Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym dokumencie opisano jednostki najwyższego poziomu w magazyn zarządzanych funkcji.
Aby uzyskać więcej informacji na temat magazyn zarządzanych funkcji, odwiedź zasób Co to jest magazyn zarządzanych funkcji?
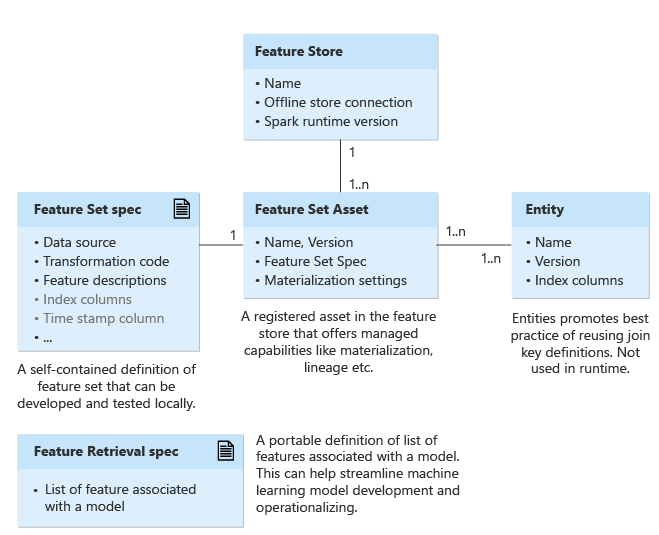
Magazyn funkcji
Zestawy funkcji można tworzyć i zarządzać nimi za pośrednictwem magazynu funkcji. Zestaw funkcji to kolekcja funkcji. Opcjonalnie można skojarzyć magazyn materializacji (połączenie magazynu w trybie offline) z magazynem funkcji, aby wstępnie skompilować i zachować funkcje w regularnych odstępach czasu. Takie podejście może sprawić, że pobieranie funkcji podczas trenowania lub wnioskowania jest szybsze i bardziej niezawodne.
Aby uzyskać więcej informacji na temat konfiguracji, zobacz zasób schematu yaML magazynu funkcji interfejsu wiersza polecenia (wersja 2).
Jednostki
Jednostka hermetyzuje kolumny indeksu dla jednostek logicznych w przedsiębiorstwie. Przykłady jednostek to jednostka konta, jednostka klienta itp. Jednostki pomagają wymusić użycie tych samych definicji kolumn indeksu w zestawach funkcji korzystających z tych samych jednostek logicznych.
Jednostki są zwykle tworzone raz, a następnie ponownie używane w zestawach funkcji. Jednostki są wersjonowane.
Aby uzyskać więcej informacji na temat konfiguracji, odwiedź zasób schematu jednostki funkcji interfejsu wiersza polecenia (wersja 2).
Specyfikacja zestawu funkcji i zasób
Zestaw funkcji to kolekcja funkcji generowanych przez zastosowanie transformacji na danych systemu źródłowego. Zestawy funkcji hermetyzują źródło, funkcję przekształcania i ustawienia materializacji. Obecnie obsługujemy kod przekształcania funkcji PySpark.
Najpierw utwórz specyfikację zestawu funkcji. Specyfikacja zestawu funkcji to samodzielna definicja zestawu funkcji, którą można lokalnie opracowywać i testować.
Specyfikacja zestawu funkcji zwykle składa się z następujących parametrów:
-
source: Jakie źródła są mapować na tę funkcję -
transformation(opcjonalnie): Logika przekształcania zastosowana do danych źródłowych w celu utworzenia funkcji. W naszym przypadku używamy platformy Spark jako obsługiwanego środowiska obliczeniowego. - Nazwy kolumn reprezentujących
index_columnswartości i :timestamp_columnTe nazwy są wymagane, gdy użytkownicy próbują połączyć dane funkcji z danymi obserwacji (więcej na ten temat później) -
materialization_settings(opcjonalnie): wymagane, jeśli chcesz buforować wartości funkcji w magazynie materializacji w celu wydajnego pobierania.
Po opracowaniu i przetestowaniu specyfikacji zestawu funkcji w środowisku lokalnym/deweloperskim można zarejestrować specyfikację jako zasób zestawu funkcji w magazynie funkcji. Zasób zestawu funkcji zapewnia funkcje zarządzane, na przykład przechowywanie wersji i materializacja.
Aby uzyskać więcej informacji na temat specyfikacji YAML zestawu funkcji, odwiedź zasób schematu zestawu funkcji interfejsu wiersza polecenia (wersja 2).
Specyfikacja pobierania funkcji
Specyfikacja pobierania funkcji to przenośna definicja listy funkcji skojarzonej z modelem. Może to pomóc usprawnić opracowywanie i operacjonalizacja modelu uczenia maszynowego. Specyfikacja pobierania funkcji jest zazwyczaj danymi wejściowymi do potoku trenowania. Pomaga to wygenerować dane szkoleniowe. Możesz spakować go za pomocą modelu. Ponadto krok wnioskowania używa go do wyszukiwania funkcji. Integruje wszystkie fazy cyklu życia uczenia maszynowego. Zmiany potoku trenowania i wnioskowania można zminimalizować podczas eksperymentowania i wdrażania.
Korzystanie ze specyfikacji pobierania funkcji i wbudowanego składnika pobierania funkcji jest opcjonalne. Jeśli chcesz, możesz bezpośrednio użyć interfejsu get_offline_features() API.
Aby uzyskać więcej informacji na temat specyfikacji yaML pobierania funkcji, odwiedź zasób schematu interfejsu wiersza polecenia (wersja 2) specyfikacji pobierania specyfikacji YAML.