Uwaga
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Usługa Service Fabric jest oparta na podsystemach warstwowych. Te podsystemy umożliwiają pisanie aplikacji, które są:
- Wysoka dostępność
- Skalowalny
- Zarządzalny
- Testowalny
Na poniższym diagramie przedstawiono główne podsystemy usługi Service Fabric.
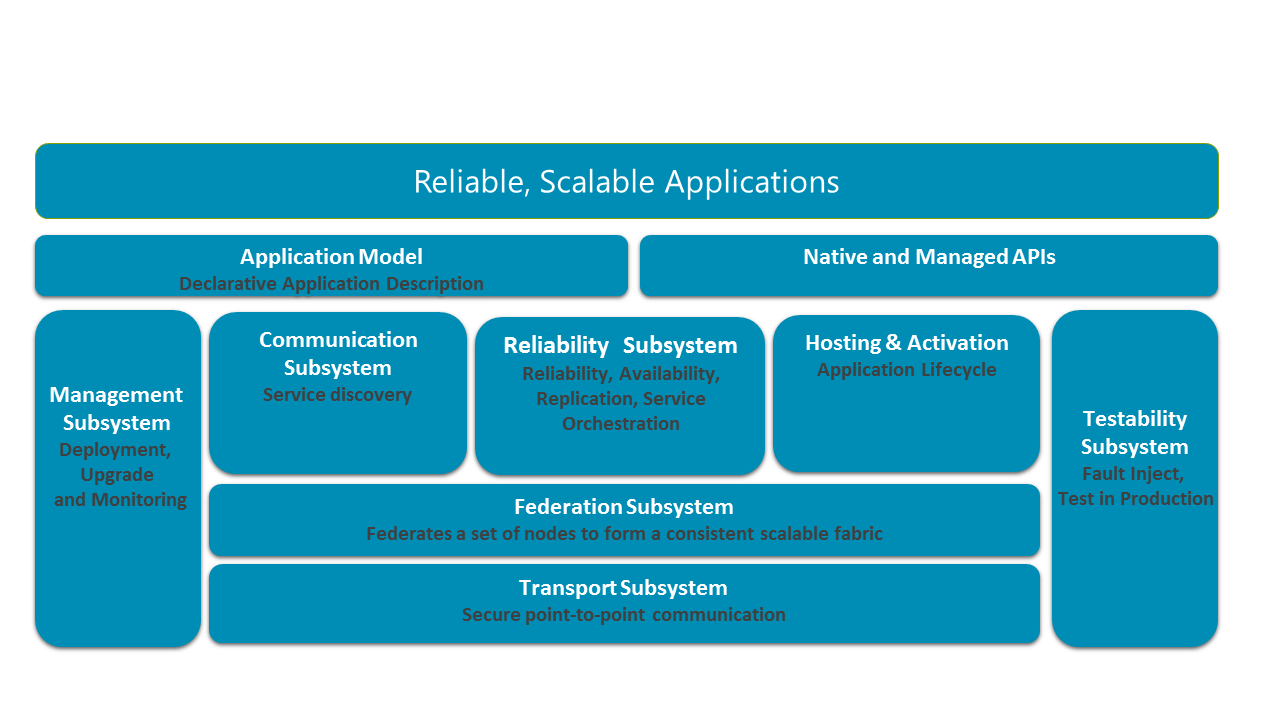
W systemie rozproszonym kluczowa jest możliwość bezpiecznego komunikowania się między węzłami w klastrze. Podstawą stosu jest podsystem transportu, który zapewnia bezpieczną komunikację między węzłami. Powyżej podsystemu transportu znajduje się podsystem federacji, który klasteruje różne węzły do jednej jednostki (nazwanych klastrów), aby usługa Service Fabric mogła wykrywać błędy, wykonywać wybory lidera i zapewniać spójny routing. Podsystem niezawodności, warstwowy nad podsystemem federacji, zapewnia niezawodność usług Service Fabric poprzez mechanizmy, takie jak replikacja, zarządzanie zasobami i przełączanie awaryjne. Podsystem federacyjny stanowi również część podsystemu hostingu i aktywacji, który zarządza cyklem życia aplikacji w jednym węźle. Podsystem zarządzania zarządza cyklem życia aplikacji i usług. Podsystem testowania pomaga deweloperom aplikacji przetestować swoje usługi za pomocą symulowanych błędów przed wdrożeniem aplikacji i usług w środowiskach produkcyjnych i po ich wdrożeniu. Usługa Service Fabric umożliwia rozpoznawanie lokalizacji usług za pośrednictwem podsystemu komunikacji. Modele programistyczne aplikacji udostępniane deweloperom są umieszczane na tych podsystemach, razem z modelem aplikacji, aby umożliwić korzystanie z narzędzi.
Podsystem transportu
Podsystem transportu implementuje kanał komunikacyjny datagramu punkt-punkt. Ten kanał jest używany do komunikacji w klastrach usługi Service Fabric i komunikacji między klastrem usługi Service Fabric a klientami. Obsługuje on wzorce komunikacji jednokierunkowej i żądań-odpowiedzi, które zapewniają podstawę implementacji emisji i multiemisji w warstwie federacyjnej. Podsystem transportu zabezpiecza komunikację przy użyciu certyfikatów X509 lub zabezpieczeń systemu Windows. Ten podsystem jest używany wewnętrznie przez usługę Service Fabric i nie jest bezpośrednio dostępny dla deweloperów na potrzeby programowania aplikacji.
Podsystem federacji
Aby poznać zestaw węzłów w systemie rozproszonym, należy mieć spójny widok systemu. Podsystem federacyjny używa pierwotnych komunikacji dostarczonych przez podsystem transportu i łączy różne węzły w jeden ujednolicony klaster, którego może poznać. Zapewnia on podstawowe systemy rozproszone wymagane przez inne podsystemy — wykrywanie błędów, wybór lidera i spójny routing. Podsystem federacji jest oparty na rozproszonych tabelach skrótów z 128-bitowym miejscem tokenu. Podsystem tworzy topologię pierścienia nad węzłami, a każdy węzeł w pierścieniu otrzymuje podzestaw przestrzeni tokenów do zarządzania. W przypadku wykrywania błędów warstwa używa mechanizmu dzierżawy opartego na biciu serca i arbitrażu. Podsystem federacji gwarantuje również za pomocą skomplikowanych protokołów dołączania i opuszczania, że w dowolnym momencie istnieje tylko jeden właściciel tokenu. Zapewnia to wybory lidera i spójne gwarancje routingu.
Podsystem niezawodności
Podsystem niezawodności udostępnia mechanizm, który umożliwia zapewnienie wysokiej dostępności usługi Service Fabric przy użyciu replikatora, Menedżera awarii i Równoważnika zasobów.
- Replikator zapewnia, że zmiany stanu repliki usługi podstawowej zostaną automatycznie zreplikowane do replik pomocniczych, zachowując spójność między replikami podstawowymi i pomocniczymi w zestawie replik usługi. Replikator jest odpowiedzialny za zarządzanie kworum wśród replik w zestawie replik. Interakcja odbywa się z jednostką przełączania awaryjnego, aby uzyskać listę operacji do replikacji, a agent rekonfiguracji dostarcza konfigurację zestawu replik. Ta konfiguracja wskazuje, na których replikach należy powtórzyć operacje. Usługa Service Fabric udostępnia domyślny replikator o nazwie Fabric Replicator, który może być używany przez interfejs API modelu programowania w celu zapewnienia wysokiej dostępności i niezawodności stanu usługi.
- Menedżer trybu failover zapewnia, że po dodaniu lub usunięciu węzłów z klastra obciążenie jest automatycznie redystrybuowane w dostępnych węzłach. Jeśli węzeł w klastrze ulegnie awarii, klaster automatycznie ponownie skonfiguruje repliki usługi w celu zachowania dostępności.
- Menedżer Zasobów umieszcza repliki usług w domenach błędów w klastrze i zapewnia, że wszystkie jednostki przełączania awaryjnego są operacyjne. Menadżer Zasobów również równoważy zasoby usług w bazowej wspólnej puli węzłów klastra, aby osiągnąć optymalny równomierny rozkład obciążenia.
Podsystem zarządzania
Podsystem zarządzania zapewnia kompleksowe zarządzanie usługą i cyklem życia aplikacji. Polecenia cmdlet programu PowerShell i administracyjne interfejsy API umożliwiają aprowizowanie, wdrażanie, stosowanie poprawek, uaktualnianie i anulowanie aprowizacji aplikacji bez utraty dostępności. Podsystem zarządzania wykonuje to za pośrednictwem następujących usług.
- Menedżer klastra: Jest to główna usługa, która współpracuje z Menedżerem trybu awaryjnego, uwzględniając niezawodność, aby umieszczać aplikacje na węzłach zgodnie z ograniczeniami związanymi z ich rozmieszczeniem. Menedżer Zasobów w podsystemie tryb failover gwarantuje, że ograniczenia nigdy nie zostaną naruszone. Menedżer klastra zarządza cyklem życia aplikacji od aprowizacji do anulowania aprowizacji. Integruje się z menedżerem kondycji, aby zapewnić, że dostępność aplikacji nie zostanie utracona z perspektywy semantycznego aspektu kondycji podczas aktualizacji.
- Menedżer kondycji: ta usługa umożliwia monitorowanie kondycji aplikacji, usług i jednostek klastra. Jednostki klastra (takie jak węzły, partycje usługi i repliki) mogą zgłaszać informacje o kondycji, które są następnie agregowane do scentralizowanego magazynu kondycji. Te informacje zdrowotne zawierają ogólną migawkę stanu zdrowia w danym momencie usług i węzłów rozmieszczonych na wielu węzłach w klastrze, umożliwiając podjęcie wszelkich niezbędnych działań naprawczych. Interfejsy API zapytań dotyczących stanu zdrowia umożliwiają przeprowadzanie zapytań dotyczących zdarzeń zdrowotnych zgłoszonych w podsystemie zdrowotnym. Interfejsy API zapytań dotyczących kondycji zwracają nieprzetworzone dane kondycji przechowywane w magazynie kondycji lub zagregowane, interpretowane dane kondycji dla określonej jednostki klastra.
- Magazyn obrazów: ta usługa zapewnia magazyn i dystrybucję plików binarnych aplikacji. Ta usługa udostępnia prosty rozproszony magazyn plików, z którego aplikacje są przekazywane i pobierane.
Podsystem hostingu
Menedżer klastra informuje podsystem hostingu (uruchomiony w każdym węźle), którymi usługami musi zarządzać dla określonego węzła. Podsystem hostingu zarządza następnie cyklem życia aplikacji w tym węźle. Współdziała ze składnikami niezawodności i stanu, aby zapewnić prawidłowe umieszczenie replik i ich kondycję.
Podsystem komunikacji
Ten podsystem zapewnia niezawodne komunikaty w ramach klastra i odnajdywania usługi za pośrednictwem usługi Naming. Usługa Nazewnictwa przekształca nazwy usług na lokalizacje w klastrze i umożliwia użytkownikom zarządzanie nazwami i właściwościami usług. Za pomocą usługi Nazewnictwa klienci mogą bezpiecznie komunikować się z dowolnym węzłem w klastrze, aby rozpoznać nazwę usługi i pobrać metadane usługi. Prosty interfejs API nazewnictwa umożliwia użytkownikom usługi Service Fabric świadczenie usług i tworzenie aplikacji klienckich, które są w stanie identyfikować aktualną lokalizację sieciową, pomimo dynamiki węzłów i zmian w rozmiarze klastra.
Podsystem testowania
Testowalność to zestaw narzędzi przeznaczony specjalnie do testowania usług opartych na usłudze Service Fabric. Narzędzia umożliwiają deweloperowi łatwe wywoływanie znaczących błędów i uruchamianie scenariuszy testowych w celu wykonania i zweryfikowania licznych stanów i przejść, które usługa będzie doświadczać przez cały okres istnienia, a wszystko to w kontrolowany i bezpieczny sposób. Możliwość testowania zapewnia również mechanizm uruchamiania dłuższych testów, które mogą iterować przez różne możliwe awarie bez utraty dostępności. Zapewnia to środowisko testowania w produkcji.