Zarządzanie ciągłością działalności biznesowej na platformie Azure
Platforma Azure utrzymuje jeden z najbardziej dojrzałych i szanowanych programów zarządzania ciągłością działalności biznesowej w branży. Celem ciągłości działalności biznesowej na platformie Azure jest tworzenie i rozwijanie możliwości odzyskiwania i odporności dla wszystkich niezależnych usług możliwych do odzyskania, niezależnie od tego, czy usługa jest obsługiwana przez klienta (część oferty platformy Azure) czy wewnętrzną usługą platformy pomocniczej.
Aby zrozumieć ciągłość działalności biznesowej, należy pamiętać, że wiele ofert składa się z wielu usług. Na platformie Azure każda usługa jest statycznie identyfikowana za pomocą narzędzi i jest jednostką miary używaną do ochrony prywatności, zabezpieczeń, spisu, zarządzania ciągłością działalności biznesowej i innych funkcji. Aby prawidłowo zmierzyć możliwości usługi, trzy elementy osób, procesów i technologii są uwzględniane dla każdej usługi, niezależnie od typu usługi.
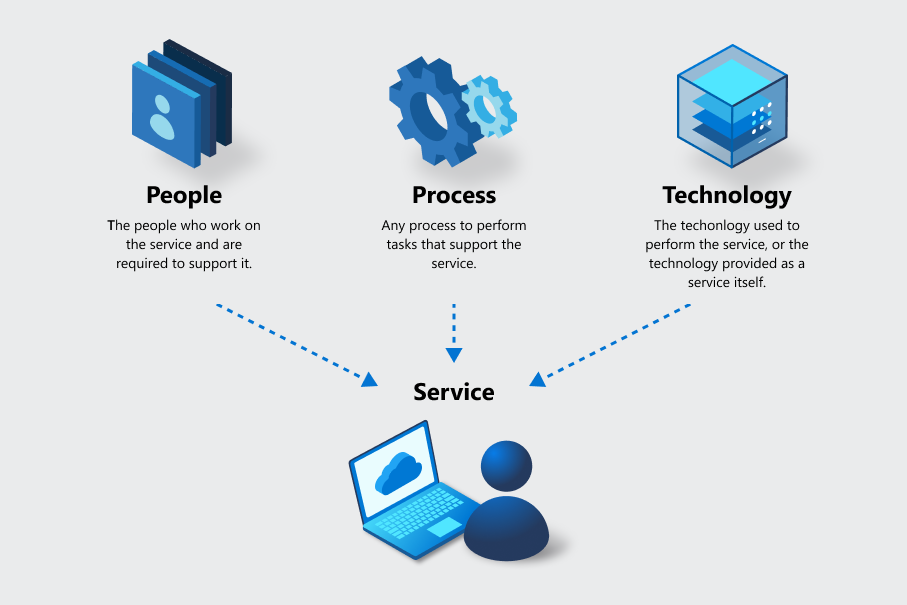
Na przykład:
- Jeśli istnieje proces biznesowy oparty na osobach, takich jak dział pomocy technicznej lub zespół, dostarczanie usług jest tym, co robią. Osoby używają procesów i technologii do wykonywania usługi.
- Jeśli istnieje technologia jako usługa, taka jak Azure Virtual Machines, dostarczanie usługi jest technologią wraz z osobami i procesami, które obsługują jej działanie.
Wspólna odpowiedzialność
Wiele ofert oferowanych przez platformę Azure wymaga skonfigurowania odzyskiwania po awarii w wielu regionach i nie ponosi odpowiedzialności firmy Microsoft. Nie wszystkie usługi platformy Azure automatycznie replikują dane lub automatycznie wracają z regionu, który zakończył się niepowodzeniem, aby przeprowadzić replikację krzyżową do innego regionu z włączoną obsługą. W takich przypadkach ponosisz odpowiedzialność za konfigurowanie odzyskiwania i replikacji.
Firma Microsoft zapewnia dostępność podstawowej infrastruktury i usług platformy. Jednak w niektórych scenariuszach użycie wymaga zduplikowania wdrożeń i magazynu w pojemności obejmującej wiele regionów, jeśli zdecydujesz się na to. Te przykłady ilustrują model wspólnej odpowiedzialności. Jest to podstawowy filar strategii ciągłości działania i odzyskiwania po awarii.
Podział odpowiedzialności
W dowolnym lokalnym centrum danych jesteś właścicielem całego stosu. Podczas przenoszenia zasobów do chmury niektóre obowiązki są przenoszone do firmy Microsoft. Na poniższym diagramie przedstawiono obszary i podział odpowiedzialności między Tobą a firmą Microsoft zgodnie z typem wdrożenia.
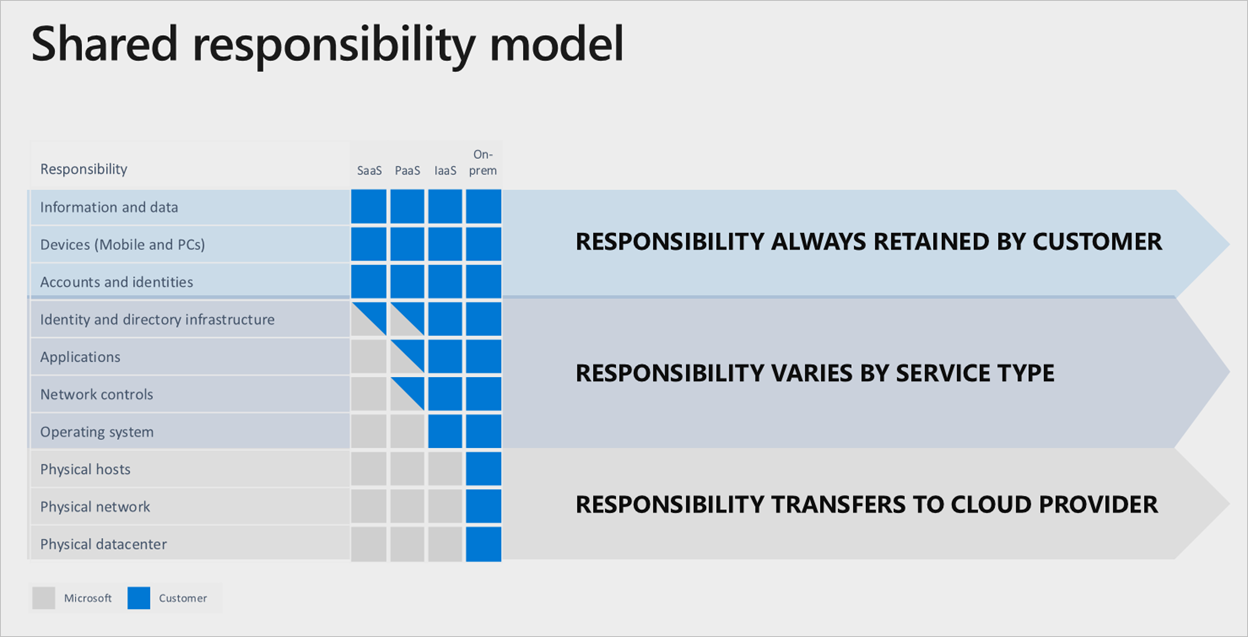
Dobrym przykładem modelu wspólnej odpowiedzialności jest wdrożenie maszyn wirtualnych. Jeśli chcesz skonfigurować replikację między regionami pod kątem odporności w przypadku awarii regionu, musisz wdrożyć zduplikowany zestaw maszyn wirtualnych w alternatywnym regionie włączonym. Platforma Azure nie replikuje tych usług automatycznie, jeśli wystąpi awaria. Twoim zadaniem jest wdrożenie niezbędnych zasobów. Musisz mieć proces ręcznej zmiany regionów podstawowych lub należy użyć usługi Traffic Manager do wykrywania i automatycznego przełączania w tryb failover.
Wszystkie usługi odzyskiwania po awarii z obsługą klienta mają publiczną dokumentację, która cię poprowadzi. Aby zapoznać się z przykładem publicznej dokumentacji dotyczącej odzyskiwania po awarii z obsługą klienta, zobacz Azure Data Lake Analytics.
Aby uzyskać więcej informacji na temat modelu wspólnej odpowiedzialności, zobacz Centrum zaufania firmy Microsoft.
Zgodność z ciągłością działania: odpowiedzialność na poziomie usługi
Każda usługa jest wymagana do ukończenia rekordów odzyskiwania po awarii ciągłości działania w narzędziu Azure Business Continuity Manager. Właściciele usług mogą używać narzędzia do pracy w modelu federacyjnym w celu ukończenia i uwzględnienia wymagań, które obejmują:
Właściwości usługi: definiuje usługę oraz sposób uzyskiwania odzyskiwania po awarii i odporności oraz identyfikuje osobę odpowiedzialną za odzyskiwanie po awarii (dla technologii). Aby uzyskać szczegółowe informacje na temat własności odzyskiwania, zobacz dyskusję na temat modelu wspólnej odpowiedzialności w poprzedniej sekcji i diagramie.
Analiza wpływu na działalność biznesową: Ta analiza pomaga właścicielowi usługi zdefiniować cel czasu odzyskiwania (RTO) i cel punktu odzyskiwania (RPO) w oparciu o krytyczność usługi w tabeli skutków. Działania, prawne, prawne, prawne, wizerunki marki i wpływy finansowe są używane jako cele docelowe do odzyskania.
Uwaga
Firma Microsoft nie publikuje obiektów RTO ani RPO dla usług, ponieważ te dane są przeznaczone tylko dla miar wewnętrznych. Wszystkie obietnice i miary klienta są oparte na umowie SLA, ponieważ obejmuje szerszy zakres w porównaniu z celami czasu odzyskiwania lub cel punktu odzyskiwania, który ma zastosowanie tylko w katastrofacznej utracie.
Zależności: każda usługa mapuje zależności (inne usługi), których wymaga, niezależnie od tego, jak krytyczne i jest mapowane na środowisko uruchomieniowe, wymagane tylko do odzyskiwania lub obu tych usług. Jeśli istnieją zależności magazynu, inne dane są mapowane, które definiują przechowywane dane i jeśli na przykład wymagają migawek do punktu w czasie.
Pracownicy: Jak wspomniano w definicji usługi, ważne jest, aby znać lokalizację i ilość pracowników, którzy mogą wspierać usługę, zapewniając brak pojedynczych punktów awarii, a jeśli kluczowi pracownicy są rozproszeni, aby uniknąć niepowodzeń przez konkubację w jednej lokalizacji.
Zewnętrzni dostawcy: Firma Microsoft utrzymuje kompleksową listę dostawców zewnętrznych, a dostawcy uznani za krytyczne są mierzone pod kątem możliwości. W przypadku zidentyfikowania przez usługę jako zależności możliwości dostawcy są porównywane z potrzebami usługi w celu zapewnienia awarii innych firm nie zakłóca usług platformy Azure.
Ocena odzyskiwania: ta ocena jest unikatowa dla programu Azure Business Continuity Management. Ta ocena mierzy kilka kluczowych elementów w celu utworzenia oceny odporności:
- Gotowość do przełączenia w tryb failover: chociaż może istnieć proces, może to nie być pierwszy wybór dla krótkoterminowych awarii.
- Automatyzacja trybu failover.
- Automatyzacja decyzji o przejściu w tryb failover.
Najbardziej niezawodny i najkrótszy czas pracy w trybie failover to usługa, która jest zautomatyzowana i nie wymaga żadnej decyzji człowieka. Zautomatyzowana usługa używa monitorowania pulsu lub transakcji syntetycznych w celu określenia, czy usługa nie działa i uruchamia natychmiastowe korygowanie.
Plan odzyskiwania i test: platforma Azure wymaga, aby każda usługa miała szczegółowy plan odzyskiwania i przetestować ten plan tak, jakby usługa uległa awarii z powodu katastrofalnego przestoju. Plany odzyskiwania są wymagane do napisania, aby ktoś z podobnymi umiejętnościami i dostępem mógł wykonać zadania. Napisany plan unika polegania na dostępnych ekspertach w danej dziedzinie.
Testowanie odbywa się na kilka sposobów, w tym samodzielne testowanie w środowisku produkcyjnym lub niemal produkcyjnym, a w ramach przechodzenia do szczegółów w pełnym regionie platformy Azure w zestawach regionów kanarowych. Te włączone regiony są identyczne z regionami produkcyjnymi, ale można je wyłączyć bez wpływu na usługi. Testowanie jest uznawane za zintegrowane, ponieważ wszystkie usługi mają wpływ jednocześnie.
Włączanie klienta: Jeśli jesteś odpowiedzialny za skonfigurowanie odzyskiwania po awarii, platforma Azure musi mieć wskazówki dotyczące dokumentacji dostępnej publicznie. W przypadku wszystkich takich usług linki są dostarczane do dokumentacji i szczegółów dotyczących procesu.
Weryfikowanie zgodności ciągłości działania
Po ukończeniu rekordu zarządzania ciągłością działania usługi należy przesłać ją do zatwierdzenia. Przypisano go do zarządzania ciągłością działalności biznesowej doświadczonym praktykem, który przegląda cały rekord pod kątem kompletności i jakości. Jeśli rekord spełnia wszystkie wymagania, zostanie zatwierdzony. Jeśli tak nie jest, zostanie ona odrzucona z prośbą o przerobienie. Ten proces gwarantuje, że obie strony zgadzają się, że została spełniona zgodność z ciągłością działania i że praca jest zaświadczona tylko przez właściciela usługi. Wewnętrzne zespoły ds. inspekcji i zgodności platformy Azure wykonują również okresowe losowe próbkowanie, aby zapewnić, że najlepsze dane są przesyłane.
Testowanie usług
Firma Microsoft i Platforma Azure przeprowadzają obszerne testy pod kątem odzyskiwania po awarii i gotowości strefy dostępności. Usługi są testowane samodzielnie w środowisku produkcyjnym lub przedprodukcyjnym, aby zademonstrować niezależną możliwość odzyskiwania dla usług, które nie są zależne od głównych trybów failover platformy.
Aby zapewnić, że usługi mogą podobnie odzyskiwać w rzeczywistym scenariuszu w dół regionu, testowanie typu "pull-the-plug" odbywa się w środowiskach kanargu, które są w pełni wdrożone regiony pasujące do środowiska produkcyjnego. Na przykład klastry, stojaki i jednostki zasilania są dosłownie wyłączone w celu symulowania całkowitej awarii regionu.
Podczas tych testów platforma Azure używa tego samego procesu produkcyjnego do wykrywania, powiadamiania, odpowiedzi i odzyskiwania. Żadna osoba nie oczekuje próbnego, a inżynierowie polegali na odzyskiwaniu są normalnymi zasobami rotacji wywołań. Ten czas pozwala uniknąć w zależności od ekspertów w danej dziedzinie, którzy mogą nie być dostępne podczas rzeczywistego wydarzenia.
Zawarte w tych testach to usługi, w których ponosisz odpowiedzialność za konfigurowanie odzyskiwania po awarii zgodnie z publiczną dokumentacją firmy Microsoft. Zespoły ds. obsługi tworzą wystąpienia podobne do klienta, aby pokazać, że odzyskiwanie po awarii z obsługą klienta działa zgodnie z oczekiwaniami i że podane instrukcje są dokładne.
Aby uzyskać więcej informacji na temat certyfikatów, zobacz Centrum zaufania Microsoft i sekcję dotyczącą zgodności.
Następne kroki
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla