Wybór funkcji oparty na filtrze
W tym artykule opisano sposób używania składnika Wyboru funkcji opartego na filtrach w projektancie usługi Azure Machine Learning. Ten składnik pomaga zidentyfikować kolumny w wejściowym zestawie danych, które mają największą moc predykcyjną.
Ogólnie rzecz biorąc, wybór funkcji odnosi się do procesu stosowania testów statystycznych do danych wejściowych, biorąc pod uwagę określone dane wyjściowe. Celem jest ustalenie, które kolumny są bardziej predykcyjne danych wyjściowych. Składnik Wybór funkcji oparty na filtrach udostępnia wiele algorytmów wyboru funkcji do wyboru. Składnik zawiera metody korelacji, takie jak korelacja Pearsona i wartości chi kwadratu.
Jeśli używasz składnika Wyboru funkcji opartej na filtrze, należy podać zestaw danych i zidentyfikować kolumnę zawierającą etykietę lub zmienną zależną. Następnie należy określić jedną metodę do użycia w mierzeniu ważności cech.
Składnik generuje zestaw danych zawierający najlepsze kolumny funkcji sklasyfikowane według mocy predykcyjnej. Zwraca również nazwy funkcji i ich wyniki z wybranej metryki.
Wybór funkcji opartych na filtrach jest
Ten składnik wyboru funkcji jest nazywany "opartym na filtrach", ponieważ używasz wybranej metryki do znajdowania nieistotnych atrybutów. Następnie odfiltrujesz nadmiarowe kolumny z modelu. Wybierasz pojedynczą miarę statystyczną, która odpowiada danym, a składnik oblicza wynik dla każdej kolumny funkcji. Kolumny są zwracane według ich wyników funkcji.
Wybierając odpowiednie funkcje, możesz potencjalnie zwiększyć dokładność i wydajność klasyfikacji.
Zazwyczaj do tworzenia modelu predykcyjnego są używane tylko kolumny z najlepszymi wynikami. Kolumny z niskimi wynikami wyboru funkcji można pozostawić w zestawie danych i ignorować podczas tworzenia modelu.
Jak wybrać metrykę wyboru funkcji
Składnik wyboru funkcji Filter-Based udostępnia różne metryki do oceny wartości informacji w każdej kolumnie. Ta sekcja zawiera ogólny opis każdej metryki i sposób jej stosowania. Dodatkowe wymagania dotyczące używania każdej metryki można znaleźć w uwagach technicznych oraz w instrukcjach dotyczących konfigurowania poszczególnych składników.
Korelacja Pearsona
Statystyka korelacji Pearsona lub współczynnik korelacji Pearsona jest również znana w modelach statystycznych jako
rwartość. W przypadku dowolnych dwóch zmiennych zwraca wartość, która wskazuje siłę korelacji.Współczynnik korelacji Pearsona jest obliczany przez pobranie wariancji dwóch zmiennych i podzielenie przez iloczyn ich odchyleń standardowych. Zmiany skali w dwóch zmiennych nie wpływają na współczynnik.
Chi kwadrat
Dwukierunkowy test chi-squared jest metodą statystyczną, która mierzy, jak blisko oczekiwane wartości są rzeczywiste wyniki. Metoda zakłada, że zmienne są losowe i pobierane z odpowiedniej próbki zmiennych niezależnych. Wynikowa statystyka chi kwadrat wskazuje, jak daleko są wyniki od oczekiwanego (losowego) wyniku.
Porada
Jeśli potrzebujesz innej opcji dla niestandardowej metody wyboru funkcji, użyj składnika Wykonaj skrypt języka R .
Jak skonfigurować wybór funkcji Filter-Based
Należy wybrać standardową metrykę statystyczną. Składnik oblicza korelację między parą kolumn: kolumną etykiety i kolumną funkcji.
Dodaj składnik wyboru funkcji Filter-Based do potoku. Można ją znaleźć w kategorii Wybór funkcji w projektancie.
Połącz wejściowy zestaw danych zawierający co najmniej dwie kolumny, które są potencjalnymi funkcjami.
Aby upewnić się, że kolumna jest analizowana i generowany jest wynik funkcji, użyj składnika Edytuj metadane , aby ustawić atrybut IsFeature .
Ważne
Upewnij się, że kolumny, które podajesz jako dane wejściowe, są potencjalnymi funkcjami. Na przykład kolumna zawierająca jedną wartość nie ma wartości informacyjnej.
Jeśli wiesz, że niektóre kolumny spowodują nieprawidłowe funkcje, możesz je usunąć z zaznaczenia kolumny. Możesz również użyć składnika Edytuj metadane , aby oznaczyć je jako kategorialne.
W obszarze Metoda oceniania funkcji wybierz jedną z następujących ustalonych metod statystycznych do użycia podczas obliczania wyników.
Metoda Wymagania Korelacja Pearsona Etykieta może być tekstem lub liczbą. Funkcje muszą być numeryczne. Chi kwadrat Etykiety i funkcje mogą być tekstowe lub liczbowe. Ta metoda służy do obliczania ważności funkcji dla dwóch kolumn podzielonych na kategorie. Porada
Jeśli zmienisz wybraną metryki, wszystkie inne wybory zostaną zresetowane. Pamiętaj, aby najpierw ustawić tę opcję.
Wybierz opcję Operuj tylko na kolumnach funkcji , aby wygenerować wynik tylko dla kolumn, które zostały wcześniej oznaczone jako funkcje.
Jeśli ta opcja zostanie wyczyszczyła, składnik utworzy ocenę dla dowolnej kolumny, która w przeciwnym razie spełnia kryteria, do liczby kolumn określonych w polu Liczba żądanych funkcji.
W obszarze Kolumna docelowa wybierz pozycję Uruchom selektor kolumny , aby wybrać kolumnę etykiety według nazwy lub według jej indeksu. (Indeksy są oparte na jednym).
Kolumna etykiety jest wymagana dla wszystkich metod obejmujących korelację statystyczną. Składnik zwraca błąd czasu projektowania, jeśli nie wybierzesz kolumny etykiety ani wielu kolumn etykiet.W polu Liczba żądanych funkcji wprowadź liczbę kolumn funkcji, które mają zostać zwrócone w wyniku:
Minimalna liczba funkcji, które można określić, to jedna, ale zalecamy zwiększenie tej wartości.
Jeśli określona liczba żądanych funkcji jest większa niż liczba kolumn w zestawie danych, zwracane są wszystkie funkcje. Zwracane są nawet funkcje z zerowymi wynikami.
Jeśli określisz mniejszą liczbę kolumn wyników niż kolumny funkcji, funkcje są klasyfikowane według malejącego wyniku. Zwracane są tylko najważniejsze funkcje.
Prześlij potok.
Ważne
Jeśli zamierzasz użyć wnioskowania funkcji opartego na filtrach , musisz użyć funkcji Select Columns Transform (Wybieranie kolumn), aby zapisać wybrany wynik funkcji i zastosuj przekształcenie , aby zastosować wybrane przekształcenie funkcji do zestawu danych oceniania.
Zapoznaj się z poniższym zrzutem ekranu, aby skompilować potok, aby upewnić się, że wybory kolumn są takie same dla procesu oceniania.
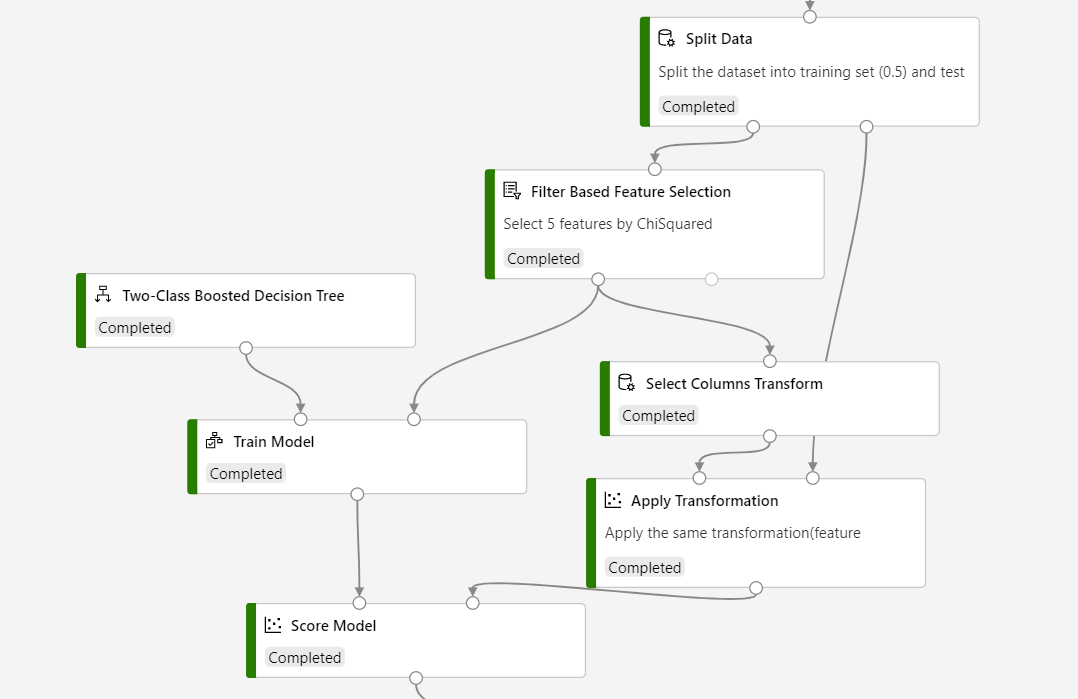
Wyniki
Po zakończeniu przetwarzania:
Aby wyświetlić pełną listę kolumn funkcji analizowanych i ich wyników, kliknij prawym przyciskiem myszy składnik i wybierz polecenie Visualize (Wizualizacja).
Aby wyświetlić zestaw danych na podstawie kryteriów wyboru funkcji, kliknij prawym przyciskiem myszy składnik i wybierz polecenie Wizualizuj.
Jeśli zestaw danych zawiera mniej kolumn niż oczekiwano, sprawdź ustawienia składnika. Sprawdź również typy danych kolumn podanych jako dane wejściowe. Jeśli na przykład ustawisz wartość Liczba żądanych funkcji na 1, wyjściowy zestaw danych zawiera tylko dwie kolumny: kolumnę etykiety i najbardziej sklasyfikowaną kolumnę funkcji.
Uwagi techniczne
Szczegóły implementacji
Jeśli używasz korelacji Pearsona z funkcją liczbową i etykietą kategorii, wynik funkcji jest obliczany w następujący sposób:
Dla każdego poziomu w kolumnie kategorii oblicz warunkową średnią kolumny liczbowej.
Skoreluj kolumnę średnich warunkowych z kolumną liczbową.
Wymagania
Nie można wygenerować wyniku wyboru funkcji dla dowolnej kolumny wyznaczonej jako kolumna Etykieta lub Wynik .
Jeśli spróbujesz użyć metody oceniania z kolumną typu danych, którego metoda nie obsługuje, składnik zgłosi błąd. Lub do kolumny zostanie przypisany wynik zerowy.
Jeśli kolumna zawiera wartości logiczne (true/false), są przetwarzane jako
True = 1iFalse = 0.Kolumna nie może być funkcją, jeśli została wyznaczona jako etykieta lub wynik.
Jak są obsługiwane brakujące wartości
Nie można określić jako kolumny docelowej (etykiety) dowolnej kolumny, która zawiera wszystkie brakujące wartości.
Jeśli kolumna zawiera brakujące wartości, składnik ignoruje je podczas obliczania wyniku dla kolumny.
Jeśli kolumna wyznaczona jako kolumna funkcji zawiera wszystkie brakujące wartości, składnik przypisuje wynik zerowy.
Następne kroki
Zobacz zestaw składników dostępnych dla usługi Azure Machine Learning.