Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Wystąpienie zarządzane platformy Azure dla systemu Apache Cassandra udostępnia zautomatyzowane operacje wdrażania i skalowania dla zarządzanych centrów danych Apache Cassandra typu open source. Ta funkcja przyspiesza scenariusze hybrydowe i pomaga zmniejszyć ciągłą konserwację.
W tym przewodniku szybkiego startu pokazano, jak za pomocą portalu Azure utworzyć w pełni zarządzany klaster Apache Spark w wirtualnej sieci platformy Azure na potrzeby wystąpienia zarządzanego klastra Apache Cassandra. Klaster Spark jest tworzony w usłudze Azure Databricks. Później możesz tworzyć lub dołączać notesy do klastra, odczytywać dane z różnych źródeł danych i analizować szczegółowe informacje.
Aby dowiedzieć się więcej, zapoznaj się ze szczegółowymi instrukcjami dotyczącymi wdrażania usługi Azure Databricks w sieci wirtualnej platformy Azure (iniekcja sieci wirtualnej).
Wymagania wstępne
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Tworzenie klastra usługi Azure Databricks
Wykonaj następujące kroki, aby utworzyć klaster Azure Databricks w sieci wirtualnej z wystąpieniem zarządzanym Azure dla Apache Cassandra.
Zaloguj się w witrynie Azure Portal.
W okienku po lewej stronie znajdź pozycję Grupy zasobów. Przejdź do grupy zasobów zawierającej sieć wirtualną, w której wdrożono wystąpienie zarządzane.
Otwórz zasób sieci wirtualnej i zanotuj przestrzeń adresową.
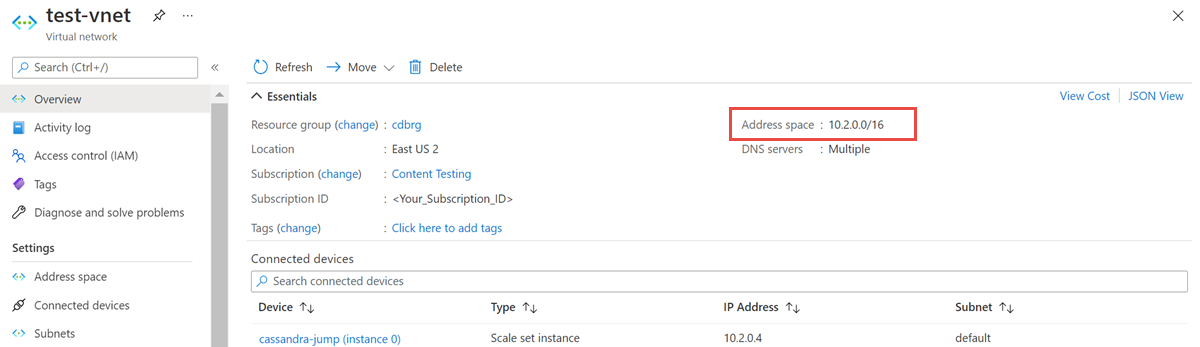
W grupie zasobów wybierz pozycję Dodaj i wyszukaj ciąg Azure Databricks w polu wyszukiwania.
Wybierz pozycję Utwórz , aby utworzyć konto usługi Azure Databricks.
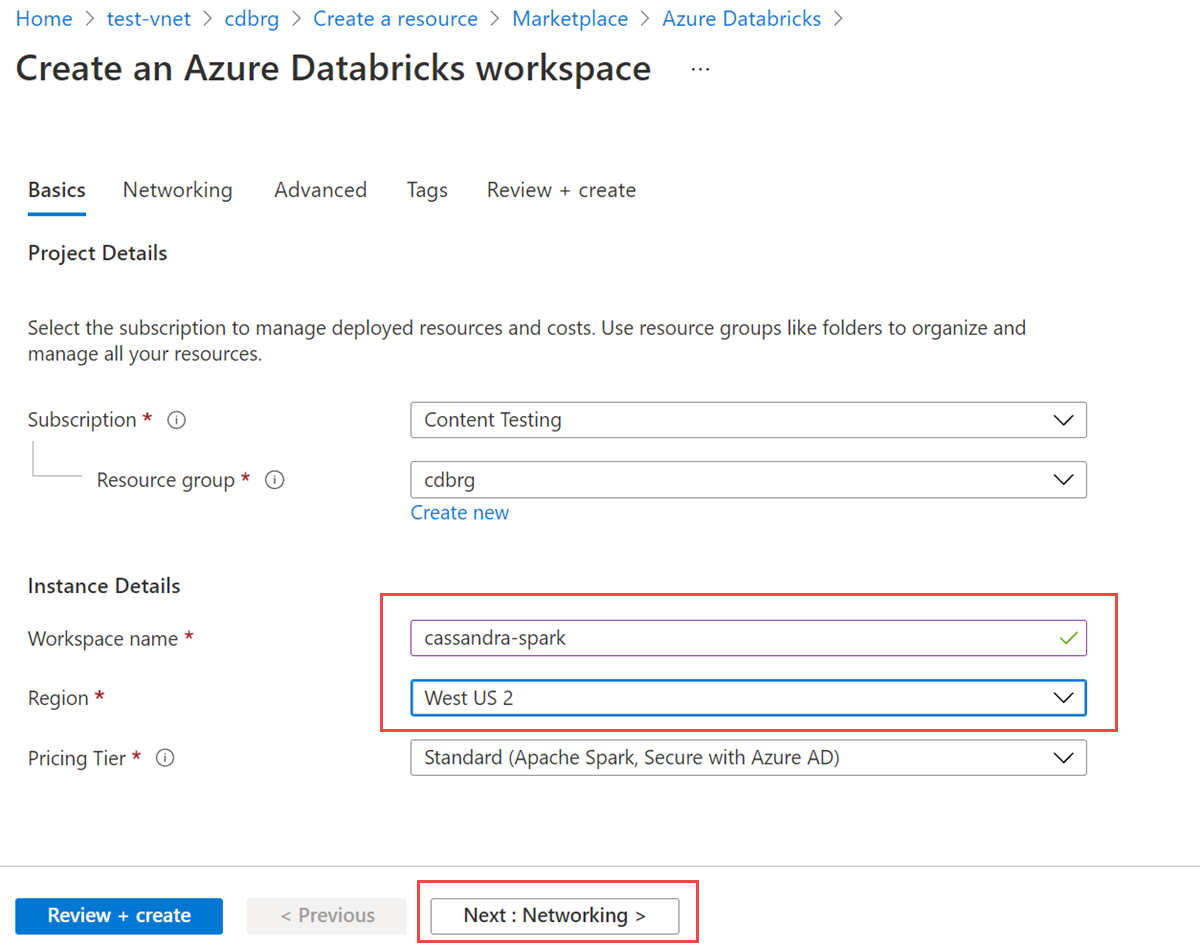
Wprowadź następujące wartości:
- Nazwa obszaru roboczego: podaj nazwę obszaru roboczego usługi Azure Databricks.
- Region: upewnij się, że wybrano ten sam region co sieć wirtualna.
- Warstwa cenowa: wybierz pozycję Standardowa, Premium lub Wersja próbna. Aby uzyskać więcej informacji na temat tych warstw, zobacz stronę cennika usługi Azure Databricks.
Wybierz kartę Sieć i wprowadź następujące szczegóły:
- Wdróż obszar roboczy usługi Azure Databricks w sieci wirtualnej: wybierz pozycję Tak.
- Sieć wirtualna: z listy rozwijanej wybierz sieć wirtualną, w której istnieje wystąpienie zarządzane.
- Nazwa podsieci publicznej: wprowadź nazwę podsieci publicznej.
- Zakres CIDR podsieci publicznej: wprowadź zakres adresów IP dla podsieci publicznej.
- Nazwa podsieci prywatnej: wprowadź nazwę podsieci prywatnej.
- Zakres CIDR podsieci prywatnej: wprowadź zakres adresów IP dla podsieci prywatnej.
Aby uniknąć kolizji zakresu, upewnij się, że wybrano wyższe zakresy. W razie potrzeby użyj wizualnego kalkulatora podsieci, aby podzielić zakresy.
Zrzut ekranu przedstawiający Visual Subnet Calculator z dwoma wyróżnionymi identycznymi adresami sieciowymi.
Poniższy zrzut ekranu przedstawia przykładowe szczegóły w okienku sieci.
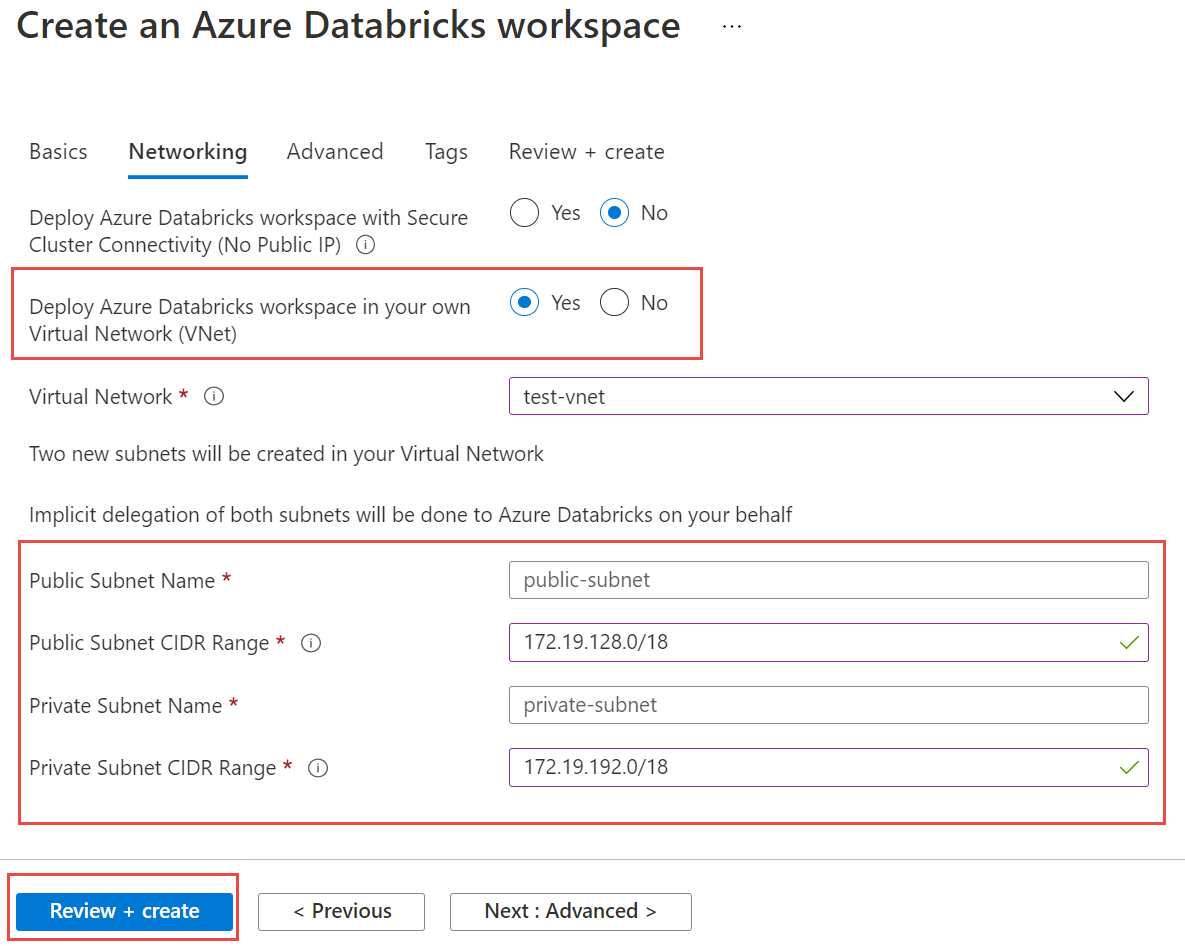
Wybierz pozycję Przejrzyj i utwórz, a następnie wybierz pozycję Utwórz , aby wdrożyć obszar roboczy.
Otwórz obszar roboczy po jego utworzeniu.
Nastąpi przekierowanie do portalu usługi Azure Databricks. W portalu wybierz pozycję Nowy klaster.
W okienku Nowy klaster zaakceptuj wartości domyślne dla wszystkich pól innych niż następujące pola:
- Nazwa klastra: wprowadź nazwę klastra.
- Wersja środowiska uruchomieniowego usługi Databricks: zalecamy wybranie środowiska uruchomieniowego usługi Azure Databricks w wersji 7.5 lub nowszej dla obsługi platformy Spark 3.x.

Rozwiń pozycję Opcje zaawansowane i dodaj następującą konfigurację. Pamiętaj, aby zastąpić adresy IP węzłów oraz poświadczenia.
spark.cassandra.connection.host <node1 IP>,<node 2 IP>, <node IP> spark.cassandra.auth.password cassandra spark.cassandra.connection.port 9042 spark.cassandra.auth.username cassandra spark.cassandra.connection.ssl.enabled trueDodaj bibliotekę łącznika Apache Spark Cassandra do klastra, aby nawiązać połączenie z punktami końcowymi natywnymi i punktami końcowymi cassandra usługi Azure Cosmos DB. W klastrze wybierz pozycję Biblioteki>Zainstaluj nowe>Maven, a następnie dodaj
com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0w polu Współrzędne Maven.
Wybierz Zainstaluj.
Czyszczenie zasobów
Jeśli nie zamierzasz nadal używać tego klastra wystąpień zarządzanych, wykonaj następujące kroki, aby go usunąć:
- W menu po lewej stronie witryny Azure Portal wybierz pozycję Grupy zasobów.
- Z listy wybierz grupę zasobów, którą utworzyłeś dla tego Quickstartu.
- W okienku Przegląd grupy zasobów wybierz pozycję Usuń grupę zasobów.
- W następnym okienku wprowadź nazwę grupy zasobów do usunięcia, a następnie wybierz pozycję Usuń.
Następny krok
W tym przewodniku Szybki start przedstawiono sposób tworzenia w pełni zarządzanego klastra Apache Spark w sieci wirtualnej wystąpienia zarządzanego platformy Azure dla klastra Apache Cassandra. Następnie dowiedz się, jak zarządzać zasobami klastra i centrum danych.