Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Aby ustanowić wysoką dostępność w lokalnym wdrożeniu SAP HANA, możesz użyć replikacji systemu SAP HANA lub magazynu udostępnionego.
Obecnie na maszynach wirtualnych platformy Azure replikacja systemu SAP HANA na platformie Azure jest jedyną obsługiwaną funkcją wysokiej dostępności.
Replikacja systemu SAP HANA składa się z jednego węzła podstawowego i co najmniej jednego węzła pomocniczego. Zmiany danych w węźle podstawowym są replikowane synchronicznie lub asynchronicznie do węzła pomocniczego.
W tym artykule opisano sposób wdrażania i konfigurowania maszyn wirtualnych, instalowania struktury klastra oraz instalowania i konfigurowania replikacji systemu SAP HANA.
Przed rozpoczęciem zapoznaj się z następującymi uwagami SAP i dokumentami:
- SAP nota 1928533. Uwaga zawiera:
- Lista rozmiarów maszyn wirtualnych platformy Azure obsługiwanych na potrzeby wdrażania oprogramowania SAP.
- Ważne informacje o pojemności dla rozmiarów maszyn wirtualnych platformy Azure.
- Obsługiwane kombinacje oprogramowania SAP, systemu operacyjnego i bazy danych.
- Wymagane wersje jądra SAP dla systemów Windows i Linux na platformie Microsoft Azure.
- Program SAP Note 2015553 zawiera listę wymagań wstępnych dotyczących wdrożeń oprogramowania SAP obsługiwanych przez oprogramowanie SAP na platformie Azure.
- Program SAP Note 2205917 ma zalecane ustawienia systemu operacyjnego dla systemu SUSE Linux Enterprise Server 12 (SLES 12) dla aplikacji SAP.
- SAP Note 2684254 zawiera zalecane ustawienia dla systemu SUSE Linux Enterprise Server 15 (SLES 15) używanego do aplikacji SAP.
- SAP Note 2235581 zawiera systemy operacyjne obsługujące SAP HANA.
- Program SAP Note 2178632 zawiera szczegółowe informacje o wszystkich metrykach monitorowania zgłaszanych dla oprogramowania SAP na platformie Azure.
- Program SAP Note 2191498 ma wymaganą wersję agenta hosta SAP dla systemu Linux na platformie Azure.
- Program SAP Note 2243692 zawiera informacje o licencjonowaniu oprogramowania SAP dla systemu Linux na platformie Azure.
- Program SAP Note 1984787 zawiera ogólne informacje o systemie SUSE Linux Enterprise Server 12.
- Program SAP Note 1999351 zawiera więcej informacji dotyczących rozwiązywania problemów z rozszerzeniem rozszerzonego monitorowania platformy Azure dla oprogramowania SAP.
- SAP Note 401162 zawiera informacje o tym, jak unikać błędów "adres już w użyciu" podczas konfigurowania replikacji systemu HANA.
- Wiki wsparcia społeczności SAP zawiera wszystkie wymagane noty SAP dla systemu Linux.
- Certyfikowane platformy IaaS oprogramowania SAP HANA.
- Przewodnik planowania i implementacji usługi Azure Virtual Machines dla oprogramowania SAP w systemie Linux .
- Przewodnik wdrażania usługi Azure Virtual Machines dla oprogramowania SAP w systemie Linux .
- Przewodnik wdrażania DBMS na maszynach wirtualnych Azure dla SAP w systemie Linux.
-
Przewodniki dotyczące najlepszych rozwiązań systemu SUSE Linux Enterprise Server for SAP Applications 15 oraz przewodniki dotyczące najlepszych rozwiązań dla systemu SUSE Linux Enterprise Server for SAP Applications 12:
- Konfigurowanie infrastruktury zoptymalizowanej pod kątem wydajności usługi SAP HANA SR (SLES dla aplikacji SAP). Ten przewodnik zawiera wszystkie informacje wymagane do skonfigurowania replikacji systemu SAP HANA na potrzeby programowania lokalnego. Skorzystaj z tego przewodnika jako punktu odniesienia.
- Konfigurowanie infrastruktury zoptymalizowanej pod kątem kosztów (SLES dla aplikacji SAP HANA SR).
Planowanie wysokiej dostępności oprogramowania SAP HANA
Aby uzyskać wysoką dostępność, zainstaluj platformę SAP HANA na dwóch maszynach wirtualnych. Dane są replikowane przy użyciu replikacji systemu HANA.
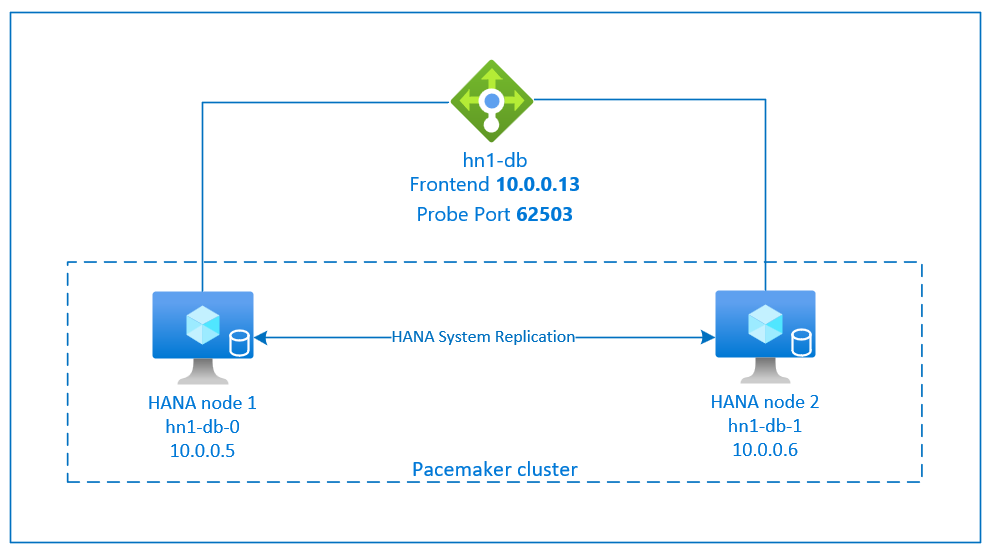
Konfiguracja replikacji systemu SAP HANA używa dedykowanej nazwy hosta wirtualnego i wirtualnych adresów IP. Na platformie Azure potrzebny jest moduł równoważenia obciążenia do wdrożenia wirtualnego adresu IP.
Na powyższej ilustracji przedstawiono przykładowy moduł równoważenia obciążenia, który ma następujące konfiguracje:
- Adres IP frontonu: 10.0.0.13 dla HN1-db
- Port sondy: 62503
Przygotowywanie infrastruktury
Agent zasobów dla platformy SAP HANA jest zawarty w systemie SUSE Linux Enterprise Server for SAP Applications. Obraz systemu SUSE Linux Enterprise Server dla aplikacji SAP w wersji 12 lub 15 jest dostępny w serwisie Azure Marketplace. Możesz użyć obrazu do wdrożenia nowych maszyn wirtualnych.
Ręczne wdrażanie maszyn wirtualnych z systemem Linux za pośrednictwem witryny Azure Portal
W tym dokumencie przyjęto założenie, że grupa zasobów, usługa Azure Virtual Network i podsieć zostały już wdrożone.
Wdrażanie maszyn wirtualnych dla platformy SAP HANA. Wybierz odpowiedni obraz SLES, który jest obsługiwany przez system HANA. Maszynę wirtualną można wdrożyć w dowolnej z dostępnych opcji – zestawie skalowania maszyn wirtualnych, strefie dostępności lub zestawie dostępności.
Ważne
Upewnij się, że wybrany system operacyjny ma certyfikat SAP dla platformy SAP HANA na określonych typach maszyn wirtualnych, które mają być używane we wdrożeniu. Możesz wyszukać typy maszyn wirtualnych z certyfikatem SAP HANA i ich wersje systemu operacyjnego w platformach IaaS certyfikowanych dla SAP HANA. Upewnij się, że zapoznasz się ze szczegółami typu maszyny wirtualnej, aby uzyskać pełną listę wersji systemu operacyjnego obsługiwanych przez platformę SAP HANA dla określonego typu maszyny wirtualnej.
Konfigurowanie modułu równoważenia obciążenia platformy Azure
Podczas konfigurowania maszyny wirtualnej masz możliwość utworzenia nowego lub wybrania istniejącego modułu równoważenia obciążenia w sekcji sieciowej. Wykonaj poniższe kroki, aby skonfigurować standardowy moduł równoważenia obciążenia na potrzeby konfiguracji bazy danych HANA o wysokiej dostępności.
Wykonaj kroki opisane w temacie Tworzenie modułu równoważenia obciążenia, aby skonfigurować standardowy moduł równoważenia obciążenia dla systemu SAP o wysokiej dostępności przy użyciu witryny Azure Portal. Podczas konfigurowania modułu równoważenia obciążenia należy wziąć pod uwagę następujące kwestie:
- Konfiguracja adresu IP frontend: utwórz adres IP frontend. Wybierz tę samą sieć wirtualną i nazwę podsieci co maszyny wirtualne bazy danych.
- Pula zaplecza: utwórz pulę zaplecza i dodaj maszyny wirtualne bazy danych.
-
Reguły ruchu przychodzącego: utwórz regułę równoważenia obciążenia. Wykonaj te same kroki dla obu reguł równoważenia obciążenia.
- Adres IP frontonu: wybierz adres IP frontonu.
- Pula zaplecza: Wybierz pulę zaplecza.
- Porty wysokiej dostępności: wybierz tę opcję.
- Protokół: wybierz pozycję TCP.
-
Sonda kondycji: utwórz sondę kondycji z następującymi szczegółami:
- Protokół: wybierz pozycję TCP.
- Port: na przykład 625<nr instancji>.
- Interwał: wprowadź wartość 5.
- Próg sondy: wprowadź 2.
- Limit czasu bezczynności (w minutach): wprowadź wartość 30.
- Włącz pływający adres IP: wybierz tę opcję.
Uwaga
Właściwość konfiguracji sondy zdrowotnej numberOfProbes, znana w portalu jako próg niezdrowości, nie jest uwzględniana. Aby kontrolować liczbę pomyślnych lub zakończonych niepowodzeniem kolejnych sond, ustaw właściwość probeThreshold na 2. Obecnie nie można ustawić tej właściwości przy użyciu portalu Azure, dlatego użyj Azure CLI lub polecenia PowerShell.
Aby uzyskać więcej informacji na temat wymaganych portów SAP HANA, przeczytaj rozdział Połączenia z bazami danych dzierżawców w przewodniku Bazy danych dzierżawców SAP HANA lub SAP Note 2388694.
Uwaga
Kiedy maszyny wirtualne, które nie mają publicznych adresów IP, są umieszczane w puli back-end standardowego wewnętrznego wystąpienia usługi Azure Load Balancer (bez publicznego adresu IP), domyślna konfiguracja nie zapewnia wychodzącej łączności internetowej. Aby zezwolić na routing do publicznych punktów końcowych, możesz wykonać dodatkowe kroki. Aby uzyskać szczegóły dotyczące łączności wychodzącej, zobacz Publiczna łączność punktów końcowych dla maszyn wirtualnych z użyciem usługi Azure Standard Load Balancer w scenariuszach wysokiej dostępności SAP.
Ważne
- Nie włączaj sygnatur czasowych protokołu TCP na maszynach wirtualnych platformy Azure, które znajdują się za Azure Load Balancer. Włączenie sygnatur czasowych protokołu TCP powoduje, że sondy kondycji zawodzą. Ustaw parametr
net.ipv4.tcp_timestampsna0. Aby uzyskać szczegółowe informacje, zobacz sondy kondycji usługi Load Balancer lub notę SAP 2382421. - Aby zapobiec zmianie ręcznie ustawionej
net.ipv4.tcp_timestampswartości z0powrotem na1, zaktualizuj program saptune do wersji 3.1.1 lub nowszej. Aby uzyskać więcej informacji, zobacz saptune 3.1.1 — Czy muszę zaktualizować?.
Utwórz klaster Pacemaker
Wykonaj kroki opisane w temacie Konfigurowanie programu Pacemaker na serwerze SUSE Linux Enterprise Server na platformie Azure , aby utworzyć podstawowy klaster Pacemaker dla tego serwera HANA. Możesz użyć tego samego klastra Pacemaker dla systemów SAP HANA i SAP NetWeaver (A)SCS.
Instalowanie platformy SAP HANA
Kroki opisane w tej sekcji korzystają z następujących prefiksów:
- [A]: Krok dotyczy wszystkich węzłów.
- [1]: Krok dotyczy tylko węzła 1.
- [2]: Krok dotyczy tylko węzła 2 klastra Pacemaker.
Zastąp <placeholders> wartościami instalacji oprogramowania SAP HANA.
[A] Skonfiguruj układ dysku przy użyciu Menedżera woluminów logicznych (LVM).
Zalecamy używanie lvm dla woluminów, które przechowują dane i pliki dziennika. W poniższym przykładzie przyjęto założenie, że maszyny wirtualne mają cztery dołączone dyski danych używane do tworzenia dwóch woluminów.
Uruchom to polecenie, aby wyświetlić listę wszystkich dostępnych dysków:
ls /dev/disk/azure/scsi1/lun*Przykładowe wyjście:
/dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 /dev/disk/azure/scsi1/lun2 /dev/disk/azure/scsi1/lun3Utwórz woluminy fizyczne dla wszystkich dysków, których chcesz użyć:
sudo pvcreate /dev/disk/azure/scsi1/lun0 sudo pvcreate /dev/disk/azure/scsi1/lun1 sudo pvcreate /dev/disk/azure/scsi1/lun2 sudo pvcreate /dev/disk/azure/scsi1/lun3Utwórz grupę woluminów dla plików danych. Użyj jednej grupy woluminów dla plików dziennika i jednej grupy woluminów dla udostępnionego katalogu sap HANA:
sudo vgcreate vg_hana_data_<HANA SID> /dev/disk/azure/scsi1/lun0 /dev/disk/azure/scsi1/lun1 sudo vgcreate vg_hana_log_<HANA SID> /dev/disk/azure/scsi1/lun2 sudo vgcreate vg_hana_shared_<HANA SID> /dev/disk/azure/scsi1/lun3Utwórz woluminy logiczne.
Wolumin liniowy jest tworzony podczas używania
lvcreatebez przełącznika-i. Zalecamy utworzenie woluminu pasmowego w celu uzyskania lepszej wydajności operacji wejścia/wyjścia. Wyrównuj rozmiary pasków do wartości opisanych w konfiguracjach magazynu maszyn wirtualnych SAP HANA. Argument-ipowinien być liczbą bazowych woluminów fizycznych, a-Iargumentem jest rozmiar paska.Jeśli na przykład dwa woluminy fizyczne są używane dla woluminu danych,
-iargument przełącznika jest ustawiony na 2, a rozmiar paska dla woluminu danych to 256KiB. Jeden wolumin fizyczny jest używany dla woluminu dziennika, więc przełączniki-i-Inie są jawnie używane dla poleceń woluminu dziennika.Ważne
Jeśli używasz więcej niż jednego woluminu fizycznego dla każdego woluminu danych, woluminu dziennika lub udostępnionego woluminu, użyj przełącznika
-ii ustaw go jako liczbę woluminów fizycznych bazowych. Podczas tworzenia woluminu paskowego użyj przełącznika-I, aby określić rozmiar paska.Aby uzyskać zalecane konfiguracje magazynu, w tym rozmiary pasków i liczbę dysków, zobacz Konfiguracje magazynu dla maszyn wirtualnych SAP HANA.
sudo lvcreate <-i number of physical volumes> <-I stripe size for the data volume> -l 100%FREE -n hana_data vg_hana_data_<HANA SID> sudo lvcreate -l 100%FREE -n hana_log vg_hana_log_<HANA SID> sudo lvcreate -l 100%FREE -n hana_shared vg_hana_shared_<HANA SID> sudo mkfs.xfs /dev/vg_hana_data_<HANA SID>/hana_data sudo mkfs.xfs /dev/vg_hana_log_<HANA SID>/hana_log sudo mkfs.xfs /dev/vg_hana_shared_<HANA SID>/hana_sharedUtwórz katalogi instalacji i skopiuj unikatowy identyfikator (UUID) wszystkich woluminów logicznych:
sudo mkdir -p /hana/data/<HANA SID> sudo mkdir -p /hana/log/<HANA SID> sudo mkdir -p /hana/shared/<HANA SID> # Write down the ID of /dev/vg_hana_data_<HANA SID>/hana_data, /dev/vg_hana_log_<HANA SID>/hana_log, and /dev/vg_hana_shared_<HANA SID>/hana_shared sudo blkidEdytuj plik /etc/fstab, aby utworzyć
fstabwpisy dla trzech woluminów logicznych:sudo vi /etc/fstabWstaw następujące wiersze w pliku /etc/fstab :
/dev/disk/by-uuid/<UUID of /dev/mapper/vg_hana_data_<HANA SID>-hana_data> /hana/data/<HANA SID> xfs defaults,nofail 0 2 /dev/disk/by-uuid/<UUID of /dev/mapper/vg_hana_log_<HANA SID>-hana_log> /hana/log/<HANA SID> xfs defaults,nofail 0 2 /dev/disk/by-uuid/<UUID of /dev/mapper/vg_hana_shared_<HANA SID>-hana_shared> /hana/shared/<HANA SID> xfs defaults,nofail 0 2Zainstaluj nowe woluminy:
sudo mount -a
[A] Skonfiguruj układ dysku przy użyciu dysków zwykłych.
W przypadku systemów demonstracyjnych można umieścić dane i pliki dziennika HANA na jednym dysku.
Utwórz partycję na /dev/disk/azure/scsi1/lun0 i sformatuj ją przy użyciu systemu XFS:
sudo sh -c 'echo -e "n\n\n\n\n\nw\n" | fdisk /dev/disk/azure/scsi1/lun0' sudo mkfs.xfs /dev/disk/azure/scsi1/lun0-part1 # Write down the ID of /dev/disk/azure/scsi1/lun0-part1 sudo /sbin/blkid sudo vi /etc/fstabWstaw ten wiersz w pliku /etc/fstab :
/dev/disk/by-uuid/<UUID> /hana xfs defaults,nofail 0 2Utwórz katalog docelowy i zainstaluj dysk:
sudo mkdir /hana sudo mount -a
[A] Skonfiguruj rozpoznawanie nazw hostów dla wszystkich hostów.
Możesz użyć serwera DNS lub zmodyfikować plik /etc/hosts na wszystkich węzłach. W tym przykładzie pokazano, jak używać pliku /etc/hosts . Zastąp adresy IP i nazwy hostów w następujących poleceniach.
Edytuj plik /etc/hosts:
sudo vi /etc/hostsWstaw następujące wiersze w pliku /etc/hosts . Zmień adresy IP i nazwy hostów, aby odpowiadały twojemu środowisku.
10.0.0.5 hn1-db-0 10.0.0.6 hn1-db-1
[A] Zainstaluj oprogramowanie SAP HANA, postępując zgodnie z dokumentacją systemu SAP.
Konfigurowanie replikacji systemu SAP HANA 2.0
Kroki opisane w tej sekcji korzystają z następujących prefiksów:
- [A]: Krok dotyczy wszystkich węzłów.
- [1]: Krok dotyczy tylko węzła 1.
- [2]: Krok dotyczy tylko węzła 2 klastra Pacemaker.
Zastąp <placeholders> wartościami instalacji oprogramowania SAP HANA.
[1] Utwórz bazę danych dzierżawcy.
Jeśli używasz oprogramowania SAP HANA 2.0 lub SAP HANA MDC, utwórz bazę danych dzierżawcy dla systemu SAP NetWeaver.
Uruchom następujące polecenie jako <HANA SID>adm:
hdbsql -u SYSTEM -p "<password>" -i <instance number> -d SYSTEMDB 'CREATE DATABASE <SAP SID> SYSTEM USER PASSWORD "<password>"'[1] Konfigurowanie replikacji systemu w pierwszym węźle:
Najpierw wykonaj kopię zapasową baz danych jako <HANA SID>adm:
hdbsql -d SYSTEMDB -u SYSTEM -p "<password>" -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file for SYS>')" hdbsql -d <HANA SID> -u SYSTEM -p "<password>" -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file for HANA SID>')" hdbsql -d <SAP SID> -u SYSTEM -p "<password>" -i <instance number> "BACKUP DATA USING FILE ('<name of initial backup file for SAP SID>')"Następnie skopiuj pliki infrastruktury kluczy publicznych (PKI) systemu do lokacji dodatkowej:
scp /usr/sap/<HANA SID>/SYS/global/security/rsecssfs/data/SSFS_<HANA SID>.DAT hn1-db-1:/usr/sap/<HANA SID>/SYS/global/security/rsecssfs/data/ scp /usr/sap/<HANA SID>/SYS/global/security/rsecssfs/key/SSFS_<HANA SID>.KEY hn1-db-1:/usr/sap/<HANA SID>/SYS/global/security/rsecssfs/key/Utwórz lokację główną:
hdbnsutil -sr_enable --name=<site 1>[2] Konfigurowanie replikacji systemu w drugim węźle:
Zarejestruj drugi węzeł, aby rozpocząć replikację systemu.
Uruchom następujące polecenie jako <HANA SID>adm:
sapcontrol -nr <instance number> -function StopWait 600 10 hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2>
Implementowanie agentów zasobów platformy HANA
SusE udostępnia dwa różne pakiety oprogramowania dla agenta zasobów Pacemaker do zarządzania platformą SAP HANA. Pakiety oprogramowania SAPHanaSR i SAPHanaSR-angi używają nieco innej składni i parametrów i nie są zgodne. Aby uzyskać szczegółowe informacje i różnice między platformami SAPHanaSR i SAPHanaSR-angi, zobacz informacje o wersji systemu SUSE i dokumentację . Ten dokument obejmuje oba pakiety na osobnych kartach w odpowiednich sekcjach.
Ostrzeżenie
Nie zamieniaj pakietu SAPHanaSR na SAPHanaSR-angi w już skonfigurowanym klastrze. Uaktualnienie z platformy SAPHanaSR do platformy SAPHanaSR-angi wymaga określonej procedury. Zobacz wpis w blogu SUSE, aby uzyskać więcej informacji: Jak przeprowadzić uaktualnienie do oprogramowania SAPHanaSR-angi.
- [A] Zainstaluj pakiety wysokiej dostępności oprogramowania SAP HANA:
Ważne
Oprogramowanie SAPHanaSR-angi ma minimalne wymaganie dotyczące wersji oprogramowania SAP HANA 2.0 SPS 05 i SUSE SLES dla aplikacji SAP 15 z dodatkiem SP4 lub nowszym.
Uruchom następujące polecenie, aby zainstalować pakiety wysokiej dostępności:
sudo zypper install SAPHanaSR-angi
Konfiguracja dostawców HA/DR dla SAP HANA
Dostawcy wysokiej dostępności/odzyskiwania po awarii platformy SAP HANA optymalizują integrację z klasterem i poprawiają wykrywanie, gdy potrzebne jest przełączenie awaryjne klastra. Główny skrypt zaczepienia to SAPHanaSR (dla pakietu SAPHanaSR) / susHanaSR (dla platformy SAPHanaSR-angi). Zdecydowanie zalecamy skonfigurowanie haka języka Python SAPHanaSR/susHanaSR. W przypadku platformy HANA 2.0 SPS 05 lub nowszej zalecamy zaimplementowanie zarówno oprogramowania SAPHanaSR/susHanaSR, jak i haków susChkSrv.
Hak susChkSrv rozszerza funkcjonalność głównego dostawcy SAPHanaSR/susHanaSR HA. Działa, gdy proces HANA hdbindexserver ulega awarii. W przypadku awarii pojedynczego procesu platforma HANA zwykle próbuje go uruchomić ponownie. Ponowne uruchomienie procesu indexserver może zająć dużo czasu, podczas którego baza danych HANA nie odpowiada.
W przypadku zaimplementowania polecenia susChkSrv wykonywana jest natychmiastowa i konfigurowalna akcja. Akcja wyzwala przejście w tryb failover w skonfigurowanym przedziale czasu zamiast oczekiwania na ponowne uruchomienie procesu hdbindexserver w tym samym węźle.
- [A] Zatrzymaj HANA na obu węzłach.
Uruchom następujący kod jako <sap-sid>adm:
sapcontrol -nr <instance number> -function StopSystem
[A] Zainstaluj haki replikacji systemu HANA. Punkty zaczepienia muszą być zainstalowane w obu węzłach bazy danych HANA.
Wskazówka
Hak języka Python SAPHanaSR można zaimplementować tylko dla platformy HANA 2.0. Pakiet SAPHanaSR musi być co najmniej w wersji 0.153.
Hak SAPHanaSR-angi Python można zaimplementować tylko dla platformy HANA 2.0 SPS 05 lub nowszej.
Funkcja susChkSrv Python wymaga SAP HANA 2.0 SPS 05, a zainstalowana musi być wersja SAPHanaSR 0.161.1_BF lub nowsza.[A] Dostosuj global.ini na każdym węźle klastra.
Jeśli zdecydujesz się nie używać zalecanego haka susChkSrv, usuń cały
[ha_dr_provider_suschksrv]blok z następujących parametrów. Możesz dostosować zachowaniesusChkSrvza pomocą parametruaction_on_lost. Prawidłowe wartości to [ignore|stop|kill|fence].[ha_dr_provider_sushanasr] provider = susHanaSR path = /usr/share/SAPHanaSR-angi execution_order = 1 [ha_dr_provider_suschksrv] provider = susChkSrv path = /usr/share/SAPHanaSR-angi execution_order = 3 action_on_lost = fence [trace] ha_dr_sushanasr = info ha_dr_suschksrv = infoJeśli wskażesz ścieżkę parametru do lokalizacji domyślnej
/usr/share/SAPHanaSR-angi, kod punktu zaczepienia języka Python zostanie automatycznie zaktualizowany za pośrednictwem aktualizacji systemu operacyjnego lub aktualizacji pakietów. Platforma HANA używa aktualizacji kodu hakowego przy następnym ponownym uruchomieniu. Za pomocą opcjonalnej ścieżki, takiej jak/hana/shared/myHooks, można rozdzielić aktualizacje systemu operacyjnego od wersji hooka, której używasz.[A] Klaster wymaga konfiguracji sudoers w każdym węźle klastra dla <sap-sid>adm. W tym przykładzie jest to osiągane przez utworzenie nowego pliku.
Uruchom następujące polecenie jako root. Zastąp <sid> małymi literami identyfikatora systemu SAP, <SID> wielkimi literami identyfikatora systemu SAP oraz <siteA/B> wybranymi nazwami witryn HANA.
cat << EOF > /etc/sudoers.d/20-saphana # Needed for susHanaSR and susChkSrv Python hooks Cmnd_Alias SOK_SITEA = /usr/sbin/crm_attribute -n hana_<sid>_site_srHook_<siteA> -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEA = /usr/sbin/crm_attribute -n hana_<sid>_site_srHook_<siteA> -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias SOK_SITEB = /usr/sbin/crm_attribute -n hana_<sid>_site_srHook_<siteB> -v SOK -t crm_config -s SAPHanaSR Cmnd_Alias SFAIL_SITEB = /usr/sbin/crm_attribute -n hana_<sid>_site_srHook_<siteB> -v SFAIL -t crm_config -s SAPHanaSR Cmnd_Alias HELPER_TAKEOVER = /usr/bin/SAPHanaSR-hookHelper --sid=<SID> --case=checkTakeover Cmnd_Alias HELPER_FENCE = /usr/bin/SAPHanaSR-hookHelper --sid=<SID> --case=fenceMe <sid>adm ALL=(ALL) NOPASSWD: SOK_SITEA, SFAIL_SITEA, SOK_SITEB, SFAIL_SITEB, HELPER_TAKEOVER, HELPER_FENCE EOFAby uzyskać szczegółowe informacje na temat implementacji hooka replikacji systemu SAP HANA, zobacz Konfigurowanie dostawców wysokiej dostępności/odzyskiwania po awarii systemu HANA.
[A] Uruchom platformę SAP HANA w obu węzłach. Uruchom następujące polecenie jako <sap-sid>adm:
sapcontrol -nr <instance number> -function StartSystem[1] Sprawdź instalację haka. Uruchom następujące polecenie jako <sap-sid>adm w aktywnej lokalizacji replikacji systemu HANA:
cdtrace grep HADR.*load.*susHanaSR nameserver_*.trc grep susHanaSR.init nameserver_*.trc # Example output # ha_dr_provider HADRProviderManager.cpp(00083) : loading HA/DR Provider 'susHanaSR' from /usr/share/SAPHanaSR-angi
-
[1] Sprawdź instalację haka susChkSrv.
Uruchom następujące polecenie jako <sap-sid>adm na maszynach wirtualnych HANA:
cdtrace egrep '(LOST:|STOP:|START:|DOWN:|init|load|fail)' nameserver_suschksrv.trc # Example output # 2022-11-03 18:06:21.116728 susChkSrv.init() version 0.7.7, parameter info: action_on_lost=fence stop_timeout=20 kill_signal=9 # 2022-11-03 18:06:27.613588 START: indexserver event looks like graceful tenant start # 2022-11-03 18:07:56.143766 START: indexserver event looks like graceful tenant start (indexserver started)
Tworzenie zasobów klastra SAP HANA
- [1] Najpierw utwórz zasób topologii HANA.
Uruchom następujące polecenia w jednym z węzłów klastra Pacemaker:
sudo crm configure property maintenance-mode=true
# Replace <placeholders> with your instance number and HANA system ID
sudo crm configure primitive rsc_SAPHanaTopology_<HANA SID>_HDB<instance number> ocf:suse:SAPHanaTopology \
op monitor interval="50" timeout="600" \
op start interval="0" timeout="600" \
op stop interval="0" timeout="300" \
params SID="<HANA SID>" InstanceNumber="<instance number>"
sudo crm configure clone cln_SAPHanaTopology_<HANA SID>_HDB<instance number> rsc_SAPHanaTopology_<HANA SID>_HDB<instance number> \
meta clone-node-max="1" interleave="true"
- [1] Następnie utwórz zasoby platformy HANA:
# Replace <placeholders> with your instance number and HANA system ID.
sudo crm configure primitive rsc_SAPHanaController_<HANA SID>_HDB<instance number> ocf:suse:SAPHanaController \
op start interval="0" timeout="3600" \
op stop interval="0" timeout="3600" \
op promote interval="0" timeout="3600" \
op demote interval="0" timeout="320" \
op monitor interval="60" role="Promoted" timeout="700" \
op monitor interval="61" role="Unpromoted" timeout="700" \
params SID="<HANA SID>" InstanceNumber="<instance number>" PREFER_SITE_TAKEOVER="true" \
DUPLICATE_PRIMARY_TIMEOUT="7200" AUTOMATED_REGISTER="false" \
meta priority=100
sudo crm configure clone msl_SAPHanaController_<HANA SID>_HDB<instance number> rsc_SAPHanaController_<HANA SID>_HDB<instance number> \
meta clone-node-max="1" interleave="true" promotable="true"
SapHanaSR-angi dodaje nowego agenta zasobów SAPHanaFilesystem do monitorowania dostępu do odczytu/zapisu do /hana/shared/SID. System operacyjny statycznie montuje system plików /hana/shared/SID, a każdy host zawiera wpisy w pliku /etc/fstab. System SAPHanaFilesystem i pacemaker nie instaluje systemu plików dla platformy HANA.
Zalecamy zaimplementowanie systemu SAPHanaFilesystem w przypadku używania systemu plików NFS dla lokalizacji /hana/shared/SID. Gdy /hana/shared/SID znajduje się na urządzeniu blokowym, takim jak dysk zarządzany platformy Azure, użycie systemu SAPHanaFilesystem jest opcjonalne.
# Replace <placeholders> with your instance number and HANA system ID.
sudo crm configure primitive rsc_SAPHanaFilesystem_<HANA SID>_HDB<instance number> ocf:suse:SAPHanaFilesystem \
op start interval="0" timeout="10" \
op stop interval="0" timeout="20" \
op monitor interval="120" timeout="120" \
params SID="<HANA SID>" InstanceNumber="<instance number>" ON_FAIL_ACTION="fence"
sudo crm configure clone cln_SAPHanaFilesystem_<HANA SID>_HDB<instance number> rsc_SAPHanaFilesystem_<HANA SID>_HDB<instance number> \
meta clone-node-max="1" interleave="true"
- [1] Kontynuuj korzystanie z zasobów klastra dla wirtualnych adresów IP, wartości domyślnych i ograniczeń.
# Replace <placeholders> with your instance number, HANA system ID, and the front-end IP address of the Azure load balancer.
sudo crm configure primitive rsc_ip_<HANA SID>_HDB<instance number> ocf:heartbeat:IPaddr2 \
meta target-role="Started" \
op start timeout=60s on-fail=fence \
op monitor interval="10s" timeout="20s" \
params ip="<front-end IP address>"
sudo crm configure primitive rsc_nc_<HANA SID>_HDB<instance number> azure-lb port=625<instance number> \
op monitor timeout=20s interval=10 \
meta resource-stickiness=0
sudo crm configure group g_ip_<HANA SID>_HDB<instance number> rsc_ip_<HANA SID>_HDB<instance number> rsc_nc_<HANA SID>_HDB<instance number>
sudo crm configure colocation col_saphana_ip_<HANA SID>_HDB<instance number> 4000: g_ip_<HANA SID>_HDB<instance number>:Started \
msl_SAPHanaController_<HANA SID>_HDB<instance number>:Promoted
sudo crm configure order ord_SAPHana_<HANA SID>_HDB<instance number> Optional: cln_SAPHanaTopology_<HANA SID>_HDB<instance number> \
msl_SAPHanaController_<HANA SID>_HDB<instance number>
# Clean up the HANA resources. The HANA resources might have failed because of a known issue.
sudo crm resource cleanup rsc_SAPHanaController_<HANA SID>_HDB<instance number>
sudo crm configure property priority-fencing-delay=30
sudo crm configure property maintenance-mode=false
sudo crm configure rsc_defaults resource-stickiness=1000
sudo crm configure rsc_defaults migration-threshold=5000
Ważne
Zalecamy ustawienie AUTOMATED_REGISTER na false tylko podczas przeprowadzania dokładnych testów przełączania awaryjnego, aby zapobiec automatycznemu zalogowaniu wystąpienia podstawowego w trybie awarii jako pomocniczego. Po pomyślnym zakończeniu testów trybu failover ustaw AUTOMATED_REGISTER na true, aby po przejęciu replikacja systemu została automatycznie wznowiona.
Upewnij się, że stan klastra to OK i że uruchomiono wszystkie zasoby. Nie ma znaczenia, na którym węźle zasoby działają.
sudo crm_mon -r
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full list of resources:
#
# stonith-sbd (stonith:external/sbd): Started hn1-db-0
# Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
# Started: [ hn1-db-0 hn1-db-1 ]
# Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_HDB03
# rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
# rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0
Konfiguracja aktywnej replikacji systemu HANA z obsługą odczytu w klastrze Pacemaker
W systemie SAP HANA 2.0 SPS 01 i nowszych wersjach system SAP umożliwia aktywną/odczytową konfigurację replikacji systemu SAP HANA. W tym scenariuszu pomocnicze systemy replikacji systemu SAP HANA mogą być aktywnie używane na potrzeby obciążeń intensywnie korzystających z odczytu.
Aby obsługiwać tę konfigurację w klastrze, wymagany jest drugi wirtualny adres IP, aby klienci mogli uzyskać dostęp do pomocniczej bazy danych SAP HANA z obsługą odczytu. Aby upewnić się, że wtórna lokalizacja replikacji będzie nadal dostępna po przejęciu, klaster musi przenieść wirtualny adres IP wokół wtórnego zasobu SAPHana.
W tej sekcji opisano dodatkowe kroki potrzebne do zarządzania replikacją systemu HANA z włączoną obsługą aktywnego/odczytu w klastrze wysokiej dostępności SUSE, który używa drugiego wirtualnego adresu IP.
Przed kontynuowaniem upewnij się, że został w pełni skonfigurowany klaster wysokiej dostępności SUSE, który zarządza bazą danych SAP HANA zgodnie z opisem we wcześniejszych sekcjach.
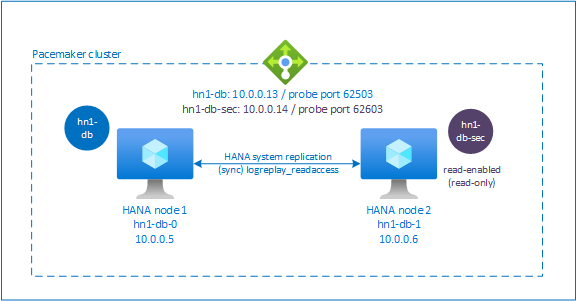
Konfigurowanie modułu równoważenia obciążenia na potrzeby replikacji systemu z aktywną obsługą odczytu
Aby wykonać dodatkowe kroki aprowizacji drugiego wirtualnego adresu IP, upewnij się, że skonfigurowano usługę Azure Load Balancer zgodnie z opisem w temacie Ręczne wdrażanie maszyn wirtualnych z systemem Linux za pośrednictwem witryny Azure Portal.
W przypadku standardowego modułu równoważenia obciążenia wykonaj te dodatkowe kroki na tym samym module równoważenia obciążenia, który utworzyłeś wcześniej.
- Utwórz drugą pulę adresów IP front-endu.
- Otwórz moduł równoważenia obciążenia, wybierz pulę adresów IP frontendu i wybierz Dodaj.
- Wprowadź nazwę drugiej puli adresów IP front-end (na przykład hana-secondaryIP).
- Ustaw Przypisanie na Statyczne i wprowadź adres IP (na przykład 10.0.0.14).
- Wybierz przycisk OK.
- Po utworzeniu nowej puli adresów IP przedniej warstwy, zanotuj adres IP przedniej warstwy.
- Utwórz sondę kondycji:
- W module równoważenia obciążenia wybierz pozycję Sondy kondycji i wybierz pozycję Dodaj.
- Wprowadź nazwę nowej sondy kondycji (na przykład hana-secondaryhp).
- Wybierz TCP jako protokół i port 626<numer wystąpienia>. Zachowaj wartość interwał ustawioną na 5, a wartość progu złej kondycji ustawioną na 2.
- Wybierz przycisk OK.
- Utwórz reguły równoważenia obciążenia:
- W module równoważenia obciążenia wybierz pozycję Reguły równoważenia obciążenia, a następnie wybierz pozycję Dodaj.
- Wprowadź nazwę nowej reguły modułu równoważenia obciążenia (na przykład hana-secondarylb).
- Wybierz przedni adres IP, pulę zaplecza i wcześniej utworzoną sondę sprawdzającą kondycję (na przykład hana-secondaryIP, hana-backend i hana-secondaryhp).
- Wybierz Porty HA.
- Zwiększ limit czasu bezczynności do 30 minut.
- Upewnij się, że włączono pływający adres IP.
- Wybierz przycisk OK.
Konfigurowanie systemu replikacji HANA z aktywnym/odczytywnym dostępem.
Kroki konfigurowania replikacji systemu HANA zostały opisane w temacie Konfigurowanie replikacji systemu SAP HANA 2.0. Jeśli wdrażasz pomocniczy scenariusz z obsługą odczytu, podczas konfigurowania replikacji systemu w drugim węźle uruchom następujące polecenie jako <adm SID HANA>:
sapcontrol -nr <instance number> -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> --operationMode=logreplay_readaccess
Dodawanie pomocniczego zasobu wirtualnego adresu IP
Drugi wirtualny adres IP i odpowiednie ograniczenie kolokacji można skonfigurować przy użyciu następujących poleceń:
crm configure property maintenance-mode=true
crm configure primitive rsc_secip_<HANA SID>_HDB<instance number> ocf:heartbeat:IPaddr2 \
op monitor interval="10s" timeout="20s" \
params ip="<secondary IP address>"
crm configure primitive rsc_secnc_<HANA SID>_HDB<instance number> azure-lb port=626<instance number> \
op monitor timeout=20s interval=10 \
meta resource-stickiness=0
crm configure group g_secip_<HANA SID>_HDB<instance number> rsc_secip_<HANA SID>_HDB<instance number> rsc_secnc_<HANA SID>_HDB<instance number>
crm configure colocation col_saphana_secip_<HANA SID>_HDB<instance number> 4000: g_secip_<HANA SID>_HDB<instance number>:Started \
msl_SAPHanaController_<HANA SID>_HDB<instance number>:Unpromoted
crm configure property maintenance-mode=false
Upewnij się, że stan klastra to OK i że uruchomiono wszystkie zasoby. Drugi wirtualny adres IP działa w lokacji pomocniczej razem z pomocniczym zasobem SAPHana.
sudo crm_mon -r
# Online: [ hn1-db-0 hn1-db-1 ]
#
# Full list of resources:
#
# stonith-sbd (stonith:external/sbd): Started hn1-db-0
# Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
# Started: [ hn1-db-0 hn1-db-1 ]
# Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
# Masters: [ hn1-db-0 ]
# Slaves: [ hn1-db-1 ]
# Resource Group: g_ip_HN1_HDB03
# rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0
# rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0
# Resource Group: g_secip_HN1_HDB03:
# rsc_secip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
# rsc_secnc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
W następnej sekcji opisano typowy zestaw testów trybu failover do wykonania.
Kluczowe aspekty testowania klastra HANA skonfigurowanego z wtórnym węzłem obsługującym odczyt:
Podczas migracji zasobu klastra
SAPHana_<HANA SID>_HDB<instance number>do programuhn1-db-1, drugi wirtualny adres IP jest przenoszony dohn1-db-0. Jeśli skonfigurowanoAUTOMATED_REGISTER="false"i replikacja systemu HANA nie jest rejestrowana automatycznie, drugi wirtualny adres IP działa nahn1-db-0, ponieważ serwer jest dostępny i usługi klastra są online.Podczas testowania awarii serwera drugie zasoby wirtualnego adresu IP (
rsc_secip_<HANA SID>_HDB<instance number>) i zasób portu modułu równoważenia obciążenia platformy Azure (rsc_secnc_<HANA SID>_HDB<instance number>) są uruchamiane na serwerze podstawowym wraz z podstawowymi zasobami wirtualnego adresu IP. Gdy serwer pomocniczy nie działa, aplikacje połączone z bazą danych HANA z włączoną obsługą odczytu łączą się z podstawową bazą danych HANA. Zachowanie jest oczekiwane, ponieważ nie chcesz, aby aplikacje połączone z bazą danych HANA z włączoną obsługą odczytu mogły być niedostępne, gdy serwer pomocniczy jest niedostępny.Gdy serwer pomocniczy jest dostępny, a usługi klastra są w trybie online, drugi wirtualny adres IP i zasoby portów są automatycznie przenoszone do serwera pomocniczego, mimo że replikacja systemu HANA może nie być zarejestrowana jako pomocnicza. Przed uruchomieniem usług klastra na tym serwerze upewnij się, że zarejestrowano pomocniczą bazę danych HANA jako włączoną do odczytu. Zasób klastra wystąpień platformy HANA można skonfigurować tak, aby automatycznie zarejestrował pomocniczą, ustawiając parametr
AUTOMATED_REGISTER="true".Podczas przełączania awaryjnego i powrotu istniejące połączenia dla aplikacji, które następnie używają drugiego wirtualnego adresu IP do nawiązania połączenia z bazą danych HANA, mogą zostać przerwane.
Testowanie konfiguracji klastra
W tej sekcji opisano sposób testowania konfiguracji. Każdy test zakłada, że użytkownik jest zalogowany jako użytkownik główny i że główny serwer sap HANA jest uruchomiony na maszynie hn1-db-0 wirtualnej.
Testowanie migracji
Przed rozpoczęciem testu upewnij się, że program Pacemaker nie ma żadnych nieudanych akcji (uruchom crm_mon -r), że nie ma żadnych nieoczekiwanych ograniczeń lokalizacji (na przykład pozostawienia testu migracji) i że platforma HANA jest w stanie synchronizacji, na przykład przez uruchomienie polecenia SAPHanaSR-showAttr.
hn1-db-0:~ # SAPHanaSR-showAttr
Global cib-update dcid prim sec sid topology
--------------------------------------------------
global 0.130728.2 1 SITE1 - HN1 ScaleUp
Resource promotable
-----------------------------------------
msl_SAPHanaController_HN1_HDB03 true
cln_SAPHanaTopology_HN1_HDB03
Site lpt lss mns opMode srHook srMode srPoll srr
-----------------------------------------------------------------------
SITE1 1722604101 4 hn1-db-0 logreplay PRIM sync PRIM P
SITE2 30 4 hn1-db-1 logreplay SWAIT sync SOK S
Host clone_state roles score site sra srah version vhost
---------------------------------------------------------------------------------------------
hn1-db-0 PROMOTED master1:master:worker:master 150 SITE1 - - 2.00.074.00 hn1-db-0
hn1-db-1 DEMOTED master1:master:worker:master 100 SITE2 - 2.00.074.00 hn1-db-1
Host clone_state roles score site sra srah version vhost
------------------------------------------------------------------------------------------------
hn1-db-0 PROMOTED master1:master:worker:master 150 SITE1 - - 2.00.074.00 hn1-db-0
hn1-db-1 SITE2 hn1-db-1
Aby przeprowadzić migrację węzła głównego platformy SAP HANA, uruchom następujące polecenie:
crm resource move msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1 force
Klaster przeprowadzi migrację węzła głównego platformy SAP HANA i grupy zawierającej wirtualny adres IP do hn1-db-1.
Po zakończeniu crm_mon -r migracji dane wyjściowe wyglądają następująco:
Online: [ hn1-db-0 hn1-db-1 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started hn1-db-1
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
Masters: [ hn1-db-1 ]
Stopped: [ hn1-db-0 ]
Resource Group: g_ip_HN1_HDB03
rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
Failed Actions:
* rsc_SAPHana_HN1_HDB03_start_0 on hn1-db-0 'not running' (7): call=84, status=complete, exitreason='none',
last-rc-change='Mon Aug 13 11:31:37 2018', queued=0ms, exec=2095ms
W przypadku AUTOMATED_REGISTER="false" klaster nie ponownie uruchomiłby niepowodzeniem zakończonej bazy danych HANA ani nie zarejestrowałby jej względem nowego głównego elementu na hn1-db-0. W takim przypadku skonfiguruj instancję HANA jako drugą, uruchamiając następujące polecenie:
su - <hana sid>adm
# Stop the HANA instance, just in case it is running
hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> sapcontrol -nr <instance number> -function StopWait 600 10
hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1>
Migracja tworzy ograniczenia lokalizacji, które należy usunąć ponownie:
# Switch back to root and clean up the failed state
exit
hn1-db-0:~ # crm resource clear msl_SAPHana_<HANA SID>_HDB<instance number>
Należy również wyczyścić stan zasobu węzła pomocniczego:
hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0
Monitoruj stan zasobu platformy HANA przy użyciu polecenia crm_mon -r. Po uruchomieniu HANA na hn1-db-0, dane wyjściowe wyglądają następująco:
Online: [ hn1-db-0 hn1-db-1 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started hn1-db-1
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_HDB03
rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
Blokowanie komunikacji sieciowej
Stan zasobu przed rozpoczęciem testu:
Online: [ hn1-db-0 hn1-db-1 ]
Full list of resources:
stonith-sbd (stonith:external/sbd): Started hn1-db-1
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03]
Started: [ hn1-db-0 hn1-db-1 ]
Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03]
Masters: [ hn1-db-1 ]
Slaves: [ hn1-db-0 ]
Resource Group: g_ip_HN1_HDB03
rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1
rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1
Wykonaj regułę zapory, aby zablokować komunikację w jednym z węzłów.
# Execute iptable rule on hn1-db-1 (10.0.0.6) to block the incoming and outgoing traffic to hn1-db-0 (10.0.0.5)
iptables -A INPUT -s 10.0.0.5 -j DROP; iptables -A OUTPUT -d 10.0.0.5 -j DROP
Gdy węzły klastra nie mogą komunikować się ze sobą, istnieje ryzyko scenariusza podzielonego mózgu. W takich sytuacjach węzły klastra będą próbować jednocześnie blokować się nawzajem, co spowoduje wyścig blokad.
Podczas konfigurowania urządzenia ogrodzeniowego zaleca się konfigurację właściwości pcmk_delay_max. Dlatego w przypadku scenariusza rozszczepienia klaster wprowadza losowe opóźnienie do wartości pcmk_delay_max w celu przeprowadzenia akcji odcięcia na każdym węźle. Węzeł z najkrótszym opóźnieniem zostanie wybrany do izolacji.
Ponadto, aby upewnić się, że węzeł z głównym systemem platformy HANA ma priorytet i wygrywa wyścig zabezpieczeń w scenariuszu podziału mózgu, zaleca się ustawienie właściwości priority-fencing-delay w konfiguracji klastra. Dzięki włączeniu właściwości "priority-fencing-delay" klaster może wprowadzić dodatkowe opóźnienie w działaniu ogrodzenia specjalnie na węźle hostującym zasób główny HANA, pozwalając węzłowi wygrać wyścig ogrodzenia.
Wykonaj poniższe polecenie, aby usunąć regułę zapory.
# If the iptables rule set on the server gets reset after a reboot, the rules will be cleared out. In case they have not been reset, please proceed to remove the iptables rule using the following command.
iptables -D INPUT -s 10.0.0.5 -j DROP; iptables -D OUTPUT -d 10.0.0.5 -j DROP
Testowanie ogrodzenia SBD
Możesz przetestować konfigurację SBD, zabijając proces inquisitor.
hn1-db-0:~ # ps aux | grep sbd
root 1912 0.0 0.0 85420 11740 ? SL 12:25 0:00 sbd: inquisitor
root 1929 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-360014056f268462316e4681b704a9f73 - slot: 0 - uuid: 7b862dba-e7f7-4800-92ed-f76a4e3978c8
root 1930 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-360014059bc9ea4e4bac4b18808299aaf - slot: 0 - uuid: 5813ee04-b75c-482e-805e-3b1e22ba16cd
root 1931 0.0 0.0 85456 11776 ? SL 12:25 0:00 sbd: watcher: /dev/disk/by-id/scsi-36001405b8dddd44eb3647908def6621c - slot: 0 - uuid: 986ed8f8-947d-4396-8aec-b933b75e904c
root 1932 0.0 0.0 90524 16656 ? SL 12:25 0:00 sbd: watcher: Pacemaker
root 1933 0.0 0.0 102708 28260 ? SL 12:25 0:00 sbd: watcher: Cluster
root 13877 0.0 0.0 9292 1572 pts/0 S+ 12:27 0:00 grep sbd
hn1-db-0:~ # kill -9 1912
Węzeł klastra <HANA SID>-db-<database 1> ponownie uruchamia się. Usługa Pacemaker może nie zostać ponownie uruchomiona. Upewnij się, że uruchamiasz go ponownie.
Przetestowanie ręcznej awarii systemu
Ręczne przełączenie awaryjne można przetestować, zatrzymując usługę Pacemaker na węźle hn1-db-0.
service pacemaker stop
Po przejściu w tryb failover możesz ponownie uruchomić usługę. Jeśli ustawisz wartość AUTOMATED_REGISTER="false", zasób SAP HANA w węźle hn1-db-0 nie może uruchomić się jako pomocniczy.
W takim przypadku skonfiguruj instancję HANA jako drugą, uruchamiając następujące polecenie:
service pacemaker start
su - <hana sid>adm
# Stop the HANA instance, just in case it is running
sapcontrol -nr <instance number> -function StopWait 600 10
hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1>
# Switch back to root and clean up the failed state
exit
crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0
Testy SUSE
Ważne
Upewnij się, że wybrany system operacyjny ma certyfikat SAP dla platformy SAP HANA na określonych typach maszyn wirtualnych, których planujesz użyć. Możesz wyszukać typy maszyn wirtualnych z certyfikatem SAP HANA i ich wersje systemu operacyjnego w platformach IaaS certyfikowanych dla SAP HANA. Upewnij się, że zapoznasz się ze szczegółami typu maszyny wirtualnej, którego planujesz użyć, aby uzyskać pełną listę wersji systemu operacyjnego obsługiwanych przez platformę SAP HANA dla tego typu maszyny wirtualnej.
Uruchom wszystkie przypadki testowe wymienione w przewodniku "Scenariusz zoptymalizowany pod kątem wydajności" platformy SAP HANA SR lub przewodniku "Scenariusz zoptymalizowany pod kątem kosztów" platformy SAP HANA SR, w zależności od scenariusza. Przewodniki wymienione w SLES dla najlepszych praktyk dotyczących SAP można znaleźć.
Poniższe testy to kopia opisów testów z przewodnika dotyczącego wydania SP1 dla SAP HANA SR Performance Optimized Scenario SUSE Linux Enterprise Server for SAP Applications 12. Aby zapoznać się z aktualną wersją, zapoznaj się również z przewodnikiem. Przed rozpoczęciem testu upewnij się, że platforma HANA jest zsynchronizowana i upewnij się, że konfiguracja programu Pacemaker jest poprawna.
W poniższych opisach testów zakładamy PREFER_SITE_TAKEOVER="true" oraz AUTOMATED_REGISTER="false".
Uwaga
Następujące testy są przeznaczone do uruchamiania w sekwencji. Każdy test zależy od stanu wyjścia poprzedniego testu.
Test 1. Zatrzymaj podstawową bazę danych w węźle 1.
Stan zasobu przed rozpoczęciem testu:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Uruchom następujące polecenia jako <hana sid>adm w węźle
hn1-db-0:hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> HDB stopProgram Pacemaker wykrywa zatrzymaną instancję HANA i przełącza się na inny węzeł. Po zakończeniu pracy w trybie failover wystąpienie platformy HANA w węźle
hn1-db-0zostanie zatrzymane, ponieważ program Pacemaker nie rejestruje węzła automatycznie jako pomocniczego oprogramowania HANA.Uruchom następujące polecenia, aby zarejestrować węzeł
hn1-db-0jako wtórny i wyczyścić zasób, który zakończył się niepowodzeniem.hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0Stan zasobu po teście:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Test 2. Zatrzymaj podstawową bazę danych w węźle 2.
Stan zasobu przed rozpoczęciem testu:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Uruchom następujące polecenia jako <hana sid>adm w węźle
hn1-db-1:hn1adm@hn1-db-1:/usr/sap/HN1/HDB01> HDB stopProgram Pacemaker wykrywa zatrzymaną instancję HANA i przełącza się na inny węzeł. Po zakończeniu pracy w trybie failover wystąpienie platformy HANA w węźle
hn1-db-1zostanie zatrzymane, ponieważ program Pacemaker nie rejestruje węzła automatycznie jako pomocniczego oprogramowania HANA.Uruchom następujące polecenia, aby zarejestrować węzeł
hn1-db-1jako wtórny i wyczyścić zasób, który zakończył się niepowodzeniem.hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> # run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Stan zasobu po teście:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Test 3. Awaria podstawowej bazy danych w węźle 1.
Stan zasobu przed rozpoczęciem testu:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Uruchom następujące polecenia jako <hana sid>adm w węźle
hn1-db-0:hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> HDB kill-9Program Pacemaker wykrywa niedziałającą instancję HANA i przełącza się na inny węzeł. Po zakończeniu pracy w trybie failover wystąpienie platformy HANA w węźle
hn1-db-0zostanie zatrzymane, ponieważ program Pacemaker nie rejestruje węzła automatycznie jako pomocniczego oprogramowania HANA.Uruchom następujące polecenia, aby zarejestrować węzeł
hn1-db-0jako wtórny i wyczyścić zasób, który zakończył się niepowodzeniem.hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0Stan zasobu po teście:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Test 4: Spowoduj awarię podstawowej bazy danych na węźle 2.
Stan zasobu przed rozpoczęciem testu:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Uruchom następujące polecenia jako <hana sid>adm w węźle
hn1-db-1:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> HDB kill-9Program Pacemaker wykrywa niedziałającą instancję HANA i przełącza się na inny węzeł. Po zakończeniu pracy w trybie failover wystąpienie platformy HANA w węźle
hn1-db-1zostanie zatrzymane, ponieważ program Pacemaker nie rejestruje węzła automatycznie jako pomocniczego oprogramowania HANA.Uruchom następujące polecenia, aby zarejestrować węzeł
hn1-db-1jako pomocniczy i wyczyścić błędny zasób.hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> # run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Stan zasobu po teście:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Test 5. Awaria węzła lokacji głównej (węzeł 1).
Stan zasobu przed rozpoczęciem testu:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Uruchom następujące polecenia jako root na węźle
hn1-db-0:hn1-db-0:~ # echo 'b' > /proc/sysrq-triggerProgram Pacemaker wykrywa wyłączony węzeł klastra i odłącza go. Gdy węzeł jest ogrodzony, program Pacemaker wyzwala przejęcie wystąpienia platformy HANA. Po ponownym uruchomieniu ogrodzonego węzła program Pacemaker nie uruchamia się automatycznie.
Uruchom następujące polecenia, aby uruchomić narzędzie Pacemaker, wyczyścić komunikaty SBD dla
hn1-db-0węzła, zarejestrowaćhn1-db-0węzeł jako pomocniczy i wyczyścić zasób, który zakończył się niepowodzeniem:# run as root # list the SBD device(s) hn1-db-0:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" hn1-db-0:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message hn1-db-0 clear hn1-db-0:~ # systemctl start pacemaker # run as <hana sid>adm hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0Stan zasobu po teście:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Test 6: Spowoduj awarię węzła strony dodatkowej (węzeł 2).
Stan zasobu przed rozpoczęciem testu:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Uruchom następujące polecenia jako root na węźle
hn1-db-1:hn1-db-1:~ # echo 'b' > /proc/sysrq-triggerProgram Pacemaker wykrywa wyłączony węzeł klastra i odłącza go. Gdy węzeł jest ogrodzony, program Pacemaker wyzwala przejęcie wystąpienia platformy HANA. Po ponownym uruchomieniu ogrodzonego węzła program Pacemaker nie uruchamia się automatycznie.
Uruchom następujące polecenia, aby uruchomić narzędzie Pacemaker, wyczyścić komunikaty SBD dla
hn1-db-1węzła, zarejestrowaćhn1-db-1węzeł jako pomocniczy i wyczyścić zasób, który zakończył się niepowodzeniem:# run as root # list the SBD device(s) hn1-db-1:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" hn1-db-1:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message hn1-db-1 clear hn1-db-1:~ # systemctl start pacemaker # run as <hana sid>adm hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-0 --remoteInstance=<instance number> --replicationMode=sync --name=<site 2> # run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Stan zasobu po teście:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0 </code></pre>Test 7: Zatrzymaj bazę danych pomocniczą na węźle 2.
Stan zasobu przed rozpoczęciem testu:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Uruchom następujące polecenia jako <hana sid>adm w węźle
hn1-db-1:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> HDB stopNarzędzie Pacemaker wykrywa zatrzymane wystąpienie platformy HANA i oznacza zasób jako uszkodzony w węźle
hn1-db-1. Program Pacemaker automatycznie uruchamia ponownie instancję HANA.Uruchom następujące polecenie, aby wyczyścić stan niepowodzenia:
# run as root hn1-db-1>:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Stan zasobu po teście:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Test 8. Spowoduj awarię pomocniczej bazy danych na węźle 2.
Stan zasobu przed rozpoczęciem testu:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Uruchom następujące polecenia jako <hana sid>adm w węźle
hn1-db-1:hn1adm@hn1-db-1:/usr/sap/HN1/HDB03> HDB kill-9Narzędzie Pacemaker wykrywa zabite wystąpienie platformy HANA i oznacza zasób jako niepowodzenie w węźle
hn1-db-1. Uruchom następujące polecenie, aby wyczyścić stan błędu. Program Pacemaker automatycznie uruchamia ponownie wystąpienie HANA.# run as root hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> HN1-db-1Stan zasobu po teście:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Test 9. Awaria węzła dla lokacji dodatkowej (węzeł 2) uruchamiającego wtórną bazę danych HANA.
Stan zasobu przed rozpoczęciem testu:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Uruchom następujące polecenia jako root na węźle
hn1-db-1:hn1-db-1:~ # echo b > /proc/sysrq-triggerProgram Pacemaker wykrywa węzeł klastra, który został zatrzymany, i odizolowuje ten węzeł. Po ponownym uruchomieniu ogrodzonego węzła program Pacemaker nie uruchamia się automatycznie.
Uruchom następujące polecenia, aby uruchomić narzędzie Pacemaker, wyczyścić komunikaty SBD dla
hn1-db-1węzła i wyczyścić zasób, który zakończył się niepowodzeniem:# run as root # list the SBD device(s) hn1-db-1:~ # cat /etc/sysconfig/sbd | grep SBD_DEVICE= # SBD_DEVICE="/dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116;/dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1;/dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3" hn1-db-1:~ # sbd -d /dev/disk/by-id/scsi-36001405772fe8401e6240c985857e116 -d /dev/disk/by-id/scsi-36001405034a84428af24ddd8c3a3e9e1 -d /dev/disk/by-id/scsi-36001405cdd5ac8d40e548449318510c3 message hn1-db-1 clear hn1-db-1:~ # systemctl start pacemaker hn1-db-1:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-1Stan zasobu po teście:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Test 10: Awaria głównego serwera indeksowego bazy danych
Ten test jest istotny tylko wtedy, gdy skonfigurowano punkt zaczepienia susChkSrv zgodnie z opisem w Implementowanie agentów zasobów HANA.
Stan zasobu przed rozpoczęciem testu:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-0 ] Slaves: [ hn1-db-1 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-0 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-0Uruchom następujące polecenia jako root na węźle
hn1-db-0:hn1-db-0:~ # killall -9 hdbindexserverPo zakończeniu działania serwera indeksów, hak susChkSrv wykrywa zdarzenie, wyzwala akcję mającą na celu zablokowanie węzła 'hn1-db-0' i inicjuje proces przejęcia.
Uruchom następujące polecenia, aby zarejestrować węzeł
hn1-db-0jako pomocniczy i wyczyścić zasób, który zakończył się niepowodzeniem.# run as <hana sid>adm hn1adm@hn1-db-0:/usr/sap/HN1/HDB03> hdbnsutil -sr_register --remoteHost=hn1-db-1 --remoteInstance=<instance number> --replicationMode=sync --name=<site 1> # run as root hn1-db-0:~ # crm resource cleanup msl_SAPHana_<HANA SID>_HDB<instance number> hn1-db-0Stan zasobu po teście:
Clone Set: cln_SAPHanaTopology_HN1_HDB03 [rsc_SAPHanaTopology_HN1_HDB03] Started: [ hn1-db-0 hn1-db-1 ] Master/Slave Set: msl_SAPHana_HN1_HDB03 [rsc_SAPHana_HN1_HDB03] Masters: [ hn1-db-1 ] Slaves: [ hn1-db-0 ] Resource Group: g_ip_HN1_HDB03 rsc_ip_HN1_HDB03 (ocf::heartbeat:IPaddr2): Started hn1-db-1 rsc_nc_HN1_HDB03 (ocf::heartbeat:azure-lb): Started hn1-db-1Można wykonać porównywalny przypadek testowy, powodując awarię serwera indexserver w węźle pomocniczym. W przypadku awarii serwera indexserver hak susChkSrv rozpoznaje zdarzenie i inicjuje akcję w celu odizolowania węzła pomocniczego.