Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule opisano składnik w projektancie usługi Azure Machine Learning.
Ten składnik służy do mierzenia dokładności wytrenowanego modelu. Udostępniasz zestaw danych zawierający wyniki wygenerowane na podstawie modelu, a składnik Evaluate Model oblicza zestaw metryk oceny standardu branżowego.
Metryki zwracane przez polecenie Evaluate Model zależą od typu modelu, który oceniasz:
- Modele klasyfikacji
- Modele regresji
- Modele klastrowania
Napiwek
Jeśli dopiero zaczynasz oceniać modele, zalecamy serię wideo dr Stephen Elston, w ramach kursu uczenia maszynowego z EdX.
Jak używać funkcji Evaluate Model
Połącz dane wyjściowe scored dataset z danymi wyjściowymi Score Model (Generowanie wyników dla modelu) lub Result (Wynik) danych wyjściowych polecenia Assign Data to Clusters (Przypisywanie danych do klastrów) z lewym portem wejściowym elementu Evaluate Model (Ocena modelu).
Uwaga
Jeśli używasz składników, takich jak "Select Columns in Dataset" (Wybieranie kolumn w zestawie danych), aby wybrać część wejściowego zestawu danych, upewnij się, że kolumna Rzeczywista etykieta (używana w trenowaniu), kolumna "Scored Probabilities" (Obliczone prawdopodobieństwa) i kolumna "Scored Labels" (Obliczone etykiety) istnieją, aby obliczyć metryki, takie jak AUC, dokładność klasyfikacji binarnej/wykrywania anomalii. Rzeczywista kolumna etykiety", kolumna "Scored Labels" istnieje, aby obliczyć metryki dla klasyfikacji/regresji wieloklasowej. Kolumna "Przypisania", kolumny "DistancesToClusterCenter no.X" (X to indeks centroid, od 0, ..., liczba centroidów-1) istnieją, aby obliczyć metryki dla klastrowania.
Ważne
- Aby ocenić wyniki, wyjściowy zestaw danych powinien zawierać określone nazwy kolumn wyników, które spełniają wymagania dotyczące składnika Evaluate Model.
- Kolumna będzie traktowana
Labelsjako rzeczywiste etykiety. - W przypadku zadania regresji zestaw danych do oceny musi zawierać jedną kolumnę o nazwie
Regression Scored Labels, która reprezentuje ocenione etykiety. - W przypadku zadania klasyfikacji binarnej zestaw danych do oceny musi zawierać dwie kolumny o nazwie
Binary Class Scored Labels,Binary Class Scored Probabilitiesktóre reprezentują odpowiednio etykiety ocenione i prawdopodobieństwa. - W przypadku zadania z wieloma klasyfikacjami zestaw danych do oceny musi zawierać jedną kolumnę o nazwie
Multi Class Scored Labels, która reprezentuje ocenione etykiety. Jeśli dane wyjściowe składnika nadrzędnego nie mają tych kolumn, należy zmodyfikować je zgodnie z powyższymi wymaganiami.
[Opcjonalnie] Połącz dane wyjściowe scored dataset z danymi wyjściowymi Score Model (Generowanie wyników dla modelu ) lub Result (Wynik) danych wyjściowych pola Assign Data to Clusters (Przypisywanie danych do klastrów) dla drugiego modelu z właściwym portem wejściowym elementu Evaluate Model (Ocena modelu). Możesz łatwo porównać wyniki z dwóch różnych modeli na tych samych danych. Dwa algorytmy wejściowe powinny być tego samego typu algorytmu. Możesz też porównać wyniki z dwóch różnych przebiegów na tych samych danych z różnymi parametrami.
Uwaga
Typ algorytmu odnosi się do "Klasyfikacja dwuklasowa", "Klasyfikacja wieloklasowa", "Regresja", "Klasterowanie" w obszarze "Algorytmy uczenia maszynowego".
Prześlij potok, aby wygenerować wyniki oceny.
Wyniki
Po uruchomieniu polecenia Evaluate Model (Ocena modelu) wybierz składnik, aby otworzyć panel nawigacyjny Evaluate Model (Ocena modelu ) po prawej stronie. Następnie wybierz kartę Dane wyjściowe i dzienniki , a na tej karcie sekcja Dane wyjściowe zawiera kilka ikon. Ikona Wizualizacja ma ikonę wykresu słupkowego i jest pierwszym sposobem wyświetlenia wyników.
W przypadku klasyfikacji binarnej po kliknięciu ikony Wizualizacja można zwizualizować macierz pomyłek binarnych. W przypadku wielu klasyfikacji można znaleźć plik wykresu macierzy pomyłek na karcie Dane wyjściowe i dzienniki , jak pokazano poniżej:
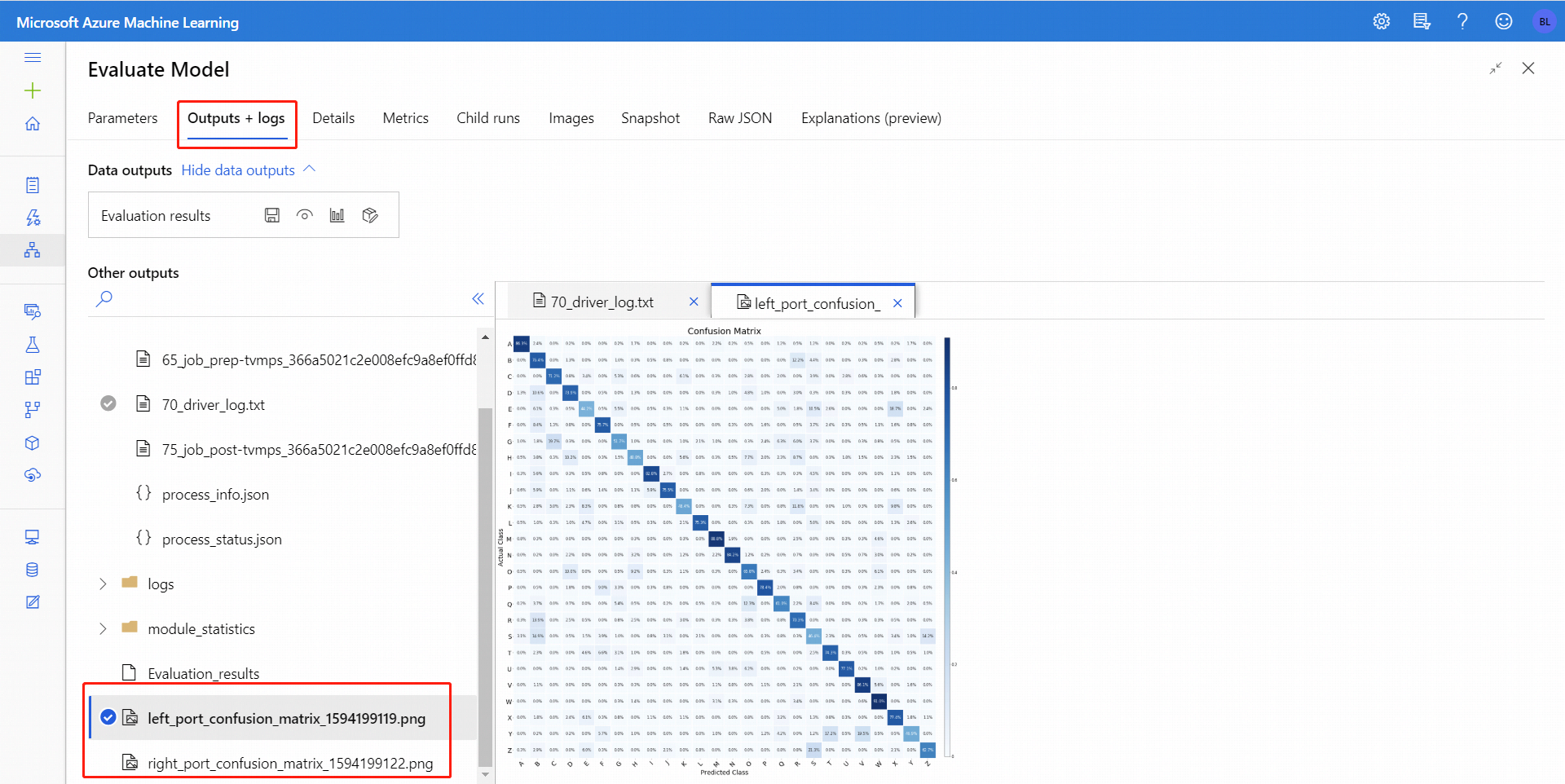
Jeśli połączysz zestawy danych z obydwoma danymi wejściowymi funkcji Evaluate Model, wyniki będą zawierać metryki dla obu zestawów danych lub obu modeli. Model lub dane dołączone do lewego portu są prezentowane najpierw w raporcie, a następnie metryki dla zestawu danych lub modelu dołączonego na prawym porcie.
Na przykład poniższa ilustracja przedstawia porównanie wyników z dwóch modeli klastrowania, które zostały utworzone na tych samych danych, ale z różnymi parametrami.
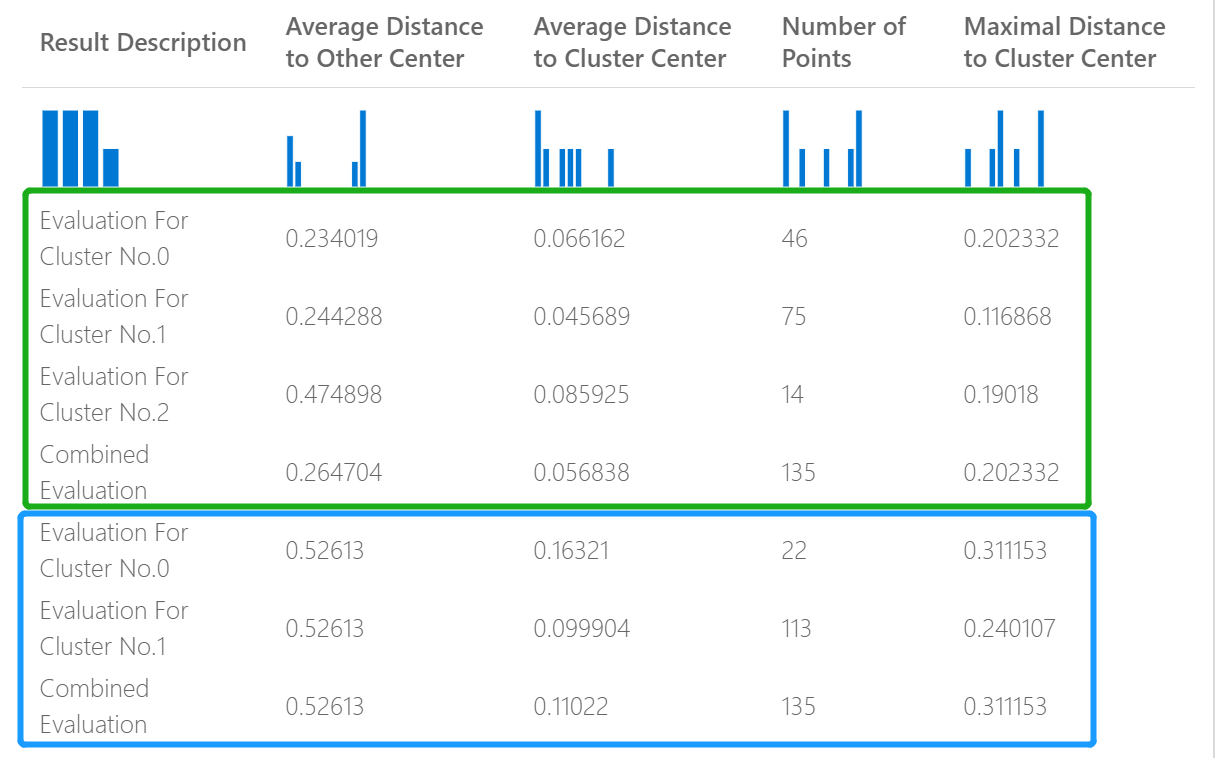
Ponieważ jest to model klastrowania, wyniki oceny są inne niż w przypadku porównywania wyników z dwóch modeli regresji lub porównywania dwóch modeli klasyfikacji. Jednak ogólna prezentacja jest taka sama.
Metryki
W tej sekcji opisano metryki zwracane dla określonych typów modeli obsługiwanych do użycia z funkcją Evaluate Model:
Metryki dla modeli klasyfikacji
Podczas oceniania modeli klasyfikacji binarnej są zgłaszane następujące metryki.
Dokładność mierzy dobroć modelu klasyfikacji jako proporcję wyników rzeczywistych do łącznej liczby przypadków.
Precyzja to proporcja wyników rzeczywistych dla wszystkich wyników dodatnich. Precyzja = TP/(TP+FP)
Kompletność to ułamek całkowitej ilości odpowiednich wystąpień, które zostały rzeczywiście pobrane. Przypomnienie = TP/(TP+FN)
Wynik F1 jest obliczany jako średnia ważona dokładności i kompletność z zakresu od 0 do 1, gdzie idealna wartość wyniku F1 wynosi 1.
Funkcja AUC mierzy obszar pod krzywą wykreślowaną z wartościami prawdziwie dodatnimi na osi y i fałszywie dodatnimi na osi x. Ta metryka jest przydatna, ponieważ udostępnia pojedynczą liczbę, która umożliwia porównywanie modeli różnych typów. Usługa AUC jest zmienną typu classification-threshold-invariant. Mierzy jakość przewidywań modelu niezależnie od wybranego progu klasyfikacji.
Metryki dla modeli regresji
Metryki zwracane dla modeli regresji zostały zaprojektowane w celu oszacowania ilości błędu. Model jest uważany za dopasowany do źródła danych, jeśli różnica między obserwowanych i przewidywanych wartości jest niewielka. Jednak patrząc na wzorzec reszt (różnica między dowolnym przewidywanym punktem a odpowiadającą jej rzeczywistą wartością) może wiele powiedzieć o potencjalnych stronniczości w modelu.
Następujące metryki są zgłaszane do oceny modeli regresji liniowej. Inne modele ruchu wychodzącego, takie jak regresja kwantylu fast forest, mogą mieć różne metryki.
Średni błąd bezwzględny (MAE) mierzy, w jaki sposób zbliżone są przewidywania do rzeczywistych wyników. W związku z tym niższy wynik jest lepszy.
Główny błąd średniokwadratowy (RMSE) tworzy pojedynczą wartość, która podsumowuje błąd w modelu. Dzięki squaring różnicy metryka pomija różnicę między nadmiernym przewidywaniem i niedostatecznym przewidywaniem.
Względny błąd bezwzględny (RAE) to względna różnica bezwzględna między oczekiwaną i rzeczywistą wartością; względna, ponieważ średnia różnica jest podzielona przez średnią arytmetyczną.
Względny błąd kwadratu (RSE) podobnie normalizuje całkowity błąd kwadratu przewidywanych wartości, dzieląc przez łączny błąd kwadratowy rzeczywistych wartości.
Współczynnik determinacji, często określany jako R2, reprezentuje moc predykcyjną modelu jako wartość z zakresu od 0 do 1. Zero oznacza, że model jest losowy (nic nie wyjaśnia); 1 oznacza, że istnieje idealne dopasowanie. Należy jednak zachować ostrożność podczas interpretowania wartości R2 , ponieważ niskie wartości mogą być całkowicie normalne, a wysokie wartości mogą być podejrzane.
Metryki dla modeli klastrowania
Ponieważ modele klastrowania różnią się znacznie od modeli klasyfikacji i regresji pod wieloma względami, funkcja Evaluate Model zwraca również inny zestaw statystyk dla modeli klastrowania.
Statystyki zwrócone dla modelu klastrowania opisują liczbę punktów danych przypisanych do każdego klastra, ilość separacji między klastrami oraz sposób ścisłego łączenia punktów danych w każdym klastrze.
Statystyki modelu klastrowania są uśrednione dla całego zestawu danych z dodatkowymi wierszami zawierającymi statystyki dla klastra.
Następujące metryki są zgłaszane do oceny modeli klastrowania.
Wyniki w kolumnie Average Distance to Other Center reprezentują, jak blisko, średnio, każdy punkt w klastrze jest centroidami wszystkich innych klastrów.
Wyniki w kolumnie Average Distance to Cluster Center (Średnia odległość do centrum klastra) reprezentują bliskość wszystkich punktów w klastrze do centroid tego klastra.
W kolumnie Liczba punktów pokazano, ile punktów danych zostało przypisanych do każdego klastra wraz z całkowitą całkowitą liczbą punktów danych w dowolnym klastrze.
Jeśli liczba punktów danych przypisanych do klastrów jest mniejsza niż całkowita liczba dostępnych punktów danych, oznacza to, że nie można przypisać punktów danych do klastra.
Wyniki w kolumnie Maximal Distance to Cluster Center reprezentują maksymalną odległość między każdym punktem a centroidem klastra tego punktu.
Jeśli ta liczba jest wysoka, może to oznaczać, że klaster jest szeroko rozproszony. Należy przejrzeć tę statystykę wraz z średnią odległością do centrum klastra, aby określić rozkład klastra.
Wynik połączonej oceny w dolnej części każdej sekcji wyników zawiera listę uśrednionych wyników dla klastrów utworzonych w tym konkretnym modelu.
Następne kroki
Zobacz zestaw składników dostępnych dla usługi Azure Machine Learning.