Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule pokazano, jak używać obciążeń procesora GPU FIRMY NVIDIA z usługą Azure Red Hat OpenShift (ARO).
Wymagania wstępne
- Interfejs wiersza polecenia platformy OpenShift
- Pakiet jq, moreutils i gettext
- Azure Red Hat OpenShift 4.10
Jeśli musisz zainstalować klaster ARO, zobacz Samouczek: tworzenie klastra usługi Azure Red Hat OpenShift 4. Klastry ARO muszą być w wersji 4.10.x lub nowszej.
Uwaga / Notatka
Od wersji ARO 4.10 nie jest już konieczne skonfigurowanie uprawnień do korzystania z operatora NVIDIA. Znacznie uprościło to konfigurację klastra dla obciążeń procesora GPU.
Linux:
sudo dnf install jq moreutils gettext
macOS
brew install jq moreutils gettext
Żądanie limitu przydziału procesora GPU
Domyślnie wszystkie przydziały procesora GPU na platformie Azure to 0. Musisz zalogować się do witryny Azure Portal i zażądać limitu przydziału procesora GPU. Ze względu na konkurencję dla pracowników procesora GPU może być konieczne aprowizowania klastra ARO w regionie, w którym można rzeczywiście zarezerwować procesor GPU.
Usługa ARO obsługuje następujące procesy robocze procesora GPU:
- NC4as T4 v3
- NC6s v3
- NC8as T4 v3
- NC12s v3
- NC16as T4 v3
- NC24s v3
- NC24rs v3
- NC64as T4 v3
Następujące wystąpienia są również obsługiwane w dodatkowych zestawach maszyn:
- Standard_ND96asr_v4
- NC24ads_A100_v4
- NC48ads_A100_v4
- NC96ads_A100_v4
- ND96amsr_A100_v4
Uwaga / Notatka
Podczas żądania limitu przydziału pamiętaj, że platforma Azure jest na rdzeń. Aby zażądać pojedynczego węzła NC4as T4 v3, należy zażądać limitu przydziału w grupach 4. Jeśli chcesz zażądać nc16as T4 v3, musisz zażądać limitu przydziału 16.
Zaloguj się do Portalu Azure.
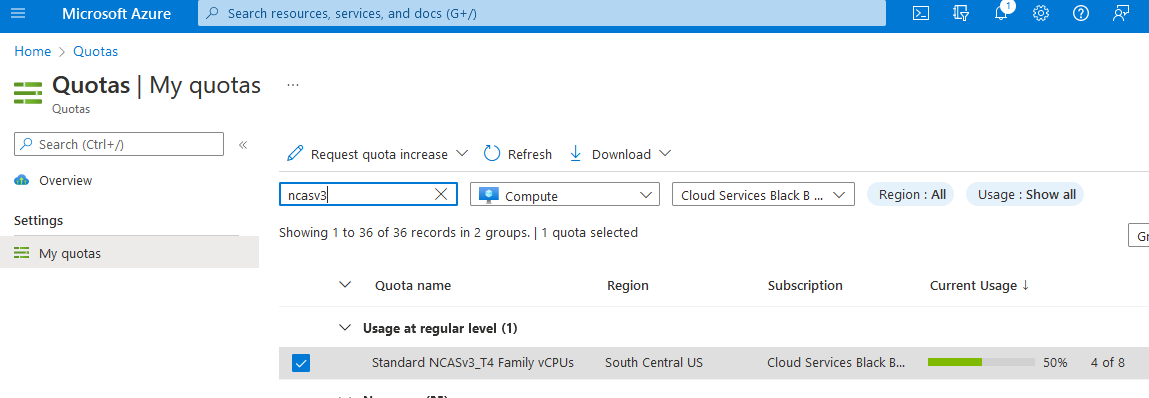
Wprowadź limity przydziału w polu wyszukiwania, a następnie wybierz pozycję Obliczenia.
W polu wyszukiwania wprowadź NCAsv3_T4, zaznacz pole wyboru dla regionu, w którym znajduje się klaster, a następnie wybierz pozycję Zażądaj zwiększenia limitu przydziału.
Konfigurowanie limitu przydziału.
Logowanie się do klastra usługi ARO
Zaloguj się do usługi OpenShift przy użyciu konta użytkownika z uprawnieniami administratora klastra. W poniższym przykładzie użyto konta o nazwie kubadmin:
oc login <apiserver> -u kubeadmin -p <kubeadminpass>
Klucz tajny ściągnięcia (warunkowy)
Zaktualizuj wpis tajny ściągnięcia, aby upewnić się, że możesz zainstalować operatory i nawiązać połączenie z cloud.redhat.com.
Uwaga / Notatka
Pomiń ten krok, jeśli utworzono już pełny wpis tajny ściągania z włączonym cloud.redhat.com.
Zaloguj się do cloud.redhat.com.
Przejdź do https://cloud.redhat.com/openshift/install/azure/aro-provisioned.
Wybierz pozycję Pobierz wpis tajny ściągnięcia i zapisz wpis tajny ściągania jako
pull-secret.txt.Ważne
Pozostałe kroki w tej sekcji muszą być uruchamiane w tym samym katalogu roboczym co
pull-secret.txt.Wyeksportuj istniejący wpis tajny ściągnięcia.
oc get secret pull-secret -n openshift-config -o json | jq -r '.data.".dockerconfigjson"' | base64 --decode > export-pull.jsonScal pobrany wpis tajny ściągnięcia z wpisem tajnym ściągania systemu, aby dodać
cloud.redhat.comelement .jq -s '.[0] * .[1]' export-pull.json pull-secret.txt | tr -d "\n\r" > new-pull-secret.jsonPrzekaż nowy plik tajny.
oc set data secret/pull-secret -n openshift-config --from-file=.dockerconfigjson=new-pull-secret.jsonMoże być konieczne odczekenie około 1 godziny, aż wszystko będzie zsynchronizowane z cloud.redhat.com.
Usuwanie wpisów tajnych.
rm pull-secret.txt export-pull.json new-pull-secret.json
Zestaw maszyn gpu
Usługa ARO używa zestawu Maszyn Kubernetes MachineSet do tworzenia zestawów maszyn. Poniższa procedura wyjaśnia, jak wyeksportować pierwszy zestaw maszyn w klastrze i użyć go jako szablonu do utworzenia pojedynczej maszyny gpu.
Wyświetl istniejące zestawy maszyn.
W celu ułatwienia konfiguracji w tym przykładzie użyto pierwszego zestawu maszyn jako jednego do sklonowania w celu utworzenia nowego zestawu maszyn gpu.
MACHINESET=$(oc get machineset -n openshift-machine-api -o=jsonpath='{.items[0]}' | jq -r '[.metadata.name] | @tsv')Zapisz kopię przykładowego zestawu maszyn.
oc get machineset -n openshift-machine-api $MACHINESET -o json > gpu_machineset.jsonZmień pole na
.metadata.namenową unikatową nazwę.jq '.metadata.name = "nvidia-worker-<region><az>"' gpu_machineset.json| sponge gpu_machineset.jsonUpewnij się, że
spec.replicasjest zgodna z żądaną liczbą replik dla zestawu maszyn.jq '.spec.replicas = 1' gpu_machineset.json| sponge gpu_machineset.jsonZmień pole tak
.spec.selector.matchLabels.machine.openshift.io/cluster-api-machineset, aby było zgodne z polem.metadata.name.jq '.spec.selector.matchLabels."machine.openshift.io/cluster-api-machineset" = "nvidia-worker-<region><az>"' gpu_machineset.json| sponge gpu_machineset.jsonZmień wartość ,
.spec.template.metadata.labels.machine.openshift.io/cluster-api-machinesetaby pasować do.metadata.namepola.jq '.spec.template.metadata.labels."machine.openshift.io/cluster-api-machineset" = "nvidia-worker-<region><az>"' gpu_machineset.json| sponge gpu_machineset.jsonZmień wartość ,
spec.template.spec.providerSpec.value.vmSizeaby pasować do żądanego typu wystąpienia procesora GPU z platformy Azure.Maszyna używana w tym przykładzie jest Standard_NC4as_T4_v3.
jq '.spec.template.spec.providerSpec.value.vmSize = "Standard_NC4as_T4_v3"' gpu_machineset.json | sponge gpu_machineset.jsonZmień wartość ,
spec.template.spec.providerSpec.value.zoneaby pasować do żądanej strefy z platformy Azure.jq '.spec.template.spec.providerSpec.value.zone = "1"' gpu_machineset.json | sponge gpu_machineset.jsonUsuń sekcję
.statuspliku yaml.jq 'del(.status)' gpu_machineset.json | sponge gpu_machineset.jsonSprawdź inne dane w pliku yaml.
Upewnij się, że ustawiono prawidłową jednostkę SKU
W zależności od obrazu używanego dla zestawu maszyn wartości image.sku i image.version muszą być odpowiednio ustawione. Ma to na celu zapewnienie, czy będzie używana maszyna wirtualna generacji 1 lub 2 dla funkcji Hyper-V. Aby uzyskać więcej informacji, zobacz tutaj.
Przykład:
W przypadku korzystania z Standard_NC4as_T4_v3programu obsługiwane są obie wersje. Jak wspomniano w temacie Obsługa funkcji. W takim przypadku nie są wymagane żadne zmiany.
W przypadku korzystania z programu Standard_NC24ads_A100_v4obsługiwana jest tylko maszyna wirtualna generacji 2.
W takim przypadku image.sku wartość musi być zgodna z równoważną v2 wersją obrazu, która odpowiada oryginalnemu image.skuklastrowi . W tym przykładzie wartość będzie mieć wartość v410-v2.
Można to znaleźć za pomocą następującego polecenia:
az vm image list --architecture x64 -o table --all --offer aro4 --publisher azureopenshift
Filtered output:
SKU VERSION
------- ---------------
v410-v2 410.84.20220125
aro_410 410.84.20220125
Jeśli klaster został utworzony przy użyciu podstawowego obrazu aro_410jednostki SKU, a ta sama wartość jest przechowywana w zestawie maszyn, zakończy się niepowodzeniem z powodu następującego błędu:
failure sending request for machine myworkernode: cannot create vm: compute.VirtualMachinesClient#CreateOrUpdate: Failure sending request: StatusCode=400 -- Original Error: Code="BadRequest" Message="The selected VM size 'Standard_NC24ads_A100_v4' cannot boot Hypervisor Generation '1'.
Tworzenie zestawu maszyn procesora GPU
Wykonaj poniższe kroki, aby utworzyć nową maszynę gpu. Aprowizowania nowej maszyny z procesorem GPU może upłynąć 10–15 minut. Jeśli ten krok zakończy się niepowodzeniem, zaloguj się do witryny Azure Portal i upewnij się, że nie występują problemy z dostępnością. W tym celu przejdź do pozycji Maszyny wirtualne i wyszukaj wcześniej utworzoną nazwę procesu roboczego, aby wyświetlić stan maszyn wirtualnych.
Utwórz zestaw maszyn gpu.
oc create -f gpu_machineset.jsonWykonanie tego polecenia potrwa kilka minut.
Zweryfikuj zestaw maszyn gpu.
Maszyny powinny być wdrażane. Stan zestawu maszyn można wyświetlić za pomocą następujących poleceń:
oc get machineset -n openshift-machine-api oc get machine -n openshift-machine-apiPo aprowizacji maszyn (co może potrwać od 5 do 15 minut), maszyny będą wyświetlane jako węzły na liście węzłów:
oc get nodesPowinien zostać wyświetlony węzeł o
nvidia-worker-southcentralus1nazwie utworzonej wcześniej.
Instalowanie operatora procesora GPU firmy NVIDIA
W tej sekcji wyjaśniono, jak utworzyć nvidia-gpu-operator przestrzeń nazw, skonfigurować grupę operatorów i zainstalować operator procesora GPU firmy NVIDIA.
Utwórz przestrzeń nazw FIRMY NVIDIA.
cat <<EOF | oc apply -f - apiVersion: v1 kind: Namespace metadata: name: nvidia-gpu-operator EOFUtwórz grupę operatorów.
cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: name: nvidia-gpu-operator-group namespace: nvidia-gpu-operator spec: targetNamespaces: - nvidia-gpu-operator EOFPobierz najnowszy kanał NVIDIA przy użyciu następującego polecenia:
CHANNEL=$(oc get packagemanifest gpu-operator-certified -n openshift-marketplace -o jsonpath='{.status.defaultChannel}')
Uwaga / Notatka
Jeśli klaster został utworzony bez podawania wpisu tajnego ściągania, klaster nie będzie zawierać przykładów ani operatorów z oprogramowania Red Hat ani certyfikowanych partnerów. Spowoduje to wyświetlenie następującego komunikatu o błędzie:
Błąd z serwera (NotFound): nie znaleziono packagemanifests.packages.operators.coreos.com "gpu-operator-certified".
Aby dodać wpis tajny ściągania oprogramowania Red Hat w klastrze usługi Azure Red Hat OpenShift, postępuj zgodnie z poniższymi wskazówkami.
Pobierz najnowszy pakiet NVIDIA przy użyciu następującego polecenia:
PACKAGE=$(oc get packagemanifests/gpu-operator-certified -n openshift-marketplace -ojson | jq -r '.status.channels[] | select(.name == "'$CHANNEL'") | .currentCSV')Utwórz subskrypcję.
envsubst <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: gpu-operator-certified namespace: nvidia-gpu-operator spec: channel: "$CHANNEL" installPlanApproval: Automatic name: gpu-operator-certified source: certified-operators sourceNamespace: openshift-marketplace startingCSV: "$PACKAGE" EOFPoczekaj, aż operator zakończy instalację.
Nie kontynuuj, dopóki nie potwierdzisz, że operator zakończył instalację. Upewnij się również, że proces roboczy procesora GPU jest w trybie online.
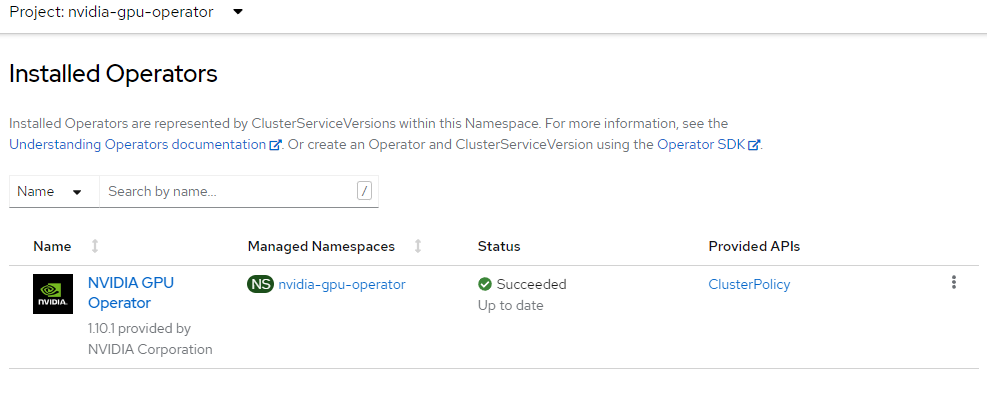
Operator odnajdywania funkcji instalacji węzła
Operator odnajdywania funkcji węzła odnajduje procesor GPU w węzłach i odpowiednio oznaczy węzły, aby umożliwić ich kierowanie do obciążeń.
W tym przykładzie operator NFD jest instalowany w openshift-ndf przestrzeni nazw i tworzy "subskrypcję", która jest konfiguracją systemu plików NFD.
Oficjalna dokumentacja instalowania operatora odnajdywania funkcji węzła.
Skonfiguruj element
Namespace.cat <<EOF | oc apply -f - apiVersion: v1 kind: Namespace metadata: name: openshift-nfd EOFUtwórz plik
OperatorGroup.cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1 kind: OperatorGroup metadata: generateName: openshift-nfd- name: openshift-nfd namespace: openshift-nfd EOFUtwórz plik
Subscription.cat <<EOF | oc apply -f - apiVersion: operators.coreos.com/v1alpha1 kind: Subscription metadata: name: nfd namespace: openshift-nfd spec: channel: "stable" installPlanApproval: Automatic name: nfd source: redhat-operators sourceNamespace: openshift-marketplace EOFPoczekaj na zakończenie instalacji odnajdywania funkcji węzła.
Możesz zalogować się do konsoli openShift, aby wyświetlić operatory lub po prostu poczekać kilka minut. Niepowodzenie oczekiwania na zainstalowanie operatora spowoduje błąd w następnym kroku.
Utwórz wystąpienie NFD.
cat <<EOF | oc apply -f - kind: NodeFeatureDiscovery apiVersion: nfd.openshift.io/v1 metadata: name: nfd-instance namespace: openshift-nfd spec: customConfig: configData: | # - name: "more.kernel.features" # matchOn: # - loadedKMod: ["example_kmod3"] # - name: "more.features.by.nodename" # value: customValue # matchOn: # - nodename: ["special-.*-node-.*"] operand: image: >- registry.redhat.io/openshift4/ose-node-feature-discovery@sha256:07658ef3df4b264b02396e67af813a52ba416b47ab6e1d2d08025a350ccd2b7b servicePort: 12000 workerConfig: configData: | core: # labelWhiteList: # noPublish: false sleepInterval: 60s # sources: [all] # klog: # addDirHeader: false # alsologtostderr: false # logBacktraceAt: # logtostderr: true # skipHeaders: false # stderrthreshold: 2 # v: 0 # vmodule: ## NOTE: the following options are not dynamically run-time ## configurable and require a nfd-worker restart to take effect ## after being changed # logDir: # logFile: # logFileMaxSize: 1800 # skipLogHeaders: false sources: # cpu: # cpuid: ## NOTE: attributeWhitelist has priority over attributeBlacklist # attributeBlacklist: # - "BMI1" # - "BMI2" # - "CLMUL" # - "CMOV" # - "CX16" # - "ERMS" # - "F16C" # - "HTT" # - "LZCNT" # - "MMX" # - "MMXEXT" # - "NX" # - "POPCNT" # - "RDRAND" # - "RDSEED" # - "RDTSCP" # - "SGX" # - "SSE" # - "SSE2" # - "SSE3" # - "SSE4.1" # - "SSE4.2" # - "SSSE3" # attributeWhitelist: # kernel: # kconfigFile: "/path/to/kconfig" # configOpts: # - "NO_HZ" # - "X86" # - "DMI" pci: deviceClassWhitelist: - "0200" - "03" - "12" deviceLabelFields: # - "class" - "vendor" # - "device" # - "subsystem_vendor" # - "subsystem_device" # usb: # deviceClassWhitelist: # - "0e" # - "ef" # - "fe" # - "ff" # deviceLabelFields: # - "class" # - "vendor" # - "device" # custom: # - name: "my.kernel.feature" # matchOn: # - loadedKMod: ["example_kmod1", "example_kmod2"] # - name: "my.pci.feature" # matchOn: # - pciId: # class: ["0200"] # vendor: ["15b3"] # device: ["1014", "1017"] # - pciId : # vendor: ["8086"] # device: ["1000", "1100"] # - name: "my.usb.feature" # matchOn: # - usbId: # class: ["ff"] # vendor: ["03e7"] # device: ["2485"] # - usbId: # class: ["fe"] # vendor: ["1a6e"] # device: ["089a"] # - name: "my.combined.feature" # matchOn: # - pciId: # vendor: ["15b3"] # device: ["1014", "1017"] # loadedKMod : ["vendor_kmod1", "vendor_kmod2"] EOFSprawdź, czy NFD jest gotowy.
Stan tego operatora powinien być wyświetlany jako Dostępny.
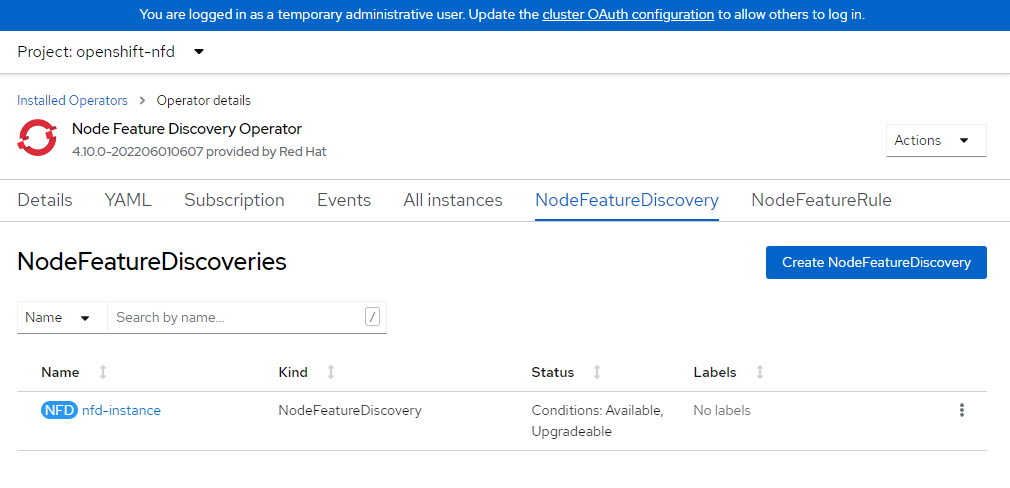
Stosowanie konfiguracji klastra NVIDIA
W tej sekcji wyjaśniono, jak zastosować konfigurację klastra NVIDIA. Przeczytaj dokumentację firmy NVIDIA dotyczącą dostosowywania tego, jeśli masz własne prywatne repozytoria lub określone ustawienia. Ukończenie tego procesu może potrwać kilka minut.
Zastosuj konfigurację klastra.
cat <<EOF | oc apply -f - apiVersion: nvidia.com/v1 kind: ClusterPolicy metadata: name: gpu-cluster-policy spec: migManager: enabled: true operator: defaultRuntime: crio initContainer: {} runtimeClass: nvidia deployGFD: true dcgm: enabled: true gfd: {} dcgmExporter: config: name: '' driver: licensingConfig: nlsEnabled: false configMapName: '' certConfig: name: '' kernelModuleConfig: name: '' repoConfig: configMapName: '' virtualTopology: config: '' enabled: true use_ocp_driver_toolkit: true devicePlugin: {} mig: strategy: single validator: plugin: env: - name: WITH_WORKLOAD value: 'true' nodeStatusExporter: enabled: true daemonsets: {} toolkit: enabled: true EOFZweryfikuj zasady klastra.
Zaloguj się do konsoli openShift i przejdź do operatorów. Upewnij się, że jesteś w
nvidia-gpu-operatorprzestrzeni nazw. Powinien on powiedziećState: Ready once everything is complete.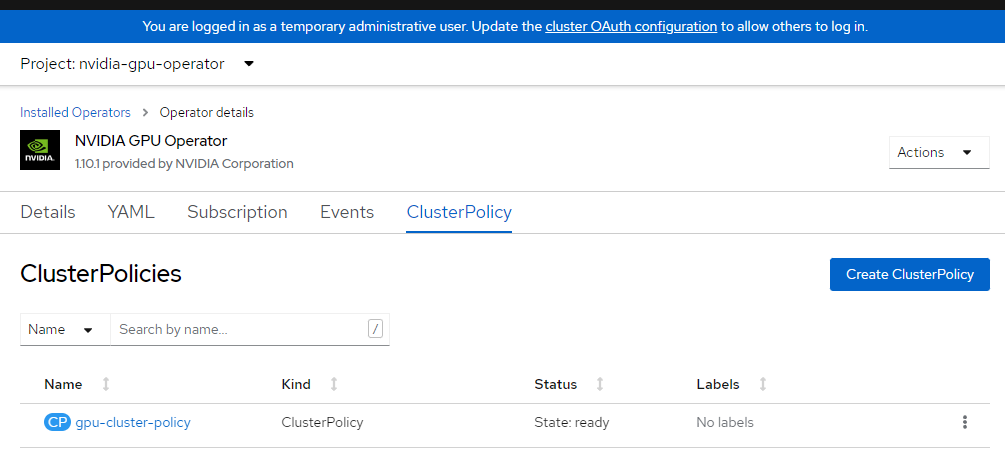
Weryfikowanie procesora GPU
Całkowite zainstalowanie i samodzielne zidentyfikowanie maszyn przez operatora NVIDIA i NFD może zająć trochę czasu. Uruchom następujące polecenia, aby sprawdzić, czy wszystko działa zgodnie z oczekiwaniami:
Sprawdź, czy NFD może wyświetlać swoje procesory GPU.
oc describe node | egrep 'Roles|pci-10de' | grep -v masterDane wyjściowe powinny wyglądać podobnie do następujących:
Roles: worker feature.node.kubernetes.io/pci-10de.present=trueZweryfikuj etykiety węzłów.
Etykiety węzłów można wyświetlić, logując się do konsoli platformy OpenShift —> Obliczenia —> Węzły —> nvidia-worker-southcentralus1-. Powinny zostać wyświetlone wiele etykiet procesora GPU FIRMY NVIDIA i urządzenia pci-10de z góry.
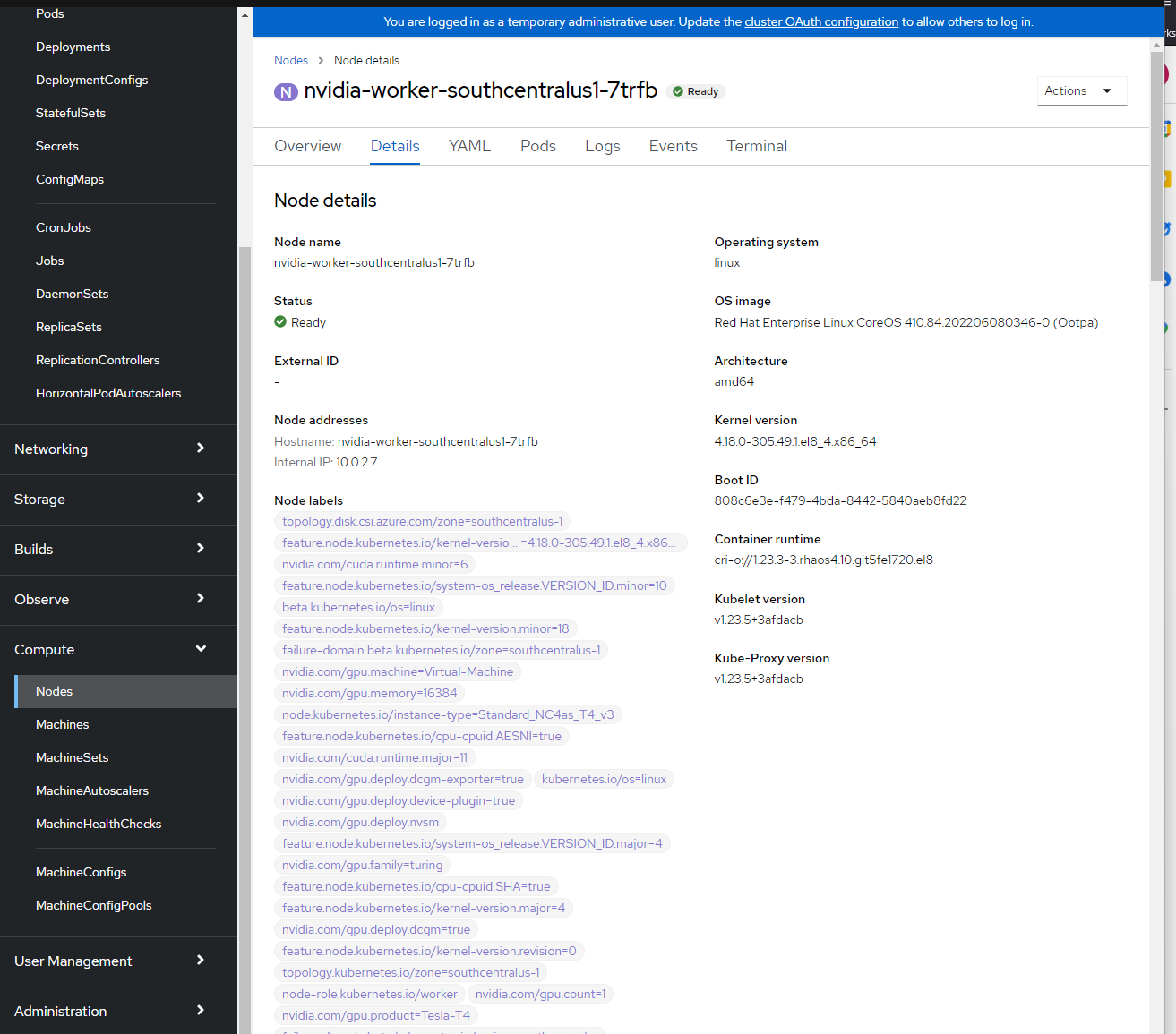
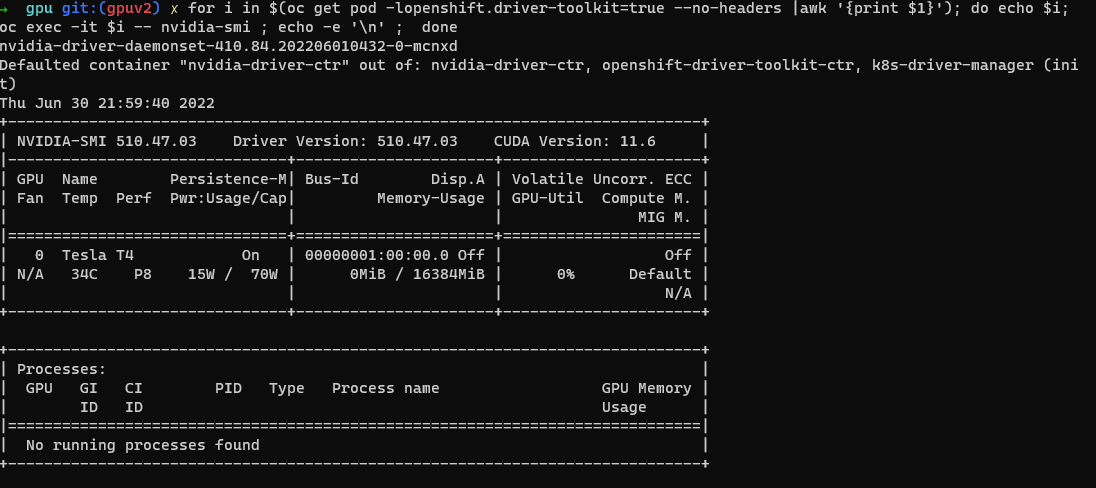
Weryfikacja narzędzia NVIDIA SMI.
oc project nvidia-gpu-operator for i in $(oc get pod -lopenshift.driver-toolkit=true --no-headers |awk '{print $1}'); do echo $i; oc exec -it $i -- nvidia-smi ; echo -e '\n' ; donePowinny zostać wyświetlone dane wyjściowe przedstawiające procesory GPU dostępne na hoście, takie jak ten przykładowy zrzut ekranu. (Różni się w zależności od typu procesu roboczego procesora GPU)
Tworzenie zasobnika w celu uruchomienia obciążenia procesora GPU
oc project nvidia-gpu-operator cat <<EOF | oc apply -f - apiVersion: v1 kind: Pod metadata: name: cuda-vector-add spec: restartPolicy: OnFailure containers: - name: cuda-vector-add image: "quay.io/giantswarm/nvidia-gpu-demo:latest" resources: limits: nvidia.com/gpu: 1 nodeSelector: nvidia.com/gpu.present: true EOFWyświetl dzienniki.
oc logs cuda-vector-add --tail=-1
Uwaga / Notatka
Jeśli wystąpi błąd Error from server (BadRequest): container "cuda-vector-add" in pod "cuda-vector-add" is waiting to start: ContainerCreating, spróbuj uruchomić oc delete pod cuda-vector-add polecenie , a następnie ponownie uruchom instrukcję create powyżej.
Dane wyjściowe powinny być podobne do następujących (w zależności od procesora GPU):
[Vector addition of 5000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done
W przypadku pomyślnego usunięcia zasobnika można usunąć:
oc delete pod cuda-vector-add