Woluminy NFS 4.1 w usłudze Azure NetApp Files dla platformy SAP HANA
Usługa Azure NetApp Files udostępnia natywne udziały NFS, których można używać dla /hana/shared, /hana/data i /hana/woluminów dziennika . Użycie udziałów NFS opartych na protokole ANF dla woluminów /hana/data i /hana/log wymaga użycia protokołu NFS w wersji 4.1. Protokół NFS w wersji 3 nie jest obsługiwany w przypadku użycia woluminów /hana/data i /hana/log podczas bazowania udziałów w anf.
Ważne
Protokół NFS w wersji 3 zaimplementowany w usłudze Azure NetApp Files nie jest obsługiwany do użycia w przypadku /hana/data i /hana/log. Użycie systemu plików NFS 4.1 jest obowiązkowe dla woluminów /hana/data i /hana/log z punktu widzenia funkcjonalności. Podczas gdy w przypadku woluminu /hana/shared system plików NFS w wersji 3 lub NFS w wersji 4.1 może być używany z punktu widzenia funkcjonalności.
Ważne uwagi
Biorąc pod uwagę usługę Azure NetApp Files dla oprogramowania SAP Netweaver i SAP HANA, należy pamiętać o następujących ważnych kwestiach:
Aby uzyskać informacje o limitach woluminów i puli pojemności, zobacz Limity zasobów usługi Azure NetApp Files.
Udziały NFS oparte na usłudze Azure NetApp Files i maszyny wirtualne, które zainstalują te udziały, muszą znajdować się w tej samej sieci wirtualnej platformy Azure lub w równorzędnych sieciach wirtualnych w tym samym regionie.
Wybrana sieć wirtualna musi mieć podsieć delegowana do usługi Azure NetApp Files. W przypadku obciążenia SAP zdecydowanie zaleca się skonfigurowanie zakresu /25 dla podsieci delegowanej do usługi Azure NetApp Files.
Ważne jest, aby maszyny wirtualne zostały wdrożone w wystarczającej odległości do magazynu usługi Azure NetApp w celu uzyskania mniejszego opóźnienia, ponieważ na przykład wymagane przez platformę SAP HANA na potrzeby ponownego zapisywania dzienników.
- W międzyczasie usługa Azure NetApp Files ma funkcje wdrażania woluminów NFS w określonej usłudze Azure Strefy dostępności. Taka bliskość strefowa będzie wystarczająca w większości przypadków, aby osiągnąć opóźnienie mniejsze niż 1 milisekund. Funkcje są dostępne w publicznej wersji zapoznawczej i opisano w artykule Zarządzanie umieszczaniem woluminów strefy dostępności dla usługi Azure NetApp Files. Ta funkcja nie wymaga żadnego interaktywnego procesu z firmą Microsoft w celu osiągnięcia zbliżenia między maszyną wirtualną a przydzielanymi woluminami NFS.
- Aby osiągnąć najbardziej optymalną bliskość, dostępne są funkcje grup woluminów aplikacji. Ta funkcja nie tylko szuka najbardziej optymalnej odległości, ale dla najbardziej optymalnego umieszczania woluminów NFS, dzięki czemu dane platformy HANA i ponownie woluminy dziennika są obsługiwane przez różne kontrolery. Wadą jest to, że ta metoda wymaga interaktywnego procesu z firmą Microsoft, aby przypiąć maszyny wirtualne.
Upewnij się, że opóźnienie z serwera bazy danych do woluminu usługi Azure NetApp Files jest mierzone i poniżej 1 milisekund
Przepływność woluminu usługi Azure NetApp jest funkcją limitu przydziału woluminu i poziomu usługi, zgodnie z opisem w artykule Poziom usługi dla usługi Azure NetApp Files. Podczas określania rozmiaru woluminów usługi Azure NetApp na platformie HANA upewnij się, że wynikowa przepływność spełnia wymagania systemowe platformy HANA. Alternatywnie rozważ użycie ręcznej puli pojemności QoS, w której pojemność woluminu i przepływność można skonfigurować i skalować niezależnie (przykłady specyficzne dla oprogramowania SAP HANA znajdują się w tym dokumencie
Spróbuj "skonsolidować" woluminy, aby uzyskać większą wydajność w większym woluminie, na przykład użyć jednego woluminu dla /sapmnt, /usr/sap/trans, ... jeśli to możliwe
Usługa Azure NetApp Files oferuje zasady eksportu: można kontrolować dozwolonych klientów, typ dostępu (odczyt i zapis, tylko do odczytu itp.).
Identyfikator użytkownika dla identyfikatora sidadm i identyfikator grupy dla
sapsysmaszyn wirtualnych musi być zgodny z konfiguracją w usłudze Azure NetApp Files.Implementowanie parametrów systemu operacyjnego Linux wymienionych w notatce SAP 3024346
Ważne
W przypadku obciążeń SAP HANA małe opóźnienia mają krytyczne znaczenie. Skontaktuj się z przedstawicielem firmy Microsoft, aby upewnić się, że maszyny wirtualne i woluminy usługi Azure NetApp Files są wdrażane blisko siebie.
Ważne
Jeśli istnieje niezgodność między identyfikatorem użytkownika dla identyfikatora sidadm a identyfikatorem grupy między sapsys maszyną wirtualną a konfiguracją usługi Azure NetApp, uprawnienia do plików na woluminach usługi Azure NetApp zainstalowane na maszynie wirtualnej będą wyświetlane jako nobody. Upewnij się, że podczas dołączania nowego systemu do usługi Azure NetApp Files określono prawidłowy identyfikator użytkownika dla identyfikatora SIDi identyfikator sapsysgrupy dla usługi .
Opcja instalacji NCONNECT
Nconnect to opcja instalacji woluminów NFS hostowanych w usłudze Azure NetApp Files, która umożliwia klientowi NFS otwieranie wielu sesji na jednym woluminie NFS. Użycie połączenia nconnect z wartością większą niż 1 wyzwala również klienta NFS do używania więcej niż jednej sesji RPC po stronie klienta (w systemie operacyjnym gościa) do obsługi ruchu między systemem operacyjnym gościa i zainstalowanych woluminów NFS. Użycie wielu sesji obsługujących ruch jednego woluminu NFS, ale także użycie wielu sesji RPC może obsługiwać scenariusze wydajności i przepływności, takie jak:
- Instalowanie wielu woluminów NFS hostowanych w usłudze Azure NetApp Files z różnymi poziomami usług na jednej maszynie wirtualnej
- Maksymalna przepływność zapisu dla woluminu i pojedynczej sesji systemu Linux wynosi od 1,2 do 1,4 GB/s. Posiadanie wielu sesji względem jednego woluminu NFS hostowanego w usłudze Azure NetApp Files może zwiększyć przepływność
W przypadku wersji systemu operacyjnego Linux, które obsługują połączenie nconnect jako opcję instalacji i niektóre ważne zagadnienia dotyczące konfiguracji nconnect, szczególnie w przypadku różnych punktów końcowych serwera NFS, przeczytaj dokument Linux NFS opcje instalacji najlepsze rozwiązania dotyczące usługi Azure NetApp Files.
Ustalanie rozmiaru bazy danych HANA w usłudze Azure NetApp Files
Przepływność woluminu usługi Azure NetApp jest funkcją rozmiaru woluminu i poziomu usługi, zgodnie z opisem w temacie Poziomy usługi dla usługi Azure NetApp Files.
Ważne jest, aby zrozumieć relację wydajności z rozmiarem i że istnieją fizyczne limity dla punktu końcowego magazynu usługi. Każdy punkt końcowy magazynu będzie dynamicznie wstrzykiwany do delegowanej podsieci usługi Azure NetApp Files podczas tworzenia woluminu i odbierania adresu IP. Woluminy usługi Azure NetApp Files mogą — w zależności od dostępnej pojemności i logiki wdrażania — współużytkować punkt końcowy magazynu
W poniższej tabeli pokazano, że warto utworzyć duży wolumin "Standardowy" do przechowywania kopii zapasowych i że nie ma sensu utworzyć woluminu "Ultra" większego niż 12 TB, ponieważ maksymalna przepustowość fizyczna pojedynczego woluminu zostanie przekroczona.
Jeśli potrzebujesz więcej niż maksymalnej przepływności zapisu dla woluminu /hana/data niż jedna sesja systemu Linux, możesz również użyć partycjonowania woluminu danych SAP HANA jako alternatywy. Partycjonowanie woluminu danych SAP HANA usuwa działanie we/wy podczas ponownego ładowania danych lub punkty zapisywania HANA w wielu plikach danych HANA, które znajdują się w wielu udziałach NFS. Aby uzyskać więcej informacji na temat usuwania woluminów danych HANA, przeczytaj następujące artykuły:
- Przewodnik administratora platformy HANA
- Blog na temat platformy SAP HANA — partycjonowanie woluminów danych
- Uwaga SAP #2400005
- Uwaga SAP #2700123
| Rozmiar | Standard przepływności | Przepływność Premium | Przepływność w warstwie Ultra |
|---|---|---|---|
| 1 TB | 16 MB/s | 64 MB/s | 128 MB/s |
| 2 TB | 32 MB/s | 128 MB/s | 256 MB/s |
| 4 TB | 64 MB/s | 256 MB/s | 512 MB/s |
| 10 TB | 160 MB/s | 640 MB/s | 1280 MB/s |
| 15 TB | 240 MB/s | 960 MB/s | 1400 MB/s1 |
| 20 TB | 320 MB/s | 1280 MB/s | 1400 MB/s1 |
| 40 TB | 640 MB/s | 1400 MB/s1 | 1400 MB/s1 |
1: limity przepływności odczytu zapisu lub pojedynczej sesji (w przypadku, gdy opcja instalacji systemu plików NFS nconnect nie jest używana)
Ważne jest, aby zrozumieć, że dane są zapisywane w tych samych dyskach SSD w zapleczu magazynu. Limit przydziału wydajności z puli pojemności został utworzony, aby móc zarządzać środowiskiem. Kluczowe wskaźniki wydajności magazynu są równe dla wszystkich rozmiarów baz danych HANA. W prawie wszystkich przypadkach to założenie nie odzwierciedla rzeczywistości i oczekiwań klientów. Rozmiar systemów HANA nie musi oznaczać, że mały system wymaga niskiej przepływności magazynu — a duży system wymaga wysokiej przepływności magazynu. Ogólnie jednak możemy oczekiwać wyższych wymagań dotyczących przepływności dla większych wystąpień bazy danych HANA. W wyniku reguł ustalania rozmiaru bazowego sprzętu sap, takich większych wystąpień platformy HANA, zapewniają również więcej zasobów procesora CPU i większą równoległość w zadaniach, takich jak ładowanie danych po ponownym uruchomieniu wystąpień. W związku z tym rozmiary woluminów powinny zostać przyjęte zgodnie z oczekiwaniami i wymaganiami klientów. Nie tylko wynika to z czystych wymagań dotyczących pojemności.
Podczas projektowania infrastruktury dla oprogramowania SAP na platformie Azure należy pamiętać o pewnych minimalnych wymaganiach dotyczących przepływności magazynu (w przypadku systemów produkcyjnych) firmy SAP. Te wymagania przekładają się na minimalne cechy przepływności:
| Typ woluminu i typ we/wy | Minimalny wskaźnik KPI zażądany przez oprogramowanie SAP | Poziom usług Premium | Poziom usługi w warstwie Ultra |
|---|---|---|---|
| Zapis woluminu dziennika | 250 MB/s | 4 TB | 2 TB |
| Zapis woluminu danych | 250 MB/s | 4 TB | 2 TB |
| Odczyt woluminu danych | 400 MB/s | 6,3 TB | 3,2 TB |
Ponieważ wymagane są wszystkie trzy kluczowe wskaźniki wydajności, wolumin /hana/data musi mieć rozmiar w kierunku większej pojemności, aby spełnić minimalne wymagania dotyczące odczytu. Jeśli używasz ręcznych pul pojemności QoS, rozmiar i przepływność woluminów można zdefiniować niezależnie. Ponieważ zarówno pojemność, jak i przepływność są pobierane z tej samej puli pojemności, poziom usługi i rozmiar puli muszą być wystarczająco duże, aby zapewnić łączną wydajność (zobacz przykład tutaj)
W przypadku systemów HANA, które nie wymagają dużej przepustowości, przepływność woluminu usługi Azure NetApp Files może zostać obniżona przez mniejszy rozmiar woluminu lub przy użyciu ręcznego QoS, dostosowując przepływność bezpośrednio. W przypadku, gdy system HANA wymaga większej przepływności, wolumin może zostać dostosowany przez zmianę rozmiaru pojemności w trybie online. Nie zdefiniowano żadnych kluczowych wskaźników wydajności dla woluminów kopii zapasowych. Jednak przepływność woluminu kopii zapasowej jest niezbędna dla dobrze działającego środowiska. Dziennik — i wydajność woluminu danych musi być zaprojektowana zgodnie z oczekiwaniami klientów.
Ważne
Niezależnie od pojemności wdrożonej na jednym woluminie NFS przepływność powinna być płaskau w zakresie przepustowości 1.2-1.4 GB/s wykorzystywanej przez użytkownika w jednej sesji. Ma to związek z podstawową architekturą oferty usługi Azure NetApp Files i powiązanymi limitami sesji systemu Linux wokół systemu plików NFS. Numery wydajności i przepływności, jak opisano w artykule Wyniki testu porównawczego wydajności dla usługi Azure NetApp Files zostały przeprowadzone względem jednego udostępnionego woluminu NFS z wieloma maszynami wirtualnymi klienta i w wyniku wielu sesji. Ten scenariusz różni się od scenariusza, który mierzymy w oprogramowaniu SAP, gdzie mierzymy przepływność z pojedynczej maszyny wirtualnej względem woluminu NFS hostowanego w usłudze Azure NetApp Files.
Aby spełnić minimalne wymagania dotyczące przepływności sap dla danych i dzienników, zgodnie z wytycznymi dla /hana/shared, zalecane rozmiary będą wyglądać następująco:
| Objętość | Rozmiar Warstwa Premium Storage |
Rozmiar Warstwa Magazynowania w warstwie Ultra |
Obsługiwany protokół NFS |
|---|---|---|---|
| /hana/log/ | 4 TiB | 2 TiB | Wersja 4.1 |
| /hana/data | 6.3 TiB | 3.2 TiB | Wersja 4.1 |
| /hana/udostępnione skalowanie w górę | Min(1 TB, 1 x RAM) | Min(1 TB, 1 x RAM) | Wersja 3 lub wersja 4.1 |
| /hana/shared scale-out | 1 x pamięci RAM węzła roboczego na cztery węzły robocze |
1 x pamięci RAM węzła roboczego na cztery węzły robocze |
Wersja 3 lub wersja 4.1 |
| /hana/logbackup | 3 x pamięć RAM | 3 x pamięć RAM | Wersja 3 lub wersja 4.1 |
| /hana/backup | 2 x pamięć RAM | 2 x pamięć RAM | Wersja 3 lub wersja 4.1 |
W przypadku wszystkich woluminów zdecydowanie zaleca się używanie systemu plików NFS w wersji 4.1.
Dokładnie zapoznaj się z zagadnieniami dotyczącymi ustalania rozmiaru /hana/shared, odpowiednio o rozmiarze /hana/udostępnionego woluminu, co przyczynia się do stabilności systemu.
Szacowane są rozmiary woluminów kopii zapasowych. Dokładne wymagania muszą być zdefiniowane na podstawie procesów obciążeń i operacji. W przypadku kopii zapasowych można skonsolidować wiele woluminów dla różnych wystąpień platformy SAP HANA do jednego (lub dwóch) większych woluminów, co może mieć niższy poziom usług usługi Azure NetApp Files.
Uwaga
Zalecenia dotyczące określania rozmiaru usługi Azure NetApp Files określone w tym dokumencie dotyczą minimalnych wymagań, które firma SAP wyraża wobec swoich dostawców infrastruktury. W rzeczywistych scenariuszach wdrożeń klientów i obciążeń może to nie wystarczyć. Użyj tych zaleceń jako punktu początkowego i dostosuj je w oparciu o wymagania określonego obciążenia.
W związku z tym można rozważyć wdrożenie podobnej przepływności dla woluminów usługi Azure NetApp Files wymienionych już w przypadku magazynu w warstwie Ultra Disk. Należy również rozważyć rozmiary rozmiarów wymienionych dla woluminów dla różnych jednostek SKU maszyn wirtualnych, jak pokazano już w tabelach dysków Ultra.
Napiwek
Woluminy usługi Azure NetApp Files można ponownie rozmiaru dynamicznie, bez konieczności unmount zatrzymywania maszyn wirtualnych lub zatrzymywania platformy SAP HANA. Pozwala to elastycznie sprostać wymaganiom aplikacji zarówno oczekiwanym, jak i nieprzewidzianym wymaganiom dotyczącym przepływności.
Dokumentacja dotycząca wdrażania konfiguracji skalowanej w poziomie platformy SAP HANA z węzłem rezerwowym przy użyciu woluminów NFS NFS 4.1 opartych na systemie Plików NFS w wersji 4.1 jest publikowana w środowisku SAP HANA skalowalnym w poziomie z węzłem rezerwowym na maszynach wirtualnych platformy Azure za pomocą usługi Azure NetApp Files na serwerze SUSE Linux Enterprise Server.
Ustawienia jądra systemu Linux
Aby pomyślnie wdrożyć platformę SAP HANA w usłudze Azure NetApp Files, należy zaimplementować ustawienia jądra systemu Linux zgodnie z 3024346 sap.
W przypadku systemów korzystających z wysokiej dostępności (HA) przy użyciu modułu pacemaker i usługi Azure Load Balancer następujące ustawienia należy zaimplementować w pliku /etc/sysctl.d/91-NetApp-HANA.conf
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 131072 16777216
net.ipv4.tcp_wmem = 4096 16384 16777216
net.core.netdev_max_backlog = 300000
net.ipv4.tcp_slow_start_after_idle=0
net.ipv4.tcp_no_metrics_save = 1
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_timestamps = 0
net.ipv4.tcp_sack = 1
Systemy bez modułu pacemaker i usługi Azure Load Balancer powinny implementować te ustawienia w folderze /etc/sysctl.d/91-NetApp-HANA.conf
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 131072 16777216
net.ipv4.tcp_wmem = 4096 16384 16777216
net.core.netdev_max_backlog = 300000
net.ipv4.tcp_slow_start_after_idle=0
net.ipv4.tcp_no_metrics_save = 1
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_sack = 1
Wdrażanie z sąsiedztwem stref
Aby uzyskać strefową bliskość woluminów i maszyn wirtualnych NFS, możesz postępować zgodnie z instrukcjami opisanymi w temacie Zarządzanie umieszczaniem woluminów strefy dostępności dla usługi Azure NetApp Files. W przypadku tej metody maszyny wirtualne i woluminy NFS będą znajdować się w tej samej strefie dostępności platformy Azure. W większości regionów świadczenia usługi Azure ten typ zbliżenia powinien być wystarczający, aby osiągnąć mniej niż 1 milisekundowe opóźnienie dla mniejszych zapisów dzienników ponownego wdrażania dla platformy SAP HANA. Ta metoda nie wymaga żadnej interaktywnej pracy z firmą Microsoft w celu umieszczania i przypinania maszyn wirtualnych do określonego centrum danych. W związku z tym możesz elastycznie zmieniać rozmiary maszyn wirtualnych i rodziny we wszystkich typach maszyn wirtualnych i rodzinach oferowanych w wdrożonej strefie dostępności. Dzięki temu można reagować elastycznie na warunki chanign lub szybciej przenosić się do bardziej oszczędnych rozmiarów maszyn wirtualnych lub rodzin. Zalecamy tę metodę dla systemów nieprodukcyjnych i systemów produkcyjnych, które mogą pracować z opóźnieniami ponownego rejestrowania, które zbliżają się do 1 milisekund. Funkcja jest obecnie dostępna w publicznej wersji zapoznawczej.
Wdrażanie za pośrednictwem grupy woluminów aplikacji usługi Azure NetApp Files dla platformy SAP HANA (AVG)
W celu wdrożenia woluminów usługi Azure NetApp Files znajdujących się w pobliżu maszyny wirtualnej opracowano nową funkcję o nazwie Grupa woluminów aplikacji usługi Azure NetApp Files dla platformy SAP HANA (AVG). Istnieje seria artykułów, które dokumentują funkcjonalność. Najlepszym rozwiązaniem jest rozpoczęcie od artykułu Omówienie grupy woluminów aplikacji usługi Azure NetApp Files dla platformy SAP HANA. Podczas czytania artykułów staje się jasne, że użycie usługi AVG obejmuje również użycie grup umieszczania w pobliżu platformy Azure. Grupy umieszczania w pobliżu są używane przez nową funkcję do wiązania z tworzonymi woluminami. Aby zapewnić, że w okresie istnienia systemu HANA maszyny wirtualne nie zostaną przeniesione z woluminów usługi Azure NetApp Files, zalecamy użycie kombinacji avset/ PPG dla każdej wdrożonej strefy. Kolejność wdrażania wygląda następująco:
- Korzystając z formularza, musisz zażądać przypinania pustego zestawu AvSet do obliczeniowego HW, aby upewnić się, że maszyny wirtualne nie będą przenoszone
- Przypisywanie grupy ppg do zestawu dostępności i uruchamianie maszyny wirtualnej przypisanej do tego zestawu dostępności
- Wdrażanie woluminów HANA przy użyciu grupy woluminów aplikacji usługi Azure NetApp Files dla funkcji sap HANA
Konfiguracja grupy umieszczania w pobliżu do korzystania z usług AVG w optymalny sposób wyglądałaby następująco:
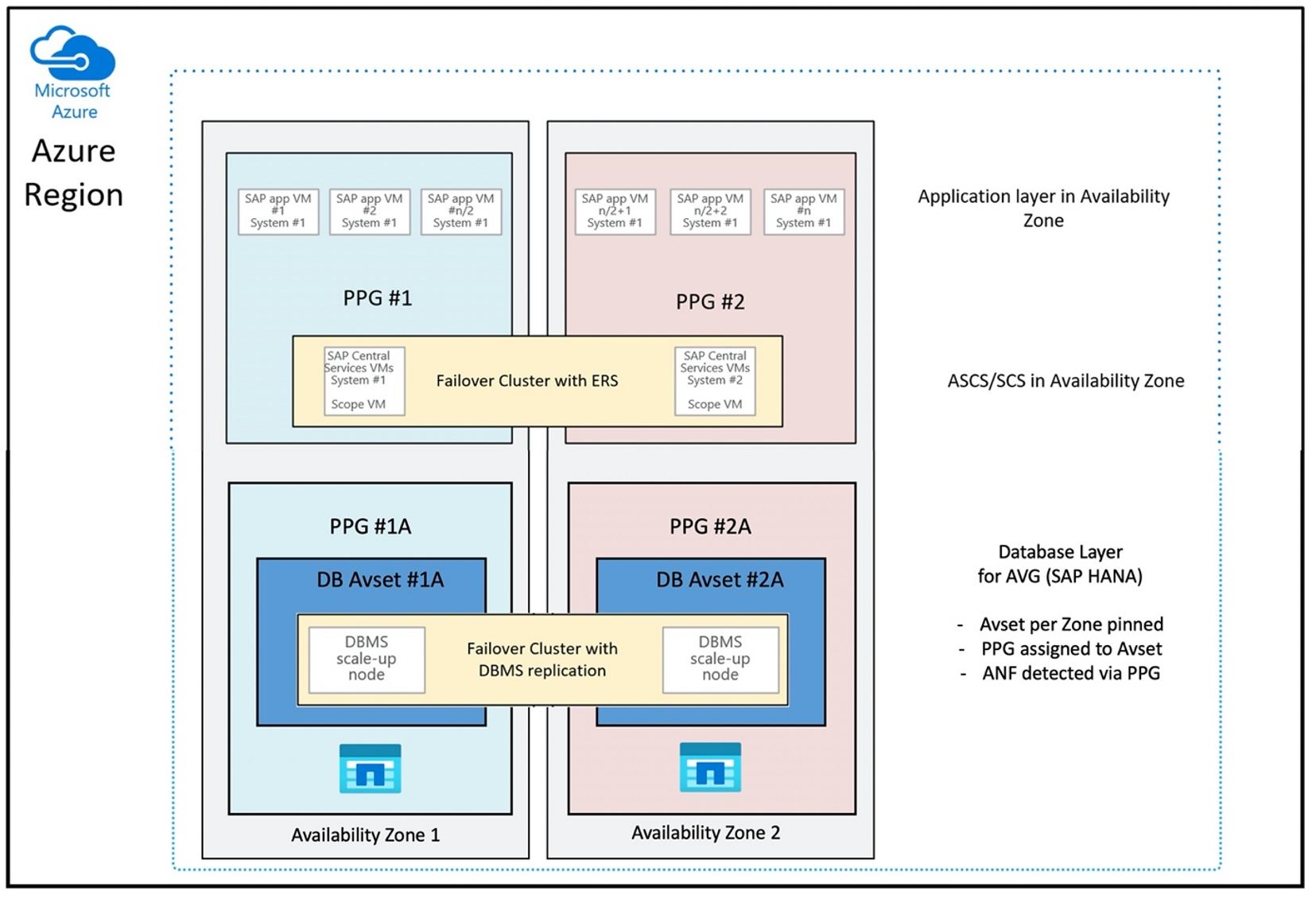
Na diagramie pokazano, że zamierzasz użyć grupy umieszczania w pobliżu platformy Azure dla warstwy DBMS. Tak więc, że może być używany razem z AVG. Najlepiej po prostu uwzględnić tylko maszyny wirtualne, które uruchamiają wystąpienia platformy HANA w grupie umieszczania w pobliżu. Grupa umieszczania w pobliżu jest niezbędna, nawet jeśli jest używana tylko jedna maszyna wirtualna z pojedynczym wystąpieniem platformy HANA, aby program AVG zidentyfikował najbliższą bliskość sprzętu usługi Azure NetApp Files. Aby przydzielić wolumin NFS w usłudze Azure NetApp Files jak najbliżej maszyn wirtualnych korzystających z woluminów NFS.
Ta metoda generuje najbardziej optymalne wyniki w odniesieniu do małych opóźnień. Nie tylko dzięki jak największej zamknięciu woluminów i maszyn wirtualnych NFS. Należy jednak wziąć pod uwagę również zagadnienia dotyczące umieszczania danych i ponownego rejestrowania na różnych kontrolerach w zapleczu usługi NetApp. Jednak wadą jest to, że wdrożenie maszyny wirtualnej jest przypięte do jednego centrum danych. Z tym tracisz elastyczność w zmienianiu typów maszyn wirtualnych i rodzin. W związku z tym należy ograniczyć tę metodę do systemów, które absolutnie wymagają takiego małego opóźnienia magazynu. W przypadku wszystkich innych systemów należy podjąć próbę wdrożenia przy użyciu tradycyjnego wdrożenia strefowego maszyny wirtualnej i usługi Azure NetApp Files. W większości przypadków jest to wystarczające pod względem małych opóźnień. Zapewnia to również łatwą konserwację i administrowanie maszyną wirtualną oraz usługą Azure NetApp Files.
Dostępność
Aktualizacje i uaktualnienia systemu ANF są stosowane bez wpływu na środowisko klienta. Zdefiniowana umowa SLA wynosi 99,99%.
Woluminy i adresy IP oraz pule pojemności
W przypadku platformy ANF ważne jest, aby zrozumieć, w jaki sposób tworzona jest podstawowa infrastruktura. Pula pojemności jest tylko konstrukcją, która zapewnia pojemność i budżet wydajności oraz jednostkę rozliczeń na podstawie poziomu usługi puli pojemności. Pula pojemności nie ma fizycznej relacji z podstawową infrastrukturą. Podczas tworzenia woluminu w usłudze tworzony jest punkt końcowy magazynu. Pojedynczy adres IP jest przypisywany do tego punktu końcowego magazynu w celu zapewnienia dostępu do danych do woluminu. Jeśli tworzysz kilka woluminów, wszystkie woluminy są dystrybuowane między bazową flotę bez systemu operacyjnego, powiązaną z tym punktem końcowym magazynu. AnF ma logikę, która automatycznie dystrybuuje obciążenia klientów po osiągnięciu wstępnie zdefiniowanego poziomu woluminów lub/i pojemności skonfigurowanego magazynu. Możesz zauważyć takie przypadki, ponieważ nowy punkt końcowy magazynu z nowym adresem IP jest tworzony automatycznie w celu uzyskania dostępu do woluminów. Usługa ANF nie zapewnia kontroli klienta nad tą logiką dystrybucji.
Wolumin dziennika i wolumin kopii zapasowej dziennika
"Wolumin dziennika" (/hana/log) służy do zapisywania dziennika ponownego wykonania online. W związku z tym w tym woluminie znajdują się otwarte pliki i nie ma sensu migawek tego woluminu. Pliki dziennika ponownego wykonania online są archiwizowane lub kopii zapasowej woluminu kopii zapasowej dziennika, gdy plik dziennika ponownego wykonania online jest pełny lub jest wykonywana kopia zapasowa dziennika ponownego wykonania. Aby zapewnić rozsądną wydajność tworzenia kopii zapasowych, wolumin kopii zapasowej dziennika wymaga dobrej przepływności. Aby zoptymalizować koszty magazynowania, warto skonsolidować wolumin dziennika kopii zapasowej wielu wystąpień HANA. Aby wiele wystąpień platformy HANA używało tego samego woluminu i zapisywało kopie zapasowe w różnych katalogach. Dzięki takiej konsolidacji można uzyskać większą przepływność, ponieważ trzeba nieco zwiększyć wolumin.
To samo dotyczy woluminu, do którego są używane pełne kopie zapasowe bazy danych HANA.
Wykonywanie kopii zapasowej
Oprócz kopii zapasowych przesyłania strumieniowego i usługi Azure Back kopii zapasowych baz danych SAP HANA zgodnie z opisem w artykule Backup guide for SAP HANA on Azure Virtual Machines (Tworzenie kopii zapasowych oprogramowania SAP HANA na maszynach wirtualnych platformy Azure) usługa Azure NetApp Files otwiera możliwość wykonywania kopii zapasowych migawek opartych na magazynie.
Oprogramowanie SAP HANA obsługuje:
- Obsługa tworzenia kopii zapasowych migawek opartych na magazynie dla pojedynczego systemu kontenerów z oprogramowaniem SAP HANA 1.0 SPS7 i nowszym
- Obsługa kopii zapasowych migawek opartych na magazynie dla środowisk HANA z wieloma kontenerami baz danych (MDC) z jedną dzierżawą z oprogramowaniem SAP HANA 2.0 SPS1 i nowszym
- Obsługa kopii zapasowych migawek opartych na magazynie dla środowisk HANA z wieloma dzierżawami z systemem SAP HANA 2.0 SPS4 i nowszymi
Tworzenie kopii zapasowych migawek opartych na magazynie to prosta procedura czteroetapowa,
- Tworzenie migawki bazy danych HANA (wewnętrznej) — działanie, które należy wykonać
- Platforma SAP HANA zapisuje dane w plikach danych w celu utworzenia spójnego stanu w magazynie — platforma HANA wykonuje ten krok w wyniku utworzenia migawki platformy HANA
- Utwórz migawkę na woluminie /hana/data w magazynie — krok, który należy wykonać. Nie ma potrzeby wykonywania migawki na woluminie /hana/log
- Usuwanie migawki bazy danych HANA (wewnętrznej) i wznawianie normalnego działania — krok, który należy wykonać
Ostrzeżenie
Brak ostatniego kroku lub niepowodzenie wykonania ostatniego kroku ma poważny wpływ na zapotrzebowanie na pamięć platformy SAP HANA i może prowadzić do zatrzymania platformy SAP HANA
BACKUP DATA FOR FULL SYSTEM CREATE SNAPSHOT COMMENT 'SNAPSHOT-2019-03-18:11:00';

az netappfiles snapshot create -g mygroup --account-name myaccname --pool-name mypoolname --volume-name myvolname --name mysnapname
BACKUP DATA FOR FULL SYSTEM CLOSE SNAPSHOT BACKUP_ID 47110815 SUCCESSFUL SNAPSHOT-2020-08-18:11:00';
Tę procedurę tworzenia kopii zapasowej migawki można zarządzać na różne sposoby przy użyciu różnych narzędzi. Jednym z przykładów jest skrypt języka Python "ntaphana_azure.py" dostępny w witrynie GitHub https://github.com/netapp/ntaphana Jest to przykładowy kod podany jako "as-is" bez żadnej konserwacji ani pomocy technicznej.
Uwaga
Migawka sama w sobie nie jest chronioną kopią zapasową, ponieważ znajduje się w tym samym magazynie fizycznym, w którym właśnie utworzono migawkę woluminu. Należy "chronić" co najmniej jedną migawkę dziennie w innej lokalizacji. Można to zrobić w tym samym środowisku, w zdalnym regionie platformy Azure lub w usłudze Azure Blob Storage.
Dostępne rozwiązania dla kopii zapasowej spójnej na poziomie aplikacji opartej na migawkach magazynu:
- Microsoft What is aplikacja systemu Azure Consistent Snapshot tool to narzędzie wiersza polecenia, które umożliwia ochronę danych dla baz danych innych firm. Obsługuje on całą aranżację wymaganą do umieszczenia baz danych w stanie spójnym na poziomie aplikacji przed wykonaniem migawki magazynu. Po utworzeniu migawki magazynu narzędzie zwraca bazy danych do stanu operacyjnego. Narzędzie AzAcSnap obsługuje kopie zapasowe oparte na migawkach dla dużych wystąpień HANA i usługi Azure NetApp Files. Aby uzyskać więcej informacji, przeczytaj artykuł Co to jest narzędzie do tworzenia migawek spójnych aplikacja systemu Azure
- Dla użytkowników produktów kopii zapasowych Commvault kolejną opcją jest Commvault IntelliSnap V.11.21 i nowsze. Ta lub nowsza wersja programu Commvault oferuje obsługę migawek usługi Azure NetApp Files. Artykuł Commvault IntelliSnap 11.21 zawiera więcej informacji.
Tworzenie kopii zapasowej migawki przy użyciu usługi Azure Blob Storage
Tworzenie kopii zapasowej w usłudze Azure Blob Storage jest ekonomiczną i szybką metodą zapisywania kopii zapasowych migawek magazynu bazy danych HANA opartej na protokole ANF. Aby zapisać migawki w usłudze Azure Blob Storage, preferowane jest narzędzie AzCopy. Pobierz najnowszą wersję tego narzędzia i zainstaluj je, na przykład w katalogu bin, w którym jest zainstalowany skrypt języka Python z usługi GitHub. Pobierz najnowsze narzędzie AzCopy:
root # wget -O azcopy_v10.tar.gz https://aka.ms/downloadazcopy-v10-linux && tar -xf azcopy_v10.tar.gz --strip-components=1
Saving to: ‘azcopy_v10.tar.gz’
Najbardziej zaawansowaną funkcją jest opcja SYNC. Jeśli używasz opcji SYNCHRONIZACJA, narzędzie azcopy przechowuje zsynchronizowane źródło i katalog docelowy. Użycie parametru --delete-destination jest ważne. Bez tego parametru azcopy nie usuwa plików w lokacji docelowej, a wykorzystanie miejsca po stronie docelowej wzrośnie. Utwórz kontener blokowych obiektów blob na koncie usługi Azure Storage. Następnie utwórz klucz sygnatury dostępu współdzielonego dla kontenera obiektów blob i zsynchronizuj folder migawki z kontenerem obiektów blob platformy Azure.
Jeśli na przykład należy zsynchronizować codzienną migawkę z kontenerem obiektów blob platformy Azure w celu ochrony danych. I tylko jedna migawka powinna być przechowywana, można użyć poniższego polecenia.
root # > azcopy sync '/hana/data/SID/mnt00001/.snapshot' 'https://azacsnaptmytestblob01.blob.core.windows.net/abc?sv=2021-02-02&ss=bfqt&srt=sco&sp=rwdlacup&se=2021-02-04T08:25:26Z&st=2021-02-04T00:25:26Z&spr=https&sig=abcdefghijklmnopqrstuvwxyz' --recursive=true --delete-destination=true
Następne kroki
Przeczytaj artykuł: