Ponowne tworzenie eksperymentu programu Studio (wersja klasyczna) w usłudze Azure Machine Learning
Ważne
Obsługa usługi Azure Machine Edukacja Studio (wersja klasyczna) zakończy się 31 sierpnia 2024 r. Zalecamy przejście do usługi Azure Machine Edukacja do tej daty.
Od 1 grudnia 2021 r. nie można utworzyć nowych zasobów usługi Machine Edukacja Studio (wersja klasyczna) (obszar roboczy i plan usługi internetowej). Do 31 sierpnia 2024 r. możesz nadal korzystać z istniejących eksperymentów i usług internetowych programu Machine Edukacja Studio (wersja klasyczna). Aby uzyskać więcej informacji, zobacz:
- Migrowanie do usługi Azure Machine Edukacja z usługi Machine Edukacja Studio (wersja klasyczna)
- Co to jest Azure Machine Learning?
Dokumentacja programu Machine Edukacja Studio (wersja klasyczna) jest wycofywana i może nie zostać zaktualizowana w przyszłości.
Z tego artykułu dowiesz się, jak ponownie skompilować eksperyment ML Studio (klasyczny) w usłudze Azure Machine Edukacja. Aby uzyskać więcej informacji na temat migracji z programu Studio (wersja klasyczna), zobacz artykuł omówienie migracji.
Eksperymenty programu Studio (klasyczne) są podobne do potoków w usłudze Azure Machine Edukacja. Jednak w usłudze Azure Machine potoki Edukacja są oparte na tym samym zapleczu, który obsługuje zestaw SDK. Oznacza to, że masz dwie opcje programowania uczenia maszynowego: projektant przeciągania i upuszczania lub zestawy SDK typu code-first.
Aby uzyskać więcej informacji na temat tworzenia potoków za pomocą zestawu SDK, zobacz Co to są potoki usługi Azure Machine Edukacja.
Wymagania wstępne
- Konto platformy Azure z aktywną subskrypcją. Utwórz konto bezpłatnie.
- Obszar roboczy usługi Azure Machine Learning. Tworzenie zasobów obszaru roboczego.
- Eksperyment programu Studio (wersja klasyczna) do migracji.
- Przekaż zestaw danych do usługi Azure Machine Edukacja.
Ponowne kompilowanie potoku
Po przeprowadzeniu migracji zestawu danych do usługi Azure Machine Edukacja możesz ponownie utworzyć eksperyment.
W usłudze Azure Machine Edukacja graf wizualizacji jest nazywany wersją roboczą potoku. W tej sekcji utworzysz ponownie klasyczny eksperyment jako wersję roboczą potoku.
Przejdź do usługi Azure Machine Edukacja Studio (ml.azure.com)
W okienku nawigacji po lewej stronie wybierz pozycję Projektant> Easy-to-use wstępnie utworzonych modułów
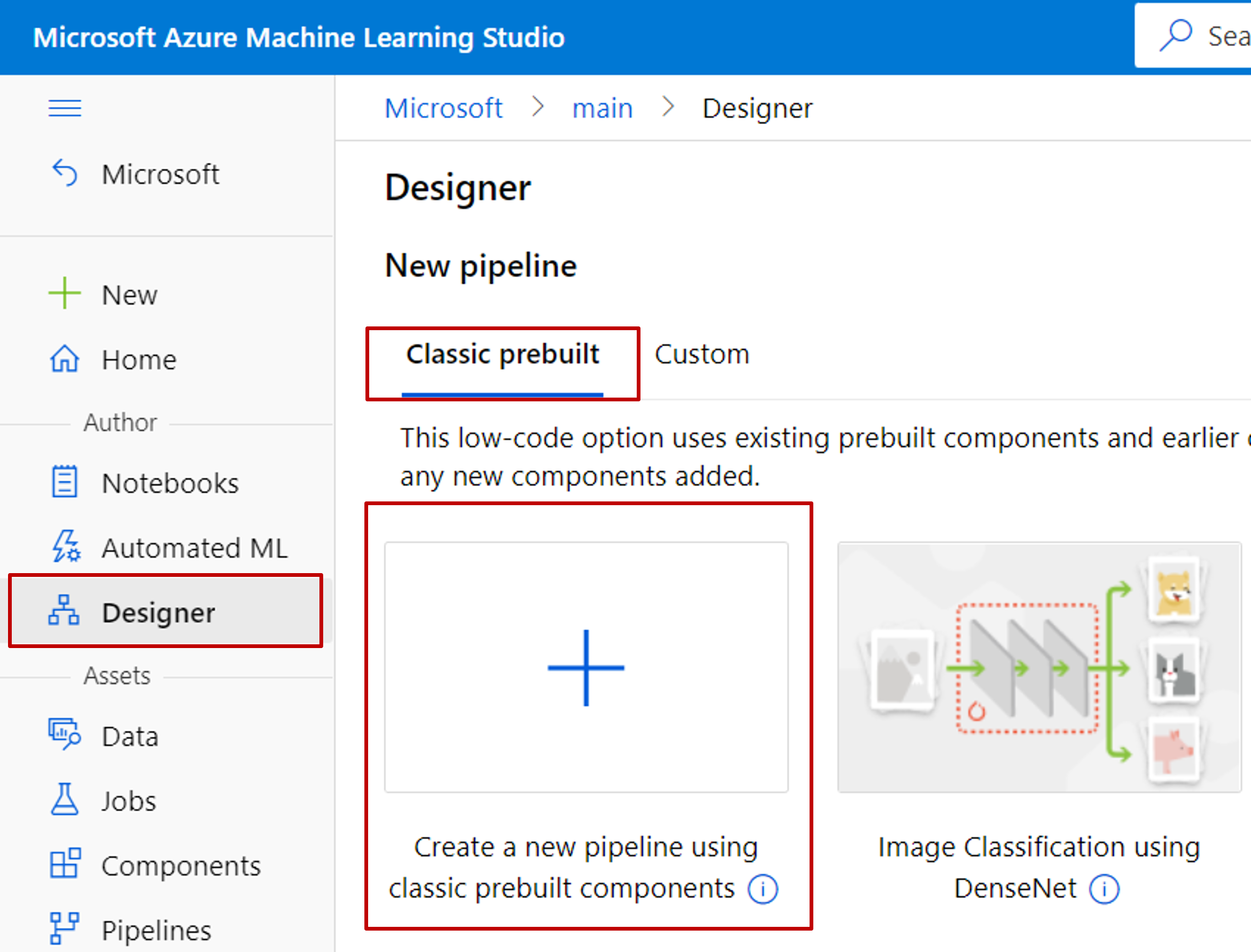
Ręcznie skompiluj eksperyment za pomocą składników projektanta.
Zapoznaj się z tabelą mapowania modułów, aby znaleźć moduły zastępcze. Wiele najpopularniejszych modułów programu Studio (klasycznych) ma identyczne wersje w projektancie.
Ważne
Jeśli eksperyment korzysta z modułu Execute R Script (Wykonywanie skryptu języka R), należy wykonać dodatkowe kroki w celu przeprowadzenia migracji eksperymentu. Aby uzyskać więcej informacji, zobacz Migrowanie modułów skryptów języka R.
Dostosuj parametry.
Wybierz każdy moduł i dostosuj parametry w panelu ustawień modułu po prawej stronie. Użyj parametrów, aby odtworzyć funkcjonalność eksperymentu programu Studio (klasycznego). Aby uzyskać więcej informacji na temat każdego modułu, zobacz dokumentację modułu.
Przesyłanie zadania i sprawdzanie wyników
Po ponownym utworzeniu eksperymentu studio (klasycznego) nadszedł czas na przesłanie zadania potoku.
Zadanie potoku jest wykonywane na docelowym obiekcie obliczeniowym dołączonym do obszaru roboczego. Można ustawić domyślny docelowy obiekt obliczeniowy dla całego potoku lub określić docelowe obiekty obliczeniowe dla poszczególnych modułów.
Po przesłaniu zadania z wersji roboczej potoku zostanie ono przekształcone w zadanie potoku. Każde zadanie potoku jest rejestrowane i rejestrowane w usłudze Azure Machine Edukacja.
Aby ustawić domyślny docelowy obiekt obliczeniowy dla całego potoku:
- Wybierz ikonę
 Koła zębatego obok nazwy potoku.
Koła zębatego obok nazwy potoku. - Wybierz pozycję Wybierz docelowy obiekt obliczeniowy.
- Wybierz istniejące zasoby obliczeniowe lub utwórz nowe środowisko obliczeniowe, postępując zgodnie z instrukcjami wyświetlanymi na ekranie.
Po ustawieniu docelowego obiektu obliczeniowego możesz przesłać zadanie potoku:
W górnej części kanwy wybierz pozycję Prześlij.
Wybierz pozycję Utwórz nowy , aby utworzyć nowy eksperyment.
Eksperymenty organizują podobne zadania potoku razem. Jeśli wielokrotnie uruchamiasz potok, możesz wybrać ten sam eksperyment dla kolejnych zadań. Jest to przydatne w przypadku rejestrowania i śledzenia.
Wprowadź nazwę eksperymentu. Następnie wybierz pozycję Prześlij.
Pierwsze zadanie może potrwać do 20 minut. Ponieważ domyślne ustawienia obliczeniowe mają minimalny rozmiar węzła wynoszący 0, projektant musi przydzielić zasoby po bezczynności. Kolejne zadania zajmują mniej czasu, ponieważ węzły są już przydzielane. Aby przyspieszyć czas działania, możesz utworzyć zasób obliczeniowy o minimalnym rozmiarze węzła wynoszącym 1 lub większy.
Po zakończeniu zadania możesz sprawdzić wyniki każdego modułu:
Kliknij prawym przyciskiem myszy moduł, którego dane wyjściowe chcesz wyświetlić.
Wybierz pozycję Visualize (Wizualizacja), View Output (Wyświetl dane wyjściowe) lub View Log (Wyświetl dziennik).
- Wizualizacja: wyświetl podgląd zestawu danych wyników.
- Wyświetl dane wyjściowe: otwórz link do wyjściowej lokalizacji magazynu. Służy do eksplorowania lub pobierania danych wyjściowych.
- Dziennik widoku: wyświetlanie dzienników sterowników i systemu. Użyj 70_driver_log, aby wyświetlić informacje dotyczące skryptu przesłanego przez użytkownika, takie jak błędy i wyjątki.
Ważne
Projektant składniki używają pakietów języka Python typu open source do implementowania algorytmów uczenia maszynowego. Jednak program Studio (wersja klasyczna) używa wewnętrznej biblioteki języka C# firmy Microsoft. W związku z tym wynik przewidywania może się różnić w zależności od projektanta i programu Studio (wersja klasyczna).
Zapisywanie wytrenowanego modelu do użycia w innym potoku
Czasami można zapisać model wytrenowany w potoku i użyć modelu w innym potoku później. W programie Studio (wersja klasyczna) wszystkie wytrenowane modele są zapisywane w kategorii "Wytrenowane modele" na liście modułów. W projektancie wytrenowane modele są automatycznie rejestrowane jako zestaw danych plików z nazwą wygenerowaną przez system. Konwencja nazewnictwa jest zgodna ze wzorcem "MD — nazwa projektu potoku — nazwa składnika — wytrenowany identyfikator modelu".
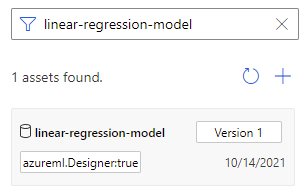
Aby nadać wytrenowanym modelowi znaczącą nazwę, możesz zarejestrować dane wyjściowe składnika Train Model jako zestaw danych plików. Nadaj mu nazwę, na przykład linear-regression-model.
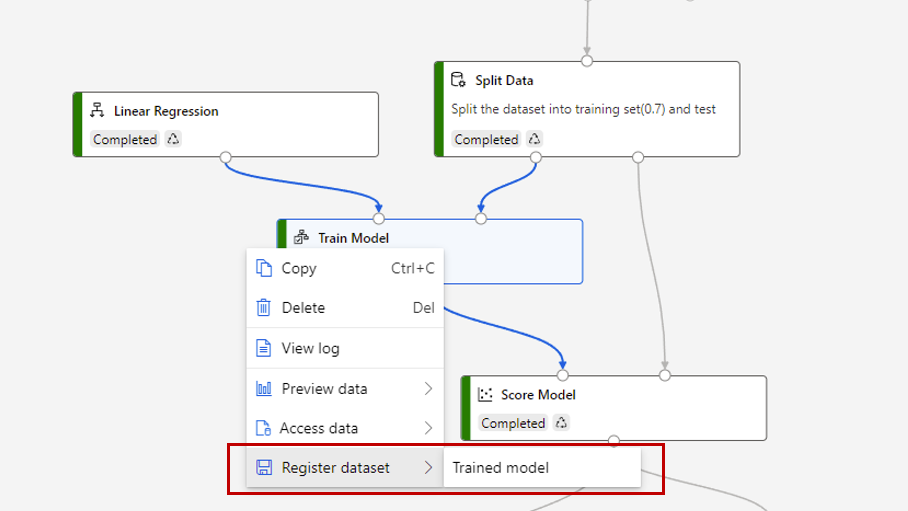
W kategorii "Zestaw danych" możesz znaleźć wytrenowany model na liście składników lub wyszukać go według nazwy. Następnie połącz wytrenowany model ze składnikiem Score Model ( Generowanie wyników dla modelu ), aby użyć go do przewidywania.
Następne kroki
W tym artykule przedstawiono sposób ponownego kompilowania eksperymentu programu Studio (klasycznego) w usłudze Azure Machine Edukacja. Następnym krokiem jest ponowne skompilowanie usług internetowych w usłudze Azure Machine Edukacja.
Zobacz inne artykuły w serii migracji programu Studio (wersja klasyczna):
- Omówienie migracji.
- Migrowanie zestawu danych.
- Ponowne kompilowanie potoku trenowania programu Studio (wersja klasyczna).
- Ponownie skompiluj usługę internetową studio (klasyczną).
- Integrowanie usługi internetowej azure Machine Edukacja z aplikacjami klienckimi.
- Migrowanie wykonywania skryptu języka R.