Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dotyczy:![]() IoT Edge 1.5
IoT Edge 1.5
Ważne
Obsługiwana wersja usługi IoT Edge 1.5 LTS. Usługa IoT Edge 1.4 LTS kończy się od 12 listopada 2024 r. Jeśli korzystasz z wcześniejszej wersji, zobacz aktualizację Azure IoT Edge.
W tym artykule poznasz pojęcia i techniki implementowania zarówno wymiarów obserwowaności, jak i monitorowania oraz rozwiązywania problemów. Zapoznaj się z następującymi tematami:
- Definiowanie wskaźników wydajności usługi do monitorowania
- Mierzenie wskaźników wydajności usługi przy użyciu metryk
- Monitorowanie metryk i wykrywanie problemów przy użyciu skoroszytów usługi Azure Monitor
- Rozwiązywanie podstawowych problemów przy użyciu wyselekcjonowanych skoroszytów
- Rozwiązywanie zaawansowanych problemów przy użyciu śledzenia rozproszonego i skorelowanych dzienników
- Opcjonalnie wdróż przykładowy scenariusz na platformie Azure, aby przećwiczyć zdobytą naukę
Scenariusz
Aby wykraczać poza zagadnienia abstrakcyjne, użyjmy rzeczywistego scenariusza, który zbiera temperatury powierzchni oceanu z czujników do usługi Azure IoT.
La Niña
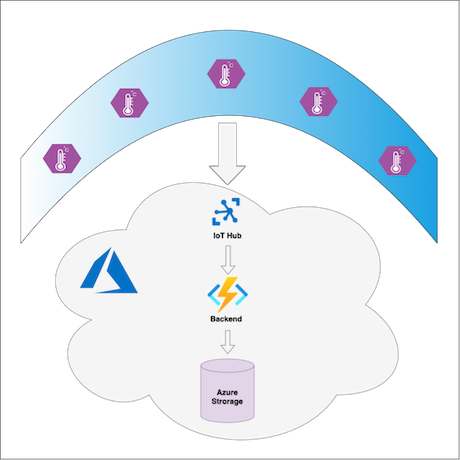
Usługa La Niña mierzy temperaturę powierzchni na Oceanie Spokojnym, aby przewidzieć zimy La Niña. Buoys w oceanie mają urządzenia usługi IoT Edge, które wysyłają dane temperatury powierzchni do chmury platformy Azure. Moduł niestandardowy na każdym urządzeniu usługi IoT Edge wstępnie przetwarza dane telemetryczne przed wysłaniem ich do chmury. W chmurze zaplecze usługi Azure Functions przetwarza dane i zapisuje je w usłudze Azure Blob Storage. Klienci usługi, tacy jak przepływy pracy wnioskowania uczenia maszynowego, systemy podejmowania decyzji i różne interfejsy użytkownika, mogą pobierać komunikaty z danymi o temperaturze z usługi Azure Blob Storage.
Mierzenie i monitorowanie
Utwórzmy rozwiązanie do pomiaru i monitorowania dla usługi La Niña, koncentrujące się na jej wartości biznesowej.
Co mierzymy i monitorujemy
Aby zrozumieć, co będziemy monitorować, musimy zrozumieć, co usługa faktycznie robi i czego klienci usługi oczekują od systemu. W tym scenariuszu oczekiwania wspólnego konsumenta usługi La Niña mogą być podzielone na kategorie według następujących czynników:
- Pokrycie. Dane pochodzą z większości zainstalowanych bojaźni
- Świeżość. Dane pochodzące z bojówek są świeże i istotne
- Przepływność. Dane dotyczące temperatury są dostarczane z buy bez znaczących opóźnień
- Poprawność Współczynnik utraconych komunikatów (błędów) jest niewielki
Zadowolenie z tych czynników oznacza, że usługa działa zgodnie z oczekiwaniami klienta.
Następnym krokiem jest zdefiniowanie instrumentów do mierzenia wartości tych czynników. To zadanie jest wykonywane przez następujące wskaźniki poziomu usług (SLI):
| Wskaźnik poziomu usług | Czynników |
|---|---|
| Stosunek urządzeń online do całkowitej liczby urządzeń | Pokrycie |
| Współczynnik często zgłaszanych urządzeń do liczby urządzeń raportowania | Świeżość, przepływność |
| Współczynnik pomyślnego dostarczania komunikatów przez urządzenia do całkowitej liczby urządzeń | Poprawność |
| Współczynnik szybkości dostarczania komunikatów przez urządzenia do całkowitej liczby urządzeń | Produktywność |
Dzięki temu możemy zastosować przesuwaną skalę dla każdego wskaźnika i zdefiniować dokładne wartości progowe reprezentujące, co oznacza, że klient ma być "zadowolony". W tym scenariuszu wybieramy przykładowe wartości progowe określone w poniższej tabeli z formalnymi celami poziomu usług (SLO):
| Cel poziomu usług | Współczynnik |
|---|---|
| 90% urządzeń zgłosiło metryki nie dłużej niż 10 minut temu (były w trybie online) dla interwału obserwacji | Pokrycie |
| 95% urządzeń online wysyła temperaturę 10 razy na minutę dla interwału obserwacji | Świeżość, przepływność |
| 99% urządzeń online pomyślnie dostarcza komunikaty z mniej niż 5% błędów dla interwału obserwacji | Poprawność |
| 95% urządzeń online dostarcza 90. percentyl komunikatów w ciągu 50 ms dla interwału obserwacji | Produktywność |
Definicja celów SLO musi również opisywać podejście do pomiaru wartości wskaźnika:
- Interwał obserwacji: 24 godziny. Oświadczenia SLO są prawdziwe z ostatnich 24 godzin. Oznacza to, że jeśli SLI ulegnie awarii i naruszy odpowiedni cel SLO, to musi minąć 24 godziny po naprawieniu SLI, aby ponownie uznać cel SLO za spełniony.
- Częstotliwość pomiarów: 5 minut. Przeprowadzamy pomiary w celu oceny wartości SLI co 5 minut.
- Co jest mierzone: interakcja między urządzeniem IoT a chmurą, dalsze zużycie danych temperatury jest poza zakresem.
Jak mierzymy
W tym momencie jasne jest, co będziemy mierzyć i jakie wartości progowe będziemy używać, aby określić, czy usługa działa zgodnie z oczekiwaniami.
Typowym rozwiązaniem jest mierzenie wskaźników poziomu usług, takich jak zdefiniowane przez nas wskaźniki, za pomocą metryk. Ten typ danych obserwacji jest uważany za stosunkowo mały w wartościach. Jest tworzony przez różne składniki systemu i zbierany w centralnym systemie monitorowania, aby być monitorowanym za pomocą dashboardów, skoroszytów i alertów.
Wyjaśnijmy, jakie składniki składa się z usługi La Niña:
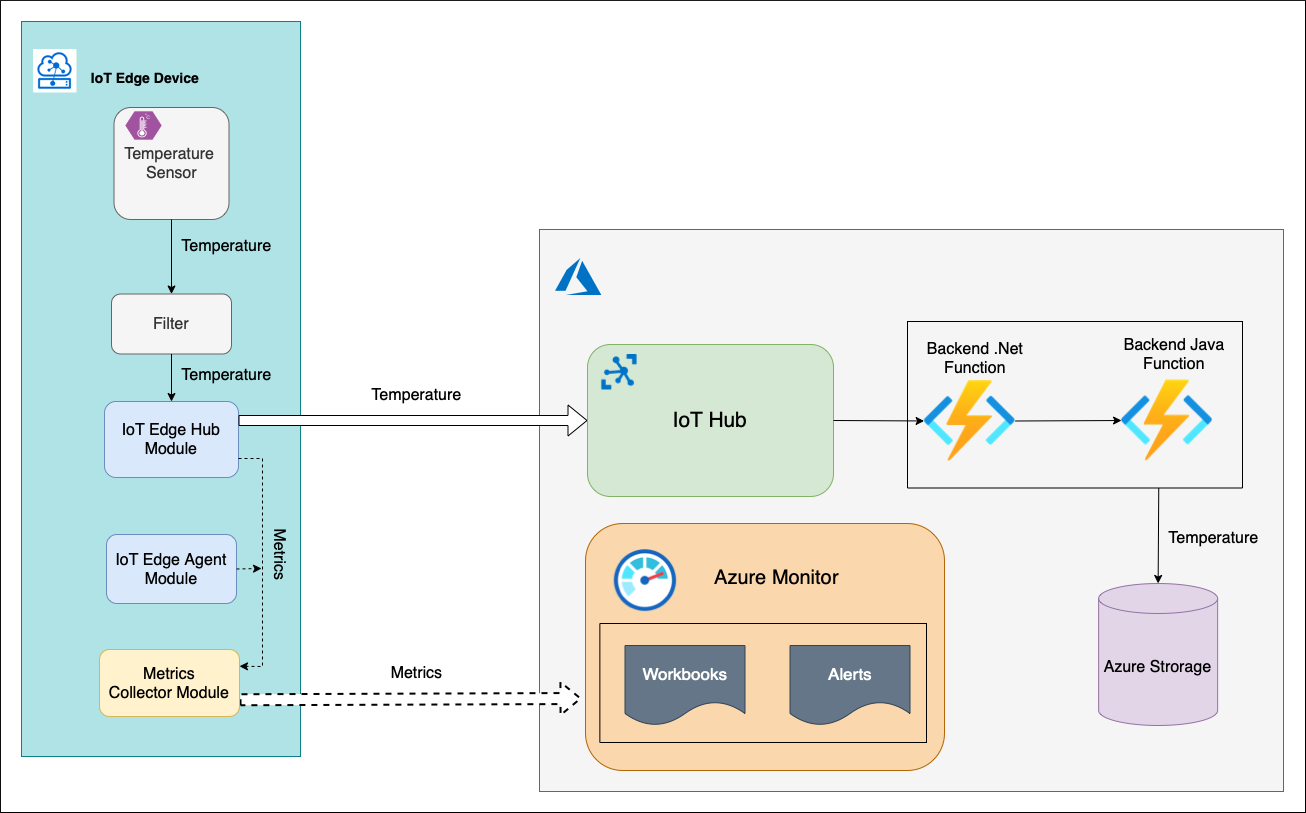
Istnieje urządzenie usługi IoT Edge z modułem Temperature Sensor niestandardowym (C#), które generuje pewną wartość temperatury i wysyła je w górę z komunikatem telemetrii. Ten komunikat jest kierowany do innego modułu Filter niestandardowego (C#). Ten moduł sprawdza odebraną temperaturę w przedziale progowym (0–100 stopni Celsjusza). Jeśli temperatura znajduje się w oknie, moduł FilterModule wysyła komunikat telemetrii do chmury.
W chmurze komunikat jest przetwarzany przez zaplecze. Zaplecze składa się z łańcucha dwóch usług Azure Functions i konta magazynu. Funkcja platformy Azure .NET pobiera komunikat telemetryczny z punktu końcowego zdarzeń usługi IoT Hub, przetwarza go i wysyła do funkcji Języka Java platformy Azure. Funkcja Java zapisuje komunikat w kontenerze obiektów blob konta magazynu.
Urządzenie usługi IoT Hub jest dostarczane z modułami edgeHub systemowymi i edgeAgent. Te moduły uwidaczniają za pośrednictwem punktu końcowego rozwiązania Prometheus listę wbudowanych metryk. Te metryki są zbierane i wypychane do usługi Azure Monitor Log Analytics przez moduł modułu zbierającego metryki uruchomionego na urządzeniu usługi IoT Edge. Oprócz modułów systemowych moduły Temperature Sensor i Filter mogą być również instrumentowane za pomocą niektórych metryk specyficznych dla firmy. Jednak zdefiniowane przez nas wskaźniki poziomu usług można mierzyć tylko za pomocą wbudowanych metryk. Tak więc w tym momencie nie musimy implementować żadnych innych elementów.
W tym scenariuszu mamy flotę 10 buy. Jedną z boi jest celowo skonfigurowana w celu nieprawidłowego działania, dzięki czemu możemy zademonstrować wykrywanie problemów i kolejne kroki rozwiązywania problemów.
Jak monitorować
Będziemy monitorować cele poziomu usług (SLO) i odpowiednie wskaźniki poziomu usług (SLI) za pomocą skoroszytów usługi Azure Monitor. To wdrożenie scenariusza obejmuje skoroszyt La Nina SLO/SLI przypisany do usługi IoT Hub.
Aby uzyskać najlepsze środowisko użytkownika, skoroszyty zostały zaprojektowane pod kątem błyskawicznego śledzenia koncepcji ->scan ->commit:
Spojrzenie
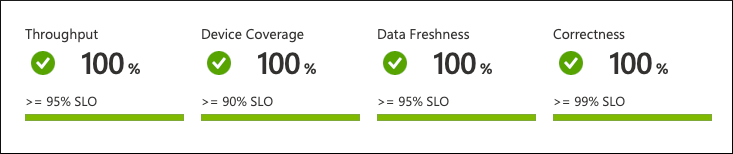
Na tym poziomie widać cały obraz na jeden rzut oka. Dane są agregowane i reprezentowane na poziomie floty:
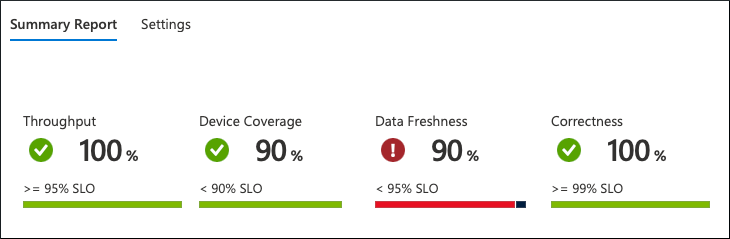
Z tego, co widzimy, usługa nie działa zgodnie z oczekiwaniami. Wystąpiło naruszenie SLO dotyczącego świeżości danych. Tylko 90% urządzeń często wysyła dane, a klienci usługi oczekują 95%.
Wszystkie wartości slo i progowe można skonfigurować na karcie ustawień skoroszytu:
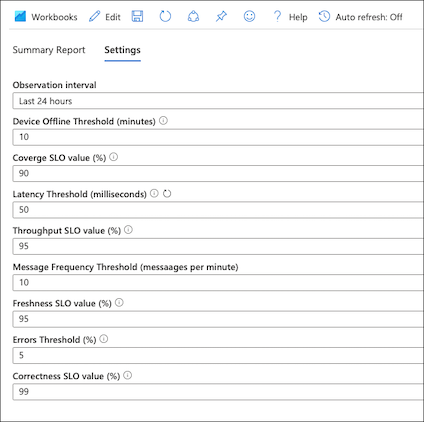
Skanuj
Klikając naruszony cel slo, możemy przejść do szczegółów na poziomie skanowania i zobaczyć, jak urządzenia przyczyniają się do zagregowanej wartości SLI.
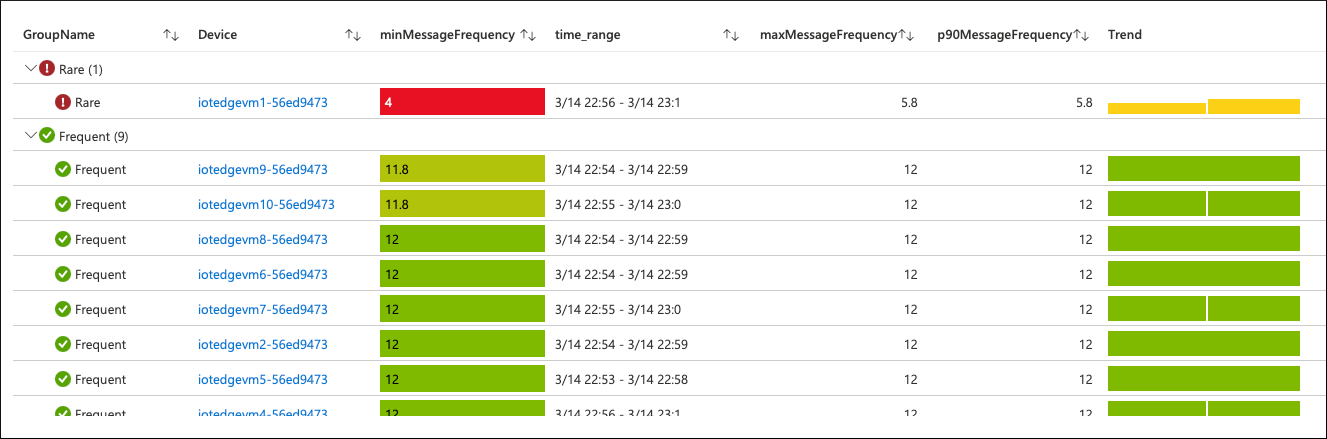
Istnieje jedno urządzenie (na 10), które wysyła dane telemetryczne do chmury "rzadko". W naszej definicji slo stwierdziliśmy, że "często" oznacza co najmniej 10 razy na minutę. Częstotliwość tego urządzenia jest poniżej tego progu.
Zatwierdzenie
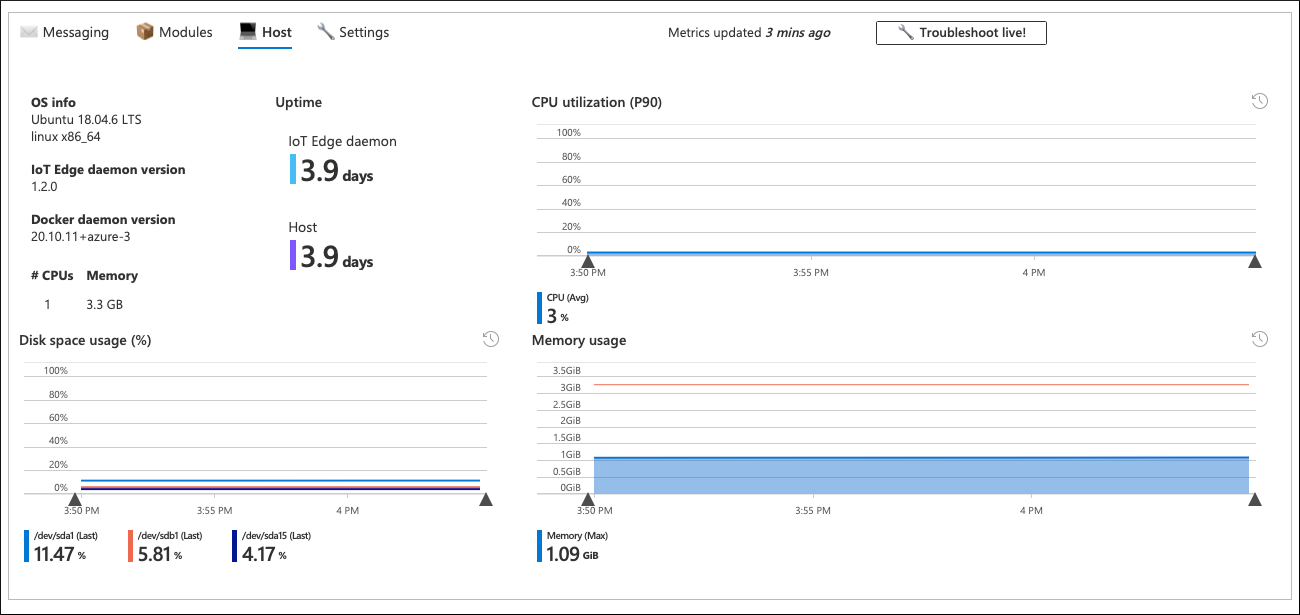
Klikając problematyczne urządzenie, przechodzimy do szczegółów na poziomie zatwierdzania . Jest to wyselekcjonowane skoroszyt Szczegóły urządzenia, który wychodzi z pudełka z ofertą monitorowania usługi IoT Hub. Skoroszyt La Nina SLO/SLI używa go ponownie, aby uzyskać szczegółowe informacje o wydajności określonego urządzenia.
Rozwiązywanie problemów
Pomiar i monitorowanie pozwala nam obserwować i przewidywać zachowanie systemu, porównać je ze zdefiniowanymi oczekiwaniami i ostatecznie wykryć istniejące lub potencjalne problemy. Z drugiej strony rozwiązywanie problemów pozwala zidentyfikować i zlokalizować przyczynę problemu.
Podstawowe rozwiązywanie problemów
Skoroszyt poziomu zatwierdzenia zawiera szczegółowe informacje o kondycji urządzenia. Obejmuje to użycie zasobów na poziomie modułu i urządzenia, opóźnienie komunikatów, częstotliwość, QLen i inne. W wielu przypadkach te informacje mogą pomóc w zlokalizowaniu źródła problemu.
W tym scenariuszu wszystkie parametry urządzenia z problemami wyglądają normalnie i nie jest jasne, dlaczego urządzenie wysyła komunikaty rzadziej niż oczekiwano. Karta wiadomości skoroszytu na poziomie urządzenia również to potwierdza.
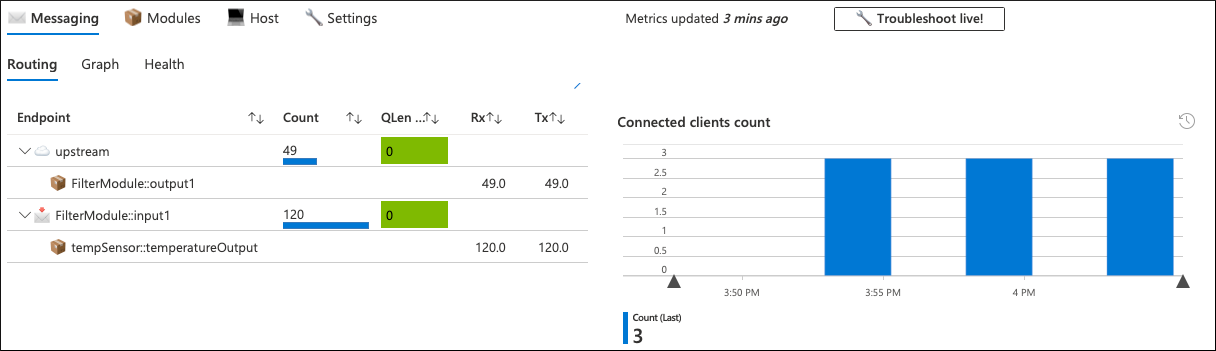
Moduł Temperature Sensor (tempSensor) wygenerował 120 komunikatów telemetrycznych, ale tylko 49 z nich przeszło w górę do chmury.
Najpierw sprawdź dzienniki wygenerowane przez Filter moduł. Wybierz pozycję Rozwiązywanie problemów na żywo!, a następnie wybierz Filter moduł.
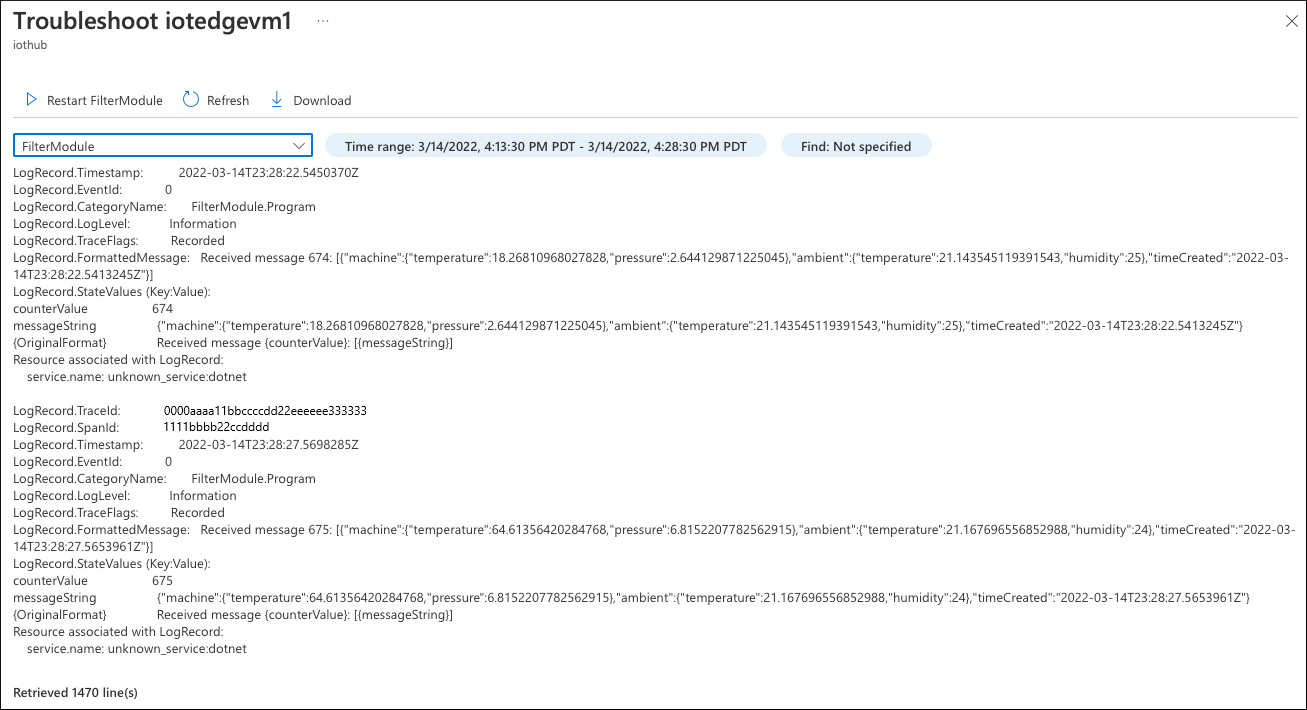
Analiza dzienników modułu nie ujawnia problemu. Moduł odbiera komunikaty i nie ma żadnych błędów. Wszystko wygląda dobrze tutaj.
Szczegółowe rozwiązywanie problemów
Dwa narzędzia do obserwacji służą do głębokich celów rozwiązywania problemów: ślady i dzienniki. W tym scenariuszu ślady pokazują, jak komunikat telemetryczny dotyczący temperatury powierzchni oceanu przemieszcza się z czujnika do przechowywania w chmurze, co dokonuje wywołań oraz z jakimi parametrami. Dzienniki pokazują, co dzieje się wewnątrz każdego składnika systemu podczas tego procesu. Prawdziwa moc śladów i dzienników przychodzi, gdy są skorelowane. Dzięki tej konfiguracji można odczytywać dzienniki określonego składnika systemu, takiego jak moduł na urządzeniu IoT lub funkcji zaplecza, podczas gdy przetwarza określony komunikat telemetrii.
Usługa La Niña używa biblioteki OpenTelemetry do tworzenia i zbierania śladów i dzienników w usłudze Azure Monitor.
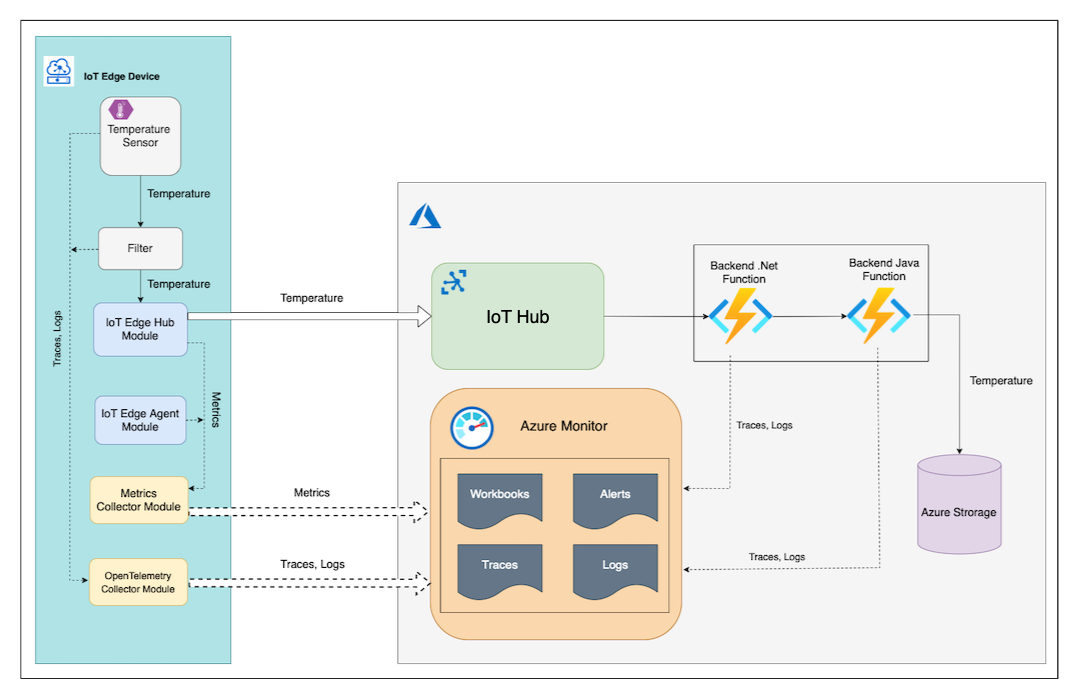
Moduły Temperature Sensor i Filter usługi IoT Edge eksportują dzienniki i dane śledzenia za pomocą protokołu OTLP (OpenTelemetry Protocol) do modułu OpenTelemetryCollector działającego na tym samym urządzeniu brzegowym. Następnie OpenTelemetryCollector moduł eksportuje dzienniki i ślady do usługi Azure Monitor Application Insights.
Funkcja Azure .NET wysyła dane śledzenia do Application Insights przy użyciu bezpośredniego eksportera Azure Monitor Open Telemetry. Wysyła również skorelowane dzienniki bezpośrednio do usługi Application Insights przy użyciu skonfigurowanej instancji ILogger.
Funkcja zaplecza Java używa agenta Java automatycznego instrumentacji OpenTelemetry do tworzenia i eksportowania danych śledzenia oraz skorelowanych dzienników do wystąpienia usługi Application Insights.
Domyślnie moduły usługi IoT Edge na urządzeniach usługi La Niña nie są ustawione na tworzenie żadnych danych śledzenia, a poziom rejestrowania jest ustawiony na Information. Objętość danych śledzenia jest kontrolowana przez mechanizm próbkujący oparty na współczynniku. Próbkator jest ustawiany z prawdopodobieństwem dla danego działania, które ma zostać uwzględnione w śladzie. Domyślnie prawdopodobieństwo wynosi 0. W przypadku tej konfiguracji urządzenia nie zalewają usługi Azure Monitor szczegółowymi danymi z obserwacji, jeśli nie są potrzebne.
Po przeanalizowaniu Information dzienników poziomu modułu Filter należy dokładniej znaleźć przyczynę problemu. Zaktualizuj właściwości w Temperature Sensor i Filter bliźniaczych reprezentacjach modułów, zwiększ loggingLevel do Debug, a następnie zmień traceSampleRatio z 0 na 1:
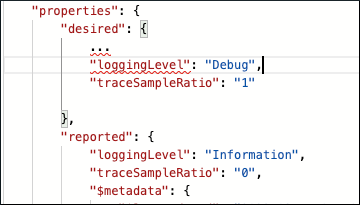
Po wprowadzeniu tych zmian uruchom ponownie moduły Temperature Sensor i Filter.
W ciągu kilku minut ślady i szczegółowe dzienniki docierają do usługi Azure Monitor z urządzenia z problemami. Cały kompletny przepływ komunikatów z czujnika na urządzeniu do magazynu w chmurze jest dostępny do monitorowania za pomocą mapy aplikacji w usłudze Application Insights:
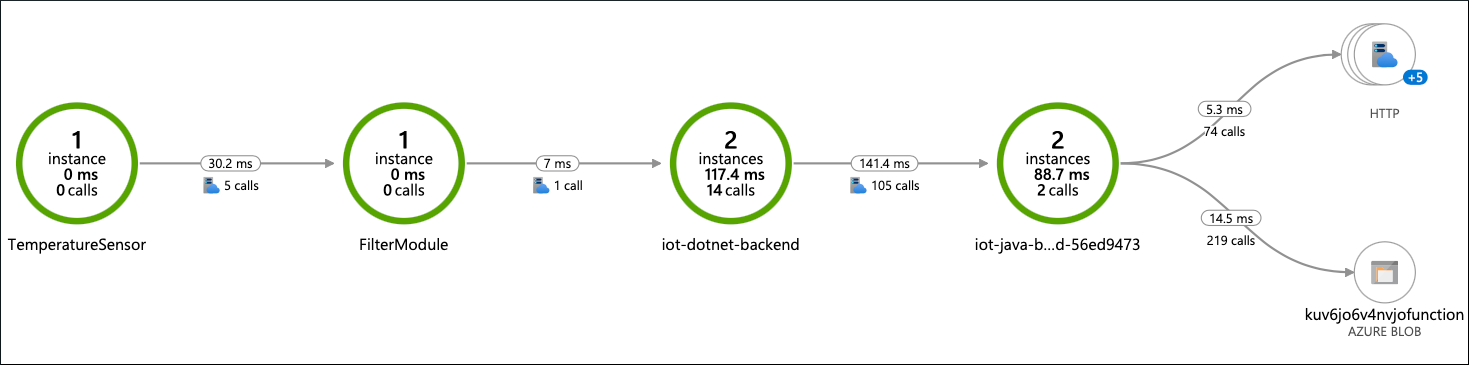
Z tej mapy możesz przejść do szczegółów śladów. Niektóre ślady wyglądają normalnie i zawierają wszystkie kroki przepływu, ale niektóre są krótkie, więc nic się nie dzieje po Filter module.
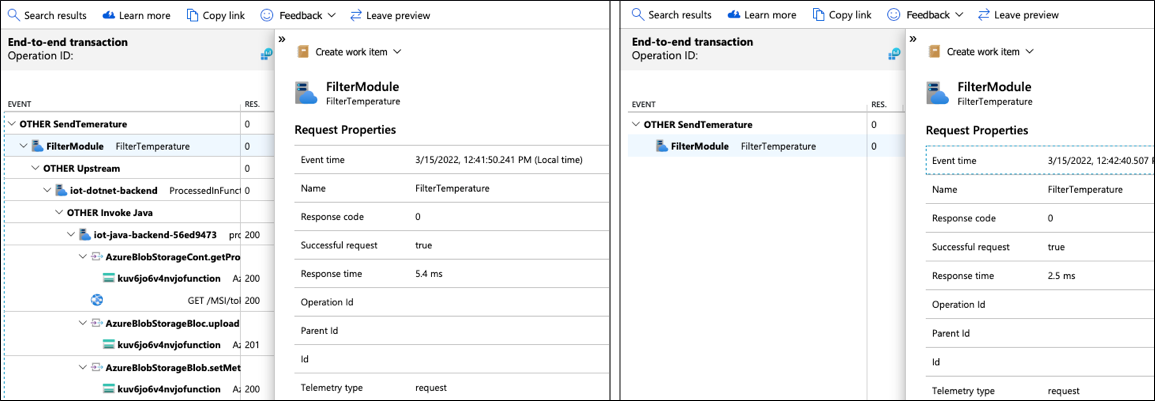
Przeanalizuj jeden z tych krótkich śladów, aby dowiedzieć się, co się stało w module Filter i dlaczego nie wysłał komunikatu do góry do chmury.
