Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W usłudze Azure AI Search zestaw umiejętności koordynuje działania umiejętności, które analizują, przekształcają lub tworzą zawartość z możliwością wyszukiwania. Często dane wyjściowe jednej umiejętności stają się danymi wejściowymi innego. Gdy dane wejściowe zależą od danych wyjściowych, błędy w definicjach zestawu umiejętności i skojarzeniach pól mogą spowodować nieodebrane operacje i dane.
Debug Sessions to narzędzie w Portalu Azure, które oferuje kompleksową wizualizację zestawu umiejętności wykonywanego w usłudze Azure AI Search. Za pomocą tego narzędzia możesz przejść do szczegółów określonych kroków, aby łatwo sprawdzić, gdzie może zawodzić działanie.
W tym samouczku użyjesz sesji debugowania, aby znaleźć i naprawić brakujące dane wejściowe i wyjściowe. Samouczek jest wszechstronny. Udostępnia przykładowe dane, plik REST, który tworzy obiekty i instrukcje dotyczące debugowania problemów w zestawie umiejętności.
Prerequisites
Konto Azure z aktywną subskrypcją. Utwórz konto bezpłatnie.
Azure AI Search. Utwórz usługę lub znajdź istniejącą usługę w bieżącej subskrypcji. W tym samouczku możesz skorzystać z bezpłatnej usługi. Warstwa Bezpłatna nie zapewnia obsługi tożsamości zarządzanej dla usługi Azure AI Search. Musisz użyć kluczy dla połączeń z usługą Azure Storage.
Konto usługi Azure Storage z usługą Blob Storage używane do hostowania przykładowych danych i utrwalania buforowanych danych utworzonych podczas sesji debugowania. Jeśli używasz bezpłatnej usługi wyszukiwania, konto magazynowe musi mieć włączone klucze dostępu współdzielonego i zezwalać na dostęp do sieci publicznej.
Przykładowy plik debug-sessions.rest używany do tworzenia potoku wzbogacania.
Note
W tym samouczku użyto również narzędzi Foundry Tools do wykrywania języka, rozpoznawania jednostek i wyodrębniania kluczowych fraz. Ponieważ obciążenie jest tak małe, narzędzia Foundry są w tle używane do bezpłatnego przetwarzania maksymalnie 20 transakcji. Oznacza to, że możesz wykonać to ćwiczenie bez konieczności tworzenia rozliczanego zasobu usługi Microsoft Foundry.
Konfigurowanie przykładowych danych
W tej sekcji tworzony jest przykładowy zestaw danych w usłudze Azure Blob Storage, dzięki czemu indeksator i zestaw umiejętności mają zawartość do pracy.
Pobierz przykładowe dane (clinical-trials-pdf-19), składające się z 19 plików.
Utwórz konto usługi Azure Storage lub znajdź istniejące konto.
Wybierz ten sam region co usługa Azure AI Search, aby uniknąć opłat za przepustowość.
Wybierz typ konta StorageV2 (ogólnego przeznaczenia w wersji 2).
Przejdź do stron usług Azure Storage w portalu Azure i utwórz kontener Blob. Najlepszym rozwiązaniem jest określenie poziomu dostępu "prywatny". Nadaj kontenerowi
clinicaltrialdatasetnazwę .W kontenerze wybierz pozycję Przekaż , aby przekazać pobrane i rozpakowane pliki przykładowe w pierwszym kroku.
W witrynie Azure Portal wybierz pozycję Ustawienia>Klucze dostępu i skopiuj parametry połączenia dla usługi Azure Storage.
Kopiowanie klucza i adresu URL
W tym samouczku używane są klucze API do uwierzytelniania i autoryzacji. Potrzebujesz punktu końcowego usługi wyszukiwania i klucza interfejsu API, który można uzyskać z witryny Azure Portal.
Przejdź do usługi wyszukiwania w witrynie Azure Portal.
Na stronie Przegląd skopiuj adres URL punktu końcowego. Przykładowy punkt końcowy może wyglądać podobnie jak
https://mydemo.search.windows.net.W obszarze Klucze ustawień> skopiuj klucz administratora. Klucze administracyjne służą do dodawania, modyfikowania i usuwania obiektów. Istnieją dwa zamienne klucze administratora. Skopiuj jedną z nich.
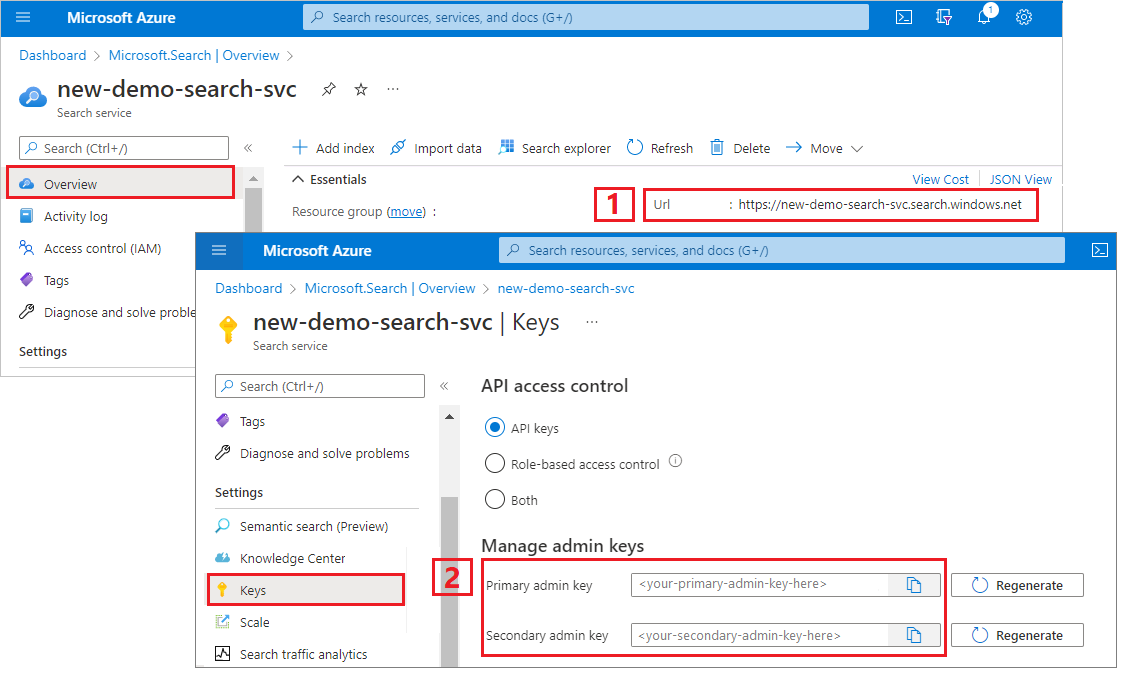
Prawidłowy klucz interfejsu API ustanawia relację zaufania dla poszczególnych żądań między aplikacją wysyłającą żądanie a usługą wyszukiwania, która go obsługuje.
Tworzenie źródła danych, zestawu umiejętności, indeksu i indeksatora
W tej sekcji utwórz wadliwy przepływ pracy, który możesz naprawić w tym samouczku.
Uruchom program Visual Studio Code i otwórz
debug-sessions.restplik.Podaj następujące zmienne: adres URL usługi wyszukiwania, klucz interfejsu API administratora usług wyszukiwania, parametry połączenia magazynu i nazwę kontenera obiektów blob przechowując pliki PDF.
Wyślij każde żądanie z kolei. Tworzenie indeksatora trwa kilka minut.
Zamknij plik.
Sprawdzanie wyników w witrynie Azure Portal
Przykładowy kod celowo tworzy indeks usterek w wyniku problemów, które wystąpiły podczas wykonywania zestawu umiejętności. Problem polega na tym, że w indeksie brakuje danych.
W witrynie Azure Portal na stronie Przegląd usługi wyszukiwania wybierz kartę Indeksy.
Wybierz badania kliniczne.
Wprowadź ten ciąg zapytania JSON w widoku JSON eksploratora wyszukiwania. Zwraca pola dla określonych dokumentów (zidentyfikowanych przez unikatowe
metadata_storage_pathpole)."search": "*", "select": "metadata_storage_path, organizations, locations", "count": trueUruchamianie zapytania. Powinny zostać wyświetlone puste wartości dla
organizationsilocations.Te pola powinny zostać wypełnione za pomocą umiejętności rozpoznawania jednostek zestawu umiejętności, używanej do wykrywania organizacji i lokalizacji w dowolnym miejscu zawartości obiektu blob. W następnym ćwiczeniu zdebugujesz zestaw umiejętności, aby określić, co poszło nie tak.
Innym sposobem zbadania błędów i ostrzeżeń jest witryna Azure Portal.
Na karcie Indeksatory wybierz pozycję clinical-trials-idxr.
Zwróć uwagę, że chociaż zadanie indeksatora zakończyło się pomyślnie, wystąpiły ostrzeżenia.
Wybierz pozycję Powodzenie , aby wyświetlić ostrzeżenia. Jeśli występują głównie błędy, link szczegółów to Niepowodzenie. Powinna zostać wyświetlona długa lista wszystkich ostrzeżeń emitowanych przez indeksator.

Uruchamianie sesji debugowania
W okienku nawigacji po lewej stronie usługi wyszukiwania w obszarze Zarządzanie wyszukiwaniem wybierz pozycję Sesje debugowania.
Wybierz pozycję + Dodaj sesję debugowania.
Nadaj sesji nazwę.
W szablonie indeksatora podaj nazwę indeksatora. Indeksator zawiera odwołania do źródła danych, zestawu umiejętności i indeksu.
Wybierz konto magazynu.
Zapisz sesję.
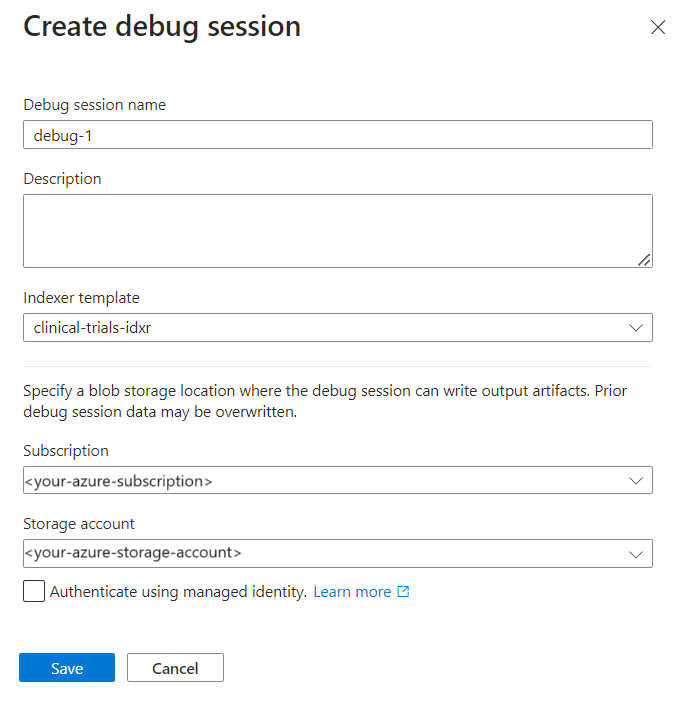
Zostanie otwarta sesja debugowania na stronie ustawień. Możesz wprowadzić modyfikacje początkowej konfiguracji i zastąpić wszystkie ustawienia domyślne. Sesja debugowania działa tylko z jednym dokumentem. Ustawieniem domyślnym jest zaakceptowanie pierwszego dokumentu w kolekcji jako podstawy sesji debugowania. Możesz wybrać konkretny dokument do debugowania , podając jego identyfikator URI w usłudze Azure Storage.
Po zakończeniu inicjowania sesji debugowania powinien zostać wyświetlony przepływ pracy umiejętności z mapowaniami i indeksem wyszukiwania. Wzbogacona struktura danych dokumentu jest wyświetlana w okienku szczegółów po stronie. Wykluczyliśmy go z poniższego zrzutu ekranu, aby zobaczyć więcej przepływu pracy.
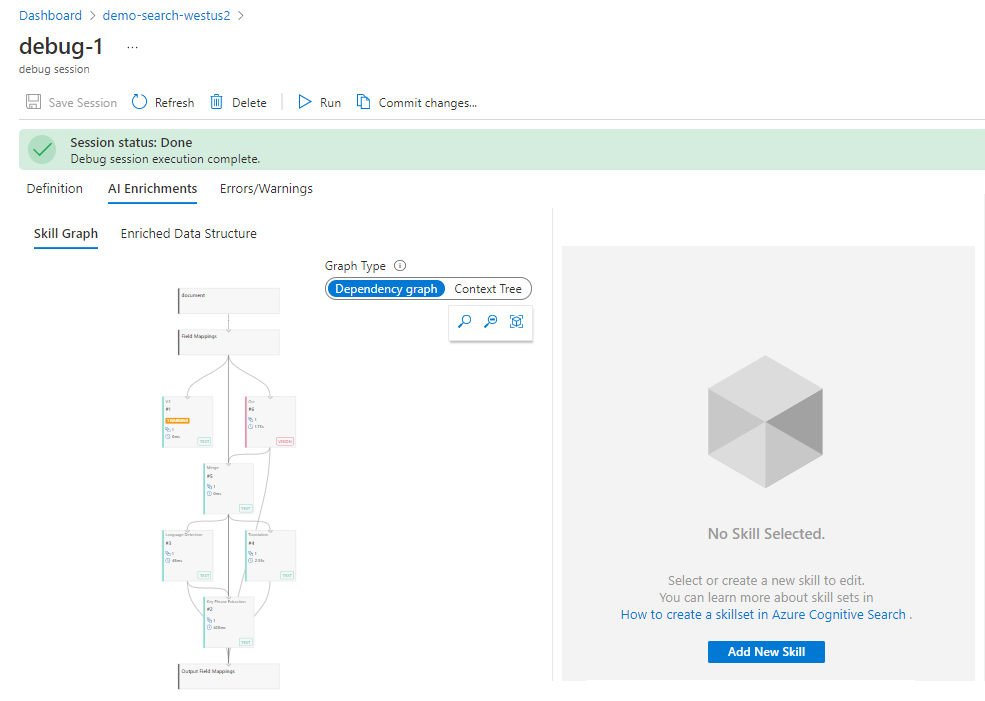


Znajdowanie problemów z zestawem umiejętności
Wszelkie problemy zgłaszane przez indeksator są wskazywane jako błędy i ostrzeżenia.
Zwróć uwagę, że liczba błędów i ostrzeżeń jest mniejszą listą niż wyświetlana wcześniej, ponieważ ta lista zawiera tylko szczegóły błędów dla pojedynczego dokumentu. Podobnie jak lista wyświetlana przez indeksator, możesz wybrać komunikat ostrzegawczy i wyświetlić szczegóły tego ostrzeżenia.
Wybierz pozycję Ostrzeżenia , aby przejrzeć powiadomienia. Powinieneś zobaczyć cztery:
Nie udało się wykonać umiejętności, ponieważ co najmniej jedne dane wejściowe umiejętności były nieprawidłowe. Brak wymaganych informacji o umiejętnościach. Nazwa: "text", Źródło: '/document/content'".
Nie można dopasować pola wyjściowego „locations” do indeksu wyszukiwania. Sprawdź właściwość "outputFieldMappings" indeksatora. Brak wartości "/document/merged_content/locations".
"Nie można mapować pola wyjściowego "organizacje" na indeks wyszukiwania. Sprawdź właściwość "outputFieldMappings" indeksatora. Brak wartości "/document/merged_content/organizations".
Umiejętność została wykonana, ale może mieć nieoczekiwane wyniki, ponieważ jedno lub więcej wejść umiejętności było nieprawidłowych. Brak opcjonalnego wpisu umiejętności. Nazwa: 'languageCode', Źródło: '/document/languageCode'. Problemy z analizowaniem języka wyrażeń: Brak wartości "/document/languageCode".
Wiele umiejętności ma parametr „languageCode”. Sprawdzając operację, możesz zauważyć, że brakuje danych wejściowych kodu języka z EntityRecognitionSkill.#1, co jest tą samą umiejętnością rozpoznawania jednostek, która ma problemy z danymi wyjściowymi dotyczącymi "lokalizacji" i "organizacji".
Ponieważ wszystkie cztery powiadomienia dotyczą tej umiejętności, następnym krokiem jest debugowanie tej umiejętności. Jeśli to możliwe, najpierw rozwiąż problemy z danymi wejściowymi przed przejściem do problemów z danymi wyjściowymi.
Napraw brakujące wartości umiejętności
Na interfejsie roboczym wybierz funkcję, która zgłasza ostrzeżenia. W tym samouczku omawiamy umiejętność rozpoznawania jednostek.
Po prawej stronie zostanie otwarte okienko Szczegóły umiejętności z sekcjami iteracji oraz ich odpowiednimi danymi wejściowymi i wyjściowymi, ustawieniami umiejętności dla definicji umiejętności JSON oraz komunikatami dotyczącymi błędów i ostrzeżeń, które emitują ta umiejętność.
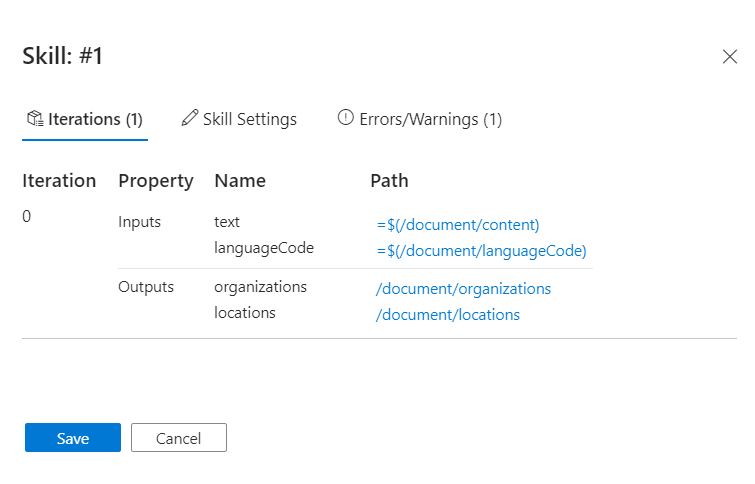
Najedź kursorem na poszczególne pola (lub wybierz pole), aby wyświetlić wartości w ewaluatorze wyrażeń. Zwróć uwagę, że wyświetlany wynik dla tych danych wejściowych nie wygląda jak wprowadzanie tekstu. Wygląda jak seria nowych znaków
\n \n\n\n\nwiersza zamiast tekstu. Brak tekstu oznacza, że nie można zidentyfikować żadnych jednostek. Ten dokument nie spełnia wymagań dotyczących umiejętności lub istnieją inne dane wejściowe, które powinny być użyte zamiast tego.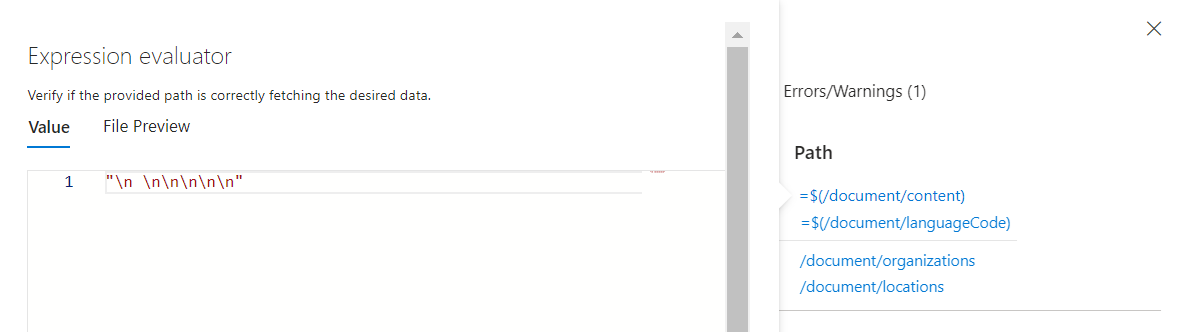
Wróć do wzbogaconej struktury danych i przejrzyj węzły wzbogacania dla tego dokumentu. Zwróć uwagę, że właściwość
\n \n\n\n\n"content" nie ma źródła źródłowego, ale inna wartość "merged_content" ma dane wyjściowe OCR. Chociaż nie ma żadnych wskazówek, zawartość tego pliku PDF wydaje się być plikiem JPEG, co jest dowodem wyodrębnionego i przetworzonego tekstu w "merged_content".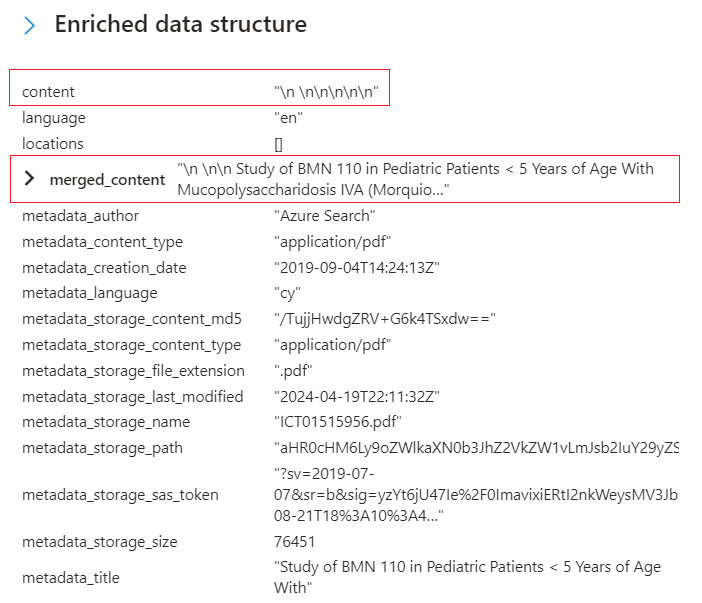
Wróć do aplikacji i wybierz Ustawienia zestawu umiejętności, aby wyświetlić definicję JSON.
Zmień wyrażenie z
/document/contentna/document/merged_content, a następnie wybierz pozycję Zapisz. Zwróć uwagę, że ostrzeżenie nie jest już wyświetlane.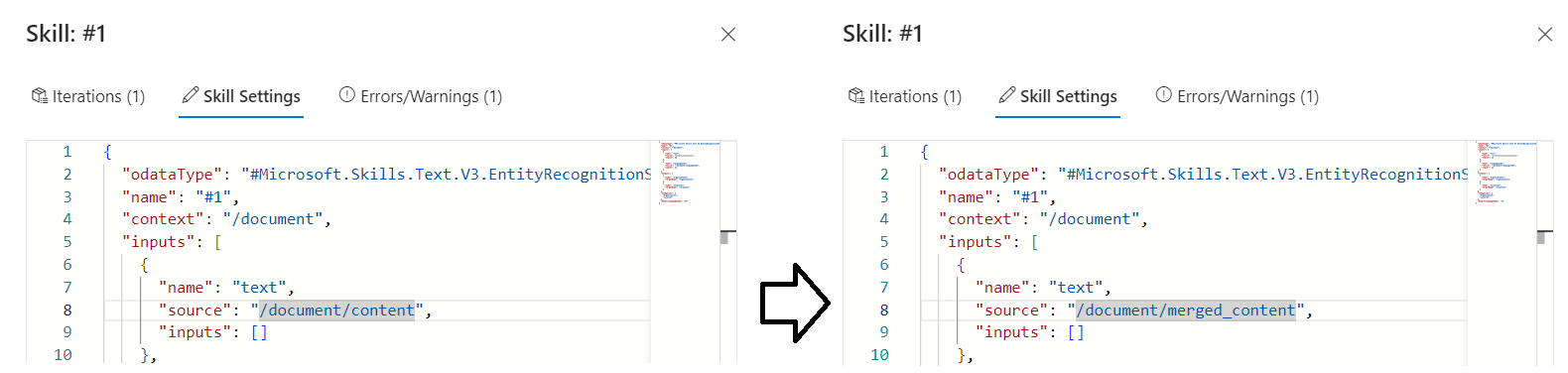
Wybierz pozycję Uruchom w menu okna sesji. Rozpoczyna to kolejne wykonanie zestawu umiejętności przy użyciu dokumentu.
Po zakończeniu wykonywania sesji debugowania zwróć uwagę, że liczba ostrzeżeń zmniejszyła się o jedną. Ostrzeżenia pokazują, że błąd dla wprowadzania tekstu zniknął, ale pozostałe nadal występują. Następnym krokiem jest rozwiązanie problemu z ostrzeżeniem dotyczącym brakującej lub pustej wartości
/document/languageCode.
Wybierz umiejętność i umieść kursor nad
/document/languageCode. Wartość dla tych danych wejściowych ma wartość null, która nie jest prawidłowym wejściem.Podobnie jak w przypadku poprzedniego problemu, zacznij od przejrzenia struktury wzbogaconych danych pod kątem dowodów na jego węzły. Zwróć uwagę, że nie ma węzła "languageCode", ale istnieje jeden dla "language". W ustawieniach umiejętności jest więc literówka.
Skopiuj wyrażenie
/document/language.W okienku Szczegóły umiejętności wybierz pozycję Ustawienia umiejętności dla umiejętności #1 i wklej nową wartość
/document/language.Wybierz Zapisz.
Wybierz Uruchom.
Po zakończeniu wykonywania sesji debugowania możesz sprawdzić wyniki w okienku Szczegóły umiejętności. Po najechaniu kursorem na
/document/language, powinna być widocznaenjako wartość w ewaluatorze wyrażeń.
Zwróć uwagę, że ostrzeżenia wejściowe znikną. Istnieją teraz tylko dwa ostrzeżenia dotyczące pól wyjściowych dla organizacji i lokalizacji.
Napraw brakujące wartości wyjściowe umiejętności
Komunikaty mówią, aby sprawdzić właściwość "outputFieldMappings" indeksatora, więc zacznijmy od tego.
Wybierz Mapowania pól wyjściowych na powierzchni roboczej. Zwróć uwagę, że brakuje mapowań pól wyjściowych.
W pierwszym kroku upewnij się, że indeks wyszukiwania ma oczekiwane pola. W tym przypadku indeks zawiera pola "lokalizacje" i "organizacje".
Jeśli nie ma problemu z indeksem, następnym krokiem jest sprawdzenie danych wyjściowych umiejętności. Tak jak poprzednio, wybierz strukturę wzbogaconych danych i przewiń węzły, aby znaleźć "lokalizacje" i "organizacje". Zwróć uwagę, że element nadrzędny to "treść" zamiast "merged_content". Kontekst jest nieprawidłowy.
Wróć do okienka Szczegóły umiejętności, aby uzyskać umiejętności rozpoznawania jednostek.
W obszarze Ustawienia umiejętności zmień wartość
contextnadocument/merged_content. W tym momencie należy mieć trzy modyfikacje definicji umiejętności.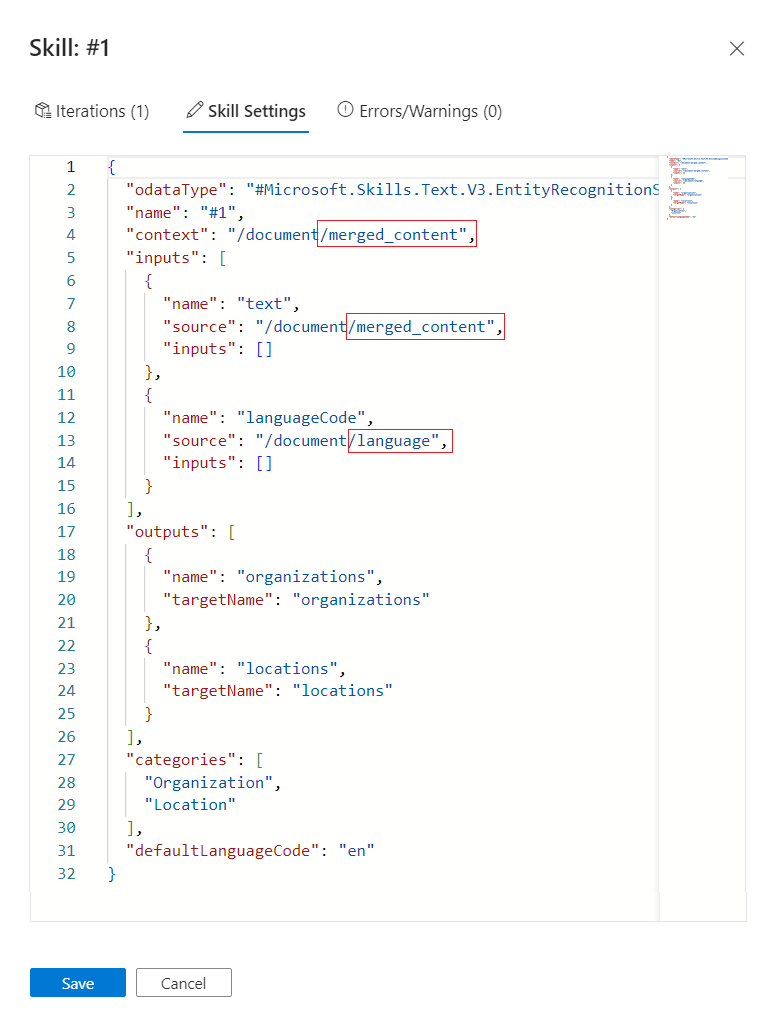
Wybierz Zapisz.
Wybierz Uruchom.
Wszystkie błędy zostały rozwiązane.
Zatwierdź zmiany w zestawie umiejętności
Po zainicjowaniu sesji debugowania usługa wyszukiwania utworzyła kopię zestawu umiejętności. Zostało to zrobione w celu ochrony oryginalnego zestawu umiejętności w usłudze wyszukiwania. Teraz, gdy debugujesz zestaw umiejętności, poprawki można przekazać (zastąpić oryginalny zestaw umiejętności).
Alternatywnie, jeśli nie jesteś gotowy do zatwierdzenia zmian, możesz zapisać sesję debugowania i ponownie otworzyć ją później.
Wybierz pozycję Zatwierdź zmiany w głównym menu Sesje debugowania.
Wybierz przycisk OK , aby potwierdzić, że chcesz zaktualizować zestaw umiejętności.
Zamknij sesję debugowania i otwórz indeksatory w okienku po lewej stronie.
Wybierz opcję "clinical-trials-idxr".
Wybierz pozycję Resetuj.
Wybierz Uruchom.
Wybierz pozycję Odśwież , aby wyświetlić stan poleceń resetowania i uruchamiania.
Po zakończeniu działania indeksatora powinien istnieć zielony znacznik wyboru i słowo Powodzenie obok sygnatury czasowej dla najnowszego uruchomienia na karcie Historia wykonywania . Aby upewnić się, że zmiany są stosowane:
W okienku po lewej stronie otwórz pozycję Indeksy.
Wybierz indeks "badania kliniczne", a następnie w zakładce Eksplorator wyszukiwania wprowadź ten ciąg zapytania:
$select=metadata_storage_path, organizations, locations&$count=trueaby zwrócić pola dla określonych dokumentów (zidentyfikowanych przez polemetadata_storage_path).Wybierz Wyszukaj.
Wyniki powinny wskazywać, że organizacje i lokalizacje są teraz wypełniane oczekiwanymi wartościami.
Czyszczenie zasobów
Jeśli pracujesz w ramach własnej subskrypcji, dobrym pomysłem po zakończeniu projektu jest sprawdzenie, czy dalej potrzebujesz utworzonych zasobów. Uruchomione zasoby mogą generować koszty. Zasoby możesz usuwać pojedynczo lub jako grupę zasobów, usuwając cały zestaw zasobów.
Zasoby można znaleźć w witrynie Azure Portal i zarządzać nimi, korzystając z linku Wszystkie zasoby lub Grupy zasobów w okienku nawigacji po lewej stronie.
Bezpłatna usługa jest ograniczona do trzech indeksów, indeksatorów i źródeł danych. Aby utrzymać limit, możesz usunąć poszczególne elementy w witrynie Azure Portal.
Dalsze kroki
Ten samouczek dotyczył różnych aspektów definicji i przetwarzania zestawu umiejętności. Aby dowiedzieć się więcej na temat pojęć i przepływów pracy, zobacz następujące artykuły: