Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Zestaw SDK języka Python w wersji 1
Zestaw SDK języka Python w wersji 1
Ważne
Ten artykuł zawiera informacje na temat korzystania z zestawu Azure Machine Learning SDK w wersji 1. Zestaw SDK w wersji 1 jest przestarzały od 31 marca 2025 r. i wsparcie dla niego zakończy się 30 czerwca 2026 r. Do tej pory możesz zainstalować zestaw SDK w wersji 1 i korzystać z niego.
Zalecamy przejście do zestawu SDK w wersji 2 przed 30 czerwca 2026 r. Aby uzyskać więcej informacji na temat zestawu SDK w wersji 2, zobacz Co to jest zestaw SDK języka Python usługi Azure Machine Learning w wersji 2 i dokumentacja zestawu SDK w wersji 2.
W tym artykule pokazano, jak zbierać dane z modelu usługi Azure Machine Learning wdrożonego w klastrze usługi Azure Kubernetes Service (AKS). Zebrane dane są następnie przechowywane w usłudze Azure Blob Storage.
Po włączeniu kolekcji zbierane dane ułatwiają wykonywanie następujących zadań:
Monitoruj dryfy danych na zbieranych danych produkcyjnych.
Analizowanie zebranych danych przy użyciu usługi Power BI lub usługi Azure Databricks
Podejmowanie lepszych decyzji dotyczących ponownego trenowania lub optymalizowania modelu.
Ponowne trenowanie modelu przy użyciu zebranych danych.
Ograniczenia
- Funkcja zbierania danych modelu może działać tylko z obrazem ubuntu 18.04.
Ważne
Od 10.03.2023 r. obraz ubuntu 18.04 jest teraz przestarzały. Obsługa obrazów z systemem Ubuntu 18.04 zostanie przerwana od stycznia 2023 r., gdy osiągnie poziom EOL 30 kwietnia 2023 r.
Funkcja MDC jest niezgodna z dowolnym innym obrazem niż Ubuntu 18.04, który nie jest dostępny po wycofaniu obrazu Ubuntu 18.04.
Więcej informacji można znaleźć w:
Uwaga
Funkcja zbierania danych jest obecnie dostępna w wersji zapoznawczej. Wszystkie funkcje w wersji zapoznawczej nie są zalecane w przypadku obciążeń produkcyjnych.
Co jest zbierane i gdzie idzie
Można zebrać następujące dane:
Modelowanie danych wejściowych z usług internetowych wdrożonych w klastrze usługi AKS. Dźwięk głosowy, obrazy i wideo nie są zbierane.
Przewidywanie modelu przy użyciu danych wejściowych produkcji.
Uwaga
Wstępne agregowanie i wstępne obliczenia na tych danych nie są obecnie częścią usługi zbierania.
Dane wyjściowe są zapisywane w usłudze Blob Storage. Ponieważ dane są dodawane do usługi Blob Storage, możesz wybrać ulubione narzędzie do uruchomienia analizy.
Ścieżka do danych wyjściowych w obiekcie blob jest następująca składnia:
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv
# example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv
Uwaga
W wersjach zestawu Azure Machine Learning SDK dla języka Python starszych niż wersja 0.1.0a16 designation argument nosi nazwę identifier. Jeśli kod został opracowany przy użyciu starszej wersji, należy go odpowiednio zaktualizować.
Wymagania wstępne
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Należy zainstalować obszar roboczy usługi Azure Machine Learning, katalog lokalny zawierający skrypty oraz zestaw SDK usługi Azure Machine Learning dla języka Python. Aby dowiedzieć się, jak je zainstalować, zobacz Jak skonfigurować środowisko deweloperskie.
Do wdrożenia w usłudze AKS potrzebny jest wytrenowany model uczenia maszynowego. Jeśli nie masz modelu, zobacz samouczek Trenowanie modelu klasyfikacji obrazów.
Potrzebny jest klaster usługi AKS. Aby uzyskać informacje na temat tworzenia jednego i wdrażania, zobacz Wdrażanie modeli uczenia maszynowego na platformie Azure.
Skonfiguruj środowisko i zainstaluj zestaw SDK monitorowania usługi Azure Machine Learning.
Użyj obrazu platformy Docker opartego na systemie Ubuntu 18.04, który jest dostarczany z usługą
libssl 1.0.0, podstawowa zależność modeludatacollector. Możesz odwoływać się do wstępnie skompilowanych obrazów.
Włączanie zbierania danych
Zbieranie danych można włączyć niezależnie od modelu wdrażanego za pomocą usługi Azure Machine Learning lub innych narzędzi.
Aby włączyć zbieranie danych, należy wykonać następujące kroki:
Otwórz plik oceniania.
Dodaj następujący kod w górnej części pliku:
from azureml.monitoring import ModelDataCollectorZadeklaruj zmienne zbierania danych w
initfunkcji:global inputs_dc, prediction_dc inputs_dc = ModelDataCollector("best_model", designation="inputs", feature_names=["feat1", "feat2", "feat3", "feat4", "feat5", "feat6"]) prediction_dc = ModelDataCollector("best_model", designation="predictions", feature_names=["prediction1", "prediction2"])CorrelationId jest opcjonalnym parametrem. Nie musisz go używać, jeśli model go nie wymaga. Użycie identyfikatora CorrelationId ułatwia mapowania z innymi danymi, takimi jak LoanNumber lub CustomerId.
Parametr Identyfikator jest później używany do tworzenia struktury folderów w obiekcie blob. Można go użyć do odróżnienia danych pierwotnych od przetworzonych danych.
Dodaj następujące wiersze kodu do
run(input_df)funkcji:data = np.array(data) result = model.predict(data) inputs_dc.collect(data) #this call is saving our input data into Azure Blob prediction_dc.collect(result) #this call is saving our prediction data into Azure BlobZbieranie danych nie jest automatycznie ustawione na wartość true podczas wdrażania usługi w usłudze AKS. Zaktualizuj plik konfiguracji, tak jak w poniższym przykładzie:
aks_config = AksWebservice.deploy_configuration(collect_model_data=True)Możesz również włączyć usługę Application Insights na potrzeby monitorowania usług, zmieniając tę konfigurację:
aks_config = AksWebservice.deploy_configuration(collect_model_data=True, enable_app_insights=True)Aby utworzyć nowy obraz i wdrożyć model uczenia maszynowego, zobacz Wdrażanie modeli uczenia maszynowego na platformie Azure.
Dodaj pakiet "Azure-Monitoring" do zależności conda środowiska usługi internetowej:
env = Environment('webserviceenv')
env.python.conda_dependencies = CondaDependencies.create(conda_packages=['numpy'],pip_packages=['azureml-defaults','azureml-monitoring','inference-schema[numpy-support]'])
Wyłączanie zbierania danych
Zbieranie danych można zatrzymać w dowolnym momencie. Użyj kodu w języku Python, aby wyłączyć zbieranie danych.
## replace <service_name> with the name of the web service
<service_name>.update(collect_model_data=False)
Weryfikowanie i analizowanie danych
Możesz wybrać narzędzie preferencji do analizowania danych zebranych w usłudze Blob Storage.
Szybki dostęp do danych obiektu blob
Zaloguj się do Portalu Azure.
Otwórz obszar roboczy.
Wybierz pozycję Magazyn.

Postępuj zgodnie ze ścieżką do danych wyjściowych obiektu blob przy użyciu następującej składni:
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv # example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv

Analizowanie danych modelu przy użyciu usługi Power BI
Pobierz i otwórz program Power BI Desktop.
Wybierz pozycję Pobierz dane i wybierz pozycję Azure Blob Storage.
Dodaj nazwę konta magazynu i wprowadź klucz magazynu. Te informacje można znaleźć, wybierając pozycję Ustawienia>Klucze dostępu w obiekcie blob.
Wybierz kontener danych modelu i wybierz pozycję Edytuj.
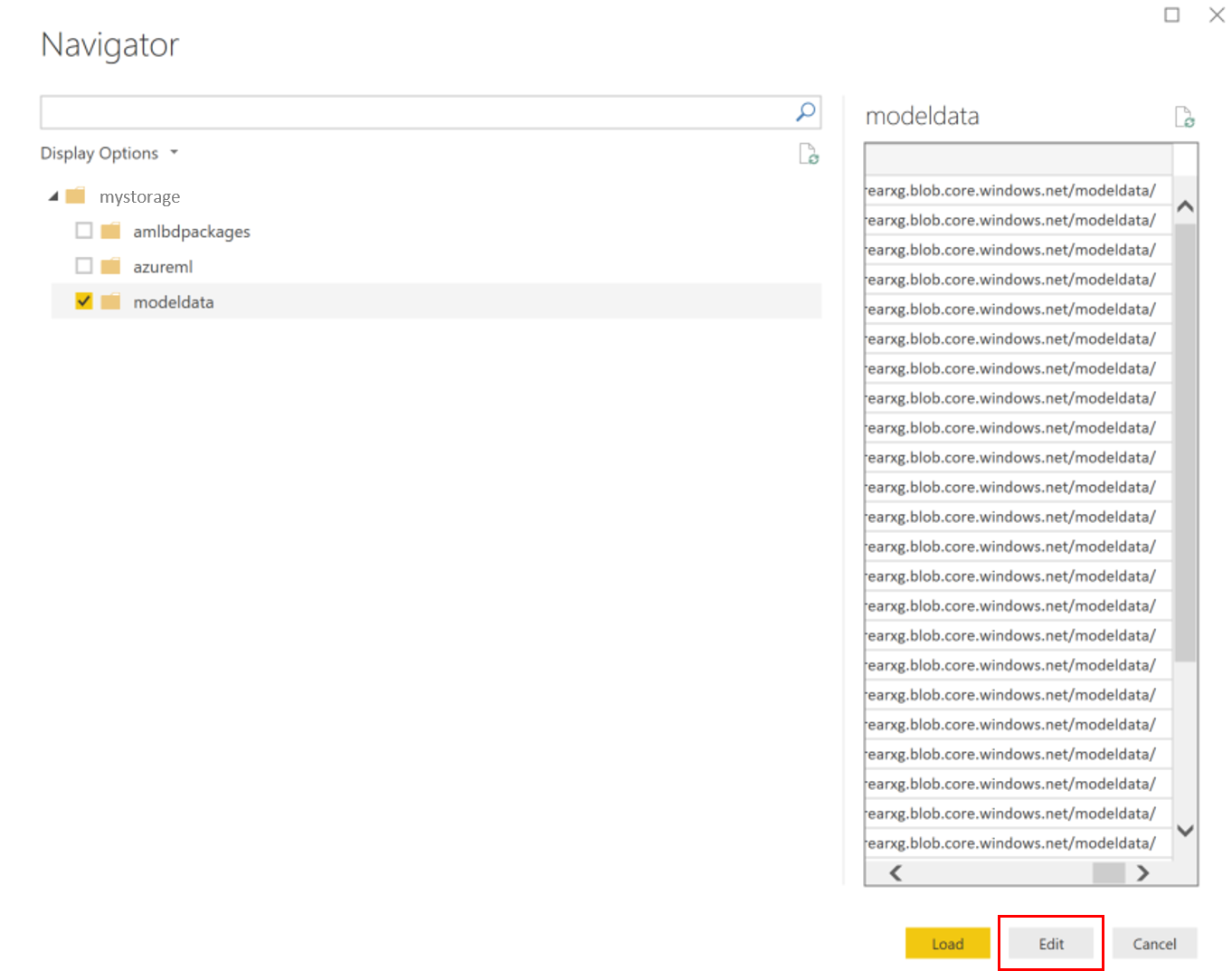
W edytorze zapytań kliknij w kolumnie Nazwa i dodaj konto magazynu.
Wprowadź ścieżkę modelu do filtru. Jeśli chcesz przeglądać tylko pliki z określonego roku lub miesiąca, po prostu rozwiń ścieżkę filtru. Aby na przykład przyjrzeć się tylko danym z marca, użyj tej ścieżki filtru:
/modeldata/<subscriptionid>/resourcegroupname</><workspacename/>webservicename<></modelname>/<modelversion>/<designation>/<year>/3
Przefiltruj dane, które są istotne dla Ciebie na podstawie wartości Nazwa . Jeśli przechowywane są przewidywania i dane wejściowe, należy utworzyć zapytanie dla każdego z nich.
Wybierz podwójne strzałki w dół obok nagłówka Kolumna zawartość , aby połączyć pliki.
Wybierz przycisk OK. Dane są ładowane wstępnie.
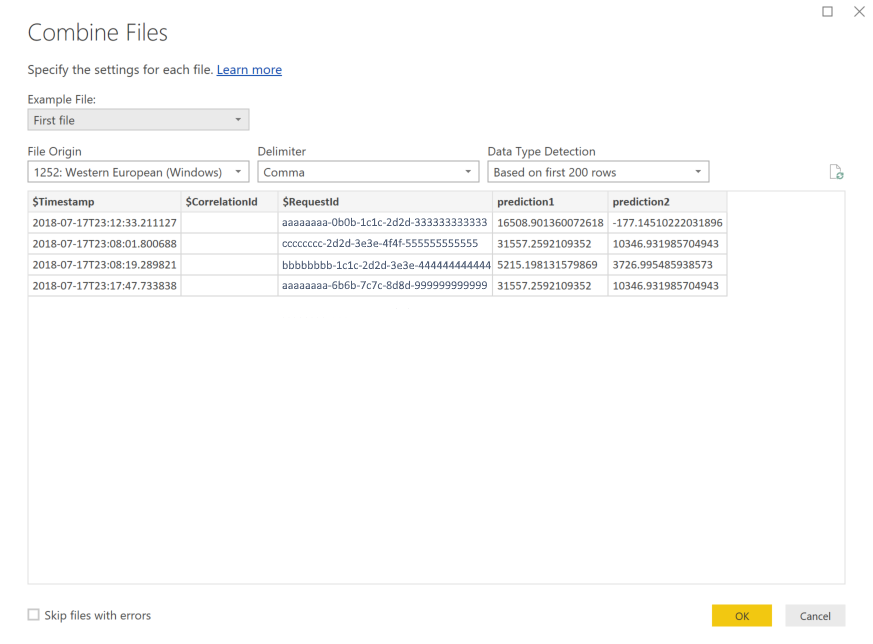
Wybierz Zamknij i zastosuj.
Jeśli dodano dane wejściowe i przewidywania, tabele są automatycznie uporządkowane według wartości RequestId .
Rozpocznij tworzenie niestandardowych raportów na danych modelu.




Analizowanie danych modelu przy użyciu usługi Azure Databricks
Przejdź do obszaru roboczego usługi Databricks.
W obszarze roboczym usługi Databricks wybierz pozycję Przekaż dane.

Wybierz pozycję Utwórz nową tabelę i wybierz pozycję Inne źródła>>Utwórz tabelę w notesie.

Zaktualizuj lokalizację danych. Oto przykład:
file_location = "wasbs://mycontainer@storageaccountname.blob.core.windows.net/*/*/data.csv" file_type = "csv"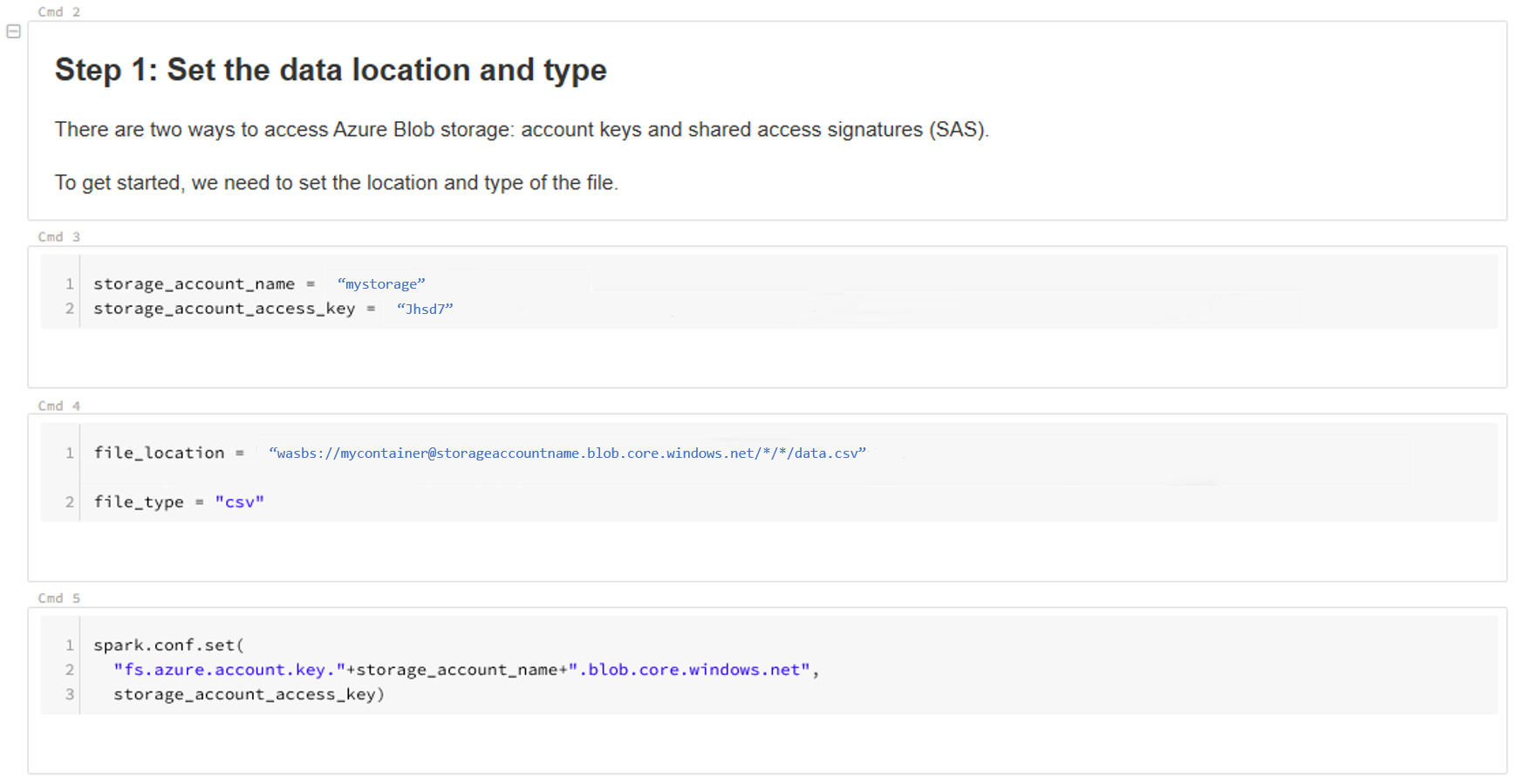
Wykonaj kroki opisane w szablonie, aby wyświetlić i przeanalizować dane.



Następne kroki
Wykryj dryf danych na zebranych danych.