Czym jest odzyskiwanie po awarii?
Awaria jest pojedynczym, głównym zdarzeniem o większym i długotrwałym wpływie, niż aplikacja może ograniczyć swoją częścią projektu o wysokiej dostępności. Odzyskiwanie po awarii dotyczy odzyskiwania po wystąpieniu zdarzeń o dużym wpływie, takich jak klęski żywiołowe lub nieudane wdrożenia, które powodują przestoje i utratę danych. Niezależnie od przyczyny najlepszym rozwiązaniem dla awarii jest dobrze zdefiniowany i przetestowany plan odzyskiwania po awarii oraz projekt aplikacji, który aktywnie obsługuje odzyskiwanie po awarii.
Cele odzyskiwania
Kompletny plan odzyskiwania po awarii musi określać następujące krytyczne wymagania biznesowe dla każdego procesu implementowania aplikacji:
Cel punktu odzyskiwania (RPO) to maksymalny czas trwania akceptowalnej utraty danych. Cel punktu odzyskiwania jest mierzony w jednostkach czasu, a nie w ilościach, takich jak "30 minut danych" lub "cztery godziny danych". Cel punktu odzyskiwania dotyczy ograniczania i odzyskiwania po utracie danych, a nie kradzieży danych.
Cel czasu odzyskiwania (RTO) to maksymalny czas trwania akceptowalnego przestoju, w którym "przestój" jest definiowany przez specyfikację. Jeśli na przykład dopuszczalny czas trwania przestoju w awarii wynosi osiem godzin, cel czasu odzyskiwania wynosi osiem godzin.
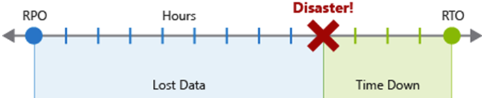
Każdy główny proces lub obciążenie implementowane przez aplikację powinny mieć oddzielne wartości celu punktu odzyskiwania i celu punktu odzyskiwania, sprawdzając ryzyko scenariusza awarii i potencjalne strategie odzyskiwania. Proces określania celu punktu odzyskiwania i celu odzyskiwania skutecznie tworzy wymagania odzyskiwania po awarii dla aplikacji w wyniku unikatowych problemów biznesowych (kosztów, wpływu, utraty danych itp.).
Projektowanie po kątem odzyskiwania po awarii
Odzyskiwanie po awarii nie jest funkcją automatyczną, ale musi być zaprojektowane, skompilowane i przetestowane. Aby obsługiwać solidną strategię odzyskiwania po awarii, należy utworzyć aplikację z myślą o odzyskiwania po awarii od podstaw. Platforma Azure oferuje usługi, funkcje i wskazówki ułatwiające obsługę odzyskiwania po awarii podczas tworzenia aplikacji.
Odzyskiwanie danych
Podczas awarii istnieją dwie główne metody przywracania danych: kopie zapasowe i replikacja.
Kopia zapasowa przywraca dane do określonego punktu w czasie. Korzystając z kopii zapasowych, można zapewnić proste, bezpieczne i ekonomiczne rozwiązania do tworzenia kopii zapasowych i odzyskiwania danych do chmury platformy Microsoft Azure. Usługa Azure Backup umożliwia tworzenie długotrwałych migawek danych tylko do odczytu do użycia w odzyskiwaniu.
Replikacja danych tworzy kopie danych na żywo w czasie rzeczywistym lub niemal w czasie rzeczywistym w wielu replikach magazynu danych z minimalnej utraty danych. Celem replikacji jest synchronizowanie replik z możliwie najmniejszym opóźnieniem przy zachowaniu czasu reakcji aplikacji. Większość w pełni funkcjonalnych systemów baz danych i innych produktów i usług magazynu danych obejmuje pewnego rodzaju replikację jako ściśle zintegrowaną funkcję ze względu na wymagania dotyczące funkcjonalności i wydajności. Przykładem jest magazyn geograficznie nadmiarowy (GRS).
Różne projekty replikacji mają różne priorytety dotyczące spójności danych, wydajności i kosztów.
Aktywna replikacja wymaga jednoczesnego aktualizowania wielu replik, co gwarantuje spójność, ale kosztem przepływności.
Replikacja pasywna wykonuje synchronizację w tle, usuwając replikację jako ograniczenie wydajności aplikacji, ale zwiększając cel punktu odzyskiwania.
Replikacja aktywna-aktywna lub wielowładna umożliwia jednoczesne używanie wielu replik, umożliwiając równoważenie obciążenia kosztem komplikowania spójności danych.
Replikacja aktywna-pasywna rezerwuje repliki do użycia na żywo tylko podczas pracy w trybie failover.
Uwaga
Większość w pełni funkcjonalnych systemów baz danych i innych produktów i usług magazynu danych obejmuje pewnego rodzaju replikację, taką jak magazyn geograficznie nadmiarowy (GRS), ze względu na ich wymagania dotyczące funkcjonalności i wydajności.
Tworzenie odpornych aplikacji
Scenariusze awarii często powodują również przestoje, niezależnie od tego, czy z powodu problemów z łącznością sieciową, awarii centrum danych, uszkodzonych maszyn wirtualnych lub uszkodzonych wdrożeń oprogramowania. W większości przypadków odzyskiwanie aplikacji obejmuje przejście w tryb failover do oddzielnego, działającego wdrożenia. W związku z tym może być konieczne odzyskanie procesów w innym regionie świadczenia usługi Azure w przypadku awarii na dużą skalę. Dodatkowe zagadnienia mogą obejmować: lokalizacje odzyskiwania, liczbę zreplikowanych środowisk oraz sposób konserwacji tych środowisk.
W zależności od projektu aplikacji można użyć kilku różnych strategii i funkcji platformy Azure, takich jak usługa Azure Site Recovery, aby poprawić obsługę odzyskiwania procesów przez aplikację po awarii.
Funkcje odzyskiwania po awarii specyficzne dla usługi
Większość usług, które działają na platformie Azure jako usługa (PaaS), takich jak aplikacja systemu Azure Service, udostępnia funkcje i wskazówki dotyczące obsługi odzyskiwania po awarii. W niektórych scenariuszach można używać funkcji specyficznych dla usługi do obsługi szybkiego odzyskiwania. Na przykład usługa Azure SQL Server obsługuje replikację geograficzną w celu szybkiego przywrócenia usługi w innym regionie. Usługa Azure App Service oferuje funkcję tworzenia kopii zapasowych i przywracania, a dokumentacja zawiera wskazówki dotyczące używania usługi Azure Traffic Manager, która umożliwia kierowanie ruchu do regionu pomocniczego.
Następne kroki
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla