Instalowanie i konfigurowanie oprogramowania SAP HANA (duże wystąpienia) na platformie Azure
W tym artykule omówimy walidację, konfigurowanie i instalowanie dużych wystąpień SAP HANA (HLI) na platformie Azure (inaczej nazywanej infrastrukturą BareMetal).
Wymagania wstępne
Przed przeczytaniem tego artykułu zapoznaj się z następującymi tematami:
Zobacz również:
- Łączenie maszyn wirtualnych platformy Azure z funkcją HANA — duże wystąpienia
- Połączenie sieci wirtualnej do dużych wystąpień HANA
Planowanie instalacji
Instalacja oprogramowania SAP HANA jest Twoim zadaniem. Możesz rozpocząć instalowanie nowego serwera SAP HANA na platformie Azure (duże wystąpienia) po ustanowieniu łączności między sieciami wirtualnymi platformy Azure i jednostkami dużych wystąpień HANA.
Uwaga
Zgodnie z zasadami sap instalacja oprogramowania SAP HANA musi być wykonywana przez osobę, która zdała egzamin Certified SAP Technology Associate, egzamin certyfikacyjny sap HANA Installation lub który jest certyfikowanym integratorem systemu SAP (SI).
Jeśli planujesz zainstalować platformę HANA 2.0, zobacz artykuł Sap support note #2235581 — SAP HANA: Supported operating systems (Obsługa oprogramowania SAP 2.0 — SAP HANA: obsługiwane systemy operacyjne). Upewnij się, że system operacyjny jest obsługiwany w instalowanej wersji sap HANA. Obsługiwany system operacyjny HANA 2.0 jest bardziej restrykcyjny niż obsługiwany system operacyjny dla platformy HANA 1.0. Upewnij się, że wersja systemu operacyjnego, którą cię interesujesz, jest obsługiwana dla konkretnego dużego wystąpienia platformy HANA. Użyj tej listy. Wybierz listę HLI, aby wyświetlić szczegóły listy obsługiwanych systemów operacyjnych dla tej lekcji.
Przed rozpoczęciem instalacji platformy HANA zweryfikuj następujące elementy:
Weryfikowanie jednostek dużych wystąpień platformy HANA
Po otrzymaniu dużych wystąpień platformy HANA od firmy Microsoft ustanów dostęp i łączność z nimi. Następnie zweryfikuj następujące ustawienia i dostosuj je w razie potrzeby.
Sprawdź w witrynie Azure Portal, czy wystąpienia są wyświetlane przy użyciu prawidłowych jednostek SKU i systemu operacyjnego. Aby uzyskać więcej informacji, zobacz Kontrola dużych wystąpień platformy Azure HANA za pośrednictwem witryny Azure Portal.
Zarejestruj system operacyjny wystąpienia u dostawcy systemu operacyjnego. Ten krok obejmuje zarejestrowanie systemu operacyjnego SUSE Linux w wystąpieniu narzędzia do zarządzania subskrypcjami SUSE (SMT) wdrożonego na maszynie wirtualnej na platformie Azure.
Duże wystąpienie platformy HANA może nawiązać połączenie z tym wystąpieniem SMT. (Aby uzyskać więcej informacji, zobacz Jak skonfigurować serwer SMT dla systemu SUSE Linux). Jeśli używasz systemu operacyjnego Red Hat, należy go zarejestrować w Menedżerze subskrypcji Red Hat, z którym się połączysz. Aby uzyskać więcej informacji, zobacz uwagi w temacie Co to jest platforma SAP HANA na platformie Azure (duże wystąpienia)?.
Ten krok jest niezbędny do stosowania poprawek systemu operacyjnego, który jest Twoim zadaniem. Aby uzyskać informacje o systemie SUSE, zapoznaj się z dokumentacją dotyczącą instalowania i konfigurowania protokołu SMT.
Sprawdź nowe poprawki i poprawki określonego wydania/wersji systemu operacyjnego. Sprawdź, czy duże wystąpienie platformy HANA ma najnowsze poprawki. Czasami najnowsze poprawki nie są uwzględnione, więc pamiętaj, aby sprawdzić.
Zapoznaj się z odpowiednimi uwagami dotyczącymi oprogramowania SAP pod kątem instalowania i konfigurowania oprogramowania SAP HANA w określonej wersji/wersji systemu operacyjnego. Firma Microsoft nie zawsze będzie całkowicie konfigurować bibliotekę HLI. Zmiana zaleceń lub zmian w notatkach lub konfiguracjach sap zależnych od poszczególnych scenariuszy może uniemożliwić.
Pamiętaj, aby przeczytać informacje o oprogramowaniu SAP związane z platformą SAP HANA, aby uzyskać dokładną wersję systemu Linux. Sprawdź również konfiguracje wersji/wersji systemu operacyjnego i zastosuj ustawienia konfiguracji, jeśli jeszcze tego nie zrobiono.
W szczególności sprawdź następujące parametry i w końcu dostosuj je do:
- net.core.rmem_max = 16777216
- net.core.wmem_max = 16777216
- net.core.rmem_default = 16777216
- net.core.wmem_default = 16777216
- net.core.optmem_max = 16777216
- net.ipv4.tcp_rmem = 65536 16777216 16777216
- net.ipv4.tcp_wmem = 65536 16777216 16777216
Począwszy od SLES12 SP1 i Red Hat Enterprise Linux (RHEL) 7.2, te parametry muszą być ustawione w pliku konfiguracji w katalogu /etc/sysctl.d. Na przykład należy utworzyć plik konfiguracji o nazwie 91-NetApp-HANA.conf. W przypadku starszych wersji SLES i RHEL te parametry muszą być ustawione w/etc/sysctl.conf.
W przypadku wszystkich wersji RHEL począwszy od wersji RHEL 6.3 należy pamiętać:
- Parametr sunrpc.tcp_slot_table_entries = 128 musi być ustawiony w/etc/modprobe.d/sunrpc-local.conf. Jeśli plik nie istnieje, utwórz go najpierw, dodając wpis:
- opcje sunrpc tcp_max_slot_table_entries=128
Sprawdź czas systemowy dużego wystąpienia platformy HANA. Wystąpienia są wdrażane z systemową strefą czasową. Ta strefa czasowa reprezentuje lokalizację regionu świadczenia usługi Azure, w którym znajduje się sygnatura dużego wystąpienia platformy HANA. Możesz zmienić czas systemowy lub strefę czasową własnych wystąpień.
Jeśli zamówisz więcej wystąpień w dzierżawie, musisz dostosować strefę czasową nowo dostarczonych wystąpień. Firma Microsoft nie ma wglądu w systemową strefę czasową skonfigurowaną z wystąpieniami po przekazaniu. Dlatego nowo wdrożone wystąpienia mogą nie być ustawione w tej samej strefie czasowej, na którą zmieniono. Należy dostosować strefę czasową przekazanych wystąpień zgodnie z potrzebami.
Sprawdź itp/hosty. Gdy bloki są przekazywane, mają różne adresy IP przypisane do różnych celów. Ważne jest, aby sprawdzić plik etc/hosts, gdy jednostki są dodawane do istniejącej dzierżawy. Plik etc/hosts nowo wdrożonych systemów może nie być poprawnie utrzymywany z adresami IP systemów dostarczonych wcześniej. Upewnij się, że nowo wdrożone wystąpienie może rozpoznać nazwy jednostek wdrożonych wcześniej w dzierżawie.
System operacyjny
Miejsce wymiany dostarczonego obrazu systemu operacyjnego jest ustawione na 2 GB zgodnie z uwagami pomocy technicznej sap #1999997 — często zadawane pytania: pamięć SAP HANA. Jeśli chcesz użyć innego ustawienia, musisz ustawić je samodzielnie.
SUSE Linux Enterprise Server 12 z dodatkiem SP1 dla aplikacji SAP to dystrybucja systemu Linux zainstalowana dla platformy SAP HANA na platformie Azure (duże wystąpienia). Ta dystrybucja zapewnia możliwości specyficzne dla oprogramowania SAP, w tym parametry wstępnie ustawione do efektywnego uruchamiania oprogramowania SAP w systemie SLES.
Aby uzyskać kilka przydatnych zasobów związanych z wdrażaniem oprogramowania SAP HANA w systemie SLES, zobacz:
- Biblioteka zasobów/oficjalne dokumenty w witrynie internetowej SUSE.
- Oprogramowanie SAP w systemie SUSE w usłudze SAP Community Network (SCN).
Te zasoby obejmują informacje na temat konfigurowania wysokiej dostępności, wzmacniania zabezpieczeń specyficznych dla operacji SAP i nie tylko.
Oto więcej zasobów dla oprogramowania SAP w systemie SUSE:
- Oprogramowanie SAP HANA w witrynie systemu SUSE Linux
- Najlepsze rozwiązanie dla systemu SAP: replikacja w kolejce — SAP NetWeaver w systemie SUSE Linux Enterprise 12
- ClamSAP — ochrona przed wirusami SLES dla oprogramowania SAP (w tym SLES 12 dla aplikacji SAP)
Poniższe dokumenty to informacje o pomocy technicznej sap dotyczące implementowania oprogramowania SAP HANA w systemie SLES 12:
- Uwaga dotycząca obsługi oprogramowania SAP #1944799 — wytyczne dotyczące oprogramowania SAP HANA dotyczące instalacji systemu operacyjnego SLES
- Uwaga dotycząca obsługi oprogramowania SAP #2205917 — zalecane ustawienia systemu operacyjnego SAP HANA dla usług SLES 12 dla aplikacji SAP
- Uwaga dotycząca obsługi oprogramowania SAP #1984787 — SUSE Linux Enterprise Server 12: informacje o instalacji
- Uwaga dotycząca obsługi oprogramowania SAP #171356 — oprogramowanie SAP w systemie Linux: ogólne informacje
- Uwaga dotycząca obsługi oprogramowania SAP #1391070 — rozwiązania UUID systemu Linux
Red Hat Enterprise Linux for SAP HANA to kolejna oferta uruchamiania oprogramowania SAP HANA na dużych wystąpieniach platformy HANA. Wersje RHEL 7.2 i 7.3 są dostępne i obsługiwane. Aby uzyskać więcej informacji na temat oprogramowania SAP on Red Hat, zobacz SAP HANA w witrynie systemu Red Hat Linux.
Poniższe dokumenty to informacje o pomocy technicznej sap dotyczące implementowania oprogramowania SAP HANA w systemie Red Hat:
- Uwaga dotycząca pomocy technicznej oprogramowania SAP #2009879 — wytyczne dotyczące oprogramowania SAP HANA dla systemu operacyjnego Red Hat Enterprise Linux (RHEL)
- Uwaga dotycząca obsługi oprogramowania SAP #2292690 — SAP HANA DB: zalecane ustawienia systemu operacyjnego dla systemu RHEL 7
- Uwaga dotycząca obsługi oprogramowania SAP #1391070 — rozwiązania UUID systemu Linux
- Uwaga dotycząca obsługi oprogramowania SAP #2228351 — Linux: SYSTEM SAP HANA Database SPS 11 w wersji 110 (lub nowszej) w systemie RHEL 6 lub SLES 11
- Uwaga dotycząca pomocy technicznej oprogramowania SAP #2397039 — często zadawane pytania: SAP w systemie RHEL
- Uwaga dotycząca obsługi oprogramowania SAP #2002167 — Red Hat Enterprise Linux 7.x: instalacja i uaktualnienie
Synchronizacja czasu
Aplikacje SAP utworzone na podstawie architektury SAP NetWeaver są wrażliwe na różnice czasu dla składników systemu SAP. Krótkie zrzuty SAP ABAP z tytułem błędu ZDATE_LARGE_TIME_DIFF są prawdopodobnie znane. Dzieje się tak, ponieważ te krótkie zrzuty pojawiają się, gdy czas systemowy różnych serwerów lub maszyn wirtualnych dryfuje zbyt daleko.
W przypadku platformy SAP HANA na platformie Azure (duże wystąpienia) synchronizacja czasu na platformie Azure nie ma zastosowania do jednostek obliczeniowych w sygnaturach dużych wystąpień. Nie ma ona również zastosowania do uruchamiania aplikacji SAP na natywnych maszynach wirtualnych platformy Azure, ponieważ platforma Azure zapewnia, że czas systemu jest prawidłowo zsynchronizowany.
W związku z tym należy skonfigurować oddzielny serwer czasu. Ten serwer będzie używany przez serwery aplikacji SAP działające na maszynach wirtualnych platformy Azure. Będzie ona również używana przez wystąpienia bazy danych SAP HANA uruchomione w dużych wystąpieniach platformy HANA. Infrastruktura magazynu w sygnaturach dużych wystąpień jest synchronizowana czasowo z serwerami protokołu NTP (Network Time Protocol).
Sieć
Podczas projektowania sieci wirtualnych platformy Azure i łączenia tych sieci wirtualnych z dużymi wystąpieniami platformy HANA należy postępować zgodnie z zaleceniami opisanymi w temacie:
- Omówienie i architektura oprogramowania SAP HANA (duże wystąpienie) na platformie Azure
- Infrastruktura i łączność oprogramowania SAP HANA (duże wystąpienia) na platformie Azure
Poniżej przedstawiono kilka szczegółów, które warto wspomnieć o sieci pojedynczych jednostek. Każda jednostka dużego wystąpienia platformy HANA zawiera dwa lub trzy adresy IP przypisane do dwóch lub trzech portów kontrolera interfejsu sieciowego (NIC). Trzy adresy IP są używane w konfiguracjach skalowalnego w poziomie platformy HANA i scenariuszu replikacji systemu HANA. Jeden z adresów IP przypisanych do karty sieciowej jednostki jest poza pulą adresów IP serwera opisaną w temacie Omówienie i architektura oprogramowania SAP HANA (duże wystąpienia) na platformie Azure.
Aby uzyskać więcej informacji na temat szczegółów sieci Ethernet dla architektury, zobacz Scenariusze obsługiwane przez interfejs HLI.
Storage
Układ magazynu dla oprogramowania SAP HANA (duże wystąpienia) jest konfigurowany przez platformę SAP HANA w usłudze Azure Service Management przy użyciu zalecanych wytycznych dotyczących oprogramowania SAP.
Przybliżone rozmiary różnych woluminów z różnymi jednostkami SKU dużych wystąpień platformy HANA są udokumentowane w omówieniu i architekturze platformy SAP HANA (dużych wystąpień) na platformie Azure.
Konwencje nazewnictwa woluminów magazynu są wymienione w poniższej tabeli:
| Użycie magazynu | Nazwa instalacji | Nazwa woluminu |
|---|---|---|
| Dane platformy HANA | /hana/data/SID/mnt0000<m> | Adres IP magazynu:/hana_data_SID_mnt00001_tenant_vol |
| Dziennik platformy HANA | /hana/log/SID/mnt0000<m> | Adres IP magazynu:/hana_log_SID_mnt00001_tenant_vol |
| Kopia zapasowa dziennika HANA | /hana/log/backups | Adres IP magazynu:/hana_log_backups_SID_mnt00001_tenant_vol |
| Udostępniono platformę HANA | /hana/shared/SID | Adres IP magazynu:/hana_shared_SID_mnt00001_tenant_vol/udostępnione |
| usr/sap | /usr/sap/SID | Adres IP magazynu:/hana_shared_SID_mnt00001_tenant_vol/usr_sap |
Identyfikator SID to identyfikator systemu wystąpienia HANA.
Dzierżawa to wewnętrzne wyliczanie operacji podczas wdrażania dzierżawy.
Zestaw usr/sap platformy HANA współużytkuje ten sam wolumin. Nomenklatura punktów instalacji zawiera identyfikator systemu wystąpień HANA i numer instalacji. W przypadku wdrożeń skalowanych w górę istnieje tylko jedna instalacja, taka jak mnt00001. W przypadku wdrożeń skalowanych w poziomie zobaczysz tyle instalacji, ile masz węzłów roboczych i podstawowych.
W przypadku środowisk skalowanych w poziomie woluminy kopii zapasowych danych, dzienników i dzienników są współużytkowane i dołączone do każdego węzła w konfiguracji skalowania w poziomie. W przypadku konfiguracji, które są wieloma wystąpieniami SAP, tworzony jest inny zestaw woluminów i dołączony do dużego wystąpienia HANA. Aby uzyskać szczegółowe informacje o układzie magazynu dla danego scenariusza, zobacz Scenariusze obsługiwane przez interfejs HLI.
Duże wystąpienia platformy HANA są dostarczane z hojnym woluminem dysku dla platformy HANA/danych oraz woluminem HANA/dziennikiem/kopią zapasową. Zrobiliśmy platformę HANA/dane tak duże, ponieważ migawki magazynu używają tego samego woluminu dysku. Im więcej migawek magazynu, tym więcej miejsca jest zużywane przez migawki w przypisanych woluminach magazynu.
Wolumin HANA/dziennika/kopii zapasowej nie powinien być woluminem kopii zapasowych bazy danych. Rozmiar jest używany jako wolumin kopii zapasowej kopii zapasowych kopii zapasowych dziennika transakcji HANA. Aby uzyskać więcej informacji, zobacz wysoka dostępność i odzyskiwanie po awarii platformy SAP HANA (duże wystąpienia) na platformie Azure.
Magazyn można zwiększyć, kupując dodatkową pojemność w przyrostach 1 TB. Ten dodatkowy magazyn można dodać jako nowe woluminy do dużego wystąpienia HANA.
Podczas dołączania do platformy SAP HANA w usłudze Azure Service Management określisz identyfikator użytkownika (UID) i identyfikator grupy (GID) dla grupy sidadm i sapsys (na przykład: 1000 500). Podczas instalacji systemu SAP HANA należy użyć tych samych wartości. Ponieważ chcesz wdrożyć wiele wystąpień platformy HANA w jednostce, otrzymujesz wiele zestawów woluminów (jeden zestaw dla każdego wystąpienia). Dlatego w czasie wdrażania należy zdefiniować następujące elementy:
- Identyfikator SID różnych wystąpień platformy HANA (sidadm pochodzi od niego).
- Rozmiary pamięci różnych wystąpień platformy HANA. Rozmiar pamięci na wystąpienie definiuje rozmiar woluminów w każdym zestawie woluminów.
Na podstawie zaleceń dotyczących dostawcy magazynu następujące opcje instalacji są skonfigurowane dla wszystkich zainstalowanych woluminów (nie obejmuje jednostki LUN rozruchu):
- nfs rw, vers=4, hard, timeo=600, rsize=1048576, wsize=1048576, intr, noatime, lock 0 0
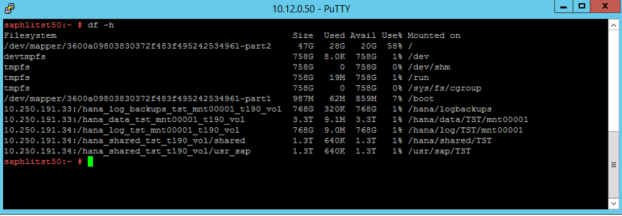
Te punkty instalacji są konfigurowane w pliku /etc/fstab, jak pokazano na poniższych zrzutach ekranu:

Dane wyjściowe polecenia df -h w dużym wystąpieniu S72m HANA wyglądają następująco:
Kontroler magazynu i węzły w sygnaturach dużych wystąpień są synchronizowane z serwerami NTP. Synchronizowanie platformy SAP HANA na platformie Azure (dużych wystąpień) i maszyn wirtualnych platformy Azure z serwerem NTP jest ważne. Eliminuje to znaczny dryf czasu między infrastrukturą a jednostkami obliczeniowymi na platformie Azure lub sygnaturami dużych wystąpień.
Aby zoptymalizować platformę SAP HANA do magazynu używanego poniżej, ustaw następujące parametry konfiguracji oprogramowania SAP HANA:
- max_parallel_io_requests 128
- async_read_submit w dniu
- async_write_submit_active w dniu
- async_write_submit_blocks wszystkie
W przypadku wersji SAP HANA 1.0 z dodatkiem SPS12 te parametry można ustawić podczas instalacji bazy danych SAP HANA, zgodnie z opisem w temacie SAP Note #2267798 — Konfiguracja bazy danych SAP HANA.
Parametry można również skonfigurować po instalacji bazy danych SAP HANA przy użyciu platformy hdbparam.
Magazyn używany w dużych wystąpieniach platformy HANA ma ograniczenie rozmiaru pliku. Ograniczenie rozmiaru wynosi 16 TB na plik. W przeciwieństwie do ograniczeń rozmiaru plików w systemach plików EXT3 platforma HANA nie jest świadoma niejawnie ograniczenia magazynu wymuszanego przez magazyn HANA Large Instances. W związku z tym platforma HANA nie utworzy automatycznie nowego pliku danych po osiągnięciu limitu rozmiaru pliku 16 TB. Gdy platforma HANA podejmie próbę zwiększenia rozmiaru pliku powyżej 16 TB, platforma HANA zgłosi błędy, a serwer indeksowania ulegnie awarii na końcu.
Ważne
Aby zapobiec próbie zwiększenia rozmiaru plików danych przez platformę HANA poza limitem rozmiaru pliku o rozmiarze 16 TB magazynu dużych wystąpień platformy HANA, ustaw następujące parametry w pliku konfiguracji global.ini sap HANA:
- datavolume_striping=true
- datavolume_striping_size_gb = 15000
- Zobacz też notę SAP #2400005
- Należy pamiętać o uwagach sap #2631285
W przypadku platformy SAP HANA 2.0 struktura hdbparam została przestarzała. Dlatego parametry muszą być ustawiane przy użyciu poleceń SQL. Aby uzyskać więcej informacji, zobacz uwaga SAP #2399079: Eliminacja parametrów hdbparam na platformie HANA 2.
Zapoznaj się z obsługiwanymi scenariuszami HLI, aby dowiedzieć się więcej o układzie magazynu dla architektury.
Następne kroki
Zapoznaj się z krokami instalowania oprogramowania SAP HANA na platformie Azure (duże wystąpienia).
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla