Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
DOTYCZY: Azure CLI rozszerzenie ml v2 (current)Python SDK azure-ai-ml v2 (current)
Azure CLI rozszerzenie ml v2 (current)Python SDK azure-ai-ml v2 (current)
Z tego artykułu dowiesz się:
- Jak odczytywać dane z usługi Azure Storage w zadaniu usługi Azure Machine Learning.
- Jak zapisywać dane z zadania usługi Azure Machine Learning w usłudze Azure Storage.
- Różnica między trybami instalacji i pobierania .
- Jak używać tożsamości użytkownika i tożsamości zarządzanej do uzyskiwania dostępu do danych.
- Ustawienia montażu dostępne w zadaniu.
- Optymalne ustawienia instalacji dla typowych scenariuszy.
- Jak uzyskać dostęp do zasobów danych V1.
Wymagania wstępne
Subskrypcja platformy Azure. Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto. Wypróbuj bezpłatną lub płatną wersję usługi Azure Machine Learning.
Zestaw SDK usługi Azure Machine Learning dla języka Python w wersji 2.
Pakiet azure-identity języka Python (
pip install azure-identity).Interfejs wiersza polecenia platformy Azure z rozszerzeniem ml v2 (
az extension add -n ml).Obszar roboczy usługi Azure Machine Learning.
Docelowy obiekt obliczeniowy usługi Azure Machine Learning (na przykład klaster obliczeniowy o nazwie
cpu-cluster).
Szybki start
Przed zapoznaniem się ze szczegółowymi opcjami dostępnymi podczas uzyskiwania dostępu do danych najpierw opiszemy odpowiednie fragmenty kodu na potrzeby dostępu do danych.
Odczytywanie danych z usługi Azure Storage w zadaniu usługi Azure Machine Learning
W tym przykładzie przesyłasz zadanie usługi Azure Machine Learning, które uzyskuje dostęp do danych z publicznego konta magazynu obiektów blob. Można jednak dostosować fragment kodu, aby uzyskać dostęp do własnych danych na prywatnym koncie usługi Azure Storage. Zaktualizuj ścieżkę zgodnie z opisem w tym miejscu. Usługa Azure Machine Learning bezproblemowo obsługuje uwierzytelnianie w magazynie w chmurze, wykorzystując funkcję Microsoft Entra passthrough. Po przesłaniu zadania możesz wybrać następujące opcje:
- Tożsamość użytkownika: wykorzystaj swoją tożsamość Microsoft Entra, aby uzyskać dostęp do danych
- Tożsamość zarządzana: użyj tożsamości zarządzanej obiektu docelowego obliczeniowego, aby uzyskać dostęp do danych
- Brak: nie określaj tożsamości w celu uzyskania dostępu do danych. Użyj 'None' podczas korzystania z magazynów danych opartych na poświadczeniach (klucz/token SAS) lub podczas uzyskiwania dostępu do danych publicznych.
Wskazówka
Jeśli używasz kluczy lub tokenów SAS do uwierzytelniania, zalecamy utworzenie magazynu danych usługi Azure Machine Learning. Środowisko uruchomieniowe automatycznie łączy się z pamięcią masową bez uwidaczniania poświadczeń.
from azure.ai.ml import command, Input, MLClient
from azure.ai.ml.entities import Data, UserIdentityConfiguration, ManagedIdentityConfiguration
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.identity import DefaultAzureCredential
# Set your subscription, resource group and workspace name:
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# connect to the AzureML workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# ==============================================================
# Set the URI path for the data.
# Supported `path` formats for input include:
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# Supported `path` format for output is:
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# We set the input path to a file on a public blob container
# ==============================================================
path = "wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv"
# ==============================================================
# What type of data does the path point to? Options include:
# data_type = AssetTypes.URI_FILE # a specific file
# data_type = AssetTypes.URI_FOLDER # a folder
# data_type = AssetTypes.MLTABLE # an mltable
# The path we set above is a specific file
# ==============================================================
data_type = AssetTypes.URI_FILE
# ==============================================================
# Set the mode. The popular modes include:
# mode = InputOutputModes.RO_MOUNT # Read-only mount on the compute target
# mode = InputOutputModes.DOWNLOAD # Download the data to the compute target
# ==============================================================
mode = InputOutputModes.RO_MOUNT
# ==============================================================
# You can set the identity you want to use in a job to access the data. Options include:
# identity = UserIdentityConfiguration() # Use the user's identity
# identity = ManagedIdentityConfiguration() # Use the compute target managed identity
# ==============================================================
# This example accesses public data, so we don't need an identity.
# You also set identity to None if you use a credential-based datastore
identity = None
# Set the input for the job:
inputs = {
"input_data": Input(type=data_type, path=path, mode=mode)
}
# This command job uses the head Linux command to print the first 10 lines of the file
job = command(
command="head ${{inputs.input_data}}",
inputs=inputs,
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4",
compute="cpu-cluster",
identity=identity,
)
# Submit the command
ml_client.jobs.create_or_update(job)
Zapisywanie danych z zadania usługi Azure Machine Learning w usłudze Azure Storage
W tym przykładzie przesyłasz zadanie usługi Azure Machine Learning, które zapisuje dane w domyślnym magazynie danych usługi Azure Machine Learning. Możesz opcjonalnie ustawić wartość name zasobu danych, aby utworzyć zasób danych w wyniku.
from azure.ai.ml import command, Input, Output, MLClient
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.identity import DefaultAzureCredential
# Set your subscription, resource group and workspace name:
subscription_id = "<SUBSCRIPTION_ID>"
resource_group = "<RESOURCE_GROUP>"
workspace = "<AML_WORKSPACE_NAME>"
# connect to the AzureML workspace
ml_client = MLClient(
DefaultAzureCredential(), subscription_id, resource_group, workspace
)
# ==============================================================
# Set the URI path for the data.
# Supported `path` formats for input include:
# local: `./<path>
# Blob: wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>
# ADLS: abfss://<file_system>@<account_name>.dfs.core.windows.net/<path>
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# Data Asset: azureml:<my_data>:<version>
# Supported `path` format for output is:
# Datastore: azureml://datastores/<data_store_name>/paths/<path>
# As an example, we set the input path to a file on a public blob container
# As an example, we set the output path to a folder in the default datastore
# ==============================================================
input_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/titanic.csv"
output_path = "azureml://datastores/workspaceblobstore/paths/quickstart-output/titanic.csv"
# ==============================================================
# What type of data are you pointing to?
# AssetTypes.URI_FILE (a specific file)
# AssetTypes.URI_FOLDER (a folder)
# AssetTypes.MLTABLE (a table)
# The path we set above is a specific file
# ==============================================================
data_type = AssetTypes.URI_FILE
# ==============================================================
# Set the input mode. The most commonly-used modes:
# InputOutputModes.RO_MOUNT
# InputOutputModes.DOWNLOAD
# Set the mode to Read Only (RO) to mount the data
# ==============================================================
input_mode = InputOutputModes.RO_MOUNT
# ==============================================================
# Set the output mode. The most commonly-used modes:
# InputOutputModes.RW_MOUNT
# InputOutputModes.UPLOAD
# Set the mode to Read Write (RW) to mount the data
# ==============================================================
output_mode = InputOutputModes.RW_MOUNT
# Set the input and output for the job:
inputs = {
"input_data": Input(type=data_type, path=input_path, mode=input_mode)
}
outputs = {
"output_data": Output(type=data_type,
path=output_path,
mode=output_mode,
# optional: if you want to create a data asset from the output,
# then uncomment `name` (`name` can be set without setting `version`, and in this way, we will set `version` automatically for you)
# name = "<name_of_data_asset>", # use `name` and `version` to create a data asset from the output
# version = "<version>",
)
}
# This command job copies the data to your default Datastore
job = command(
command="cp ${{inputs.input_data}} ${{outputs.output_data}}",
inputs=inputs,
outputs=outputs,
environment="azureml://registries/azureml/environments/sklearn-1.1/versions/4",
compute="cpu-cluster",
)
# Submit the command
ml_client.jobs.create_or_update(job)
Środowisko uruchomieniowe danych usługi Azure Machine Learning
Po przesłaniu zadania środowisko uruchomieniowe danych usługi Azure Machine Learning kontroluje obciążenie danych z lokalizacji magazynu do docelowego obiektu obliczeniowego. Środowisko uruchomieniowe danych usługi Azure Machine Learning jest zoptymalizowane pod kątem szybkości i wydajności zadań uczenia maszynowego. Kluczowe korzyści obejmują:
- Dane są ładowane w języku Rust, czyli języku znanym z dużej szybkości i wysokiej wydajności pamięci. W przypadku współbieżnego pobierania danych, Rust unika problemów związanych z blokadą globalnego interpretera w Pythonie (GIL).
- Lekka waga; Rust nie ma zależności od innych technologii — na przykład JVM. W związku z tym środowisko uruchomieniowe jest szybko instalowane i nie opróżnia dodatkowych zasobów (procesora CPU, pamięci) na docelowym obiekcie obliczeniowym
- Ładowanie danych wieloprocesowych (równoległych)
- Prefetchuje dane jako zadanie w tle na co najmniej jednym procesorze, aby umożliwić efektywniejsze wykorzystanie procesorów GPU w procesach uczenia głębokiego
- Zapewnianie bezproblemowej obsługi uwierzytelniania podczas przechowywania w chmurze
- Udostępnia opcje instalowania danych (strumienia) lub pobierania wszystkich danych. Aby uzyskać więcej informacji, odwiedź sekcje Instalowanie (przesyłanie strumieniowe) i Pobieranie .
- Bezproblemowa integracja z fsspec — ujednolicony pythonic interfejs do lokalnych, zdalnych i osadzonych systemów plików oraz przechowywania bajtów.
Wskazówka
Zalecamy zastosowanie runtime'u danych usługi Azure Machine Learning zamiast tworzenia własnej funkcji montowania/pobierania w kodzie trenowania (klienta). Zaobserwowaliśmy ograniczenia przepływności magazynu, gdy kod klienta używa języka Python do pobierania danych z magazynu z powodu problemów z globalną blokadą interpretera (GIL).
Ścieżki
Po podaniu danych wejściowych lub wyjściowych zadania należy określić path parametr wskazujący lokalizację danych. W tej tabeli przedstawiono różne lokalizacje danych obsługiwane przez usługę Azure Machine Learning i przedstawiono path przykłady parametrów:
| Lokalizacja | Przykłady | Dane wejściowe | Dane wyjściowe |
|---|---|---|---|
| Ścieżka na komputerze lokalnym | ./home/username/data/my_data |
Y | N |
| Ścieżka na publicznym serwerze HTTP(S) | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
Y | N |
| Ścieżka w usłudze Azure Storage | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
Y, tylko w przypadku uwierzytelniania opartego na tożsamości | N |
| Ścieżka w magazynie danych usługi Azure Machine Learning | azureml://datastores/<data_store_name>/paths/<path> |
Y | Y |
| Ścieżka do zasobu danych | azureml:<my_data>:<version> |
Y | N, ale możesz użyć polecenia name i version utworzyć zasób danych na podstawie danych wyjściowych |
Tryby
Po uruchomieniu zadania z danymi wejściowymi/wyjściowymi można wybrać spośród następujących opcji trybu :
ro_mount: Zainstaluj lokalizację magazynu jako tylko do odczytu na docelowym obiekcie obliczeniowym dysku lokalnego (SSD).rw_mount: Zamontuj lokalizację magazynu jako odczyt-zapis na lokalnym dysku (SSD) jako docelowym obiekcie obliczeniowym.download: pobierz dane z lokalizacji magazynu do docelowego obiektu obliczeniowego dysku lokalnego (SSD).upload: prześlij dane z obiektu obliczeniowego do lokalizacji pamięci masowej.eval_mount/eval_download:Te tryby pracy są specyficzne dla tabeli MLTable. W niektórych scenariuszach tabela MLTable może zwracać pliki, które mogą znajdować się na koncie magazynowym innym niż konto magazynowe hostujące plik MLTable. Alternatywnie tabela MLTable może podzestawować lub przetasować dane znajdujące się w zasobie magazynu. Ten widok podzestawu/mieszania staje się widoczny tylko wtedy, gdy środowisko uruchomieniowe danych usługi Azure Machine Learning ocenia plik MLTable. Na przykład na tym diagramie pokazano, jak tabela MLTable, używana zeval_mountlubeval_download, może pobrać obrazy z dwóch różnych kontenerów magazynu oraz plik adnotacji znajdujący się na innym koncie magazynu, a następnie zamontować/pobrać je do systemu plików zdalnego celu obliczeniowego.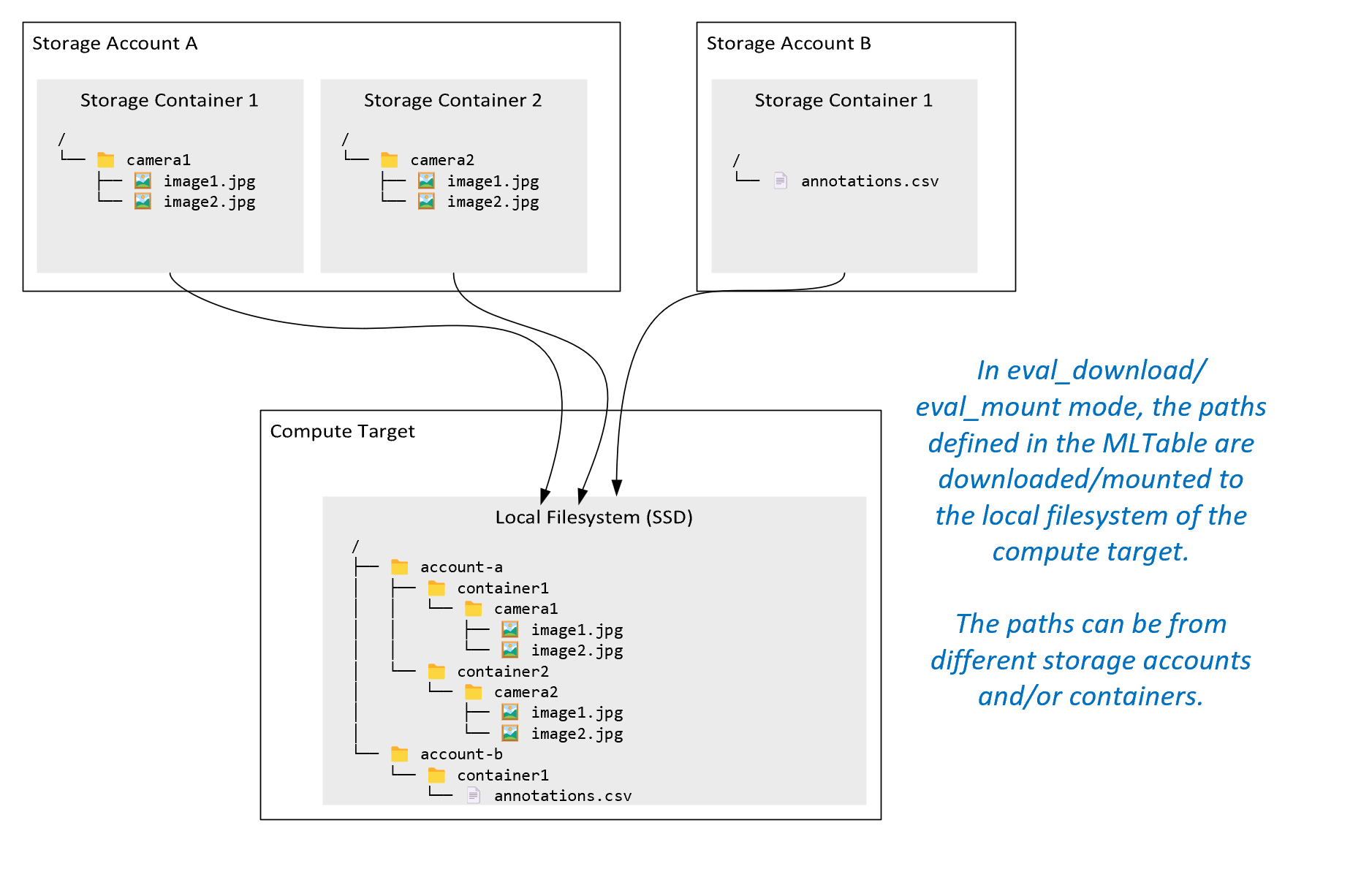
Folder
camera1i foldercamera2oraz plikannotations.csvsą następnie dostępne w strukturze folderów systemu plików docelowego obiektu obliczeniowego./INPUT_DATA ├── account-a │ ├── container1 │ │ └── camera1 │ │ ├── image1.jpg │ │ └── image2.jpg │ └── container2 │ └── camera2 │ ├── image1.jpg │ └── image2.jpg └── account-b └── container1 └── annotations.csvdirect: Być może zechcesz odczytywać dane bezpośrednio z identyfikatora URI przy użyciu innych interfejsów API, zamiast korzystać ze środowiska uruchomieniowego danych Azure Machine Learning. Na przykład możesz chcieć uzyskać dostęp do danych w zasobniku s3 (z adresem URL typu hostowanego w trybie wirtualnym lub w styluhttpsścieżki) przy użyciu klienta boto s3. Identyfikator URI danych wejściowych można uzyskać w postaci ciągu za pomocą trybudirect. Zobaczysz użycie trybu bezpośredniego w zadaniach platformy Spark, ponieważspark.read_*()metody wiedzą, jak przetwarzać identyfikatory URI. W przypadku zadań innych niż Spark ponosisz odpowiedzialność za zarządzanie poświadczeniami dostępu. Na przykład należy jawnie korzystać z MSI obliczeniowego lub uzyskać dostęp do zasobów za pośrednictwem brokera.

W tej tabeli przedstawiono możliwe tryby dla różnych kombinacji typów/trybu/danych wejściowych/wyjściowych:
| Typ | Dane wejściowe/wyjściowe | upload |
download |
ro_mount |
rw_mount |
direct |
eval_download |
eval_mount |
|---|---|---|---|---|---|---|---|---|
uri_folder |
Dane wejściowe | ✓ | ✓ | ✓ | ||||
uri_file |
Dane wejściowe | ✓ | ✓ | ✓ | ||||
mltable |
Dane wejściowe | ✓ | ✓ | ✓ | ✓ | ✓ | ||
uri_folder |
Dane wyjściowe | ✓ | ✓ | |||||
uri_file |
Dane wyjściowe | ✓ | ✓ | |||||
mltable |
Dane wyjściowe | ✓ | ✓ | ✓ |
Pobierz
W trybie pobierania wszystkie dane wejściowe są kopiowane na dysk lokalny (SSD) docelowego obiektu obliczeniowego. Środowisko uruchomieniowe danych usługi Azure Machine Learning uruchamia skrypt trenowania użytkownika po skopiowaniu wszystkich danych. Po uruchomieniu skryptu użytkownika odczytuje dane z dysku lokalnego, podobnie jak w przypadku innych plików. Po zakończeniu zadania dane zostaną usunięte z dysku docelowego obiektu obliczeniowego.
| Zalety | Niedostatki |
|---|---|
| Po rozpoczęciu trenowania wszystkie dane są dostępne na dysku lokalnym (SSD) docelowego obiektu obliczeniowego dla skryptu trenowania. Nie jest wymagana żadna interakcja z usługą Azure Storage/siecią. | Zestaw danych musi być całkowicie dopasowany do dysku docelowego obliczeń. |
| Po uruchomieniu skryptu użytkownika nie ma zależności od niezawodności przechowywania / połączenia sieciowego. | Cały zestaw danych jest pobierany (jeśli trenowanie musi losowo wybrać tylko niewielką część danych, znaczna część pobierania zostanie zmarnowana). |
| Środowisko uruchomieniowe danych usługi Azure Machine Learning może równolegle przetwarzać pobieranie (co ma znaczący wpływ w przypadku wielu małych plików) i maksymalizować przepustowość sieci oraz magazynowania. | Zadanie czeka na pobranie wszystkich danych na dysk lokalny docelowego obiektu obliczeniowego. W przypadku przesłanego zadania dotyczącego uczenia głębokiego, procesory GPU są bezczynne, dopóki dane nie będą gotowe. |
| Brak nieuniknionego obciążenia dodanego przez warstwę FUSE (wywołanie z przestrzeni użytkownika w skrypcie użytkownika → jądro → demon FUSE w przestrzeni użytkownika → jądro → odpowiedź do skryptu użytkownika w przestrzeni użytkownika) | Zmiany pamięci nie są zauważalne na danych po zakończeniu pobierania. |
Kiedy należy używać pobierania
- Dane są wystarczająco małe, aby zmieścić się na dysku obliczeniowego obiektu docelowego bez ingerencji w inne treningi.
- Trenowanie używa większości lub wszystkich zestawów danych
- Proces szkoleniowy odczytuje pliki z zestawu danych wielokrotnie
- Szkolenie musi przeskakiwać do losowych pozycji dużego pliku
- Można poczekać, aż wszystkie dane zostaną pobrane przed rozpoczęciem trenowania
Dostępne ustawienia pobierania
Ustawienia pobierania można dostroić przy użyciu tych zmiennych środowiskowych w zadaniu:
| Nazwa zmiennej środowiskowej | Typ | Wartość domyślna | opis |
|---|---|---|---|
RSLEX_DOWNLOADER_THREADS |
u64 | NUMBER_OF_CPU_CORES * 4 |
Liczba jednoczesnych wątków, które mogą być używane do pobierania. |
AZUREML_DATASET_HTTP_RETRY_COUNT |
u64 | 7 | Liczba prób ponownych dla pojedynczego składowania / http żądania w celu odzyskania po tymczasowych błędach. |
W zadaniu możesz zmienić powyższe wartości domyślne, ustawiając zmienne środowiskowe — na przykład:
W przypadku zwięzłości pokazujemy tylko sposób definiowania zmiennych środowiskowych w zadaniu.
from azure.ai.ml import command
env_var = {
"RSLEX_DOWNLOADER_THREADS": 64,
"AZUREML_DATASET_HTTP_RETRY_COUNT": 10
}
job = command(
environment_variables=env_var
)
Pobieranie metryk wydajności
Rozmiar maszyny wirtualnej docelowego obiektu obliczeniowego ma wpływ na czas pobierania danych. Szczególnie:
- Liczba rdzeni. Więcej dostępnych rdzeni, tym większa współbieżność i tym większa szybkość pobierania.
- Oczekiwana przepustowość sieci. Każda maszyna wirtualna na platformie Azure ma maksymalną przepływność z karty interfejsu sieciowego.
Uwaga
W przypadku maszyn wirtualnych z procesorem GPU A100 środowisko uruchomieniowe danych usługi Azure Machine Learning może doprowadzić do saturacji karty sieciowej podczas pobierania danych do celu obliczeniowego (~24 Gbit/s): teoretycznie możliwa maksymalna przepływność.
W tej tabeli przedstawiono wydajność pobierania, które środowisko uruchomieniowe danych usługi Azure Machine Learning może obsłużyć dla pliku 100 GB na maszynie Standard_D15_v2 wirtualnej (20 rdzeni, przepływność sieci 25 GB/s):
| Struktura danych | Tylko pobieranie (sek.) | Pobierz i oblicz MD5 (s) | Osiągnięta przepływność (Gbit/s) |
|---|---|---|---|
| 10 x 10 GB plików | 55.74 | 260.97 | 14,35 Gb/s |
| 100 x 1 GB plików | 58.09 | 259.47 | 13,77 Gb/s |
| 1 x 100 GB pliku | 96.13 | 300.61 | 8.32 Gb/s |
Widzimy, że większy plik podzielony na mniejsze pliki może zwiększyć wydajność pobierania z powodu równoległości. Zalecamy unikanie plików, które stają się zbyt małe (mniej niż 4 MB), ponieważ czas potrzebny do przesłania żądań magazynu wzrasta w porównaniu z czasem spędzonym na pobieraniu ładunku. Aby uzyskać więcej informacji, przeczytaj problem wielu małych plików.
Instalowanie (przesyłanie strumieniowe)
W trybie instalacji funkcja danych usługi Azure Machine Learning korzysta z funkcji FUSE (systemu plików w przestrzeni użytkownika) systemu Linux w celu utworzenia emulowanego systemu plików. Zamiast pobierać wszystkie dane na dysk lokalny (SSD) docelowego obiektu obliczeniowego, środowisko uruchomieniowe może reagować na akcje skryptu użytkownika w czasie rzeczywistym. Na przykład "otwórz plik", "odczytaj fragment o rozmiarze 2 KB z pozycji X", "wyświetl zawartość katalogu".
| Zalety | Niedostatki |
|---|---|
| Dane, które przekraczają docelową pojemność lokalnego dysku obliczeniowego, mogą być używane (nie są ograniczone przez sprzęt obliczeniowy) | Dodano obciążenie modułu FUSE systemu Linux. |
| Brak opóźnień na początku trenowania (w przeciwieństwie do trybu pobierania). | Zależność od zachowania kodu użytkownika (jeśli kod trenowania, który sekwencyjnie odczytuje małe pliki w jednym wątku, żąda również danych z pamięci masowej, może nie zmaksymalizować przepustowości sieci lub pamięci masowej). |
| Bardziej dostępne ustawienia dostrajania scenariusza użycia. | Brak obsługi okien. |
| Tylko dane potrzebne do szkolenia są odczytywane z pamięci masowej. |
Kiedy należy użyć montowania
- Dane są duże i nie mieszczą się na docelowym dysku lokalnym obliczeniowym.
- Każdy pojedynczy węzeł obliczeniowy w klastrze nie musi odczytywać całego zestawu danych (wybór losowego pliku lub wierszy w pliku CSV itp.).
- Opóźnienia oczekiwania na pobranie wszystkich danych przed rozpoczęciem trenowania mogą stać się problemem (czas bezczynności procesora GPU).
Dostępne ustawienia instalacji
Ustawienia instalacji można dostosować przy użyciu tych zmiennych środowiskowych w zadaniu:
| Nazwa zmiennej Env | Typ | Domyślna wartość | opis |
|---|---|---|---|
DATASET_MOUNT_ATTRIBUTE_CACHE_TTL |
u64 | Nie ustawiono (pamięć podręczna nigdy nie wygasa) | Czas w milisekundach potrzebny do zachowania getattr wyników wywołania w pamięci podręcznej i uniknięcia kolejnych żądań tych informacji z magazynu. |
DATASET_RESERVED_FREE_DISK_SPACE |
u64 | 150 MB | Przeznaczone do konfiguracji systemu, aby zachować dobrą kondycję obliczeniową. Niezależnie od wartości innych ustawień środowisko uruchomieniowe danych usługi Azure Machine Learning nie używa ostatnich RESERVED_FREE_DISK_SPACE bajtów miejsca na dysku. |
DATASET_MOUNT_CACHE_SIZE |
usize | Nieograniczony | Określa, ile miejsca na dysku może używać. Wartość dodatnia ustawia wartość bezwzględną w bajtach. Wartość ujemna określa ilość wolnego miejsca na dysku. Ta tabela zawiera więcej opcji pamięci podręcznej dysku. Obsługuje KB, MB i GB modyfikatory dla wygody. |
DATASET_MOUNT_FILE_CACHE_PRUNE_THRESHOLD |
f64 | 1.0 | Montaż woluminu rozpoczyna oczyszczanie pamięci podręcznej, gdy pamięć podręczna jest zapełniona do AVAILABLE_CACHE_SIZE * DATASET_MOUNT_FILE_CACHE_PRUNE_THRESHOLD. Powinna należeć do zakresu od 0 do 1. Ustawienie tej wartości na < 1 powoduje wcześniejsze rozpoczęcie oczyszczania pamięci podręcznej w tle.
AVAILABLE_CACHE_SIZE nie jest zmienną środowiskową, którą można modyfikować ani wyświetlać bezpośrednio. W tym kontekście odnosi się do "liczby bajtów, które system oblicza jako dostępne dla buforowania". Ta wartość zależy od czynników, takich jak rozmiar dysku, ilość miejsca na dysku wymagana do kondycji systemu i konfiguracje ustawione w zmiennych środowiskowych (na przykład DATASET_RESERVED_FREE_DISK_SPACE i DATASET_MOUNT_CACHE_SIZE). |
DATASET_MOUNT_FILE_CACHE_PRUNE_TARGET |
f64 | 0,7 | Czyszczenie pamięci podręcznej próbuje zwolnić co najmniej (1-DATASET_MOUNT_FILE_CACHE_PRUNE_TARGET) miejsca w pamięci podręcznej. |
DATASET_MOUNT_READ_BLOCK_SIZE |
usize | 2 MB | Rozmiar bloku odczytu przesyłania strumieniowego. Gdy plik jest wystarczająco duży, zażądaj co najmniej DATASET_MOUNT_READ_BLOCK_SIZE danych z magazynu i buforuj je, nawet gdy system plików FUSE zażądał operacji odczytu dla mniejszej ilości danych. |
DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT |
usize | 32 | Liczba bloków do pobrania wstępnego (blok odczytu k wyzwala wstępne pobieranie w tle bloków k+1, ..., k.+DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT) |
DATASET_MOUNT_READ_THREADS |
usize | NUMBER_OF_CORES * 4 |
Liczba wątków wstępnego pobierania w tle. |
DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED |
Bool | fałsz | Włącz buforowanie oparte na blokach. |
DATASET_MOUNT_MEMORY_CACHE_SIZE |
usize | 128 MB | Dotyczy wyłącznie buforowania opartego na blokach. Rozmiar pamięci dla buforowania opartego na blokach, który może być używany. Wartość 0 powoduje całkowite wyłączenie buforowania pamięci. |
DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED |
Bool | prawda | Dotyczy wyłącznie buforowania opartego na blokach. W przypadku ustawienia wartości true, blokowe buforowanie używa lokalnego dysku twardego do przechowywania bloków. |
DATASET_MOUNT_BLOCK_FILE_CACHE_MAX_QUEUE_SIZE |
usize | 512 MB | Dotyczy wyłącznie buforowania opartego na blokach. Buforowanie blokowe zapisuje buforowane bloki na dysku lokalnym w tle. To ustawienie określa, ile miejsca instalacji pamięci może używać do przechowywania bloków oczekujących na opróżnienie do pamięci podręcznej dysku lokalnego. |
DATASET_MOUNT_BLOCK_FILE_CACHE_WRITE_THREADS |
usize | NUMBER_OF_CORES * 2 |
Dotyczy wyłącznie buforowania opartego na blokach. Liczba wątków w tle używanych przez pamięć podręczną opartą na blokach do zapisywania pobranych bloków na dysku lokalnym docelowego celu obliczeniowego. |
DATASET_UNMOUNT_TIMEOUT_SECONDS |
u64 | 30 | Czas w sekundach dla unmount na bezpieczne zakończenie wszystkich oczekujących operacji (na przykład opróżnianie wywołań) przed wymuszonym zakończeniem pętli komunikatów montowania. |
W zadaniu możesz zmienić powyższe wartości domyślne, ustawiając zmienne środowiskowe, na przykład:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": True
}
job = command(
environment_variables=env_var
)
Tryb otwierania oparty na bloku
Tryb otwierania oparty na bloku dzieli każdy plik na bloki wstępnie zdefiniowanego rozmiaru (z wyjątkiem ostatniego bloku). Żądanie odczytu z określonej pozycji żąda odpowiedniego bloku z magazynu i natychmiast zwraca żądane dane. Odczyt wyzwala również wstępne pobieranie następnych N bloków w tle, wykorzystując wiele wątków (zoptymalizowanych pod kątem odczytu sekwencyjnego). Pobrane bloki są buforowane w dwóch warstwach pamięci podręcznej (pamięć RAM i dysk lokalny).
| Zalety | Niedostatki |
|---|---|
| Szybkie dostarczanie danych do skryptu trenowania (mniej blokowania fragmentów, których jeszcze nie zażądano). | Losowe odczyty mogą marnować bloki pobrane do przodu. |
| Więcej zadań jest przenoszonych na wątki w tle (pobieranie wstępne/buforowanie). Następnie można kontynuować szkolenie. | Dodano nakład pracy na nawigowanie między pamięciami podręcznymi w porównaniu z bezpośrednim odczytywaniem pliku z lokalnej pamięci podręcznej dysku (na przykład w trybie pamięci podręcznej całego pliku). |
| Tylko żądane dane (plus prefetching) są odczytywane z pamięci. | |
| W przypadku wystarczająco małych danych używana jest szybka pamięć podręczna oparta na pamięci RAM. |
Kiedy należy używać trybu otwierania opartego na blokach
Zalecane w przypadku większości scenariuszy , z wyjątkiem sytuacji, w których potrzebne są szybkie odczyty z losowych lokalizacji plików. W takich przypadkach należy użyć trybu otwierania całej pamięci podręcznej plików.
Tryb otwierania całej pamięci podręcznej plików
Po otwarciu pliku w folderze instalacji (na przykład f = open(path, args)) w trybie całego pliku wywołanie zostanie zablokowane do momentu pobrania całego pliku do docelowego folderu pamięci podręcznej obliczeniowej na dysku. Wszystkie kolejne wywołania odczytu przekierowują do buforowanego pliku, więc nie jest wymagana żadna interakcja z magazynem. Jeśli pamięć podręczna nie ma wystarczająco dostępnego miejsca do przechowania bieżącego pliku, mount próbuje usunąć z niej najrzadziej używany plik. W przypadkach, gdy plik nie może zmieścić się na dysku (w odniesieniu do ustawień pamięci podręcznej), środowisko uruchomieniowe danych powraca do trybu przesyłania strumieniowego.
| Zalety | Niedostatki |
|---|---|
| Nie ma zależności od niezawodności/przepustowości magazynu danych po otwarciu pliku. | Otwarte wywołanie jest blokowane do momentu pobrania całego pliku. |
| Szybkie losowe operacje odczytu (odczytywanie fragmentów z losowych miejsc pliku). | Cały plik jest odczytywany z magazynu, nawet jeśli niektóre fragmenty pliku mogą nie być potrzebne. |
Kiedy go używać
Gdy są potrzebne losowe operacje odczytu dla stosunkowo dużych plików, które przekraczają 128 MB.
Użycie
Ustaw zmienną środowiskową DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED na false w zadaniu:
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": False
}
job = command(
environment_variables=env_var
)
Instalowanie: wyświetlanie listy plików
Podczas pracy z milionami plików unikaj cyklicznej listy — na przykład ls -R /mnt/dataset/folder/. Lista cykliczna wyzwala wiele wywołań, aby wyświetlić listę zawartości katalogu nadrzędnego. Następnie wymaga oddzielnego wywołania cyklicznego dla każdego katalogu wewnątrz, na wszystkich poziomach podrzędnych. Zazwyczaj usługa Azure Storage umożliwia zwracanie tylko 5000 elementów na pojedyncze żądanie listy. W rezultacie, rekursywne wylistowanie 1M folderów, z których każdy zawiera 10 plików, wymaga 1,000,000 / 5000 + 1,000,000 = 1,000,200 żądań do magazynu. Dla porównania 1 000 folderów z 10 000 plików wymagałoby tylko 1 001 żądań do magazynowania dla rekursywnego listowania.
Usługa Azure Machine Learning obsługuje montowanie w sposób leniwy. Dlatego aby wyświetlić listę wielu małych plików, lepiej użyć iteracyjnego wywołania biblioteki klienta (na przykład w języku Python) zamiast wywołania biblioteki klienta zwracającej pełną listę (na przykład os.scandir()os.listdir() w języku Python). Iteracyjna funkcja wywołująca bibliotekę klienta zwraca generator, co oznacza, że nie trzeba czekać, aż cała lista zostanie załadowana. Następnie może działać szybciej.
Ta tabela porównuje czas potrzebny dla języka Python os.scandir() i os.listdir() funkcji, aby wyświetlić listę folderów zawierających pliki ~4M w płaskiej strukturze:
| Wskaźnik | os.scandir() |
os.listdir() |
|---|---|---|
| Czas uzyskania pierwszego wpisu (s) | 0.67 | 553.79 |
| Czas uzyskania pierwszych 50 tys. wpisów (s) | 9.56 | 562.73 |
| Czas na pobranie wszystkich wpisów (s) | 558.35 | 582.14 |
Optymalne ustawienia instalacji dla typowych scenariuszy
W przypadku niektórych typowych scenariuszy przedstawiono optymalne ustawienia instalacji, które należy ustawić w zadaniu usługi Azure Machine Learning.
Odczytywanie dużych plików pojedynczo (przetwarzanie wierszy w pliku CSV)
Uwzględnij te ustawienia montowania w sekcji environment_variables swojego zadania usługi Azure Machine Learning.
Uwaga
Aby użyć bezserwerowych obliczeń, usuń compute="cpu-cluster", w tym kodzie.
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
# Increase the number of blocks used for prefetch. This leads to use of more RAM (2 MB * #value set).
# Can adjust up and down for fine-tuning, depending on the actual data processing pattern.
# An optimal setting based on our test ~= the number of prefetching threads (#CPU_CORES * 4 by default)
"DATASET_MOUNT_READ_BUFFER_BLOCK_COUNT": 80,
}
job = command(
environment_variables=env_var
)
Odczytywanie dużego pliku jednorazowo z wielu wątków (przetwarzanie partycjonowanego pliku CSV w wielu wątkach)
Uwzględnij te ustawienia montowania w sekcji environment_variables swojego zadania usługi Azure Machine Learning.
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
}
job = command(
environment_variables=env_var
)
Odczytywanie milionów małych plików (obrazów) z wielu wątków jednorazowo (trenowanie pojedynczej epoki na obrazach)
Uwzględnij te ustawienia montowania w sekcji environment_variables swojego zadania usługi Azure Machine Learning.
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
"DATASET_MOUNT_BLOCK_FILE_CACHE_ENABLED": False, # Disable caching on disk
"DATASET_MOUNT_MEMORY_CACHE_SIZE": 0, # Disabling in-memory caching
}
job = command(
environment_variables=env_var
)
Wielokrotne odczytywanie milionów małych plików (obrazów) z wielu wątków (trenowanie wielu epok na obrazach)
Uwzględnij te ustawienia montowania w sekcji environment_variables swojego zadania usługi Azure Machine Learning.
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": True, # Enable block-based caching
}
job = command(
environment_variables=env_var
)
Odczytywanie dużego pliku z losowymi wyszukiwaniami (na przykład obsługa bazy danych plików z zainstalowanego folderu)
Uwzględnij te ustawienia montowania w sekcji environment_variables swojego zadania usługi Azure Machine Learning.
from azure.ai.ml import command
env_var = {
"DATASET_MOUNT_BLOCK_BASED_CACHE_ENABLED": False, # Disable block-based caching
}
job = command(
environment_variables=env_var
)
Diagnozowanie i rozwiązywanie problemów z przepustowością ładowania danych
Gdy zadanie usługi Azure Machine Learning jest wykonywane z danymi, element wejściowy określa, mode jak bajty są odczytywane z magazynu i buforowane na docelowym docelowym dysku SSD obliczeniowym. W trybie pobierania wszystkie pamięci podręczne danych są umieszczane na dysku przed rozpoczęciem wykonywania kodu użytkownika. Kilka czynników wpływa na maksymalną szybkość pobierania:
- Liczba wątków równoległych
- Liczba plików
- Rozmiar pliku
W przypadku trybu instalacji kod użytkownika musi zacząć otwierać pliki przed rozpoczęciem buforowania danych. Różne ustawienia montażu powodują różne zachowanie odczytu i buforowania. Różne czynniki wpływają na szybkość ładowania danych z magazynu:
- Lokalizacja danych do obliczenia: Lokalizacja docelowa magazynu i zasobów obliczeniowych powinna być taka sama. Jeśli magazyn i docelowy obiekt obliczeniowy znajdują się w różnych regionach, wydajność spada, ponieważ dane muszą być przesyłane między regionami. Aby uzyskać więcej informacji na temat sposobu zapewniania kolokacji danych za pomocą obliczeń, odwiedź stronę Colocate data with compute (Kolokuj dane za pomocą obliczeń).
-
Rozmiar docelowy obliczeń: Małe obliczenia mają mniejsze liczby rdzeni (mniejsze równoległości) i mniejszą oczekiwaną przepustowość sieci w porównaniu z większymi rozmiarami obliczeniowymi — oba czynniki wpływają na wydajność ładowania danych.
- Jeśli na przykład używasz małego rozmiaru maszyny wirtualnej (
Standard_D2_v22 rdzenie, karta sieciowa 1500 Mb/s) i spróbujesz załadować 50 000 MB (50 GB) danych, najlepszy osiągalny czas ładowania danych wyniesie ok. 270 s (przy założeniu, że karta sieciowa działa z przepustowością 187,5 MB/s).Standard_D5_v2Natomiast urządzenie (16 rdzeni, 12 000 Mb/s) załadowałoby te same dane w około 33 sekundy (zakładając pełne wykorzystanie przepustowości karty sieciowej przy przepływności 1500 MB/s).
- Jeśli na przykład używasz małego rozmiaru maszyny wirtualnej (
- Warstwa magazynowania: w przypadku większości scenariuszy, w tym modeli dużych języków (LLM), standardowa warstwa magazynowania zapewnia najlepszy profil kosztów/wydajności. Jeśli jednak masz wiele małych plików, usługa Premium Storage oferuje lepszy koszt/profil wydajności. Aby uzyskać więcej informacji, przeczytaj opcje usługi Azure Storage.
- Obciążenie pamięci: jeśli konto magazynu jest pod dużym obciążeniem — na przykład wiele węzłów GPU w klastrze żąda danych — istnieje ryzyko osiągnięcia granicy przepustowości wychodzącej magazynu. Aby uzyskać więcej informacji, zobacz Obciążenie pamięci. Jeśli masz wiele małych plików, które wymagają jednoczesnego dostępu, możesz napotkać limity żądań przechowywania. Przeczytaj aktualne informacje na temat limitów zarówno dla przepustowości ruchu wychodzącego, jak i żądań dotyczących przechowywania w celach skalowania dla standardowych kont przechowywania.
- Wzorzec dostępu do danych w kodzie użytkownika: w przypadku korzystania z trybu instalacji dane są pobierane na podstawie akcji otwierania/odczytu w kodzie. Na przykład, podczas odczytywania losowych sekcji dużego pliku, domyślne ustawienia wstępnego pobierania danych zamontowanych systemów plików mogą prowadzić do pobierania bloków, które nie będą odczytywane. Może być konieczne dostosowanie niektórych ustawień w celu osiągnięcia maksymalnej przepływności. Aby uzyskać więcej informacji, zobacz Optymalne ustawienia instalacji dla typowych scenariuszy.
Diagnozowanie problemów przy użyciu dzienników
Aby uzyskać dostęp do logów środowiska wykonawczego danych z zadania:
- Wybierz kartę Wyniki i Dzienniki na stronie zadania.
- Wybierz folder system_logs, a następnie folder data_capability.
- Powinny zostać wyświetlone dwa pliki dziennika:
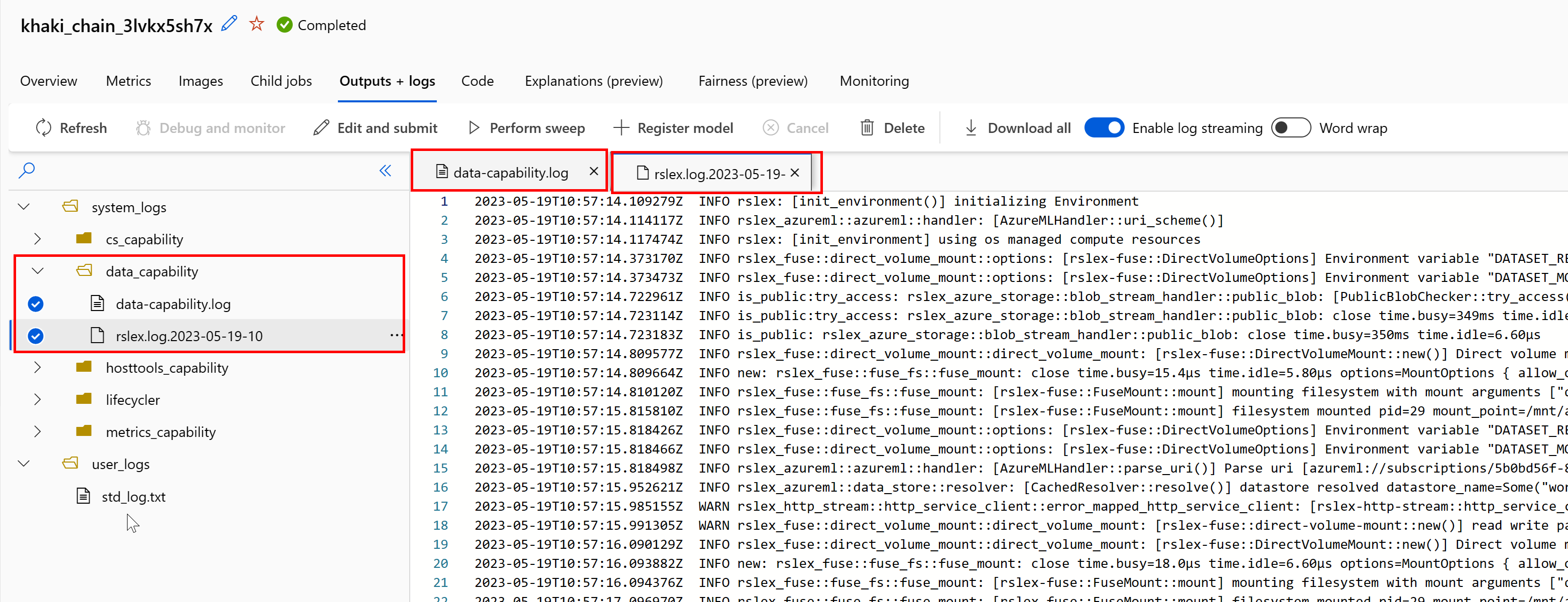

Plik logu data-capability.log przedstawia informacje ogólne o czasie spędzonym na kluczowych zadaniach ładowania danych. Na przykład podczas pobierania danych środowisko uruchomieniowe rejestruje czas rozpoczęcia i zakończenia działania pobierania:
INFO 2023-05-18 17:14:47,790 sdk_logger.py:44 [28] - ActivityStarted, download
INFO 2023-05-18 17:14:50,295 sdk_logger.py:44 [28] - ActivityCompleted: Activity=download, HowEnded=Success, Duration=2504.39 [ms]
Jeśli prędkość pobierania jest ułamkiem oczekiwanej przepustowości sieciowej dla rozmiaru maszyny wirtualnej, możesz sprawdzić plik logu rslex.log.<ZNACZNIK CZASOWY>. Ten plik zawiera całe drobiazgowe rejestrowanie ze środowiska uruchomieniowego opartego na języku Rust, na przykład przetwarzanie równoległe.
2023-05-18T14:08:25.388670Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:reduce:get_iter: rslex::prefetching: close time.busy=23.2µs time.idle=1.90µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 i=0 index=0
2023-05-18T14:08:25.388731Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:reduce: rslex::dataset_crossbeam: close time.busy=90.9µs time.idle=9.10µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 i=0
2023-05-18T14:08:25.388762Z INFO copy_uri:copy_uri:copy_dataset:write_streams_to_files:collect:reduce:reduce_and_combine:combine: rslex::dataset_crossbeam: close time.busy=1.22ms time.idle=9.50µs sessionId=012ea46a-341c-4258-8aba-90bde4fdfb51 source=Dataset[Partitions: 1, Sources: 1] file_name_column=None break_on_first_error=true skip_existing_files=false parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4 self=Dataset[Partitions: 1, Sources: 1] parallelization_degree=4
Plik rslex.log zawiera szczegółowe informacje o wszystkich kopiach plików, niezależnie od tego, czy wybrano tryb instalacji, czy pobierania. Opisuje również używane ustawienia (zmienne środowiskowe). Aby rozpocząć debugowanie, sprawdź, czy dla typowych scenariuszy ustawiono optymalne ustawienia instalacji.
Monitorowanie usługi Azure Storage
W witrynie Azure Portal możesz wybrać konto magazynu, a następnie metryki, aby wyświetlić metryki magazynu:

Następnie wykreślasz SuccessE2ELatency z SuccessServerLatency. Jeśli metryki pokazują wysoką wartość SuccessE2ELatency i niską wartość SuccessServerLatency, masz ograniczoną liczbę dostępnych wątków lub kończą ci się zasoby, takie jak CPU, pamięć lub przepustowość sieci. Należy:
- Użyj widoku monitorowania w usłudze Azure Machine Learning Studio, aby sprawdzić wykorzystanie procesora i pamięci zadania. Jeśli jest mało procesora CPU i pamięci, rozważ zwiększenie docelowego rozmiaru maszyny wirtualnej obliczeniowej.
- Rozważ zwiększenie
RSLEX_DOWNLOADER_THREADS, jeśli pobierasz i nie korzystasz z procesora i pamięci. Jeśli używasz polecenia mount, należy zwiększyćDATASET_MOUNT_READ_BUFFER_BLOCK_COUNTpobieranie wstępne i zwiększyćDATASET_MOUNT_READ_THREADSliczbę wątków odczytu.
Jeśli metryki pokazują niską wartość SuccessE2ELatency i niską wartość SuccessServerLatency, ale klient ma duże opóźnienie, masz opóźnienie w żądaniu magazynowania, które dociera do serwisu. Należy sprawdzić:
- Czy liczba wątków używanych do montowania/pobierania (
DATASET_MOUNT_READ_THREADS/RSLEX_DOWNLOADER_THREADS) jest ustawiona zbyt nisko w porównaniu do liczby rdzeni dostępnych w docelowej jednostce obliczeniowej? Jeśli ustawienie jest zbyt niskie, zwiększ liczbę wątków. - Określa, czy liczba ponownych prób pobierania (
AZUREML_DATASET_HTTP_RETRY_COUNT) jest zbyt wysoka. Jeśli tak, zmniejsz liczbę ponownych prób.
Monitorowanie użycia dysku podczas zadania
W Azure Machine Learning Studio można również monitorować operacje wejścia/wyjścia dysku docelowego jednostki obliczeniowej i jego użycie podczas wykonywania zadań. Przejdź do zadania i wybierz kartę Monitorowanie . Ta karta zawiera szczegółowe informacje o zasobach zadania w 30 dniach. Na przykład:

Uwaga
Monitorowanie zadań obsługuje tylko zasoby obliczeniowe zarządzane przez usługę Azure Machine Learning. Zadania z czasem działania krótszym niż 5 minut nie będą miały wystarczającej liczby danych, aby zapełnić widok.
Środowisko uruchomieniowe danych usługi Azure Machine Learning nie używa ostatnich RESERVED_FREE_DISK_SPACE bajtów miejsca na dysku, aby zachować dobrą kondycję obliczeniową (wartość domyślna to 150MB). Jeśli dysk jest pełny, kod zapisuje pliki na dysku bez deklarowania plików jako danych wyjściowych. W związku z tym sprawdź kod, aby upewnić się, że dane nie są błędnie zapisywane na dysku tymczasowym. Jeśli musisz zapisać pliki na dysku tymczasowym i ten zasób staje się pełny, rozważ:
- Zwiększanie rozmiaru maszyny wirtualnej do takiego, który ma większy dysk tymczasowy
- Ustawianie czasu wygaśnięcia na buforowanych danych (
DATASET_MOUNT_ATTRIBUTE_CACHE_TTL) w celu przeczyszczania danych z dysku
Kolokowanie danych za pomocą obliczeń
Uwaga
Jeśli magazyn i zasoby obliczeniowe znajdują się w różnych regionach, wydajność spada, ponieważ dane muszą być przesyłane między regionami. Zwiększa to koszty. Upewnij się, że twoje konto magazynu i zasoby obliczeniowe znajdują się w tym samym regionie.
Jeśli dane i obszar roboczy usługi Azure Machine Learning są przechowywane w różnych regionach, zalecamy skopiowanie danych na konto magazynowe w tym samym regionie, używając narzędzia azcopy. Narzędzie AzCopy używa interfejsów API serwer-serwer, dzięki czemu dane są kopiowane bezpośrednio pomiędzy serwerami przechowywania. Te operacje kopiowania nie korzystają z przepustowości sieci komputera. Możesz zwiększyć przepływność tych operacji za pomocą zmiennej środowiskowej AZCOPY_CONCURRENCY_VALUE . Aby dowiedzieć się więcej, zobacz Zwiększanie współbieżności.
Ładowanie magazynu
Pojedyncze konto magazynu może stać się ograniczone, jeśli występuje duże obciążenie, gdy:
- Zadanie używa wielu węzłów procesora GPU
- Konto magazynowe ma wiele równoczesnych aplikacji, które uzyskują dostęp do danych, gdy uruchamiasz zadanie.
W tej sekcji przedstawiono obliczenia określające, czy ograniczanie przepustowości może stać się problemem dla obciążenia, oraz sposób podejścia do redukcji ograniczania przepustowości.
Obliczanie limitów przepustowości
Konto usługi Azure Storage ma domyślny limit ruchu wychodzącego 120 GB/s. Maszyny wirtualne platformy Azure mają różne przepustowości sieci, które wpływają na teoretyczną liczbę węzłów obliczeniowych potrzebnych do osiągnięcia maksymalnej domyślnej wydajności ruchu wychodzącego z magazynu.
| Rozmiar | Karta procesora GPU | procesor wirtualny | Pamięć: GiB | Magazyn tymczasowy (SSD): GiB | Liczba kart gpu | Pamięć procesora GPU: GiB | Oczekiwana przepustowość sieci (Gbit/s) | Domyślna maksymalna przepustowość wyjściowa konta magazynowego (Gbit/s)* | Liczba węzłów, które mają osiągnąć domyślną pojemność ruchu wychodzącego |
|---|---|---|---|---|---|---|---|---|---|
| Standard_ND96asr_v4 | A100 | 96 | 900 | 6000 | 8 | 40 | 24 | 120 | 5 |
| Standard_ND96amsr_A100_v4 | A100 | 96 | 1900 | 6400 | 8 | 80 | 24 | 120 | 5 |
| Standard_NC6s_v3 | V100 | 6 | 112 | 736 | 1 | 16 | 24 | 120 | 5 |
| Standard_NC12s_v3 | V100 | 12 | 224 | 1474 | 2 | 32 | 24 | 120 | 5 |
| Standard_NC24s_v3 | V100 | 24 | 448 | 2948 | 4 | 64 | 24 | 120 | 5 |
| Standard_NC24rs_v3 | V100 | 24 | 448 | 2948 | 4 | 64 | 24 | 120 | 5 |
| Standard_NC4as_T4_v3 | T4 | 4 | 28 | 180 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC8as_T4_v3 | T4 | 8 | 56 | 360 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC16as_T4_v3 | T4 | 16 | 110 | 360 | 1 | 16 | 8 | 120 | 15 |
| Standard_NC64as_T4_v3 | T4 | 64 | 440 | 2880 | 4 | 64 | 32 | 120 | 3 |
Obie jednostki SKU A100/V100 mają maksymalną przepustowość sieci na węzeł wynoszącą 24 gb/s. Jeśli każdy węzeł odczytujący dane z jednego konta może odczytywać blisko teoretycznego maksimum 24 Gbit/s, limit ruchu wychodzącego byłby osiągnięty przy pięciu węzłach. Użycie co najmniej sześciu węzłów obliczeniowych zacznie obniżać przepływność danych we wszystkich węzłach.
Ważne
Jeśli obciążenie wymaga więcej niż sześciu węzłów A100/V100 lub uważasz, że przekroczysz domyślną pojemność ruchu wychodzącego magazynu (120 GB/s), skontaktuj się z pomocą techniczną (za pośrednictwem witryny Azure Portal) i zażądasz zwiększenia limitu ruchu wychodzącego magazynu.
Skalowanie na wielu kontach magazynowych
Możesz przekroczyć maksymalną przepustowość ruchu wychodzącego z przestrzeni dyskowej i/lub osiągnąć limity szybkości żądań. Jeśli wystąpią te problemy, sugerujemy, aby skontaktować się z pomocą techniczną najpierw, aby zwiększyć te limity na koncie przechowywania.
Jeśli nie możesz zwiększyć maksymalnej pojemności ruchu wychodzącego lub limitu szybkości żądań, rozważ replikowanie danych na wielu kontach magazynowych. Skopiuj dane do wielu kont za pomocą usługi Azure Data Factory, Eksplorator usługi Azure Storage lub azcopy, a następnie zainstaluj wszystkie konta w zadaniu szkoleniowym. Pobierane są tylko dane, do których uzyskuje się dostęp podczas instalacji. W związku z tym, Twój kod treningowy może odczytać RANK ze zmiennej środowiskowej, aby określić, z których z wielu punktów montowań wejściowych należy odczytać. Definicja zadania jest przekazywana na liście kont magazynu:
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
code: src
command: >-
python train.py
--epochs ${{inputs.epochs}}
--learning-rate ${{inputs.learning_rate}}
--data ${{inputs.cifar_storage1}}, ${{inputs.cifar_storage2}}
inputs:
epochs: 1
learning_rate: 0.2
cifar_storage1:
type: uri_folder
path: azureml://datastores/storage1/paths/cifar
cifar_storage2:
type: uri_folder
path: azureml://datastores/storage2/paths/cifar
environment: azureml:AzureML-pytorch-1.9-ubuntu18.04-py37-cuda11-gpu@latest
compute: azureml:gpu-cluster
distribution:
type: pytorch
process_count_per_instance: 1
resources:
instance_count: 2
display_name: pytorch-cifar-distributed-example
experiment_name: pytorch-cifar-distributed-example
description: Train a basic convolutional neural network (CNN) with PyTorch on the CIFAR-10 dataset, distributed via PyTorch.
Twój kod szkoleniowy w Pythonie może następnie użyć RANK do uzyskania konta magazynu przypisanego do tego węzła.
import argparse
import os
parser = argparse.ArgumentParser()
parser.add_argument('--data', nargs='+')
args = parser.parse_args()
world_size = int(os.environ["WORLD_SIZE"])
rank = int(os.environ["RANK"])
local_rank = int(os.environ["LOCAL_RANK"])
data_path_for_this_rank = args.data[rank]
Problem z wieloma małymi plikami
Odczytywanie plików z magazynu obejmuje wykonywanie żądań dla każdego pliku. Liczba żądań na plik różni się w zależności od rozmiarów plików i ustawień oprogramowania obsługującego odczyty pliku.
Pliki są odczytywane w blokach o rozmiarze od 1 do 4 MB. Pliki mniejsze niż blok są odczytywane z pojedynczym żądaniem (GET file.jpg 0–4 MB), a pliki większe niż blok mają jedno żądanie na blok (GET file.jpg 0–4 MB, GET file.jpg 4–8 MB). W tej tabeli pokazano, że pliki mniejsze niż blok 4 MB powodują więcej żądań magazynowania w porównaniu z większymi plikami:
| # Pliki | Rozmiar pliku | Łączny rozmiar danych | Rozmiar bloku | # Żądania magazynu |
|---|---|---|---|---|
| 2,000,000 | 500 KB | 1 TB (terabajt) | 4 MB | 2,000,000 |
| 1000 | 1 GB | 1 TB (terabajt) | 4 MB | 256,000 |
W przypadku małych plików interwał opóźnienia obejmuje głównie obsługę żądań do magazynu zamiast transferów danych. W związku z tym oferujemy te zalecenia, aby zwiększyć rozmiar pliku:
- Dla danych nieustrukturyzowanych (obrazów, wideo itp.), spakuj małe pliki w archiwum (zip/tar), aby przechowywać je jako większy plik, który można odczytywać partiami. Te większe zarchiwizowane pliki można otworzyć w zasobie obliczeniowym, a narzędzie PyTorch Archive DataPipes może wyodrębnić mniejsze pliki.
- W przypadku danych strukturalnych (CSV, parquet itp.) sprawdź proces ETL, aby upewnić się, że pliki łączą się w celu zwiększenia rozmiaru. Spark ma metody
repartition()icoalesce()aby pomóc zwiększyć rozmiar plików.
Jeśli nie możesz zwiększyć rozmiarów plików, zapoznaj się z opcjami usługi Azure Storage.
Opcje usługi Azure Storage
Usługa Azure Storage oferuje dwie warstwy — Standardowa i Premium:
| Magazyn | Scenariusz |
|---|---|
| Azure Blob — Standardowa (HDD) | Dane są ustrukturyzowane w większych obiektach typu blob — takich jak obrazy, wideo itp. |
| Azure Blob — Premium (SSD) | Wysokie szybkości transakcji, mniejsze obiekty lub stale niskie wymogi dotyczące opóźnień pamięci |
Wskazówka
W przypadku "wielu" małych plików (wielkość KB) zalecamy użycie warstwy Premium (SSD), ponieważ koszt magazynu jest mniejszy niż koszty uruchamiania obliczeń procesora GPU.
Odczytywanie zasobów danych wersji 1
W tej sekcji wyjaśniono, jak odczytywać jednostki danych V1 FileDataset oraz TabularDataset w zadaniu V2.
Odczytaj FileDataset
W obiekcie Input określ type jako AssetTypes.MLTABLE oraz mode jako InputOutputModes.EVAL_MOUNT:
Uwaga
Aby użyć bezserwerowych obliczeń, usuń compute="cpu-cluster", w tym kodzie.
Aby uzyskać więcej informacji o obiektach MLClient, opcjach inicjowania obiektu MLClient i sposobach nawiązywania połączenia z obszarem roboczym, odwiedź stronę Nawiązywanie połączenia z obszarem roboczym.
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<filedataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.EVAL_MOUNT
)
}
job = command(
code="./src", # Local path where the code is stored
command="ls ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the job status
returned_job.services["Studio"].endpoint
Odczytaj TabularDataset
Input W obiekcie określ parametr type jako AssetTypes.MLTABLEi mode jako InputOutputModes.DIRECT:
Uwaga
Aby użyć bezserwerowych obliczeń, usuń compute="cpu-cluster", w tym kodzie.
from azure.ai.ml import command
from azure.ai.ml.entities import Data
from azure.ai.ml import Input
from azure.ai.ml.constants import AssetTypes, InputOutputModes
from azure.ai.ml import MLClient
ml_client = MLClient.from_config(credential=DefaultAzureCredential())
filedataset_asset = ml_client.data.get(name="<tabulardataset_name>", version="<version>")
my_job_inputs = {
"input_data": Input(
type=AssetTypes.MLTABLE,
path=filedataset_asset.id,
mode=InputOutputModes.DIRECT
)
}
job = command(
code="./src", # Local path where the code is stored
command="python train.py --inputs ${{inputs.input_data}}",
inputs=my_job_inputs,
environment="<environment_name>:<version>",
compute="cpu-cluster",
)
# Submit the command
returned_job = ml_client.jobs.create_or_update(job)
# Get a URL for the status of the job
returned_job.services["Studio"].endpoint
Sprzątanie
Jeśli na potrzeby tego samouczka utworzono zasoby platformy Azure, które nie są już potrzebne, usuń je, aby uniknąć ponoszenia kosztów:
Przeskaluj klaster obliczeniowy w dół do zera lub usuń go, jeśli nie jest już potrzebny:
az ml compute update --name cpu-cluster --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME> --min-instances 0Usuń wszystkie zasoby danych wyjściowych lub kontenery magazynu utworzone podczas testowania.