Wskazówki dotyczące rozwiązywania problemów
Ten artykuł zawiera często zadawane pytania dotyczące użycia przepływu monitów.
Problemy związane z tworzeniem przepływu
Błąd „Narzędzie pakietu nie zostanie znaleziony” podczas aktualizowania przepływu dla środowiska code-first
W przypadku aktualizowania przepływów dla środowiska opartego na kodzie, jeśli przepływ korzysta z wyszukiwania indeksu Faiss, wyszukiwania indeksu wektorowego, wyszukiwania wektorów bazy danych lub narzędzi bezpieczeństwa zawartości (tekst) może wystąpić następujący komunikat o błędzie:
Package tool 'embeddingstore.tool.faiss_index_lookup.search' is not found in the current environment.
Aby rozwiązać ten problem, masz dwie opcje:
Opcja 1
Zaktualizuj sesję obliczeniową do najnowszej wersji obrazu podstawowego.
Wybierz pozycję Tryb nieprzetworzonego pliku, aby przełączyć się do widoku nieprzetworzonego kodu. Następnie otwórz plik flow.dag.yaml .

Zaktualizuj nazwy narzędzi.
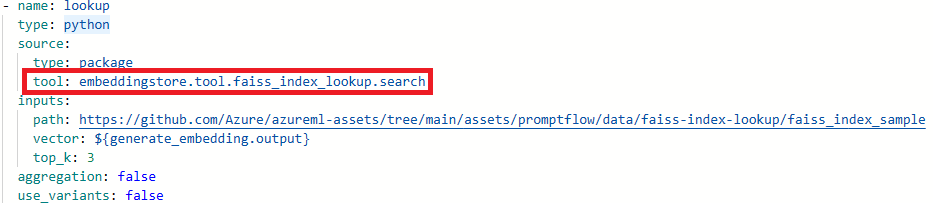
Narzędzie Nowa nazwa narzędzia Wyszukiwanie indeksu Faiss promptflow_vectordb.tool.faiss_index_lookup. FaissIndexLookup.search Wyszukiwanie indeksu wektorowego promptflow_vectordb.tool.vector_index_lookup. VectorIndexLookup.search Wyszukiwanie wektorowej bazy danych promptflow_vectordb.tool.vector_db_lookup. VectorDBLookup.search Bezpieczeństwo zawartości (tekst) content_safety_text.tools.content_safety_text_tool.analyze_text Zapisz plik flow.dag.yaml.
Opcja 2
- Aktualizowanie sesji obliczeniowej do najnowszej wersji obrazu podstawowego
- Usuń stare narzędzie i ponownie utwórz nowe narzędzie.
Błąd „Nie ma takiego pliku lub katalogu”
Przepływ monitów opiera się na magazynie udziałów plików do przechowywania migawki przepływu. Jeśli magazyn udziałów plików ma problem, może wystąpić następujący problem. Oto kilka obejść, które można wypróbować:
Jeśli używasz prywatnego konta magazynu, zobacz Izolacja sieci w przepływie monitu, aby upewnić się, że obszar roboczy ma dostęp do konta magazynu.
Jeśli konto magazynu jest włączone na potrzeby dostępu publicznego, sprawdź, czy w obszarze roboczym znajduje się magazyn danych o nazwie
workspaceworkingdirectory. Powinien to być typ udziału plików.
- Jeśli nie masz tego magazynu danych, musisz dodać go do obszaru roboczego.
- Utwórz udział plików o nazwie
code-391ff5ac-6576-460f-ba4d-7e03433c68b6. - Utwórz magazyn danych o nazwie
workspaceworkingdirectory. Zobacz Tworzenie magazynów danych.
- Utwórz udział plików o nazwie
- Jeśli masz magazyn danych,
workspaceworkingdirectoryale jego typ toblobzamiastfileshare, utwórz nowy obszar roboczy. Użyj magazynu, który nie włącza hierarchicznych przestrzeni nazw dla usługi Azure Data Lake Storage Gen2 jako domyślnego konta magazynu obszaru roboczego. Aby uzyskać więcej informacji, zobacz Tworzenie obszaru roboczego.
- Jeśli nie masz tego magazynu danych, musisz dodać go do obszaru roboczego.

Brak przepływu

Istnieją możliwe przyczyny tego problemu:
Jeśli dostęp publiczny do konta magazynu jest wyłączony, musisz zapewnić dostęp przez dodanie adresu IP do zapory magazynu lub włączenie dostępu za pośrednictwem sieci wirtualnej, która ma prywatny punkt końcowy połączony z kontem magazynu.

W niektórych przypadkach klucz konta w magazynie danych nie jest zsynchronizowany z kontem magazynu. Aby rozwiązać ten problem, możesz spróbować zaktualizować klucz konta na stronie szczegółów magazynu danych.

Jeśli używasz programu AI Studio, konto magazynu musi ustawić mechanizm CORS, aby zezwolić programowi AI Studio na dostęp do konta magazynu, w przeciwnym razie zobaczysz brak problemu z przepływem. Aby rozwiązać ten problem, możesz dodać następujące ustawienia mechanizmu CORS do konta magazynu.
- Przejdź do strony konta magazynu, wybierz w obszarze
settings, a następnie wybierzResource sharing (CORS)File servicekartę. - Dozwolone źródła:
https://mlworkspace.azure.ai,https://ml.azure.com,https://*.ml.azure.com,https://ai.azure.com,https://*.ai.azure.com,https://mlworkspacecanary.azure.ai,https://mlworkspace.azureml-test.net - Dozwolone metody:
DELETE, GET, HEAD, POST, OPTIONS, PUT

- Przejdź do strony konta magazynu, wybierz w obszarze



Problemy związane z sesją obliczeniową
Uruchomienie nie powiodło się z powodu błędu „Brak modułu o nazwie XXX”
Ten typ błędu związany z sesją obliczeniową nie zawiera wymaganych pakietów. Jeśli używasz środowiska domyślnego, upewnij się, że obraz sesji obliczeniowej używa najnowszej wersji. Jeśli używasz niestandardowego obrazu podstawowego, upewnij się, że zainstalowano wszystkie wymagane pakiety w kontekście platformy Docker. Aby uzyskać więcej informacji, zobacz Dostosowywanie obrazu podstawowego na potrzeby sesji obliczeniowej.
Gdzie znaleźć wystąpienie bezserwerowe używane przez sesję obliczeniową?
Wystąpienie bezserwerowe używane przez sesję obliczeniową można wyświetlić na karcie listy sesji obliczeniowej na stronie obliczeniowej. Dowiedz się więcej na temat zarządzania wystąpieniem bezserwerowymi.
Błędy sesji obliczeniowej przy użyciu niestandardowego obrazu podstawowego
Niepowodzenie rozpoczęcia sesji obliczeniowej z requirements.txt lub niestandardowym obrazem podstawowym
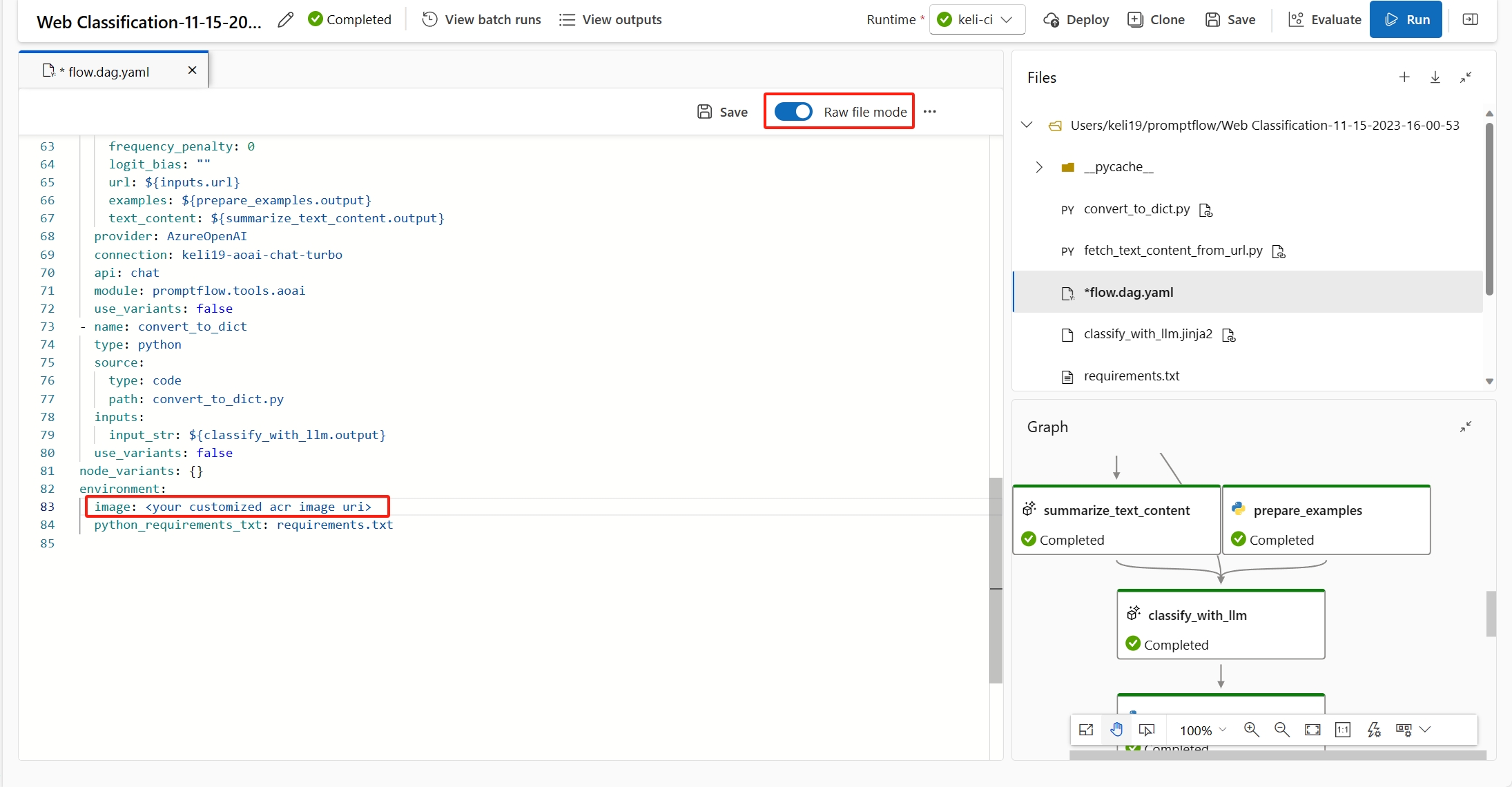
Obsługa sesji obliczeniowej do użycia requirements.txt lub niestandardowego obrazu podstawowego w programie w flow.dag.yaml celu dostosowania obrazu. Zalecamy użycie w requirements.txt przypadku typowych przypadków, które będą używane pip install -r requirements.txt do instalowania pakietów. Jeśli masz zależność więcej niż pakiety języka Python, musisz wykonać czynności opisane w sekcji Dostosowywanie obrazu podstawowego, aby utworzyć nową bazę obrazów na podstawie obrazu podstawowego przepływu monitu. Następnie użyj go w pliku flow.dag.yaml. Dowiedz się więcej na temat określania obrazu podstawowego w sesji obliczeniowej.
- Do utworzenia sesji obliczeniowej nie można użyć dowolnego obrazu podstawowego. Należy użyć obrazu podstawowego podanego przez przepływ monitu.
- Nie przypinaj wersji elementu
promptflowipromptflow-toolswrequirements.txtpliku , ponieważ uwzględniamy je już w obrazie podstawowym. Używanie starej wersji elementupromptflowipromptflow-toolsmoże spowodować nieoczekiwane zachowanie.
Problemy związane z uruchamianiem przepływu
Jak znaleźć nieprzetworzone dane wejściowe i wyjściowe narzędzia LLM w celu dalszego zbadania?
W przepływie monitu na stronie przepływu z pomyślnym uruchomieniem i stroną szczegółów przebiegu można znaleźć nieprzetworzone dane wejściowe i wyjściowe narzędzia LLM w sekcji danych wyjściowych. Wybierz przycisk, view full output aby wyświetlić pełne dane wyjściowe.

Trace sekcja zawiera każde żądanie i odpowiedź na narzędzie LLM. Możesz sprawdzić nieprzetworzone komunikaty wysyłane do modelu LLM i nieprzetworzone odpowiedzi z modelu LLM.

Jak naprawić błąd 409 z usługi Azure OpenAI?
Może wystąpić błąd 409 z usługi Azure OpenAI, oznacza to, że osiągnięto limit szybkości usługi Azure OpenAI. Komunikat o błędzie można sprawdzić w sekcji danych wyjściowych węzła LLM. Dowiedz się więcej na temat limitu szybkości usługi Azure OpenAI.

Określanie, który węzeł zużywa najwięcej czasu
Sprawdź dzienniki sesji obliczeniowej.
Spróbuj znaleźć następujący format dziennika ostrzegawczego:
Program {node_name} został uruchomiony przez {duration} sekundy.
Na przykład:
Przypadek 1. Węzeł skryptu języka Python jest uruchamiany przez długi czas.

W tym przypadku można znaleźć, że
PythonScriptNodedziałało przez długi czas (prawie 300 sekund). Następnie możesz sprawdzić szczegóły węzła, aby zobaczyć, co to jest problem.Przypadek 2. Węzeł LLM jest uruchamiany przez długi czas.
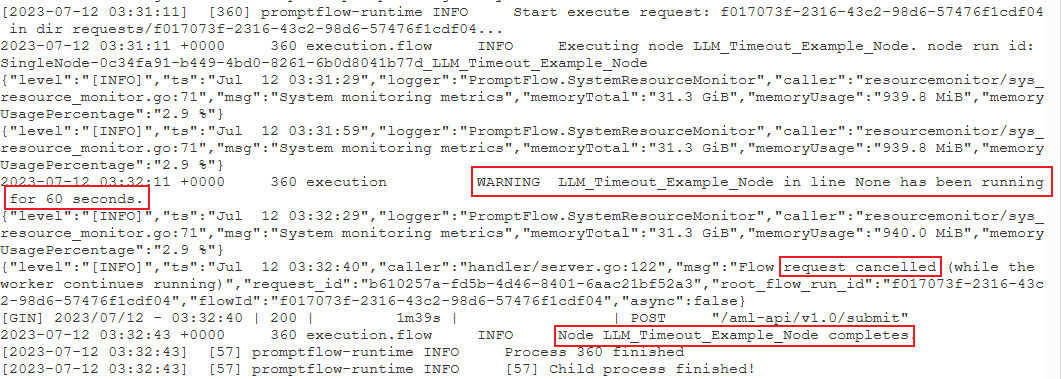
W takim przypadku, jeśli znajdziesz komunikat
request canceledw dziennikach, może to być spowodowane zbyt długim czasem wywołania interfejsu API openAI i przekroczeniem limitu czasu.Przekroczenie limitu czasu interfejsu API openAI może być spowodowane problemem z siecią lub złożonym żądaniem, które wymaga więcej czasu przetwarzania. Aby uzyskać więcej informacji, zobacz Limit czasu interfejsu API interfejsu OpenAI.
Zaczekaj kilka sekund i spróbuj ponownie wysłać żądanie. Ta akcja zwykle rozwiązuje wszelkie problemy z siecią.
Jeśli ponawianie nie działa, sprawdź, czy używasz długiego modelu kontekstu, takiego jak
gpt-4-32k, i ustaw dużą wartość dla elementumax_tokens. Jeśli tak, zachowanie jest oczekiwane, ponieważ monit może wygenerować długą odpowiedź, która trwa dłużej niż górny próg trybu interaktywnego. W takiej sytuacji zalecamy wypróbowanieBulk test, ponieważ ten tryb nie ma ustawienia limitu czasu.
Jeśli nie możesz znaleźć niczego w dziennikach, aby wskazać, że jest to konkretny problem z węzłem:
- Skontaktuj się z zespołem przepływu monitów (promptflow-eng) przy użyciu dzienników. Staramy się zidentyfikować główną przyczynę.


