Uczenie głębokie a uczenie maszynowe w usłudze Azure Machine Learning
W tym artykule opisano uczenie głębokie a uczenie maszynowe oraz sposób ich dopasowania do szerszej kategorii sztucznej inteligencji. Dowiedz się więcej o rozwiązaniach uczenia głębokiego, które można tworzyć w usłudze Azure Machine Learning, takich jak wykrywanie oszustw, rozpoznawanie głosu i twarzy, analiza tonacji i prognozowanie szeregów czasowych.
Aby uzyskać wskazówki dotyczące wybierania algorytmów dla Twoich rozwiązań, zobacz ściągawkę dotyczącą algorytmów uczenia maszynowego.
Modele podstawowe w usłudze Azure Machine Learning to wstępnie wytrenowane modele uczenia głębokiego, które można dostosować do konkretnych przypadków użycia. Dowiedz się więcej o modelach foundation (wersja zapoznawcza) w usłudze Azure Machine Learning i sposobie korzystania z modeli foundation w usłudze Azure Machine Learning (wersja zapoznawcza).
Uczenie głębokie, uczenie maszynowe i sztuczna inteligencja
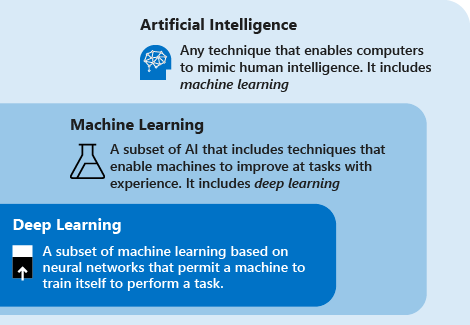
Rozważ następujące definicje, aby zrozumieć uczenie głębokie a uczenie maszynowe a sztuczną inteligencję:
Uczenie głębokie to podzbiór uczenia maszynowego oparty na sztucznych sieciach neuronowych. Proces uczenia jest głęboki, ponieważ struktura sztucznych sieci neuronowych składa się z wielu warstw wejściowych, wyjściowych i ukrytych. Każda warstwa zawiera jednostki, które przekształcają dane wejściowe w informacje, których następne warstwy mogą używać do wykonania pewnego zadania predykcyjnego. Dzięki tej strukturze maszyna może uczyć się za pomocą własnego przetwarzania danych.
Uczenie maszynowe to podzbiór sztucznej inteligencji, który korzysta z technik (takich jak uczenie głębokie), które umożliwiają maszynom korzystanie ze środowiska w celu ulepszania zadań. Proces uczenia opiera się na następujących krokach:
- Przekaż dane do algorytmu. (W tym kroku możesz podać dodatkowe informacje do modelu, na przykład wykonując wyodrębnianie funkcji).
- Użyj tych danych do wytrenowania modelu.
- Testowanie i wdrażanie modelu.
- Korzystanie z wdrożonego modelu w celu wykonania zautomatyzowanego zadania predykcyjnego. (Innymi słowy, wywołaj i użyj wdrożonego modelu, aby otrzymywać przewidywania zwrócone przez model).
Sztuczna inteligencja (AI) to technika umożliwiająca komputerom naśladowanie ludzkiej inteligencji. Obejmuje ona uczenie maszynowe.
Generowanie sztucznej inteligencji to podzbiór sztucznej inteligencji, który używa technik (takich jak uczenie głębokie) do generowania nowej zawartości. Na przykład możesz użyć generowania sztucznej inteligencji do tworzenia obrazów, tekstu lub dźwięku. Te modele wykorzystują ogromną wstępnie wytrenowaną wiedzę, aby wygenerować tę zawartość.
Korzystając z technik uczenia maszynowego i uczenia głębokiego, można tworzyć systemy komputerowe i aplikacje, które wykonują zadania, które są często skojarzone z inteligencją człowieka. Te zadania obejmują rozpoznawanie obrazów, rozpoznawanie mowy i tłumaczenie języka.
Techniki uczenia głębokiego a uczenie maszynowe
Teraz, gdy masz już omówienie uczenia maszynowego i uczenia głębokiego, porównajmy te dwie techniki. W uczeniu maszynowym algorytm musi powiedzieć, jak dokonać dokładnego przewidywania, zużywając więcej informacji (na przykład przez wyodrębnianie funkcji). W uczeniu głębokim algorytm może dowiedzieć się, jak dokonać dokładnego przewidywania za pomocą własnego przetwarzania danych, dzięki sztucznej strukturze sieci neuronowej.
W poniższej tabeli przedstawiono bardziej szczegółowe porównanie dwóch technik:
| Wszystkie uczenie maszynowe | Tylko uczenie głębokie | |
|---|---|---|
| Liczba punktów danych | Może używać małych ilości danych do przewidywania. | Aby przewidywać, należy używać dużych ilości danych szkoleniowych. |
| Zależności sprzętowe | Może pracować na maszynach niskokońcowych. Nie potrzebuje dużej mocy obliczeniowej. | Zależy od maszyn wysokiej klasy. Z natury wykonuje dużą liczbę operacji mnożenia macierzy. Procesor GPU może wydajnie zoptymalizować te operacje. |
| Proces cechowania | Wymaga dokładnego zidentyfikowania i utworzenia funkcji przez użytkowników. | Uczy się funkcji wysokiego poziomu na podstawie danych i tworzy nowe funkcje samodzielnie. |
| Podejście szkoleniowe | Dzieli proces uczenia się na mniejsze kroki. Następnie łączy wyniki z każdego kroku w jedno dane wyjściowe. | Przechodzi przez proces uczenia się, rozwiązując problem na zasadzie kompleksowej. |
| Czas wykonywania | Trenowanie trwa stosunkowo mało czasu, od kilku sekund do kilku godzin. | Zwykle trenowanie trwa długo, ponieważ algorytm uczenia głębokiego obejmuje wiele warstw. |
| Wyjście | Dane wyjściowe są zwykle wartością liczbową, na przykład wynikiem lub klasyfikacją. | Dane wyjściowe mogą mieć wiele formatów, takich jak tekst, wynik lub dźwięk. |
Co to jest uczenie transferowe?
Trenowanie modeli uczenia głębokiego często wymaga dużych ilości danych szkoleniowych, zasobów obliczeniowych wysokiej klasy (GPU, TPU) i dłuższego czasu trenowania. W scenariuszach, w których nie masz żadnego z tych dostępnych, możesz skrócić proces trenowania przy użyciu techniki znanej jako uczenie transferowe.
Uczenie transferowe to technika, która stosuje wiedzę uzyskaną od rozwiązania jednego problemu do innego, ale powiązanego problemu.
Ze względu na strukturę sieci neuronowych pierwszy zestaw warstw zwykle zawiera funkcje niższego poziomu, natomiast końcowy zestaw warstw zawiera funkcje wyższego poziomu, które znajdują się bliżej danej domeny. Poprzez zmianę przeznaczenia warstw końcowych w nowej domenie lub problemie można znacznie zmniejszyć ilość czasu, danych i zasobów obliczeniowych potrzebnych do wytrenowania nowego modelu. Jeśli na przykład masz już model, który rozpoznaje samochody, możesz ponownie zastosować ten model przy użyciu uczenia transferowego, aby rozpoznawać również ciężarówki, motocykle i inne rodzaje pojazdów.
Dowiedz się, jak zastosować uczenie transferowe do klasyfikacji obrazów przy użyciu platformy open source w usłudze Azure Machine Learning: trenowanie modelu PyTorch uczenia głębokiego przy użyciu uczenia transferowego.
Przypadki użycia uczenia głębokiego
Ze względu na sztuczną strukturę sieci neuronowej uczenie głębokie wyróżnia się w identyfikowaniu wzorców w danych bez struktury, takich jak obrazy, dźwięk, wideo i tekst. Z tego powodu uczenie głębokie szybko przekształca wiele branż, w tym opieki zdrowotnej, energii, finansów i transportu. Te branże przemyśleją teraz tradycyjne procesy biznesowe.
Niektóre z najbardziej typowych zastosowań uczenia głębokiego opisano w poniższych akapitach. W usłudze Azure Machine Learning możesz użyć modelu utworzonego na podstawie platformy typu open source lub utworzyć model przy użyciu dostarczonych narzędzi.
Rozpoznawanie nazwanych jednostek
Rozpoznawanie jednostek nazwanych to metoda uczenia głębokiego, która przyjmuje fragment tekstu jako dane wejściowe i przekształca je w wstępnie określoną klasę. Te nowe informacje mogą być kodem pocztowym, datą, identyfikatorem produktu. Informacje te można następnie przechowywać w schemacie ustrukturyzowanym, aby utworzyć listę adresów lub służyć jako punkt odniesienia dla aparatu sprawdzania poprawności tożsamości.
Wykrywanie obiektów
Uczenie głębokie zostało zastosowane w wielu przypadkach użycia wykrywania obiektów. Wykrywanie obiektów służy do identyfikowania obiektów na obrazie (takich jak samochody lub osoby) i zapewnia określoną lokalizację dla każdego obiektu z polem ograniczenia.
Wykrywanie obiektów jest już używane w takich branżach jak gry, handel detaliczny, turystyka i samochody samojezdne.
Generowanie podpisów obrazów
Podobnie jak w przypadku rozpoznawania obrazów w podpisach obrazów dla danego obrazu system musi wygenerować podpis opisujący zawartość obrazu. Gdy można wykrywać i oznaczać obiekty na zdjęciach, następnym krokiem jest przekształcenie tych etykiet w zdania opisowe.
Zazwyczaj aplikacje podpisujące obrazy używają splotowych sieci neuronowych do identyfikowania obiektów na obrazie, a następnie używają rekursyjnej sieci neuronowej, aby przekształcić etykiety w spójne zdania.
Tłumaczenie maszynowe
Tłumaczenie maszynowe pobiera wyrazy lub zdania z jednego języka i automatycznie tłumaczy je na inny język. Tłumaczenie maszynowe trwa od dłuższego czasu, ale uczenie głębokie osiąga imponujące wyniki w dwóch konkretnych obszarach: automatyczne tłumaczenie tekstu (i tłumaczenie mowy na tekst) i automatyczne tłumaczenie obrazów.
Dzięki odpowiedniej transformacji danych sieć neuronowa może zrozumieć sygnały tekstowe, dźwiękowe i wizualne. Tłumaczenie maszynowe może służyć do identyfikowania fragmentów dźwięku w większych plikach audio i transkrypcji słowa mówionego lub obrazu jako tekstu.
Analiza tekstu
Analiza tekstu oparta na metodach uczenia głębokiego obejmuje analizowanie dużych ilości danych tekstowych (na przykład dokumentów medycznych lub wpływów wydatków), rozpoznawanie wzorców i tworzenie zorganizowanych i zwięzłych informacji z niego.
Firmy używają uczenia głębokiego do przeprowadzania analizy tekstu w celu wykrywania handlu niejawnego i zgodności z przepisami rządowymi. Innym typowym przykładem jest oszustwo ubezpieczeniowe: analiza tekstu jest często używana do analizowania dużych ilości dokumentów w celu rozpoznania prawdopodobieństwa oszustwa roszczenia ubezpieczeniowego.
Sztuczne sieci neuronowe
Sztuczne sieci neuronowe są tworzone przez warstwy połączonych węzłów. Modele uczenia głębokiego używają sieci neuronowych, które mają dużą liczbę warstw.
W poniższych sekcjach omówiono najbardziej popularne topologie sztucznej sieci neuronowej.
Kanał informacyjny dla sieci neuronowej
Kanał informacyjny dla sieci neuronowej jest najprostszym typem sztucznej sieci neuronowej. W sieci kanału informacyjnego informacje są przesuwane tylko w jednym kierunku od warstwy wejściowej do warstwy wyjściowej. Sieci neuronowe feedforward przekształcają dane wejściowe, umieszczając je w serii ukrytych warstw. Każda warstwa składa się z zestawu neuronów, a każda warstwa jest w pełni połączona ze wszystkimi neuronami w warstwie przed. Ostatnia w pełni połączona warstwa (warstwa wyjściowa) reprezentuje wygenerowane przewidywania.
