Nauka o danych przy użyciu maszyny wirtualnej Nauka o danych z systemem Windows
Maszyna wirtualna z systemem Windows Nauka o danych (DSVM) to zaawansowane środowisko programistyczne do nauki o danych, które obsługuje zadania eksploracji i modelowania danych. Środowisko jest wstępnie utworzone i wstępnie podzielone na kilka popularnych narzędzi do analizy danych, które ułatwiają rozpoczęcie analizy wdrożeń lokalnych, w chmurze lub hybrydowych.
Maszyna DSVM ściśle współpracuje z usługami platformy Azure. Może odczytywać i przetwarzać dane już przechowywane na platformie Azure w usłudze Azure Synapse (dawniej SQL DW), Azure Data Lake, Azure Storage lub Azure Cosmos DB. Może również korzystać z innych narzędzi analitycznych, takich jak usługa Azure Machine Learning.
Z tego artykułu dowiesz się, jak używać maszyny DSVM do obsługi zadań nauki o danych i interakcji z innymi usługami platformy Azure. Jest to przykład zadań, które mogą obejmować maszyny DSVM:
- Używanie notesu Jupyter Notebook do eksperymentowania z danymi w przeglądarce przy użyciu języków Python 2, Python 3 i Microsoft R. (Microsoft R to wersja języka R gotowa do użycia w przedsiębiorstwie przeznaczona do wysokiej wydajności).
- Poznaj dane i twórz modele lokalnie na maszynie DSVM przy użyciu programu Microsoft Machine Learning Server i języka Python.
- Administrowanie zasobami platformy Azure przy użyciu witryny Azure Portal lub programu PowerShell.
- Rozszerzanie miejsca do magazynowania i udostępnianie zestawów danych/kodu na dużą skalę w całym zespole dzięki udziałowi usługi Azure Files jako dysku możliwego do zainstalowania na maszynie DSVM.
- Udostępnij kod zespołowi w usłudze GitHub. Uzyskaj dostęp do repozytorium przy użyciu wstępnie zainstalowanych klientów Git: powłoki Git Bash i graficznego interfejsu użytkownika usługi Git.
- Uzyskiwanie dostępu do usług danych i analiz platformy Azure:
- Azure Blob Storage
- Azure Cosmos DB
- Azure Synapse (wcześniej SQL DW)
- Azure SQL Database
- Tworzenie raportów i pulpitu nawigacyjnego przy użyciu wystąpienia programu Power BI Desktop — wstępnie zainstalowanego na maszynie DSVM — i wdrażanie ich w chmurze.
- Zainstaluj więcej narzędzi na maszynie wirtualnej.
Uwaga
Dodatkowe opłaty za użycie dotyczą wielu usług magazynu danych i analiz wymienionych w tym artykule. Aby dowiedzieć się więcej, odwiedź stronę z cenami platformy Azure.
Wymagania wstępne
- Subskrypcja platformy Azure. Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
- Aprowizowana maszyna DSVM w witrynie Azure Portal. Aby uzyskać więcej informacji, odwiedź stronę Tworzenie zasobu maszyny wirtualnej.
Uwaga
Do interakcji z platformą Azure zalecamy używanie modułu Azure Az w programie PowerShell. Aby rozpocząć, zobacz Instalowanie programu Azure PowerShell. Aby dowiedzieć się, jak przeprowadzić migrację do modułu Az PowerShell, zobacz Migracja programu Azure PowerShell z modułu AzureRM do modułu Az.
Korzystanie z notesów Jupyter
Notes Jupyter Notebook udostępnia oparte na przeglądarce środowisko IDE do eksploracji i modelowania danych. Możesz użyć języka Python 2, Python 3 lub R w notesie Jupyter Notebook.
Aby uruchomić notes Jupyter Notebook, wybierz ikonę notesu Jupyter Notebook w menu Start lub na pulpicie. W wierszu polecenia maszyny DSVM można również uruchomić polecenie jupyter notebook z katalogu, który hostuje istniejące notesy lub gdzie chcesz utworzyć nowe notesy.
Po uruchomieniu /notebooks programu Jupyter przejdź do katalogu. Ten katalog hostuje przykładowe notesy, które są wstępnie pakowane do maszyny DSVM. Masz następujące możliwości:
- Wybierz notes, aby wyświetlić kod.
- Wybierz pozycję Shift+Enter, aby uruchomić każdą komórkę.
- Wybierz pozycję Uruchom komórkę>, aby uruchomić cały notes.
- Utwórz nowy notes; wybierz ikonę Jupyter (w lewym górnym rogu), wybierz przycisk Nowy , a następnie wybierz język notesu (znany również jako jądra).
Uwaga
Obecnie obsługiwane są jądra python 2.7, Python 3.6, R, Julia i PySpark w programie Jupyter. Jądro języka R obsługuje programowanie zarówno w języku R typu open source, jak i w języku Microsoft R. W notesie możesz eksplorować dane, kompilować model i testować ten model przy użyciu wybranej biblioteki.
Eksplorowanie danych i opracowywanie modeli za pomocą programu Microsoft Machine Learning Server
Uwaga
Wsparcie dla autonomicznego serwera Machine Learning Server zakończyło się 1 lipca 2021 r. Usunęliśmy go z obrazów MASZYN DSVM po 30 czerwca 2021 r. Istniejące wdrożenia nadal mogą uzyskiwać dostęp do oprogramowania, ale wsparcie techniczne zakończyło się po 1 lipca 2021 r.
Do analizy danych można używać języków R i Python bezpośrednio na maszynie DSVM.
W przypadku języka R można użyć narzędzi R Tools for Visual Studio. Firma Microsoft udostępnia inne biblioteki oprócz zasobu języka CRAN R typu open source. Te biblioteki umożliwiają zarówno skalowalną analizę, jak i możliwość analizowania mas danych, które przekraczają ograniczenia rozmiaru pamięci równoległej analizy fragmentowanej.
W przypadku języka Python można użyć środowiska IDE — na przykład Visual Studio Community Edition — który ma wstępnie zainstalowane rozszerzenie Python Tools for Visual Studio (PTVS). Domyślnie tylko środowisko Conda w języku Python 3.6 jest skonfigurowane na serwerze PTVS. Aby włączyć środowisko Anaconda Python 2.7:
- Utwórz środowiska niestandardowe dla każdej wersji. Wybierz pozycję Narzędzia>języka Python Tools>Python Environments, a następnie wybierz pozycję + Custom w programie Visual Studio Community Edition.
- Podaj opis i ustaw ścieżkę prefiksu środowiska jako c:\anaconda\envs\python2 dla środowiska Anaconda Python 2.7.
- Wybierz pozycję Automatycznie wykryj>zastosuj, aby zapisać środowisko.
Aby uzyskać więcej informacji na temat tworzenia środowisk języka Python, odwiedź zasób dokumentacji PTVS.
Teraz możesz utworzyć nowy projekt w języku Python. Wybierz pozycję Plik>nowy>projekt>w języku Python i wybierz typ aplikacji języka Python, którą chcesz skompilować. Środowisko języka Python dla bieżącego projektu można ustawić na żądaną wersję (Python 2.7 lub 3.6), klikając prawym przyciskiem myszy środowiska języka Python, a następnie wybierając polecenie Dodaj/Usuń środowiska języka Python. Odwiedź dokumentację produktu, aby uzyskać więcej informacji na temat pracy z ptVS.
Zarządzanie zasobami platformy Azure
Maszyna DSVM umożliwia lokalne tworzenie rozwiązania analitycznego na maszynie wirtualnej. Umożliwia również dostęp do usług na platformie Azure w chmurze. Platforma Azure oferuje kilka usług, takich jak obliczenia, magazyn, analiza danych i nie tylko, które można administrować maszyną DSVM i uzyskiwać do tego dostęp.
Dostępne są dwie opcje administrowania subskrypcją platformy Azure i zasobami w chmurze:
Odwiedź witrynę Azure Portal w przeglądarce.
Użyj skryptów programu PowerShell. Uruchom program Azure PowerShell ze skrótu pulpitu lub z menu Start . Aby uzyskać więcej informacji, odwiedź zasób dokumentacji programu Microsoft Azure PowerShell.
Rozszerzanie magazynu przy użyciu udostępnionych systemów plików
Analitycy danych mogą udostępniać duże zestawy danych, kod lub inne zasoby w zespole. Maszyna DSVM ma około 45 GB dostępnego miejsca. Aby rozszerzyć magazyn, możesz użyć usługi Azure Files i zainstalować je na co najmniej jednym wystąpieniu maszyny WIRTUALNEJ DSVM lub uzyskać do niego dostęp za pomocą interfejsu API REST. Możesz również użyć witryny Azure Portal lub użyć programu Azure PowerShell, aby dodać dodatkowe dedykowane dyski danych.
Uwaga
Maksymalna ilość miejsca w udziale plików platformy Azure wynosi 5 TB. Każdy plik ma limit rozmiaru 1 TB.
Ten skrypt programu Azure PowerShell tworzy udział usługi Azure Files:
# Authenticate to Azure.
Connect-AzAccount
# Select your subscription
Get-AzSubscription –SubscriptionName "<your subscription name>" | Select-AzSubscription
# Create a new resource group.
New-AzResourceGroup -Name <dsvmdatarg>
# Create a new storage account. You can reuse existing storage account if you want.
New-AzStorageAccount -Name <mydatadisk> -ResourceGroupName <dsvmdatarg> -Location "<Azure Data Center Name For eg. South Central US>" -Type "Standard_LRS"
# Set your current working storage account
Set-AzCurrentStorageAccount –ResourceGroupName "<dsvmdatarg>" –StorageAccountName <mydatadisk>
# Create an Azure Files share
$s = New-AzStorageShare <<teamsharename>>
# Create a directory under the file share. You can give it any name
New-AzStorageDirectory -Share $s -Path <directory name>
# List the share to confirm that everything worked
Get-AzStorageFile -Share $s
Udział usługi Azure Files można zainstalować na dowolnej maszynie wirtualnej na platformie Azure. Zalecamy umieszczenie maszyny wirtualnej i konta magazynu w tym samym centrum danych platformy Azure, aby uniknąć opóźnień i opłat za transfer danych. Te polecenia programu Azure PowerShell umożliwiają zainstalowanie dysku na maszynie DSVM:
# Get the storage key of the storage account that has the Azure Files share from the Azure portal. Store it securely on the VM to avoid being prompted in the next command.
cmdkey /add:<<mydatadisk>>.file.core.windows.net /user:<<mydatadisk>> /pass:<storage key>
# Mount the Azure Files share as drive Z on the VM. You can choose another drive letter if you want.
net use z: \\<mydatadisk>.file.core.windows.net\<<teamsharename>>
Dostęp do tego dysku można uzyskać tak, jak w przypadku dowolnego normalnego dysku na maszynie wirtualnej.
Udostępnianie kodu w usłudze GitHub
Repozytorium kodu GitHub hostuje przykłady kodu i źródła kodu dla wielu narzędzi, które udostępnia społeczność deweloperów. Używa usługi Git jako technologii do śledzenia i przechowywania wersji plików kodu. Usługa GitHub służy również jako platforma do tworzenia własnego repozytorium. Własne repozytorium może przechowywać udostępniony kod i dokumentację zespołu, implementować kontrolę wersji i kontrolować uprawnienia dostępu dla uczestników projektu, którzy chcą wyświetlać i współtworzyć kod. Usługa GitHub obsługuje współpracę w zespole, korzystanie z kodu opracowanego przez społeczność i współtworzenie kodu z powrotem do społeczności. Odwiedź strony pomocy usługi GitHub, aby uzyskać więcej informacji na temat usługi Git.
Maszyna DSVM jest ładowana z narzędziami klienckimi w wierszu polecenia i w graficznym interfejsie użytkownika w celu uzyskania dostępu do repozytorium GitHub. Narzędzie wiersza polecenia powłoki Git Bash działa z usługami Git i GitHub. Program Visual Studio jest zainstalowany na maszynie DSVM i ma rozszerzenia Git. Zarówno menu Start, jak i pulpit mają ikony dla tych narzędzi.
Użyj polecenia , git clone aby pobrać kod z repozytorium GitHub. Aby pobrać repozytorium nauki o danych opublikowane przez firmę Microsoft do bieżącego katalogu, na przykład uruchom to polecenie w powłoce Git Bash:
git clone https://github.com/Azure/DataScienceVM.git
Program Visual Studio może obsługiwać tę samą operację klonowania. Ten zrzut ekranu przedstawia sposób uzyskiwania dostępu do narzędzi Git i GitHub w programie Visual Studio:

Możesz pracować z dostępnymi zasobami github.com w repozytorium GitHub. Aby uzyskać więcej informacji, odwiedź zasób ściągawek usługi GitHub.
Uzyskiwanie dostępu do usług danych i analiz platformy Azure
Azure Blob Storage
Azure Blob Storage to niezawodna, ekonomiczna usługa magazynu w chmurze zarówno dla dużych, jak i małych zasobów danych. W tej sekcji opisano sposób przenoszenia danych do usługi Blob Storage i uzyskiwania dostępu do danych przechowywanych w obiekcie blob platformy Azure.
Wymagania wstępne
Konto usługi Azure Blob Storage utworzone w witrynie Azure Portal.
Upewnij się, że narzędzie AzCopy wiersza polecenia jest wstępnie zainstalowane za pomocą następującego polecenia:
C:\Program Files (x86)\Microsoft SDKs\Azure\AzCopy\azcopy.exeKatalog hostujący azcopy.exe znajduje się już w zmiennej środowiskowej PATH, dzięki czemu można uniknąć wpisywania pełnej ścieżki polecenia podczas uruchamiania tego narzędzia. Aby uzyskać więcej informacji na temat narzędzia AzCopy, przeczytaj dokumentację narzędzia AzCopy.
Uruchom narzędzie Eksplorator usługi Azure Storage. Możesz pobrać go ze strony internetowej Eksplorator usługi Storage.


Przenoszenie danych z maszyny wirtualnej do obiektu blob platformy Azure: AzCopy
Aby przenieść dane między lokalnymi plikami i usługą Blob Storage, możesz użyć narzędzia AzCopy w wierszu polecenia lub w programie PowerShell:
AzCopy /Source:C:\myfolder /Dest:https://<mystorageaccount>.blob.core.windows.net/<mycontainer> /DestKey:<storage account key> /Pattern:abc.txt
- Zastąp plik C:\myfolder ścieżką katalogu hostująca plik
- Zastąp ciąg mystorageaccount nazwą konta usługi Blob Storage
- Zastąp ciąg mycontainer nazwą kontenera
- Zastąp klucz konta magazynu kluczem dostępu do usługi Blob Storage
Poświadczenia konta magazynu można znaleźć w witrynie Azure Portal.
Uruchom polecenie AzCopy w programie PowerShell lub w wierszu polecenia. Oto przykłady poleceń narzędzia AzCopy:
# Copy *.sql from a local machine to an Azure blob
"C:\Program Files (x86)\Microsoft SDKs\Azure\AzCopy\azcopy" /Source:"c:\Aaqs\Data Science Scripts" /Dest:https://[ENTER STORAGE ACCOUNT].blob.core.windows.net/[ENTER CONTAINER] /DestKey:[ENTER STORAGE KEY] /S /Pattern:*.sql
# Copy back all files from an Azure blob container to a local machine
"C:\Program Files (x86)\Microsoft SDKs\Azure\AzCopy\azcopy" /Dest:"c:\Aaqs\Data Science Scripts\temp" /Source:https://[ENTER STORAGE ACCOUNT].blob.core.windows.net/[ENTER CONTAINER] /SourceKey:[ENTER STORAGE KEY] /S
Po uruchomieniu polecenia AzCopy w celu skopiowania pliku do obiektu blob platformy Azure plik zostanie wyświetlony w Eksplorator usługi Azure Storage.

Przenoszenie danych z maszyny wirtualnej do obiektu blob platformy Azure: Eksplorator usługi Azure Storage
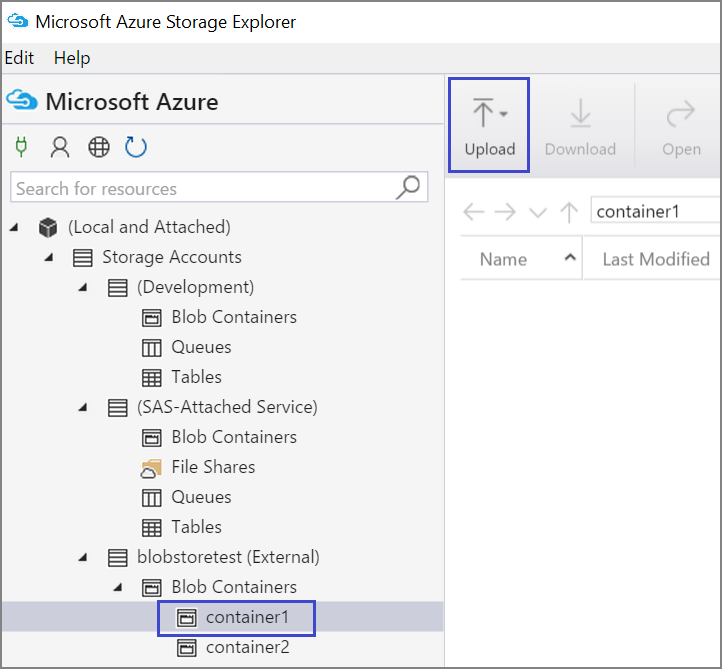
Możesz również przekazać dane z pliku lokalnego na maszynie wirtualnej przy użyciu Eksplorator usługi Azure Storage:
Aby przekazać dane do kontenera, wybierz kontener docelowy i wybierz przycisk Przekaż .
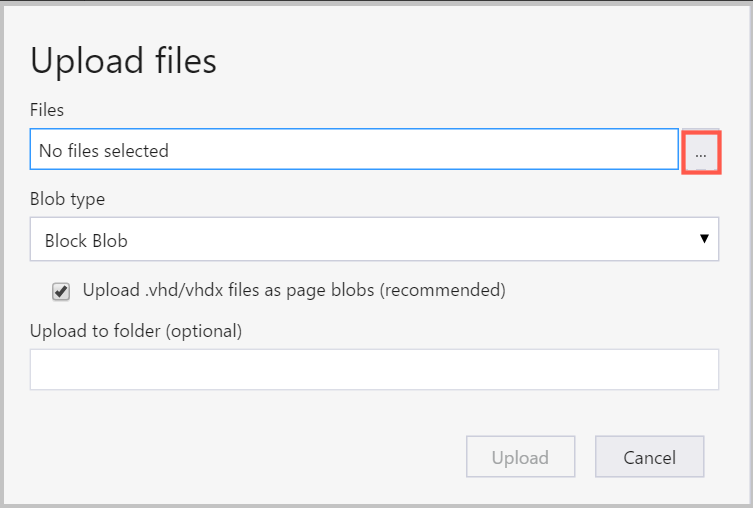
Po prawej stronie pola Pliki wybierz wielokropek (...), wybierz jeden lub wiele plików do przekazania z systemu plików, a następnie wybierz pozycję Przekaż , aby rozpocząć przekazywanie plików.


Odczytywanie danych z obiektu blob platformy Azure: Python ODBC
Biblioteka blobService może odczytywać dane bezpośrednio z obiektu blob znajdującego się w notesie Jupyter Lub w programie języka Python. Najpierw zaimportuj wymagane pakiety:
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
import matplotlib.pyplot as plt
from time import time
import pyodbc
import os
from azure.storage.blob import BlobService
import tables
import time
import zipfile
import random
Podłącz poświadczenia konta usługi Blob Storage i odczytaj dane z obiektu blob:
CONTAINERNAME = 'xxx'
STORAGEACCOUNTNAME = 'xxxx'
STORAGEACCOUNTKEY = 'xxxxxxxxxxxxxxxx'
BLOBNAME = 'nyctaxidataset/nyctaxitrip/trip_data_1.csv'
localfilename = 'trip_data_1.csv'
LOCALDIRECTORY = os.getcwd()
LOCALFILE = os.path.join(LOCALDIRECTORY, localfilename)
#download from blob
t1 = time.time()
blob_service = BlobService(account_name=STORAGEACCOUNTNAME,account_key=STORAGEACCOUNTKEY)
blob_service.get_blob_to_path(CONTAINERNAME,BLOBNAME,LOCALFILE)
t2 = time.time()
print(("It takes %s seconds to download "+BLOBNAME) % (t2 - t1))
#unzip downloaded files if needed
#with zipfile.ZipFile(ZIPPEDLOCALFILE, "r") as z:
# z.extractall(LOCALDIRECTORY)
df1 = pd.read_csv(LOCALFILE, header=0)
df1.columns = ['medallion','hack_license','vendor_id','rate_code','store_and_fwd_flag','pickup_datetime','dropoff_datetime','passenger_count','trip_time_in_secs','trip_distance','pickup_longitude','pickup_latitude','dropoff_longitude','dropoff_latitude']
print 'the size of the data is: %d rows and %d columns' % df1.shape
Dane są odczytywane jako ramka danych:

Azure Synapse Analytics i bazy danych
Usługa Azure Synapse Analytics to elastyczne dane "warehouse as a service" z funkcją SQL Server klasy korporacyjnej. W tym zasobie opisano sposób aprowizacji usługi Azure Synapse Analytics. Po aprowizacji usługi Azure Synapse Analytics w tym przewodniku wyjaśniono, jak obsługiwać przekazywanie, eksplorowanie i modelowanie danych przy użyciu danych w usłudze Azure Synapse Analytics.
Azure Cosmos DB
Azure Cosmos DB to oparta na chmurze baza danych NoSQL. Może ona obsługiwać na przykład dokumenty JSON i może przechowywać dokumenty i wykonywać względem niego zapytania. W poniższych przykładowych krokach pokazano, jak uzyskać dostęp do usługi Azure Cosmos DB z maszyny DSVM:
Zestaw SDK języka Python usługi Azure Cosmos DB jest już zainstalowany na maszynie WIRTUALNEJ DSVM. Aby go zaktualizować, uruchom polecenie
pip install pydocumentdb --upgradew wierszu polecenia.Utwórz konto i bazę danych usługi Azure Cosmos DB w witrynie Azure Portal.
Pobierz narzędzie do migracji danych usługi Azure Cosmos DB z Centrum pobierania Microsoft i wyodrębnij je do wybranego katalogu.
Zaimportuj dane JSON (dane wulkanu) przechowywane w publicznym obiekcie blob do usługi Azure Cosmos DB przy użyciu następujących parametrów polecenia do narzędzia migracji. (Użyj dtui.exe z katalogu, w którym zainstalowano narzędzie do migracji danych usługi Azure Cosmos DB). Wprowadź lokalizację źródłową i docelową z następującymi parametrami:
/s:JsonFile /s.Files:https://data.humdata.org/dataset/a60ac839-920d-435a-bf7d-25855602699d/resource/7234d067-2d74-449a-9c61-22ae6d98d928/download/volcano.json /t:DocumentDBBulk /t.ConnectionString:AccountEndpoint=https://[DocDBAccountName].documents.azure.com:443/;AccountKey=[[KEY];Database=volcano /t.Collection:volcano1
Po zaimportowaniu danych możesz przejść do programu Jupyter i otworzyć notes o nazwie DocumentDBSample. Zawiera on kod języka Python umożliwiający dostęp do usługi Azure Cosmos DB i obsługę niektórych podstawowych zapytań. Odwiedź stronę dokumentacji usługi Azure Cosmos DB, aby uzyskać więcej informacji na temat usługi Azure Cosmos DB.
Korzystanie z raportów i pulpitów nawigacyjnych usługi Power BI
Możesz zwizualizować plik JSON wulkanu opisany w poprzednim przykładzie usługi Azure Cosmos DB w programie Power BI Desktop, aby uzyskać wizualny wgląd w same dane. Ten artykuł usługi Power BI zawiera szczegółowe kroki. Są to kroki na wysokim poziomie:
- Otwórz program Power BI Desktop i wybierz pozycję Pobierz dane. Określ ten adres URL:
https://cahandson.blob.core.windows.net/samples/volcano.json. - Rekordy JSON zaimportowane jako lista powinny stać się widoczne. Przekonwertuj listę na tabelę, aby usługa Power BI mogła z nią pracować.
- Wybierz ikonę rozwijania (strzałki), aby rozwinąć kolumny.
- Lokalizacja jest polem Rekord . Rozwiń rekord i wybierz tylko współrzędne. Współrzędna jest kolumną listy.
- Dodaj nową kolumnę, aby przekonwertować kolumnę współrzędnych listy na kolumnę latlong rozdzielaną przecinkami. Użyj formuły
Text.From([coordinates]{1})&","&Text.From([coordinates]{0}), aby połączyć dwa elementy w polu listy współrzędnych. - Przekonwertuj kolumnę Podniesienie uprawnień na dziesiętną, a następnie wybierz przyciski Zamknij i Zastosuj .
Poniższy kod można użyć jako alternatywy dla powyższych kroków. Wykonuje skrypty kroków używanych w Edytor zaawansowany w usłudze Power BI w celu zapisania przekształceń danych w języku zapytań:
let
Source = Json.Document(Web.Contents("https://cahandson.blob.core.windows.net/samples/volcano.json")),
#"Converted to Table" = Table.FromList(Source, Splitter.SplitByNothing(), null, null, ExtraValues.Error),
#"Expanded Column1" = Table.ExpandRecordColumn(#"Converted to Table", "Column1", {"Volcano Name", "Country", "Region", "Location", "Elevation", "Type", "Status", "Last Known Eruption", "id"}, {"Volcano Name", "Country", "Region", "Location", "Elevation", "Type", "Status", "Last Known Eruption", "id"}),
#"Expanded Location" = Table.ExpandRecordColumn(#"Expanded Column1", "Location", {"coordinates"}, {"coordinates"}),
#"Added Custom" = Table.AddColumn(#"Expanded Location", "LatLong", each Text.From([coordinates]{1})&","&Text.From([coordinates]{0})),
#"Changed Type" = Table.TransformColumnTypes(#"Added Custom",{{"Elevation", type number}})
in
#"Changed Type"
Masz teraz dane w modelu danych usługi Power BI. Wystąpienie programu Power BI Desktop powinno wyglądać następująco:

Możesz rozpocząć tworzenie raportów i wizualizacji za pomocą modelu danych. W tym artykule dotyczącym usługi Power BI wyjaśniono, jak utworzyć raport.
Dynamiczne skalowanie maszyny DSVM
Maszynę DSVM można skalować w górę i w dół, aby zaspokoić potrzeby projektu. Jeśli nie musisz używać maszyny wirtualnej wieczorem lub w weekendy, możesz zamknąć maszynę wirtualną z witryny Azure Portal.
Uwaga
Opłaty za obliczenia są naliczane tylko wtedy, gdy używasz przycisku zamykania dla systemu operacyjnego na maszynie wirtualnej. Zamiast tego należy cofnąć przydział maszyny DSVM przy użyciu witryny Azure Portal lub usługi Cloud Shell.
W przypadku projektu analizy na dużą skalę może być potrzebna większa pojemność procesora CPU, pamięci lub dysku. Jeśli tak, możesz znaleźć maszyny wirtualne o różnych liczbach rdzeni procesora CPU, pojemności pamięci, typów dysków (w tym dysków półprzewodnikowych) i wystąpieniach opartych na procesorze GPU na potrzeby uczenia głębokiego, które spełniają potrzeby obliczeniowe i budżetowe. Na stronie cennika usługi Azure Virtual Machines jest wyświetlana pełna lista maszyn wirtualnych wraz z godzinowymi cenami obliczeniowymi.
Dodawanie kolejnych narzędzi
Maszyna DSVM oferuje wstępnie utworzone narzędzia, które mogą zaspokoić wiele typowych potrzeb analizy danych. Oszczędzają czas, ponieważ nie trzeba instalować i konfigurować środowisk indywidualnie. Oszczędzają one również pieniądze, ponieważ płacisz tylko za używane zasoby.
W celu ulepszenia środowiska analitycznego możesz użyć innych usług danych i analiz platformy Azure profilowanych w tym artykule. W niektórych przypadkach może być potrzebne inne narzędzia, w tym określone zastrzeżone narzędzia partnerskie. Masz pełny dostęp administracyjny na maszynie wirtualnej, aby zainstalować potrzebne narzędzia. Możesz również zainstalować inne pakiety w języku Python i R, które nie są wstępnie zainstalowane. W przypadku języka Python możesz użyć conda polecenia lub pip. W przypadku języka R można użyć w konsoli języka R lub użyć install.packages() środowiska IDE i wybrać pozycję Pakiety Instaluj pakiety>.
Uczenie głębokie
Oprócz przykładów opartych na strukturze można uzyskać zestaw kompleksowych przewodników, które zostały zweryfikowane na maszynie DSVM. Te przewodniki ułatwiają szybkie rozpoczęcie tworzenia aplikacji uczenia głębokiego w domenach obrazów i analizy tekstu/języka.
Uruchamianie sieci neuronowych w różnych strukturach: w tym przewodniku pokazano, jak migrować kod z jednej platformy do innej. Pokazano również, jak porównać modele i wydajność środowiska uruchomieniowego w różnych strukturach.
Przewodnik z instrukcjami tworzenia kompleksowego rozwiązania do wykrywania produktów na obrazach: Technika wykrywania obrazów umożliwia lokalizowanie i klasyfikowanie obiektów na obrazach. Ta technologia ma potencjał, aby przynieść ogromne nagrody w wielu rzeczywistych domenach biznesowych. Na przykład sprzedawcy detaliczni mogą użyć tej techniki, aby zidentyfikować produkt, który klient odebrał z półki. Te informacje ułatwiają sklepom detalicznym zarządzanie spisem produktów.
Uczenie głębokie dla dźwięku: w tym samouczku pokazano, jak wytrenować model uczenia głębokiego na potrzeby wykrywania zdarzeń dźwiękowych w zestawie danych dźwięku miejskiego. Zawiera również omówienie sposobu pracy z danymi audio.
Klasyfikacja dokumentów tekstowych: w tym przewodniku pokazano, jak utworzyć i wytrenować dwie architektury sieci neuronowej: hierarchiczną sieć uwagi i sieć pamięci krótkoterminowej (LSTM). Te sieci neuronowe używają interfejsu API Keras do uczenia głębokiego do klasyfikowania dokumentów tekstowych.
Podsumowanie
W tym artykule opisano niektóre czynności, które można wykonać na maszynie wirtualnej microsoft Nauka o danych. Istnieje wiele innych rzeczy, które można zrobić, aby maszyna DSVM była skutecznym środowiskiem analitycznym.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla