Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Dotyczy: ✔️ udziały plików NFS
W tym artykule wyjaśniono, jak zwiększyć wydajność udziałów plików platformy Azure w sieciowym systemie plików (NFS).
Zwiększ rozmiar bufora odczytu, aby poprawić wydajność odczytu
read_ahead_kb Parametr jądra w systemie Linux reprezentuje ilość danych, które powinny być "odczytywane z wyprzedzeniem" lub pobierane wstępnie podczas operacji odczytu sekwencyjnego. Wersje jądra systemu Linux przed 5.4 ustawiają wartość wyprzedzenia odczytu na równowartość 15-krotności zamontowanego systemu rsize plików, co odpowiada opcji montowania po stronie klienta dla rozmiaru bufora odczytu. Spowoduje to ustawienie wartości wyprzedzania odczytu na tyle wysokiej, by zwiększyć przepływność odczytu sekwencyjnego przez klienta w większości przypadków.
Jednak począwszy od jądra systemu Linux w wersji 5.4, klient systemu plików NFS systemu Linux używa wartości domyślnej read_ahead_kb 128 KiB. Ta mała wartość może zmniejszyć przepływność odczytu dla dużych plików. Użytkownicy, którzy dokonują aktualizacji z wersji systemu Linux z większym buforem odczytu do wersji z domyślną wartością 128 KiB, mogą doświadczyć spadku wydajności odczytu sekwencyjnego.
W przypadku jąder systemu Linux w wersji 5.4 lub nowszej zalecamy trwałe ustawienie wartości read_ahead_kb 15 MiB w celu zwiększenia wydajności.
Aby zmienić tę wartość, ustaw rozmiar bufora odczytu, dodając regułę w udev, menedżerze urządzeń jądra systemu Linux. Wykonaj te kroki:
W edytorze tekstów utwórz plik /etc/udev/rules.d/99-nfs.rules , wprowadzając i zapisując następujący tekst:
SUBSYSTEM=="bdi" \ , ACTION=="add" \ , PROGRAM="/usr/bin/awk -v bdi=$kernel 'BEGIN{ret=1} {if ($4 == bdi) {ret=0}} END{exit ret}' /proc/fs/nfsfs/volumes" \ , ATTR{read_ahead_kb}="15360"W konsoli zastosuj regułę udev, uruchamiając polecenie udevadm jako superużytkownik i ponownie ładując pliki reguł i inne bazy danych. Aby udev rozpoznał nowy plik, wystarczy uruchomić to polecenie tylko raz.
sudo udevadm control --reload
NFS nconnect
NFS nconnect to opcja instalacji po stronie klienta dla udziałów plików NFS, która umożliwia korzystanie z wielu połączeń TCP między klientem a udziałem plików NFS.
Korzyści
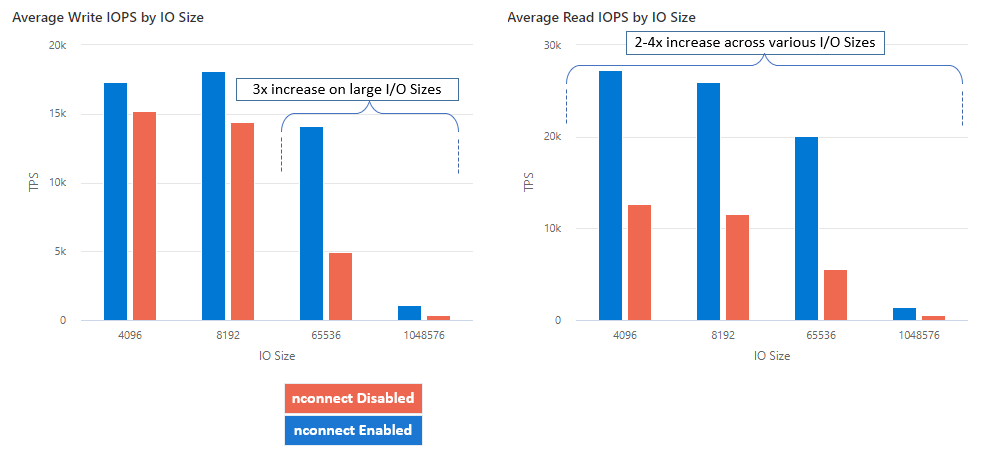
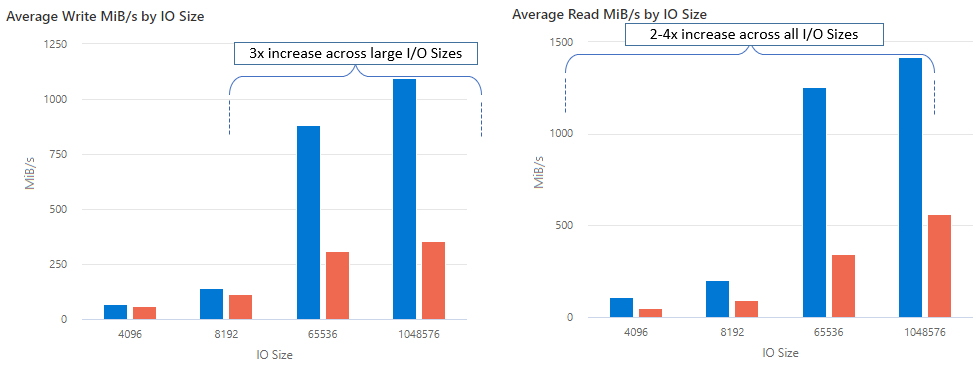
Dzięki nconnect można zwiększyć wydajność na dużą skalę przy użyciu mniejszej liczby maszyn klienckich, aby zmniejszyć całkowity koszt posiadania (TCO). Funkcja nconnect zwiększa wydajność przy użyciu wielu kanałów TCP na co najmniej jednej karcie sieciowej przy użyciu jednego lub wielu klientów. Bez funkcji nconnect potrzebowałbyś około 20 maszyn klienckich, aby osiągnąć limity skalowania przepustowości (10 GiB/s) oferowane przez największy rozmiar przydzielania udziału plików SSD. Za pomocą połączenia nconnect można osiągnąć te limity przy użyciu tylko klientów 6–7, zmniejszając koszty obliczeń o prawie 70%, zapewniając jednocześnie znaczne ulepszenia operacji we/wy na sekundę i przepływność na dużą skalę. Zobacz poniższą tabelę.
| Metryka (operacja) | Rozmiar we/wy | Poprawa wydajności |
|---|---|---|
| IOPS (zapis) | 64 KiB, 1024 KiB | 3x |
| Liczba operacji we/wy na sekundę (IOPS - odczyt) | Wszystkie rozmiary we/wy | 2–4 x |
| Przepustowość (zapis) | 64 KiB, 1024 KiB | 3x |
| Przepływność (odczyt) | Wszystkie rozmiary we/wy | 2–4 x |
Wymagania wstępne
- Najnowsze dystrybucje systemu Linux w pełni obsługują połączenie nconnect. W przypadku starszych dystrybucji systemu Linux upewnij się, że wersja jądra systemu Linux to 5.3 lub nowsza.
- Konfiguracja per montowanie jest obsługiwana tylko wtedy, gdy jedno udostępnienie plików jest używane na każde konto magazynu przez prywatny punkt końcowy.
Wpływ na wydajność
Uzyskaliśmy następujące wyniki wydajności podczas korzystania z opcji instalacji nconnect z udziałami plików platformy Azure NFS na dużą skalę na klientach z systemem Linux. Aby uzyskać więcej informacji na temat sposobu osiągnięcia tych wyników, zobacz Konfiguracja testu wydajnościowego.
Rekomendacje
Postępuj zgodnie z tymi zaleceniami, aby uzyskać najlepsze wyniki z witryny nconnect.
Zbiór nconnect=4
Chociaż usługa Azure Files obsługuje ustawienie nconnect do maksymalnego ustawienia 16, zalecamy skonfigurowanie opcji instalacji przy użyciu optymalnego ustawienia nconnect=4. W chwili obecnej nie ma żadnych korzyści w implementacji nconnect dla usługi Azure Files poza czterema kanałami. W rzeczywistości przekroczenie czterech kanałów z jednego klienta do pojedynczego udziału plików Azure może niekorzystnie wpłynąć na wydajność z powodu przeciążenia sieci TCP.
Dokładne ustawianie rozmiaru maszyn wirtualnych
W zależności od wymagań dotyczących obciążenia ważne jest prawidłowe ustawianie rozmiaru maszyn wirtualnych klienta w celu uniknięcia ograniczenia ich oczekiwanej przepustowości sieci. Aby osiągnąć oczekiwaną przepływność sieci, nie potrzebujesz wielu kontrolerów interfejsu sieciowego. Chociaż często używane są maszyny wirtualne ogólnego przeznaczenia w usłudze Azure Files, różne typy maszyn wirtualnych są dostępne w zależności od potrzeb obciążeń i dostępności regionu. Aby uzyskać więcej informacji, zobacz Selektor maszyn wirtualnych platformy Azure.
Zachowaj głębokość kolejki mniejszą lub równą 64
Głębokość kolejki to liczba oczekujących żądań we/wy, które może obsłużyć zasób magazynu. Nie zalecamy przekraczania optymalnej głębokości kolejki wynoszącej 64, ponieważ nie zobaczysz jeszcze większej wydajności. Aby uzyskać więcej informacji, zobacz Głębokość kolejki.
Konfiguracja mocowania.
Jeśli obciążenie wymaga montowania wielu udziałów z jednym lub bardziej kontami magazynu z różnymi ustawieniami nconnect z pojedynczego klienta, nie możemy zagwarantować, że te ustawienia będą utrzymywane podczas montowania w publicznym punkcie końcowym. Konfiguracja montowania jest obsługiwana tylko, gdy jeden udział plików Azure jest używany na każde konto magazynu przez prywatny punkt końcowy, zgodnie z opisem w scenariuszu 1.
Scenariusz 1: konfiguracja montowania za pośrednictwem prywatnego punktu końcowego z wieloma kontami przechowywania (obsługiwane)
- StorageAccount.file.core.windows.net = 10.10.10.10
- StorageAccount2.file.core.windows.net = 10.10.10.11
Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare1 nconnect=4Mount StorageAccount2.file.core.windows.net:/StorageAccount2/FileShare1
Scenariusz 2: konfiguracja instalacji za pośrednictwem publicznego punktu końcowego (nieobsługiwane)
- StorageAccount.file.core.windows.net = 52.239.238.8
- StorageAccount2.file.core.windows.net = 52.239.238.7
Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare1 nconnect=4Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare2Mount StorageAccount2.file.core.windows.net:/StorageAccount2/FileShare1
Uwaga / Notatka
Nawet jeśli konto magazynu rozpozna inny adres IP, nie możemy zagwarantować trwałości tego adresu, ponieważ publiczne punkty końcowe nie są adresami statycznymi.
Scenariusz 3: konfiguracja montowania przez prywatny punkt końcowy z wieloma udziałami na jednym koncie magazynowym (nieobsługiwane)
- StorageAccount.file.core.windows.net = 10.10.10.10
Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare1 nconnect=4Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare2Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare3
Konfiguracja testu wydajnościowego
Użyliśmy następujących zasobów i narzędzi do testów porównawczych, aby osiągnąć i zmierzyć wyniki opisane w tym artykule.
- Pojedynczy klient: Maszyna wirtualna platformy Azure (seria DSv4) z jedną kartą sieciową
- SYSTEM OPERACYJNY: Linux (Ubuntu 20.40)
-
Magazyn NFS: Udział plików SSD (aprowizowany 30 TiB, zestaw
nconnect=4)
| rozmiar | vCPU | Pamięć | ** Przechowywanie tymczasowe (SSD) | Maksymalna liczba dysków danych | Maksymalna liczba kart sieciowych | Oczekiwana przepustowość sieci |
|---|---|---|---|---|---|---|
| Standard_D16_v4 | 16 | 64 GiB | Tylko magazyn zdalny | 32 | 8 | 12 500 Mb/s |
Narzędzia i testy porównawcze
Użyliśmy Flexible I/O Tester (FIO), bezpłatnego narzędzia typu open source do testów we/wy dysku, które jest używane zarówno do testów porównawczych, jak i weryfikacji sprzętowej. Aby zainstalować program FIO, postępuj zgodnie z sekcją Pakiety binarne w pliku FIO README , aby zainstalować wybraną platformę.
Te testy koncentrują się na losowych wzorcach dostępu I/O, ale uzyskujesz podobne wyniki podczas korzystania z sekwencyjnego I/O.
Wysoki IOPS: 100 odczytów%
Rozmiar we/wy 4k — losowy odczyt — głębokość kolejki 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=4k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
Rozmiar we/wy 8k — losowy odczyt — głębokość kolejki 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=8k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
Wysoka przepustowość: 100 odczytów%
64 Rozmiar we/wy KiB — losowy odczyt — głębokość kolejki 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=64k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
Rozmiar I/O w KiB - 1024 - 100% losowy odczyt - 64 głębokość kolejki
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=1024k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
Wysokie IOPS: 100 zapisów%
Rozmiar operacji we/wy 4 KiB — losowy zapis% — głębokość kolejki 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=4k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
Rozmiar we/wy: 8 KiB — 100% losowy zapis — głębokość kolejki: 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=8k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
Wysoka przepływność: 100% zapisów
Rozmiar I/O 64 KiB —% losowy zapis — głębokość kolejki 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=64k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
Rozmiar we/wy 1024 KiB - 100 zapisów losowych% - głębokość kolejki 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=1024k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
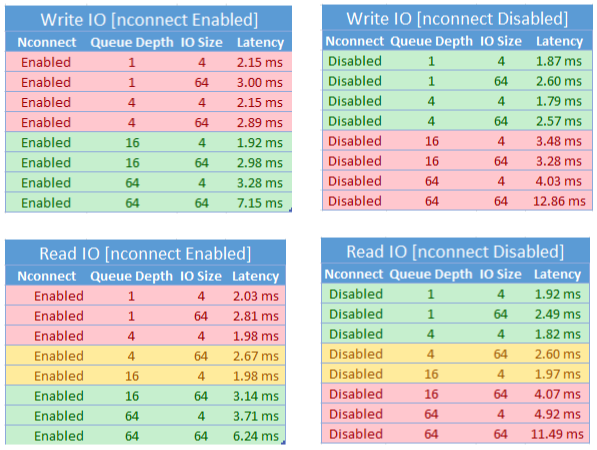
Zagadnienia dotyczące wydajności nconnect
W przypadku korzystania z nconnect opcji montowania należy dokładnie ocenić obciążenia, które mają następujące cechy:
- Obciążenia zapisu wrażliwe na opóźnienia, które są jednowątkowe i/lub używają niskiej głębokości kolejki (mniej niż 16)
- Obciążenia odczytu wrażliwe na opóźnienia, które są jednowątkowe i/lub używają małej głębokości kolejki w połączeniu z mniejszymi rozmiarami operacji wejścia/wyjścia
Nie wszystkie obciążenia wymagają wysokiej liczby operacji we/wy na sekundę lub wysokiej wydajności przepustowości. W przypadku obciążeń o mniejszej nconnect skali może nie mieć sensu. Skorzystaj z poniższej tabeli, aby zdecydować, czy nconnect jest korzystne dla obciążenia roboczego. Zalecane są scenariusze wyróżnione kolorem zielonym, natomiast scenariusze wyróżnione na czerwono nie są zalecane. Scenariusze wyróżnione na żółto są neutralne.
Zastosuj umieszczanie strefowe
W przypadku klasycznych udziałów plików utworzonych za pomocą dostawcy zasobów Microsoft.Storage zalecamy użycie rozmieszczenia strefowego w celu wybrania konkretnej strefy dostępności, w której znajduje się konto magazynowe. Dzięki temu można umieścić maszyny wirtualne w tej samej strefie dostępności co magazyn, co może zmniejszyć opóźnienie o maksymalnie 30 procent. Ta funkcja jest obecnie dostępna tylko dla kont magazynu SSD korzystających z magazynu lokalnie nadmiarowego (LRS) w obsługiwanych regionach.