Ciągłość działania i odzyskiwanie po awarii dla usługi Azure Logic Apps
Aby zmniejszyć wpływ i wpływ nieprzewidywalnych zdarzeń na firmę i klientów, upewnij się, że masz rozwiązanie odzyskiwania po awarii (DR), aby można było chronić dane, szybko przywrócić zasoby, które obsługują krytyczne funkcje biznesowe, i zachować działanie operacji w celu utrzymania ciągłości działania firmy (BC). Na przykład zakłócenia mogą obejmować awarie, straty w podstawowej infrastrukturze lub składnikach, takich jak magazyn, sieć lub zasoby obliczeniowe, nieodwracalne awarie aplikacji, a nawet pełną utratę centrum danych. Dzięki gotowemu rozwiązaniu do zapewnienia ciągłości działania i odzyskiwania po awarii (BCDR, business continuity and disaster recovery) twoje przedsiębiorstwo lub organizacja może szybciej reagować na przerwy, planowane lub nieplanowane oraz ograniczyć przestoje dla klientów.
Ten artykuł zawiera wskazówki i strategie bcDR, które można zastosować podczas tworzenia zautomatyzowanych przepływów pracy przy użyciu usługi Azure Logic Apps. Przepływy pracy aplikacji logiki ułatwiają integrowanie i organizowanie danych między aplikacjami, usługami w chmurze i systemami lokalnymi dzięki zmniejszeniu ilości kodu, który trzeba napisać. Podczas planowania bcDR upewnij się, że rozważasz nie tylko aplikacje logiki, ale także te zasoby platformy Azure, których używasz z aplikacjami logiki:
Połączenia tworzone na podstawie przepływów pracy aplikacji logiki do innych aplikacji, usług i systemów. Aby uzyskać więcej informacji, zobacz Połączenia z zasobami w dalszej części tego tematu.
Lokalne bramy danych, które są zasobami platformy Azure tworzonymi i używanymi w aplikacjach logiki do uzyskiwania dostępu do danych w systemach lokalnych. Każdy zasób bramy reprezentuje oddzielną instalację bramy danych na komputerze lokalnym. Aby uzyskać więcej informacji, zobacz lokalne bramy danych w dalszej części tego tematu.
Konta integracji, na których definiujesz i przechowujesz artefakty używane przez aplikacje logiki na potrzeby scenariuszy integracji z przedsiębiorstwem (B2B). Na przykład można skonfigurować odzyskiwanie po awarii między regionami dla kont integracji.
Środowiska usługi integracji (ISE), w których tworzone są aplikacje logiki uruchamiane w izolowanym wystąpieniu środowiska uruchomieniowego usługi Logic Apps w sieci wirtualnej platformy Azure. Te aplikacje logiki mogą następnie uzyskiwać dostęp do zasobów chronionych za zaporą w tej sieci wirtualnej.
Lokalizacje podstawowe i pomocnicze
Każda aplikacja logiki musi określić lokalizację, której chcesz użyć do wdrożenia. Ta lokalizacja jest regionem publicznym na globalnej platformie Azure z wieloma dzierżawami, takimi jak "Zachodnie stany USA" lub środowisko usługi integracji (ISE), które zostało wcześniej utworzone i wdrożone w sieci wirtualnej platformy Azure. Uruchamianie aplikacji logiki w środowisku ISE jest podobne do uruchamiania aplikacji logiki w globalnym regionie świadczenia usługi Azure, co oznacza, że strategia odzyskiwania po awarii może mieć zastosowanie do obu scenariuszy. Jednak isE mają inne zagadnienia, takie jak konfigurowanie dostępu do zasobów, które są dostępne tylko dla środowisk ISE.
Uwaga
Jeśli aplikacja logiki działa również z artefaktami B2B, takimi jak partnerzy handlowi, umowy, schematy, mapy i certyfikaty, które są przechowywane na koncie integracji, zarówno konto integracji, jak i aplikacje logiki muszą określać tę samą lokalizację.
Ta strategia odzyskiwania po awarii koncentruje się na konfigurowaniu podstawowej aplikacji logiki w celu przejścia w tryb failover do aplikacji logiki rezerwowej lub tworzenia kopii zapasowej w alternatywnej lokalizacji, w której jest również dostępna usługa Azure Logic Apps. W ten sposób, jeśli podstawowy poniesie straty, zakłócenia lub awarie, pomocnicza może przejąć pracę. Ta strategia wymaga, aby pomocnicza aplikacja logiki i zasoby zależne zostały już wdrożone i gotowe w lokalizacji alternatywnej.
Jeśli zastosujesz dobre rozwiązania devOps, szablony usługi Azure Resource Manager są już używane do definiowania i wdrażania aplikacji logiki i ich zasobów zależnych. Szablony usługi Resource Manager umożliwiają używanie pojedynczej definicji wdrożenia, a następnie używanie plików parametrów w celu udostępnienia wartości konfiguracji do użycia dla każdego miejsca docelowego wdrożenia. Ta możliwość oznacza, że można wdrożyć tę samą aplikację logiki w różnych środowiskach, na przykład programowanie, testowanie i produkcja. Tę samą aplikację logiki można również wdrożyć w różnych regionach platformy Azure lub środowiskach ISE, które obsługują strategie odzyskiwania po awarii korzystające z sparowanych regionów.
W przypadku strategii trybu failover aplikacje logiki i lokalizacje muszą spełniać następujące wymagania:
Wystąpienie pomocniczej aplikacji logiki ma dostęp do tych samych aplikacji, usług i systemów co podstawowe wystąpienie aplikacji logiki.
Oba wystąpienia aplikacji logiki mają ten sam typ hosta. W związku z tym oba wystąpienia są wdrażane w regionach na globalnej wielodostępnej platformie Azure lub oba wystąpienia są wdrażane w środowiskach ISE, co umożliwia aplikacjom logiki bezpośredni dostęp do zasobów w sieci wirtualnej platformy Azure. Aby uzyskać najlepsze rozwiązania i więcej informacji na temat sparowanych regionów dla trasy BCDR, zobacz Replikacja między regionami na platformie Azure: ciągłość działania i odzyskiwanie po awarii.
Na przykład zarówno lokalizacje podstawowe, jak i pomocnicze muszą być isEs, gdy podstawowa aplikacja logiki działa w środowisku ISE i używa łączników z wersją ISE, akcji HTTP do wywoływania zasobów w sieci wirtualnej platformy Azure lub obu tych elementów. W tym scenariuszu pomocnicza aplikacja logiki musi również mieć podobną konfigurację w lokalizacji pomocniczej jako podstawowa aplikacja logiki.
Uwaga
W przypadku bardziej zaawansowanych scenariuszy można mieszać platformę Azure z wieloma dzierżawami i ise jako lokalizacje. Upewnij się jednak, że rozważasz i rozumiesz różnice między sposobem działania aplikacji logiki w środowisku ISE a platformą Azure z wieloma dzierżawami.
Jeśli używasz ise, upewnij się, że są skalowane w poziomie lub mają wystarczającą pojemność do obsługi obciążenia.
Przykład: Wielodostępna platforma Azure
W tym przykładzie przedstawiono podstawowe i pomocnicze wystąpienia aplikacji logiki, które są wdrażane w oddzielnych regionach na globalnej platformie Azure z wieloma dzierżawami na potrzeby tego scenariusza. Pojedynczy szablon usługi Resource Manager definiuje zarówno wystąpienia aplikacji logiki, jak i zasoby zależne wymagane przez te aplikacje logiki. Oddzielne pliki parametrów określają wartości konfiguracji do użycia dla każdej lokalizacji wdrożenia:
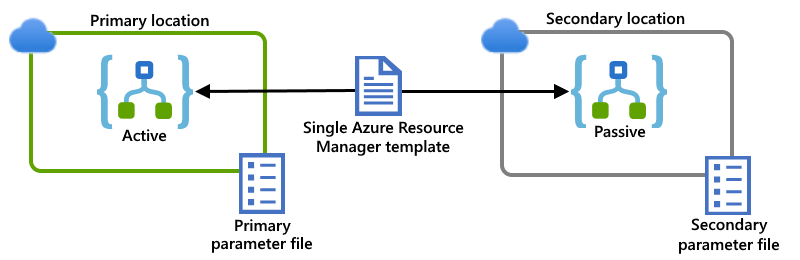
Przykład: Środowisko usługi integracji
W tym przykładzie pokazano poprzednie wystąpienia aplikacji logiki podstawowej i pomocniczej, ale wdrożone w oddzielnych środowiskach ISE. Pojedynczy szablon usługi Resource Manager definiuje zarówno wystąpienia aplikacji logiki, zasoby zależne wymagane przez te aplikacje logiki, jak i środowiska ISE jako lokalizacje wdrożenia. Oddzielne pliki parametrów definiują wartości konfiguracji, które mają być używane do wdrożenia w każdej lokalizacji:
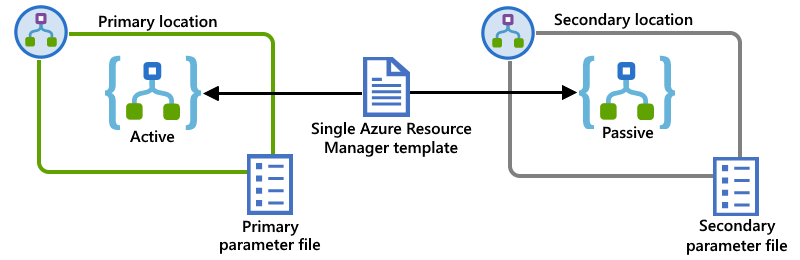
Połączenia z zasobami
Usługa Azure Logic Apps udostępnia wiele setek operacji łącznika, których przepływ pracy aplikacji logiki może używać do pracy z innymi aplikacjami, usługami, systemami i innymi zasobami, takimi jak konta usługi Azure Storage, bazy danych programu SQL Server, służbowe konta e-mail itd. Jeśli aplikacja logiki potrzebuje dostępu do tych zasobów, należy utworzyć połączenia, które uwierzytelniają dostęp do tych zasobów. Każde połączenie to oddzielny zasób platformy Azure, który istnieje w określonej lokalizacji i nie może być używany przez zasoby w innych lokalizacjach.
W przypadku strategii odzyskiwania po awarii należy wziąć pod uwagę lokalizacje, w których istnieją zasoby zależne względem wystąpień aplikacji logiki:
Wystąpienie podstawowe i zasoby zależne istnieją w różnych lokalizacjach. W takim przypadku wystąpienie pomocnicze może łączyć się z tymi samymi zasobami zależnymi lub punktami końcowymi. Należy jednak utworzyć połączenia specjalnie dla wystąpienia pomocniczego. W ten sposób, jeśli lokalizacja podstawowa stanie się niedostępna, połączenia pomocnicze nie będą miały wpływu.
Załóżmy na przykład, że podstawowa aplikacja logiki łączy się z usługą zewnętrzną, taką jak Salesforce. Zazwyczaj dostępność i lokalizacja usługi zewnętrznej są niezależne od dostępności aplikacji logiki. W takim przypadku wystąpienie pomocnicze może nawiązać połączenie z tą samą usługą, ale powinno mieć własne połączenie.
Zarówno wystąpienie podstawowe, jak i zasoby zależne istnieją w tej samej lokalizacji. W takim przypadku zasoby zależne powinny mieć kopie zapasowe lub zreplikowane wersje w innej lokalizacji, aby wystąpienie pomocnicze mogło nadal uzyskiwać dostęp do tych zasobów.
Załóżmy na przykład, że podstawowa aplikacja logiki łączy się z usługą znajdującą się w tej samej lokalizacji lub regionie, na przykład z usługą Azure SQL Database. Jeśli cały region stanie się niedostępny, usługa Azure SQL Database w tym regionie jest również prawdopodobnie niedostępna. W takim przypadku chcesz, aby wystąpienie pomocnicze używało replikowanej bazy danych lub bazy danych kopii zapasowej wraz z oddzielnym połączeniem z tą bazą danych.
Lokalne bramy danych
Jeśli aplikacja logiki działa na platformie Azure z wieloma dzierżawami i potrzebuje dostępu do zasobów lokalnych, takich jak bazy danych programu SQL Server, musisz zainstalować lokalną bramę danych na komputerze lokalnym. Następnie możesz utworzyć zasób bramy danych w witrynie Azure Portal, aby aplikacja logiki mogła używać bramy podczas tworzenia połączenia z zasobem.
Zasób bramy danych jest skojarzony z lokalizacją lub regionem platformy Azure, podobnie jak zasób aplikacji logiki. W strategii odzyskiwania po awarii upewnij się, że brama danych pozostaje dostępna do użycia przez aplikację logiki. Wysoką dostępność bramy można włączyć, jeśli masz wiele instalacji bramy.
Uwaga
Jeśli aplikacja logiki działa w środowisku usługi integracji (ISE) i używa tylko łączników ISE w wersji dla lokalnych źródeł danych, nie potrzebujesz bramy danych, ponieważ łączniki ISE zapewniają bezpośredni dostęp do zasobu lokalnego.
Jeśli dla żądanego zasobu lokalnego nie jest dostępny żaden łącznik ISE, aplikacja logiki nadal może utworzyć połączenie przy użyciu łącznika innego niż ISE, który działa na globalnej platformie Azure z wieloma dzierżawami, a nie w środowisku ISE. Jednak to połączenie wymaga lokalnej bramy danych.
Role aktywne-aktywne i aktywne-pasywne
Możesz skonfigurować lokalizacje podstawowe i pomocnicze, aby wystąpienia aplikacji logiki w tych lokalizacjach mogły odgrywać następujące role:
| Rola pomocnicza podstawowa | opis |
|---|---|
| Aktywne-aktywne | Wystąpienia podstawowej i pomocniczej aplikacji logiki w obu lokalizacjach aktywnie obsługują żądania, postępując zgodnie z jednym z następujących wzorców: - Równoważenie obciążenia: oba wystąpienia mogą nasłuchiwać punktu końcowego i równoważyć obciążenie ruchu do każdego wystąpienia w razie potrzeby. - Konkurujący odbiorcy: oba wystąpienia mogą działać jako konkurujący odbiorcy, aby wystąpienia rywalizowały o komunikaty z kolejki. Jeśli jedno wystąpienie ulegnie awarii, drugie wystąpienie przejmuje obciążenie. |
| Aktywny-pasywny | Wystąpienie podstawowej aplikacji logiki aktywnie obsługuje całe obciążenie, a wystąpienie pomocnicze jest pasywne (wyłączone lub nieaktywne). Pomocniczy czeka na sygnał, że podstawowy jest niedostępny lub nie działa z powodu zakłóceń lub awarii i przejmuje obciążenie jako aktywne wystąpienie. |
| Kombinacja | Niektóre aplikacje logiki odgrywają rolę aktywne-aktywne, a inne aplikacje logiki odgrywają rolę aktywne-pasywne. |
Przykłady aktywne-aktywne
W tych przykładach pokazano konfigurację aktywne-aktywne, w której oba wystąpienia aplikacji logiki aktywnie obsługują żądania lub komunikaty. Inny system lub usługa dystrybuuje żądania lub komunikaty między wystąpieniami, na przykład jedną z następujących opcji:
Moduł równoważenia obciążenia "fizyczny", taki jak sprzęt, który kieruje ruchem
"miękki" moduł równoważenia obciążenia, taki jak usługa Azure Load Balancer lub usługa Azure API Management. Za pomocą usługi API Management można określić zasady określające sposób równoważenia obciążenia ruchu przychodzącego. Możesz też użyć usługi obsługującej śledzenie stanu, na przykład usługi Azure Service Bus.
Chociaż w tym przykładzie przedstawiono głównie usługę Azure Load Balancer, możesz użyć opcji, która najlepiej odpowiada potrzebom scenariusza:
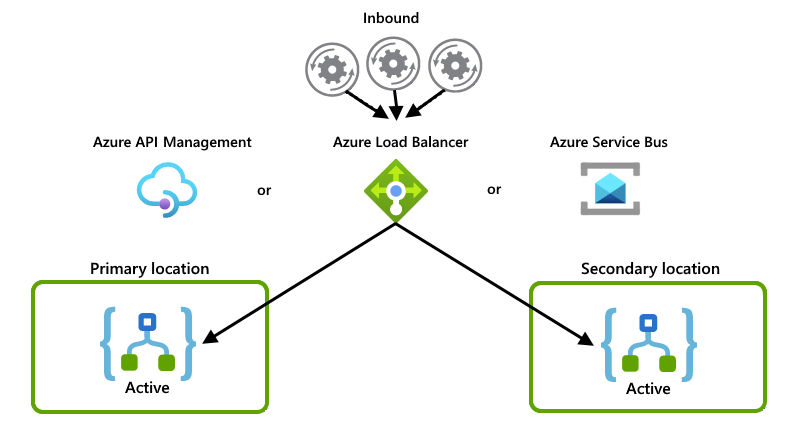
Każde wystąpienie aplikacji logiki działa jako użytkownik i oba wystąpienia konkurują o komunikaty z kolejki:
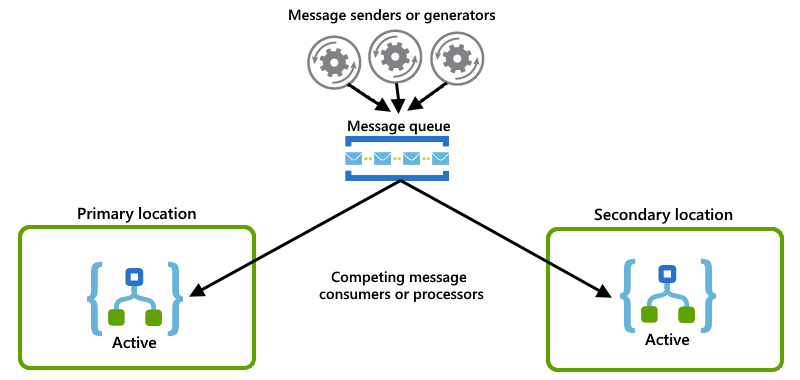
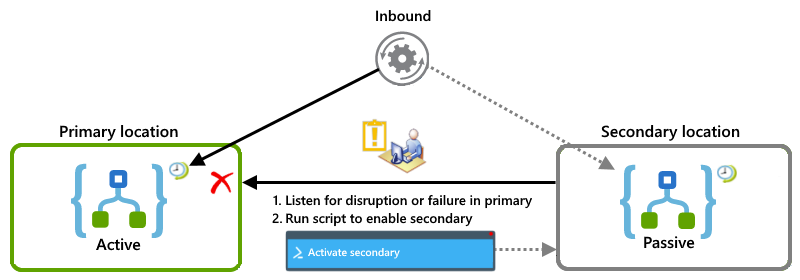
Przykłady aktywne-pasywne
W tym przykładzie pokazano konfigurację aktywne-pasywne, w której główne wystąpienie aplikacji logiki jest aktywne w jednej lokalizacji, a wystąpienie pomocnicze pozostaje nieaktywne w innej lokalizacji. Jeśli w przypadku wystąpienia zakłóceń lub awarii, operator może uruchomić skrypt, który aktywuje pomocniczą, aby przejąć obciążenie.
Połączenie z aktywne-aktywne i aktywne-pasywne
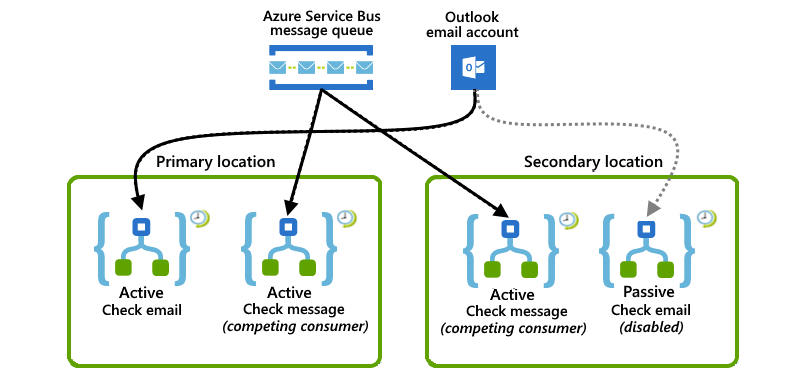
W tym przykładzie pokazano połączoną konfigurację, w której lokalizacja podstawowa ma zarówno aktywne wystąpienia aplikacji logiki, jak i wystąpienie aplikacji logiki aktywne-pasywne. Jeśli lokalizacja podstawowa wystąpi zakłócenia lub awaria, aktywna aplikacja logiki w lokalizacji pomocniczej, która obsługuje już częściowe obciążenie, może przejąć całe obciążenie.
W lokalizacji podstawowej aktywna aplikacja logiki nasłuchuje kolejki usługi Azure Service Bus dla komunikatów, podczas gdy inna aktywna aplikacja logiki sprawdza wiadomości e-mail przy użyciu wyzwalacza sondowania usługi Office 365 Outlook.
W lokalizacji pomocniczej aktywna aplikacja logiki współpracuje z aplikacją logiki w lokalizacji podstawowej, słuchając i konkurując o komunikaty z tej samej kolejki usługi Service Bus. W międzyczasie pasywna nieaktywna aplikacja logiki czeka na wstrzymanie, aby sprawdzić wiadomości e-mail, gdy lokalizacja podstawowa stanie się niedostępna, ale jest wyłączona , aby uniknąć ponownego odczytywania wiadomości e-mail.
Stan i historia aplikacji logiki
Po wyzwoleniu i uruchomieniu aplikacji logiki stan aplikacji jest przechowywany w tej samej lokalizacji, w której uruchomiono aplikację i nie można jej przenieść do innej lokalizacji. Jeśli wystąpi awaria lub zakłócenia, wszystkie wystąpienia przepływu pracy w toku zostaną porzucone. Po skonfigurowaniu lokalizacji podstawowej i pomocniczej nowe wystąpienia przepływu pracy zaczynają działać w lokalizacji pomocniczej.
Zmniejszanie porzuconych wystąpień w toku
Aby zminimalizować liczbę porzuconych wystąpień przepływu pracy w toku, możesz wybrać spośród różnych wzorców komunikatów, które można zaimplementować, na przykład:
Stały wzorzec poślizgu routingu
Ten wzorzec komunikatów przedsiębiorstwa, który dzieli proces biznesowy na mniejsze etapy. Dla każdego etapu skonfigurujesz aplikację logiki, która obsługuje obciążenie dla tego etapu. Aby komunikować się ze sobą, aplikacje logiki używają asynchronicznego protokołu obsługi komunikatów, takiego jak kolejki lub tematy usługi Azure Service Bus. Podczas dzielenia procesu na mniejsze etapy zmniejsza się liczbę procesów biznesowych, które mogą zostać zablokowane w wystąpieniu aplikacji logiki, które zakończyły się niepowodzeniem. Aby uzyskać więcej ogólnych informacji na temat tego wzorca, zobacz Wzorce integracji dla przedsiębiorstw — poślizg routingu.
W tym przykładzie pokazano wzorzec poślizgu routingu, w którym każda aplikacja logiki reprezentuje etap i używa kolejki usługi Service Bus do komunikowania się z następną aplikacją logiki w procesie.
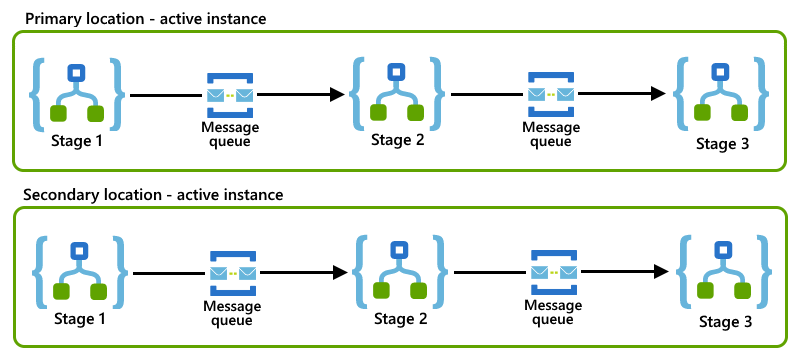
Jeśli zarówno podstawowe, jak i pomocnicze wystąpienia aplikacji logiki są zgodne z tym samym wzorcem poślizgu routingu w ich lokalizacjach, możesz zaimplementować wzorzec konkurujących odbiorców, konfigurując role aktywne-aktywne dla tych wystąpień.
Dostęp do historii wyzwalaczy i przebiegów
Aby uzyskać więcej informacji na temat poprzednich wykonań przepływu pracy aplikacji logiki, możesz przejrzeć wyzwalacz i historię przebiegów aplikacji. Historia wykonywania aplikacji logiki jest przechowywana w tej samej lokalizacji lub regionie, w którym uruchomiono tę aplikację logiki, co oznacza, że nie można migrować tej historii do innej lokalizacji. Jeśli wystąpienie podstawowe przechodzi w tryb failover do wystąpienia pomocniczego, możesz uzyskać dostęp tylko do wyzwalacza każdego wystąpienia i historii przebiegów w odpowiednich lokalizacjach, w których uruchomiono te wystąpienia. Można jednak uzyskać niezależne od lokalizacji informacje o historii aplikacji logiki, konfigurując aplikacje logiki w celu wysyłania zdarzeń diagnostycznych do obszaru roboczego usługi Azure Log Analytics. Następnie możesz przejrzeć kondycję i historię w aplikacjach logiki uruchamianych w wielu lokalizacjach.
Wskazówki dotyczące typu wyzwalacza
Typ wyzwalacza używany w aplikacjach logiki określa opcje konfigurowania aplikacji logiki w różnych lokalizacjach w strategii odzyskiwania po awarii. Poniżej przedstawiono dostępne typy wyzwalaczy, których można używać w aplikacjach logiki:
Wyzwalacz cyklu
Wyzwalacz cyklu jest niezależny od dowolnej konkretnej usługi lub punktu końcowego i uruchamia wyłącznie określony harmonogram i nie ma innych kryteriów, na przykład:
- Stała częstotliwość i interwał, taki jak co 10 minut
- Bardziej zaawansowany harmonogram, taki jak ostatni poniedziałek każdego miesiąca o godzinie 17:00
Gdy aplikacja logiki rozpoczyna się od wyzwalacza Cykl, musisz skonfigurować wystąpienia podstawowej i pomocniczej aplikacji logiki z rolami aktywny-pasywny. Aby skrócić cel czasu odzyskiwania (RTO), który odnosi się do docelowego czasu trwania przywracania procesu biznesowego po przerwie lub awarii, możesz skonfigurować wystąpienia aplikacji logiki z kombinacją ról aktywne-pasywne i role pasywne-aktywne. W tej konfiguracji harmonogram jest podzielony między lokalizacje.
Załóżmy na przykład, że masz aplikację logiki, która musi działać co 10 minut. Możesz skonfigurować aplikacje logiki i lokalizacje, aby jeśli lokalizacja podstawowa stanie się niedostępna, lokalizacja pomocnicza może przejąć pracę:
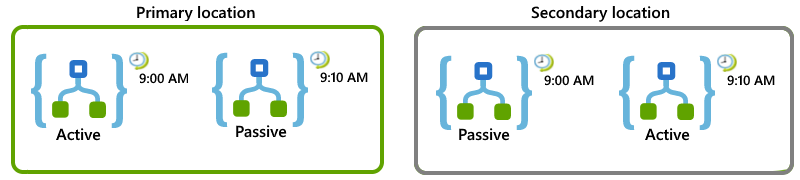
W lokalizacji podstawowej skonfiguruj role aktywne-pasywne dla tych aplikacji logiki:
W przypadku aktywnej włączonej aplikacji logiki ustaw wyzwalacz Cykl, aby rozpoczynał się w górnej części godziny i powtarzał się co 20 minut, na przykład 9:00, 9:20 itd.
W przypadku pasywnej wyłączonej aplikacji logiki ustaw wyzwalacz Cykl na taki sam harmonogram, ale zacznij od 10 minut po godzinie i powtórz co 20 minut, na przykład 9:10, 9:30 itd.
W lokalizacji pomocniczej skonfiguruj pasywne aktywne dla tych aplikacji logiki:
W przypadku pasywnej wyłączonej aplikacji logiki ustaw wyzwalacz Cykl na taki sam harmonogram jak aktywna aplikacja logiki w lokalizacji podstawowej, która znajduje się w górnej części godziny i powtarzaj co 20 minut, na przykład 9:00, 9:10 itd.
W przypadku aktywnej włączonej aplikacji logiki ustaw wyzwalacz Cykl na taki sam harmonogram jak pasywna aplikacja logiki w lokalizacji podstawowej, która ma zaczynać się od 10 minut po godzinie i powtarzać co 20 minut, na przykład 9:10, 9:20 i tak dalej.
Teraz, jeśli w lokalizacji podstawowej wystąpi zdarzenie zakłócające, aktywuj pasywną aplikację logiki w lokalizacji alternatywnej. W ten sposób, jeśli znalezienie błędu zajmuje trochę czasu, ta konfiguracja ogranicza liczbę nieodebranych cykli w tym opóźnieniu.
Wyzwalacz sondowania
Aby regularnie sprawdzać, czy nowe dane do przetwarzania są dostępne z określonej usługi lub punktu końcowego, aplikacja logiki może używać wyzwalacza sondowania , który wielokrotnie wywołuje usługę lub punkt końcowy na podstawie stałego harmonogramu cyklu. Dane, które udostępnia usługa lub punkt końcowy, mogą mieć jeden z następujących typów:
- Dane statyczne, które opisują dane, które są zawsze dostępne do odczytu
- Dane nietrwałe, które opisują dane, które nie są już dostępne po odczytaniu
Aby uniknąć wielokrotnego odczytywania tych samych danych, aplikacja logiki musi pamiętać, które dane były wcześniej odczytywane, zachowując stan po stronie klienta lub po stronie serwera, usługi lub systemu.
Aplikacje logiki współpracujące ze stanem po stronie klienta używają wyzwalaczy, które mogą obsługiwać stan.
Na przykład wyzwalacz odczytujący nową wiadomość ze skrzynki odbiorczej wiadomości e-mail wymaga, aby wyzwalacz zapamiętał ostatnio odczytaną wiadomość. W ten sposób wyzwalacz uruchamia aplikację logiki tylko wtedy, gdy pojawi się następny nieprzeczytany komunikat.
Aplikacje logiki współpracujące z serwerem, usługą lub stanem po stronie systemu używają wartości właściwości lub ustawień, które znajdują się po stronie serwera, usługi lub systemu.
Na przykład wyzwalacz oparty na zapytaniach, który odczytuje wiersz z bazy danych, wymaga, aby wiersz miał kolumnę ustawioną
isReadnaFALSEwartość . Za każdym razem, gdy wyzwalacz odczytuje wiersz, aplikacja logiki aktualizuje ten wiersz, zmieniając kolumnęisReadzFALSEnaTRUE.To podejście po stronie serwera działa podobnie w przypadku kolejek lub tematów usługi Service Bus, które mają semantyka kolejkowania, gdzie wyzwalacz może odczytywać i blokować komunikat, gdy aplikacja logiki przetwarza komunikat. Po zakończeniu przetwarzania aplikacji logiki wyzwalacz usuwa komunikat z kolejki lub tematu.
Z punktu widzenia odzyskiwania po awarii podczas konfigurowania podstawowych i pomocniczych wystąpień aplikacji logiki upewnij się, że uwzględniasz te zachowania na podstawie tego, czy aplikacja logiki śledzi stan po stronie klienta, czy po stronie serwera:
W przypadku aplikacji logiki, która działa ze stanem po stronie klienta, upewnij się, że aplikacja logiki nie odczytuje tego samego komunikatu więcej niż raz. Tylko jedna lokalizacja może mieć aktywne wystąpienie aplikacji logiki w dowolnym momencie. Upewnij się, że wystąpienie aplikacji logiki w lokalizacji alternatywnej jest nieaktywne lub wyłączone, dopóki wystąpienie podstawowe nie ulegnie awarii w lokalizacji alternatywnej.
Na przykład wyzwalacz usługi Office 365 Outlook zachowuje stan po stronie klienta i śledzi sygnaturę czasową ostatnio odczytywanej wiadomości e-mail, aby uniknąć odczytywania duplikatu.
W przypadku aplikacji logiki, która działa ze stanem po stronie serwera, można skonfigurować wystąpienia aplikacji logiki do odtwarzania ról aktywne-aktywne,w których działają jako konkurujący odbiorcy lub role aktywne-pasywne, w których wystąpienie alternatywne czeka, aż wystąpienie podstawowe ulegnie awarii do lokalizacji alternatywnej.
Na przykład odczyt z kolejki komunikatów, taki jak kolejka usługi Azure Service Bus, używa stanu po stronie serwera, ponieważ usługa kolejkowania utrzymuje blokady komunikatów, aby uniemożliwić innym klientom odczytywanie tych samych komunikatów.
Uwaga
Jeśli aplikacja logiki musi odczytywać komunikaty w określonej kolejności, na przykład z kolejki usługi Service Bus, możesz użyć konkurencyjnego wzorca konsumenta, ale tylko w połączeniu z sesjami usługi Service Bus, który jest również znany jako wzorzec konwoju sekwencyjnego. W przeciwnym razie należy skonfigurować wystąpienia aplikacji logiki z rolami aktywny-pasywny.
Wyzwalacz żądania
Wyzwalacz Żądanie sprawia, że aplikacja logiki może być wywoływana z innych aplikacji, usług i systemów i jest zwykle używana do zapewniania tych możliwości:
Bezpośredni interfejs API REST dla aplikacji logiki, który inni mogą wywoływać
Na przykład użyj wyzwalacza Żądania, aby uruchomić aplikację logiki, aby inne aplikacje logiki mogły wywoływać wyzwalacz przy użyciu akcji Wywołaj przepływ pracy — Logic Apps .
Mechanizm elementu webhook lub wywołania zwrotnego dla aplikacji logiki
Sposób ręcznego uruchamiania operacji użytkownika lub procedur w celu wywołania aplikacji logiki, na przykład przy użyciu skryptu programu PowerShell wykonującego określone zadanie
Z perspektywy odzyskiwania po awarii wyzwalacz żądania jest odbiornikiem pasywnym, ponieważ aplikacja logiki nie wykonuje żadnej pracy i czeka, aż inna usługa lub system jawnie wywoła wyzwalacz. Jako pasywny punkt końcowy można skonfigurować wystąpienia podstawowe i pomocnicze w następujący sposób:
Aktywny-aktywny: oba wystąpienia aktywnie obsługują żądania lub wywołania. Obiekt wywołujący lub router równoważy lub dystrybuuje ruch między tymi wystąpieniami.
Aktywny-pasywny: tylko wystąpienie podstawowe jest aktywne i obsługuje całą pracę, podczas gdy wystąpienie pomocnicze czeka do momentu wystąpienia podstawowego zakłóceń lub awarii. Obiekt wywołujący lub router określa, kiedy wywołać wystąpienie pomocnicze.
Zalecana architektura umożliwia używanie usługi Azure API Management jako serwera proxy dla aplikacji logiki korzystających z wyzwalaczy żądania. Usługa API Management zapewnia wbudowaną odporność między regionami i możliwość kierowania ruchu między wieloma punktami końcowymi.
Wyzwalacz elementu webhook
Wyzwalacz elementu webhook umożliwia aplikacji logiki subskrybowanie usługi przez przekazanie adresu URL wywołania zwrotnego do tej usługi. Aplikacja logiki może następnie nasłuchiwać i czekać, aż określone zdarzenie stanie się w tym punkcie końcowym usługi. Po wystąpieniu zdarzenia usługa wywołuje wyzwalacz elementu webhook przy użyciu adresu URL wywołania zwrotnego, który następnie uruchamia aplikację logiki. Po włączeniu wyzwalacz elementu webhook subskrybuje usługę. Po wyłączeniu wyzwalacz anuluje subskrypcję usługi.
Z perspektywy odzyskiwania po awarii skonfiguruj wystąpienia podstawowe i pomocnicze, które używają wyzwalaczy elementu webhook do odtwarzania ról aktywny-pasywny, ponieważ tylko jedno wystąpienie powinno odbierać zdarzenia lub komunikaty z subskrybowanego punktu końcowego.
Ocena kondycji wystąpienia podstawowego
Aby strategia odzyskiwania po awarii działała, rozwiązanie wymaga sposobów wykonywania tych zadań:
- Sprawdzanie dostępności wystąpienia podstawowego
- Monitorowanie kondycji wystąpienia podstawowego
- Aktywowanie wystąpienia pomocniczego
W tej sekcji opisano jedno rozwiązanie, którego można użyć wprost lub jako podstawy dla własnego projektu. Oto ogólne omówienie wizualizacji dla tego rozwiązania:
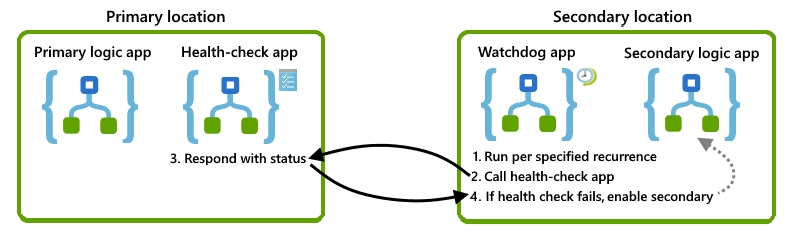
Sprawdzanie dostępności wystąpienia podstawowego
Aby określić, czy wystąpienie podstawowe jest dostępne, uruchomione i może działać, możesz utworzyć aplikację logiki "kontrola kondycji", która znajduje się w tej samej lokalizacji co wystąpienie podstawowe. Następnie możesz wywołać tę aplikację do sprawdzania kondycji z lokalizacji alternatywnej. Jeśli aplikacja do sprawdzania kondycji pomyślnie odpowie, podstawowa infrastruktura usługi Azure Logic Apps w tym regionie jest dostępna i działa. Jeśli aplikacja do sprawdzania kondycji nie odpowie, możesz założyć, że lokalizacja nie jest już w dobrej kondycji.
W tym zadaniu utwórz podstawową aplikację logiki sprawdzania kondycji, która wykonuje następujące zadania:
Odbiera wywołanie z aplikacji watchdog przy użyciu wyzwalacza Żądanie.
Odpowiedz ze stanem wskazującym, czy sprawdzona aplikacja logiki nadal działa przy użyciu akcji Odpowiedź.
