Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dotyczy: Azure Logic Apps (Zużycie + Standardowa)
Czasami trzeba przekonwertować zawartość na tokeny, które są wyrazami lub fragmentami znaków, albo podzielić duży dokument na mniejsze elementy, zanim będzie można użyć tej zawartości z określonymi akcjami. Na przykład Wyszukiwanie AI platformy Azure lub Azure OpenAI akcje oczekują tokenizowanych danych wejściowych i mogą obsługiwać tylko ograniczoną liczbę tokenów.
W tych scenariuszach użyj akcji Operacje na danych o nazwach Przeanalizuj dokument i Podziel tekst na fragmenty w przepływie pracy aplikacji logiki. Te działania odpowiednio przekształcają zawartość, taką jak dokument PDF, plik CSV, plik Excel itd., w tokenizowany ciąg wyjściowy, a następnie dzielą ten ciąg na elementy na podstawie liczby tokenów. Następnie możesz odwoływać się do tych danych wyjściowych i używać ich z kolejnymi akcjami w przepływie pracy.
Wskazówka
Aby dowiedzieć się więcej, możesz zadać Azure Copilot następujące pytania:
- Co to jest token w sztucznej inteligencji?
- Co to są tokenizowane dane wejściowe?
- Co to są dane wyjściowe tokenizowanego ciągu?
- Co to jest analizowanie w sztucznej inteligencji?
- Co to jest fragmentowanie w sztucznej inteligencji?
Aby znaleźć Azure Copilot, na pasku narzędzi Azure portal wybierz Copilot.
W tym przewodniku pokazano, jak dodawać i konfigurować akcje do analizowania dokumentów i fragmentowania tekstu w przepływie pracy.
Znane problemy i ograniczenia
W przepływach pracy dotyczących zużycia, akcja 'Parsuj dokument' jest dostępna tylko w następujących regionach Azure:
- Australia Wschodnia
- Brazylia Południowa
- Azja Wschodnia
- Wschodnie stany USA
- Wschodnie stany USA 2
- Europa Północna
- Południowo-środkowe stany USA
- Azja Południowo-Wschodnia
- Szwecja Środkowa
- Zachodnie stany USA 2
- Zachodnie stany USA 3
- Południowe Zjednoczone Królestwo
Te regiony zapewniają połączenia ze źródłem danych, śledzenie dokumentów, fragmentowanie dokumentów, obsługę modeli osadzania Azure OpenAI oraz wbudowaną obsługę indeksowania na potrzeby ściągania danych. Aby uzyskać więcej informacji, zobacz Automatyzacja indeksowania w wyszukiwarce AI z przepływami pracy w Azure Logic Apps.
Obecnie akcje parsowania dokumentu i dzielenia tekstu na fragmenty nie obsługują plików na hostingu, na przykład plików mainframe i plików binarnych midrange, takich jak pliki metody dostępu do wirtualnego magazynu (VSAM). Zamiast tego, jeśli pracujesz z przepływami pracy w warstwie Standard, możesz użyć wbudowanej akcji Plik hosta IBM o nazwie Przeanalizuj zawartość pliku hosta.
Wymagania wstępne
Konto i subskrypcja Azure. Jeśli nie masz subskrypcji Azure, podpisaj bezpłatne konto Azure.
Przepływ pracy aplikacji logicznej typu Konsumpcja lub Standardowa z istniejącym wyzwalaczem, ponieważ operacje Analizowanie dokumentu i Dzielenie tekstu na fragmenty są dostępne tylko jako akcje. Upewnij się, że akcja pobierająca zawartość, którą chcesz przeanalizować lub fragment poprzedza te operacje danych.
Analizowanie dokumentu
Akcja Parse a document konwertuje zawartość, taką jak dokument PDF, plik CSV, plik Excel itd., na tokenizowany ciąg. W tym przykładzie załóżmy, że przepływ pracy rozpoczyna się od wyzwalacza Żądania o nazwie Po odebraniu żądania HTTP. Ten wyzwalacz oczekuje na odebranie żądania HTTP wysłanego z innego składnika, takiego jak funkcja Azure, inny przepływ pracy aplikacji logiki itd. Żądanie HTTP zawiera adres URL nowego przesłanego dokumentu, który jest dostępny dla procesu w celu pobrania i przeanalizowania. Akcja HTTP natychmiast następuje po wyzwalaczu i wysyła żądanie HTTP do adresu URL dokumentu i zwraca zawartość dokumentu z lokalizacji przechowywania.
Jeśli używasz innych źródeł zawartości, takich jak Azure Blob Storage, SharePoint, OneDrive, System plików, FTP itd., możesz sprawdzić, czy wyzwalacze są dostępne dla tych źródeł. Możesz również sprawdzić, czy działania są dostępne, aby pobrać treść w tych źródłach. Aby uzyskać więcej informacji, zobacz Wbudowane operacje i Łączniki zarządzane.
W portalu Azure otwórz zasób logiki aplikacji i przepływ pracy w projektancie.
W obszarze istniejącego wyzwalacza i akcji wykonaj następujące ogólne kroki, aby dodać akcję Operacje danych o nazwie Przeanalizuj dokument do przepływu pracy.
W projektancie wybierz akcję Przeanalizuj dokument .
Po otworze okienka informacji o akcji na karcie Parametry we właściwości Zawartość dokumentu określ zawartość do przeanalizowana, wykonując następujące kroki:
Wybierz wewnątrz pola Zawartość dokumentu.
Pojawią się opcje listy zawartości dynamicznej (ikona błyskawicy) i edytora wyrażeń (ikona funkcji).
Aby wybrać dane wyjściowe z poprzedniej akcji, wybierz listę zawartości dynamicznej.
Aby utworzyć wyrażenie, które manipuluje danymi wyjściowymi z poprzedniej akcji, wybierz edytor wyrażeń.
Przykład ten kontynuuje się, wybierając ikonę pioruna dla listy dynamicznej zawartości.
Po otworze listy zawartości dynamicznej wybierz dane wyjściowe z poprzedniej operacji.
W tym przykładzie akcja Przeanalizuj dokument odwołuje się do danych wyjściowych Treści z akcji HTTP .
Dane wyjściowe Treść są teraz wyświetlane w polu Zawartość dokumentu:
W ramach akcji Przeanalizuj dokument dodaj akcje, które mają współpracować z wyjściowym ciągiem znaków, na przykład Podziel tekst, który opisano w dalszej części tego przewodnika.
Analizowanie dokumentu — odniesienie
Parametry
| Nazwa/nazwisko | Wartość | Typ danych | opis | Ograniczenie |
|---|---|---|---|---|
| Zawartość dokumentu | < zawartość do analizy> | Dowolne | Zawartość do przeanalizowania. | Brak |
Dane wyjściowe
| Nazwa/nazwisko | Typ danych | opis |
|---|---|---|
| Przeanalizowany tekst wyniku | Tablica ciągów | Tablica ciągów. |
| Przeanalizowany wynik | Objekt | Obiekt zawierający cały przeanalizowany tekst. |
Fragment tekstu
Akcja tekst w kawałkach dzieli zawartość na mniejsze fragmenty, aby ułatwić użycie w kolejnych krokach bieżącego przepływu pracy. Poniższe kroki opierają się na przykładzie z sekcji Parse a document i dzielą dane wyjściowe ciągów tokenów w celu wykorzystania w operacjach sztucznej inteligencji Azure, które oczekują tokenizowanych, małych fragmentów zawartości.
Uwaga
Poprzednie akcje korzystające z fragmentowania nie wpływają na akcję Fragment tekstu, ani akcja Fragment tekstu nie wpływa na kolejne akcje, które używają fragmentowania.
W portalu Azure otwórz zasób logiki aplikacji i przepływ pracy w projektancie.
Pod akcją Parsowanie dokumentuwykonaj następujące ogólne kroki, aby dodać akcję Operacje danych o nazwie Dzielenie tekstu.
W projektancie wybierz akcję Fragment tekstu .
Po otwarciu panelu informacji o akcji, na karcie Parametry, w przypadku właściwości Strategia fragmentowania, wybierz TokenSize jako metodę fragmentowania, jeśli nie została jeszcze wybrana.
Strategia opis Rozmiar tokenu Podziel określoną zawartość na podstawie liczby tokenów. Po wybraniu strategii kliknij wewnątrz pola tekstowego, aby określić zawartość do dzielenia na fragmenty.
Pojawią się opcje listy zawartości dynamicznej (ikona błyskawicy) i edytora wyrażeń (ikona funkcji).
Aby wybrać dane wyjściowe z poprzedniej akcji, wybierz listę zawartości dynamicznej.
Aby utworzyć wyrażenie, które manipuluje danymi wyjściowymi z poprzedniej akcji, wybierz edytor wyrażeń.
Przykład ten kontynuuje się, wybierając ikonę pioruna dla listy dynamicznej zawartości.
Po otworze listy zawartości dynamicznej wybierz dane wyjściowe z poprzedniej operacji.
W tym przykładzie akcja fragmentu tekstu odwołuje się do danych wyjściowych przeanalizowanego tekstu wynikowego z akcji Przeanalizuj dokument .
W polu Tekst są teraz wyświetlane dane wyjściowe przeanalizowanego wyniku akcji.
Ukończ konfigurację dla akcji Chunk tekstu na podstawie wybranej strategii i scenariusza. Aby uzyskać więcej informacji, zobacz Fragment tekstu – odwołanie.
Gdy dodasz inne akcje, które oczekują i wykorzystują tokenizowane dane wejściowe, takie jak akcje Azure AI, treść wejściowa jest sformatowana dla ułatwienia przetwarzania.
Tekst fragmentu — odniesienie
Parametry
| Nazwa/nazwisko | Wartość | Typ danych | opis | Limity |
|---|---|---|---|---|
| Strategia fragmentowania | Rozmiar tokenu | Wyliczenie typu string | Podziel zawartość na podstawie liczby tokenów. Ustawienie domyślne: TokenSize |
Nie dotyczy |
| Tekst | < podział zawartości na fragmenty> | Dowolne | Zawartość do dzielenia na części. | Zobacz Podręcznik referencyjny dotyczący limitów i konfiguracji |
| Model kodowania | < metoda kodowania> | Wyliczenie typu string | Model kodowania do użycia: - Domyślnie: cl100k_base (gpt4, gpt-3,5-turbo, gpt-35-turbo) - r50k_base (gpt-3) - p50k_base (gpt-3) - p50k_edit (gpt-3) - cl200k_base (gpt-4o) Aby uzyskać więcej informacji, zobacz OpenAI — Modele — omówienie. |
Nie dotyczy |
| Rozmiar tokenu | < max-tokens-per-chunk> | Integer | Maksymalna liczba tokenów na fragment zawartości. Ustawienie domyślne: Brak |
Minimum: 1 Maksimum: 8000 |
| PageOverlapLength | < liczba nakładających się znaków> | Integer | Liczba znaków z końca poprzedniego fragmentu do uwzględnienia w następnym fragmentzie. To ustawienie pomaga uniknąć utraty ważnych informacji podczas dzielenia zawartości na fragmenty i zachowuje ciągłość i kontekst między fragmenty. Ustawienie domyślne: 0 — nie istnieją nakładające się znaki. |
Minimum: 0 |
Wskazówka
Aby dowiedzieć się więcej, możesz zadać Azure Copilot następujące pytania:
- Co to jest PageOverlapLength we fragmentowaniu?
- Czym jest kodowanie w usłudze Azure AI?
Aby znaleźć Azure Copilot, na pasku narzędzi Azure portal wybierz Copilot.
Dane wyjściowe
| Nazwa/nazwisko | Typ danych | opis |
|---|---|---|
| Fragmentowane elementy tekstowe wyniku | Tablica ciągów | Tablica ciągów. |
| Element elementów tekstowych wynikowych fragmentowanych | String | Pojedynczy ciąg w tablicy. |
| Wynik fragmentowany | Objekt | Obiekt, który zawiera cały fragmentowany tekst. |
Przykładowy przepływ pracy
Poniższy przykład zawiera inne akcje, które tworzą kompletny wzorzec przepływu pracy w celu pozyskiwania danych z dowolnego źródła:
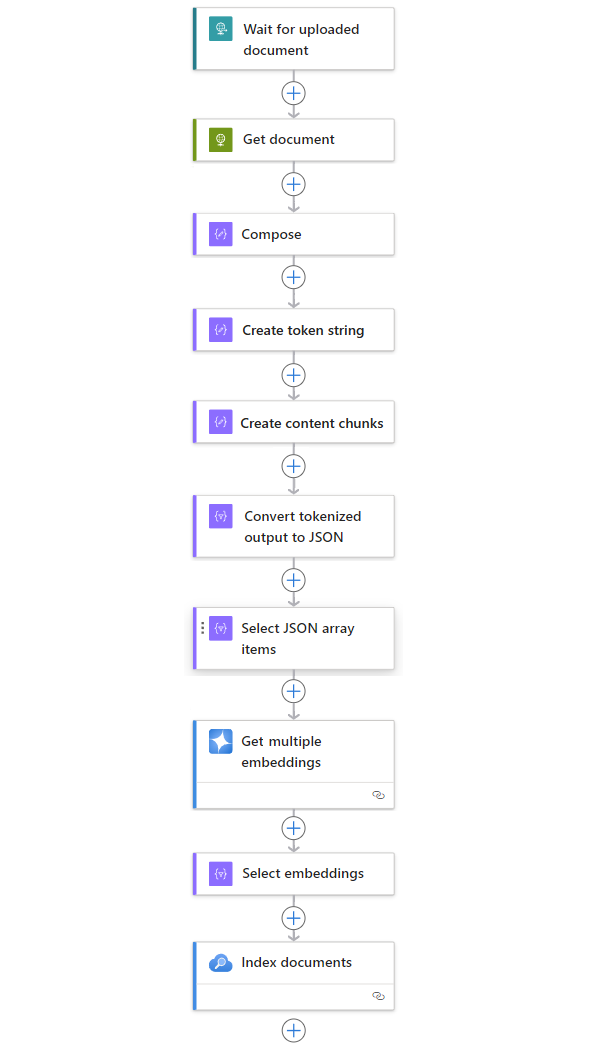
| Krok | Zadanie | Operacja bazowa | opis |
|---|---|---|---|
| 1 | Zaczekaj lub sprawdź nową zawartość. | Po odebraniu żądania HTTP | Wyzwalacz, który albo sonduje, albo czeka na nadejście nowych danych, w oparciu o zaplanowany cykl lub reagując na określone zdarzenia. Takie zdarzenie może być nowym plikiem przesłanym do określonego systemu przechowywania, takiego jak Azure Blob Storage, SharePoint, OneDrive, System plików, FTP itd. W tym przykładzie operacja wyzwalacza żądania czeka na żądanie HTTP lub HTTPS wysłane z innego punktu końcowego. Żądanie zawiera adres URL nowego przekazanego dokumentu. |
| 2 | Pobierz zawartość. | HTTP | Akcja HTTP , która pobiera przekazany dokument przy użyciu adresu URL pliku z danych wyjściowych wyzwalacza. |
| 3 | Utwórz szczegóły dokumentu. | Redaguj | Akcja Operacje na danych, która łączy różne elementy. Ten przykład łączy dane dotyczące pary klucz-wartość dokumentu. |
| 4 | Utwórz ciąg tokenu. | Analizowanie dokumentu | Akcja Operacje na danych, która tworzy tokenizowany ciąg przy użyciu danych wyjściowych akcji Komponuj. |
| 5 | Tworzenie fragmentów zawartości. | Tekst fragmentu | Akcja 'Operacje na danych' dzieląca ciąg tokenu na fragmenty w oparciu o liczbę tokenów na jednostkę zawartości. |
| 6 | Konwertowanie tokenizowanego i fragmentowanego tekstu na format JSON. | Przeanalizuj dane JSON | Akcja Operacje na danych, która konwertuje wynik podzielony na części na tablicę JSON. |
| 7 | Wybierz elementy tablicy JSON. | Wybierz | Akcja Operacji na danych, która wybiera wiele elementów z tablicy JSON. |
| 8 | Wygeneruj osadzanie. | Pobierz wiele osadzeń | Akcja Azure OpenAI która tworzy osadzanie dla każdego elementu tablicy JSON. |
| 9 | Wybierz osadzenia i inne informacje. | Wybierz | Akcja Operacje danych, która wybiera embeddingi i inne informacje o dokumencie. |
| 10 | Indeksowanie danych. | Indeksowanie dokumentów | Akcja Wyszukiwanie AI platformy Azure która indeksuje dane na podstawie każdego wybranego osadzania. |