Przykładowe potoki i zestawy danych dla projektanta usługi Azure Machine Learning
Skorzystaj z wbudowanych przykładów w projektancie usługi Azure Machine Learning, aby szybko rozpocząć tworzenie własnych potoków uczenia maszynowego. Repozytorium GitHub projektanta usługi Azure Machine Learning zawiera szczegółową dokumentację, która ułatwia zrozumienie typowych scenariuszy uczenia maszynowego.
Wymagania wstępne
- Subskrypcja platformy Azure. Jeśli nie masz subskrypcji platformy Azure, utwórz bezpłatne konto
- Obszar roboczy usługi Azure Machine Learning
Ważne
Jeśli nie widzisz elementów graficznych wymienionych w tym dokumencie, takich jak przyciski w studio lub projektancie, być może nie masz odpowiedniego poziomu uprawnień do obszaru roboczego. Skontaktuj się z administratorem subskrypcji platformy Azure, aby sprawdzić, czy udzielono Ci poprawnego poziomu dostępu. Aby uzyskać więcej informacji, zobacz Zarządzanie użytkownikami i rolami.
Korzystanie z przykładowych potoków
Projektant zapisuje kopię przykładowych potoków w obszarze roboczym programu Studio. Potok można edytować, aby dostosować go do własnych potrzeb i zapisać go jako własny. Użyj ich jako punktu początkowego, aby rozpocząć tworzenie projektów.
Oto jak używać przykładu projektanta:
Zaloguj się do ml.azure.com i wybierz obszar roboczy, z którym chcesz pracować.
Wybierz opcję Konstruktor.
Wybierz przykładowy potok w sekcji Nowy potok .
Wybierz pozycję Pokaż więcej przykładów, aby uzyskać pełną listę przykładów .
Aby uruchomić potok, najpierw należy ustawić domyślny docelowy obiekt obliczeniowy, aby uruchomić potok.
W okienku Ustawienia po prawej stronie kanwy wybierz pozycję Wybierz docelowy obiekt obliczeniowy.
W wyświetlonym oknie dialogowym wybierz istniejący docelowy obiekt obliczeniowy lub utwórz nowy. Wybierz pozycję Zapisz.
Wybierz pozycję Prześlij w górnej części kanwy, aby przesłać zadanie potoku.
W zależności od przykładowego potoku i ustawień obliczeniowych ukończenie zadań może zająć trochę czasu. Domyślne ustawienia obliczeniowe mają minimalny rozmiar węzła wynoszący 0, co oznacza, że projektant musi przydzielić zasoby po bezczynności. Powtarzające się zadania potoku potrwają mniej czasu, ponieważ zasoby obliczeniowe są już przydzielone. Ponadto projektant używa buforowanych wyników dla każdego składnika, aby zwiększyć wydajność.
Po zakończeniu działania potoku możesz przejrzeć potok i wyświetlić dane wyjściowe dla każdego składnika, aby dowiedzieć się więcej. Aby wyświetlić dane wyjściowe składników, wykonaj następujące czynności:
- Kliknij prawym przyciskiem myszy składnik na kanwie, którego dane wyjściowe chcesz wyświetlić.
- Wybierz pozycję Visualize ( Wizualizacja).
Użyj przykładów jako punktów wyjścia dla niektórych z najbardziej typowych scenariuszy uczenia maszynowego.
Regresja
Zapoznaj się z tymi wbudowanymi przykładami regresji.
| Przykładowy tytuł | opis |
|---|---|
| Regresja — przewidywanie cen samochodów (podstawowa) | Przewidywanie cen samochodów przy użyciu regresji liniowej. |
| Regresja — przewidywanie cen samochodów (zaawansowane) | Przewidywanie cen samochodów przy użyciu lasu decyzyjnego i zwiększenie regresji drzewa decyzyjnego. Porównaj modele, aby znaleźć najlepszy algorytm. |
Klasyfikacja
Zapoznaj się z tymi wbudowanymi przykładami klasyfikacji. Więcej informacji na temat przykładów można dowiedzieć się, otwierając przykłady i wyświetlając komentarze składników w projektancie.
| Przykładowy tytuł | opis |
|---|---|
| Klasyfikacja binarna z wyborem funkcji — przewidywanie dochodów | Przewidywanie dochodów jako wysokich lub niskich przy użyciu dwuklasowego wzmocnionego drzewa decyzyjnego. Użyj korelacji Pearsona, aby wybrać funkcje. |
| Klasyfikacja binarna z niestandardowym skryptem języka Python — przewidywanie ryzyka kredytowego | Klasyfikowanie aplikacji kredytowych jako wysokiego lub niskiego ryzyka. Użyj składnika Execute Python Script (Wykonywanie skryptu języka Python), aby zważyć dane. |
| Klasyfikacja binarna — przewidywanie relacji klienta | Przewidywanie zmian klientów przy użyciu dwóch klas wzmocnionych drzew decyzyjnych. Użyj funkcji SMOTE do próbkowania stronniczych danych. |
| Klasyfikacja tekstu — Zestaw danych Wikipedia SP 500 | Klasyfikowanie typów firm z artykułów w Wikipedii przy użyciu regresji logistycznej wieloklasowej. |
| Klasyfikacja wieloklasowa — rozpoznawanie listów | Utwórz zespół klasyfikatorów binarnych w celu klasyfikowania pisanych liter. |
Przetwarzanie obrazów
Zapoznaj się z tymi wbudowanymi przykładami przetwarzania obrazów. Więcej informacji na temat przykładów można dowiedzieć się, otwierając przykłady i wyświetlając komentarze składników w projektancie.
| Przykładowy tytuł | opis |
|---|---|
| Klasyfikacja obrazów przy użyciu aplikacji DenseNet | Używanie składników przetwarzania obrazów do tworzenia modelu klasyfikacji obrazów na podstawie sieci PyTorch DenseNet. |
Moduł poleceń
Zapoznaj się z tymi wbudowanymi przykładami rekomendacji. Więcej informacji na temat przykładów można dowiedzieć się, otwierając przykłady i wyświetlając komentarze składników w projektancie.
| Przykładowy tytuł | opis |
|---|---|
| Rekomendacje oparte na szerokim i głębokim — przewidywanie klasyfikacji restauracji | Utwórz aparat rekomendatora restauracji z funkcji restauracji/użytkowników i klasyfikacji. |
| Zalecenie — tweety oceny filmów | Tworzenie aparatu rekomendacji filmu z funkcji i klasyfikacji filmów/użytkowników. |
Narzędzie
Dowiedz się więcej o przykładach demonstrujących narzędzia i funkcje uczenia maszynowego. Więcej informacji na temat przykładów można dowiedzieć się, otwierając przykłady i wyświetlając komentarze składników w projektancie.
| Przykładowy tytuł | opis |
|---|---|
| Klasyfikacja binarna przy użyciu modelu Vowpal Wabbit — przewidywanie dochodu dla dorosłych | Vowpal Wabbit to system uczenia maszynowego, który pcha granicę uczenia maszynowego z technikami, takimi jak online, hashing, allreduce, redukcje, learning2search, aktywne i interaktywne uczenie. W tym przykładzie pokazano, jak używać modelu Vowpal Wabbit do tworzenia modelu klasyfikacji binarnej. |
| Korzystanie z niestandardowego skryptu języka R — przewidywanie opóźnienia lotu | Użyj dostosowanego skryptu języka R, aby przewidzieć, czy zaplanowany lot pasażera zostanie opóźniony o ponad 15 minut. |
| Krzyżowa walidacja klasyfikacji binarnej — przewidywanie dochodu dla dorosłych | Użyj krzyżowej walidacji, aby utworzyć klasyfikator binarny dla dochodu dla dorosłych. |
| Ważność funkcji permutacji | Użyj znaczenia funkcji permutacji, aby obliczyć wyniki ważności dla testowego zestawu danych. |
| Dostrajanie parametrów klasyfikacji binarnej — przewidywanie dochodu dla dorosłych | Użyj hiperparametrów dostrajania modelu do znajdowania optymalnych hiperparametrów w celu utworzenia klasyfikatora binarnego. |
Zestawy danych
Podczas tworzenia nowego potoku w projektancie usługi Azure Machine Learning domyślnie dołącza się wiele przykładowych zestawów danych. Te przykładowe zestawy danych są używane przez przykładowe potoki na stronie głównej projektanta.
Przykładowe zestawy danych są dostępne w kategorii Przykłady zestawów- danych. Tę pozycję można znaleźć na palecie składników po lewej stronie kanwy w projektancie. Możesz użyć dowolnego z tych zestawów danych we własnym potoku, przeciągając go na kanwę.
| Nazwa zestawu danych | Opis zestawu danych |
|---|---|
| Zestaw danych klasyfikacji binarnej o dochodach dla dorosłych | Podzbiór bazy danych spisu z 1994 r., używając pracujących dorosłych w wieku powyżej 16 lat z skorygowanym indeksem dochodów w > wysokości 100 lat. Użycie: klasyfikuj osoby używające danych demograficznych, aby przewidzieć, czy dana osoba zarabia ponad 50 tys. rocznie. Powiązane badania: Kohavi, R., Becker, B., (1996). REPOZYTORIum UCI Machine Learning. Irvine, CA: University of California, School of Information and Computer Science |
| Dane dotyczące cen samochodów (nieprzetworzone) | Informacje o samochodach według marki i modelu, w tym cena, cechy, takie jak liczba cylindrów i MPG, a także ocena ryzyka ubezpieczeniowego. Ocena ryzyka jest początkowo skojarzona z ceną automatyczną. Następnie jest dostosowywany pod kątem rzeczywistego ryzyka w procesie znanym do działania jako symboli. Wartość +3 wskazuje, że auto jest ryzykowne i wartość -3, że jest prawdopodobnie bezpieczna. Użycie: przewidywanie oceny ryzyka według funkcji przy użyciu regresji lub klasyfikacji wielowariancji. Powiązane badania: Schlimmer, J.C. (1987). REPOZYTORIum UCI Machine Learning. Irvine, CA: University of California, School of Information and Computer Science. |
| Udostępnione etykiety aplikacji CRM | Etykiety z wyzwania przewidywania relacji z klientem KDD Cup 2009 (orange_small_train_appetency.labels). |
| Udostępnione etykiety zmian crm | Etykiety z wyzwania przewidywania relacji z klientem KDD Cup 2009 (orange_small_train_churn.labels). |
| Udostępniony zestaw danych CRM | Te dane pochodzą z wyzwania przewidywania relacji klienta KDD Cup 2009 (orange_small_train.data.zip). Zestaw danych zawiera 50 tys. klientów firmy French Telecom Orange. Każdy klient ma 230 anonimowych funkcji, z których 190 jest liczbowych i 40 są podzielone na kategorie. Funkcje są bardzo rozrzedłe. |
| Udostępnione etykiety sprzedaży dodatkowej crm | Etykiety z wyzwania przewidywania relacji klienta KDD Cup 2009 (orange_large_train_upselling.labels |
| Dane opóźnień lotów | Dane dotyczące wydajności lotów pasażerskich pobrane z zbierania danych TranStats departamentu transportu USA (na czas). Zestaw danych obejmuje okres od kwietnia do października 2013 r. Przed przekazaniem do projektanta zestaw danych został przetworzony w następujący sposób: - Zestaw danych został przefiltrowany tak, aby obejmował tylko 70 najbardziej ruchliwych lotnisk w kontynentalnych Stanach Zjednoczonych - Anulowane loty zostały oznaczone jako opóźnione o ponad 15 minut - Przekierowane loty zostały odfiltrowane - Wybrano następujące kolumny: Year, Month, DayofMonth, DayOfWeek, Carrier, OriginAirportID, DestAirportID, CRSDepTime, DepDelay, DepDelay, DepDel15, CRSArrTime, ArrDelay, ArrDelay, ArrDel15, Canceled |
| Zestaw danych uci niemieckiej karty kredytowej | Zestaw danych UCI Statlog (niemiecka karta kredytowa) (Statlog+German+Credit+Data) przy użyciu pliku german.data. Zestaw danych klasyfikuje osoby, opisane przez zestaw atrybutów, jako niskie lub wysokie ryzyko kredytowe. Każdy przykład reprezentuje osobę. Istnieje 20 cech, zarówno liczbowych, jak i kategorialnych oraz etykiety binarnej (wartość ryzyka kredytowego). Wpisy wysokiego ryzyka kredytowego mają etykietę = 2, wpisy niskiego ryzyka kredytowego mają etykietę = 1. Koszt błędnego sklasyfikowania przykładu niskiego ryzyka jako wysokiego wynosi 1, natomiast koszt błędnej klasyfikacji przykładu wysokiego ryzyka wynosi 5. |
| Tytuły filmów IMDB | Zestaw danych zawiera informacje o filmach, które zostały ocenione w tweetach X: IDENTYFIKATOR filmu IMDB, nazwa filmu, gatunek i rok produkcji. Zestaw danych zawiera 17 000 filmów. Zestaw danych został wprowadzony w dokumencie "S. Dooms, T. De Pessemier i L. Martens. MovieTweetings: zestaw danych oceny filmu zebrany z Serwisu Twitter. Workshop on Crowdsourcing and Human Computation for Recommender Systems, CrowdRec at RecSys 2013". |
| Oceny filmów | Zestaw danych to rozszerzona wersja zestawu danych Movie Tweetings. Zestaw danych ma 170 000 ocen filmów, wyodrębnionych z dobrze ustrukturyzowanych tweetów na X. Każde wystąpienie reprezentuje tweet i jest krotką: identyfikator użytkownika, identyfikator filmu IMDB, ocena, sygnatura czasowa, liczba ulubionych dla tego tweetu i liczba ponownych prób tego tweetu. Zestaw danych został udostępniony przez A. Said, S. Dooms, B. Loni i D. Tikk for Recommender Systems Challenge 2014. |
| Zestaw danych pogody | Obserwacje pogody oparte na godzinach z NOAA (scalone dane z 201304 do 201310 r.). Dane pogodowe obejmują obserwacje ze stacji pogodowych na lotnisku, obejmujące okres od kwietnia do października 2013 r. Przed przekazaniem do projektanta zestaw danych został przetworzony w następujący sposób: - Identyfikatory stacji pogodowej zostały zamapowane na odpowiednie identyfikatory lotnisk - Stacje pogodowe niezwiązane z 70 najbardziej ruchliwymi lotniskami zostały odfiltrowane — Kolumna Date została podzielona na oddzielne kolumny Year( Rok), Month (Miesiąc) i Day (Dzień) - Wybrano następujące kolumny: AirportID, Year, Month, Day, Time, TimeZone, SkyCondition, Visibility, WeatherType, DryBulbFarenheit, DryBulbCelsius, WetBulbFarenheit, WetBulbCelsius, DewPointFarenheit, DewPointCelsius, RelativeHumidity, WindSpeed, WindDirection, ValueForWindCharacter, StationPressure, PressureTendency, PressureChange, SeaLevelPressure, RecordType, HourlyPrecip, Altimeter |
| Wikipedia SP 500 Dataset | Dane pochodzą z Wikipedii (https://www.wikipedia.org/) na podstawie artykułów każdej firmy S&P 500 przechowywanej jako dane XML. Przed przekazaniem do projektanta zestaw danych został przetworzony w następujący sposób: - Wyodrębnianie zawartości tekstowej dla każdej konkretnej firmy - Usuwanie formatowania wiki - Usuń znaki inne niż alfanumeryczne — Konwertowanie całego tekstu na małe litery - Dodano znane kategorie firmy Należy pamiętać, że w przypadku niektórych firm nie można odnaleźć artykułu, więc liczba rekordów jest mniejsza niż 500. |
| Dane funkcji restauracji | Zestaw metadanych dotyczących restauracji i ich funkcji, takich jak typ żywności, styl jadalni i lokalizacja. Użycie: użyj tego zestawu danych, w połączeniu z dwoma innymi zestawami danych restauracji, aby wytrenować i przetestować system rekomendacji. Powiązane badania: Bache, K. i Lichman, M. (2013). REPOZYTORIum UCI Machine Learning. Irvine, CA: University of California, School of Information and Computer Science. |
| Klasyfikacje restauracji | Zawiera oceny podane przez użytkowników do restauracji w skali od 0 do 2. Użycie: użyj tego zestawu danych, w połączeniu z dwoma innymi zestawami danych restauracji, aby wytrenować i przetestować system rekomendacji. Powiązane badania: Bache, K. i Lichman, M. (2013). REPOZYTORIum UCI Machine Learning. Irvine, CA: University of California, School of Information and Computer Science. |
| Dane klienta restauracji | Zestaw metadanych dotyczących klientów, w tym dane demograficzne i preferencje. Użycie: użyj tego zestawu danych, w połączeniu z dwoma innymi zestawami danych restauracji, aby wytrenować i przetestować system rekomendacji. Powiązane badania: Bache, K. i Lichman, M. (2013). UCI Machine Learning Repository Irvine, CA: University of California, School of Information and Computer Science. |
Czyszczenie zasobów
Ważne
Możesz użyć zasobów utworzonych jako wymagania wstępne dla innych samouczków usługi Azure Machine Learning i artykułów z instrukcjami.
Usuń wszystko
Jeśli nie planujesz używać utworzonych elementów, usuń całą grupę zasobów, aby nie ponosić żadnych opłat.
W witrynie Azure Portal wybierz pozycję Grupy zasobów po lewej stronie okna.
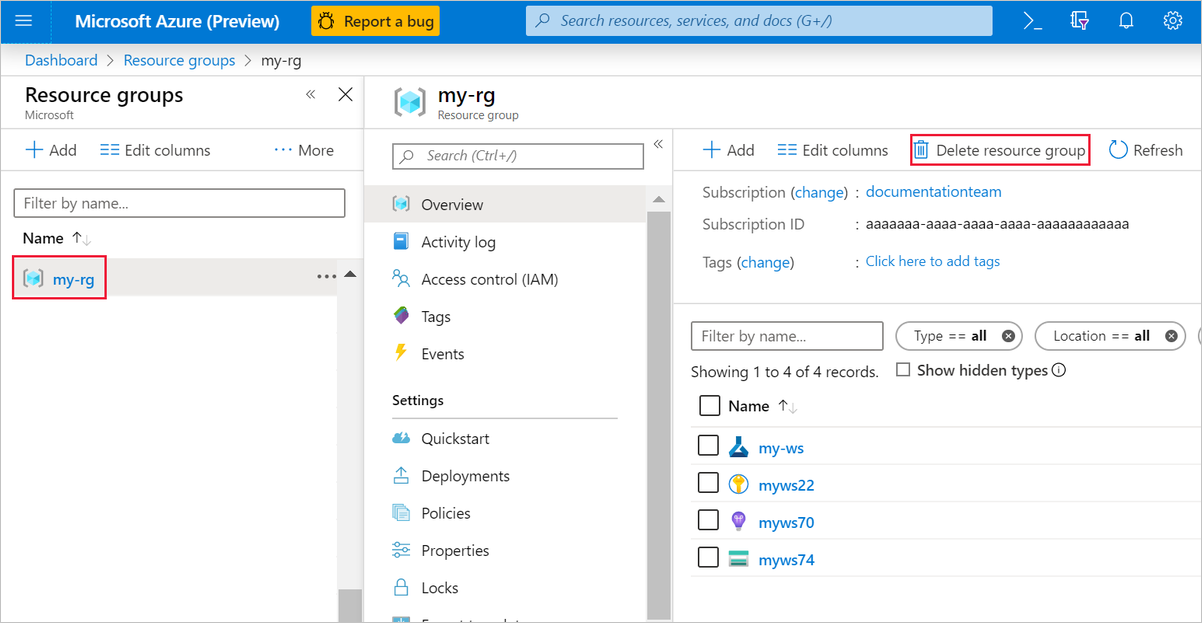
Na liście wybierz utworzoną grupę zasobów.
Wybierz pozycję Usuń grupę zasobów.
Usunięcie grupy zasobów powoduje również usunięcie wszystkich zasobów utworzonych w projektancie.
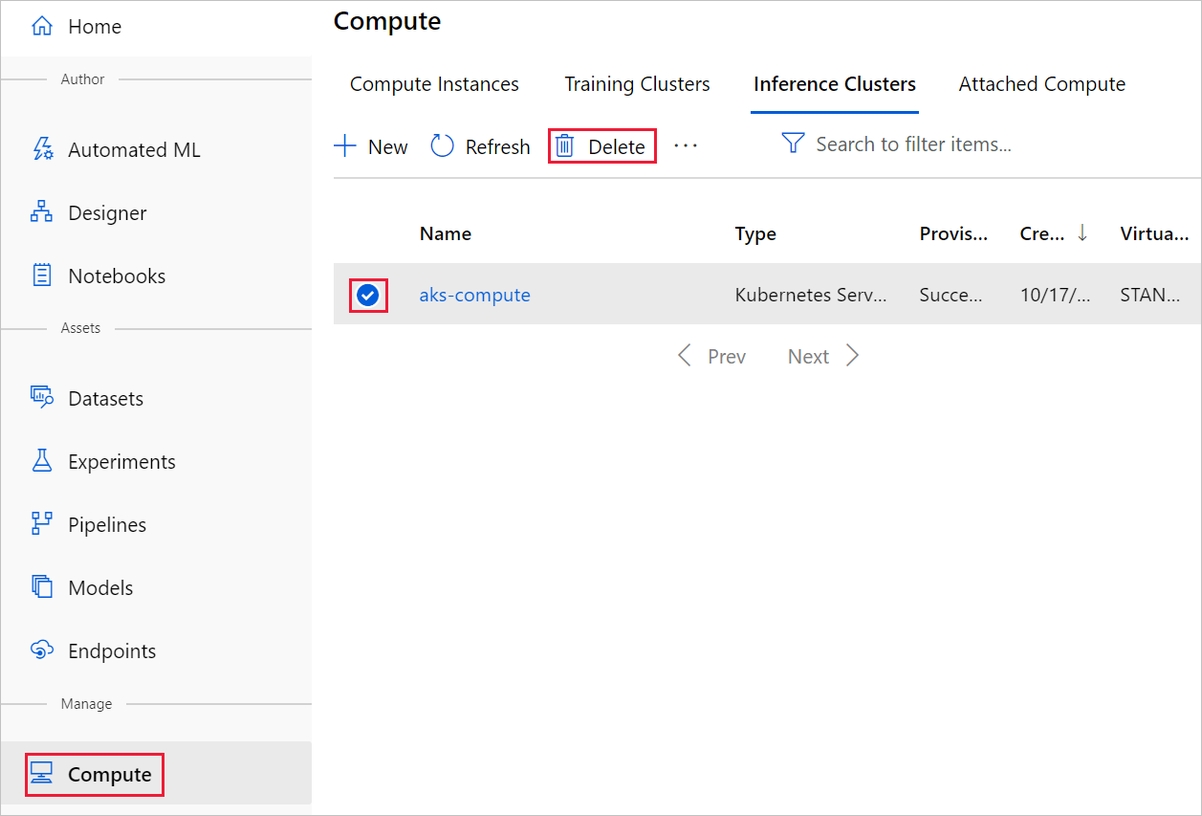
Usuwanie pojedynczych zasobów
W projektancie, w którym utworzono eksperyment, usuń poszczególne zasoby, wybierając je, a następnie wybierając przycisk Usuń .
Docelowy obiekt obliczeniowy utworzony w tym miejscu automatycznie skaluje się do zera węzłów, gdy nie jest używany. Ta akcja jest podejmowana w celu zminimalizowania opłat. Jeśli chcesz usunąć docelowy obiekt obliczeniowy, wykonaj następujące kroki:
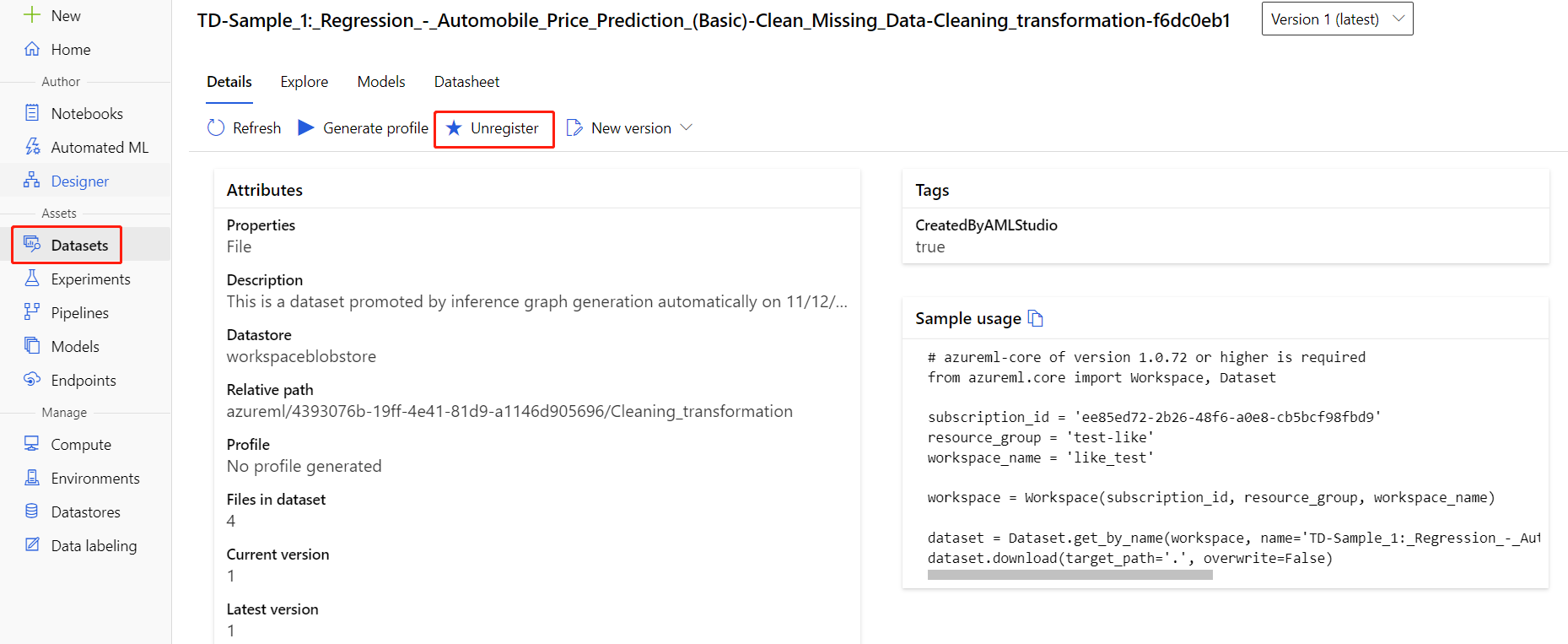
Zestawy danych można wyrejestrować z obszaru roboczego, wybierając każdy zestaw danych i wybierając pozycję Wyrejestruj.
Aby usunąć zestaw danych, przejdź do konta magazynu przy użyciu witryny Azure Portal lub Eksplorator usługi Azure Storage i ręcznie usuń te zasoby.
Następne kroki
Poznaj podstawy analizy predykcyjnej i uczenia maszynowego za pomocą samouczka: przewidywanie cen samochodów za pomocą projektanta