Dostosowywanie przepływu i metryk oceny
Przepływy oceny to specjalne typy przepływów, które oceniają, jak dobrze dane wyjściowe przebiegu są zgodne z określonymi kryteriami i celami, obliczając metryki.
W przepływie monitów możesz dostosować lub utworzyć własny przepływ oceny i metryki dostosowane do zadań i celów, a następnie użyć go do oceny innych przepływów. Ten dokument zawiera informacje:
- Omówienie oceny w przepływie monitów
- Dane wejściowe
- Dane wyjściowe i rejestrowanie metryk
- Jak opracować przepływ oceny
- Jak używać dostosowanego przepływu oceny w przebiegu wsadowym
Omówienie oceny w przepływie monitów
W przepływie monitu przepływ to sekwencja węzłów, która przetwarza dane wejściowe i generuje dane wyjściowe. Podobnie przepływy oceny mogą pobierać wymagane dane wejściowe i generować odpowiednie dane wyjściowe, które często są wynikiem lub metrykami. Koncepcje przepływów oceny są podobne do przepływów standardowych, ale istnieją pewne różnice w środowisku tworzenia i sposób ich użycia.
Oto niektóre specjalne funkcje przepływów oceny:
- Zwykle są uruchamiane po uruchomieniu do przetestowania, odbierając jego dane wyjściowe. Używa on danych wyjściowych do obliczania wyników i metryk. Dane wyjściowe przepływu oceny to wyniki, które mierzą wydajność testowanego przepływu.
- Mogą mieć węzeł agregacji, który oblicza ogólną wydajność przepływu testowanego w testowym zestawie danych.
- Mogą rejestrować metryki przy użyciu
log_metric()funkcji.
Przedstawimy sposób opracowywania metod oceny danych wejściowych i wyjściowych.
Dane wejściowe
Przepływy oceny obliczają metryki lub wyniki dla przebiegu wsadowego przepływu na podstawie zestawu danych. W tym celu muszą pobrać dane wyjściowe testowanego przebiegu. Dane wejściowe przepływu oceny można zdefiniować w taki sam sposób, jak definiowanie danych wejściowych standardowego przepływu.
Przepływ oceny jest uruchamiany po innym przebiegu, aby ocenić, jak dobrze dane wyjściowe tego przebiegu są zgodne z określonymi kryteriami i celami. W związku z tym ocena odbiera dane wyjściowe wygenerowane na podstawie tego przebiegu.
Jeśli na przykład testowany przepływ jest przepływem pytań i odpowiedzi, który generuje odpowiedzi na podstawie pytania, możesz odpowiednio podać dane wejściowe oceny jako answer. Jeśli testowany przepływ jest przepływem klasyfikacji, który klasyfikuje tekst w kategorii, możesz nazwać dane wejściowe oceny jako category.
Inne dane wejściowe, takie jak ground truth mogą być również potrzebne. Jeśli na przykład chcesz obliczyć dokładność przepływu klasyfikacji, musisz podać kolumnę category w zestawie danych jako podstawowe informacje. Jeśli chcesz obliczyć dokładność przepływu pytań i odpowiedzi, musisz podać kolumnę answer w zestawie danych jako podstawowe informacje.
Domyślnie ocena używa tego samego zestawu danych co zestaw danych testowych dostarczonych do przetestowanego przebiegu. Jeśli jednak odpowiednie etykiety lub docelowe wartości prawdy podstawowej znajdują się w innym zestawie danych, możesz łatwo przełączyć się na ten zestaw danych.
Niektóre inne dane wejściowe mogą być potrzebne do obliczenia metryk, takich jak question i context w scenariuszu QnA lub RAG. Te dane wejściowe można zdefiniować w taki sam sposób, jak definiowanie danych wejściowych standardowego przepływu.
Opis wejścia
Aby przypomnieć, jakie dane wejściowe są potrzebne do obliczenia metryk, możesz dodać opis dla każdego wymaganego danych wejściowych. Opisy są wyświetlane podczas mapowania źródeł w przesłaniu przebiegu wsadowego.

Aby dodać opisy dla poszczególnych danych wejściowych, wybierz pozycję Pokaż opis w sekcji danych wejściowych podczas opracowywania metody oceny. Możesz również wybrać pozycję "Ukryj opis", aby ukryć opis.

Następnie ten opis jest wyświetlany w przypadku korzystania z tej metody ewaluacyjnej w przesłaniu przebiegu wsadowego.
Dane wyjściowe i metryki
Dane wyjściowe oceny to wyniki, które mierzą wydajność testowanego przepływu. Dane wyjściowe zwykle zawierają metryki, takie jak wyniki, i mogą również zawierać tekst z przyczyn i sugestii.
Dane wyjściowe oceny — wyniki na poziomie wystąpienia
W przepływie monitu przepływ przetwarza jeden wiersz danych jednocześnie i generuje rekord wyjściowy. Podobnie w większości przypadków oceny istnieje wynik dla poszczególnych danych wyjściowych, co pozwala sprawdzić, jak przepływ działa na poszczególnych danych.
Przepływ oceny może obliczyć wyniki dla poszczególnych danych i zarejestrować wyniki dla każdego przykładu danych jako dane wyjściowe przepływu, ustawiając je w sekcji wyjściowej przepływu oceny. To środowisko tworzenia jest takie samo jak definiowanie standardowych danych wyjściowych przepływu.

Wyniki można wyświetlić na karcie Przegląd-dane> wyjściowe , gdy ta metoda oceny jest używana do oceny innego przepływu. Ten proces jest taki sam, jak sprawdzanie danych wyjściowych przebiegu wsadowego standardowego przepływu. Wynik na poziomie wystąpienia jest dołączany do danych wyjściowych testowanego przepływu.
Rejestrowanie metryk i węzeł agregacji
Ponadto ważne jest również, aby zapewnić ogólną ocenę przebiegu. Aby odróżnić od indywidualnego wyniku oceny poszczególnych danych wyjściowych, nazywamy wartościami oceny ogólnej wydajności przebiegu jako "metryki".
Aby obliczyć ogólną wartość oceny na podstawie każdego indywidualnego wyniku, możesz sprawdzić pozycję "Agregacja" węzła języka Python w przepływie oceny, aby przekształcić go w węzeł "redukcji", umożliwiając węzłowi przejęcie danych wejściowych jako listy i przetworzenie ich w partii.

W ten sposób można obliczyć i przetworzyć wszystkie wyniki poszczególnych danych wyjściowych przepływu i obliczyć ogólny wynik dla każdego wyniku wyjściowego oceny. Jeśli na przykład chcesz obliczyć dokładność przepływu klasyfikacji, możesz obliczyć dokładność poszczególnych danych wyjściowych oceny, a następnie obliczyć średnią dokładność wszystkich wyników wyjściowych. Następnie można rejestrować średnią dokładność jako metrykę przy użyciu promptflow_sdk.log_metrics(). Metryki powinny być liczbowe (float/int). Rejestrowanie metryk typu ciągu nie jest obsługiwane.
Poniższy fragment kodu jest przykładem obliczania ogólnej dokładności przez uśrednianie wyniku dokładności (grade) poszczególnych danych. Ogólna dokładność jest rejestrowana jako metryka przy użyciu promptflow_sdk.log_metrics().
from typing import List
from promptflow import tool, log_metric
@tool
def calculate_accuracy(grades: List[str]): # Receive a list of grades from a previous node
# calculate accuracy
accuracy = round((grades.count("Correct") / len(grades)), 2)
log_metric("accuracy", accuracy)
return accuracy
Po wywołaniu tej funkcji w węźle języka Python nie musisz przypisywać jej nigdzie indziej i później można wyświetlić metryki. Gdy ta metoda oceny jest używana w przebiegu wsadowym, metryki wskazujące ogólną wydajność można wyświetlić na karcie Przegląd-metryki>.

Rozpoczynanie opracowywania metody oceny
Istnieją dwa sposoby tworzenia własnych metod oceny:
- Utwórz nowy przepływ oceny od podstaw: utwórz zupełnie nową metodę oceny od podstaw. Na stronie głównej karty przepływu monitu w sekcji "Utwórz według typu" możesz wybrać pozycję "Przepływ oceny" i wyświetlić szablon przepływu oceny.

- Dostosowywanie wbudowanego przepływu oceny: Zmodyfikuj wbudowany przepływ oceny. Znajdź wbudowany przepływ oceny z poziomu kreatora tworzenia przepływu — galeria przepływów, wybierz pozycję "Klonuj", aby wykonać dostosowywanie. Następnie możesz zobaczyć i sprawdzić logikę i przepływ wbudowanych ocen, a następnie zmodyfikować przepływ. W ten sposób nie zaczynasz od samego początku, ale przykład, którego chcesz użyć do dostosowania.

Obliczanie wyników dla poszczególnych danych
Jak wspomniano, ocena jest uruchamiana w celu obliczenia wyników i metryk na podstawie przepływu uruchamianego w zestawie danych. W związku z tym pierwszym krokiem w przepływach oceny jest obliczanie wyników dla poszczególnych danych wyjściowych.
Weźmy wbudowany przepływ oceny jako przykładowy wynik Classification Accuracy Evaluation grade, który mierzy dokładność każdego wygenerowanego przepływu danych wyjściowych do odpowiadającej jej podstawowej prawdy, jest obliczana w węźle grade . Jeśli utworzysz przepływ oceny i zmodyfikujesz go od podstaw podczas tworzenia według typu, ten wynik zostanie obliczony w line_process węźle w szablonie. Możesz również zastąpić line_process węzeł języka Python węzłem LLM, aby użyć usługi LLM do obliczenia wyniku lub użyć wielu węzłów do wykonania obliczeń.

Następnie należy określić dane wyjściowe węzłów jako dane wyjściowe przepływu oceny, co wskazuje, że dane wyjściowe są wynikiem obliczanym dla każdej próbki danych. Możesz również użyć rozumowania wyjściowego jako dodatkowych informacji i jest to takie samo środowisko podczas definiowania danych wyjściowych w standardowym przepływie.
Obliczanie i rejestrowanie metryk
Drugim krokiem oceny jest obliczenie ogólnych metryk w celu oceny przebiegu. Jak wspomniano, metryki są obliczane w węźle języka Python ustawionym jako Aggregation. Ten węzeł przyjmuje wyniki obliczone w poprzednim węźle i organizuje wynik każdego przykładu danych na liście, a następnie oblicza je razem naraz.
Jeśli tworzysz i edytujesz od podstaw podczas tworzenia według typu, ten wynik jest obliczany w węźle aggregate . Fragment kodu jest szablonem węzła agregacji.
from typing import List
from promptflow import tool
@tool
def aggregate(processed_results: List[str]):
"""
This tool aggregates the processed result of all lines and log metric.
:param processed_results: List of the output of line_process node.
"""
# Add your aggregation logic here
aggregated_results = {}
# Log metric
# from promptflow import log_metric
# log_metric(key="<my-metric-name>", value=aggregated_results["<my-metric-name>"])
return aggregated_results
Możesz użyć własnej logiki agregacji, takiej jak obliczanie średniej, średniej wartości lub odchylenie standardowe wyników.
Następnie należy zarejestrować metryki za pomocą promptflow.logmetrics() funkcji. W jednym przepływie oceny można rejestrować wiele metryk. Metryki powinny być liczbowe (float/int).
Korzystanie z dostosowanego przepływu oceny
Po utworzeniu własnego przepływu i metryk oceny możesz użyć tego przepływu, aby ocenić wydajność standardowego przepływu.
Najpierw zacznij od strony tworzenia przepływu, na której chcesz ocenić. Na przykład przepływ pytań i odpowiedzi, z którym wiesz, jak działa na dużym zestawie danych i chcesz go przetestować. Kliknij
Evaluateprzycisk i wybierz pozycjęCustom evaluation.
Następnie, podobnie jak w krokach przesyłania przebiegu wsadowego, jak wspomniano w temacie Submit batch run (Przesyłanie przebiegu wsadowego) i oceń przepływ w przepływie monitu, wykonaj kilka pierwszych kroków, aby przygotować zestaw danych do uruchomienia przepływu.
Następnie w
Evaluation settings - Select evaluationkroku, wraz z wbudowanymi ocenami, dostosowane oceny są również dostępne do wyboru. Spowoduje to wyświetlenie listy wszystkich przepływów oceny utworzonych, sklonowanych lub dostosowanych. Przepływy ewaluacyjne utworzone przez inne osoby w tym samym projekcie nie będą wyświetlane w tej sekcji.
Następnie w
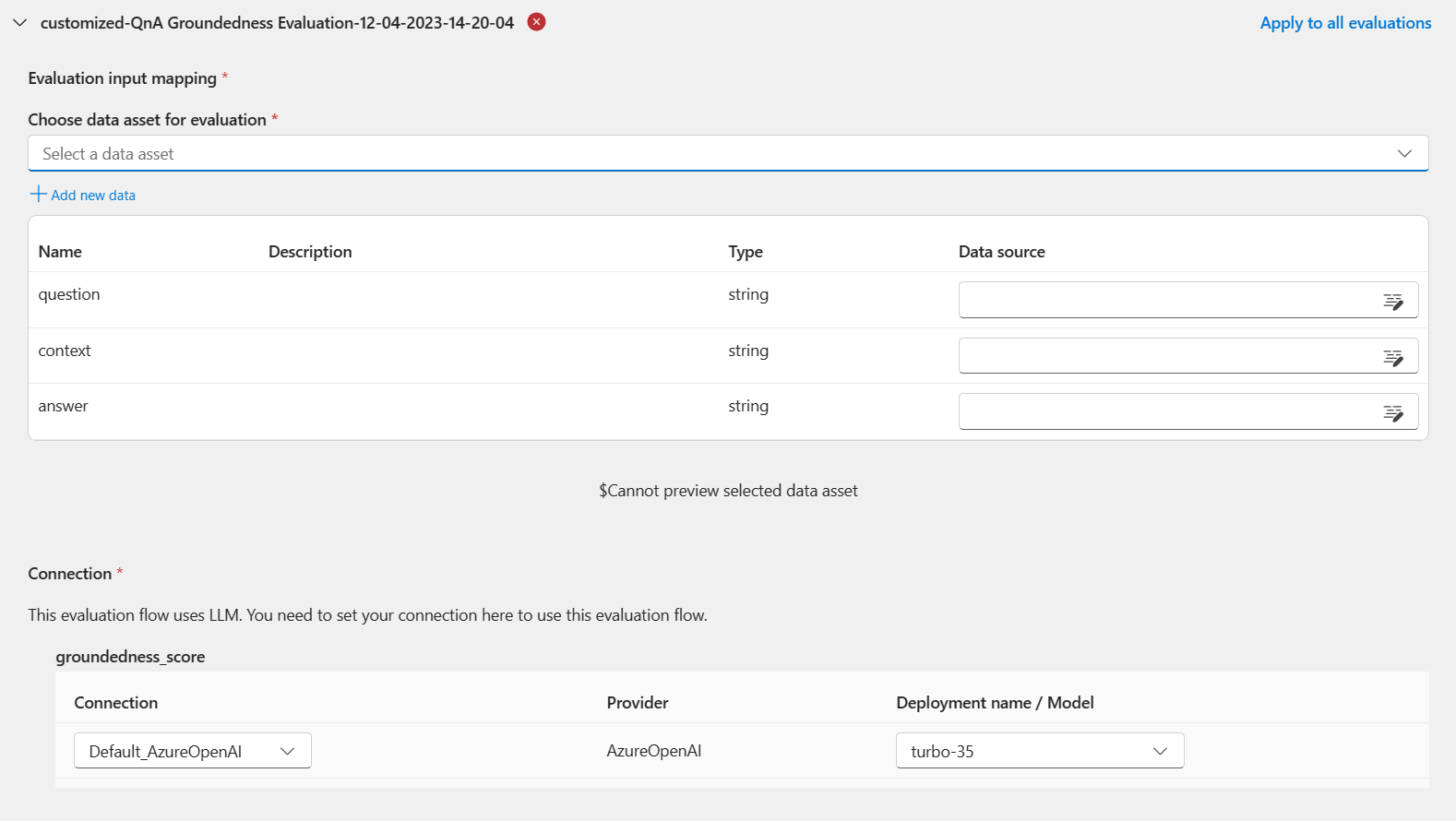
Evaluation settings - Configure evaluationkroku należy określić źródła danych wejściowych, które są wymagane dla metody oceny. Na przykład kolumna podstawowej prawdy może pochodzić z zestawu danych.Aby uruchomić ocenę, możesz wskazać źródła tych wymaganych danych wejściowych w sekcji "mapowanie danych wejściowych" podczas przesyłania oceny. Ten proces jest taki sam jak konfiguracja wymieniona w temacie Przesyłanie przebiegu wsadowego i ocena przepływu w przepływie monitu.
- Jeśli źródło danych pochodzi z danych wyjściowych przebiegu, źródło jest wskazane jako
${run.output.[OutputName]} - Jeśli źródło danych pochodzi z testowego zestawu danych, źródło jest wskazywane jako
${data.[ColumnName]}
Uwaga
Jeśli ocena nie wymaga danych z zestawu danych, nie musisz odwoływać się do żadnych kolumn zestawu danych w sekcji mapowania danych wejściowych, co wskazuje, że wybór zestawu danych jest opcjonalną konfiguracją. Wybór zestawu danych nie wpłynie na wynik oceny.
- Jeśli źródło danych pochodzi z danych wyjściowych przebiegu, źródło jest wskazane jako
Gdy ta metoda oceny jest używana do oceny innego przepływu, wynik na poziomie wystąpienia można wyświetlić na karcie Przegląd ->Dane wyjściowe .





Następne kroki
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla