Dzienniki i wyświetlanie metryk i plików dziennika w wersji 1
DOTYCZY: Zestaw SDK języka Python w wersji 1
Zestaw SDK języka Python w wersji 1
Rejestrowanie informacji w czasie rzeczywistym przy użyciu zarówno domyślnego pakietu rejestrowania języka Python, jak i funkcji specyficznych dla zestawu SDK języka Python usługi Azure Machine Learning. Możesz rejestrować lokalnie i wysyłać dzienniki do obszaru roboczego w portalu.
Dzienniki mogą ułatwić diagnozowanie błędów i ostrzeżeń lub śledzenie metryk wydajności, takich jak parametry i wydajność modelu. W tym artykule dowiesz się, jak włączyć rejestrowanie w następujących scenariuszach:
- Metryki uruchamiania dziennika
- Interaktywne sesje trenowania
- Przesyłanie zadań trenowania przy użyciu polecenia ScriptRunConfig
- Natywne ustawienia rejestrowania (
logging) języka Python - Rejestrowanie z dodatkowych źródeł
Napiwek
W tym artykule pokazano, jak monitorować proces trenowania modelu. Jeśli interesuje Cię monitorowanie użycia zasobów i zdarzeń z usługi Azure Machine Learning, takich jak limity przydziału, ukończone przebiegi trenowania lub ukończone wdrożenia modelu, zobacz Monitorowanie usługi Azure Machine Learning.
Typy danych
Można rejestrować wiele typów danych, w tym wartości skalarne, listy, tabele, obrazy, katalogi itd. Aby uzyskać więcej informacji oraz przykłady kodu w języku Python dla różnych typów danych, zobacz stronę referencyjną uruchamiania klasy.
Rejestrowanie metryk przebiegu
Użyj następujących metod w interfejsach API rejestrowania, aby wpłynąć na wizualizacje metryk. Zwróć uwagę na limity usługi dla tych zarejestrowanych metryk.
| Zarejestrowana wartość | Przykładowy kod | Formatowanie w portalu |
|---|---|---|
| Rejestrowanie tablicy wartości liczbowych | run.log_list(name='Fibonacci', value=[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89]) |
wykres liniowy z pojedynczą zmienną |
| Rejestrowanie pojedynczej wartości liczbowej o tej samej nazwie metryki wielokrotnie używanej (na przykład z wewnątrz pętli for) | for i in tqdm(range(-10, 10)): run.log(name='Sigmoid', value=1 / (1 + np.exp(-i))) angle = i / 2.0 |
Wykres liniowy z jedną zmienną |
| Rejestrowanie wiersza z 2 kolumnami liczbowymi wielokrotnie | run.log_row(name='Cosine Wave', angle=angle, cos=np.cos(angle)) sines['angle'].append(angle) sines['sine'].append(np.sin(angle)) |
Dwu zmienny wykres liniowy |
| Tabela dzienników z 2 kolumnami liczbowymi | run.log_table(name='Sine Wave', value=sines) |
Dwu zmienny wykres liniowy |
| Obraz dziennika | run.log_image(name='food', path='./breadpudding.jpg', plot=None, description='desert') |
Ta metoda służy do rejestrowania pliku obrazu lub wykresu matplotlib do uruchomienia. Te obrazy będą widoczne i porównywalne w rekordzie przebiegu |
Rejestrowanie za pomocą biblioteki MLflow
Zalecamy rejestrowanie modeli, metryk i artefaktów za pomocą biblioteki MLflow, ponieważ jest to rozwiązanie typu open source i obsługuje tryb lokalny do przenoszenia do chmury. W poniższej tabeli i przykładach kodu pokazano, jak używać biblioteki MLflow do rejestrowania metryk i artefaktów z przebiegów trenowania. Dowiedz się więcej na temat metod rejestrowania i wzorców projektowych platformy MLflow.
Pamiętaj, aby zainstalować mlflow pakiety i azureml-mlflow w obszarze roboczym.
pip install mlflow
pip install azureml-mlflow
Ustaw identyfikator URI śledzenia MLflow tak, aby wskazywał zaplecze usługi Azure Machine Learning, aby upewnić się, że metryki i artefakty są rejestrowane w obszarze roboczym.
from azureml.core import Workspace
import mlflow
from mlflow.tracking import MlflowClient
ws = Workspace.from_config()
mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
mlflow.create_experiment("mlflow-experiment")
mlflow.set_experiment("mlflow-experiment")
mlflow_run = mlflow.start_run()
| Zarejestrowana wartość | Przykładowy kod | Uwagi |
|---|---|---|
| Rejestrowanie wartości liczbowej (int lub float) | mlflow.log_metric('my_metric', 1) |
|
| Rejestrowanie wartości logicznej | mlflow.log_metric('my_metric', 0) |
0 = Prawda, 1 = Fałsz |
| Rejestrowanie ciągu | mlflow.log_text('foo', 'my_string') |
Zarejestrowane jako artefakt |
| Rejestrowanie metryk numpy lub obiektów obrazów PIL | mlflow.log_image(img, 'figure.png') |
|
| Wykres matlotlib dziennika lub plik obrazu | mlflow.log_figure(fig, "figure.png") |
Wyświetlanie metryk uruchamiania za pomocą zestawu SDK
Metryki wytrenowanego modelu można wyświetlić przy użyciu polecenia run.get_metrics().
from azureml.core import Run
run = Run.get_context()
run.log('metric-name', metric_value)
metrics = run.get_metrics()
# metrics is of type Dict[str, List[float]] mapping metric names
# to a list of the values for that metric in the given run.
metrics.get('metric-name')
# list of metrics in the order they were recorded
Dostęp do informacji o przebiegu można również uzyskać za pomocą biblioteki MLflow za pośrednictwem właściwości danych i informacji obiektu przebiegu. Aby uzyskać więcej informacji, zobacz dokumentację obiektu MLflow.entities.Run.
Po zakończeniu przebiegu można go pobrać przy użyciu klasy MlFlowClient().
from mlflow.tracking import MlflowClient
# Use MlFlow to retrieve the run that was just completed
client = MlflowClient()
finished_mlflow_run = MlflowClient().get_run(mlflow_run.info.run_id)
Metryki, parametry i tagi przebiegu można wyświetlić w polu danych obiektu przebiegu.
metrics = finished_mlflow_run.data.metrics
tags = finished_mlflow_run.data.tags
params = finished_mlflow_run.data.params
Uwaga
Słownik metryk w obszarze mlflow.entities.Run.data.metrics zwraca tylko ostatnio zarejestrowaną wartość dla danej nazwy metryki. Jeśli na przykład logujesz się, w kolejności 1, 2, a następnie 3, a następnie 4 do metryki o nazwie sample_metric, tylko 4 znajduje się w słowniku metryk dla sample_metric.
Aby pobrać wszystkie metryki zarejestrowane dla określonej nazwy metryki, możesz użyć polecenia MlFlowClient.get_metric_history().
Wyświetlanie metryk uruchamiania w interfejsie użytkownika programu Studio
Ukończone rekordy uruchamiania, w tym zarejestrowane metryki, można przeglądać w usłudze Azure Machine Learning Studio.
Przejdź do karty Eksperymenty . Aby wyświetlić wszystkie przebiegi w obszarze roboczym w ramach eksperymentów, wybierz kartę Wszystkie uruchomienia . Możesz przejść do szczegółów przebiegów dla określonych eksperymentów, stosując filtr Eksperymenty na górnym pasku menu.
Dla pojedynczego widoku Eksperyment wybierz kartę Wszystkie eksperymenty . Na pulpicie nawigacyjnym przebiegu eksperymentu można zobaczyć śledzone metryki i dzienniki dla każdego przebiegu.
Możesz również edytować tabelę listy uruchomień, aby wybrać wiele przebiegów i wyświetlić ostatnią, minimalną lub maksymalną zarejestrowaną wartość dla przebiegów. Dostosuj wykresy, aby porównać zarejestrowane wartości metryk i agregacje w wielu przebiegach. Możesz wykreślić wiele metryk na osi y wykresu i dostosować oś x, aby wykreślić zarejestrowane metryki.
Wyświetlanie i pobieranie plików dziennika dla przebiegu
Pliki dziennika to podstawowy zasób do debugowania obciążeń usługi Azure Machine Learning. Po przesłaniu zadania szkoleniowego przejdź do określonego przebiegu, aby wyświetlić jego dzienniki i dane wyjściowe:
- Przejdź do karty Eksperymenty .
- Wybierz identyfikator runID dla określonego przebiegu.
- Wybierz pozycję Dane wyjściowe i dzienniki w górnej części strony.
- Wybierz pozycję Pobierz wszystko , aby pobrać wszystkie dzienniki do folderu zip.
- Możesz również pobrać poszczególne pliki dziennika, wybierając plik dziennika i wybierając pozycję Pobierz
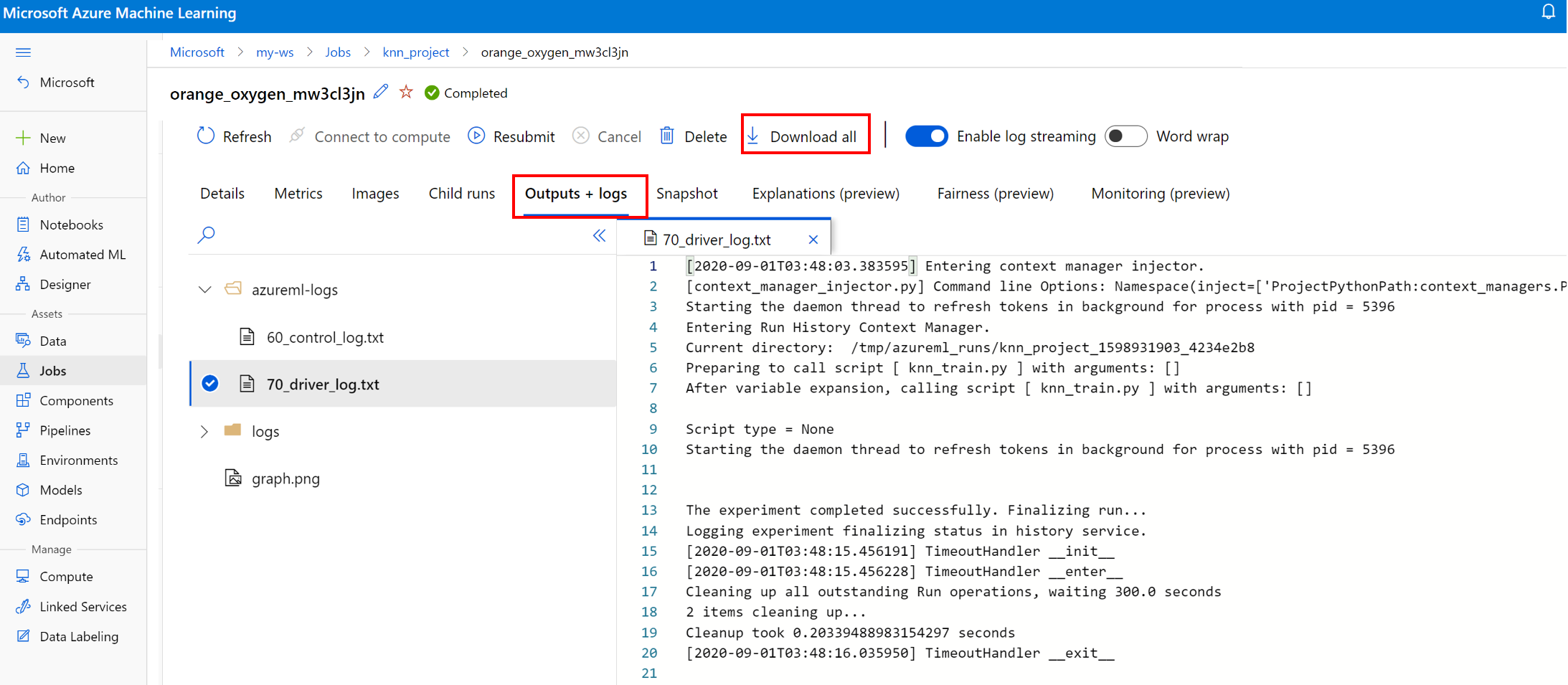
folder user_logs
Ten folder zawiera informacje o dziennikach wygenerowanych przez użytkownika. Ten folder jest domyślnie otwarty, a std_log.txt dziennik jest zaznaczony. Std_log.txt to miejsce, w którym są wyświetlane dzienniki kodu (na przykład instrukcje drukowania). Ten plik zawiera stdout dzienniki i stderr dzienniki ze skryptu sterującego i skryptu trenowania— jeden na proces. W większości przypadków będziesz monitorować dzienniki tutaj.
folder system_logs
Ten folder zawiera dzienniki generowane przez usługę Azure Machine Learning i zostaną domyślnie zamknięte. Dzienniki generowane przez system są pogrupowane w różne foldery na podstawie etapu zadania w środowisku uruchomieniowym.
Inne foldery
W przypadku zadań szkoleniowych w klastrach z wieloma obliczeniami dzienniki są obecne dla każdego adresu IP węzła. Struktura dla każdego węzła jest taka sama jak zadania pojedynczego węzła. Istnieje jeszcze jeden folder dzienników dla ogólnych dzienników wykonywania, stderr i stdout dzienników.
Usługa Azure Machine Learning rejestruje informacje z różnych źródeł podczas trenowania, takie jak Rozwiązanie AutoML lub kontener platformy Docker, który uruchamia zadanie trenowania. Wiele z tych dzienników nie jest udokumentowanych. Jeśli napotkasz problemy i skontaktujesz się z pomocą techniczną firmy Microsoft, mogą one być w stanie używać tych dzienników podczas rozwiązywania problemów.
Interaktywna sesja rejestrowania
Interaktywne sesje rejestrowania są zwykle używane w środowiskach notesów. Metoda Experiment.start_logging() uruchamia interaktywną sesję rejestrowania. Wszystkie metryki zarejestrowane w trakcie sesji są dodawane do rekordu przebiegu w eksperymencie. Metoda run.complete() kończy sesje i oznacza przebieg jako zakończony.
Dzienniki ScriptRun
W tej sekcji dowiesz się, jak dodać kod rejestrowania w ramach przebiegów utworzonych podczas konfigurowania za pomocą klasy ScriptRunConfig. Do hermetyzowania skryptów i środowisk na potrzeby powtarzalnych przebiegów można użyć klasy ScriptRunConfig. Możesz również użyć tej opcji, aby wyświetlić widżet notesów Jupyter Notebook na potrzeby monitorowania.
Ten przykład wykonuje czyszczenie parametrów nad wartościami alfa i przechwytuje wyniki przy użyciu metody run.log().
Utwórz skrypt trenowania zawierający logikę rejestrowania, skrypt
train.py.# Copyright (c) Microsoft. All rights reserved. # Licensed under the MIT license. from sklearn.datasets import load_diabetes from sklearn.linear_model import Ridge from sklearn.metrics import mean_squared_error from sklearn.model_selection import train_test_split from azureml.core.run import Run import os import numpy as np import mylib # sklearn.externals.joblib is removed in 0.23 try: from sklearn.externals import joblib except ImportError: import joblib os.makedirs('./outputs', exist_ok=True) X, y = load_diabetes(return_X_y=True) run = Run.get_context() X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0) data = {"train": {"X": X_train, "y": y_train}, "test": {"X": X_test, "y": y_test}} # list of numbers from 0.0 to 1.0 with a 0.05 interval alphas = mylib.get_alphas() for alpha in alphas: # Use Ridge algorithm to create a regression model reg = Ridge(alpha=alpha) reg.fit(data["train"]["X"], data["train"]["y"]) preds = reg.predict(data["test"]["X"]) mse = mean_squared_error(preds, data["test"]["y"]) run.log('alpha', alpha) run.log('mse', mse) model_file_name = 'ridge_{0:.2f}.pkl'.format(alpha) # save model in the outputs folder so it automatically get uploaded with open(model_file_name, "wb") as file: joblib.dump(value=reg, filename=os.path.join('./outputs/', model_file_name)) print('alpha is {0:.2f}, and mse is {1:0.2f}'.format(alpha, mse))Prześlij skrypt
train.pyw celu uruchomienia go w środowisku zarządzanym przez użytkownika. Na potrzeby trenowania jest przesyłany cały folder skryptu.from azureml.core import ScriptRunConfig src = ScriptRunConfig(source_directory='./scripts', script='train.py', environment=user_managed_env)run = exp.submit(src)Parametr
show_outputwłącza pełne rejestrowanie, które umożliwia wyświetlenie szczegółowych informacji z procesu trenowania, a także informacji o wszelkich zasobach zdalnych lub docelowych obiektach obliczeniowych. Użyj poniższego kodu, aby włączyć pełne rejestrowanie podczas przesyłania eksperymentu.run = exp.submit(src, show_output=True)Można również użyć tego samego parametru w funkcji
wait_for_completionw wynikowym przebiegu.run.wait_for_completion(show_output=True)
Natywne rejestrowanie w języku Python
Niektóre dzienniki w zestawie SDK mogą zawierać błąd, który powoduje ustawienie poziomu rejestrowania na DEBUGOWANIE. Aby ustawić poziom rejestrowania, dodaj następujący kod do skryptu.
import logging
logging.basicConfig(level=logging.DEBUG)
Inne źródła rejestrowania
Usługa Azure Machine Learning może również rejestrować informacje z innych źródeł podczas trenowania, takich jak przebiegi zautomatyzowanego uczenia maszynowego lub kontenery platformy Docker, które uruchamiają zadania. Te dzienniki nie są udokumentowane, ale jeśli wystąpią problemy i skontaktujesz się z pomocą techniczną firmy Microsoft, być może będą oni mogli wykorzystać te dzienniki podczas rozwiązywania problemów.
Informacje dotyczące rejestrowania metryk w projektancie usługi Azure Machine Learning znajdują się w temacie Sposób rejestrowania metryk w projektancie
Przykładowe notesy
W poniższych notesach przedstawiono pojęcia opisane w tym artykule:
- how-to-use-azureml/training/train-on-local
- how-to-use-azureml/track-and-monitor-experiments/logging-api
Instrukcję uruchamiania notesów znajdziesz w artykule Use Jupyter notebooks to explore this service (Eksplorowanie tej usługi za pomocą notesów Jupyter).
Następne kroki
Zobacz następujące artykuły, aby dowiedzieć się więcej na temat korzystania z usługi Azure Machine Learning:
- Zobacz w samouczku Trenowanie modelu klasyfikacji obrazów za pomocą usługi Azure Machine Learning przykład sposobu rejestrowania najlepszego modelu i wdrożenia go.