Ważne
Aplikacja logiki sprawdzania kondycji musi używać akcji Odpowiedź, aby aplikacja odpowiadała synchronicznie, a nie asynchronicznie.
Opcjonalnie, aby dodatkowo określić, czy lokalizacja podstawowa jest w dobrej kondycji, możesz uwzględnić kondycję innych usług, które wchodzą w interakcję z docelową aplikacją logiki w tej lokalizacji. Po prostu rozwiń aplikację logiki sprawdzania kondycji, aby ocenić kondycję tych innych usług.
Tworzenie aplikacji logiki watchdog
Aby monitorować kondycję wystąpienia podstawowego i wywoływać aplikację logiki sprawdzania kondycji, utwórz aplikację logiki "watchdog" w alternatywnej lokalizacji. Można na przykład skonfigurować aplikację logiki watchdog tak, aby w przypadku wywołania logiki sprawdzania kondycji usługa watchdog mogła wysłać alert do zespołu operacyjnego, aby mógł zbadać błąd i dlaczego wystąpienie podstawowe nie odpowiada.
Ważne
Upewnij się, że aplikacja logiki watchdog znajduje się w lokalizacji, która różni się od lokalizacji podstawowej. Jeśli usługa Azure Logic Apps w lokalizacji podstawowej napotka problemy, przepływ pracy aplikacji logiki watchdog może nie zostać uruchomiony.
W tym zadaniu w lokalizacji pomocniczej utwórz aplikację logiki watchdog, która wykonuje następujące zadania:
Uruchom polecenie na podstawie stałego lub zaplanowanego cyklu przy użyciu wyzwalacza Cykl.
Możesz ustawić cykl na wartość poniżej poziomu tolerancji dla celu czasu odzyskiwania (RTO).
Wywołaj przepływ pracy aplikacji logiki sprawdzania kondycji w lokalizacji podstawowej przy użyciu akcji HTTP.
Możesz również utworzyć bardziej zaawansowaną aplikację logiki watchdog, która po wielu awariach wywołuje inną aplikację logiki, która automatycznie obsługuje przełączanie się do lokalizacji pomocniczej, gdy awaria podstawowa zakończy się niepowodzeniem.
Aktywowanie wystąpienia pomocniczego
Aby automatycznie aktywować wystąpienie pomocnicze, możesz utworzyć aplikację logiki, która wywołuje interfejs API zarządzania, taki jak łącznik usługi Azure Resource Manager, aby aktywować odpowiednie aplikacje logiki w lokalizacji pomocniczej. Możesz rozwinąć aplikację watchdog, aby wywołać tę aplikację logiki aktywacji po wystąpieniu określonej liczby błędów.
Nadmiarowość strefy ze strefami dostępności
W każdym regionie świadczenia usługi Azure strefy dostępności są fizycznie oddzielnymi lokalizacjami, które są odporne na awarie lokalne. Takie awarie mogą wahać się od awarii oprogramowania i sprzętu do zdarzeń, takich jak trzęsienia ziemi, powodzie i pożary. Te strefy osiągają tolerancję dzięki nadmiarowości i logicznej izolacji usług platformy Azure.
Aby zapewnić odporność i dostępność rozproszoną, co najmniej trzy oddzielne strefy dostępności istnieją w dowolnym regionie świadczenia usługi Azure, który obsługuje nadmiarowość strefy i umożliwia jej nadmiarowość. Platforma Azure Logic Apps dystrybuuje te strefy i obciążenia aplikacji logiki w tych strefach. Ta funkcja jest kluczowym wymaganiem w zakresie włączania odpornych architektur i zapewnienia wysokiej dostępności w przypadku awarii centrum danych w regionie.
Obecnie ta funkcja jest dostępna w wersji zapoznawczej i jest dostępna dla nowych aplikacji logiki Zużycie w określonych regionach. Więcej informacji można znaleźć w następującej dokumentacji:
- Ochrona aplikacji logiki Zużycie przed awariami regionów przy użyciu stref nadmiarowości i stref dostępności
- Regiony platformy Azure i strefy dostępności
Zbieranie danych diagnostycznych
Możesz skonfigurować rejestrowanie dla przebiegów aplikacji logiki i wysłać wynikowe dane diagnostyczne do usług takich jak Azure Storage, Azure Event Hubs i Azure Log Analytics w celu dalszej obsługi i przetwarzania.
Jeśli chcesz używać tych danych z usługą Azure Log Analytics, możesz udostępnić dane zarówno dla lokalizacji podstawowej, jak i pomocniczej, konfigurując ustawienia diagnostyczne aplikacji logiki i wysyłając dane do wielu obszarów roboczych usługi Log Analytics. Aby uzyskać więcej informacji, zobacz Konfigurowanie dzienników usługi Azure Monitor i zbieranie danych diagnostycznych dla usługi Azure Logic Apps.
Jeśli chcesz wysłać dane do usługi Azure Storage lub Azure Event Hubs, możesz udostępnić dane zarówno dla lokalizacji podstawowej, jak i pomocniczej, konfigurując nadmiarowość geograficzną. Więcej informacji można znaleźć w tych artykułach:
Następne kroki
- Projektowanie niezawodnych aplikacji platformy Azure
- Lista kontrolna dotycząca odporności dla określonych usług platformy Azure
- Zarządzanie danymi pod kątem odporności na platformie Azure
- Tworzenie kopii zapasowych i odzyskiwanie po awarii dla aplikacji platformy Azure
- Odzyskiwanie po zakłóceniu usługi w całym regionie
- Umowy dotyczące poziomu usług (SLA) firmy Microsoft dla usług platformy Azure
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla