Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Azure Machine Learning umożliwia zaimplementowanie wsadowych punktów końcowych i wdrożeń do wykonywania długotrwałych, asynchronicznych predykcji za pomocą modeli i potoków uczenia maszynowego. Podczas trenowania modelu lub potoku uczenia maszynowego należy go wdrożyć, aby inni mogli używać go z nowymi danymi wejściowymi do generowania przewidywań. Ten proces generowania przewidywań za pomocą modelu lub potoku jest nazywany wnioskowaniem.
Punkty końcowe usługi Batch odbierają wskaźniki do danych i uruchamiają zadania asynchronicznie w celu równoległego przetwarzania danych w klastrach obliczeniowych. Punkty końcowe usługi Batch przechowują dane wyjściowe w magazynie danych w celu dalszej analizy. Użyj punktów końcowych wsadowych, gdy:
- Masz kosztowne modele lub potoki, które wymagają dłuższego czasu do działania.
- Chcesz operacjonalizować potoki uczenia maszynowego i ponownie używać komponentów.
- Należy przeprowadzić wnioskowanie na dużych ilościach danych dystrybuowanych w wielu plikach.
- Nie masz wymagań dotyczących małych opóźnień.
- Dane wejściowe modelu są przechowywane na koncie magazynowym lub w zasobie danych w Azure Machine Learning.
- Możesz skorzystać z przetwarzania równoległego.
Wdrożenia wsadowe
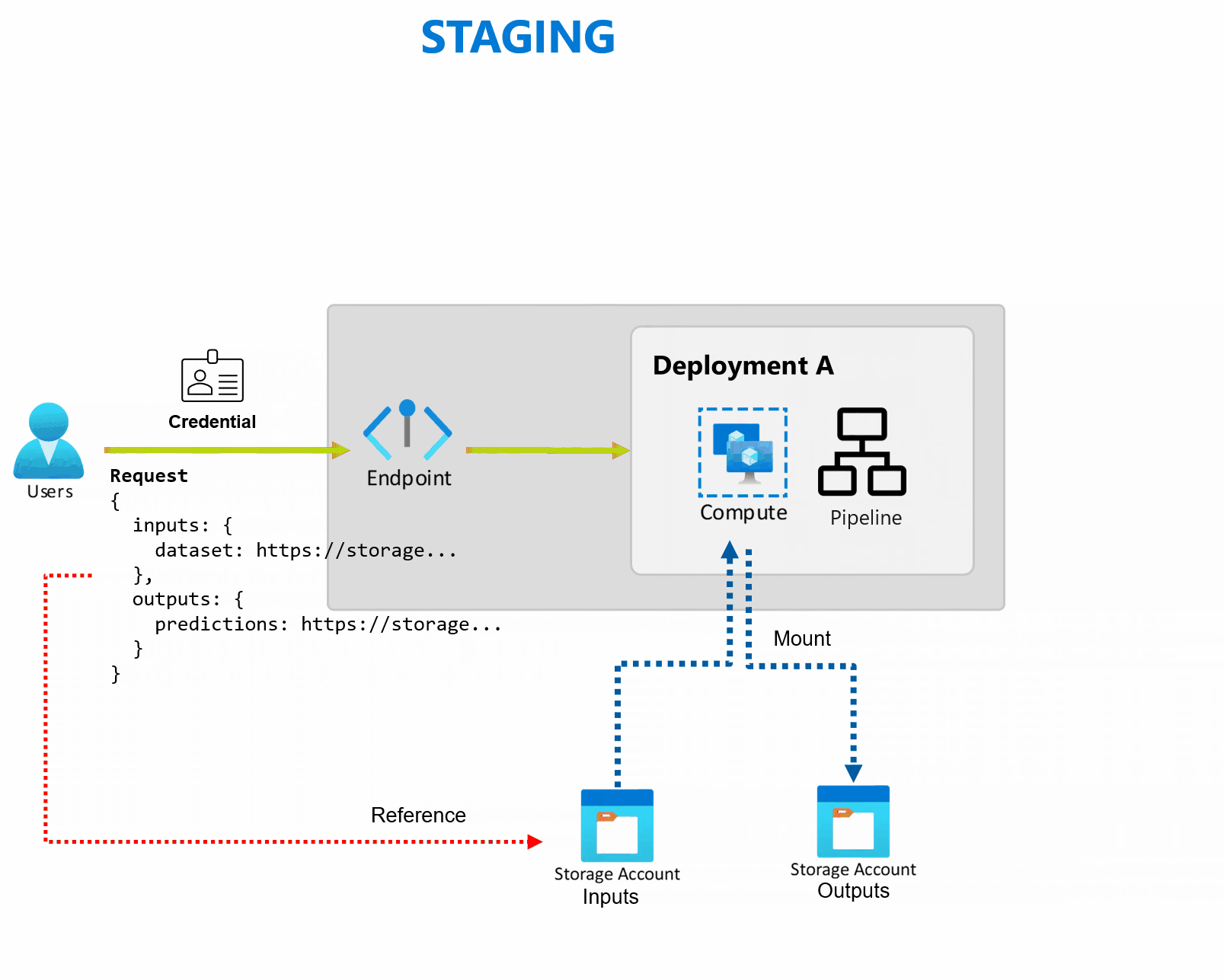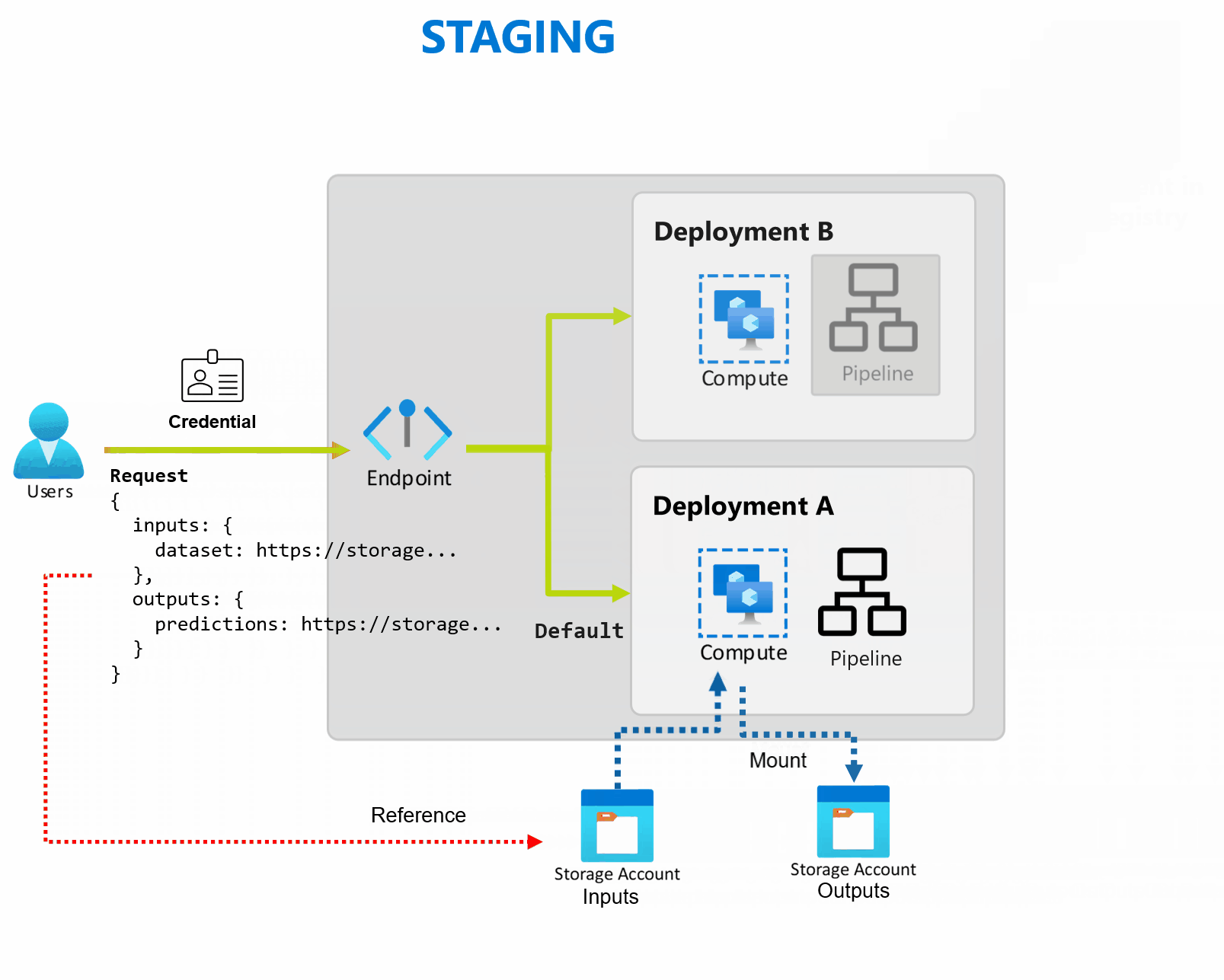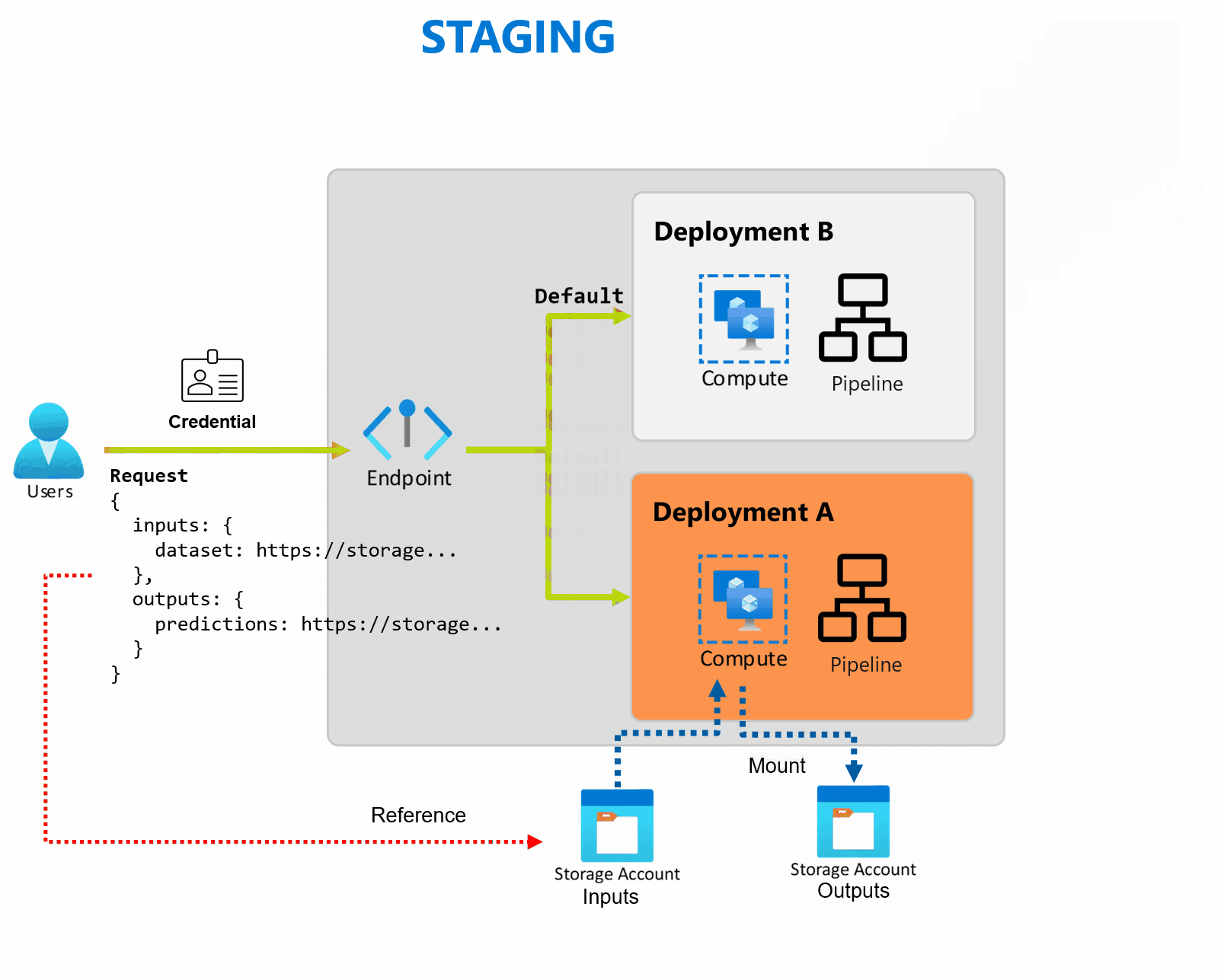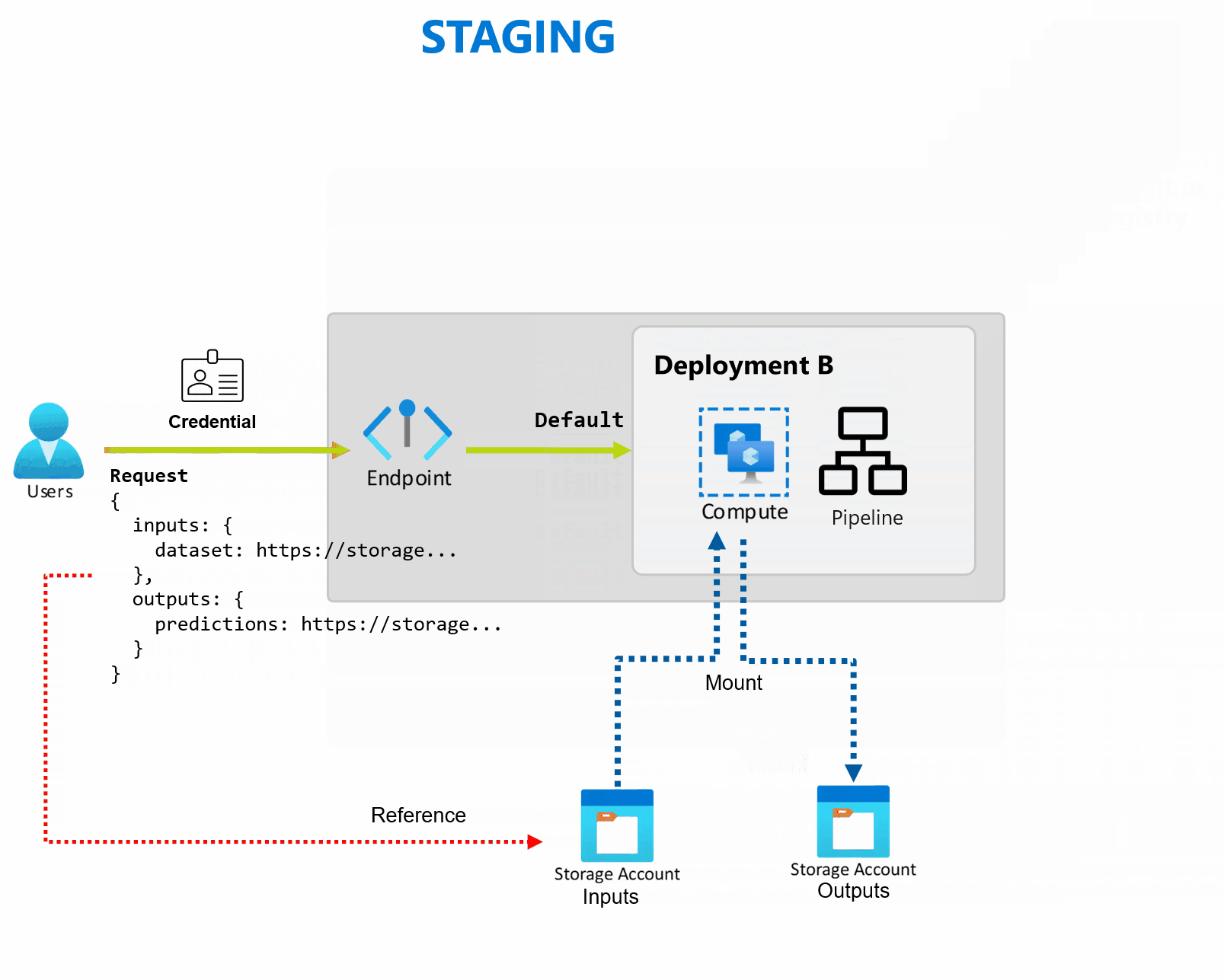
Wdrożenie to zestaw zasobów i obliczeń wymaganych do zaimplementowania funkcji zapewnianych przez punkt końcowy. Punkt końcowy może hostować wiele wdrożeń, z których każda ma własną konfigurację, oddzielenie interfejsu punktu końcowego od szczegółów implementacji wdrożenia. Po wywołaniu punktu końcowego wsadowego automatycznie kieruje klienta do domyślnego wdrożenia. To domyślne wdrożenie można skonfigurować i zmienić w dowolnym momencie.

Dwa typy wdrożeń są możliwe w Azure Machine Learning punktach końcowych wsadowych:
Wdrażanie modelu
Wdrożenie modelu umożliwia operacjonalizacja wnioskowania modelu na dużą skalę, umożliwiając przetwarzanie dużych ilości danych w sposób o małym opóźnieniu i asynchronicznym. Azure Machine Learning automatycznie instrumentuje skalowalność, zapewniając równoległość procesów wnioskowania w wielu węzłach w klastrze obliczeniowym.
Użyj wdrożenia modelu gdy:
- Masz kosztowne modele, które wymagają dłuższego czasu na wnioskowanie.
- Należy przeprowadzić wnioskowanie na dużych ilościach danych dystrybuowanych w wielu plikach.
- Nie masz wymagań dotyczących małych opóźnień.
- Możesz skorzystać z przetwarzania równoległego.
Główną zaletą wdrożeń modelu jest to, że można używać tych samych zasobów, które są wdrażane na potrzeby wnioskowania w czasie rzeczywistym w punktach końcowych online, ale teraz można uruchamiać je na dużą skalę w partii. Jeśli model wymaga prostego przetwarzania wstępnego lub przetwarzania końcowego, możesz utworzyć skrypt oceniania , który wykonuje wymagane przekształcenia danych.
Aby utworzyć wdrożenie modelu w punkcie końcowym wsadowym, należy określić następujące elementy:
- Model
- Klaster obliczeniowy
- Skrypt oceniania (opcjonalny dla modeli MLflow)
- Środowisko (opcjonalne dla modeli MLflow)
Wdrożenie komponentu potoku
Wdrożenie składnika potoku umożliwia operacjonalizację całych grafów przetwarzania (lub potoków) do wykonywania wnioskowania wsadowego o niskim opóźnieniu i w sposób asynchroniczny.
Użyj wdrożenia składnika przetwarzania, gdy:
- Trzeba wdrożyć pełne grafy obliczeniowe, które można podzielić na kilka etapów.
- Należy wykorzystać ponownie składniki z potoków treningowych w potoku wnioskowania.
- Nie masz wymagań dotyczących małych opóźnień.
Główną zaletą wdrażania komponentów w potoku jest możliwość ponownego wykorzystania istniejących elementów na Twojej platformie oraz wdrażania złożonych procedur inferencji.
Aby utworzyć wdrożenie składnika potoku w punkcie końcowym wsadowym, należy określić następujące elementy:
- Składnik rurociągu
- Konfiguracja klastra obliczeniowego
Punkty końcowe usługi Batch umożliwiają również tworzenie wdrożeń komponentów potoku z istniejącego zadania potoku. W takim przypadku Azure Machine Learning automatycznie tworzy składnik potoku z zadania. Upraszcza to korzystanie z tego rodzaju wdrożeń. Jednak najlepszym rozwiązaniem jest jawne tworzenie składników potoku w celu usprawnienia praktyki metodyki MLOps.
Zarządzanie kosztami
Wywoływanie punktu końcowego wsadowego wyzwala asynchroniczne zadanie wnioskowania wsadowego. Azure Machine Learning automatycznie aprowizuje zasoby obliczeniowe, gdy zadanie się rozpoczyna, i automatycznie zwalnia je po jego zakończeniu. W ten sposób płacisz tylko za obliczenia, gdy go używasz.
Wskazówka
Podczas wdrażania modeli można zastąpić ustawienia zasobów obliczeniowych (na przykład liczbę instancji) i ustawienia zaawansowane (takie jak rozmiar minipartii, próg błędu itd.) dla każdego zadania przetwarzania wsadowego. Korzystając z tych konkretnych konfiguracji, możesz przyspieszyć wykonywanie i obniżyć koszty.
Punkty końcowe usługi Batch mogą również działać na maszynach wirtualnych o niskim priorytcie. Punkty końcowe usługi Batch mogą automatycznie odtwarzać swoją funkcjonalność po zdezaktywowanych maszynach wirtualnych i wznawiać pracę od miejsca, w którym została przerwana podczas wdrażania modeli do wnioskowania. Aby uzyskać więcej informacji na temat używania maszyn wirtualnych o niskim priorytcie w celu zmniejszenia kosztów obciążeń wnioskowania wsadowego, zobacz Używanie maszyn wirtualnych o niskim priorytcie w punktach końcowych wsadowych.
Na koniec Azure Machine Learning nie pobiera opłat za punkty końcowe wsadowe ani wdrożenia wsadowe, dzięki czemu możesz organizować punkty końcowe i wdrożenia zgodnie z twoim scenariuszem. Punkty końcowe i wdrożenia mogą używać niezależnych lub udostępnionych klastrów, dzięki którym można uzyskać szczegółową kontrolę nad tym, które zasoby obliczeniowe zużywają zadania. Użyj mechanizmu scale-to-zero w klastrach, aby upewnić się, że zasoby nie są wykorzystywane podczas ich bezczynności.
Usprawnij praktykę metodyki MLOps
Punkty końcowe usługi Batch mogą obsługiwać wiele wdrożeń w ramach tego samego punktu końcowego, co umożliwia zmianę implementacji punktu końcowego bez zmiany adresu URL używanego przez użytkowników do jego wywoływania.
Wdrożenia można dodawać, usuwać i aktualizować bez wpływu na sam punkt końcowy.
Elastyczne źródła danych i przechowywanie
Punkty końcowe usługi Batch odczytują i zapisują dane bezpośrednio z magazynu. Można określić magazyny danych Azure Machine Learning, zasoby danych Azure Machine Learning lub konta magazynu jako dane wejściowe. Aby uzyskać więcej informacji na temat obsługiwanych opcji wejściowych i sposobu ich określania, zobacz Tworzenie zadań i danych wejściowych w punktach końcowych wsadowych.
Zabezpieczenia
Punkty końcowe usługi Batch zapewniają wszystkie możliwości wymagane do obsługi obciążeń na poziomie produkcyjnym w środowisku przedsiębiorstwa. Obsługują one prywatną sieć w zabezpieczonych obszarach roboczych oraz uwierzytelnianie Microsoft Entra przy użyciu jednostki użytkownika (takiej jak konto użytkownika) lub jednostki usługi (takiej jak tożsamość zarządzana lub niezarządzana). Zadania generowane przez punkt końcowy wsadowy są uruchamiane w ramach tożsamości obiektu invoker, co zapewnia elastyczność implementacji dowolnego scenariusza. Aby uzyskać więcej informacji na temat autoryzacji podczas korzystania z punktów końcowych wsadowych, zobacz Jak uwierzytelniać się w punktach końcowych wsadowych.