Problemy związane z wdrażaniem usługi Flow
Brak autoryzacji do wykonania akcji "Microsoft.MachineLearningService/workspaces/datastores/read"
Jeśli przepływ zawiera narzędzie wyszukiwania indeksów, po wdrożeniu przepływu punkt końcowy musi uzyskać dostęp do magazynu danych obszaru roboczego, aby odczytać plik YAML MLIndex lub folder FAISS zawierający fragmenty i osadzanie. W związku z tym należy ręcznie przyznać temu uprawnienie tożsamości punktu końcowego.
Tożsamość punktu końcowego można przyznać badacze dancyh AzureML w zakresie obszaru roboczego lub rolę niestandardową zawierającą akcję "MachineLearningService/workspace/datastore/reader".
Problem z przekroczeniem limitu czasu żądania nadrzędnego podczas korzystania z punktu końcowego
Jeśli używasz interfejsu wiersza polecenia lub zestawu SDK do wdrożenia przepływu, może wystąpić błąd przekroczenia limitu czasu. Domyślnie wartość to request_timeout_ms 5000. Można określić maksymalnie 5 minut, czyli 300 000 ms. Poniżej przedstawiono przykład pokazujący, jak określić limit czasu żądania w pliku yaml wdrożenia. Aby dowiedzieć się więcej, zobacz schemat wdrażania.
request_settings:
request_timeout_ms: 300000
Interfejs API interfejsu OpenAI osiąga błąd uwierzytelniania
Jeśli ponownie wygenerowano klucz usługi Azure OpenAI i ręcznie zaktualizujesz połączenie używane w przepływie monitu, mogą wystąpić błędy takie jak "Brak autoryzacji. Brak tokenu dostępu, nieprawidłowy, odbiorcy są niepoprawni lub wygasły". Podczas wywoływania istniejącego punktu końcowego utworzonego przed ponownego wygenerowania klucza.
Dzieje się tak, ponieważ połączenia używane w punktach końcowych/wdrożeniach nie zostaną automatycznie zaktualizowane. Każda zmiana klucza lub wpisów tajnych we wdrożeniach powinna być wykonywana przez ręczną aktualizację, która ma na celu uniknięcie wpływu na wdrożenie produkcyjne online z powodu niezamierzonej operacji offline.
- Jeśli punkt końcowy został wdrożony w interfejsie użytkownika programu Studio, wystarczy ponownie wdrożyć przepływ do istniejącego punktu końcowego przy użyciu tej samej nazwy wdrożenia.
- Jeśli punkt końcowy został wdrożony przy użyciu zestawu SDK lub interfejsu wiersza polecenia, musisz wprowadzić pewne modyfikacje definicji wdrożenia, takie jak dodanie fikcyjnej zmiennej środowiskowej, a następnie użyć jej
az ml online-deployment updatedo zaktualizowania wdrożenia.
Problemy z lukami w zabezpieczeniach we wdrożeniach przepływu monitów
W przypadku luk w zabezpieczeniach związanych z środowiskiem uruchomieniowym przepływu monitów poniżej przedstawiono następujące podejścia, które mogą pomóc w ograniczeniu ryzyka:
- Zaktualizuj pakiety zależności w requirements.txt w folderze przepływu.
- Jeśli używasz dostosowanego obrazu podstawowego dla przepływu, musisz zaktualizować środowisko uruchomieniowe przepływu monitów do najnowszej wersji i ponownie skompilować obraz podstawowy, a następnie ponownie wdrożyć przepływ.
W przypadku innych luk w zabezpieczeniach zarządzanych wdrożeń online usługa Azure Machine Learning rozwiązuje problemy w miesięczny sposób.
"MissingDriverProgram Error" lub "Nie można odnaleźć programu sterownika w żądaniu"
Jeśli wdrożysz przepływ i wystąpi następujący błąd, może to być związane ze środowiskiem wdrażania.
'error':
{
'code': 'BadRequest',
'message': 'The request is invalid.',
'details':
{'code': 'MissingDriverProgram',
'message': 'Could not find driver program in the request.',
'details': [],
'additionalInfo': []
}
}
Could not find driver program in the request
Istnieją dwa sposoby naprawienia tego błędu.
(Zalecane) Identyfikator URI obrazu kontenera można znaleźć na stronie szczegółów środowiska niestandardowego i ustawić go jako obraz podstawowy przepływu w pliku flow.dag.yaml. Podczas wdrażania przepływu w interfejsie użytkownika wystarczy wybrać pozycję Użyj środowiska bieżącej definicji przepływu, a usługa zaplecza utworzy dostosowane środowisko na podstawie tego obrazu podstawowego i
requirement.txtwdrożenia. Dowiedz się więcej o środowisku określonym w definicji przepływu.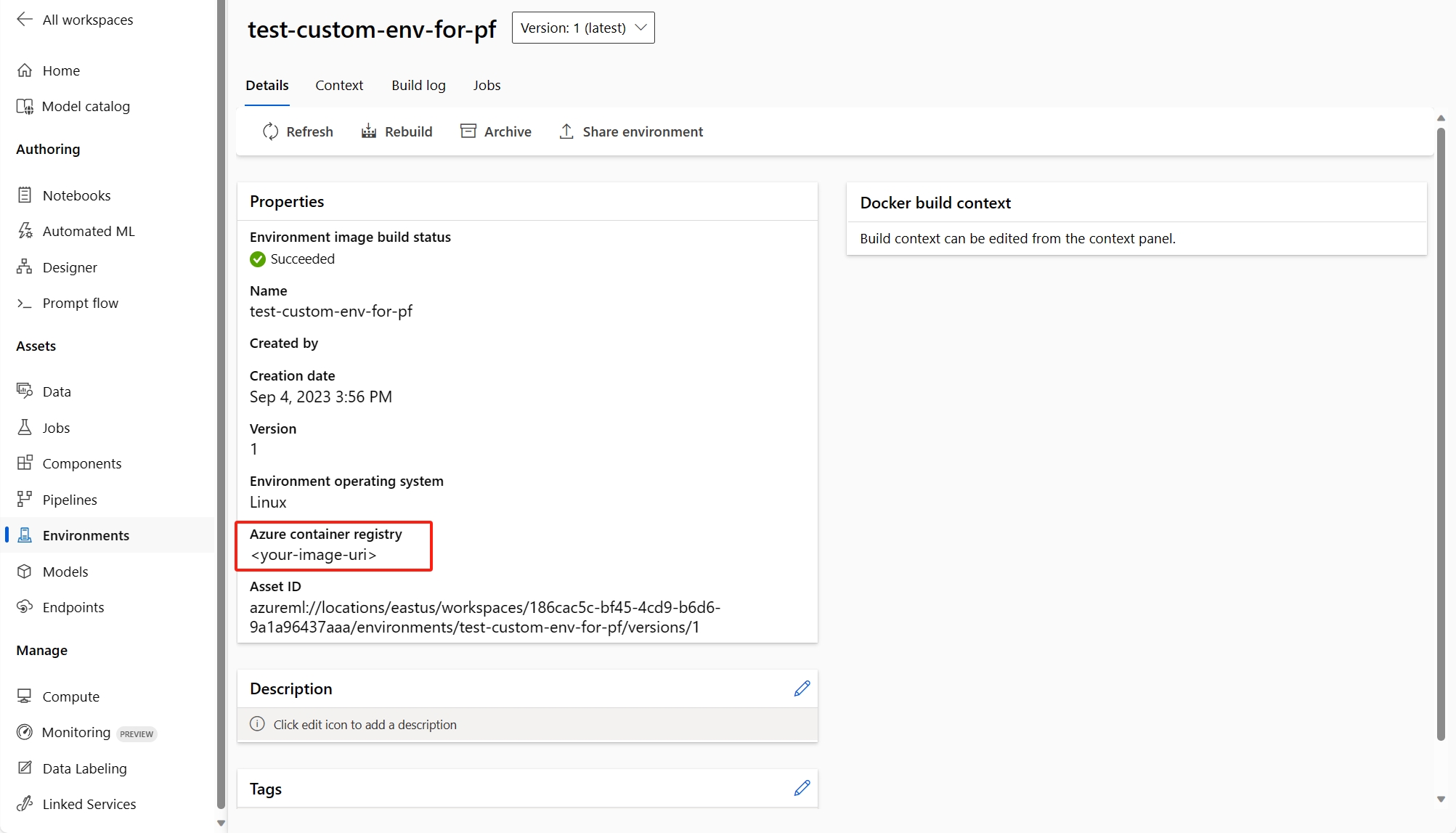
Ten błąd można naprawić, dodając
inference_configdefinicję środowiska niestandardowego.Poniżej przedstawiono przykład dostosowanej definicji środowiska.


$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: pf-customized-test
build:
path: ./image_build
dockerfile_path: Dockerfile
description: promptflow customized runtime
inference_config:
liveness_route:
port: 8080
path: /health
readiness_route:
port: 8080
path: /health
scoring_route:
port: 8080
path: /score
Odpowiedź modelu trwa zbyt długo
Czasami może się okazać, że reagowanie na wdrożenie trwa zbyt długo. Istnieje kilka potencjalnych czynników, które mogą wystąpić.
- Model używany w przepływie nie jest wystarczająco zaawansowany (na przykład: użyj biblioteki GPT 3.5 zamiast text-ada)
- Zapytanie indeksu nie jest zoptymalizowane i trwa zbyt długo
- Przepływ ma wiele kroków do przetworzenia
Rozważ optymalizację punktu końcowego z powyższymi zagadnieniami, aby zwiększyć wydajność modelu.
Nie można pobrać schematu wdrożenia
Po wdrożeniu punktu końcowego i przetestowaniu go na karcie Test na stronie szczegółów punktu końcowego, jeśli na karcie Test jest wyświetlany schemat nie można pobrać wdrożenia, możesz wypróbować następujące dwie metody, aby rozwiązać ten problem:

- Upewnij się, że udzielono poprawnego uprawnienia do tożsamości punktu końcowego. Dowiedz się więcej na temat udzielania uprawnień do tożsamości punktu końcowego.
- Może to być spowodowane tym, że przepływ został uruchomiony w starym środowisku uruchomieniowym wersji, a następnie wdrożono przepływ, wdrożenie używało również środowiska uruchomieniowego, które było w starej wersji. Aby zaktualizować środowisko uruchomieniowe, postępuj zgodnie z instrukcjami Aktualizowanie środowiska uruchomieniowego w interfejsie użytkownika i ponownie uruchom przepływ w najnowszym środowisku uruchomieniowym, a następnie ponownie wdróż przepływ.
Odmowa dostępu do listy wpisów tajnych obszaru roboczego
Jeśli wystąpi błąd, taki jak "Odmowa dostępu do wyświetlania listy wpisów tajnych obszaru roboczego", sprawdź, czy udzielono poprawnego uprawnienia do tożsamości punktu końcowego. Dowiedz się więcej na temat udzielania uprawnień do tożsamości punktu końcowego.
Problemy związane z uwierzytelnianiem i tożsamościami
Jak mogę używać magazynu danych bez poświadczeń w przepływie monitu?
Aby użyć magazynu bez poświadczeń w usłudze Azure AI Studio. W zasadzie należy wykonać następujące czynności:
- Zmień typ uwierzytelniania magazynu danych na Brak.
- Udziel tożsamości usługi zarządzanej projektu i uprawnienia współautora danych obiektu blob/pliku użytkownika w magazynie.
Zmień typ uwierzytelniania magazynu danych na Brak
Aby zmniejszyć poświadczenia magazynu danych, możesz postępować zgodnie z uwierzytelnianiem danych opartym na tożsamościach.
Musisz zmienić typ uwierzytelniania magazynu danych na Brak, co oznacza uwierzytelnianie oparte na meid_token. Możesz wprowadzić zmiany ze strony szczegółów magazynu danych lub interfejsu wiersza polecenia/zestawu SDK: https://github.com/Azure/azureml-examples/tree/main/cli/resources/datastore

W przypadku magazynu danych opartego na obiektach blob można zmienić typ uwierzytelniania, a także włączyć tożsamość usługi zarządzanej obszaru roboczego w celu uzyskania dostępu do konta magazynu.

W przypadku magazynu danych opartego na udziale plików można zmienić tylko typ uwierzytelniania.

Udzielanie uprawnień tożsamości użytkownika lub tożsamości zarządzanej
Aby użyć magazynu danych bez poświadczeń w przepływie monitu, musisz przyznać wystarczające uprawnienia tożsamości użytkownika lub tożsamości zarządzanej w celu uzyskania dostępu do magazynu danych.
- Upewnij się, że tożsamość zarządzana przypisana przez system obszaru roboczego ma
Storage Blob Data ContributoriStorage File Data Privileged Contributorna koncie magazynu, co najmniej wymaga uprawnień do odczytu/zapisu (lepiej również uwzględnić usuwanie). - Jeśli używasz tożsamości użytkownika tej opcji domyślnej w przepływie monitów, upewnij się, że tożsamość użytkownika ma następującą rolę na koncie magazynu:
Storage Blob Data Contributorna koncie magazynu co najmniej potrzebujesz uprawnień do odczytu/zapisu (lepiej również uwzględnić usuwanie).Storage File Data Privileged Contributorna koncie magazynu co najmniej potrzebujesz uprawnień do odczytu/zapisu (lepiej również uwzględnić usuwanie).
- Jeśli używasz tożsamości zarządzanej przypisanej przez użytkownika, upewnij się, że tożsamość zarządzana ma następującą rolę na koncie magazynu:
Storage Blob Data Contributorna koncie magazynu co najmniej potrzebujesz uprawnień do odczytu/zapisu (lepiej również uwzględnić usuwanie).Storage File Data Privileged Contributorna koncie magazynu co najmniej potrzebujesz uprawnień do odczytu/zapisu (lepiej również uwzględnić usuwanie).- W międzyczasie musisz przynajmniej przypisać rolę tożsamości
Storage Blob Data Readużytkownika do konta magazynu, jeśli chcesz użyć przepływu monitu do tworzenia i testowania przepływu.
- Jeśli nadal nie możesz wyświetlić strony szczegółów przepływu i przy pierwszym użyciu przepływu monitu jest wcześniejsza niż 2024-01-01, musisz udzielić tożsamości usługi zarządzanej obszaru roboczego jako
Storage Table Data Contributorkonta magazynu połączonego z obszarem roboczym.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla