Rozwiązywanie problemów z platformą Apache Spark za pomocą usługi Azure HDInsight
Dowiedz się więcej o najważniejszych problemach i ich rozwiązaniach podczas pracy z ładunkami platformy Apache Spark w systemie Apache Ambari.
Jak skonfigurować aplikację platformy Apache Spark za pomocą usługi Apache Ambari w klastrach?
Wartości konfiguracji platformy Spark można dostroić, aby uniknąć wyjątku aplikacji OutofMemoryError platformy Apache Spark. W poniższych krokach przedstawiono domyślne wartości konfiguracji platformy Spark w usłudze Azure HDInsight:
Zaloguj się do systemu Ambari przy
https://CLUSTERNAME.azurehdidnsight.netużyciu poświadczeń klastra. Na ekranie początkowym zostanie wyświetlony pulpit nawigacyjny przeglądu. Istnieją niewielkie różnice kosmetyczne między usługą HDInsight 4.0.Przejdź do pozycji Spark2 Configs (Konfiguracje platformy Spark2>).
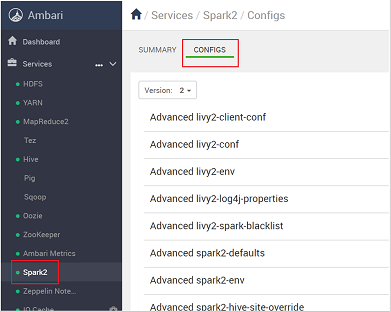
Na liście konfiguracji wybierz i rozwiń węzeł Custom-spark2-defaults.
Poszukaj ustawienia wartości, które należy dostosować, na przykład spark.executor.memory. W tym przypadku wartość 9728m jest zbyt wysoka.
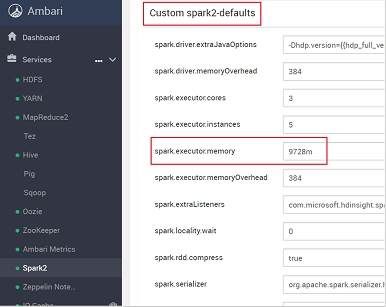
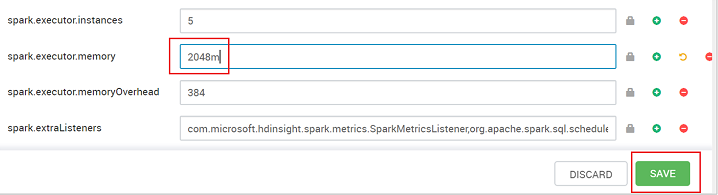
Ustaw wartość na zalecane ustawienie. Wartość 2048m jest zalecana dla tego ustawienia.
Zapisz wartość, a następnie zapisz konfigurację. Wybierz pozycję Zapisz.
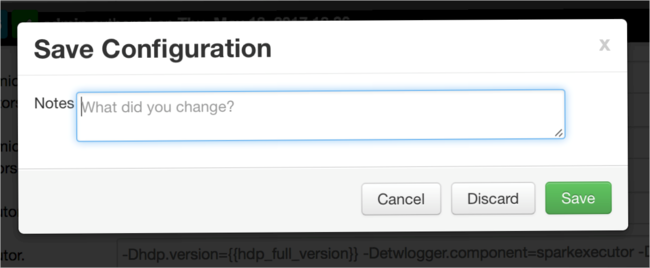
Napisz notatkę dotyczącą zmian konfiguracji, a następnie wybierz pozycję Zapisz.
Jeśli jakiekolwiek konfiguracje wymagają uwagi, otrzymasz powiadomienie. Zanotuj elementy, a następnie wybierz pozycję Kontynuuj mimo to.

Za każdym razem, gdy konfiguracja zostanie zapisana, zostanie wyświetlony monit o ponowne uruchomienie usługi. Wybierz Uruchom ponownie.
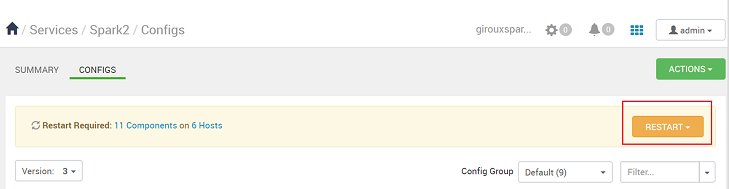
Potwierdź ponowne uruchomienie.
Możesz przejrzeć uruchomione procesy.
Konfiguracje można dodawać. Na liście konfiguracji wybierz pozycję Custom-spark2-defaults, a następnie wybierz pozycję Dodaj właściwość.
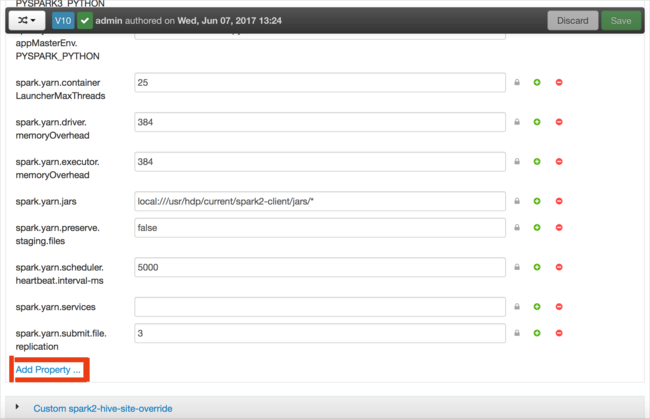
Zdefiniuj nową właściwość. Jedną właściwość można zdefiniować przy użyciu okna dialogowego dla określonych ustawień, takich jak typ danych. Możesz też zdefiniować wiele właściwości przy użyciu jednej definicji na wiersz.
W tym przykładzie właściwość spark.driver.memory jest definiowana z wartością 4g.
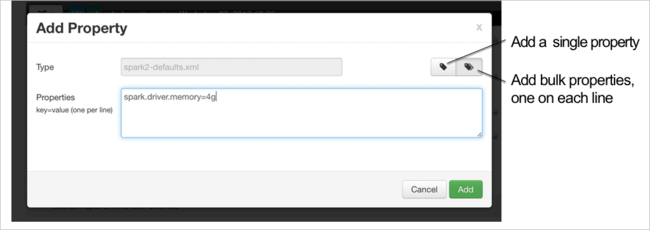
Zapisz konfigurację, a następnie uruchom ponownie usługę zgodnie z opisem w krokach 6 i 7.
Te zmiany są w całym klastrze, ale można je przesłonić podczas przesyłania zadania platformy Spark.
Jak mogę skonfigurować aplikację platformy Apache Spark przy użyciu notesu Jupyter Notebook w klastrach?
W pierwszej komórce notesu Jupyter Po dyrektywie %%configure określ konfiguracje platformy Spark w prawidłowym formacie JSON. Zmień rzeczywiste wartości zgodnie z potrzebami:

Jak skonfigurować aplikację platformy Apache Spark za pomocą usługi Apache Livy w klastrach?
Prześlij aplikację Spark do usługi Livy przy użyciu klienta REST, takiego jak cURL. Użyj polecenia podobnego do poniższego. Zmień rzeczywiste wartości zgodnie z potrzebami:
curl -k --user 'username:password' -v -H 'Content-Type: application/json' -X POST -d '{ "file":"wasb://container@storageaccountname.blob.core.windows.net/example/jars/sparkapplication.jar", "className":"com.microsoft.spark.application", "numExecutors":4, "executorMemory":"4g", "executorCores":2, "driverMemory":"8g", "driverCores":4}'
Jak skonfigurować aplikację platformy Apache Spark za pomocą polecenia spark-submit w klastrach?
Uruchom powłokę spark przy użyciu polecenia podobnego do poniższego. Zmień rzeczywistą wartość konfiguracji w razie potrzeby:
spark-submit --master yarn-cluster --class com.microsoft.spark.application --num-executors 4 --executor-memory 4g --executor-cores 2 --driver-memory 8g --driver-cores 4 /home/user/spark/sparkapplication.jar
Dodatkowe czytanie
Przesyłanie zadania platformy Apache Spark w klastrach usługi HDInsight
Następne kroki
Jeśli problem nie został wyświetlony lub nie możesz go rozwiązać, odwiedź jeden z następujących kanałów, aby uzyskać więcej pomocy technicznej:
Omówienie zarządzania pamięcią platformy Spark.
Debugowanie aplikacji Spark w klastrach usługi HDInsight.
Uzyskaj odpowiedzi od ekspertów platformy Azure za pośrednictwem pomocy technicznej społeczności platformy Azure.
Połączenie za pomocą @AzureSupport — oficjalne konto platformy Microsoft Azure w celu poprawy jakości obsługi klienta. Połączenie społeczności platformy Azure do odpowiednich zasobów: odpowiedzi, pomocy technicznej i ekspertów.
Jeśli potrzebujesz dodatkowej pomocy, możesz przesłać wniosek o pomoc techniczną w witrynie Azure Portal. Wybierz pozycję Pomoc techniczna na pasku menu lub otwórz centrum Pomoc i obsługa techniczna . Aby uzyskać bardziej szczegółowe informacje, zobacz How to create an pomoc techniczna platformy Azure request (Jak utworzyć żądanie pomoc techniczna platformy Azure). Dostęp do pomocy technicznej dotyczącej zarządzania subskrypcjami i rozliczeniami jest oferowany w ramach subskrypcji platformy Microsoft Azure, a pomoc techniczna jest świadczona w ramach jednego z planów pomocy technicznej platformy Azure.