Niezawodność w usłudze Azure Traffic Manager
Ten artykuł zawiera obsługę odzyskiwania po awarii między regionami i ciągłości działalności biznesowej dla usługi Azure Traffic Manager.
Odzyskiwanie po awarii między regionami i ciągłość działania
Odzyskiwanie po awarii dotyczy odzyskiwania po wystąpieniu zdarzeń o dużym wpływie, takich jak klęski żywiołowe lub nieudane wdrożenia, które powodują przestoje i utratę danych. Niezależnie od przyczyny najlepszym rozwiązaniem dla awarii jest dobrze zdefiniowany i przetestowany plan odzyskiwania po awarii oraz projekt aplikacji, który aktywnie obsługuje odzyskiwanie po awarii. Zanim zaczniesz myśleć o tworzeniu planu odzyskiwania po awarii, zobacz Zalecenia dotyczące projektowania strategii odzyskiwania po awarii.
Jeśli chodzi o odzyskiwanie po awarii, firma Microsoft korzysta z modelu wspólnej odpowiedzialności. W modelu wspólnej odpowiedzialności firma Microsoft zapewnia dostępność infrastruktury bazowej i usług platformy. Jednocześnie wiele usług platformy Azure nie replikuje automatycznie danych ani nie wraca z regionu, w którym wystąpił błąd, aby przeprowadzić replikację krzyżową do innego regionu z włączoną obsługą. W przypadku tych usług ponosisz odpowiedzialność za skonfigurowanie planu odzyskiwania po awarii, który działa dla obciążenia. Większość usług uruchamianych na platformie Azure jako usługa (PaaS) oferuje funkcje i wskazówki dotyczące obsługi odzyskiwania po awarii. Funkcje specyficzne dla usługi umożliwiają szybkie odzyskiwanie w celu ułatwienia opracowania planu odzyskiwania po awarii.
Usługa Azure Traffic Manager to oparty na systemie DNS moduł równoważenia obciążenia ruchu, który umożliwia dystrybucję ruchu do publicznych aplikacji w globalnych regionach świadczenia usługi Azure. Usługa Traffic Manager zapewnia również publiczne punkty końcowe o wysokiej dostępności i szybkiej reakcji.
Usługa Traffic Manager używa systemu DNS do kierowania żądań klientów do odpowiedniego punktu końcowego usługi na podstawie metody routingu ruchu. Usługa Traffic Manager zapewnia również monitorowanie kondycji dla każdego punktu końcowego. Punkt końcowy może być dowolną usługą dostępną z Internetu hostowaną wewnątrz platformy Azure lub poza platformą Azure. Usługa Traffic Manager udostępnia szereg metod routingu ruchu oraz opcji monitorowania punktów końcowych, które zaspokoją potrzeby różnych aplikacji i modeli automatycznej pracy w trybie failover. Usługa Traffic Manager jest odporna na awarie, w tym awarię całego regionu platformy Azure.
Odzyskiwanie po awarii w lokalizacji geograficznej obejmującej wiele regionów
DNS to jeden z najbardziej wydajnych mechanizmów przekierowywania ruchu sieciowego. System DNS jest wydajny, ponieważ usługa DNS jest często globalna i zewnętrzna dla centrum danych. System DNS jest również odizolowany od błędów poziomu regionalnego lub strefy dostępności (AZ).
Istnieją dwa aspekty techniczne dotyczące konfigurowania architektury odzyskiwania po awarii:
Używanie mechanizmu wdrażania do replikowania wystąpień, danych i konfiguracji między środowiskami podstawowymi i rezerwowymi. Tego typu odzyskiwanie po awarii można wykonać natywnie za pośrednictwem usługiAzure Site Recovery. Zobacz dokumentację usługi Azure Site Recovery za pośrednictwem urządzeń/usług partnerskich platformy Microsoft Azure, takich jak Veritas lub NetApp.
Opracowanie rozwiązania do przekierowywania ruchu sieciowego/internetowego z lokacji głównej do lokacji rezerwowej. Ten typ odzyskiwania po awarii można osiągnąć za pośrednictwem usług Azure DNS, Azure Traffic Manager (DNS) lub globalnych modułów równoważenia obciążenia innych firm.
Ten artykuł koncentruje się specjalnie na planowaniu odzyskiwania po awarii usługi Azure Traffic Manager.
Wykrywanie, powiadamianie i zarządzanie awariami
Podczas awarii podstawowy punkt końcowy jest sondowany, a stan zmieni się na obniżoną wydajność , a lokacja odzyskiwania po awarii pozostaje w trybie online. Domyślnie usługa Traffic Manager kieruje cały ruch do podstawowego punktu końcowego (punktu końcowego o najwyższym priorytecie). Jeśli podstawowy punkt końcowy zostanie obniżony, usługa Traffic Manager kieruje ruch do drugiego punktu końcowego, o ile pozostanie w dobrej kondycji. Można skonfigurować więcej punktów końcowych w usłudze Traffic Manager, które mogą służyć jako dodatkowe punkty końcowe trybu failover lub jako moduły równoważenia obciążenia współdzielą obciążenie między punktami końcowymi.
Konfigurowanie odzyskiwania po awarii i wykrywania awarii
Jeśli masz złożone architektury i wiele zestawów zasobów, które mogą wykonywać tę samą funkcję, możesz skonfigurować usługę Azure Traffic Manager (opartą na systemie DNS), aby sprawdzić kondycję zasobów i kierować ruch z zasobu niebędącego w dobrej kondycji do zasobu w dobrej kondycji.
W poniższym przykładzie zarówno region podstawowy, jak i region pomocniczy mają pełne wdrożenie. To wdrożenie obejmuje usługi w chmurze i zsynchronizowaną bazę danych.
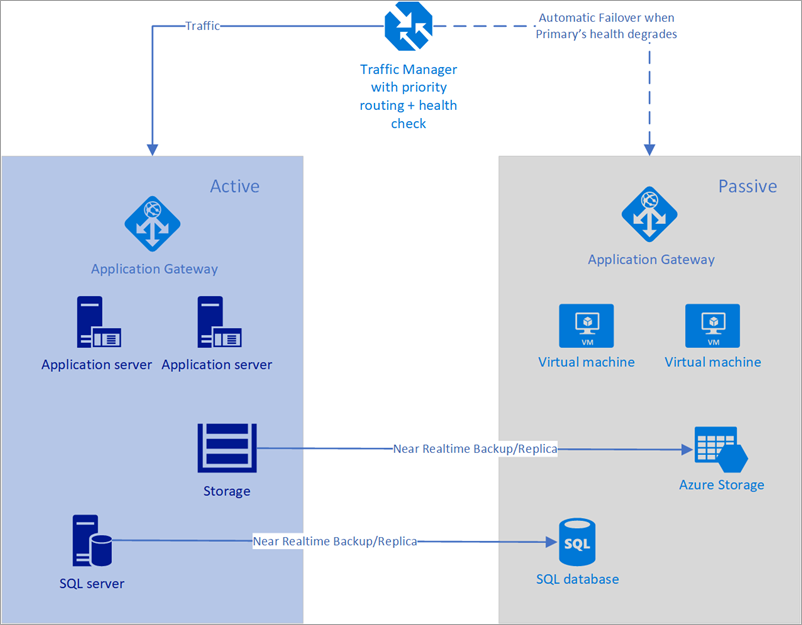
Rysunek — automatyczne przechodzenie w tryb failover przy użyciu usługi Azure Traffic Manager
Jednak tylko region podstawowy aktywnie obsługuje żądania sieciowe od użytkowników. Region pomocniczy staje się aktywny tylko wtedy, gdy region podstawowy doświadcza przerwy w działaniu usługi. W takim przypadku wszystkie nowe żądania sieciowe są kierowane do regionu pomocniczego. Ponieważ tworzenie kopii zapasowej bazy danych jest niemal natychmiastowe, oba moduły równoważenia obciążenia mają adresy IP, które mogą być sprawdzane pod kątem kondycji, a wystąpienia są zawsze uruchomione, ta topologia zapewnia opcję przechodzenia na niski cel czasu odzyskiwania i tryb failover bez żadnej interwencji ręcznej. Pomocniczy region trybu failover musi być gotowy do przejścia na żywo natychmiast po awarii regionu podstawowego.
Ten scenariusz jest idealny do użycia usługi Azure Traffic Manager, która ma wbudowane sondy dla różnych typów kontroli kondycji, w tym http/https i TCP. Usługa Azure Traffic Manager ma również aparat reguł, który można skonfigurować do przełączania w tryb failover, gdy wystąpi awaria zgodnie z poniższym opisem. Rozważmy następujące rozwiązanie przy użyciu usługi Traffic Manager:
- Klient ma punkt końcowy Region #1 znany jako prod.contoso.com ze statycznym adresem IP jako 100.168.124.44 i punktem końcowym Region #2 znanym jako dr.contoso.com ze statycznym adresem IP jako 100.168.124.43.
- Każde z tych środowisk jest frontowane za pośrednictwem właściwości publicznej, takiej jak moduł równoważenia obciążenia. Moduł równoważenia obciążenia można skonfigurować tak, aby miał punkt końcowy oparty na systemie DNS lub w pełni kwalifikowaną nazwę domeny (FQDN), jak pokazano powyżej.
- Wszystkie wystąpienia w regionie 2 są niemal w czasie rzeczywistym replikacji z regionem 1. Ponadto obrazy maszyn są aktualne, a wszystkie dane oprogramowania/konfiguracji są poprawiane i są zgodne z regionem 1.
- Skalowanie automatyczne jest wstępnie skonfigurowane z wyprzedzeniem.
Aby skonfigurować tryb failover za pomocą usługi Azure Traffic Manager:
Utwórz nowy profil usługi Azure Traffic Manager Utwórz nowy profil usługi Azure Traffic Manager o nazwie contoso123 i wybierz metodę routingu jako Priorytet. Jeśli masz wcześniej istniejącą grupę zasobów, z którą chcesz skojarzyć, możesz wybrać istniejącą grupę zasobów, w przeciwnym razie utworzyć nową grupę zasobów.
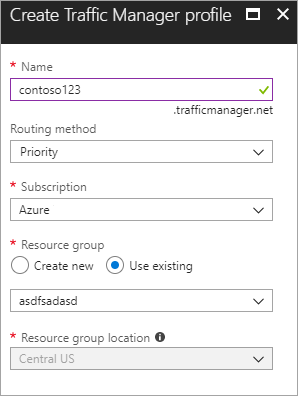
Rysunek — tworzenie profilu usługi Traffic Manager
Tworzenie punktów końcowych w profilu usługi Traffic Manager
W tym kroku utworzysz punkty końcowe wskazujące lokacje produkcyjne i odzyskiwania po awarii. W tym miejscu wybierz typ jako zewnętrzny punkt końcowy, ale jeśli zasób jest hostowany na platformie Azure, możesz również wybrać punkt końcowy platformy Azure. Jeśli wybierzesz punkt końcowy platformy Azure, wybierz zasób docelowy, który jest usługą App Service lub publicznym adresem IP przydzielonym przez platformę Azure. Priorytet jest ustawiany jako 1 , ponieważ jest to usługa podstawowa dla regionu 1. Podobnie utwórz punkt końcowy odzyskiwania po awarii w usłudze Traffic Manager.
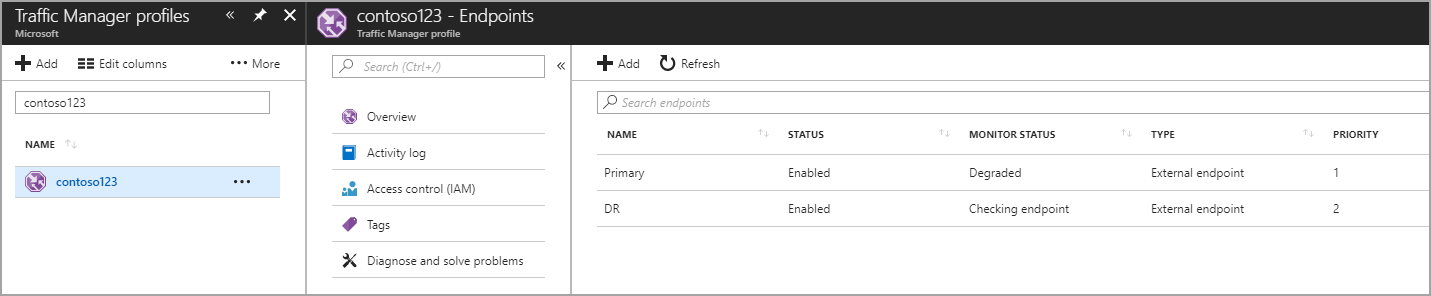
Rysunek — tworzenie punktów końcowych odzyskiwania po awarii
Konfigurowanie kontroli kondycji i konfiguracji trybu failover
W tym kroku ustawisz czas wygaśnięcia DNS na 10 sekund, który jest honorowany przez większość rekursywnych rozpoznawania cyklicznego dostępnego z Internetu. Ta konfiguracja oznacza, że żaden program rozpoznawania nazw DNS nie buforuje informacji przez ponad 10 sekund.
W przypadku ustawień monitora punktu końcowego ścieżka jest bieżąca ustawiona w folderze /lub katalogu głównym, ale możesz dostosować ustawienia punktu końcowego, aby ocenić ścieżkę, na przykład prod.contoso.com/index.
W poniższym przykładzie pokazano protokół https jako protokół sondowania. Można jednak również wybrać protokół HTTP lub tcp . Wybór protokołu zależy od aplikacji końcowej. Interwał sondowania jest ustawiony na 10 sekund, co umożliwia szybkie sondowanie, a ponowna próba jest ustawiona na 3. W związku z tym usługa Traffic Manager przejdzie w tryb failover do drugiego punktu końcowego, jeśli trzy kolejne interwały rejestrują błąd.
Poniższa formuła definiuje całkowity czas automatycznego przejścia w tryb failover:
Time for failover = TTL + Retry * Probing intervalW tym przypadku wartość to 10 + 3 * 10 = 40 sekund (maks.).
Jeśli ponawianie jest ustawione na 1, a czas wygaśnięcia jest ustawiony na 10 sekund, wówczas czas przejścia w tryb failover 10 + 1 * 10 = 20 sekund.
Ustaw wartość Ponów próbę na wartość większą niż 1 , aby wyeliminować prawdopodobieństwo przejścia w tryb failover z powodu wyników fałszywie dodatnich lub drobnych blipów sieci.
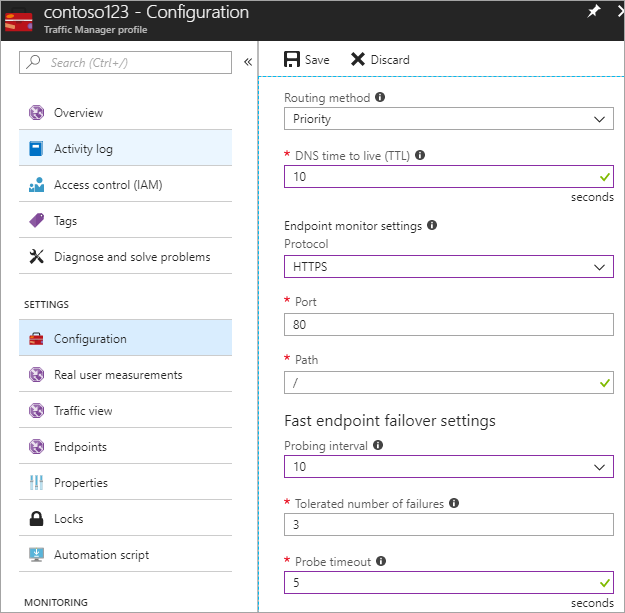
Rysunek — Konfigurowanie kontroli kondycji i konfiguracji trybu failover
Następne kroki
Dowiedz się więcej o usłudze Azure Traffic Manager.
Dowiedz się więcej o usłudze Azure DNS.