Konfigurowanie zasad platformy Apache Ranger dla usługi Spark SQL w usłudze HDInsight przy użyciu pakietu Enterprise Security
W tym artykule opisano sposób konfigurowania zasad platformy Apache Ranger dla usługi Spark SQL z pakietem Enterprise Security w usłudze HDInsight.
W tym artykule omówiono sposób wykonywania następujących zadań:
- Tworzenie zasad platformy Apache Ranger.
- Sprawdź zastosowane zasady platformy Ranger.
- Stosowanie wytycznych dotyczących ustawiania platformy Apache Ranger dla usługi Spark SQL.
Wymagania wstępne
- Klaster Apache Spark w usłudze HDInsight w wersji 5.1 z pakietem Enterprise Security
Połączenie do interfejsu użytkownika administratora platformy Apache Ranger
W przeglądarce połącz się z interfejsem użytkownika administratora platformy Ranger przy użyciu adresu URL
https://ClusterName.azurehdinsight.net/Ranger/.Zmień
ClusterNamenazwę klastra Spark.Zaloguj się przy użyciu poświadczeń administratora firmy Microsoft Entra. Poświadczenia administratora usługi Microsoft Entra nie są takie same jak poświadczenia klastra usługi HDInsight ani poświadczenia protokołu Secure Shell (SSH) węzła usługi HDInsight systemu Linux.
Tworzenie użytkowników domeny
Aby uzyskać informacje na temat tworzenia sparkuser użytkowników domeny, zobacz Create an HDInsight cluster with ESP (Tworzenie klastra usługi HDInsight przy użyciu esp). W scenariuszu produkcyjnym użytkownicy domeny pochodzą z dzierżawy firmy Microsoft Entra.
Tworzenie zasad platformy Ranger
W tej sekcji utworzysz dwie zasady platformy Ranger:
- Zasady dostępu do uzyskiwania
hivesampletabledostępu z usługi Spark SQL - Zasady maskowania na potrzeby zaciemniania kolumn w
hivesampletable
Tworzenie zasad dostępu platformy Ranger
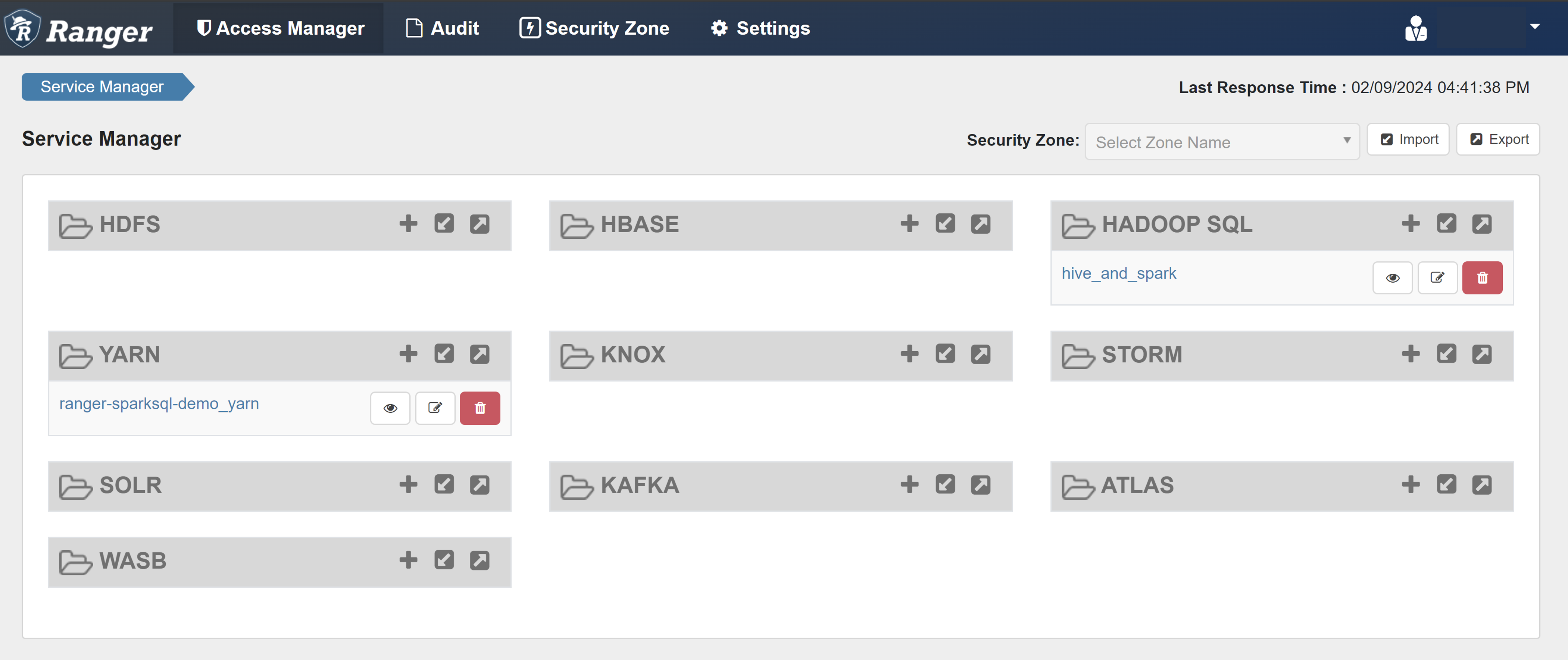
Otwórz interfejs użytkownika administratora platformy Ranger.
W obszarze HADOOP SQL wybierz pozycję hive_and_spark.
Na karcie Dostęp wybierz pozycję Dodaj nowe zasady.
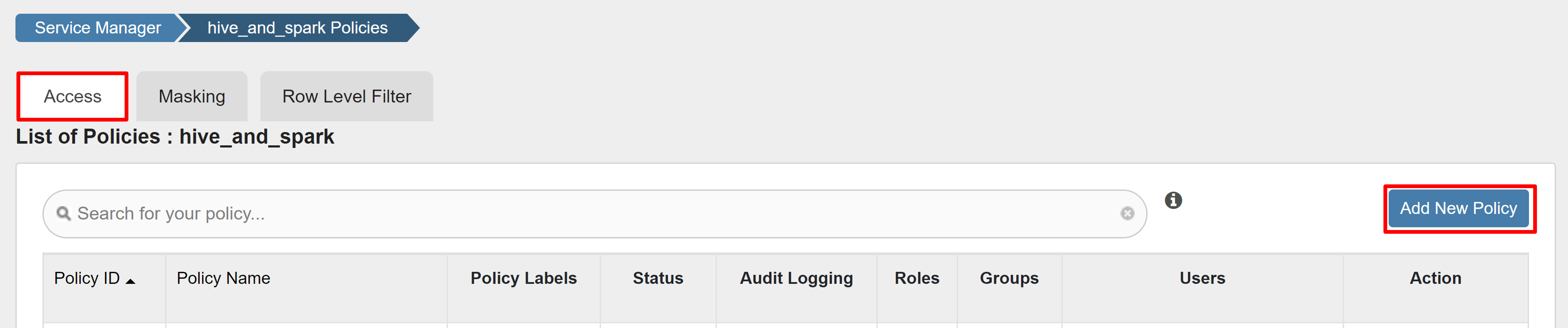
Wprowadź następujące wartości:
Właściwości Wartość Policy Name (Nazwa zasad) read-hivesampletable-all database domyślna table hivesampletable column * Select User (Wybierz użytkownika) sparkuserUprawnienia select 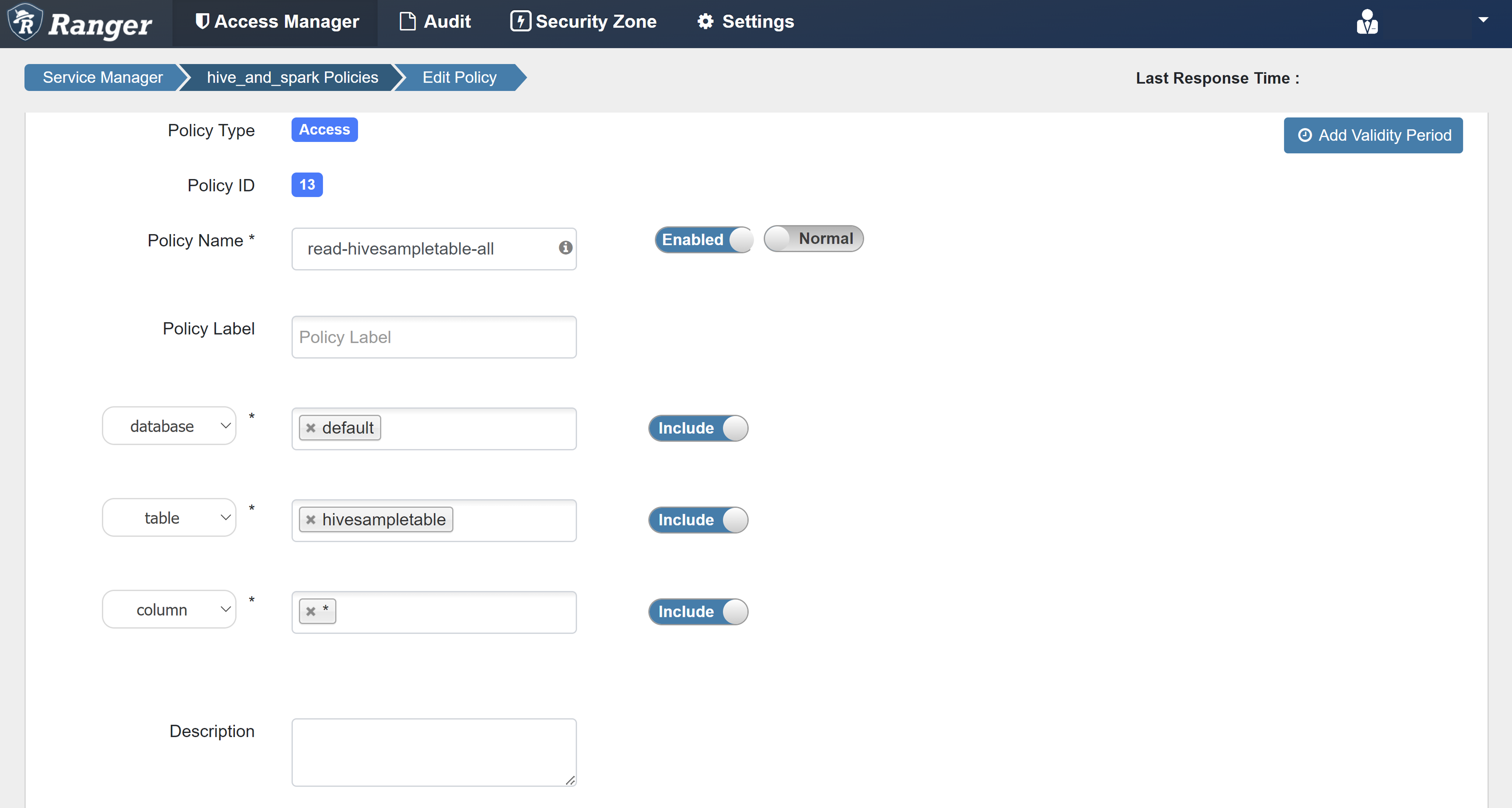
Jeśli użytkownik domeny nie zostanie automatycznie wypełniony dla pozycji Wybierz użytkownika, zaczekaj chwilę na synchronizację platformy Ranger z identyfikatorem Entra firmy Microsoft.
Wybierz pozycję Dodaj , aby zapisać zasady.
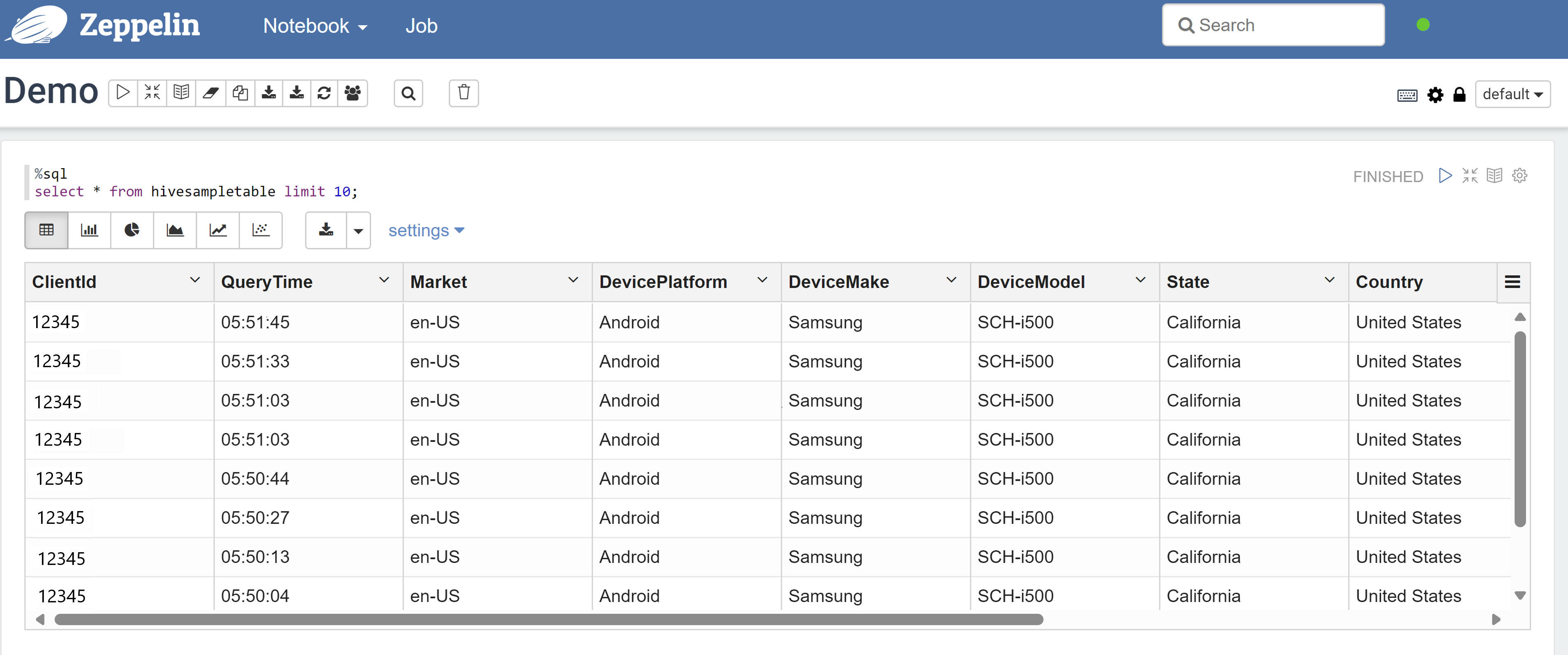
Otwórz notes Zeppelin i uruchom następujące polecenie, aby zweryfikować zasady:
%sql select * from hivesampletable limit 10;Oto wynik przed zastosowaniem zasad:
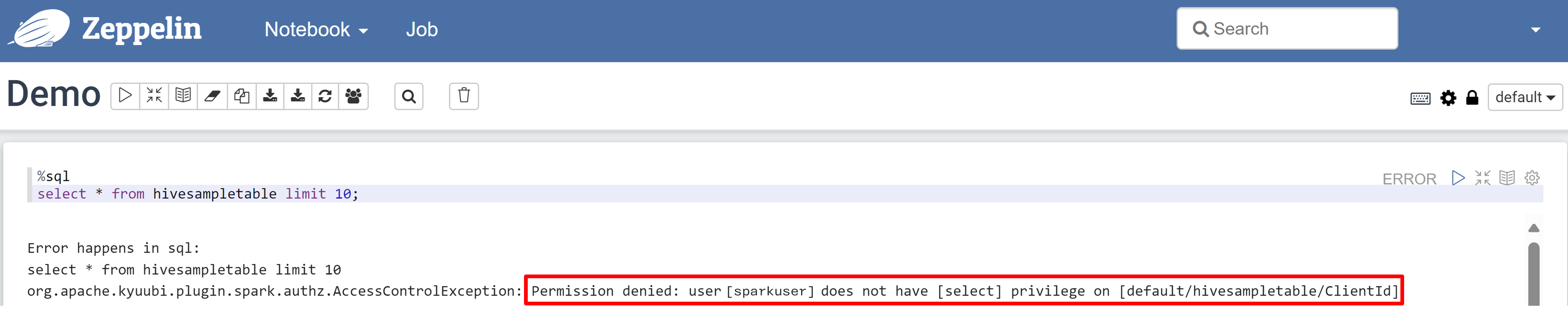
Oto wynik po zastosowaniu zasad:




Tworzenie zasad maskowania platformy Ranger
W poniższym przykładzie pokazano, jak utworzyć zasady maskowania kolumny:
Na karcie Maskowanie wybierz pozycję Dodaj nowe zasady.
Wprowadź następujące wartości:
Właściwości Wartość Policy Name (Nazwa zasad) maska-hivesampletable Baza danych Programu Hive domyślna Tabela Programu Hive hivesampletable Kolumna Hive devicemake Select User (Wybierz użytkownika) sparkuserTypy dostępu select Wybieranie opcji maskowania Skrót 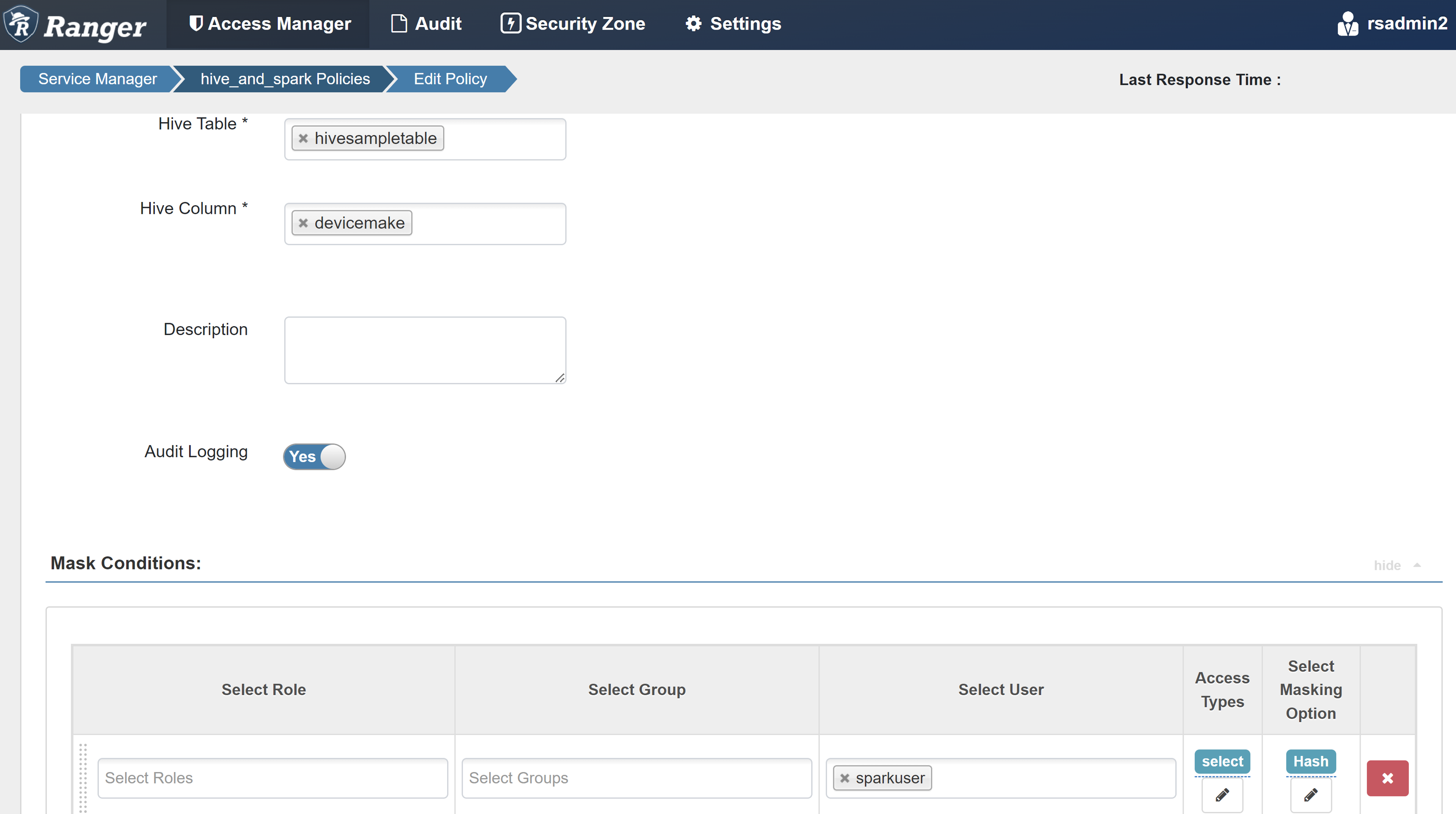
Wybierz pozycję Zapisz , aby zapisać zasady.
Otwórz notes Zeppelin i uruchom następujące polecenie, aby zweryfikować zasady:
%sql select clientId, deviceMake from hivesampletable;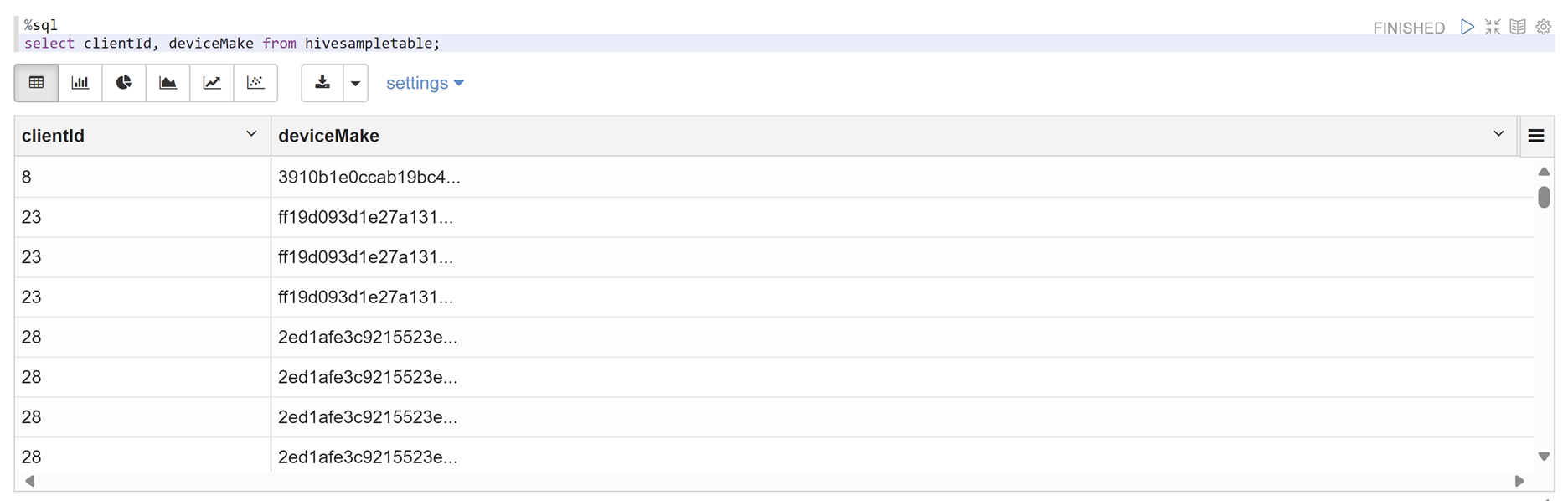



Uwaga
Domyślnie zasady dla programów Hive i Spark SQL są wspólne w usłudze Ranger.
Stosowanie wytycznych dotyczących konfigurowania platformy Apache Ranger dla usługi Spark SQL
W poniższych scenariuszach przedstawiono wskazówki dotyczące tworzenia klastra Spark usługi HDInsight 5.1 przy użyciu nowej bazy danych ranger i istniejącej bazy danych ranger.
Scenariusz 1. Używanie nowej bazy danych Ranger podczas tworzenia klastra Spark usługi HDInsight 5.1
Gdy tworzysz klaster przy użyciu nowej bazy danych Ranger, odpowiednie repozytorium Ranger zawierające zasady platformy Ranger dla programu Hive i platformy Spark jest tworzone pod nazwą hive_and_spark w usłudze Hadoop SQL w bazie danych Ranger.

Jeśli edytujesz zasady, są one stosowane zarówno do programu Hive, jak i platformy Spark.
Rozważ następujące kwestie:
Jeśli masz dwie bazy danych magazynu metadanych o tej samej nazwie używanej dla programu Hive (na przykład DB1) i Spark (na przykład DB1) wykazów:
- Jeśli platforma Spark korzysta z wykazu Spark (
metastore.catalog.default=spark), zasady są stosowane do bazy danych DB1 katalogu Spark. - Jeśli platforma Spark korzysta z katalogu Hive (
metastore.catalog.default=hive), zasady są stosowane do bazy danych DB1 katalogu Hive.
Z perspektywy platformy Ranger nie ma możliwości rozróżnienia między bazami danych DB1 katalogów Hive i Spark.
W takich przypadkach zalecamy:
- Użyj katalogu Hive zarówno dla technologii Hive, jak i Spark.
- Zachowaj różne nazwy baz danych, tabel i kolumn zarówno dla katalogów Hive, jak i Spark, aby zasady nie były stosowane do baz danych między wykazami.
- Jeśli platforma Spark korzysta z wykazu Spark (
Jeśli używasz wykazu hive zarówno dla programu Hive, jak i platformy Spark, rozważ poniższy przykład.
Załóżmy, że utworzysz tabelę o nazwie table1 za pomocą programu Hive z bieżącym użytkownikiem xyz . Tworzy on plik rozproszonego systemu plików Hadoop (HDFS) o nazwie table1.db , którego właścicielem jest użytkownik xyz .
Teraz wyobraź sobie, że używasz użytkownika abc do rozpoczęcia sesji Spark SQL. W tej sesji użytkownika abc, jeśli spróbujesz napisać coś do tabeli table1, jest to powiązane z niepowodzeniem, ponieważ właściciel tabeli jest xyz.
W takim przypadku zalecamy używanie tego samego użytkownika w usługach Hive i Spark SQL do aktualizowania tabeli. Ten użytkownik powinien mieć wystarczające uprawnienia do wykonywania operacji aktualizacji.
Scenariusz 2. Używanie istniejącej bazy danych Ranger (z istniejącymi zasadami) podczas tworzenia klastra Spark usługi HDInsight 5.1
Podczas tworzenia klastra usługi HDInsight 5.1 przy użyciu istniejącej bazy danych ranger na tej bazie danych zostanie ponownie utworzone nowe repozytorium ranger o nazwie nowego klastra w tym formacie: hive_and_spark.

Załóżmy, że masz zasady zdefiniowane w repozytorium Ranger już pod nazwą oldclustername_hive w istniejącej bazie danych Ranger wewnątrz usługi Hadoop SQL. Chcesz udostępnić te same zasady w nowym klastrze spark usługi HDInsight 5.1. Aby osiągnąć ten cel, wykonaj następujące kroki.
Uwaga
Użytkownik, który ma uprawnienia administratora systemu Ambari, może wykonywać aktualizacje konfiguracji.
Otwórz interfejs użytkownika systemu Ambari z nowego klastra usługi HDInsight 5.1.
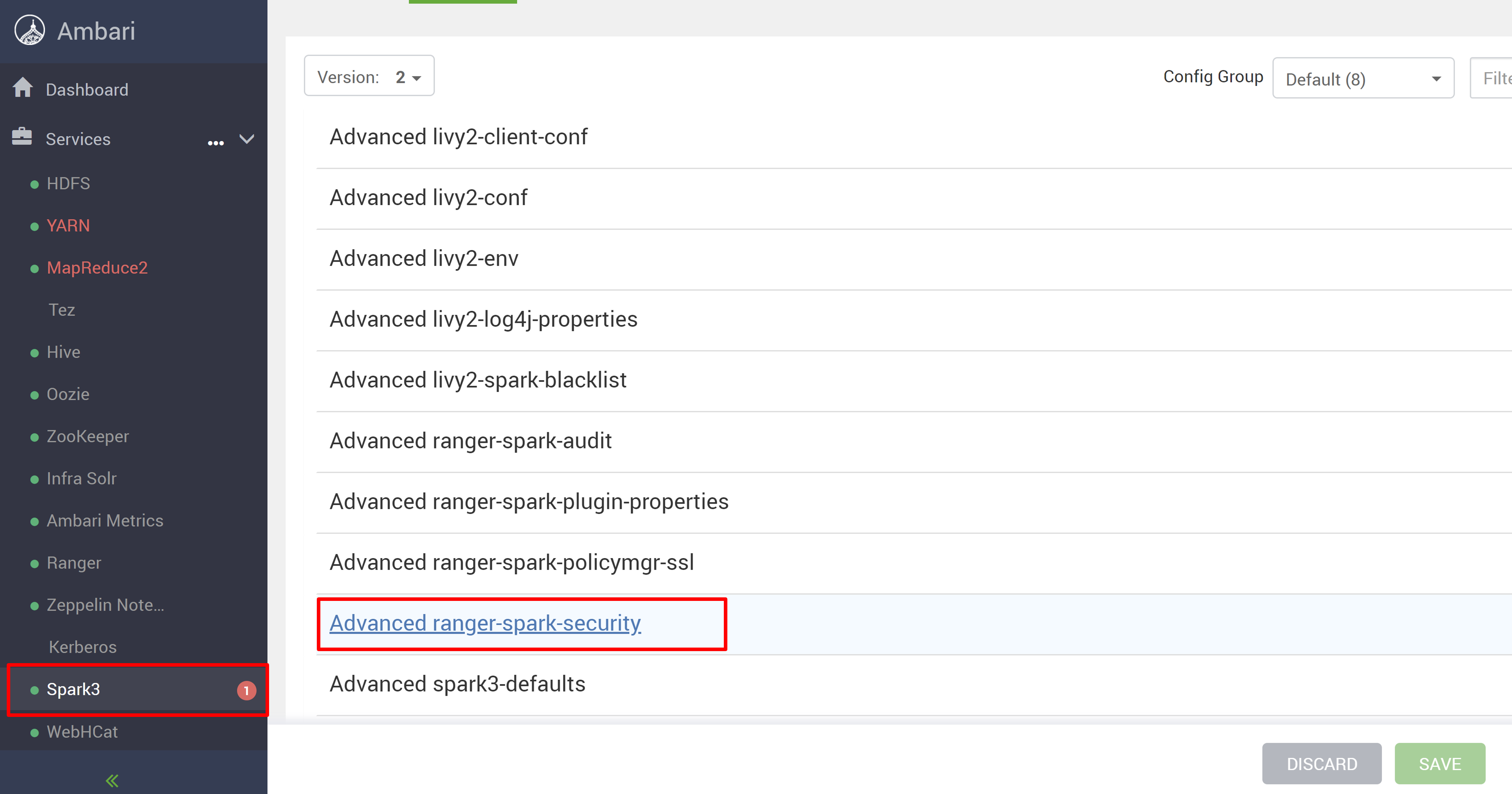
Przejdź do usługi Spark3 , a następnie przejdź do pozycji Konfiguracje.
Otwórz konfigurację Advanced ranger-spark-security .
możesz również otworzyć tę konfigurację w pliku /etc/spark3/conf przy użyciu protokołu SSH.
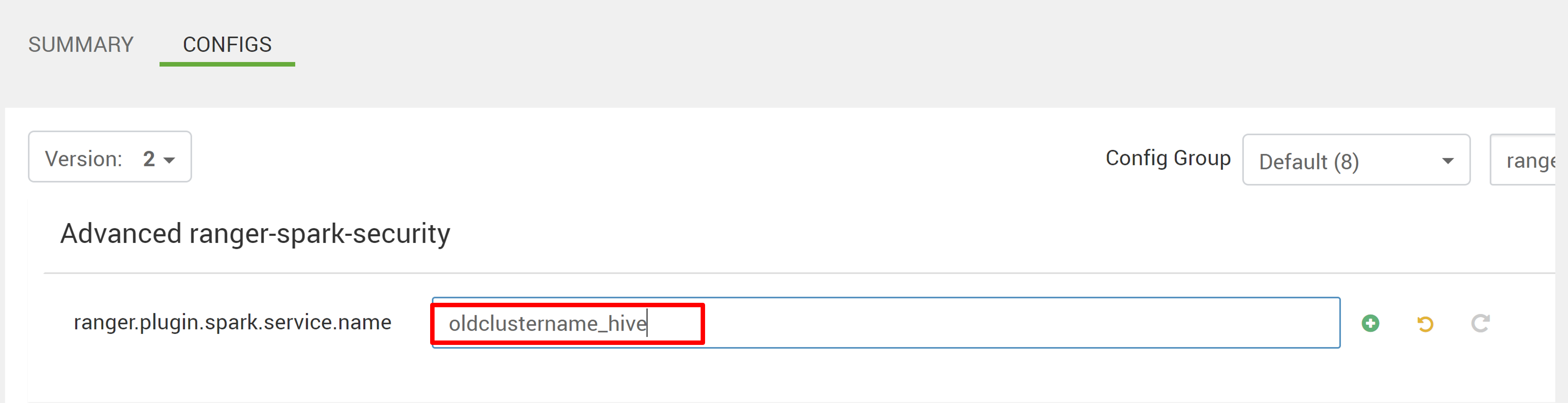
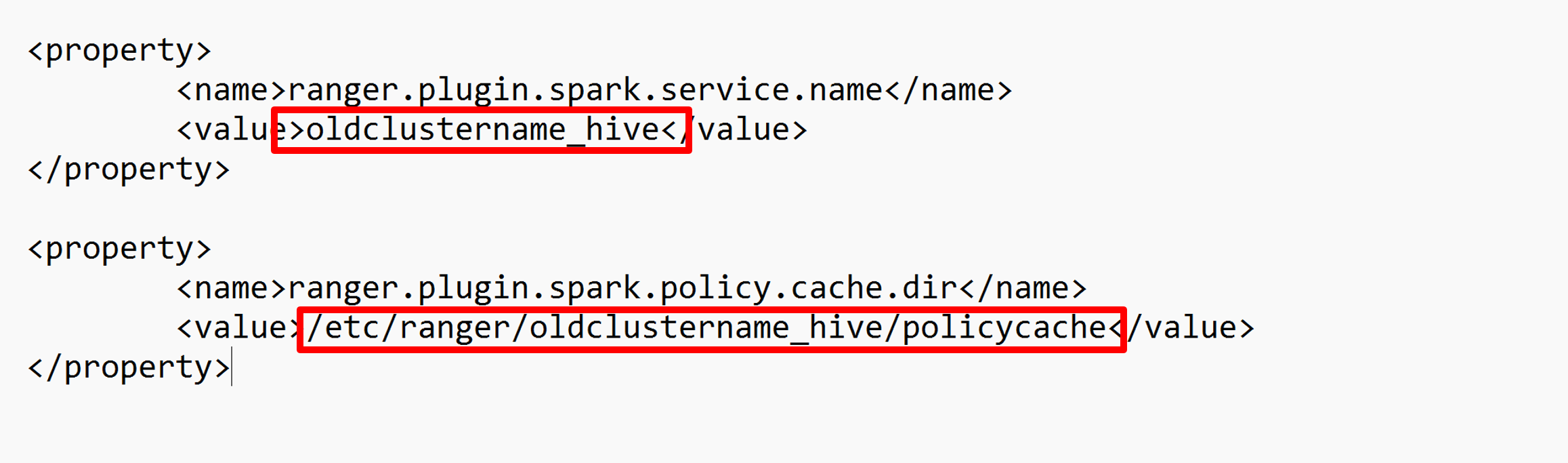
Edytuj dwie konfiguracje (ranger.plugin.spark.service.name i ranger.plugin.spark.policy.cache.dir), aby wskazać stare repozytorium zasad oldclustername_hive, a następnie zapisać konfiguracje.
Ambari:
Plik XML:
Uruchom ponownie usługi Ranger i Spark z poziomu systemu Ambari.
Otwórz interfejs użytkownika administratora platformy Ranger i kliknij przycisk edytuj w usłudze HADOOP SQL .
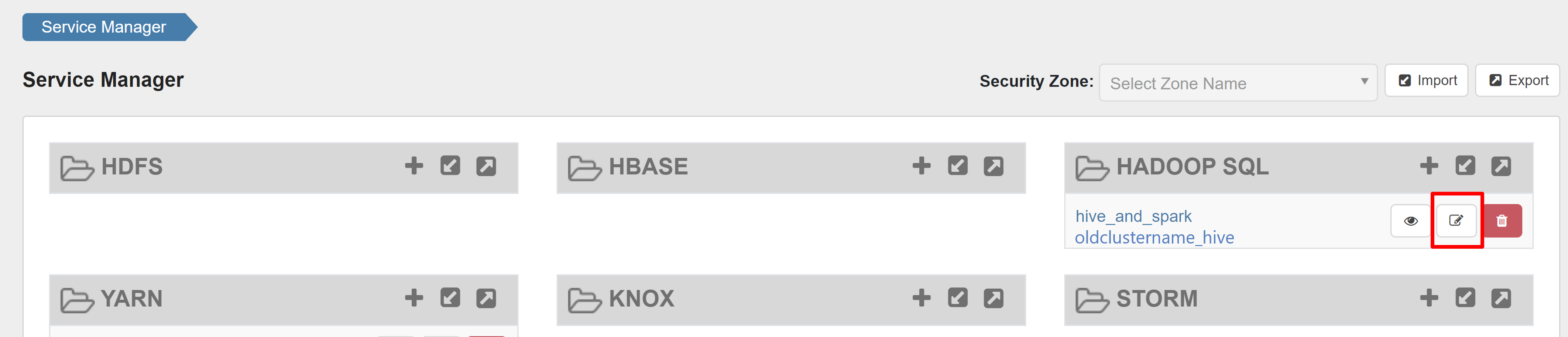
W przypadku usługi oldclustername_hive dodaj użytkownika rangersparklookup w obszarze policy.download.auth.users i tag.download.auth.users i kliknij pozycję Zapisz.






Zasady są stosowane w bazach danych w wykazie platformy Spark. Jeśli chcesz uzyskać dostęp do baz danych w katalogu hive:
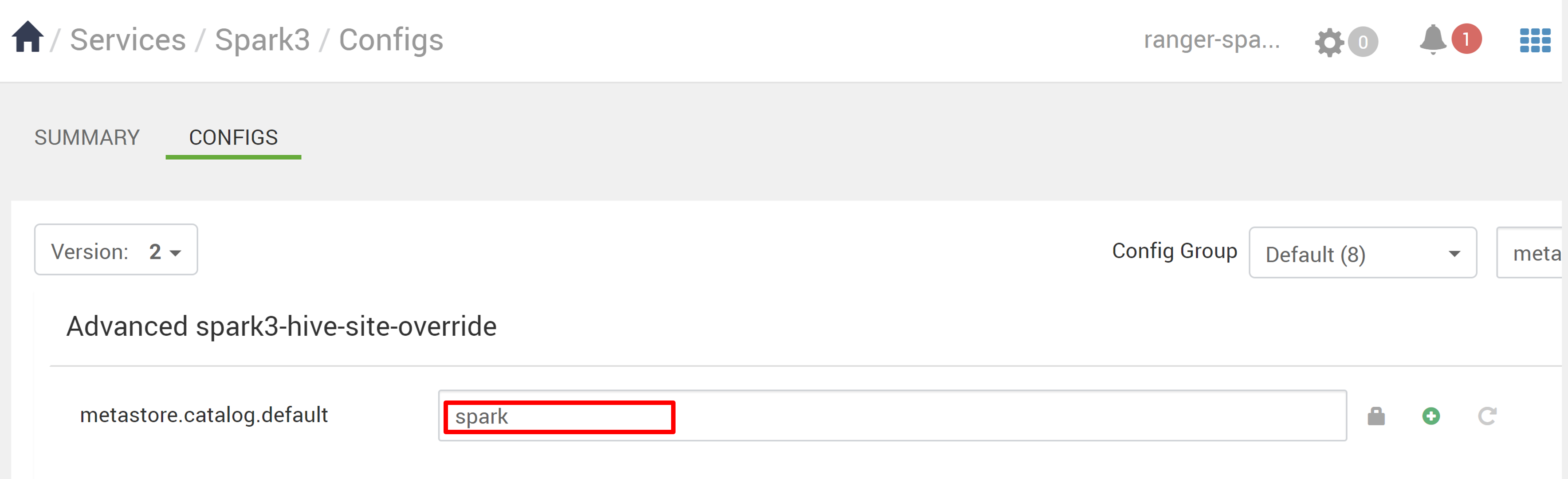
W narzędziu Ambari przejdź do pozycji Spark3 Configs (Konfiguracje platformy Spark3>).
Zmień wartość metastore.catalog.default z platformy Spark na gałąź.

Znane problemy
- Integracja platformy Apache Ranger z usługą Spark SQL nie działa, jeśli administrator platformy Ranger nie działa.
- W dziennikach inspekcji platformy Ranger po umieszczeniu wskaźnika myszy na kolumnie Zasób nie można wyświetlić całego uruchomionego zapytania.