Rekurencyjna sieć neuronowa (RNN, Recurrent Neural Network)
Rekursowe sieci neuronowe to powszechnie używana sztuczna sieć neuronowa. Te sieci zapisują dane wyjściowe warstwy i przesyłają ją z powrotem do warstwy wejściowej, aby ułatwić przewidywanie wyniku warstwy. Rekursowe sieci neuronowe mają doskonałe możliwości uczenia się. Są one szeroko używane w przypadku złożonych zadań, takich jak prognozowanie szeregów czasowych, uczenie się pisma ręcznego i rozpoznawanie języka.
Konwolucyjna sieć neuronowa (CNN, Convolutional Neural Network)
Splotowa sieć neuronowa jest szczególnie efektywną sztuczną siecią neuronową i stanowi unikatową architekturę. Warstwy są zorganizowane w trzech wymiarach: szerokość, wysokość i głębokość. Neurony w jednej warstwie łączą się nie ze wszystkimi neuronami w następnej warstwie, ale tylko z małym regionem neuronów warstwy. Końcowe dane wyjściowe są zmniejszane do pojedynczego wektora wyników prawdopodobieństwa uporządkowanego wzdłuż wymiaru głębokości.
Splotowe sieci neuronowe są używane w takich obszarach jak rozpoznawanie wideo, rozpoznawanie obrazów i systemy rekomendacji.
Generatywna sieć przeciwstawna (GAN, Generative Adversarial Network)
Generowanie niepożądanych sieci to modele generowania wytrenowane w celu tworzenia realistycznej zawartości, takiej jak obrazy. Składa się z dwóch sieci nazywanych generatorem i dyskryminującymi. Obie sieci są trenowane jednocześnie. Podczas trenowania generator używa losowego szumu do tworzenia nowych syntetycznych danych, które są ściśle podobne do rzeczywistych danych. Dyskryminator pobiera dane wyjściowe z generatora jako dane wejściowe i używa rzeczywistych danych w celu określenia, czy wygenerowana zawartość jest prawdziwa, czy syntetyczna. Każda sieć rywalizuje ze sobą. Generator próbuje wygenerować syntetyczną zawartość, która jest nie do odróżnienia od rzeczywistej zawartości, a dyskryminujący próbuje poprawnie sklasyfikować dane wejściowe jako rzeczywiste lub syntetyczne. Dane wyjściowe są następnie używane do aktualizowania wag obu sieci, aby pomóc im lepiej osiągnąć odpowiednie cele.
Sieci generujące niepożądane są używane do rozwiązywania problemów, takich jak tłumaczenie obrazu i postęp wieku.
Transformatory
Transformatory to architektura modelu, która jest odpowiednia do rozwiązywania problemów zawierających sekwencje, takie jak dane tekstowe lub szeregi czasowe. Składają się one z warstw kodera i dekodera. Koder pobiera dane wejściowe i mapuje je na reprezentację liczbową zawierającą informacje, takie jak kontekst. Dekoder używa informacji z kodera do tworzenia danych wyjściowych, takich jak przetłumaczony tekst. Co sprawia, że transformatory różnią się od innych architektur zawierających kodery i dekodatory to warstwy podrzędne uwagi. Uwaga polega na skupieniu się na określonych częściach danych wejściowych na podstawie znaczenia ich kontekstu w odniesieniu do innych danych wejściowych w sekwencji. Na przykład podczas podsumowywania artykułu z wiadomościami nie wszystkie zdania mają zastosowanie do opisania głównej idei. Koncentrując się na słowach kluczowych w całym artykule, podsumowanie można wykonać w jednym zdaniu— nagłówku.
Transformatory służą do rozwiązywania problemów z przetwarzaniem języka naturalnego, takich jak tłumaczenie, generowanie tekstu, odpowiadanie na pytania i podsumowywanie tekstu.
Niektóre dobrze znane implementacje transformatorów to:
- Reprezentacje kodera dwukierunkowego z funkcji Transformers ()
- Generowanie wstępnie wytrenowanego transformatora 2 (GPT-2)
- Generowanie wstępnie wytrenowanego transformatora 3 (GPT-3)
Następne kroki
W poniższych artykułach przedstawiono więcej opcji korzystania z modeli uczenia głębokiego typu open source w usłudze Azure Machine Learning: