Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Zestaw PYTHON SDK azure-ai-ml w wersji 2 (bieżąca)
Zestaw PYTHON SDK azure-ai-ml w wersji 2 (bieżąca)
Projekt uczenia maszynowego zwykle rozpoczyna się od eksploracyjnej analizy danych (EDA), przetwarzania wstępnego danych (czyszczenia, inżynierii cech) i obejmuje tworzenie prototypów modeli uczenia maszynowego w celu zweryfikowania hipotez. Ta faza tworzenia prototypów projektu jest wysoce interaktywna i nadaje się do programowania w notesie Jupyter lub w środowisku IDE z interaktywną konsolą języka Python. Z tego artykułu dowiesz się, jak wykonywać następujące działania:
- Uzyskiwanie dostępu do danych z identyfikatora URI magazynu danych usługi Azure Machine Learning w taki sposób, jakby był to system plików.
- Materializuj dane do biblioteki Pandas przy użyciu
mltablebiblioteki języka Python. - Materializuj zasoby danych usługi Azure Machine Learning do biblioteki Pandas przy użyciu
mltablebiblioteki języka Python. - Materializuj dane za pomocą jawnego pobierania za
azcopypomocą narzędzia .
Wymagania wstępne
- Obszar roboczy usługi Azure Machine Learning. Aby uzyskać więcej informacji, odwiedź stronę Zarządzanie obszarami roboczymi usługi Azure Machine Learning w portalu lub przy użyciu zestawu SDK języka Python (wersja 2).
- Magazyn danych usługi Azure Machine Learning. Aby uzyskać więcej informacji, odwiedź stronę Tworzenie magazynów danych.
Napiwek
Wskazówki zawarte w tym artykule opisują dostęp do danych podczas opracowywania interakcyjnego. Dotyczy to dowolnego hosta, który może uruchomić sesję języka Python. Może to obejmować maszynę lokalną, maszynę wirtualną w chmurze, usługę GitHub Codespace itp. Zalecamy użycie wystąpienia obliczeniowego usługi Azure Machine Learning — w pełni zarządzanej i wstępnie skonfigurowanej stacji roboczej w chmurze. Aby uzyskać więcej informacji, odwiedź stronę Tworzenie wystąpienia obliczeniowego usługi Azure Machine Learning.
Ważne
Upewnij się, że masz zainstalowane najnowsze azure-fsspecbiblioteki , mltablei azure-ai-ml python w środowisku języka Python:
pip install -U azureml-fsspec==1.3.1 mltable azure-ai-ml
Najnowsza azure-fsspec wersja pakietu może potencjalnie ulec zmianie w czasie. Aby uzyskać więcej informacji na temat azure-fsspec pakietu, odwiedź ten zasób.
Uzyskiwanie dostępu do danych z identyfikatora URI magazynu danych, takiego jak system plików
Magazyn danych usługi Azure Machine Learning to odwołanie do istniejącego konta usługi Azure Storage. Zalety tworzenia i używania magazynu danych obejmują:
- Typowy, łatwy w użyciu interfejs API do interakcji z różnymi typami magazynu (Blob/Files/ADLS).
- Łatwe odnajdywanie przydatnych magazynów danych w operacjach zespołowych.
- Obsługa dostępu opartego na poświadczeniach (na przykład tokenu SAS) i opartego na tożsamości (użyj identyfikatora Microsoft Entra ID lub tożsamości manged) w celu uzyskania dostępu do danych.
- W przypadku dostępu opartego na poświadczeniach informacje o połączeniu są zabezpieczone w celu unieważnienia ujawnienia klucza w skryptach.
- Przeglądanie danych i wklejanie identyfikatorów URI magazynu danych w interfejsie użytkownika programu Studio.
Identyfikator URI magazynu danych to jednolity identyfikator zasobu, który jest odwołaniemdo lokalizacji magazynu (ścieżki) na koncie usługi Azure Storage. Identyfikator URI magazynu danych ma następujący format:
# Azure Machine Learning workspace details:
subscription = '<subscription_id>'
resource_group = '<resource_group>'
workspace = '<workspace>'
datastore_name = '<datastore>'
path_on_datastore = '<path>'
# long-form Datastore uri format:
uri = f'azureml://subscriptions/{subscription}/resourcegroups/{resource_group}/workspaces/{workspace}/datastores/{datastore_name}/paths/{path_on_datastore}'.
Te identyfikatory URI magazynu danych to znana implementacja specyfikacji systemu plików (fsspec): ujednolicony interfejs języka Python dla lokalnych, zdalnych i osadzonych systemów plików oraz magazynu bajtów. Najpierw użyj narzędzia, aby zainstalować azureml-fsspec pakiet i jego pakiet zależności azureml-dataprep . Następnie możesz użyć implementacji magazynu fsspec danych usługi Azure Machine Learning.
Implementacja magazynu fsspec danych usługi Azure Machine Learning automatycznie obsługuje przekazywanie poświadczeń/tożsamości używane przez magazyn danych usługi Azure Machine Learning. Można uniknąć ujawnienia klucza konta w skryptach i dodatkowych procedur logowania w wystąpieniu obliczeniowym.
Możesz na przykład bezpośrednio użyć identyfikatorów URI magazynu danych w bibliotece Pandas. W tym przykładzie pokazano, jak odczytać plik CSV:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
df.head()
Napiwek
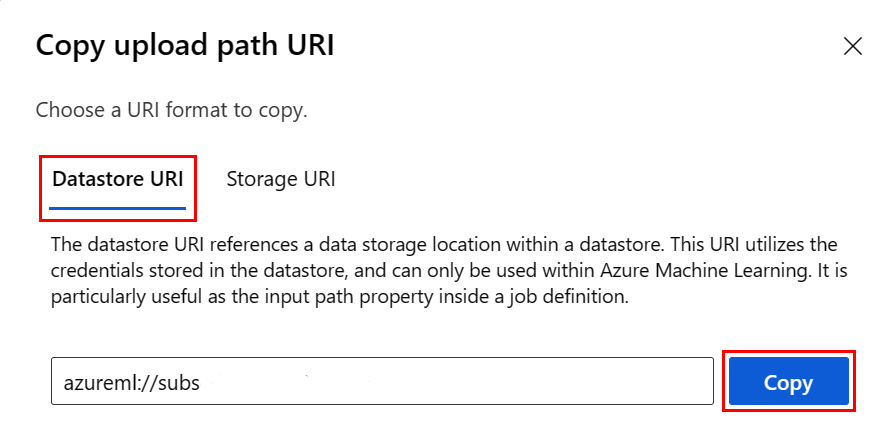
Aby uniknąć zapamiętowania formatu identyfikatora URI magazynu danych, możesz skopiować i wkleić identyfikator URI magazynu danych z poziomu interfejsu użytkownika programu Studio, wykonując następujące kroki:
- Wybierz pozycję Dane z menu po lewej stronie, a następnie wybierz kartę Magazyny danych.
- Wybierz nazwę magazynu danych, a następnie pozycję Przeglądaj.
- Znajdź plik/folder, który chcesz odczytać w bibliotece Pandas, i wybierz obok niego wielokropek (...). Wybierz pozycję Kopiuj identyfikator URI z menu. Możesz wybrać identyfikator URI magazynu danych, aby skopiować go do notesu/skryptu.
Możesz również utworzyć wystąpienie systemu plików usługi Azure Machine Learning, aby obsługiwać polecenia podobne do systemu plików — na przykład ls, , globexists, open.
- Metoda
ls()wyświetla listę plików w określonym katalogu. Do wyświetlania listy plików można użyć ls(), ls(.), ls (<<folder_level_1>/<folder_level_2>). Obsługujemy zarówno ścieżki '.', jak i '..', w ścieżkach względnych. - Metoda
glob()obsługuje globbing "*" i "**". - Metoda
exists()zwraca wartość logiczną wskazującą, czy określony plik istnieje w bieżącym katalogu głównym. - Metoda
open()zwraca obiekt podobny do pliku, który można przekazać do dowolnej innej biblioteki, która oczekuje pracy z plikami języka Python. Kod może również używać tego obiektu, tak jakby był to normalny obiekt pliku języka Python. Te obiekty podobne do plików szanują użyciewithkontekstów, jak pokazano w tym przykładzie:
from azureml.fsspec import AzureMachineLearningFileSystem
# instantiate file system using following URI
fs = AzureMachineLearningFileSystem('azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastore*s*/datastorename')
fs.ls() # list folders/files in datastore 'datastorename'
# output example:
# folder1
# folder2
# file3.csv
# use an open context
with fs.open('./folder1/file1.csv') as f:
# do some process
process_file(f)
Przekazywanie plików za pośrednictwem elementu AzureMachineLearningFileSystem
from azureml.fsspec import AzureMachineLearningFileSystem
# instantiate file system using following URI
fs = AzureMachineLearningFileSystem('azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastorename>/paths/')
# you can specify recursive as False to upload a file
fs.upload(lpath='data/upload_files/crime-spring.csv', rpath='data/fsspec', recursive=False, **{'overwrite': 'MERGE_WITH_OVERWRITE'})
# you need to specify recursive as True to upload a folder
fs.upload(lpath='data/upload_folder/', rpath='data/fsspec_folder', recursive=True, **{'overwrite': 'MERGE_WITH_OVERWRITE'})
lpath jest ścieżką lokalną i rpath jest ścieżką zdalną.
Jeśli foldery określone w rpath pliku jeszcze nie istnieją, utworzymy foldery dla Ciebie.
Obsługujemy trzy tryby zastępowania:
- APPEND: jeśli plik o tej samej nazwie istnieje w ścieżce docelowej, funkcja APPEND przechowuje oryginalny plik
- FAIL_ON_FILE_CONFLICT: jeśli plik o tej samej nazwie istnieje w ścieżce docelowej, FAIL_ON_FILE_CONFLICT zgłasza błąd
- MERGE_WITH_OVERWRITE: jeśli plik o tej samej nazwie istnieje w ścieżce docelowej, MERGE_WITH_OVERWRITE zastąpi istniejący plik nowym plikiem
Pobieranie plików za pośrednictwem usługi AzureMachineLearningFileSystem
# you can specify recursive as False to download a file
# downloading overwrite option is determined by local system, and it is MERGE_WITH_OVERWRITE
fs.download(rpath='data/fsspec/crime-spring.csv', lpath='data/download_files/, recursive=False)
# you need to specify recursive as True to download a folder
fs.download(rpath='data/fsspec_folder', lpath='data/download_folder/', recursive=True)
Przykłady
W tych przykładach pokazano użycie specyfikacji systemu plików w typowych scenariuszach.
Odczytywanie pojedynczego pliku CSV do biblioteki Pandas
Pojedynczy plik CSV można odczytać w bibliotece Pandas, jak pokazano poniżej:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
Odczytywanie folderu plików CSV w bibliotece Pandas
Metoda Pandas read_csv() nie obsługuje odczytywania folderu plików CSV. Aby to obsłużyć, utwórz globing ścieżek csv i połącz je z ramką danych za pomocą metody Pandas concat() . W następnym przykładzie kodu pokazano, jak osiągnąć to połączenie z systemem plików usługi Azure Machine Learning:
import pandas as pd
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# append csv files in folder to a list
dflist = []
for path in fs.glob('/<folder>/*.csv'):
with fs.open(path) as f:
dflist.append(pd.read_csv(f))
# concatenate data frames
df = pd.concat(dflist)
df.head()
Odczytywanie plików CSV w języku Dask
W tym przykładzie pokazano, jak odczytać plik CSV do ramki danych dask:
import dask.dd as dd
df = dd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
df.head()
Odczytywanie folderu plików parquet do biblioteki Pandas
W ramach procesu ETL pliki Parquet są zwykle zapisywane w folderze, co może następnie emitować pliki istotne dla ETL, takie jak postęp, zatwierdzenia itp. W tym przykładzie pokazano pliki utworzone na podstawie procesu ETL (pliki rozpoczynające się od _), które następnie tworzą plik parquet danych.
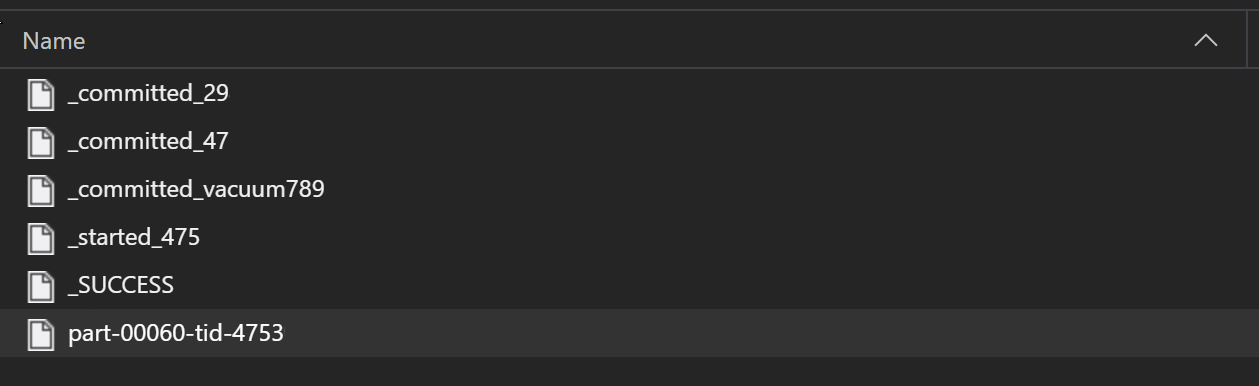
W tych scenariuszach odczytujesz tylko pliki parquet w folderze i ignorujesz pliki procesów ETL. W tym przykładzie kodu pokazano, jak wzorce glob mogą odczytywać tylko pliki parquet w folderze:
import pandas as pd
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# append parquet files in folder to a list
dflist = []
for path in fs.glob('/<folder>/*.parquet'):
with fs.open(path) as f:
dflist.append(pd.read_parquet(f))
# concatenate data frames
df = pd.concat(dflist)
df.head()
Uzyskiwanie dostępu do danych z systemu plików usługi Azure Databricks (dbfs)
Specyfikacja systemu plików (fsspec) zawiera szereg znanych implementacji, w tym system plików usługi Databricks (dbfs).
Aby uzyskać dostęp do danych z dbfs zasobu, potrzebne są następujące elementy:
-
Nazwa wystąpienia w postaci
adb-<some-number>.<two digits>.azuredatabricks.net. Tę wartość można znaleźć w adresie URL obszaru roboczego usługi Azure Databricks. - Osobisty token dostępu (PAT); aby uzyskać więcej informacji na temat tworzenia tokenu pat, odwiedź stronę Authentication using Azure Databricks personal access tokens (Uwierzytelnianie przy użyciu osobistych tokenów dostępu usługi Azure Databricks)
Przy użyciu tych wartości należy utworzyć zmienną środowiskową tokenu PAT w wystąpieniu obliczeniowym:
export ADB_PAT=<pat_token>
Następnie możesz uzyskać dostęp do danych w bibliotece Pandas, jak pokazano w tym przykładzie:
import os
import pandas as pd
pat = os.getenv(ADB_PAT)
path_on_dbfs = '<absolute_path_on_dbfs>' # e.g. /folder/subfolder/file.csv
storage_options = {
'instance':'adb-<some-number>.<two digits>.azuredatabricks.net',
'token': pat
}
df = pd.read_csv(f'dbfs://{path_on_dbfs}', storage_options=storage_options)
Odczytywanie obrazów za pomocą polecenia pillow
from PIL import Image
from azureml.fsspec import AzureMachineLearningFileSystem
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
with fs.open('/<folder>/<image.jpeg>') as f:
img = Image.open(f)
img.show()
Przykład niestandardowego zestawu danych PyTorch
W tym przykładzie utworzysz niestandardowy zestaw danych PyTorch do przetwarzania obrazów. Zakładamy, że plik adnotacji (w formacie CSV) istnieje z tą ogólną strukturą:
image_path, label
0/image0.png, label0
0/image1.png, label0
1/image2.png, label1
1/image3.png, label1
2/image4.png, label2
2/image5.png, label2
Podfoldery przechowują te obrazy zgodnie z ich etykietami:
/
└── 📁images
├── 📁0
│ ├── 📷image0.png
│ └── 📷image1.png
├── 📁1
│ ├── 📷image2.png
│ └── 📷image3.png
└── 📁2
├── 📷image4.png
└── 📷image5.png
Niestandardowa klasa zestawu danych PyTorch musi implementować trzy funkcje: __init__, i __len____getitem__, jak pokazano poniżej:
import os
import pandas as pd
from PIL import Image
from torch.utils.data import Dataset
class CustomImageDataset(Dataset):
def __init__(self, filesystem, annotations_file, img_dir, transform=None, target_transform=None):
self.fs = filesystem
f = filesystem.open(annotations_file)
self.img_labels = pd.read_csv(f)
f.close()
self.img_dir = img_dir
self.transform = transform
self.target_transform = target_transform
def __len__(self):
return len(self.img_labels)
def __getitem__(self, idx):
img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])
f = self.fs.open(img_path)
image = Image.open(f)
f.close()
label = self.img_labels.iloc[idx, 1]
if self.transform:
image = self.transform(image)
if self.target_transform:
label = self.target_transform(label)
return image, label
Następnie możesz utworzyć wystąpienie zestawu danych, jak pokazano poniżej:
from azureml.fsspec import AzureMachineLearningFileSystem
from torch.utils.data import DataLoader
# define the URI - update <> placeholders
uri = 'azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>'
# create the filesystem
fs = AzureMachineLearningFileSystem(uri)
# create the dataset
training_data = CustomImageDataset(
filesystem=fs,
annotations_file='/annotations.csv',
img_dir='/<path_to_images>/'
)
# Prepare your data for training with DataLoaders
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True)
Materializowanie danych do biblioteki Pandas przy użyciu mltable biblioteki
Biblioteka mltable może również ułatwić dostęp do danych w magazynie w chmurze. Odczytywanie danych do biblioteki Pandas z następującym ogólnym formatem mltable :
import mltable
# define a path or folder or pattern
path = {
'file': '<supported_path>'
# alternatives
# 'folder': '<supported_path>'
# 'pattern': '<supported_path>'
}
# create an mltable from paths
tbl = mltable.from_delimited_files(paths=[path])
# alternatives
# tbl = mltable.from_parquet_files(paths=[path])
# tbl = mltable.from_json_lines_files(paths=[path])
# tbl = mltable.from_delta_lake(paths=[path])
# materialize to Pandas
df = tbl.to_pandas_dataframe()
df.head()
Obsługiwane ścieżki
Biblioteka mltable obsługuje odczytywanie danych tabelarycznych z różnych typów ścieżek:
| Lokalizacja | Przykłady |
|---|---|
| Ścieżka na komputerze lokalnym | ./home/username/data/my_data |
| Ścieżka na publicznym serwerze HTTP | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
| Ścieżka w usłudze Azure Storage | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path> abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
| Długi magazyn danych usługi Azure Machine Learning | azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<wsname>/datastores/<name>/paths/<path> |
Uwaga
mltable Program wykonuje przekazywanie poświadczeń użytkownika dla ścieżek w magazynach danych usługi Azure Storage i Azure Machine Learning. Jeśli nie masz uprawnień dostępu do danych w magazynie bazowym, nie możesz uzyskać dostępu do danych.
Pliki, foldery i globy
mltable program obsługuje odczytywanie z:
- pliki — na przykład:
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-csv.csv - foldery — na przykład
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-folder/ -
wzorce globu — na przykład
abfss://<file_system>@<account_name>.dfs.core.windows.net/my-folder/*.csv - kombinacja plików, folderów i/lub wzorców symboli globbingowych
mltable elastyczność umożliwia materializację danych w jedną ramkę danych z kombinacji zasobów magazynu lokalnego i w chmurze oraz kombinacji plików/folderów/globów. Na przykład:
path1 = {
'file': 'abfss://filesystem@account1.dfs.core.windows.net/my-csv.csv'
}
path2 = {
'folder': './home/username/data/my_data'
}
path3 = {
'pattern': 'abfss://filesystem@account2.dfs.core.windows.net/folder/*.csv'
}
tbl = mltable.from_delimited_files(paths=[path1, path2, path3])
Obsługiwane formaty plików
mltable program obsługuje następujące formaty plików:
- Rozdzielany tekst (na przykład: pliki CSV):
mltable.from_delimited_files(paths=[path]) - Parkiet:
mltable.from_parquet_files(paths=[path]) - Delta:
mltable.from_delta_lake(paths=[path]) - Format wierszy JSON:
mltable.from_json_lines_files(paths=[path])
Przykłady
Odczytywanie pliku CSV
Zaktualizuj symbole zastępcze (<>) w tym fragmencie kodu przy użyciu określonych szczegółów:
import mltable
path = {
'file': 'abfss://<filesystem>@<account>.dfs.core.windows.net/<folder>/<file_name>.csv'
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Odczytywanie plików parquet w folderze
W tym przykładzie pokazano, jak mltable można używać wzorców globu , takich jak symbole wieloznaczne , aby upewnić się, że tylko pliki parquet są odczytywane.
Zaktualizuj symbole zastępcze (<>) w tym fragmencie kodu przy użyciu określonych szczegółów:
import mltable
path = {
'pattern': 'abfss://<filesystem>@<account>.dfs.core.windows.net/<folder>/*.parquet'
}
tbl = mltable.from_parquet_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Odczytywanie zasobów danych
W tej sekcji pokazano, jak uzyskać dostęp do zasobów danych usługi Azure Machine Learning w bibliotece Pandas.
Zasób tabeli
Jeśli wcześniej utworzono zasób tabeli w usłudze Azure Machine Learning (lub mltablew wersji 1 TabularDataset), możesz załadować ten zasób tabeli do biblioteki Pandas przy użyciu następującego kodu:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
tbl = mltable.load(f'azureml:/{data_asset.id}')
df = tbl.to_pandas_dataframe()
df.head()
Zasób pliku
Jeśli zarejestrowano zasób pliku (na przykład plik CSV), możesz odczytać ten zasób do ramki danych biblioteki Pandas przy użyciu następującego kodu:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
path = {
'file': data_asset.path
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Zasób folderu
Jeśli zarejestrowano zasób folderu (uri_folder lub V1 FileDataset) — na przykład folder zawierający plik CSV — możesz odczytać ten zasób do ramki danych biblioteki Pandas przy użyciu następującego kodu:
import mltable
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
data_asset = ml_client.data.get(name="<name_of_asset>", version="<version>")
path = {
'folder': data_asset.path
}
tbl = mltable.from_delimited_files(paths=[path])
df = tbl.to_pandas_dataframe()
df.head()
Uwaga dotycząca odczytywania i przetwarzania dużych woluminów danych za pomocą biblioteki Pandas
Napiwek
Biblioteka Pandas nie jest przeznaczona do obsługi dużych zestawów danych. Biblioteka Pandas może przetwarzać tylko dane, które mogą mieścić się w pamięci wystąpienia obliczeniowego.
W przypadku dużych zestawów danych zalecamy użycie zarządzanej platformy Spark w usłudze Azure Machine Learning. Zapewnia to interfejs API biblioteki Pandas PySpark.
Przed skalowaniem w górę do zdalnego zadania asynchronicznego warto szybko wykonać iterację w mniejszym podzestawie dużego zestawu danych.
mltable udostępnia wbudowane funkcje umożliwiające pobieranie przykładów dużych danych przy użyciu metody take_random_sample :
import mltable
path = {
'file': 'https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv'
}
tbl = mltable.from_delimited_files(paths=[path])
# take a random 30% sample of the data
tbl = tbl.take_random_sample(probability=.3)
df = tbl.to_pandas_dataframe()
df.head()
Możesz również wziąć podzbióry dużych danych za pomocą następujących operacji:
Pobieranie danych przy użyciu azcopy narzędzia
azcopy Użyj narzędzia , aby pobrać dane do lokalnego dysku SSD hosta (maszyny lokalnej, maszyny wirtualnej w chmurze, wystąpienia obliczeniowego usługi Azure Machine Learning itp.) do lokalnego systemu plików. Narzędzie azcopy , które jest wstępnie zainstalowane w wystąpieniu obliczeniowym usługi Azure Machine Learning, obsługuje pobieranie danych. Jeśli nie używasz azcopy Aby uzyskać więcej informacji, odwiedź stronę azcopy.
Uwaga
Nie zalecamy pobierania danych do lokalizacji w wystąpieniu /home/azureuser/cloudfiles/code obliczeniowym. Ta lokalizacja jest przeznaczona do przechowywania artefaktów notesu i kodu, a nie danych. Odczytywanie danych z tej lokalizacji spowoduje znaczne obciążenie związane z wydajnością podczas trenowania. Zamiast tego zalecamy magazyn danych w obiekcie home/azureuser, który jest lokalnym dyskiem SSD węzła obliczeniowego.
Otwórz terminal i utwórz nowy katalog, na przykład:
mkdir /home/azureuser/data
Zaloguj się do narzędzia azcopy przy użyciu:
azcopy login
Następnie możesz skopiować dane przy użyciu identyfikatora URI magazynu
SOURCE=https://<account_name>.blob.core.windows.net/<container>/<path>
DEST=/home/azureuser/data
azcopy cp $SOURCE $DEST