Dzienniki są skorelowane ze śladami, dlatego można wykonywać zapytania dotyczące dzienników, określając TraceId i SpanId w celu pobrania dzienników dla tej instancji wykonania modułu Filter :
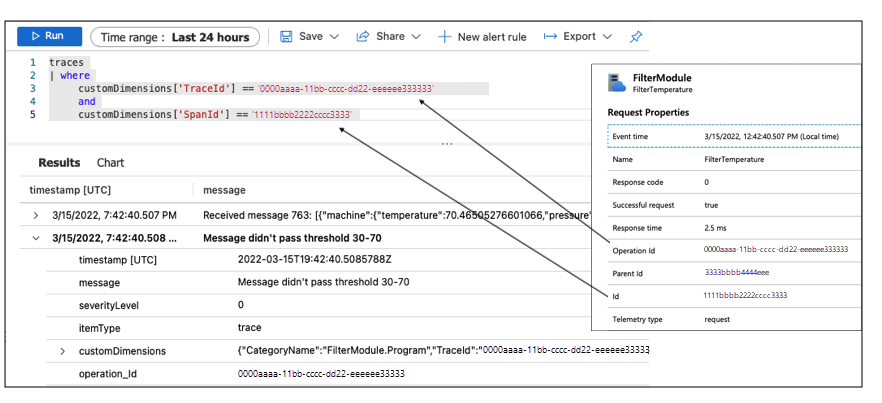
Dzienniki pokazują, że moduł otrzymał komunikat o temperaturze 70,465 stopni. Jednak próg filtrowania ustawiony na tym urządzeniu wynosi od 30 do 70. W związku z tym komunikat nie przekroczył progu. To urządzenie jest niepoprawnie skonfigurowane. Ta konfiguracja jest przyczyną wykrytego problemu podczas monitorowania wydajności usługi La Niña za pomocą skoroszytu.
Napraw konfigurację modułu Filter na tym urządzeniu, aktualizując właściwości w bliźniaczej reprezentacji modułu. Ponadto zmniejsz loggingLevel do Information i ustaw traceSampleRatio na 0.

Po wprowadzeniu tych zmian uruchom ponownie moduł. W ciągu kilku minut urządzenie zgłasza nowe wartości metryk do usługi Azure Monitor. Wykresy skoroszytu odzwierciedlają następujące aktualizacje:
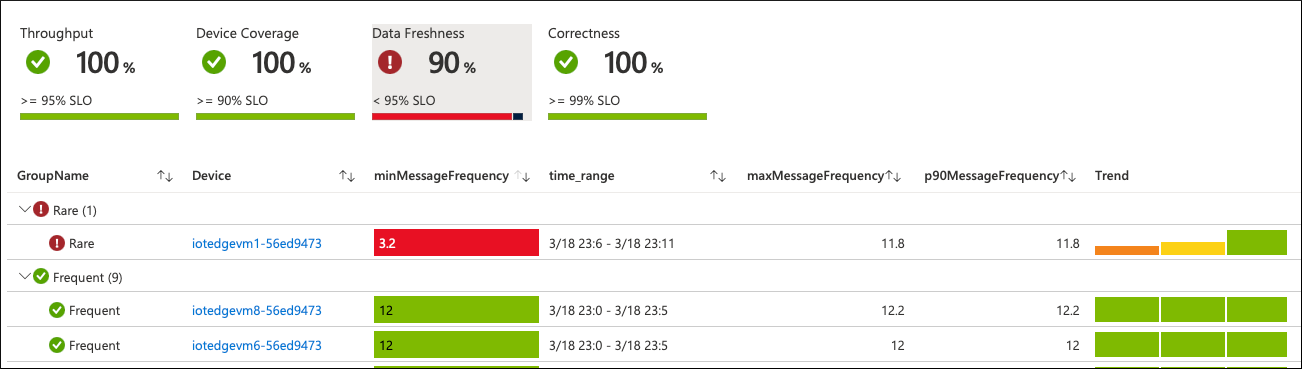
Częstotliwość komunikatów na problematycznym urządzeniu powraca do normalnego. Ogólna wartość SLO zmieni kolor na zielony ponownie, jeśli nic innego nie dzieje się w skonfigurowanym interwale obserwacji.
Wypróbuj przykład
W tym momencie możesz wdrożyć przykładowy scenariusz na platformie Azure, aby wykonać kroki i wypróbować własne przypadki użycia.
Aby wdrożyć to rozwiązanie, potrzebne są następujące elementy:
- PowerShell
- Interfejs wiersza polecenia platformy Azure
- Konto platformy Azure z aktywną subskrypcją. Utwórz je bezpłatnie.
Sklonuj repozytorium IoT Elms .
git clone https://github.com/Azure-Samples/iotedge-logging-and-monitoring-solution.gitOtwórz konsolę programu PowerShell i uruchom
deploy-e2e-tutorial.ps1skrypt../Scripts/deploy-e2e-tutorial.ps1
Następne kroki
W tym artykule skonfigurujesz rozwiązanie z funkcjami kompleksowej obserwacji na potrzeby monitorowania i rozwiązywania problemów. Typowym wyzwaniem w tych rozwiązaniach dla systemów IoT jest wysyłanie danych z urządzeń do chmury. Urządzenia w tym scenariuszu powinny być w trybie online i mieć stabilne połączenie z usługą Azure Monitor, ale nie zawsze tak jest.
Przejdź do artykułów kontynuacyjnych, takich jak Śledzenie rozproszone za pomocą IoT Edge, aby uzyskać zalecenia i techniki obsługi scenariuszy, gdy urządzenia są zwykle offline lub mają ograniczone albo zastrzeżone połączenia z zapleczem monitorowania w chmurze.