Przykłady dotyczące usługi Azure Data Science Virtual Machines
Usługa Azure Data Science Virtual Machines (DSVM) zawiera kompleksowy zestaw przykładowego kodu. Przykłady te obejmują notesy i skrypty jupyter w językach takich jak Python i R.
Uwaga
Aby uzyskać więcej informacji na temat uruchamiania notesów Jupyter na maszynach wirtualnych do nauki o danych, zobacz sekcję Access Jupyter (Uzyskiwanie dostępu do programu Jupyter ).
Wymagania wstępne
Aby można było uruchomić te przykłady, musisz aprowizować Data Science Virtual Machine Ubuntu.
Dostępne przykłady
| Kategoria przykładów | Opis | Lokalizacje |
|---|---|---|
| Język Python | Przykłady wyjaśniają scenariusze, takie jak nawiązywanie połączenia z magazynami danych w chmurze opartymi na platformie Azure i jak pracować z usługą Azure Machine Learning. Język Python |
~notebooks |
| Język Julia | Zawiera szczegółowy opis kreślenia i uczenia głębokiego w Julii. Wyjaśniono również, jak wywoływać języki C i Python z julii. Język Julia |
W systemie Windows: ~notebooks/Julia_notebooksW systemie Linux: ~notebooks/julia |
| Azure Machine Learning | Ilustruje sposób tworzenia modeli uczenia maszynowego i uczenia głębokiego przy użyciu uczenia maszynowego. Wdrażanie modeli w dowolnym miejscu. Użyj zautomatyzowanego uczenia maszynowego i inteligentnego dostrajania hiperparametrów. Używaj również zarządzania modelami i trenowania rozproszonego. Usługa Machine Learning |
~notebooks/AzureML |
| Notesy PyTorch | Przykłady uczenia głębokiego korzystające z sieci neuronowych opartych na protokole PyTorch. Notesy obejmują od początkujących do zaawansowanych scenariuszy. Notesy PyTorch |
~notebooks/Deep_learning_frameworks/pytorch |
| TensorFlow | Różne przykłady i techniki sieci neuronowych implementowane przy użyciu struktury TensorFlow. TensorFlow |
~notebooks/Deep_learning_frameworks/tensorflow |
| H2O | Przykłady oparte na języku Python, które używają funkcji H2O w rzeczywistych scenariuszach problemów. H2O |
~notebooks/h2o |
| Język SparkML | Przykłady korzystające z funkcji zestawu narzędzi Apache Spark MLLib za pośrednictwem narzędzi pySpark i MMLSpark: Microsoft Machine Learning for Apache Spark on Apache Spark 2.x. Język SparkML |
~notebooks/SparkML/pySpark~notebooks/MMLSpark |
| XGBoost | Standardowe przykłady uczenia maszynowego w biblioteki XGBoost dla scenariuszy takich jak klasyfikacja i regresja. XGBoost |
W systemie Windows: \dsvm\samples\xgboost\demo |
Uzyskiwanie dostępu do programu Jupyter
Aby uzyskać dostęp do aplikacji Jupyter, wybierz ikonę Jupyter w menu pulpitu lub aplikacji. Możesz również uzyskać dostęp do programu Jupyter w wersji systemu Linux maszyny DSVM. Aby uzyskać zdalny dostęp z przeglądarki internetowej, przejdź do https://<Full Domain Name or IP Address of the DSVM>:8000 strony w systemie Ubuntu.
Aby dodać wyjątki i udostępnić dostęp programu Jupyter za pośrednictwem przeglądarki, skorzystaj z następujących wskazówek:
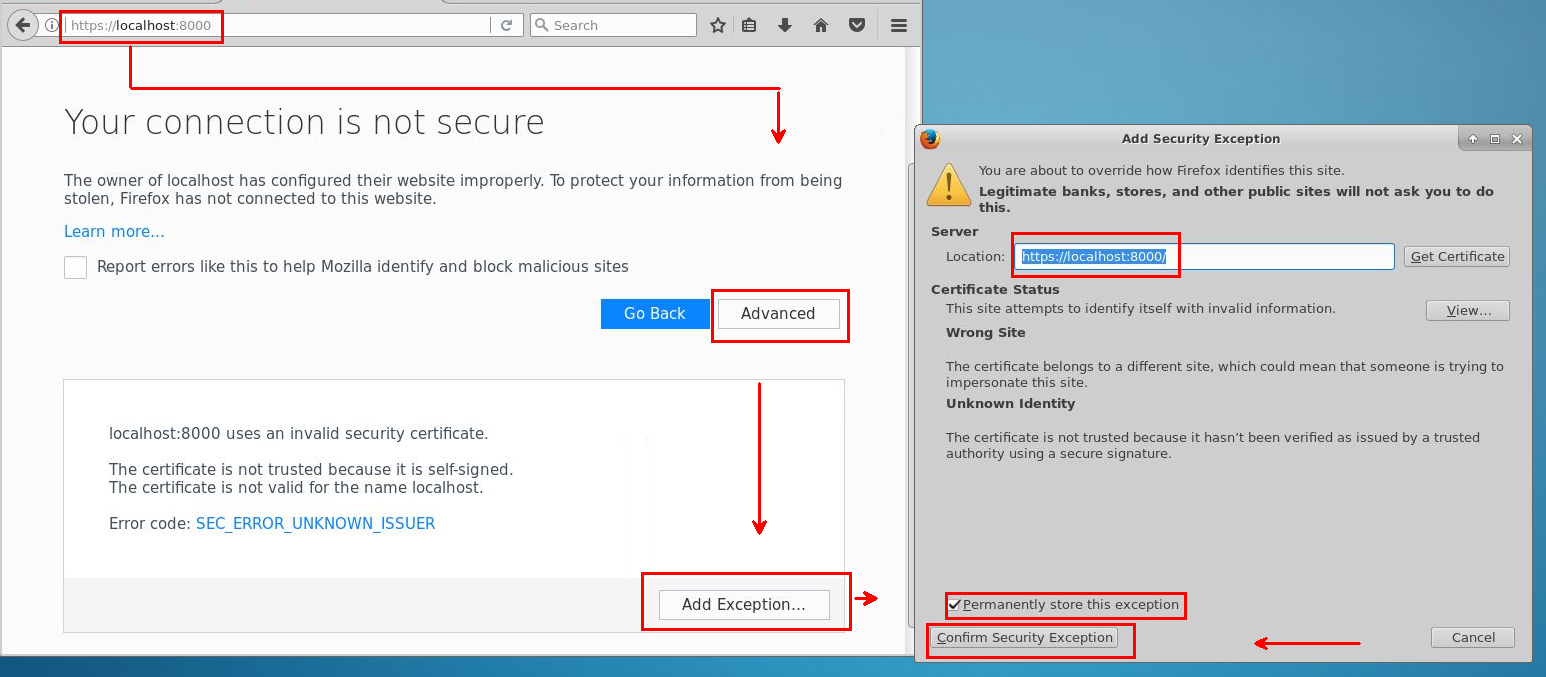
Zaloguj się przy użyciu tego samego hasła, którego używasz do logowania się do Data Science Virtual Machine.
Strona główna Jupyter
Język R
Język Python
Język Julia
Azure Machine Learning
PyTorch
TensorFlow
H2O
SparkML
XGBoost