Nuta
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Potoki usługi Azure Machine Learning obsługują dane wejściowe i wyjściowe zarówno na poziomie składnika, jak i potoku. W tym artykule opisano potok i składniki wejściowe i wyjściowe oraz sposób zarządzania nimi.
Na poziomie składnika dane wejściowe i wyjściowe definiują interfejs składnika. Dane wyjściowe z jednego składnika można użyć jako danych wejściowych dla innego składnika w tym samym potoku nadrzędnym, co umożliwia przekazywanie danych lub modeli między składnikami. Ta wzajemne połączenie reprezentuje przepływ danych w potoku.
Na poziomie potoku można użyć danych wejściowych i wyjściowych do przesyłania zadań potoku z różnych danych wejściowych lub parametrów, takich jak learning_rate. Dane wejściowe i wyjściowe są szczególnie przydatne podczas wywoływania potoku za pośrednictwem punktu końcowego REST. Możesz przypisać różne wartości do danych wejściowych potoku lub uzyskać dostęp do danych wyjściowych różnych zadań potoku. Aby uzyskać więcej informacji, zobacz Tworzenie zadań i danych wejściowych dla punktów końcowych wsadowych.
Typy danych wejściowych i wyjściowych
Następujące typy są obsługiwane zarówno jako dane wejściowe, jak i wyjściowe składników lub potoków:
Typy danych. Aby uzyskać więcej informacji, zobacz Typy danych.
uri_fileuri_foldermltable
Typy modeli.
mlflow_modelcustom_model
Następujące typy pierwotne są również obsługiwane tylko dla danych wejściowych:
- Typy pierwotne
stringnumberintegerboolean
Dane wyjściowe typu pierwotnego nie są obsługiwane.
Przykładowe dane wejściowe i wyjściowe
Te przykłady pochodzą z potoku regresji danych taksówek w Nowym Jorku w repozytorium GitHub przykładów Azure Machine Learning:
- Składnik train ma
numberdane wejściowe o nazwietest_split_ratio. - Składnik przygotowywania ma
uri_folderdane wyjściowe typu. Kod źródłowy składnika odczytuje pliki CSV z folderu wejściowego, przetwarza pliki i zapisuje przetworzone pliki CSV w folderze wyjściowym. - Składnik pociągu
mlflow_modelma dane wyjściowe typu. Kod źródłowy składnika zapisuje wytrenowany model przy użyciumlflow.sklearn.save_modelmetody .
Serializacja wyjściowa
Użycie danych lub danych wyjściowych modelu serializuje dane wyjściowe i zapisuje je jako pliki w lokalizacji przechowywania. Późniejsze kroki mogą uzyskiwać dostęp do plików podczas wykonywania zadania przez zainstalowanie tej lokalizacji magazynu lub pobranie lub przekazanie plików do obliczeniowego systemu plików.
Kod źródłowy składnika musi serializować obiekt wyjściowy, który jest zwykle przechowywany w pamięci, do plików. Można na przykład serializować ramkę danych biblioteki pandas w pliku CSV. Usługa Azure Machine Learning nie definiuje żadnych standardowych metod serializacji obiektów. Masz elastyczność wyboru preferowanych metod serializacji obiektów w plikach. W składniku podrzędnym można wybrać sposób deserializacji i odczytywania tych plików.
Ścieżki wejściowe i wyjściowe typu danych
W przypadku danych wejściowych i wyjściowych zasobu danych należy określić parametr ścieżki wskazujący lokalizację danych. W poniższej tabeli przedstawiono obsługiwane lokalizacje danych dla danych wejściowych i wyjściowych potoku usługi Azure Machine Learning z path przykładami parametrów:
| Lokalizacja | Dane wejściowe | Dane wyjściowe | Przykład |
|---|---|---|---|
| Ścieżka na komputerze lokalnym | ✓ | ./home/<username>/data/my_data |
|
| Ścieżka na publicznym serwerze http/s | ✓ | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
|
| Ścieżka w usłudze Azure Storage | * | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>lub abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
|
| Ścieżka w magazynie danych usługi Azure Machine Learning | ✓ | ✓ | azureml://datastores/<data_store_name>/paths/<path> |
| Ścieżka do zasobu danych | ✓ | ✓ | azureml:my_data:<version> |
Wskazówka
Bezpośrednie używanie usługi Azure Storage nie jest zalecane w przypadku danych wejściowych, ponieważ może wymagać dodatkowej konfiguracji tożsamości w celu odczytania danych. Lepiej jest używać ścieżek magazynu danych usługi Azure Machine Learning, które są obsługiwane w różnych typach zadań potoku.
Tryby wejściowe i wyjściowe typu danych
W przypadku danych wejściowych i wyjściowych typu danych można wybrać spośród kilku trybów pobierania, przekazywania i instalacji, aby zdefiniować sposób uzyskiwania dostępu do danych przez obiekt docelowy obliczeń. W poniższej tabeli przedstawiono obsługiwane tryby dla różnych typów danych wejściowych i wyjściowych.
| Typ | upload |
download |
ro_mount |
rw_mount |
direct |
eval_download |
eval_mount |
|---|---|---|---|---|---|---|---|
uri_folder wkład |
✓ | ✓ | ✓ | ||||
uri_file wkład |
✓ | ✓ | ✓ | ||||
mltable wkład |
✓ | ✓ | ✓ | ✓ | ✓ | ||
uri_folder wyjście |
✓ | ✓ | |||||
uri_file wyjście |
✓ | ✓ | |||||
mltable wyjście |
✓ | ✓ | ✓ |
W większości przypadków zalecamy tryb ro_mount lub tryb rw_mount. Aby uzyskać więcej informacji, zobacz Tryby.
Dane wejściowe i wyjściowe w grafach potoku
Na stronie zadania potoku w usłudze Azure Machine Learning Studio dane wejściowe i wyjściowe składników są wyświetlane jako małe okręgi nazywane portami wejściowymi/wyjściowymi. Te porty reprezentują przepływ danych w potoku. Dane wyjściowe na poziomie potoku są wyświetlane w purpurowych polach w celu łatwej identyfikacji.
Poniższy zrzut ekranu z wykresu potoku regresji danych taksówek w Nowym Jorku przedstawia wiele składników i danych wejściowych i wyjściowych potoku.

Po umieszczeniu wskaźnika myszy na porcie wejściowym/wyjściowym zostanie wyświetlony typ.
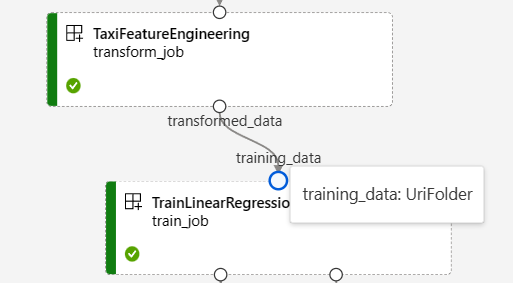
Wykres potoku nie wyświetla danych wejściowych typu pierwotnego. Te dane wejściowe są wyświetlane na karcie Ustawienia panelu Przegląd zadania potoku dla danych wejściowych na poziomie potoku lub panelu składników dla danych wejściowych na poziomie składnika. Aby otworzyć panel składników, kliknij dwukrotnie składnik na grafie.

Podczas edytowania potoku w projektancie studio dane wejściowe i wyjściowe potoku znajdują się w panelu interfejsu potoku, a dane wejściowe i wyjściowe składników znajdują się w panelu składników.
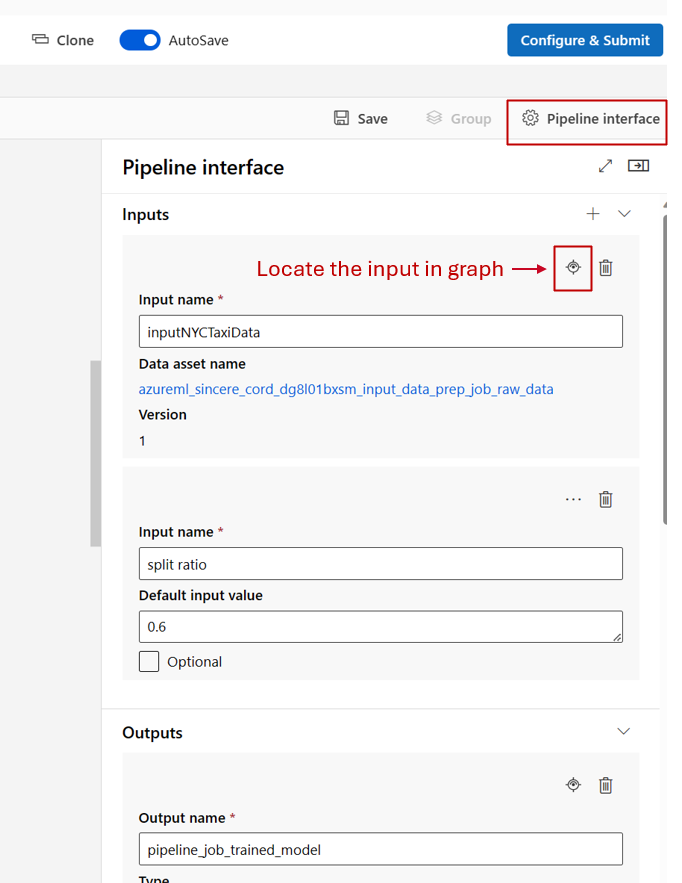
Podwyższanie poziomu danych wejściowych/wyjściowych składników do poziomu potoku
Podwyższenie poziomu danych wejściowych/wyjściowych składnika do poziomu potoku umożliwia zastąpienie danych wejściowych/wyjściowych składnika podczas przesyłania zadania potoku. Ta możliwość jest szczególnie przydatna w przypadku wyzwalania potoków przy użyciu punktów końcowych REST.
W poniższych przykładach pokazano, jak podwyższyć poziom danych wejściowych/wyjściowych na poziomie składnika do danych wejściowych/wyjściowych na poziomie potoku.
- Interfejs wiersza polecenia platformy Azure
- Zestaw SDK dla języka Python
- Interfejs użytkownika programu Studio
Poniższy potok promuje trzy dane wejściowe i trzy dane wyjściowe na poziomie potoku. Na przykład to dane wejściowe na poziomie potoku, pipeline_job_training_max_epocs ponieważ są deklarowane w inputs sekcji na poziomie głównym.
train_job W jobs sekcji dane wejściowe o nazwie max_epocs odwołują się do ${{parent.inputs.pipeline_job_training_max_epocs}}elementu , co oznacza, że train_jobmax_epocs dane wejściowe odwołują się do danych wejściowych na poziomie pipeline_job_training_max_epocs potoku. Dane wyjściowe potoku są promowane przy użyciu tego samego schematu.
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: 1b_e2e_registered_components
description: E2E dummy train-score-eval pipeline with registered components
inputs:
pipeline_job_training_max_epocs: 20
pipeline_job_training_learning_rate: 1.8
pipeline_job_learning_rate_schedule: 'time-based'
outputs:
pipeline_job_trained_model:
mode: upload
pipeline_job_scored_data:
mode: upload
pipeline_job_evaluation_report:
mode: upload
settings:
default_compute: azureml:cpu-cluster
jobs:
train_job:
type: command
component: azureml:my_train@latest
inputs:
training_data:
type: uri_folder
path: ./data
max_epocs: ${{parent.inputs.pipeline_job_training_max_epocs}}
learning_rate: ${{parent.inputs.pipeline_job_training_learning_rate}}
learning_rate_schedule: ${{parent.inputs.pipeline_job_learning_rate_schedule}}
outputs:
model_output: ${{parent.outputs.pipeline_job_trained_model}}
services:
my_vscode:
type: vs_code
my_jupyter_lab:
type: jupyter_lab
my_tensorboard:
type: tensor_board
log_dir: "outputs/tblogs"
# my_ssh:
# type: tensor_board
# ssh_public_keys: <paste the entire pub key content>
# nodes: all # Use the `nodes` property to pick which node you want to enable interactive services on. If `nodes` are not selected, by default, interactive applications are only enabled on the head node.
score_job:
type: command
component: azureml:my_score@latest
inputs:
model_input: ${{parent.jobs.train_job.outputs.model_output}}
test_data:
type: uri_folder
path: ./data
outputs:
score_output: ${{parent.outputs.pipeline_job_scored_data}}
evaluate_job:
type: command
component: azureml:my_eval@latest
inputs:
scoring_result: ${{parent.jobs.score_job.outputs.score_output}}
outputs:
eval_output: ${{parent.outputs.pipeline_job_evaluation_report}}
Pełny przykład można znaleźć w artykule Train-score-eval pipeline with registered components (Potok train-score-eval z zarejestrowanymi składnikami) w repozytorium przykładów usługi Azure Machine Learning.
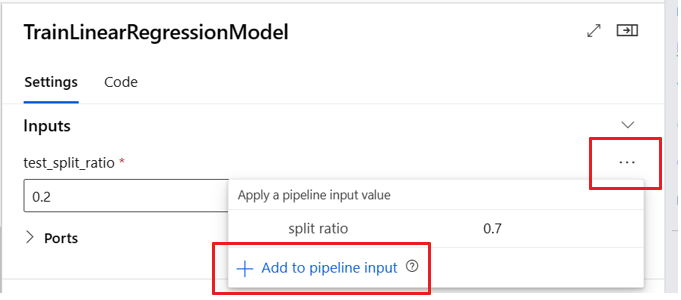
Definiowanie opcjonalnych danych wejściowych
Domyślnie wszystkie dane wejściowe są wymagane i muszą mieć wartość domyślną lub mieć przypisaną wartość przy każdym przesłaniu zadania potoku. Można jednak zdefiniować opcjonalne dane wejściowe.
Uwaga
Opcjonalne dane wyjściowe nie są obsługiwane.
Ustawienie opcjonalnych danych wejściowych może być przydatne w dwóch scenariuszach:
Jeśli zdefiniujesz opcjonalne dane wejściowe/typ modelu i nie przypiszesz do niego wartości podczas przesyłania zadania potoku, składnik potoku nie ma tej zależności danych. Jeśli port wejściowy składnika nie jest połączony z żadnym składnikiem lub węzłem danych/modelu, potok wywołuje składnik bezpośrednio zamiast czekać na poprzednią zależność.
Jeśli dla potoku zostanie ustawiona
continue_on_step_failure = Truewartość , alenode2używa wymaganych danych wejściowych znode1elementu ,node2polecenie nie zostanie wykonane, jeślinode1nie powiedzie się. Jeślinode1dane wejściowe są opcjonalne,node2jest wykonywane nawet w przypadkunode1niepowodzenia. Na poniższym wykresie przedstawiono ten scenariusz.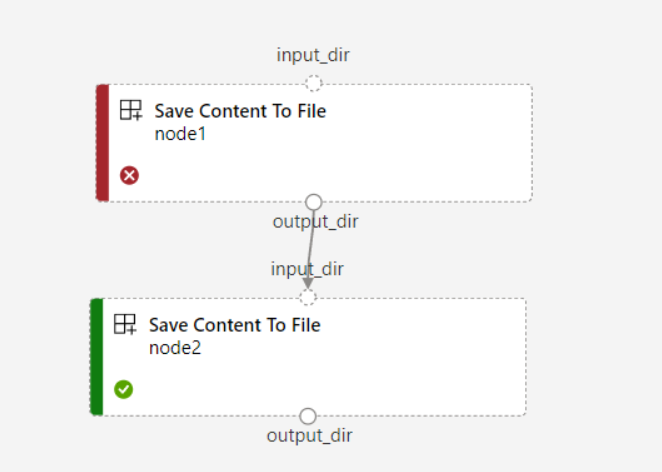
Poniższy przykład kodu przedstawia sposób definiowania opcjonalnych danych wejściowych. Gdy dane wejściowe są ustawione jako optional = true, należy użyć $[[]] polecenia , aby objąć dane wejściowe wiersza polecenia, jak w wyróżnionych wierszach przykładu.
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
name: train_data_component_cli
display_name: train_data
description: A example train component
tags:
author: azureml-sdk-team
type: command
inputs:
training_data:
type: uri_folder
max_epocs:
type: integer
optional: true
learning_rate:
type: number
default: 0.01
optional: true
learning_rate_schedule:
type: string
default: time-based
optional: true
outputs:
model_output:
type: uri_folder
code: ./train_src
environment: azureml://registries/azureml/environments/sklearn-1.5/labels/latest
command: >-
python train.py
--training_data ${{inputs.training_data}}
$[[--max_epocs ${{inputs.max_epocs}}]]
$[[--learning_rate ${{inputs.learning_rate}}]]
$[[--learning_rate_schedule ${{inputs.learning_rate_schedule}}]]
--model_output ${{outputs.model_output}}

Dostosowywanie ścieżek wyjściowych
Domyślnie dane wyjściowe składnika są przechowywane w {default_datastore} ustawieniu dla potoku . azureml://datastores/${{default_datastore}}/paths/${{name}}/${{output_name}} Jeśli nie zostanie ustawiona, wartość domyślna to magazyn obiektów blob obszaru roboczego.
Zadanie {name} jest rozpoznawane w czasie wykonywania zadania i {output_name} jest nazwą zdefiniowaną w składniku YAML. Możesz dostosować miejsce przechowywania danych wyjściowych, definiując ścieżkę wyjściową.
- Interfejs wiersza polecenia platformy Azure
- Zestaw SDK dla języka Python
- Interfejs użytkownika programu Studio
Plik pipeline.yml w potoku train-score-eval z zarejestrowanymi składnikami definiuje potok, który ma trzy dane wyjściowe na poziomie potoku. Użyj następującego polecenia, aby ustawić niestandardowe ścieżki wyjściowe dla wyjścia pipeline_job_trained_model.
# define the custom output path using datastore uri
# add relative path to your blob container after "azureml://datastores/<datastore_name>/paths"
output_path="azureml://datastores/{datastore_name}/paths/{relative_path_of_container}"
# create job and define path using --outputs.<outputname>
az ml job create -f ./pipeline.yml --set outputs.pipeline_job_trained_model.path=$output_path

Pobieranie danych wyjściowych
Dane wyjściowe można pobrać na poziomie potoku lub składnika.
Pobieranie danych wyjściowych na poziomie potoku
- Interfejs wiersza polecenia platformy Azure
- Zestaw SDK dla języka Python
- Interfejs użytkownika programu Studio
Możesz pobrać wszystkie dane wyjściowe zadania lub pobrać określone dane wyjściowe.
# Download all the outputs of the job
az ml job download --all -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>
# Download a specific output
az ml job download --output-name <OUTPUT_PORT_NAME> -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>

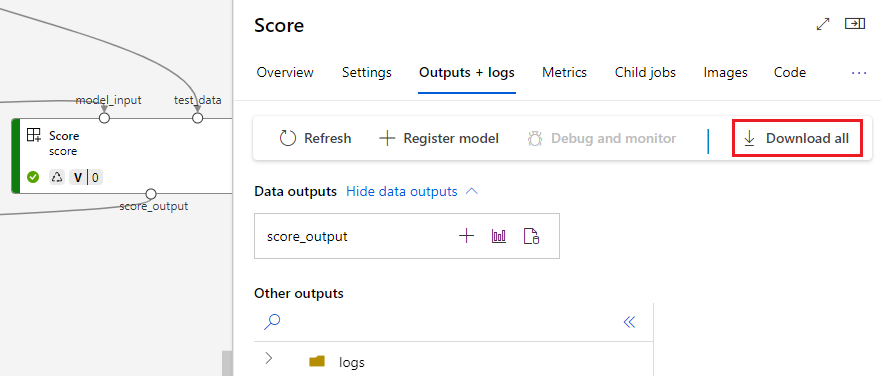
Pobieranie danych wyjściowych składnika
- Interfejs wiersza polecenia platformy Azure
- Zestaw SDK dla języka Python
- Interfejs użytkownika programu Studio
Aby pobrać dane wyjściowe składnika podrzędnego, najpierw wyświetl listę wszystkich zadań podrzędnych zadania zadania potoku, a następnie użyj podobnego kodu, aby pobrać dane wyjściowe.
# List all child jobs in the job and print job details in table format
az ml job list --parent-job-name <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID> -o table
# Select the desired child job name to download output
az ml job download --all -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>
Rejestrowanie danych wyjściowych jako nazwanego zasobu
Dane wyjściowe składnika lub potoku można zarejestrować jako nazwany zasób, przypisując name element i version do danych wyjściowych. Zarejestrowany zasób można wymienić w obszarze roboczym za pośrednictwem interfejsu użytkownika programu Studio, interfejsu wiersza polecenia lub zestawu SDK i można się do niego odwoływać w przyszłych zadaniach obszaru roboczego.
Rejestrowanie danych wyjściowych na poziomie potoku
- Interfejs wiersza polecenia platformy Azure
- Zestaw SDK dla języka Python
- Interfejs użytkownika programu Studio
display_name: register_pipeline_output
type: pipeline
jobs:
node:
type: command
inputs:
component_in_path:
type: uri_file
path: https://dprepdata.blob.core.windows.net/demo/Titanic.csv
component: ../components/helloworld_component.yml
outputs:
component_out_path: ${{parent.outputs.component_out_path}}
outputs:
component_out_path:
type: mltable
name: pipeline_output # Define name and version to register pipeline output
version: '1'
settings:
default_compute: azureml:cpu-cluster