HDInsight.
Jeśli funkcja wykonawcza zakończy się niepowodzeniem, jego zadania i odbiorniki są automatycznie uruchamiane przez platformę Spark, więc nie trzeba zmieniać konfiguracji.
Jeśli jednak sterownik ulegnie awarii, wszystkie skojarzone z nim funkcje wykonawcze kończą się niepowodzeniem, a wszystkie odebrane bloki i wyniki obliczeń zostaną utracone. Aby odzyskać sprawność po awarii sterownika, użyj DStream checkpointing zgodnie z opisem w Tworzenie zadań Spark Streaming z dokładnie raz przetwarzanie zdarzeń. Punkt kontrolny DStream okresowo zapisuje skierowany graf acykliczny (DAG) strumieni DStream do magazynu odpornego na błędy, takiego jak usługa Azure Storage. Checkpointing umożliwia Spark Structured Streaming ponowne uruchomienie uszkodzonego sterownika z informacji o punkcie kontrolnym. Ten sterownik ponownie uruchamia nowe funkcje wykonawcze, a także uruchamia ponownie odbiorniki.
Aby odzyskać sterowniki za pomocą punktów kontrolnych DStream:
Skonfiguruj automatyczne ponowne uruchamianie sterownika w usłudze YARN przy użyciu ustawienia
yarn.resourcemanager.am.max-attempts.Ustaw katalog punktu kontrolnego w systemie plików zgodnym z systemem plików HDFS za pomocą polecenia
streamingContext.checkpoint(hdfsDirectory).Zmień strukturę kodu źródłowego, aby używać punktów kontrolnych do odzyskiwania, na przykład:
def creatingFunc() : StreamingContext = { val context = new StreamingContext(...) val lines = KafkaUtils.createStream(...) val words = lines.flatMap(...) ... context.checkpoint(hdfsDir) } val context = StreamingContext.getOrCreate(hdfsDir, creatingFunc) context.start()Skonfiguruj odzyskiwanie utraconych danych, włączając dziennik zapisu z wyprzedzeniem (WAL) z
sparkConf.set("spark.streaming.receiver.writeAheadLog.enable","true")i wyłączając replikację w pamięci dla strumieni wejściowych DStream zStorageLevel.MEMORY_AND_DISK_SER.
Podsumowując, dzięki zastosowaniu punktów kontrolnych, WAL oraz niezawodnych odbiorników, będziesz w stanie zapewnić odzyskiwanie danych z zachowaniem zasady "przynajmniej raz".
- Dokładnie raz, tak długo, jak odebrane dane nie zostaną utracone, a dane wyjściowe są idempotentne lub transakcyjne.
- Dokładnie raz, przy użyciu nowego podejścia platformy Kafka Direct, który używa platformy Kafka jako zreplikowanego dziennika, zamiast używać odbiorników lub list WALS.
Typowe obawy dotyczące wysokiej dostępności
Trudniej jest monitorować zadania przesyłania strumieniowego niż zadania wsadowe. Zadania przesyłania strumieniowego platformy Spark są zwykle długotrwałe, a usługa YARN nie agreguje dzienników do momentu zakończenia zadania. Punkty kontrolne platformy Spark zostaną utracone podczas uaktualniania aplikacji lub platformy Spark i należy wyczyścić katalog punktu kontrolnego podczas uaktualniania.
Skonfiguruj tryb klastra YARN, aby uruchamiać sterowniki, nawet jeśli klient ulegnie awarii. Aby skonfigurować automatyczne ponowne uruchamianie sterowników:
spark.yarn.maxAppAttempts = 2 spark.yarn.am.attemptFailuresValidityInterval=1hSpark i interfejs użytkownika Spark Streaming mają konfigurowalny system metryk. Możesz również użyć dodatkowych bibliotek, takich jak Graphite/Grafana, aby pobrać metryki pulpitu nawigacyjnego, takie jak "liczba przetworzonych rekordów", "użycie pamięci/GC dla sterowników i funkcji wykonawczych", "całkowite opóźnienie", "wykorzystanie klastra" itd. W przypadku przesyłania strumieniowego ze strukturą w wersji 2.1 lub nowszej można użyć
StreamingQueryListenerdo zbierania dodatkowych metryk.Należy podzielić długotrwałe zadania na segmenty. Gdy aplikacja Spark Streaming jest przesyłana do klastra, należy zdefiniować kolejkę usługi YARN, w której jest uruchamiane zadanie. Możesz użyć YARN Capacity Scheduler, aby wysyłać długotrwałe zadania do oddzielnych kolejek.
Bezpiecznie zamknij aplikację do przesyłania strumieniowego. Jeśli przesunięcia są znane, a cały stan aplikacji jest przechowywany zewnętrznie, możesz programowo zatrzymać aplikację przesyłania strumieniowego w odpowiednim miejscu. Jedną z technik jest użycie "haczykowania wątków" na platformie Spark, sprawdzając flagę zewnętrzną co n sekund. Możesz również użyć pliku znacznika, który jest tworzony w systemie plików HDFS podczas uruchamiania aplikacji, a następnie usunięty, gdy chcesz ją zatrzymać. W przypadku podejścia z plikiem wskaźnikowym użyj osobnego wątku w aplikacji Spark, który wywołuje kod podobny do następującego:
streamingContext.stop(stopSparkContext = true, stopGracefully = true) // to be able to recover on restart, store all offsets in an external database
Następne kroki
- Omówienie przesyłania strumieniowego platformy Apache Spark
- Tworzenie zadań przesyłania strumieniowego w Apache Spark z dokładnie jeden raz przetwarzaniem zdarzeń
- Długotrwałe zadania przesyłania strumieniowego platformy Apache Spark w usłudze YARN
- Przesyłanie strumieniowe ze strukturą: semantyka odporna na uszkodzenia
- Zdyretyzowane strumienie: model odporny na uszkodzenia na potrzeby skalowalnego przetwarzania strumienia