Trenowanie składnika modelu
W tym artykule opisano składnik w projektancie usługi Azure Machine Learning.
Ten składnik służy do trenowania modelu klasyfikacji lub regresji. Trenowanie odbywa się po zdefiniowaniu modelu i ustawieniu jego parametrów i wymaga oznakowanych danych. Możesz również użyć trenowania modelu , aby ponownie wytrenować istniejący model przy użyciu nowych danych.
Jak działa proces trenowania
W usłudze Azure Machine Learning tworzenie i używanie modelu uczenia maszynowego jest zazwyczaj procesem trzyetapowym.
Model można skonfigurować, wybierając określony typ algorytmu i definiując jego parametry lub hiperparametry. Wybierz dowolny z następujących typów modeli:
- Modele klasyfikacji oparte na sieciach neuronowych, drzewach decyzyjnych i lasach decyzyjnych oraz innych algorytmach.
- Modele regresji, które mogą obejmować standardową regresję liniową lub które używają innych algorytmów, w tym sieci neuronowych i regresji bayesowskiej.
Podaj zestaw danych, który jest oznaczony etykietą i ma dane zgodne z algorytmem. Połącz zarówno dane, jak i model, aby wytrenować model.
To, co generuje trenowanie, to określony format binarny iLearner, który hermetyzuje wzorce statystyczne poznane na podstawie danych. Nie można bezpośrednio modyfikować ani odczytywać tego formatu; jednak inne składniki mogą używać tego wytrenowanego modelu.
Można również wyświetlić właściwości modelu. Aby uzyskać więcej informacji, zobacz sekcję Wyniki.
Po zakończeniu trenowania użyj wytrenowanego modelu z jednym ze składników oceniania, aby przewidywać nowe dane.
Jak używać trenowania modelu
Dodaj składnik Train Model (Trenowanie modelu ) do potoku. Ten składnik można znaleźć w kategorii Machine Learning . Rozwiń węzeł Train (Trenowanie), a następnie przeciągnij składnik Train Model (Trenowanie modelu ) do potoku.
Po lewej stronie danych wejściowych dołącz tryb nieprzetrenowany. Dołącz zestaw danych trenowania do danych wejściowych po prawej stronie w polu Train Model (Trenowanie modelu).
Zestaw danych trenowania musi zawierać kolumnę etykiety. Wszystkie wiersze bez etykiet są ignorowane.
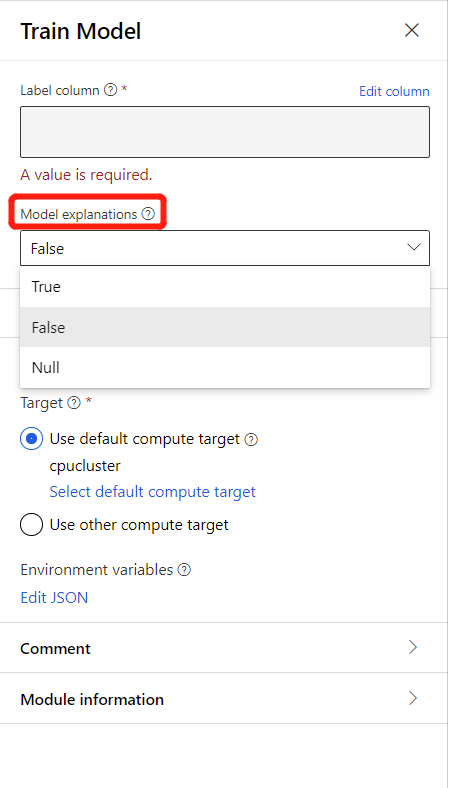
W obszarze Kolumna etykieta kliknij pozycję Edytuj kolumnę w prawym panelu składnika i wybierz jedną kolumnę zawierającą wyniki, których model może użyć do trenowania.
W przypadku problemów z klasyfikacją kolumna etykiety musi zawierać wartości podzielone na kategorie lub wartości dyskretne . Niektóre przykłady mogą być klasyfikacją tak/nie, kodem klasyfikacji chorób lub nazwą albo grupą dochodów. W przypadku wybrania kolumny niekategoricznej składnik zwróci błąd podczas trenowania.
W przypadku problemów z regresją kolumna etykiety musi zawierać dane liczbowe reprezentujące zmienną odpowiedzi. W idealnym przypadku dane liczbowe reprezentują ciągłą skalę.
Przykłady mogą być wynikiem ryzyka kredytowego, przewidywanym czasem awarii dysku twardego lub prognozowaną liczbą połączeń z centrum telefonicznego w danym dniu lub o określonej godzinie. Jeśli nie wybierzesz kolumny liczbowej, może wystąpić błąd.
- Jeśli nie określisz kolumny etykiety do użycia, usługa Azure Machine Learning spróbuje wywnioskować, która jest odpowiednią kolumną etykiet, przy użyciu metadanych zestawu danych. Jeśli wybierze nieprawidłową kolumnę, użyj selektora kolumn, aby go poprawić.
Porada
Jeśli masz problemy z używaniem selektora kolumn, zobacz artykuł Select Columns in Dataset (Wybieranie kolumn w zestawie danych ), aby uzyskać porady. Opisano w nim niektóre typowe scenariusze i porady dotyczące używania opcji WITH RULES i BY NAME .
Prześlij potok. Jeśli masz dużo danych, może to trochę potrwać.
Ważne
Jeśli masz kolumnę IDENTYFIKATORa, która jest identyfikatorem każdego wiersza lub kolumną tekstową zawierającą zbyt wiele unikatowych wartości, model trenowania może napotkać błąd, taki jak "Liczba unikatowych wartości w kolumnie: "{column_name}" jest większa niż dozwolona.
Wynika to z tego, że kolumna osiągnęła próg unikatowych wartości i może spowodować brak pamięci. Możesz użyć funkcji Edytuj metadane , aby oznaczyć tę kolumnę jako funkcję Clear i nie będzie używana w trenowaniu ani wyodrębniać funkcji N-Gram ze składnika Text w celu wstępnego przetwarzania kolumny tekstowej. Aby uzyskać więcej informacji o błędzie, zobacz Projektant kod błędu.
Możliwość interpretowania modelu
Możliwość interpretacji modelu umożliwia zrozumienie modelu uczenia maszynowego i przedstawienie podstawy podejmowania decyzji w sposób zrozumiały dla ludzi.
Obecnie składnik Train Model obsługuje korzystanie z pakietu interpretacji w celu wyjaśnienia modeli uczenia maszynowego. Obsługiwane są następujące wbudowane algorytmy:
- Regresja liniowa
- Regresja sieci neuronowej
- Zwiększona regresja drzewa dezystacji
- Regresja lasu decyzyjnego
- Regresja Poissona
- Dwuklasowa regresja logistyczna
- Two-Class Support Vector Machine (Dwuklasowa maszyna wektorów nośnych)
- Two-Class wzmocnione drzewo dekodacji
- Dwuklasowy las decyzyjny
- Wieloklasowy las decyzyjny
- Regresja logistyczna wieloklasowa
- Wieloklasowa sieć neuronowa
Aby wygenerować wyjaśnienia modelu, możesz wybrać pozycję True na liście rozwijanej Wyjaśnienie modelu w składniku Train Model (Trenowanie modelu). Domyślnie jest ustawiona wartość False w składniku Train Model (Trenowanie modelu ). Należy pamiętać, że generowanie wyjaśnienia wymaga dodatkowych kosztów obliczeniowych.
Po zakończeniu przebiegu potoku możesz odwiedzić kartę Wyjaśnienia w okienku po prawej stronie składnika Train Model (Trenowanie składnika modelu ) oraz zapoznać się z wydajnością modelu, zestawem danych i ważnością funkcji.
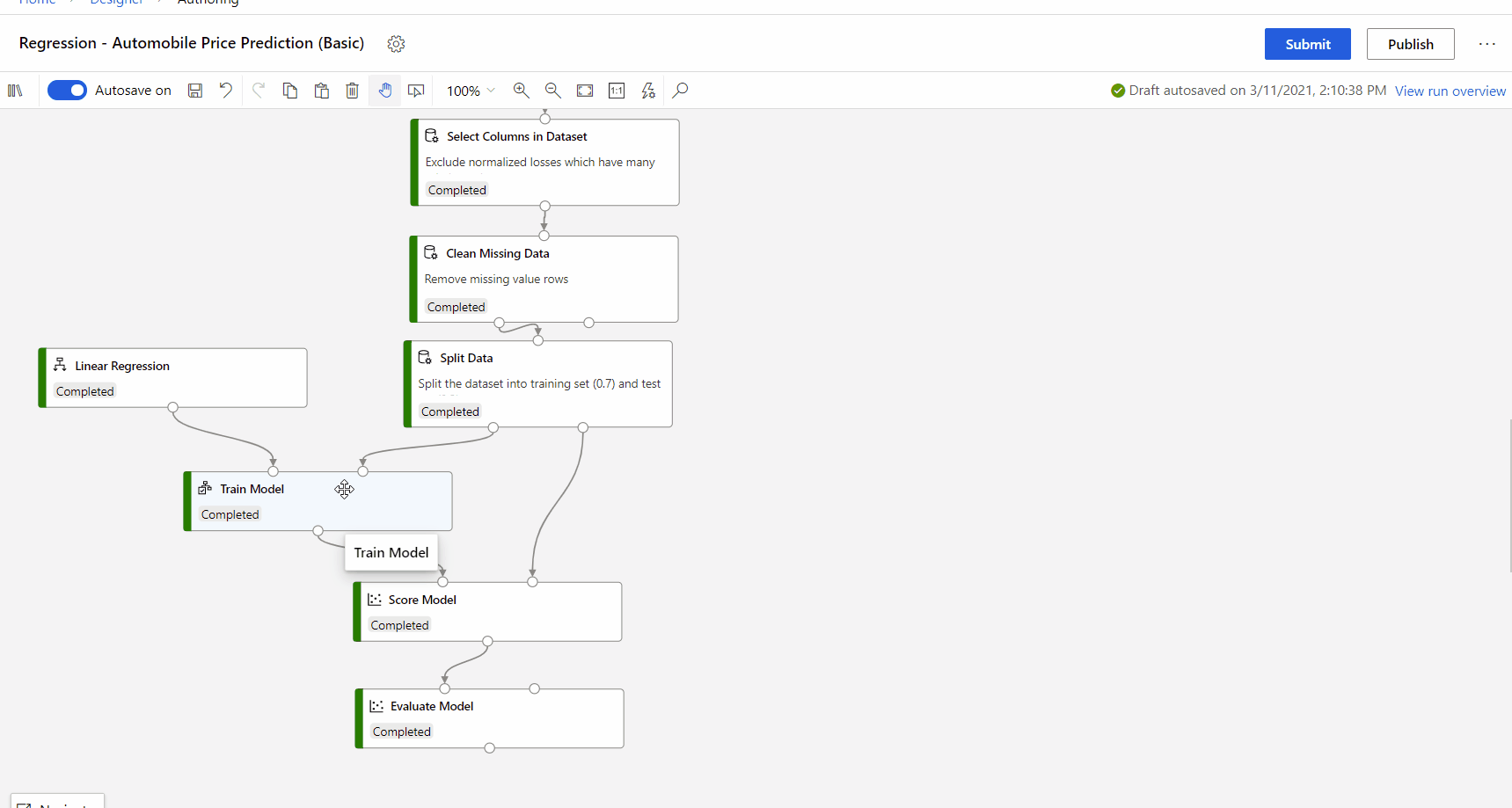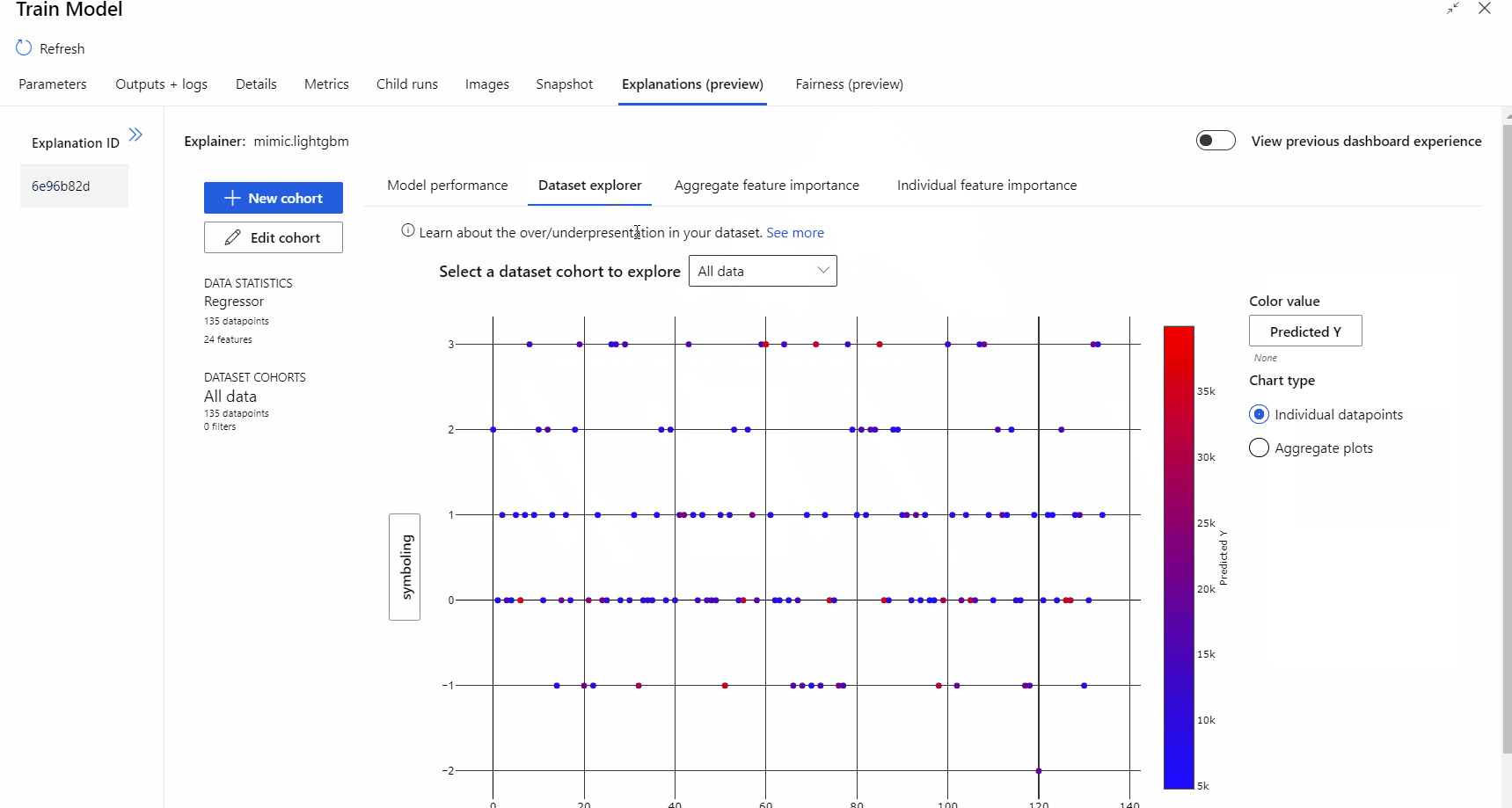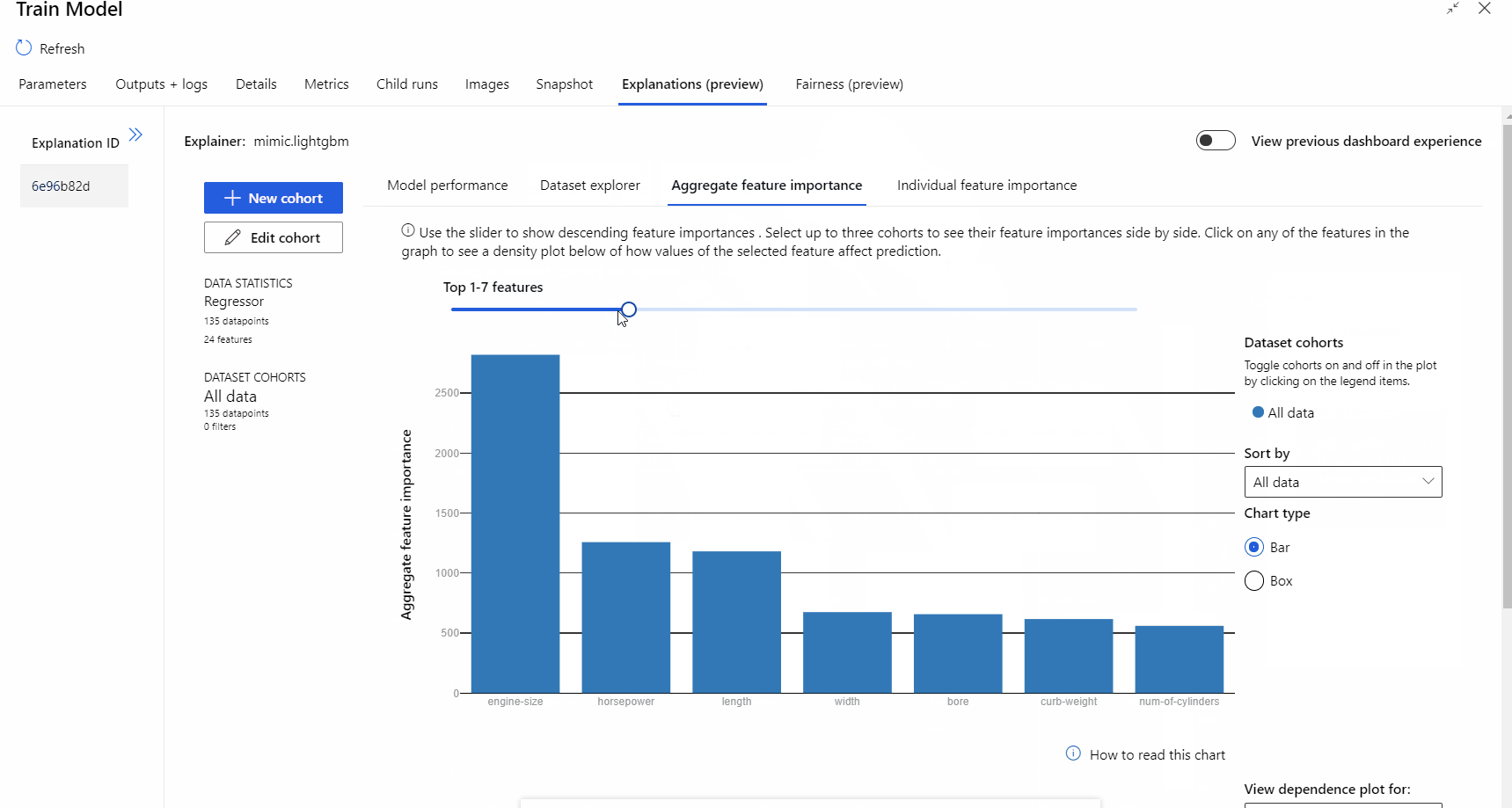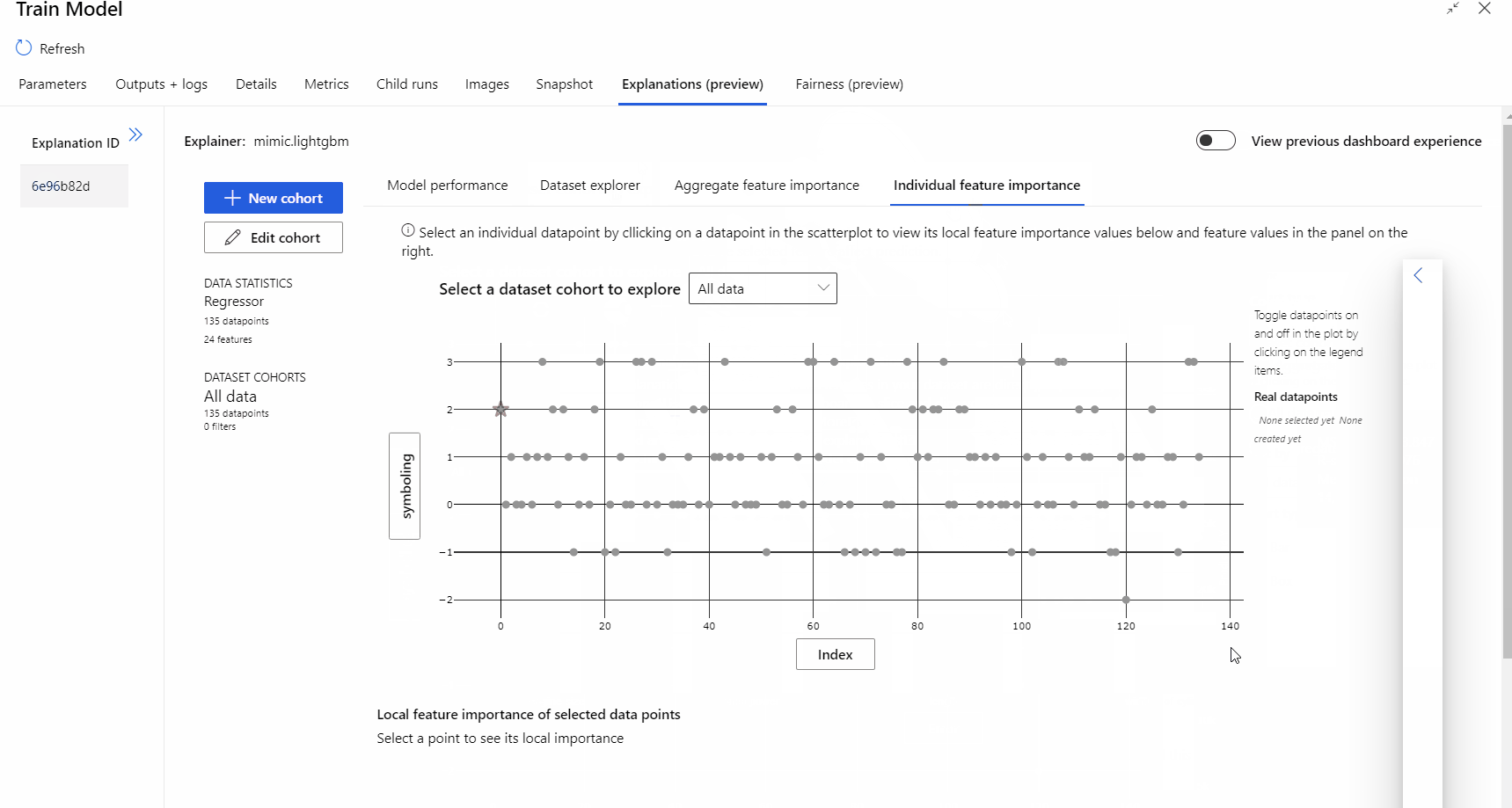
Aby dowiedzieć się więcej na temat korzystania z wyjaśnień modelu w usłudze Azure Machine Learning, zapoznaj się z artykułem z instrukcjami dotyczącymi interpretowania modeli uczenia maszynowego.
Wyniki
Po wytrenowanym modelu:
Aby użyć modelu w innych potokach, wybierz składnik i wybierz ikonę Zarejestruj zestaw danych na karcie Dane wyjściowe w prawym panelu. Dostęp do zapisanych modeli można uzyskać w palecie składników w obszarze Zestawy danych.
Aby użyć modelu w przewidywaniu nowych wartości, połącz go ze składnikiem Score Model (Generowanie wyników dla modelu ) wraz z nowymi danymi wejściowymi.
Następne kroki
Zobacz zestaw składników dostępnych dla usługi Azure Machine Learning.