Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule omówimy kroki konfigurowania wysokiej dostępności (HA) w dużych instancjach HANA w systemie operacyjnym SUSE przy użyciu urządzenia typu fencing.
Uwaga
Ten przewodnik pochodzi z pomyślnego testowania konfiguracji w środowisku microsoft HANA Large Instances. Zespół zarządzania usługami firmy Microsoft dla dużych wystąpień HANA nie obsługuje systemu operacyjnego. Aby uzyskać informacje na temat rozwiązywania problemów lub wyjaśnienia dotyczące warstwy systemu operacyjnego, skontaktuj się z systemem SUSE.
Zespół zarządzania usługami firmy Microsoft konfiguruje i w pełni obsługuje urządzenie ogrodzeniowe. Może pomóc w rozwiązywaniu problemów z urządzeniami ogrodzenia.
Wymagania wstępne
Aby skonfigurować wysoką dostępność przy użyciu klastrowania SUSE, należy wykonać następujące kroki:
- Aprowizuj duże wystąpienia platformy HANA.
- Zainstaluj i zarejestruj system operacyjny przy użyciu najnowszych poprawek.
- Połącz serwery dużych wystąpień HANA z serwerem SMT, aby uzyskać poprawki i pakiety.
- Skonfiguruj protokół czasu sieciowego (serwer czasu NTP).
- Przeczytaj i zrozum najnowszą dokumentację SUSE dotyczącą konfiguracji wysokiej dostępności.
Szczegóły instalacji
W tym przewodniku użyto następującej konfiguracji:
- System operacyjny: SLES 12 SP1 dla systemu SAP
- Duże instancje HANA: 2xS192 (cztery gniazda, 2 TB)
- Wersja HANA: HANA 2.0 SP1
- Nazwy serwerów: sapprdhdb95 (node1) i sapprdhdb96 (node2)
- Urządzenie ogrodzeniowe: oparte na protokole iSCSI
- NTP w jednym z węzłów dużych instancji HANA
Podczas konfigurowania dużych wystąpień HANA z replikacją systemu HANA, możesz zażądać, aby zespół Microsoft ds. zarządzania usługami skonfigurował urządzenie do zabezpieczania. Zrób to w momencie wdrożenia.
Jeśli jesteś istniejącym klientem z już aprowizowaną usługą HANA Large Instances, nadal możesz skonfigurować urządzenie ogrodzenia. Podaj następujące informacje zespołowi zarządzania usługami firmy Microsoft w formularzu żądania obsługi (SRF). Plik SRF można uzyskać za pośrednictwem Menedżera konta technicznego lub kontaktu z firmy Microsoft w celu wdrożenia dużych instancji HANA.
- Nazwa serwera i adres IP serwera (na przykład myhanaserver1 i 10.35.0.1)
- Lokalizacja (na przykład Wschodnie stany USA)
- Nazwa klienta (na przykład Microsoft)
- Identyfikator systemu HANA (SID) (na przykład H11)
Po skonfigurowaniu urządzenia ogrodzenia zespół zarządzania usługami firmy Microsoft udostępni nazwę IBD i adres IP magazynu iSCSI. Te informacje umożliwiają skonfigurowanie konfiguracji ogrodzenia.
Wykonaj kroki opisane w poniższych sekcjach, aby skonfigurować wysoką dostępność (HA) za pomocą urządzenia typu fencing.
Identyfikowanie urządzenia SBD
Uwaga
Ta sekcja dotyczy tylko istniejących klientów. Jeśli jesteś nowym klientem, zespół zarządzania usługami firmy Microsoft nada nazwę urządzenia SBD, więc pomiń tę sekcję.
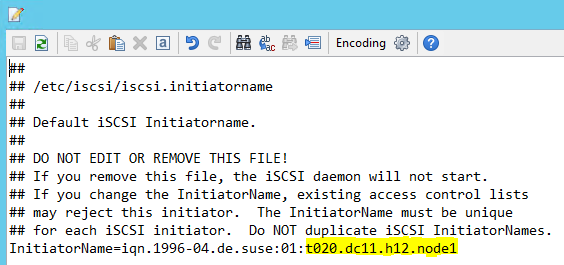
Zmodyfikuj parametr /etc/iscsi/initiatorname.isci , aby:
iqn.1996-04.de.suse:01:<Tenant><Location><SID><NodeNumber>Zarządzanie usługami firmy Microsoft udostępnia ten ciąg. Zmodyfikuj plik na obu węzłach. Jednak numer węzła jest inny w każdym węźle.
Zmodyfikuj plik /etc/iscsid.conf , ustawiając wartości
node.session.timeo.replacement_timeout=5inode.startup = automatic. Zmodyfikuj plik na obu węzłach.Uruchom następujące polecenie odnajdywania na obu węzłach.
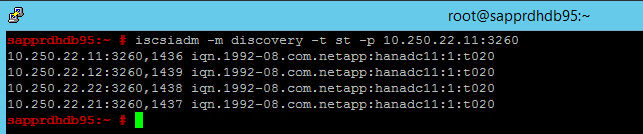
iscsiadm -m discovery -t st -p <IP address provided by Service Management>:3260Wyniki pokazują cztery sesje.
Uruchom następujące polecenie w obu węzłach, aby zalogować się do urządzenia iSCSI.
iscsiadm -m node -lWyniki pokazują cztery sesje.

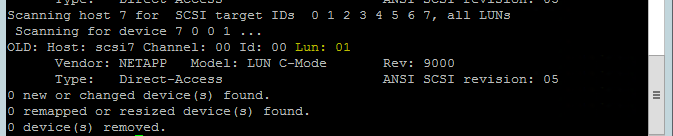
Użyj następującego polecenia, aby uruchomić skrypt ponownego skanowania rescan-scsi-bus.sh . Ten skrypt przedstawia nowe dyski utworzone dla Ciebie. Uruchom go w obu węzłach.
rescan-scsi-bus.shWyniki powinny zawierać numer LUN większy niż zero (na przykład: 1, 2 itd.).
Aby uzyskać nazwę urządzenia, uruchom następujące polecenie w obu węzłach.
fdisk –lW wynikach wybierz urządzenie o rozmiarze 178 MiB.

Inicjowanie urządzenia SBD
Użyj następującego polecenia, aby zainicjować urządzenie SBD w obu węzłach.
sbd -d <SBD Device Name> create
Użyj następującego polecenia w obu węzłach, aby sprawdzić, co zostało zapisane na urządzeniu.
sbd -d <SBD Device Name> dump
Konfigurowanie klastra SUSE HA
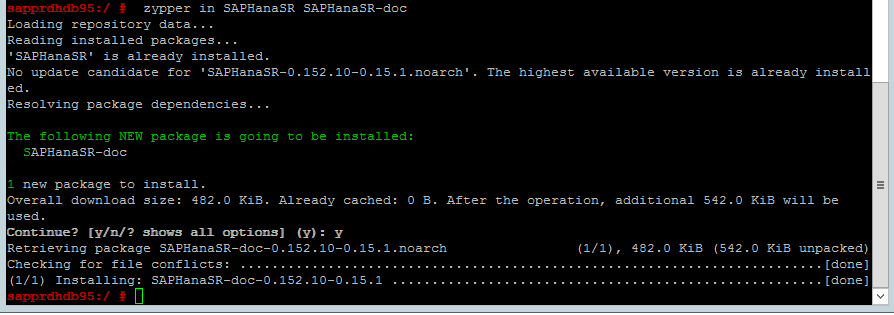
Użyj następującego polecenia, aby sprawdzić, czy wzorce ha_sles i SAPHanaSR-doc są zainstalowane w obu węzłach. Jeśli nie są zainstalowane, zainstaluj je.
zypper in -t pattern ha_sles zypper in SAPHanaSR SAPHanaSR-doc
Skonfiguruj klaster przy użyciu
ha-cluster-initpolecenia lub kreatora yast2. W tym przykładzie używamy kreatora Yast2. Wykonaj ten krok tylko w węźle podstawowym.Przejdź do yast2>wysoko dostępnych>klastrów.
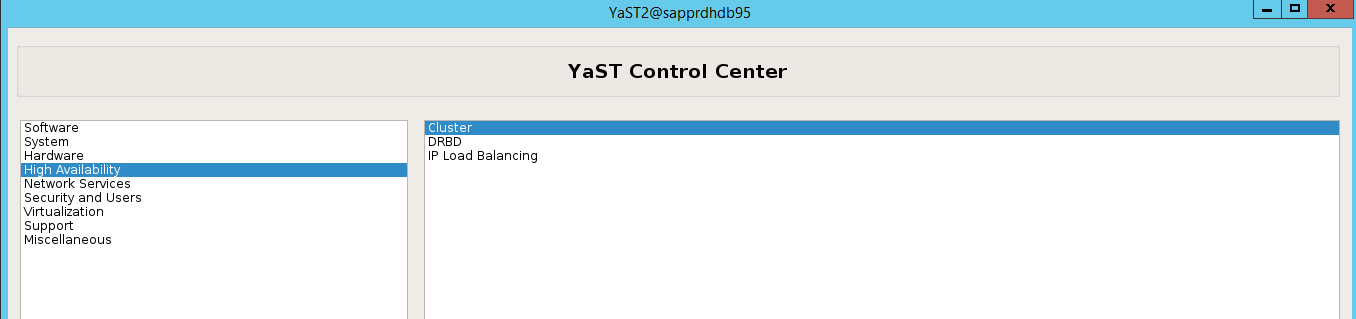
W wyświetlonym oknie dialogowym dotyczącym instalacji pakietu hawk wybierz pozycję Anuluj , ponieważ pakiet halk2 jest już zainstalowany.
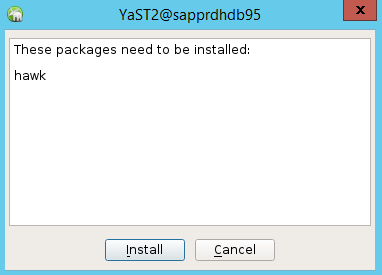
W wyświetlonym oknie dialogowym dotyczącym kontynuowania wybierz pozycję Kontynuuj.
Oczekiwana wartość to liczba wdrożonych węzłów (w tym przypadku 2). Wybierz Dalej.
Dodaj nazwy węzłów, a następnie wybierz pozycję Dodaj sugerowane pliki.
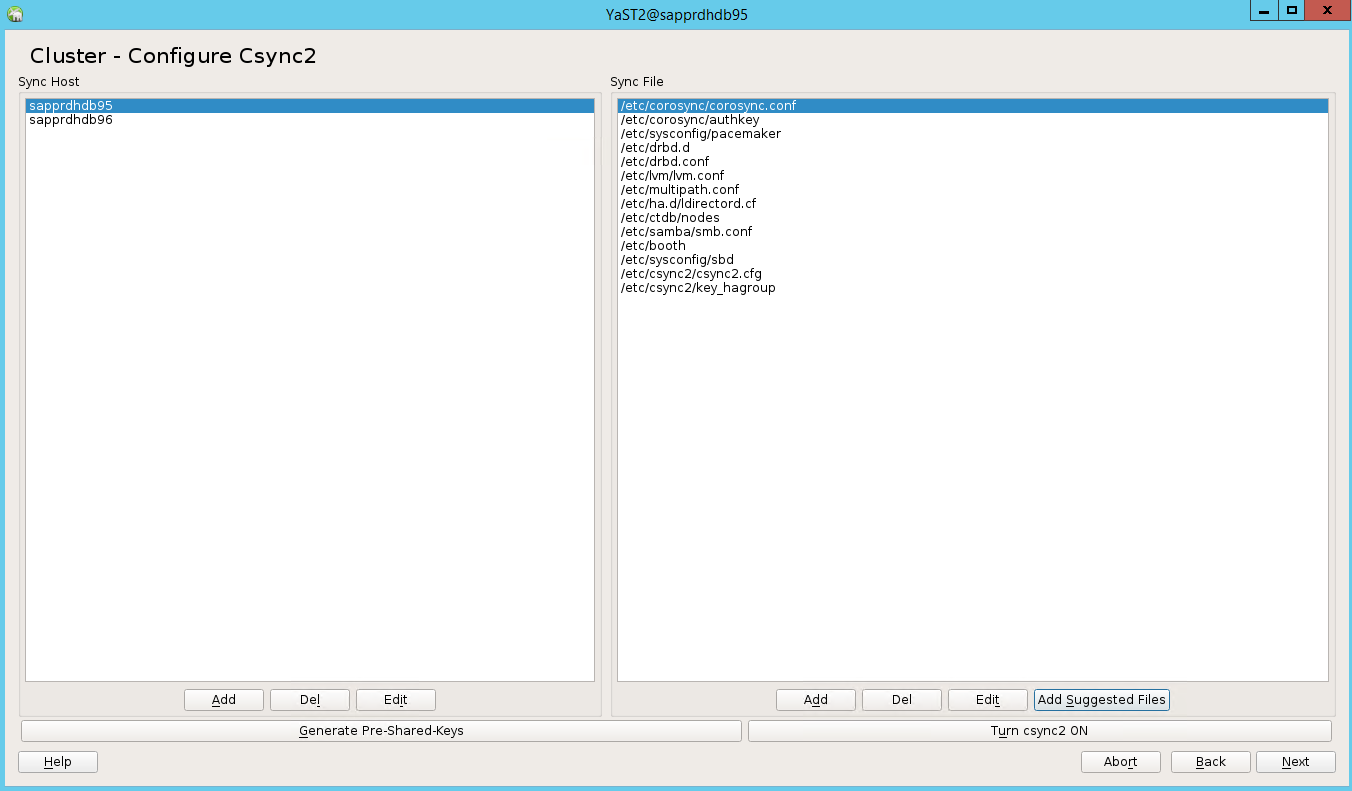
Wybierz pozycję Włącz csync2.
Wybierz pozycję Generuj klucze współdzielone.
W wyświetlonym oknie podręcznym wybierz OK.
Uwierzytelnianie jest wykonywane przy użyciu adresów IP i kluczy wstępnych w Csync2. Plik klucza jest generowany za pomocą polecenia
csync2 -k /etc/csync2/key_hagroup.Ręcznie skopiuj plik key_hagroup do wszystkich członków klastra po jego utworzeniu. Pamiętaj, aby skopiować plik z węzła Node1 do węzła2. Następnie wybierz Dalej.
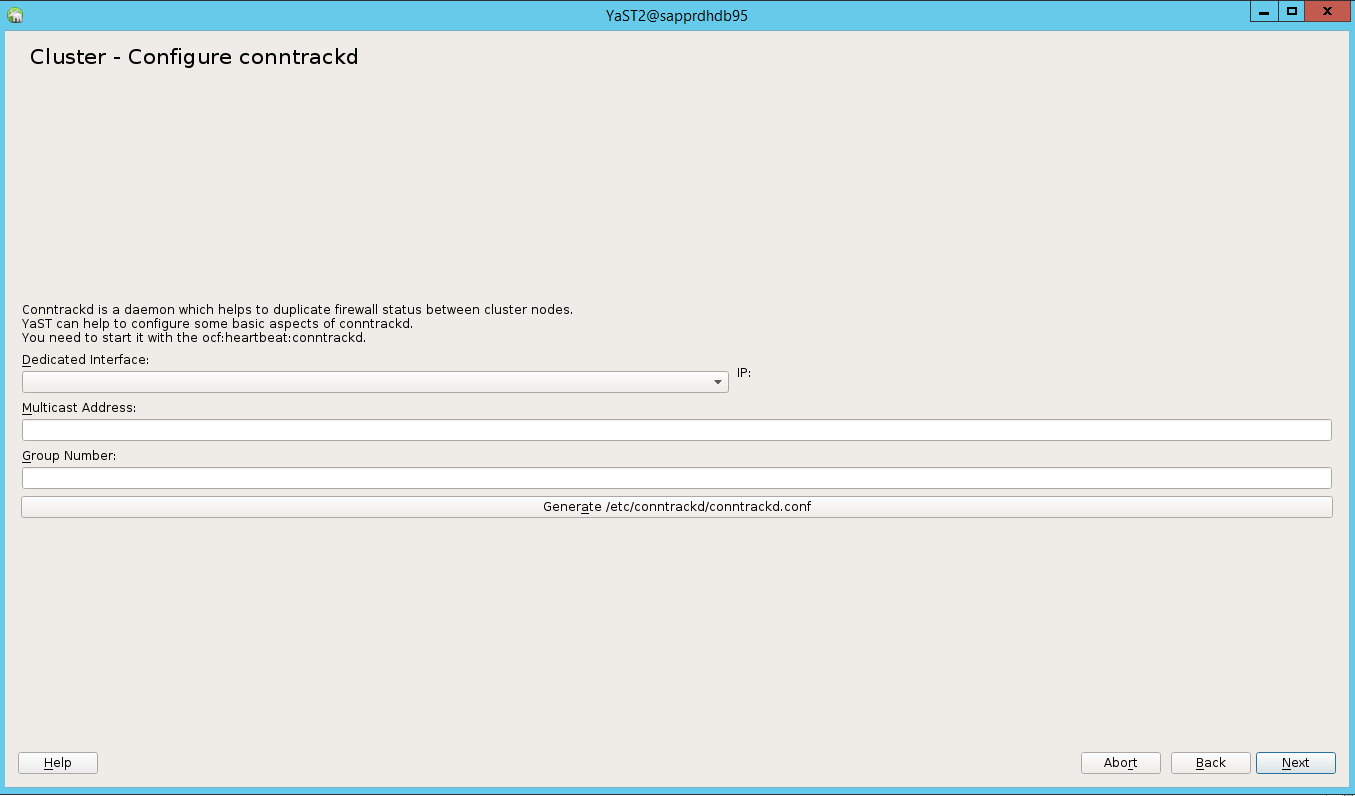
W opcji domyślnej rozruch był wyłączony. Zmień ją na Wł., aby usługa pacemaker została uruchomiona podczas rozruchu. Możesz dokonać wyboru na podstawie wymagań dotyczących konfiguracji.
Wybierz pozycję Dalej, a konfiguracja klastra zostanie ukończona.
Konfigurowanie aplikacji softdog watchdog
Dodaj następujący wiersz do pliku /etc/init.d/boot.local w obu węzłach.
modprobe softdog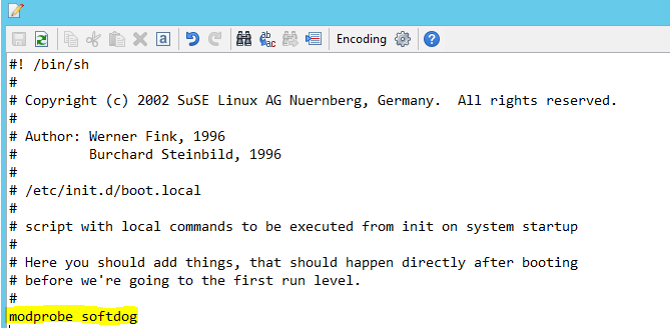
Użyj następującego polecenia, aby zaktualizować plik /etc/sysconfig/sbd w obu węzłach.
SBD_DEVICE="<SBD Device Name>"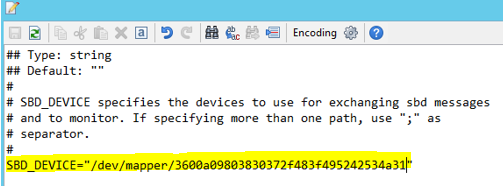
Załaduj moduł jądra w obu węzłach, uruchamiając następujące polecenie.
modprobe softdog
Użyj następującego polecenia, aby upewnić się, że program softdog jest uruchomiony w obu węzłach.
lsmod | grep dog
Użyj następującego polecenia, aby uruchomić urządzenie SBD w obu węzłach.
/usr/share/sbd/sbd.sh start
Użyj następującego polecenia, aby przetestować demona SBD w obu węzłach.
sbd -d <SBD Device Name> listWyniki pokazują dwa wpisy po konfiguracji na obu węzłach.

Wyślij następujący komunikat testowy do jednego z węzłów.
sbd -d <SBD Device Name> message <node2> <message>W drugim węźle (node2) użyj następującego polecenia, aby sprawdzić stan komunikatu.
sbd -d <SBD Device Name> list
Aby wdrożyć konfigurację usługi SBD, zaktualizuj plik /etc/sysconfig/sbd w następujący sposób w obu węzłach.
SBD_DEVICE=" <SBD Device Name>" SBD_WATCHDOG="yes" SBD_PACEMAKER="yes" SBD_STARTMODE="clean" SBD_OPTS=""Użyj następującego polecenia, aby uruchomić usługę pacemaker w węźle podstawowym (node1).
systemctl start pacemaker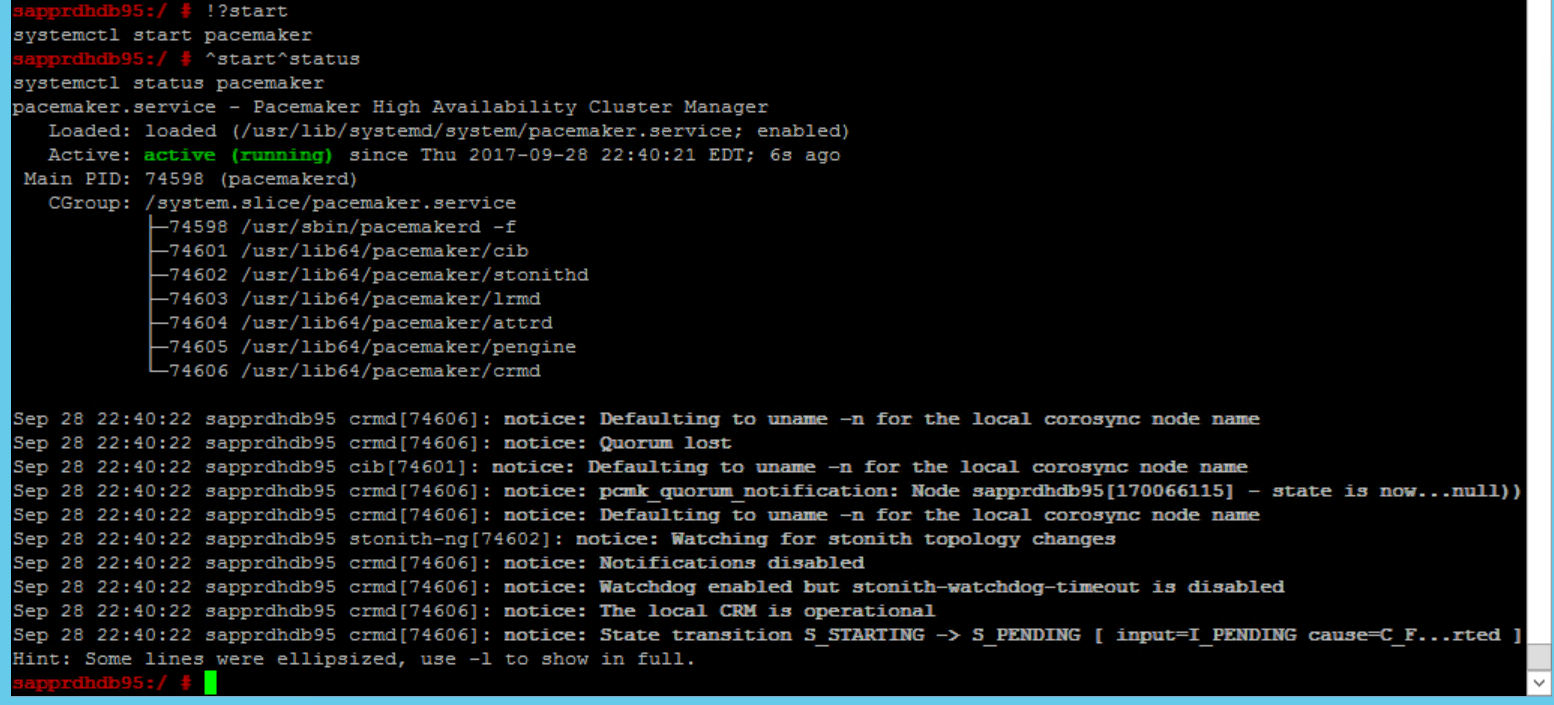
Jeśli usługa pacemaker zakończy się niepowodzeniem, zobacz sekcję Scenariusz 5: usługa Pacemaker kończy się niepowodzeniem w dalszej części tego artykułu.
Dołączanie węzła do klastra
Uruchom następujące polecenie w węźle Node2 , aby umożliwić dołączenie tego węzła do klastra.
ha-cluster-join
Jeśli podczas dołączania do klastra wystąpi błąd, zobacz sekcję Scenariusz 6: Węzeł2 nie może dołączyć do klastra w dalszej części tego artykułu.
Weryfikowanie klastra
Użyj następujących poleceń, aby sprawdzić i opcjonalnie uruchomić klaster po raz pierwszy w obu węzłach.
systemctl status pacemaker systemctl start pacemaker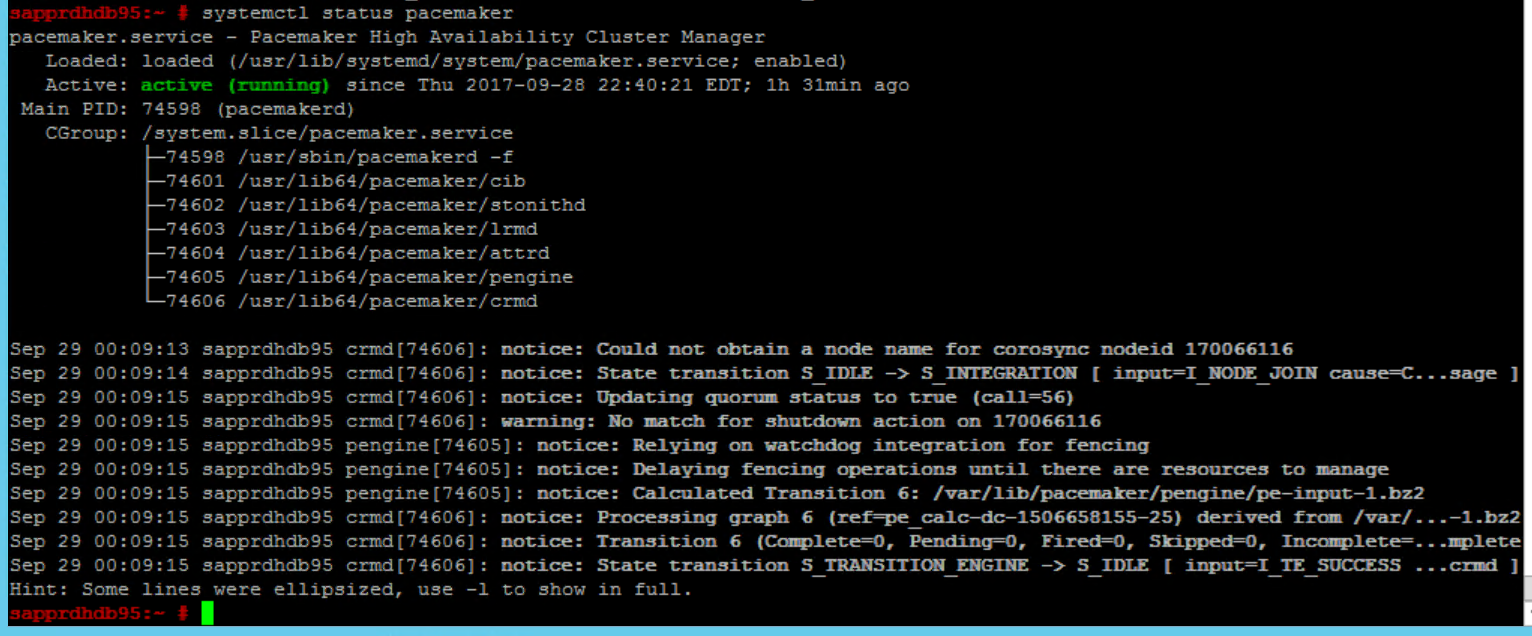
Uruchom następujące polecenie, aby upewnić się, że oba węzły są w trybie online. Można go uruchomić w dowolnym z węzłów klastra.
crm_mon
Możesz również zalogować się do usługi hawk, aby sprawdzić stan klastra:
https://\<node IP>:7630. Domyślny użytkownik to hacluster, a hasło to linux. W razie potrzeby możesz zmienić hasło przy użyciupasswdpolecenia .
Konfigurowanie właściwości i zasobów klastra
W tej sekcji opisano kroki konfigurowania zasobów klastra. W tym przykładzie skonfigurujesz następujące zasoby. Resztę (w razie potrzeby) można skonfigurować, odwołując się do przewodnika SUSE HA.
- Uruchamianie klastra
- Urządzenie ogrodzeniowe
- Wirtualny adres IP
Wykonaj konfigurację tylko w węźle podstawowym .
Utwórz plik bootstrap klastra i skonfiguruj go, dodając następujący tekst.
sapprdhdb95:~ # vi crm-bs.txt # enter the following to crm-bs.txt property $id="cib-bootstrap-options" \ no-quorum-policy="ignore" \ stonith-enabled="true" \ stonith-action="reboot" \ stonith-timeout="150s" rsc_defaults $id="rsc-options" \ resource-stickiness="1000" \ migration-threshold="5000" op_defaults $id="op-options" \ timeout="600"Użyj następującego polecenia, aby dodać konfigurację do klastra.
crm configure load update crm-bs.txt
Skonfiguruj urządzenie ogrodzeniowe, dodając zasób, tworząc plik i dodając tekst w następujący sposób.
# vi crm-sbd.txt # enter the following to crm-sbd.txt primitive stonith-sbd stonith:external/sbd \ params pcmk_delay_max="15"Użyj następującego polecenia, aby dodać konfigurację do klastra.
crm configure load update crm-sbd.txtDodaj wirtualny adres IP zasobu, tworząc plik i dodając następujący tekst.
# vi crm-vip.txt primitive rsc_ip_HA1_HDB10 ocf:heartbeat:IPaddr2 \ operations $id="rsc_ip_HA1_HDB10-operations" \ op monitor interval="10s" timeout="20s" \ params ip="10.35.0.197"Użyj następującego polecenia, aby dodać konfigurację do klastra.
crm configure load update crm-vip.txtUżyj polecenia ,
crm_monaby zweryfikować zasoby.Wyniki pokazują dwa zasoby.

Stan można również sprawdzić pod adresem< IP https://> node:7630/cib/live/state.
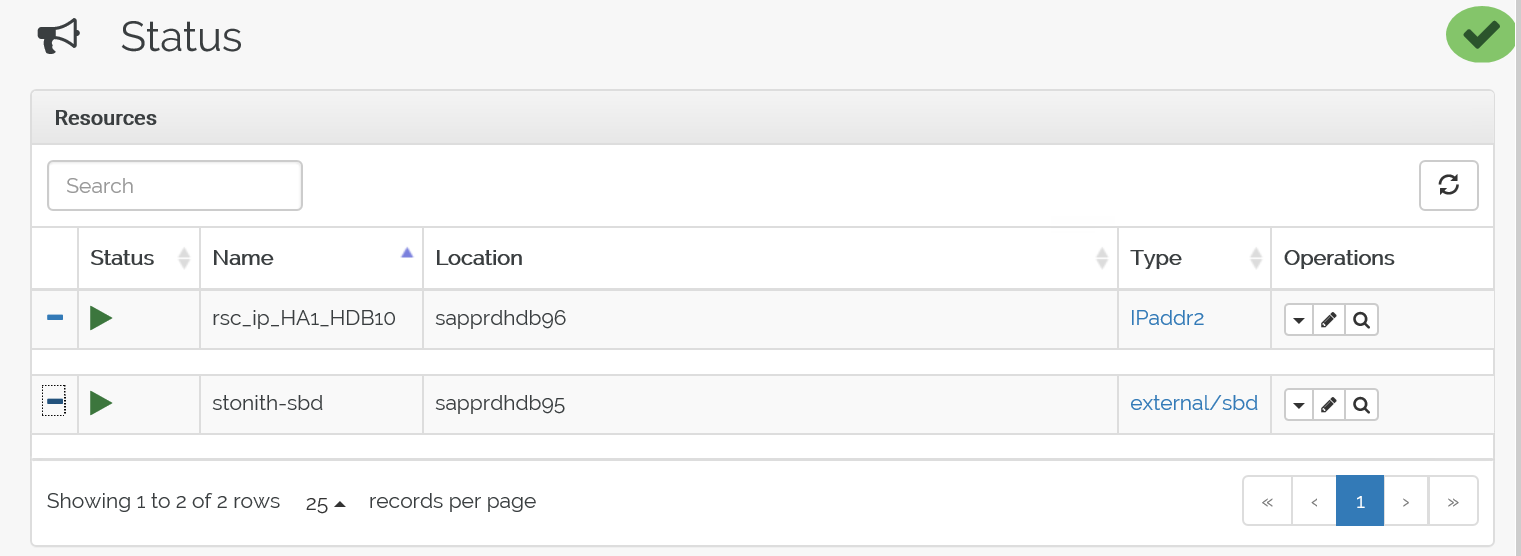
Przetestuj proces awaryjnego przełączania
Aby przetestować proces pracy w trybie failover, użyj następującego polecenia, aby zatrzymać usługę pacemaker w węźle Node1.
Service pacemaker stopZasoby przełączają się na węzeł Node2.
Zatrzymaj usługę pacemakera na węźle Node2, a zasoby zostaną przełączone na węzeł Node1.
Oto stan przed przejściem w tryb failover:
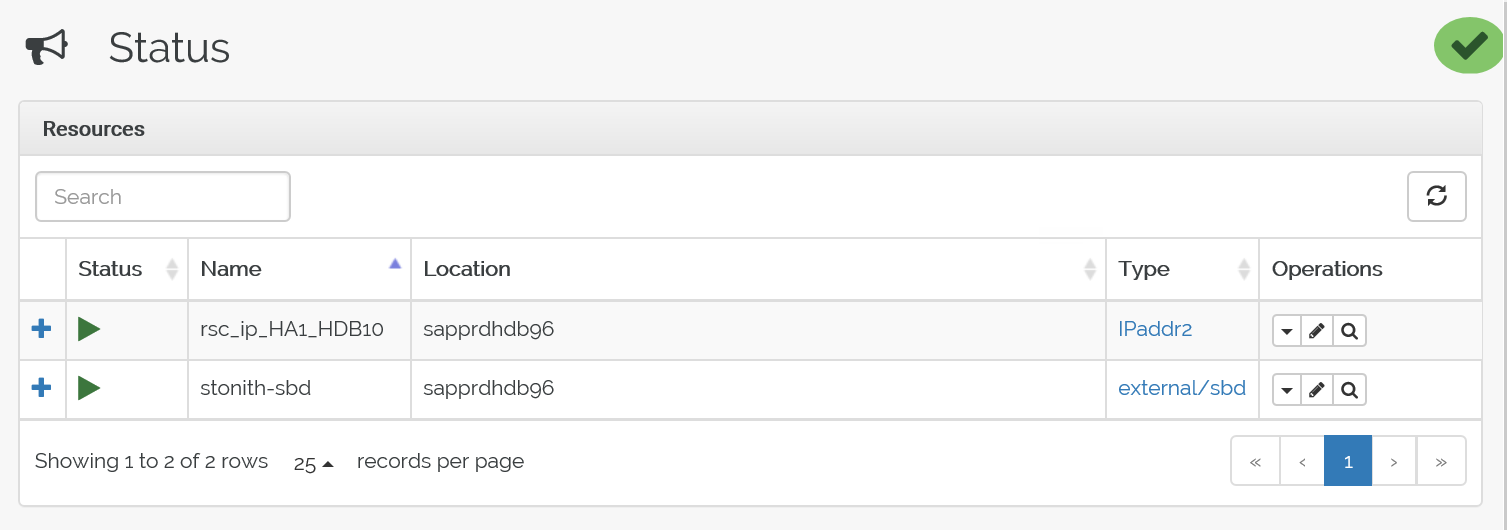
Oto stan po przejściu w tryb failover:
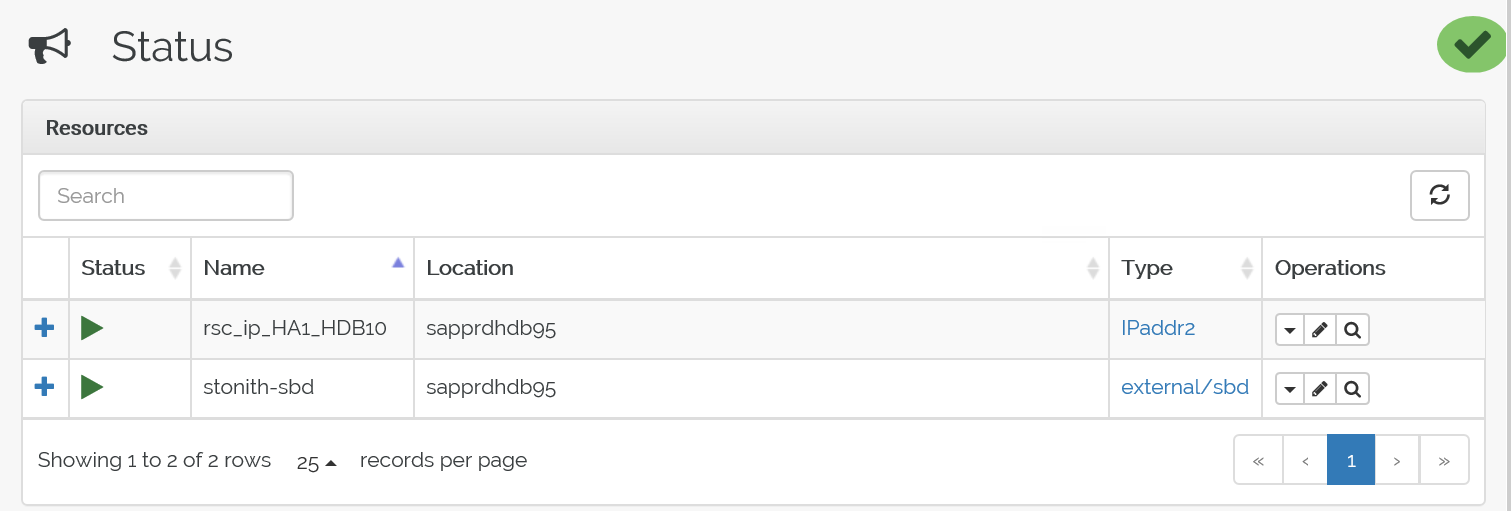

Rozwiązywanie problemów
W tej sekcji opisano scenariusze błędów, które mogą wystąpić podczas instalacji.
Scenariusz 1: Węzeł klastra nie jest online
Jeśli którykolwiek z węzłów nie jest widoczny jako dostępny online w Menedżerze klastra, możesz spróbować tej procedury, aby go przywrócić do trybu online.
Użyj następującego polecenia, aby uruchomić usługę iSCSI.
service iscsid startUżyj następującego polecenia, aby zalogować się do tego węzła iSCSI.
iscsiadm -m node -lOczekiwane dane wyjściowe wyglądają następująco:
sapprdhdb45:~ # iscsiadm -m node -l Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.11,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.12,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.22,3260] (multiple) Logging in to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.21,3260] (multiple) Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.11,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.12,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.22,3260] successful. Login to [iface: default, target: iqn.1992-08.com.netapp:hanadc11:1:t020, portal: 10.250.22.21,3260] successful.
Scenariusz 2: Yast2 nie pokazuje widoku graficznego
Ekran graficzny yast2 służy do konfigurowania klastra wysokiej dostępności w tym artykule. Jeśli plik yast2 nie jest otwarty przy użyciu okna graficznego, jak pokazano, i zgłasza błąd qt, wykonaj następujące kroki, aby zainstalować wymagane pakiety. Jeśli otworzy się z oknem graficznym, możesz pominąć kroki.
Oto przykład błędu Qt:

Oto przykład oczekiwanych danych wyjściowych:
Upewnij się, że zalogowano się jako użytkownik "root" i skonfigurowano protokół SMT do pobierania i instalowania pakietów.
Przejdź do yast>Oprogramowanie>Zarządzanie oprogramowaniem>Zależności, a następnie wybierz Zainstaluj zalecane pakiety.
Uwaga
Wykonaj kroki w obu węzłach, aby uzyskać dostęp do widoku graficznego yast2 z obu węzłów.
Poniższy zrzut ekranu przedstawia oczekiwany ekran.
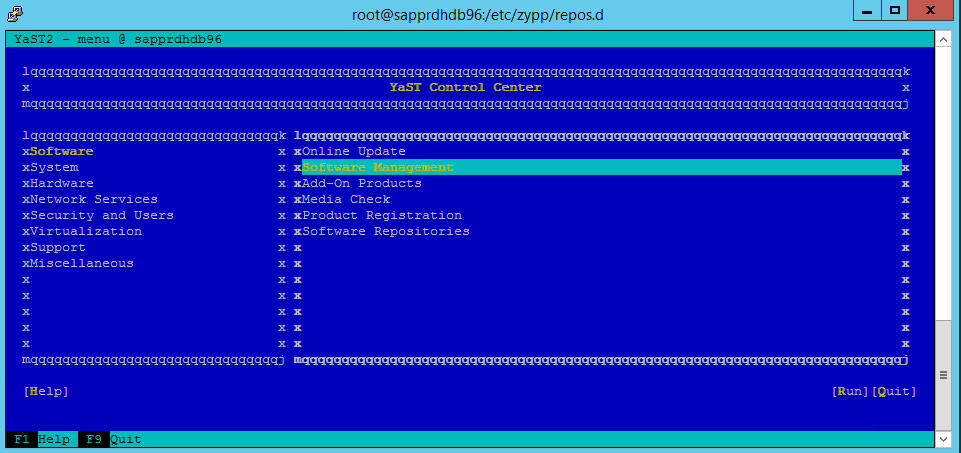
W obszarze Zależności wybierz pozycję Zainstaluj zalecane pakiety.
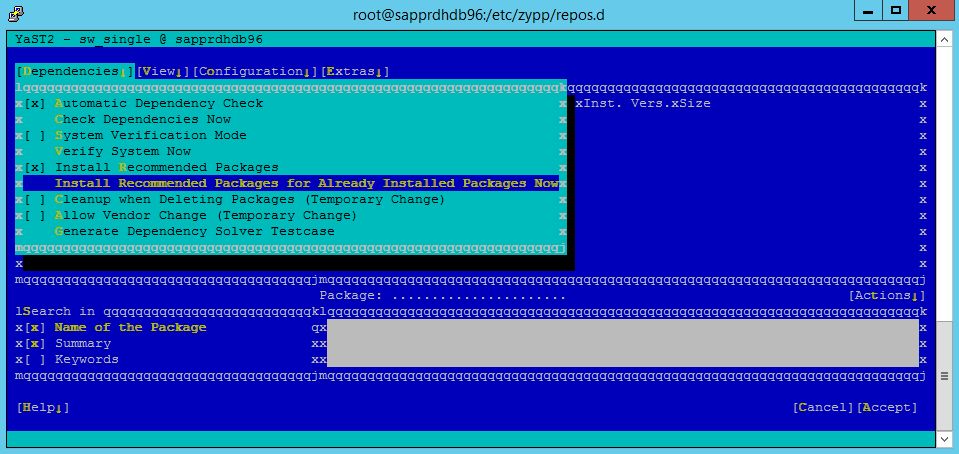
Przejrzyj zmiany i wybierz przycisk OK.
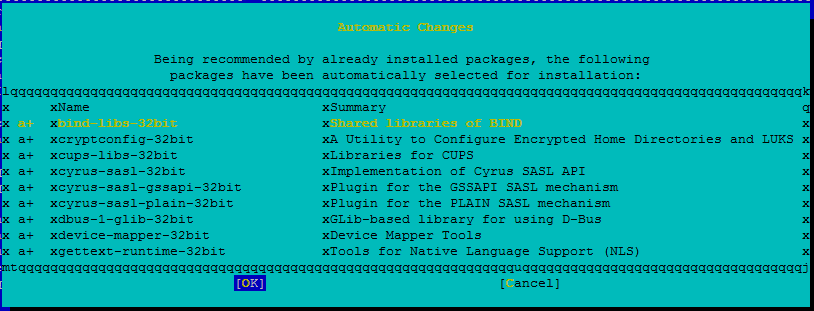
Instalacja pakietu jest kontynuowana.
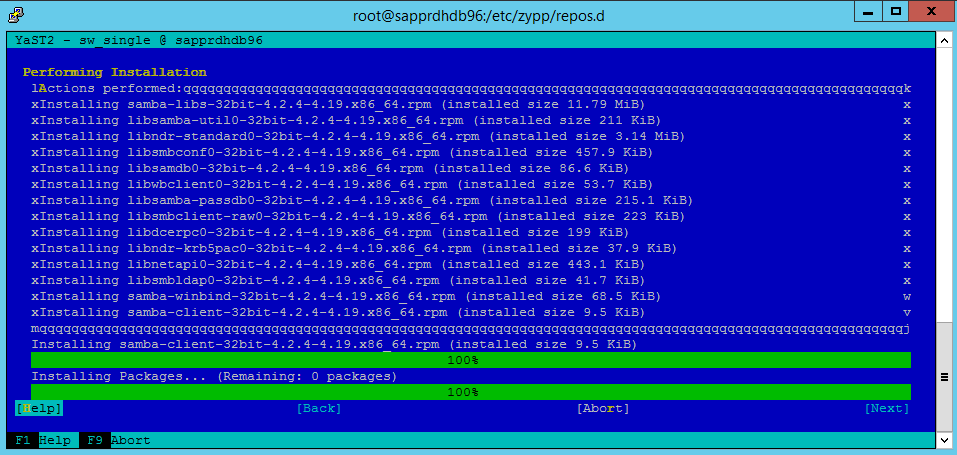
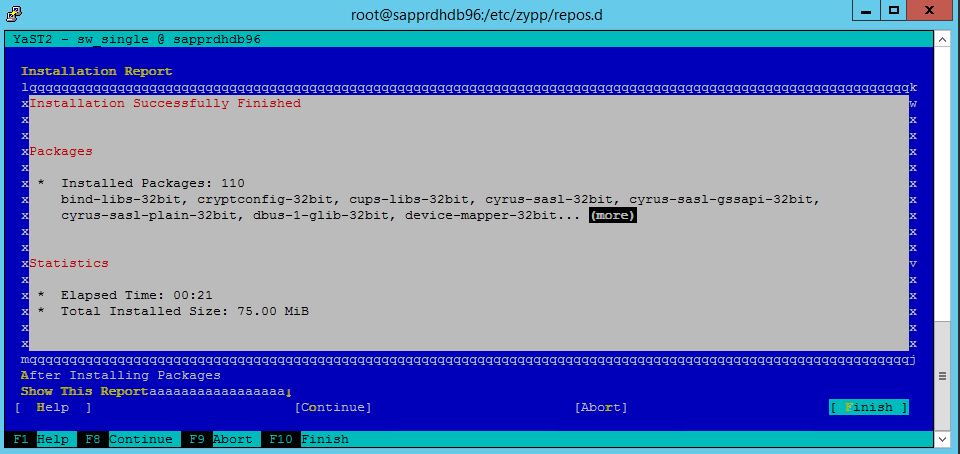
Wybierz Dalej.
Po wyświetleniu ekranu Instalacja zakończona pomyślnie wybierz pozycję Zakończ.
Użyj następujących poleceń, aby zainstalować pakiety libqt4 i libyui-qt.
zypper -n install libqt4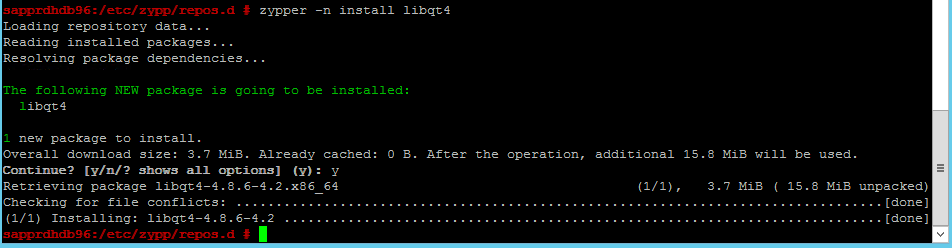
zypper -n install libyui-qt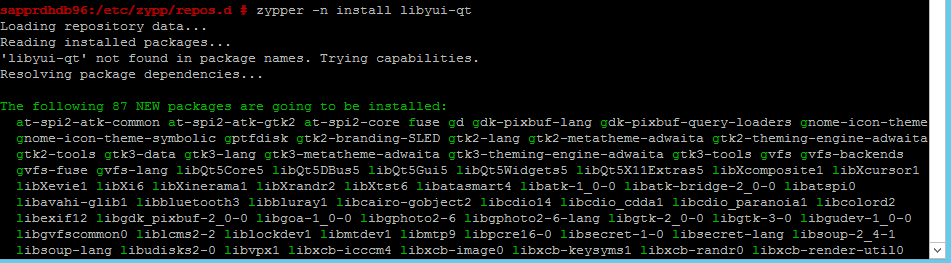

Yast2 może teraz otworzyć widok graficzny.
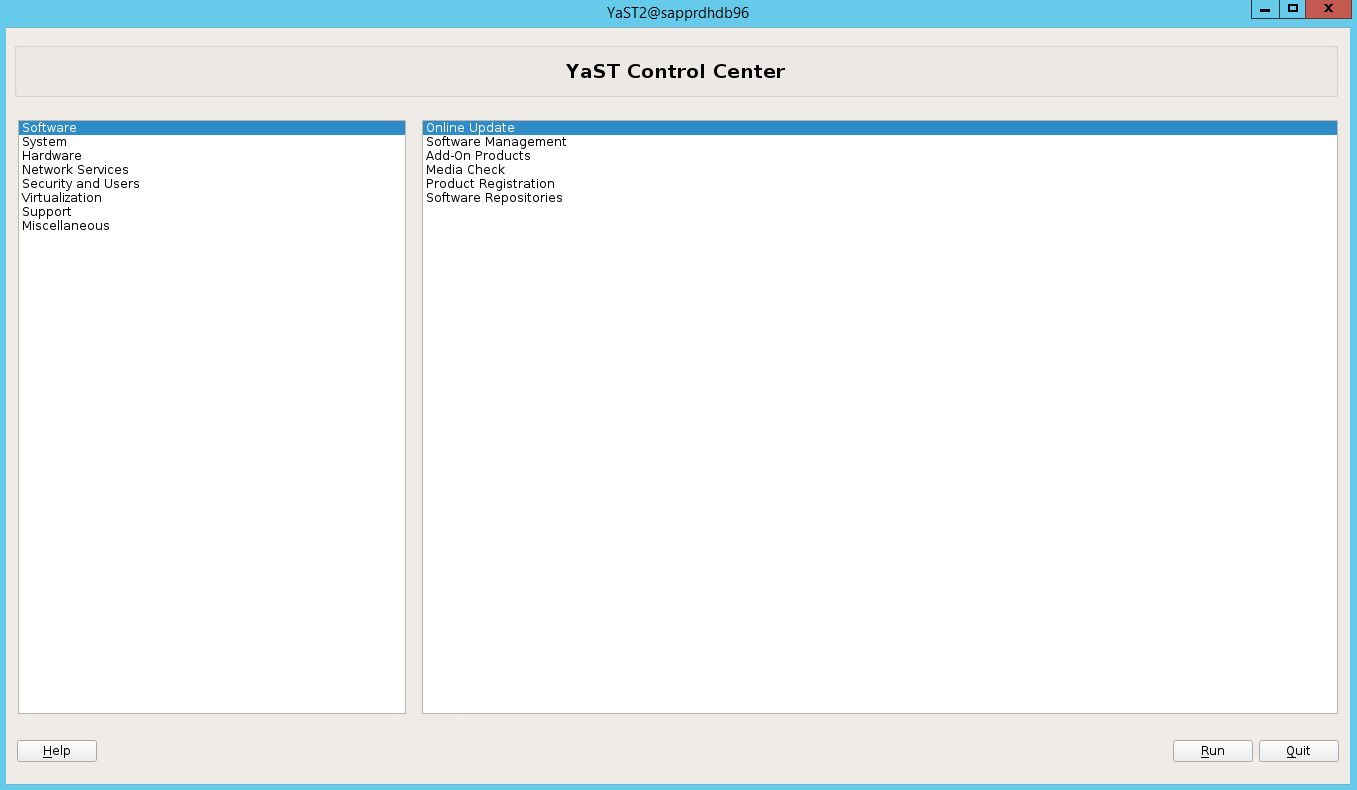
Scenariusz 3: Yast2 nie pokazuje opcji wysokiej dostępności
Aby opcja wysokiej dostępności była widoczna w centrum sterowania yast2, należy zainstalować inne pakiety.
Przejdź do Yast2>Software>Zarządzanie oprogramowaniem. Następnie wybierz pozycjęAktualizacja online>.
Wybierz wzorce dla następujących elementów. Następnie wybierz pozycję Akceptuj.
- Baza serwerów SAP HANA
- Kompilator i narzędzia języka C/C++
- Wysoka dostępność
- Baza serwera aplikacji SAP
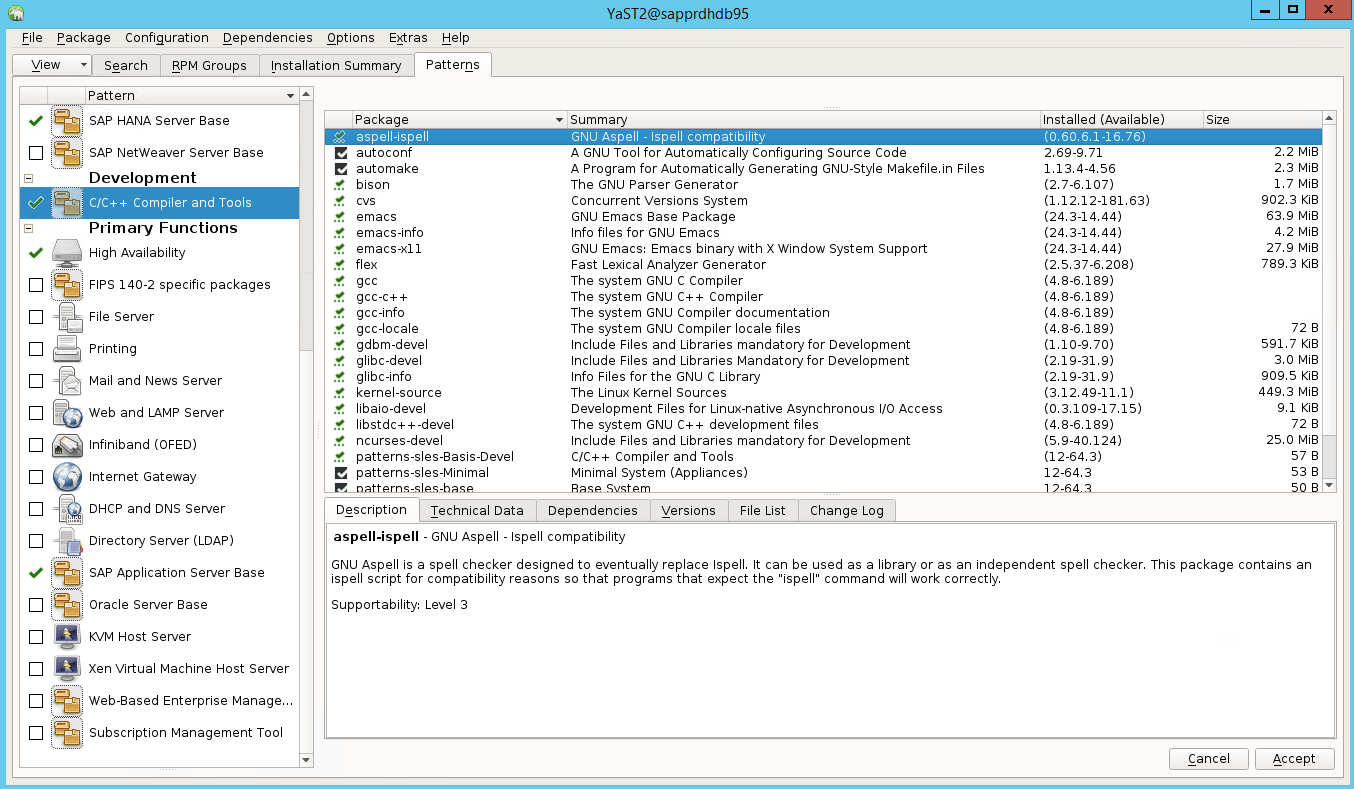
Na liście pakietów, które zostały zmienione w celu rozwiązania zależności, wybierz pozycję Kontynuuj.
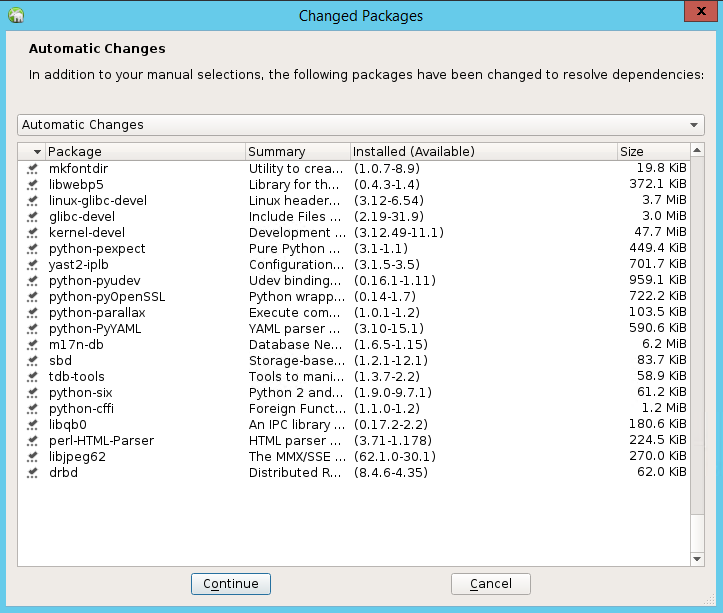
Na stronie Wykonywanie instalacji wybierz Dalej.
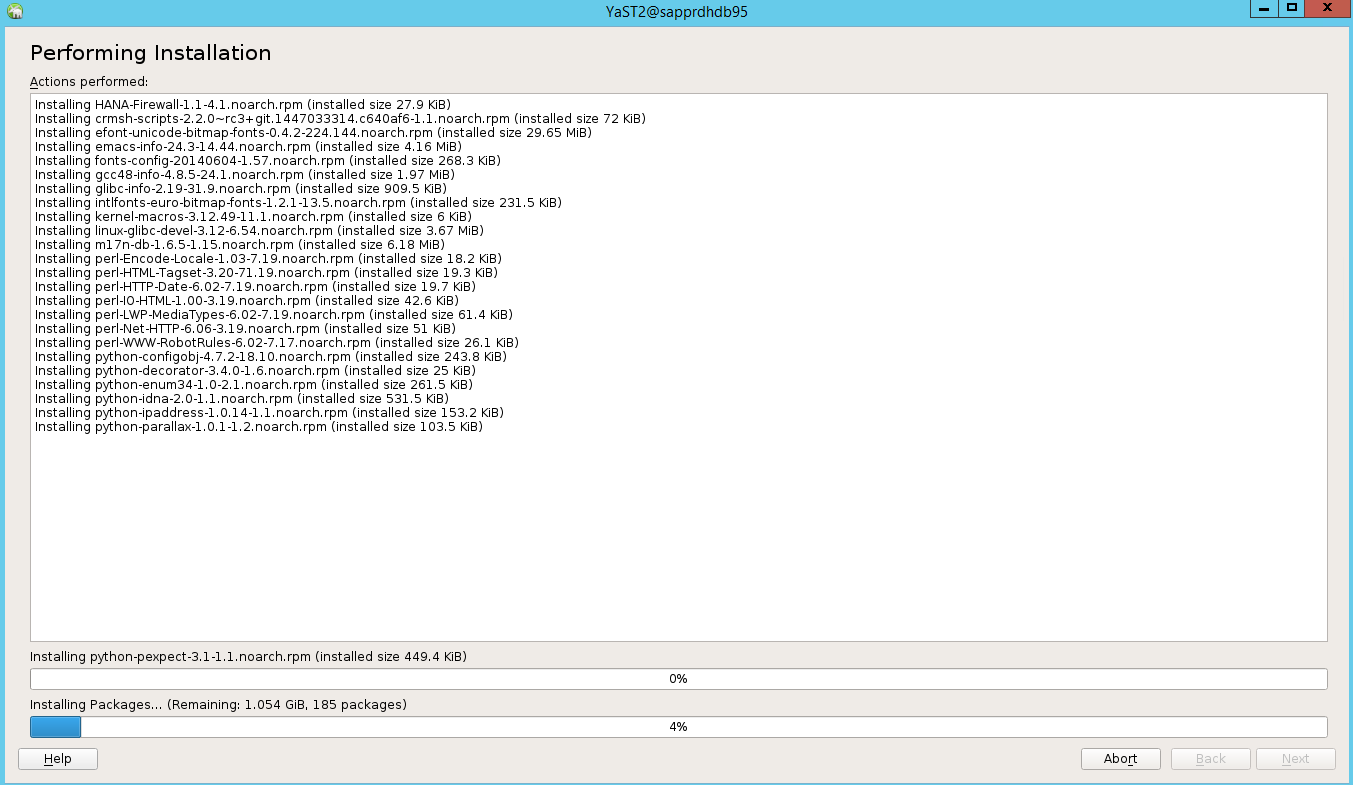
Po zakończeniu instalacji zostanie wyświetlony raport instalacji. Wybierz Zakończ
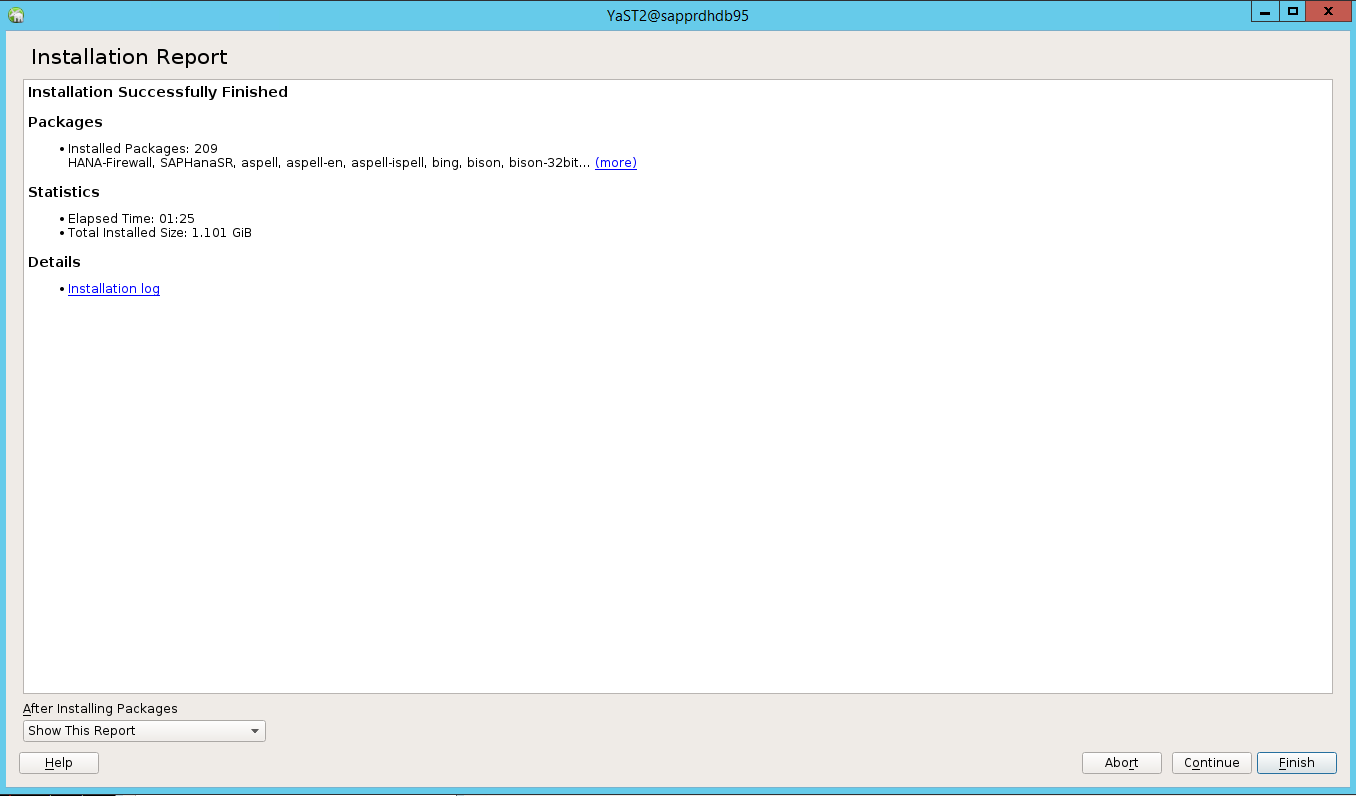
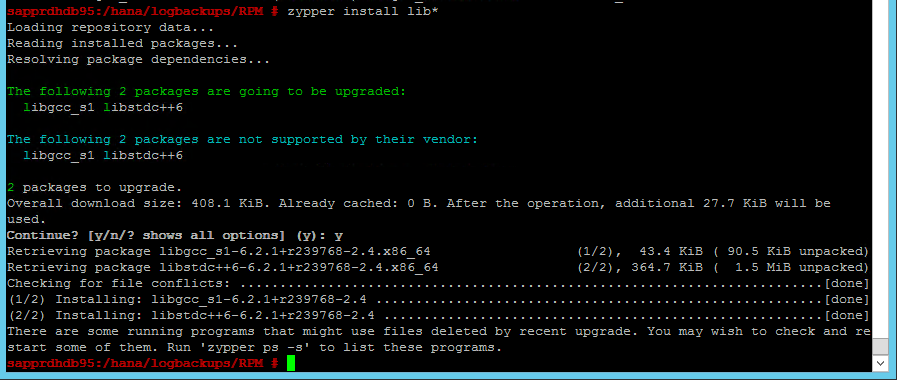
Scenariusz 4. Instalacja platformy HANA kończy się niepowodzeniem z powodu błędu zestawów biblioteki gcc
Jeśli instalacja platformy HANA nie powiedzie się, może zostać wyświetlony następujący błąd.
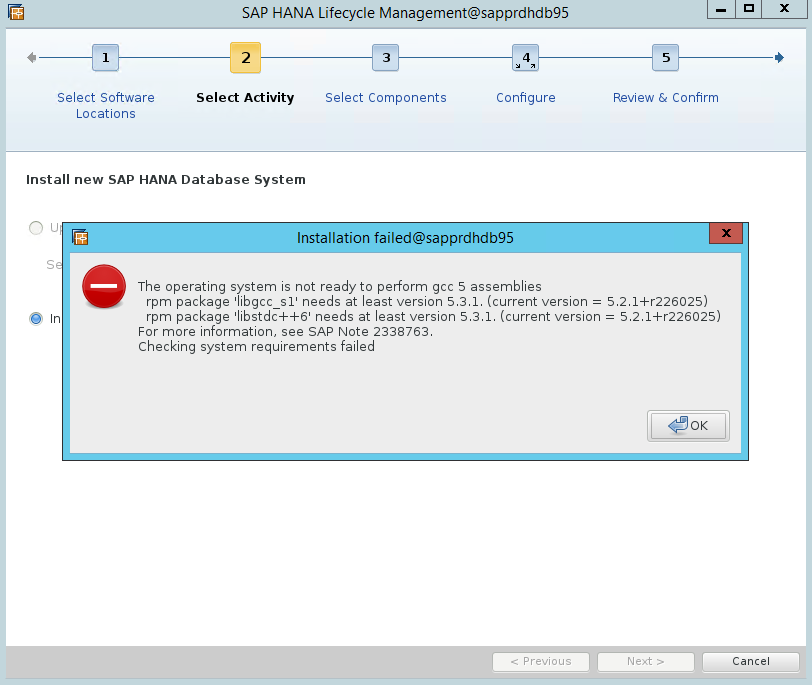
Aby rozwiązać ten problem, zainstaluj biblioteki libgcc_sl i libstdc++6, jak pokazano na poniższym zrzucie ekranu.
Scenariusz 5. Niepowodzenie usługi Pacemaker
Poniższe informacje są wyświetlane, jeśli usługa pacemaker nie może się uruchomić.
sapprdhdb95:/ # systemctl start pacemaker
A dependency job for pacemaker.service failed. See 'journalctl -xn' for details.
sapprdhdb95:/ # journalctl -xn
-- Logs begin at Thu 2017-09-28 09:28:14 EDT, end at Thu 2017-09-28 21:48:27 EDT. --
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync configuration map
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync configuration ser
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync cluster closed pr
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [QB ] withdrawing server sockets
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync cluster quorum se
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [SERV ] Service engine unloaded: corosync profile loading s
Sep 28 21:48:27 sapprdhdb95 corosync[68812]: [MAIN ] Corosync Cluster Engine exiting normally
Sep 28 21:48:27 sapprdhdb95 systemd[1]: Dependency failed for Pacemaker High Availability Cluster Manager
-- Subject: Unit pacemaker.service has failed
-- Defined-By: systemd
-- Support: https://lists.freedesktop.org/mailman/listinfo/systemd-devel
--
-- Unit pacemaker.service has failed.
--
-- The result is dependency.
sapprdhdb95:/ # tail -f /var/log/messages
2017-09-28T18:44:29.675814-04:00 sapprdhdb95 corosync[57600]: [QB ] withdrawing server sockets
2017-09-28T18:44:29.676023-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync cluster closed process group service v1.01
2017-09-28T18:44:29.725885-04:00 sapprdhdb95 corosync[57600]: [QB ] withdrawing server sockets
2017-09-28T18:44:29.726069-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync cluster quorum service v0.1
2017-09-28T18:44:29.726164-04:00 sapprdhdb95 corosync[57600]: [SERV ] Service engine unloaded: corosync profile loading service
2017-09-28T18:44:29.776349-04:00 sapprdhdb95 corosync[57600]: [MAIN ] Corosync Cluster Engine exiting normally
2017-09-28T18:44:29.778177-04:00 sapprdhdb95 systemd[1]: Dependency failed for Pacemaker High Availability Cluster Manager.
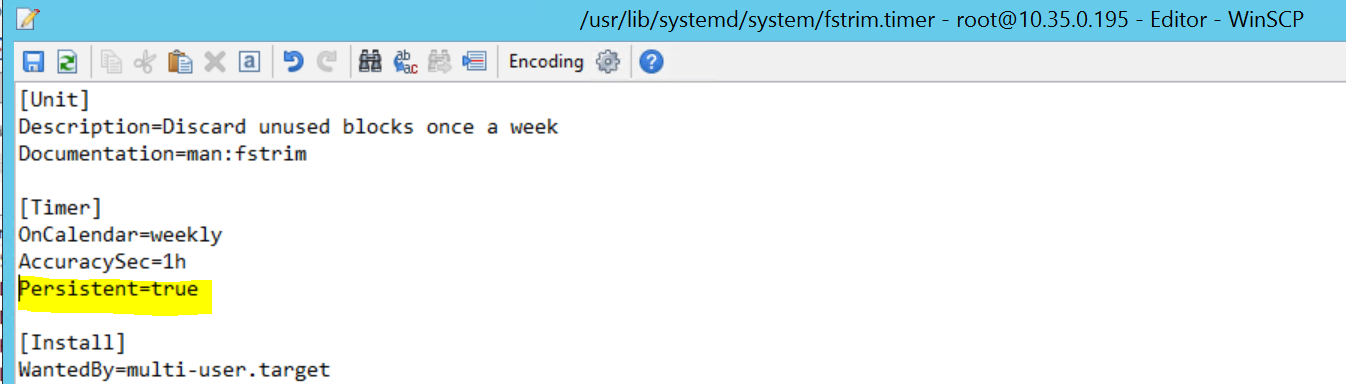
2017-09-28T18:44:40.141030-04:00 sapprdhdb95 systemd[1]: [/usr/lib/systemd/system/fstrim.timer:8] Unknown lvalue 'Persistent' in section 'Timer'
2017-09-28T18:45:01.275038-04:00 sapprdhdb95 cron[57995]: pam_unix(crond:session): session opened for user root by (uid=0)
2017-09-28T18:45:01.308066-04:00 sapprdhdb95 CRON[57995]: pam_unix(crond:session): session closed for user root
Aby rozwiązać ten problem, usuń następujący wiersz z pliku /usr/lib/systemd/system/fstrim.timer:
Persistent=true
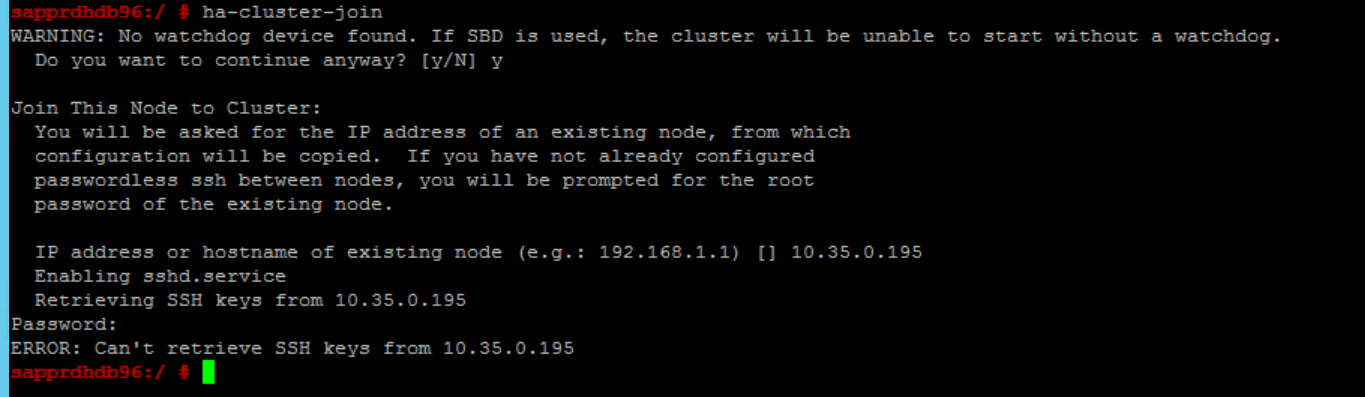
Scenariusz 6: Węzeł Node2 nie może przyłączyć się do klastra
Poniższy błąd pojawia się, jeśli wystąpił problem z dołączeniem węzła2 do istniejącego klastra za pomocą polecenia ha-cluster-join .
ERROR: Can’t retrieve SSH keys from <Primary Node>
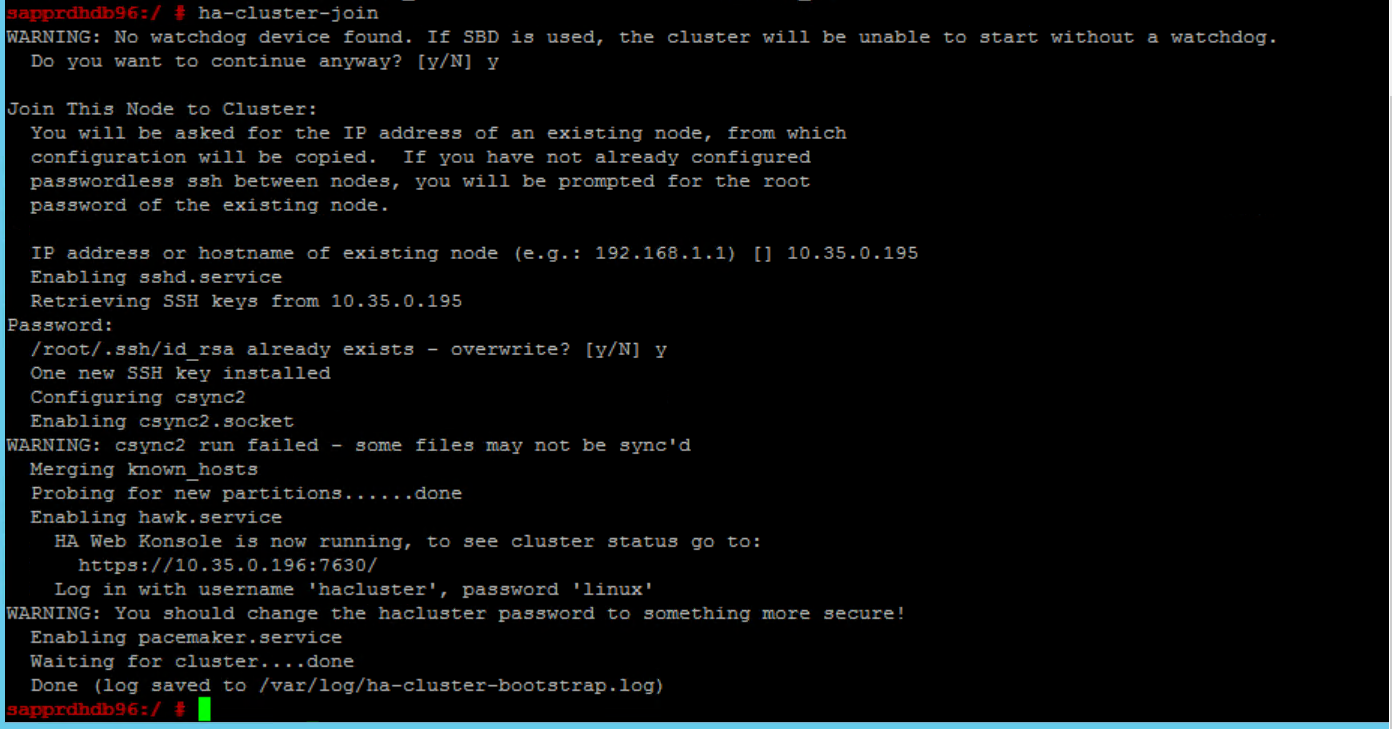
Aby rozwiązać ten problem:
Uruchom następujące polecenia w obu węzłach.
ssh-keygen -q -f /root/.ssh/id_rsa -C 'Cluster Internal' -N '' cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys

Upewnij się, że węzeł Node2 został dodany do klastra.
Następne kroki
Więcej informacji na temat konfiguracji SUSE HA można znaleźć w następujących artykułach:
- Scenariusz zoptymalizowany pod kątem wydajności usługi SAP HANA ( witryna internetowa SUSE)
- Szermierka i urządzenia ochronne (strona internetowa SUSE)
- Przygotuj się do korzystania z klastra Pacemaker dla platformy SAP HANA — część 1: Podstawy (blog SAP)
- Przygotuj się do korzystania z klastra Pacemaker dla platformy SAP HANA — część 2: awaria obu węzłów (blog SAP)
- Tworzenie kopii zapasowej i przywracanie systemu operacyjnego