Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule opisano pewne wzorce, które są odpowiednie do użycia z rozwiązaniami usługi Table Service. Ponadto zobaczysz, jak można praktycznie rozwiązać niektóre problemy i kompromisy omówione w innych artykułach dotyczących projektowania usługi Table Storage. Na poniższym diagramie przedstawiono podsumowanie relacji między różnymi wzorcami:
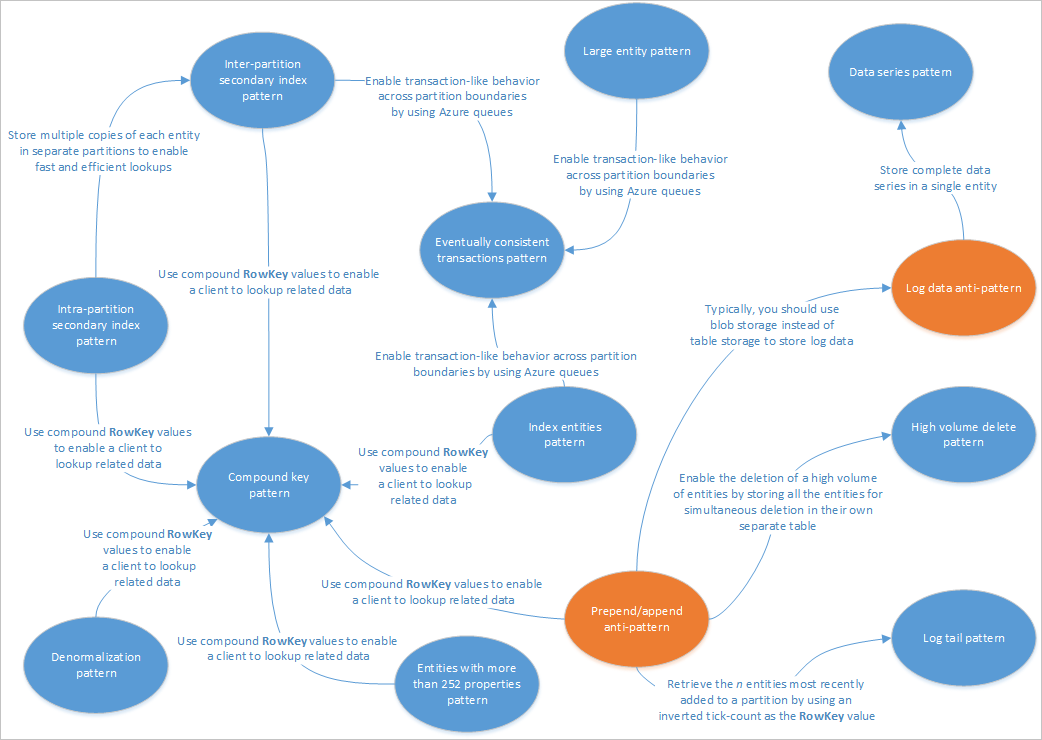
Na powyższej mapie wzorca wyróżniono niektóre relacje między wzorcami (niebieskim) i antywzór (pomarańczowy), które zostały udokumentowane w tym przewodniku. Istnieje wiele innych wzorców, które warto rozważyć. Na przykład jednym z kluczowych scenariuszy usługi Table Service jest użycie wzorca zmaterializowanego widoku ze wzorca podziału odpowiedzialności zapytań poleceń (CQRS).
Wzorzec indeksu pomocniczego wewnątrz partycji
Przechowuj wiele kopii każdej jednostki przy użyciu różnych wartości RowKey (w tej samej partycji), aby umożliwić szybkie i wydajne wyszukiwanie i alternatywne kolejności sortowania przy użyciu różnych wartości RowKey . Aktualizacje między kopiami można zachować spójność przy użyciu transakcji grupy jednostek (EGT).
Kontekst i problem
Usługa Table Service automatycznie indeksuje jednostki przy użyciu wartości PartitionKey i RowKey . Dzięki temu aplikacja kliencka może efektywnie pobierać jednostkę przy użyciu tych wartości. Na przykład przy użyciu struktury tabeli pokazanej poniżej aplikacja kliencka może użyć zapytania punktowego, aby pobrać pojedynczą jednostkę pracownika przy użyciu nazwy działu i identyfikatora pracownika ( wartości PartitionKey i RowKey ). Klient może również pobierać jednostki posortowane według identyfikatora pracownika w każdym dziale.
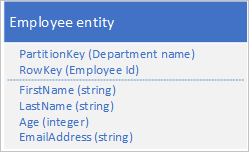
Jeśli chcesz również znaleźć jednostkę pracownika na podstawie wartości innej właściwości, takiej jak adres e-mail, należy użyć mniej wydajnego skanowania partycji, aby znaleźć dopasowanie. Dzieje się tak, ponieważ usługa tabel nie udostępnia indeksów pomocniczych. Ponadto nie ma możliwości zażądania listy pracowników posortowanych w innej kolejności niż kolejność wierszy .
Rozwiązanie
Aby obejść brak indeksów pomocniczych, można przechowywać wiele kopii każdej jednostki przy użyciu innej wartości RowKey . Jeśli przechowujesz jednostkę ze strukturami przedstawionymi poniżej, możesz efektywnie pobierać jednostki pracowników na podstawie adresu e-mail lub identyfikatora pracownika. Wartości prefiksu rowKey, "empid_" i "email_" umożliwiają wykonywanie zapytań o jednego pracownika lub zakres pracowników przy użyciu zakresu adresów e-mail lub identyfikatorów pracowników.

Następujące dwa kryteria filtrowania (jeden wyszukujący według identyfikatora pracownika i jeden wyszukujący według adresu e-mail) określają zapytania dotyczące punktów:
- $filter=(PartitionKey eq 'Sales') i (RowKey eq 'empid_000223')
- $filter=(PartitionKey eq 'Sales') i (RowKey eq 'email_jonesj@contoso.com')
W przypadku wykonywania zapytań dotyczących zakresu jednostek pracowników można określić zakres posortowany w zamówieniu identyfikatora pracownika lub zakres posortowany w kolejności adresów e-mail, wysyłając zapytanie o jednostki z odpowiednim prefiksem w kluczu Wiersza.
Aby znaleźć wszystkich pracowników w dziale sprzedaży z identyfikatorem pracownika w zakresie 000100 do 000199 użyć: $filter=(PartitionKey eq 'Sales') i (RowKey ge 'empid_000100') i (RowKey le 'empid_000199')
Aby znaleźć wszystkich pracowników w dziale sprzedaży z adresem e-mail rozpoczynającym się od litery "a", użyj: $filter=(PartitionKey eq 'Sales') i (RowKey ge 'email_a') i (RowKey lt 'email_b')
Składnia filtru używana w powyższych przykładach pochodzi z interfejsu API REST usługi Table Service, aby uzyskać więcej informacji, zobacz Query Entities (Jednostki zapytań).
Problemy i kwestie do rozważenia
Podczas podejmowania decyzji o sposobie wdrożenia tego wzorca należy rozważyć następujące punkty:
Magazyn tabel jest stosunkowo tani w użyciu, więc koszty związane z przechowywaniem zduplikowanych danych nie powinny być głównym problemem. Jednak zawsze należy ocenić koszt projektu na podstawie przewidywanych wymagań magazynu i dodać tylko zduplikowane jednostki do obsługi zapytań, które będą wykonywane przez aplikację kliencka.
Ponieważ jednostki indeksu pomocniczego są przechowywane w tej samej partycji co oryginalne jednostki, upewnij się, że nie przekraczasz celów skalowalności dla pojedynczej partycji.
Jednostki zduplikowane można zachować nawzajem, używając egt do aktualizacji dwóch kopii jednostki niepodzielnie. Oznacza to, że należy przechowywać wszystkie kopie jednostki w tej samej partycji. Aby uzyskać więcej informacji, zobacz sekcję Using Entity Group Transactions (Używanie transakcji grupy jednostek).
Wartość używana dla elementu RowKey musi być unikatowa dla każdej jednostki. Rozważ użycie wartości klucza złożonego.
Uzupełnianie wartości liczbowych w kluczu RowKey (na przykład identyfikator pracownika 000223) umożliwia poprawne sortowanie i filtrowanie na podstawie górnych i dolnych granic.
Niekoniecznie musisz duplikować wszystkie właściwości jednostki. Jeśli na przykład zapytania wyszukujące jednostki przy użyciu adresu e-mail w kluczu RowKey nigdy nie potrzebują wieku pracownika, te jednostki mogą mieć następującą strukturę:
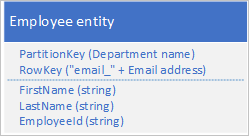
Zazwyczaj lepiej jest przechowywać zduplikowane dane i upewnić się, że można pobrać wszystkie potrzebne dane za pomocą jednego zapytania, niż użyć jednego zapytania w celu zlokalizowania jednostki, a drugiego w celu wyszukania wymaganych danych.
Kiedy używać tego wzorca
Użyj tego wzorca, gdy aplikacja kliencka musi pobierać jednostki przy użyciu różnych kluczy, gdy klient musi pobrać jednostki w różnych zamówieniach sortowania i gdzie można zidentyfikować każdą jednostkę przy użyciu różnych unikatowych wartości. Należy jednak upewnić się, że nie przekraczasz limitów skalowalności partycji podczas wykonywania wyszukiwania jednostek przy użyciu różnych wartości RowKey .
Powiązane wzorce i wskazówki
Podczas implementowania tego wzorca mogą być istotne następujące wzorce i wskazówki:
- Wzorzec indeksu pomocniczego między partycjami
- Wzorzec klucza złożonego
- Transakcje grupy jednostek
- Praca z typami jednostek heterogenicznych
Wzorzec indeksu pomocniczego między partycjami
Przechowuj wiele kopii każdej jednostki przy użyciu różnych wartości RowKey w oddzielnych partycjach lub w oddzielnych tabelach, aby umożliwić szybkie i wydajne wyszukiwanie i alternatywne kolejności sortowania przy użyciu różnych wartości RowKey .
Kontekst i problem
Usługa Table Service automatycznie indeksuje jednostki przy użyciu wartości PartitionKey i RowKey . Dzięki temu aplikacja kliencka może efektywnie pobierać jednostkę przy użyciu tych wartości. Na przykład przy użyciu struktury tabeli pokazanej poniżej aplikacja kliencka może użyć zapytania punktowego, aby pobrać pojedynczą jednostkę pracownika przy użyciu nazwy działu i identyfikatora pracownika ( wartości PartitionKey i RowKey ). Klient może również pobierać jednostki posortowane według identyfikatora pracownika w każdym dziale.
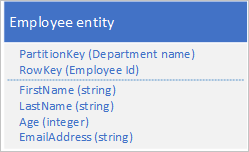
Jeśli chcesz również znaleźć jednostkę pracownika na podstawie wartości innej właściwości, takiej jak adres e-mail, należy użyć mniej wydajnego skanowania partycji, aby znaleźć dopasowanie. Dzieje się tak, ponieważ usługa tabel nie udostępnia indeksów pomocniczych. Ponadto nie ma możliwości zażądania listy pracowników posortowanych w innej kolejności niż kolejność wierszy .
Przewidujesz dużą liczbę transakcji względem tych jednostek i chcesz zminimalizować ryzyko ograniczania przepustowości usługi Table Service.
Rozwiązanie
Aby obejść brak indeksów pomocniczych, można przechowywać wiele kopii każdej jednostki przy użyciu różnych wartości PartitionKey i RowKey . Jeśli przechowujesz jednostkę ze strukturami przedstawionymi poniżej, możesz efektywnie pobierać jednostki pracowników na podstawie adresu e-mail lub identyfikatora pracownika. Wartości prefiksów dla wartości PartitionKey, "empid_" i "email_" umożliwiają określenie indeksu, którego chcesz użyć dla zapytania.

Następujące dwa kryteria filtrowania (jeden wyszukujący według identyfikatora pracownika i jeden wyszukujący według adresu e-mail) określają zapytania dotyczące punktów:
- $filter=(PartitionKey eq 'empid_Sales') i (RowKey eq '000223')
- $filter=(PartitionKey eq 'email_Sales') i (RowKey eq 'jonesj@contoso.com')
W przypadku wykonywania zapytań dotyczących zakresu jednostek pracowników można określić zakres posortowany w zamówieniu identyfikatora pracownika lub zakres posortowany w kolejności adresów e-mail, wysyłając zapytanie o jednostki z odpowiednim prefiksem w kluczu Wiersza.
- Aby znaleźć wszystkich pracowników w dziale sprzedaży z identyfikatorem pracownika w zakresie 000100 do 000199 posortowane w użyciu zamówienia identyfikatora pracownika: $filter=(PartitionKey eq "empid_Sales") i (RowKey ge '000100') i (RowKey le '000199')
- Aby znaleźć wszystkich pracowników w dziale sprzedaży przy użyciu adresu e-mail rozpoczynającego się od "a" posortowanego w kolejności adresów e-mail, użyj polecenia: $filter=(PartitionKey eq 'email_Sales') i (RowKey ge 'a') i (RowKey lt 'b')
Składnia filtru używana w powyższych przykładach pochodzi z interfejsu API REST usługi Table Service, aby uzyskać więcej informacji, zobacz Query Entities (Jednostki zapytań).
Problemy i kwestie do rozważenia
Podczas podejmowania decyzji o sposobie wdrożenia tego wzorca należy rozważyć następujące punkty:
Możesz zachować zduplikowane jednostki w końcu spójne ze sobą, używając wzorca Ostatecznie spójne transakcje, aby zachować jednostki indeksu podstawowego i pomocniczego.
Magazyn tabel jest stosunkowo tani w użyciu, więc koszty związane z przechowywaniem zduplikowanych danych nie powinny być głównym problemem. Jednak zawsze należy ocenić koszt projektu na podstawie przewidywanych wymagań magazynu i dodać tylko zduplikowane jednostki do obsługi zapytań, które będą wykonywane przez aplikację kliencka.
Wartość używana dla elementu RowKey musi być unikatowa dla każdej jednostki. Rozważ użycie wartości klucza złożonego.
Uzupełnianie wartości liczbowych w kluczu RowKey (na przykład identyfikator pracownika 000223) umożliwia poprawne sortowanie i filtrowanie na podstawie górnych i dolnych granic.
Niekoniecznie musisz duplikować wszystkie właściwości jednostki. Jeśli na przykład zapytania wyszukujące jednostki przy użyciu adresu e-mail w kluczu RowKey nigdy nie potrzebują wieku pracownika, te jednostki mogą mieć następującą strukturę:
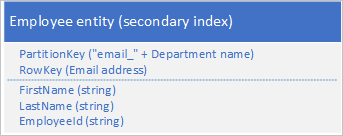
Zazwyczaj lepiej jest przechowywać zduplikowane dane i upewnić się, że można pobrać wszystkie potrzebne dane za pomocą jednego zapytania niż użyć jednego zapytania w celu zlokalizowania jednostki przy użyciu indeksu pomocniczego, a drugiego w celu wyszukania wymaganych danych w indeksie podstawowym.
Kiedy używać tego wzorca
Użyj tego wzorca, gdy aplikacja kliencka musi pobierać jednostki przy użyciu różnych kluczy, gdy klient musi pobrać jednostki w różnych zamówieniach sortowania i gdzie można zidentyfikować każdą jednostkę przy użyciu różnych unikatowych wartości. Użyj tego wzorca, jeśli chcesz uniknąć przekroczenia limitów skalowalności partycji podczas wyszukiwania jednostek przy użyciu różnych wartości RowKey .
Powiązane wzorce i wskazówki
Podczas implementowania tego wzorca mogą być istotne następujące wzorce i wskazówki:
- Wzorzec ostatecznie spójnych transakcji
- Wzorzec indeksu pomocniczego wewnątrz partycji
- Wzorzec klucza złożonego
- Transakcje grupy jednostek
- Praca z typami jednostek heterogenicznych
Wzorzec ostatecznie spójnych transakcji
Włącz ostatecznie spójne zachowanie między granicami partycji lub granicami systemu magazynu przy użyciu kolejek platformy Azure.
Kontekst i problem
Sieci EGT umożliwiają transakcje niepodzielne w wielu jednostkach, które współużytkuje ten sam klucz partycji. Ze względu na wydajność i skalowalność możesz zdecydować się na przechowywanie jednostek, które mają wymagania dotyczące spójności w oddzielnych partycjach lub w osobnym systemie magazynowania: w takim scenariuszu nie można użyć egt do zachowania spójności. Na przykład może być wymagane zachowanie spójności ostatecznej między:
- Jednostki przechowywane w dwóch różnych partycjach w tej samej tabeli, w różnych tabelach lub na różnych kontach magazynu.
- Jednostka przechowywana w usłudze Table Service i obiekt blob przechowywany w usłudze Blob Service.
- Jednostka przechowywana w usłudze Table Service i pliku w systemie plików.
- Jednostka przechowywana w usłudze Table Service jeszcze indeksowana przy użyciu usługi Azure Cognitive usługa wyszukiwania.
Rozwiązanie
Korzystając z kolejek platformy Azure, można zaimplementować rozwiązanie, które zapewnia spójność ostateczną w co najmniej dwóch partycjach lub systemach magazynowania. Aby zilustrować to podejście, załóżmy, że musisz mieć możliwość archiwizowania starych jednostek pracowników. Stare jednostki pracowników są rzadko odpytywane i powinny być wykluczone z wszelkich działań, które zajmują się bieżącymi pracownikami. Aby zaimplementować to wymaganie, należy przechowywać aktywnych pracowników w tabeli Current i starych pracowników w tabeli Archive . Archiwizowanie pracownika wymaga usunięcia jednostki z tabeli Current i dodania jednostki do tabeli Archive , ale nie można użyć egT do wykonania tych dwóch operacji. Aby uniknąć ryzyka, że awaria powoduje, że jednostka pojawia się w obu lub żadnym z tabel, operacja archiwum musi być ostatecznie spójna. Na poniższym diagramie sekwencji przedstawiono kroki opisane w tej operacji. Więcej szczegółów można uzyskać dla ścieżek wyjątków w następującym tekście.
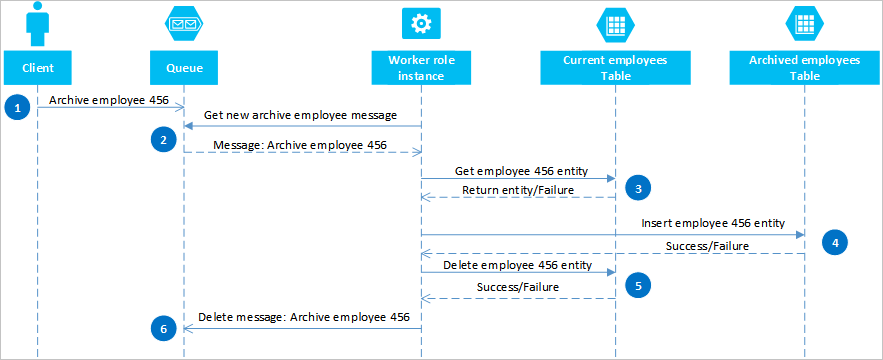
Klient inicjuje operację archiwum, umieszczając komunikat w kolejce platformy Azure, w tym przykładzie w celu zarchiwizowania pracownika nr 456. Rola procesu roboczego sonduje kolejkę pod kątem nowych komunikatów; gdy go znajdzie, odczytuje komunikat i pozostawia ukrytą kopię w kolejce. Następnie rola procesu roboczego pobiera kopię jednostki z tabeli Current , wstawia kopię w tabeli Archiwum , a następnie usuwa oryginał z tabeli Current . Na koniec, jeśli w poprzednich krokach nie wystąpiły żadne błędy, rola procesu roboczego usuwa ukryty komunikat z kolejki.
W tym przykładzie krok 4 wstawia pracownika do tabeli Archive . Może dodać pracownika do obiektu blob w usłudze Blob Service lub pliku w systemie plików.
Odzyskiwanie po awariach
Należy pamiętać, że operacje w krokach 4 i 5 muszą być idempotentne , jeśli rola procesu roboczego musi ponownie uruchomić operację archiwum. Jeśli używasz usługi Table Service, w kroku 4 należy użyć operacji "wstawiania lub zastępowania", w kroku 5 należy użyć operacji "usuń, jeśli istnieje" w używanej bibliotece klienta. Jeśli używasz innego systemu magazynu, musisz użyć odpowiedniej operacji idempotentnej.
Jeśli rola procesu roboczego nigdy nie zakończy kroku 6, po przekroczeniu limitu czasu komunikat pojawi się ponownie w kolejce gotowej do wykonania roli procesu roboczego, aby spróbować go ponownie przetworzyć. Rola procesu roboczego może sprawdzić, ile razy komunikat w kolejce został odczytany i, w razie potrzeby, flaga jest komunikatem "trucizny" do badania, wysyłając go do oddzielnej kolejki. Aby uzyskać więcej informacji na temat odczytywania komunikatów w kolejce i sprawdzania liczby dequeue, zobacz Pobieranie komunikatów.
Niektóre błędy usług Table and Queue są błędami przejściowymi, a aplikacja kliencka powinna zawierać odpowiednią logikę ponawiania prób w celu ich obsługi.
Problemy i kwestie do rozważenia
Podczas podejmowania decyzji o sposobie wdrożenia tego wzorca należy rozważyć następujące punkty:
- To rozwiązanie nie zapewnia izolacji transakcji. Na przykład klient może odczytać tabele Bieżące i Archiwum , gdy rola procesu roboczego była między krokami 4 i 5, i zobaczyć niespójny widok danych. Dane będą spójne w końcu.
- Aby zapewnić spójność ostateczną, należy upewnić się, że kroki 4 i 5 są idempotentne.
- Rozwiązanie można skalować przy użyciu wielu kolejek i wystąpień roli procesu roboczego.
Kiedy używać tego wzorca
Użyj tego wzorca, jeśli chcesz zagwarantować spójność ostateczną między jednostkami, które istnieją w różnych partycjach lub tabelach. Ten wzorzec można rozszerzyć, aby zapewnić spójność ostateczną dla operacji w usłudze Table Service oraz w usłudze Blob Service i innych źródłach danych spoza usługi Azure Storage, takich jak baza danych lub system plików.
Powiązane wzorce i wskazówki
Podczas implementowania tego wzorca mogą być istotne następujące wzorce i wskazówki:
- Transakcje grupy jednostek
- Scal lub zastąp
Uwaga
Jeśli izolacja transakcji jest ważna dla twojego rozwiązania, należy rozważyć przeprojektowanie tabel, aby umożliwić korzystanie z egt.
Wzorzec jednostek indeksowania
Obsługa jednostek indeksu w celu umożliwienia wydajnych wyszukiwań, które zwracają listy jednostek.
Kontekst i problem
Usługa Table Service automatycznie indeksuje jednostki przy użyciu wartości PartitionKey i RowKey . Dzięki temu aplikacja kliencka może efektywnie pobierać jednostkę przy użyciu zapytania punktowego. Na przykład przy użyciu przedstawionej poniżej struktury tabeli aplikacja kliencka może efektywnie pobrać jednostkę pracownika przy użyciu nazwy działu i identyfikatora pracownika ( PartitionKey i RowKey).

Jeśli chcesz również pobrać listę jednostek pracowników na podstawie wartości innej nieu unikatowej właściwości, takiej jak ich nazwisko, należy użyć mniej wydajnego skanowania partycji, aby znaleźć dopasowania, zamiast wyszukiwać je bezpośrednio za pomocą indeksu. Dzieje się tak, ponieważ usługa tabel nie udostępnia indeksów pomocniczych.
Rozwiązanie
Aby włączyć wyszukiwanie według nazwiska wraz ze strukturą jednostki pokazaną powyżej, musisz obsługiwać listy identyfikatorów pracowników. Jeśli chcesz pobrać jednostki pracowników z określonym nazwiskiem, takim jak Jones, musisz najpierw zlokalizować listę identyfikatorów pracowników dla pracowników z Jones jako ich nazwisko, a następnie pobrać te jednostki pracowników. Istnieją trzy główne opcje przechowywania list identyfikatorów pracowników:
- Użyj magazynu obiektów blob.
- Utwórz jednostki indeksu w tej samej partycji co jednostki pracowników.
- Utwórz jednostki indeksu w oddzielnej partycji lub tabeli.
Opcja 1. Korzystanie z magazynu obiektów blob
Dla pierwszej opcji utworzysz obiekt blob dla każdego unikatowego nazwiska, a w każdym magazynie obiektów blob zostanie wyświetlona lista wartości PartitionKey (dział) i RowKey (identyfikator pracownika) dla pracowników, którzy mają to nazwisko. Podczas dodawania lub usuwania pracownika należy upewnić się, że zawartość odpowiedniego obiektu blob jest ostatecznie zgodna z jednostkami pracowników.
Opcja 2. Tworzenie jednostek indeksu w tej samej partycji
W przypadku drugiej opcji użyj jednostek indeksu, które przechowują następujące dane:
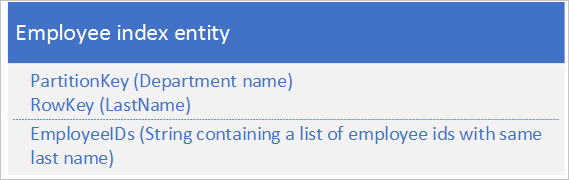
Właściwość EmployeeIDs zawiera listę identyfikatorów pracowników dla pracowników z nazwiskiem przechowywanym w kluczu RowKey.
W poniższych krokach opisano proces, który należy wykonać podczas dodawania nowego pracownika, jeśli używasz drugiej opcji. W tym przykładzie dodajemy pracownika o identyfikatorze 000152 i nazwisko Jones w dziale sprzedaży:
- Pobierz jednostkę indeksu z wartością PartitionKey "Sales" i wartością RowKey "Jones". Zapisz element ETag tej jednostki do użycia w kroku 2.
- Utwórz transakcję grupy jednostek (czyli operację wsadową), która wstawia nową jednostkę pracownika (wartość PartitionKey "Sales" i RowKey "000152") i aktualizuje jednostkę indeksu (wartość PartitionKey "Sales" i RowKey wartość "Jones"), dodając nowy identyfikator pracownika do listy w polu EmployeeIDs. Aby uzyskać więcej informacji na temat transakcji grupy jednostek, zobacz Entity Group Transactions (Transakcje grupy jednostek).
- Jeśli transakcja grupy jednostek nie powiedzie się z powodu błędu optymistycznej współbieżności (ktoś inny właśnie zmodyfikował jednostkę indeksu), musisz zacząć od nowa w kroku 1.
Możesz użyć podobnego podejścia do usunięcia pracownika, jeśli używasz drugiej opcji. Zmiana nazwiska pracownika jest nieco bardziej złożona, ponieważ konieczne będzie wykonanie transakcji grupy jednostek, która aktualizuje trzy jednostki: jednostkę pracownika, jednostkę indeksu starego nazwiska i jednostkę indeksu dla nowego nazwiska. Należy pobrać każdą jednostkę przed wprowadzeniem jakichkolwiek zmian, aby pobrać wartości elementu ETag, których następnie można użyć do wykonania aktualizacji przy użyciu optymistycznej współbieżności.
W poniższych krokach opisano proces, który należy wykonać, gdy musisz wyszukać wszystkich pracowników z danym nazwiskiem w dziale, jeśli używasz drugiej opcji. W tym przykładzie szukamy wszystkich pracowników z nazwiskiem Jones w dziale sprzedaży:
- Pobierz jednostkę indeksu z wartością PartitionKey "Sales" i wartością RowKey "Jones".
- Przeanalizuj listę identyfikatorów pracowników w polu Identyfikatory pracowników.
- Jeśli potrzebujesz dodatkowych informacji o każdym z tych pracowników (takich jak ich adresy e-mail), pobierz każdą z jednostek pracowników przy użyciu wartości PartitionKey "Sales" i RowKey z listy pracowników uzyskanych w kroku 2.
Opcja 3. Tworzenie jednostek indeksu w oddzielnej partycji lub tabeli
W przypadku trzeciej opcji użyj jednostek indeksu, które przechowują następujące dane:

Właściwość EmployeeDetails zawiera listę identyfikatorów pracowników i par nazw działów dla pracowników z nazwiskiem przechowywanym w obiekcie RowKey.
W przypadku trzeciej opcji nie można zachować spójności przy użyciu egt, ponieważ jednostki indeksu znajdują się w oddzielnej partycji od jednostek pracowników. Upewnij się, że jednostki indeksu są ostatecznie zgodne z jednostkami pracowników.
Problemy i kwestie do rozważenia
Podczas podejmowania decyzji o sposobie wdrożenia tego wzorca należy rozważyć następujące punkty:
- To rozwiązanie wymaga co najmniej dwóch zapytań, aby pobrać pasujące jednostki: jeden, aby wykonać zapytanie względem jednostek indeksu w celu uzyskania listy wartości RowKey , a następnie wysyła zapytania dotyczące pobierania każdej jednostki na liście.
- Biorąc pod uwagę, że pojedyncza jednostka ma maksymalny rozmiar 1 MB, opcja #2 i opcja #3 w rozwiązaniu zakładają, że lista identyfikatorów pracowników dla danego nazwiska nigdy nie jest większa niż 1 MB. Jeśli lista identyfikatorów pracowników prawdopodobnie będzie większa niż 1 MB rozmiaru, użyj opcji 1 i zapisz dane indeksu w magazynie obiektów blob.
- Jeśli używasz opcji #2 (przy użyciu egt do obsługi dodawania i usuwania pracowników i zmiany nazwiska pracownika), musisz ocenić, czy liczba transakcji zbliży się do limitów skalowalności w danej partycji. W takim przypadku należy rozważyć ostatecznie spójne rozwiązanie (opcja 1 lub opcja 3), które używa kolejek do obsługi żądań aktualizacji i umożliwia przechowywanie jednostek indeksu w oddzielnej partycji od jednostek pracowników.
- Opcja 2 w tym rozwiązaniu zakłada, że chcesz wyszukać według nazwiska w dziale: na przykład chcesz pobrać listę pracowników z nazwiskiem Jones w dziale sprzedaży. Jeśli chcesz mieć możliwość wyszukiwania wszystkich pracowników z nazwiskiem Jones w całej organizacji, użyj opcji #1 lub opcji #3.
- Możesz zaimplementować rozwiązanie oparte na kolejce, które zapewnia spójność ostateczną (zobacz Wzorzec ostatecznie spójnych transakcji, aby uzyskać więcej szczegółów).
Kiedy używać tego wzorca
Użyj tego wzorca, jeśli chcesz wyszukać zestaw jednostek, które mają wspólną wartość właściwości, na przykład wszystkich pracowników z nazwiskiem Jones.
Powiązane wzorce i wskazówki
Podczas implementowania tego wzorca mogą być istotne następujące wzorce i wskazówki:
- Wzorzec klucza złożonego
- Wzorzec ostatecznie spójnych transakcji
- Transakcje grupy jednostek
- Praca z typami jednostek heterogenicznych
Wzorzec denormalizacji
Połącz powiązane dane w jednej jednostce, aby umożliwić pobieranie wszystkich potrzebnych danych za pomocą zapytania o jeden punkt.
Kontekst i problem
W relacyjnej bazie danych zwykle normalizujesz dane w celu usunięcia duplikatów, co powoduje, że zapytania pobierające dane z wielu tabel. Jeśli znormalizowasz dane w tabelach platformy Azure, musisz wykonać wiele rund z klienta do serwera, aby pobrać powiązane dane. Na przykład ze strukturą tabeli pokazaną poniżej potrzebujesz dwóch rund, aby pobrać szczegóły dla działu: jeden do pobrania jednostki działu zawierającej identyfikator menedżera, a następnie kolejne żądanie pobrania szczegółów menedżera w jednostce pracownika.

Rozwiązanie
Zamiast przechowywać dane w dwóch osobnych jednostkach, zdenormalizuj dane i zachowaj kopię szczegółów menedżera w jednostce działu. Na przykład:
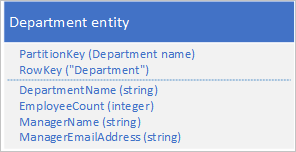
W przypadku jednostek działu przechowywanych przy użyciu tych właściwości można teraz pobrać wszystkie potrzebne szczegóły dotyczące działu przy użyciu zapytania dotyczącego punktu.
Problemy i kwestie do rozważenia
Podczas podejmowania decyzji o sposobie wdrożenia tego wzorca należy rozważyć następujące punkty:
- Istnieje pewne obciążenie związane z przechowywaniem niektórych danych dwa razy. Korzyść z wydajności (wynikająca z mniejszej liczby żądań do usługi magazynu) zwykle przewyższa marginalny wzrost kosztów magazynowania (a koszt ten jest częściowo przesunięty przez zmniejszenie liczby transakcji, których potrzebujesz, aby pobrać szczegóły działu).
- Należy zachować spójność dwóch jednostek, które przechowują informacje o menedżerach. Problem z spójnością można rozwiązać przy użyciu egt w celu zaktualizowania wielu jednostek w jednej transakcji niepodzielnej: w tym przypadku jednostka działu i jednostka pracownika dla menedżera działu są przechowywane w tej samej partycji.
Kiedy używać tego wzorca
Użyj tego wzorca, gdy często trzeba wyszukać powiązane informacje. Ten wzorzec zmniejsza liczbę zapytań, które klient musi wykonać, aby pobrać wymagane dane.
Powiązane wzorce i wskazówki
Podczas implementowania tego wzorca mogą być istotne następujące wzorce i wskazówki:
- Wzorzec klucza złożonego
- Transakcje grupy jednostek
- Praca z typami jednostek heterogenicznych
Wzorzec klucza złożonego
Użyj złożonych wartości RowKey , aby umożliwić klientowi wyszukiwanie powiązanych danych za pomocą zapytania pojedynczego punktu.
Kontekst i problem
W relacyjnej bazie danych naturalne jest użycie sprzężeń w zapytaniach w celu zwrócenia powiązanych fragmentów danych do klienta w jednym zapytaniu. Możesz na przykład użyć identyfikatora pracownika, aby wyszukać listę powiązanych jednostek, które zawierają dane dotyczące wydajności i przeglądania danych dla tego pracownika.
Załóżmy, że przechowujesz jednostki pracowników w usłudze Table Service przy użyciu następującej struktury:
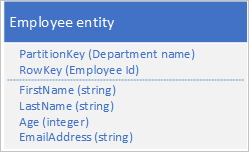
Musisz również przechowywać dane historyczne dotyczące przeglądów i wydajności dla każdego roku, w którym pracownik pracował w organizacji i musisz mieć możliwość uzyskania dostępu do tych informacji według roku. Jedną z opcji jest utworzenie innej tabeli, która przechowuje jednostki o następującej strukturze:
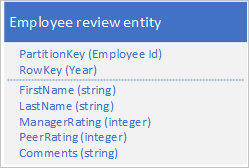
Zwróć uwagę, że w przypadku tego podejścia możesz zdecydować się na zduplikowanie niektórych informacji (takich jak imię i nazwisko) w nowej jednostce, aby umożliwić pobieranie danych za pomocą jednego żądania. Nie można jednak zachować silnej spójności, ponieważ nie można użyć egT do atomowej aktualizacji dwóch jednostek.
Rozwiązanie
Zapisz nowy typ jednostki w oryginalnej tabeli przy użyciu jednostek o następującej strukturze:
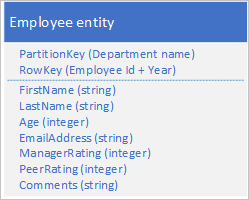
Zwróć uwagę, że klucz RowKey jest teraz kluczem złożonym składającym się z identyfikatora pracownika i roku danych przeglądu, które umożliwiają pobranie wydajności pracownika i przejrzenie danych z pojedynczym żądaniem dla pojedynczej jednostki.
W poniższym przykładzie przedstawiono sposób pobierania wszystkich danych przeglądu dla określonego pracownika (na przykład pracownika 000123 w dziale sprzedaży):
$filter=(PartitionKey eq 'Sales') i (RowKey ge 'empid_000123') i (RowKey lt '000123_2012')&$select=RowKey,Manager Rating,Peer Rating,Comments
Problemy i kwestie do rozważenia
Podczas podejmowania decyzji o sposobie wdrożenia tego wzorca należy rozważyć następujące punkty:
- Należy użyć odpowiedniego znaku separatora, który ułatwia analizowanie wartości RowKey : na przykład 000123_2012.
- Przechowujesz również tę jednostkę w tej samej partycji co inne jednostki, które zawierają powiązane dane dla tego samego pracownika, co oznacza, że możesz użyć egt do utrzymania silnej spójności.
- Należy rozważyć częstotliwość wykonywania zapytań dotyczących danych w celu określenia, czy ten wzorzec jest odpowiedni. Jeśli na przykład będziesz uzyskiwać dostęp do danych przeglądu rzadko, a główne dane pracowników często powinny być zachowywane jako oddzielne jednostki.
Kiedy używać tego wzorca
Użyj tego wzorca, jeśli musisz przechowywać co najmniej jedną powiązaną jednostkę, której często wysyłasz zapytania.
Powiązane wzorce i wskazówki
Podczas implementowania tego wzorca mogą być istotne następujące wzorce i wskazówki:
- Transakcje grupy jednostek
- Praca z typami jednostek heterogenicznych
- Wzorzec ostatecznie spójnych transakcji
Wzorzec ogona dziennika
Pobierz n jednostek ostatnio dodanych do partycji przy użyciu wartości RowKey, która sortuje w odwrotnej kolejności daty i godziny.
Kontekst i problem
Typowym wymaganiem jest pobranie ostatnio utworzonych jednostek, na przykład 10 najnowszych oświadczeń wydatków przesłanych przez pracownika. Zapytania tabeli obsługują operację zapytania $top zwracającą pierwsze n jednostek z zestawu: nie ma równoważnej operacji zapytania, aby zwrócić ostatnie n jednostek w zestawie.
Rozwiązanie
Przechowuj jednostki przy użyciu klawisza RowKey , który naturalnie sortuje w odwrotnej kolejności daty/godziny przy użyciu, dzięki czemu najnowszy wpis jest zawsze pierwszym wpisem w tabeli.
Aby na przykład można było pobrać 10 najnowszych roszczeń wydatków przesłanych przez pracownika, możesz użyć wartości odwrotnej znacznika pochodzącej z bieżącej daty/godziny. Poniższy przykład kodu w języku C# przedstawia jeden ze sposobów utworzenia odpowiedniej wartości "odwróconych znaczników" dla elementu RowKey , który sortuje od najnowszych do najstarszych:
string invertedTicks = string.Format("{0:D19}", DateTime.MaxValue.Ticks - DateTime.UtcNow.Ticks);
Możesz wrócić do wartości daty i godziny przy użyciu następującego kodu:
DateTime dt = new DateTime(DateTime.MaxValue.Ticks - Int64.Parse(invertedTicks));
Zapytanie tabeli wygląda następująco:
https://myaccount.table.core.windows.net/EmployeeExpense(PartitionKey='empid')?$top=10
Problemy i kwestie do rozważenia
Podczas podejmowania decyzji o sposobie wdrożenia tego wzorca należy rozważyć następujące punkty:
- Aby zapewnić sortowanie wartości ciągu zgodnie z oczekiwaniami, należy wypełnić wartość odwrotną znacznika z wiodącymi zerami.
- Należy pamiętać o celach skalowalności na poziomie partycji. Należy zachować ostrożność, aby nie tworzyć partycji typu hot spot.
Kiedy używać tego wzorca
Użyj tego wzorca, jeśli musisz uzyskać dostęp do jednostek w odwrotnej kolejności daty/godziny lub gdy musisz uzyskać dostęp do ostatnio dodanych jednostek.
Powiązane wzorce i wskazówki
Podczas implementowania tego wzorca mogą być istotne następujące wzorce i wskazówki:
Wzorzec usuwania dużego woluminu
Włącz usuwanie dużej liczby jednostek, przechowując wszystkie jednostki w celu jednoczesnego usunięcia we własnej oddzielnej tabeli; jednostki można usunąć, usuwając tabelę.
Kontekst i problem
Wiele aplikacji usuwa stare dane, które nie muszą być już dostępne dla aplikacji klienckiej lub że aplikacja została zarchiwizowana na innym nośniku magazynu. Zazwyczaj identyfikujesz takie dane według daty: na przykład wymagane jest usunięcie rekordów wszystkich żądań logowania, które mają więcej niż 60 dni.
Jednym z możliwych projektów jest użycie daty i godziny żądania logowania w kluczu RowKey:
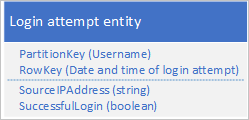
Takie podejście pozwala uniknąć hotspotów partycji, ponieważ aplikacja może wstawiać i usuwać jednostki logowania dla każdego użytkownika w oddzielnej partycji. Jednak takie podejście może być kosztowne i czasochłonne, jeśli masz dużą liczbę jednostek, ponieważ najpierw należy przeprowadzić skanowanie tabeli, aby zidentyfikować wszystkie jednostki do usunięcia, a następnie usunąć każdą starą jednostkę. Liczbę rund na serwerze wymaganym do usunięcia starych jednostek można zmniejszyć, umieszczając wiele żądań usuwania w partiach w egtach.
Rozwiązanie
Użyj oddzielnej tabeli dla każdego dnia prób logowania. Możesz użyć powyższego projektu jednostki, aby uniknąć hotspotów podczas wstawiania jednostek, a usuwanie starych jednostek jest teraz po prostu pytaniem o usunięcie jednej tabeli każdego dnia (pojedynczej operacji magazynowania) zamiast znajdować i usuwać setki i tysiące pojedynczych jednostek logowania każdego dnia.
Problemy i kwestie do rozważenia
Podczas podejmowania decyzji o sposobie wdrożenia tego wzorca należy rozważyć następujące punkty:
- Czy projekt obsługuje inne sposoby używania przez aplikację danych, takich jak wyszukanie określonych jednostek, łączenie z innymi danymi lub generowanie zagregowanych informacji?
- Czy projekt unika punktów aktywnych podczas wstawiania nowych jednostek?
- Jeśli chcesz ponownie użyć tej samej nazwy tabeli po jego usunięciu, spodziewaj się opóźnienia. Lepiej zawsze używać unikatowych nazw tabel.
- Spodziewaj się ograniczenia podczas pierwszego użycia nowej tabeli, podczas gdy usługa Table Service uczy się wzorców dostępu i dystrybuuje partycje między węzłami. Należy wziąć pod uwagę częstotliwość tworzenia nowych tabel.
Kiedy używać tego wzorca
Użyj tego wzorca, gdy masz dużą liczbę jednostek, które należy usunąć w tym samym czasie.
Powiązane wzorce i wskazówki
Podczas implementowania tego wzorca mogą być istotne następujące wzorce i wskazówki:
- Transakcje grupy jednostek
- Modyfikowanie jednostek
Wzorzec serii danych
Przechowuj kompletną serię danych w jednej jednostce, aby zminimalizować liczbę wysyłanych żądań.
Kontekst i problem
Typowym scenariuszem jest przechowywanie przez aplikację serii danych, które zwykle muszą być pobierane jednocześnie. Na przykład aplikacja może rejestrować liczbę wiadomości błyskawicznych wysyłanych przez każdego pracownika co godzinę, a następnie użyć tych informacji do wykreślenia liczby komunikatów wysyłanych przez każdego użytkownika w ciągu ostatnich 24 godzin. Jednym z projektów może być przechowywanie 24 jednostek dla każdego pracownika:
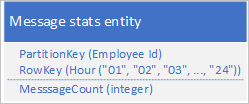
Dzięki temu projektowi można łatwo zlokalizować i zaktualizować jednostkę do aktualizacji dla każdego pracownika za każdym razem, gdy aplikacja musi zaktualizować wartość liczby komunikatów. Aby jednak pobrać informacje, aby wykreślić wykres działania z poprzednich 24 godzin, należy pobrać 24 jednostki.
Rozwiązanie
Użyj następującego projektu z oddzielną właściwością, aby przechowywać liczbę komunikatów dla każdej godziny:
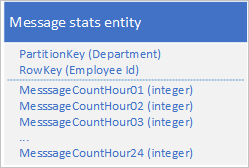
W tym projekcie można użyć operacji scalania, aby zaktualizować liczbę komunikatów dla pracownika przez określoną godzinę. Teraz możesz pobrać wszystkie informacje potrzebne do wykreślenia wykresu przy użyciu żądania dla pojedynczej jednostki.
Problemy i kwestie do rozważenia
Podczas podejmowania decyzji o sposobie wdrożenia tego wzorca należy rozważyć następujące punkty:
- Jeśli kompletna seria danych nie pasuje do jednej jednostki (jednostka może mieć maksymalnie 252 właściwości), użyj alternatywnego magazynu danych, takiego jak obiekt blob.
- Jeśli masz jednocześnie wielu klientów aktualizując jednostkę, musisz użyć elementu ETag do zaimplementowania optymistycznej współbieżności. Jeśli masz wielu klientów, może wystąpić wysoka rywalizacja.
Kiedy używać tego wzorca
Użyj tego wzorca, gdy musisz zaktualizować i pobrać serię danych skojarzona z pojedynczą jednostką.
Powiązane wzorce i wskazówki
Podczas implementowania tego wzorca mogą być istotne następujące wzorce i wskazówki:
- Wzorzec dużych jednostek
- Scal lub zastąp
- Ostatecznie spójny wzorzec transakcji (jeśli przechowujesz serię danych w obiekcie blob)
Wzorzec szerokich jednostek
Używanie wielu jednostek fizycznych do przechowywania jednostek logicznych z więcej niż 252 właściwościami.
Kontekst i problem
Jednostka indywidualna może mieć nie więcej niż 252 właściwości (z wyłączeniem obowiązkowych właściwości systemu) i nie może przechowywać łącznie więcej niż 1 MB danych. W relacyjnej bazie danych zazwyczaj można zaokrąglić wszelkie limity rozmiaru wiersza, dodając nową tabelę i wymuszając relację od 1 do 1 między nimi.
Rozwiązanie
Za pomocą usługi Table Service można przechowywać wiele jednostek reprezentujących jeden duży obiekt biznesowy z ponad 252 właściwościami. Jeśli na przykład chcesz przechowywać liczbę komunikatów błyskawicznych wysyłanych przez każdego pracownika przez ostatnie 365 dni, możesz użyć następującego projektu, który używa dwóch jednostek z różnymi schematami:
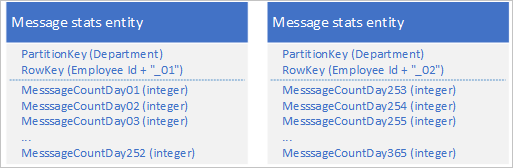
Jeśli musisz wprowadzić zmianę, która wymaga zaktualizowania obu jednostek, aby zachować ich synchronizację ze sobą, możesz użyć EGT. W przeciwnym razie można użyć pojedynczej operacji scalania, aby zaktualizować liczbę komunikatów dla określonego dnia. Aby pobrać wszystkie dane dla pojedynczego pracownika, musisz pobrać obie jednostki, które można wykonać za pomocą dwóch wydajnych żądań, które używają wartości PartitionKey i RowKey .
Problemy i kwestie do rozważenia
Podczas podejmowania decyzji o sposobie wdrożenia tego wzorca należy rozważyć następujące punkty:
- Pobieranie pełnej jednostki logicznej obejmuje co najmniej dwie transakcje magazynu: jedną do pobrania każdej jednostki fizycznej.
Kiedy używać tego wzorca
Użyj tego wzorca, gdy trzeba przechowywać jednostki, których rozmiar lub liczba właściwości przekraczają limity dla pojedynczej jednostki w usłudze Table Service.
Powiązane wzorce i wskazówki
Podczas implementowania tego wzorca mogą być istotne następujące wzorce i wskazówki:
- Transakcje grupy jednostek
- Scal lub zastąp
Wzorzec dużych jednostek
Magazyn obiektów blob służy do przechowywania dużych wartości właściwości.
Kontekst i problem
Pojedyncza jednostka nie może przechowywać łącznie więcej niż 1 MB danych. Jeśli co najmniej jedna z właściwości przechowuje wartości, które powodują przekroczenie całkowitego rozmiaru jednostki, nie można przechowywać całej jednostki w usłudze Table Service.
Rozwiązanie
Jeśli rozmiar jednostki przekracza 1 MB, ponieważ co najmniej jedna właściwość zawiera dużą ilość danych, możesz przechowywać dane w usłudze Blob Service, a następnie przechowywać adres obiektu blob we właściwości w jednostce. Na przykład możesz przechowywać zdjęcie pracownika w magazynie obiektów blob i przechowywać link do zdjęcia we właściwości Zdjęcie jednostki pracownika:
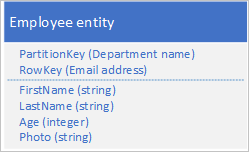
Problemy i kwestie do rozważenia
Podczas podejmowania decyzji o sposobie wdrożenia tego wzorca należy rozważyć następujące punkty:
- Aby zachować spójność ostateczną między jednostką w usłudze Table Service i danymi w usłudze Blob Service, użyj wzorca Ostatecznie spójne transakcje, aby zachować jednostki.
- Pobieranie pełnej jednostki obejmuje co najmniej dwie transakcje magazynu: jedną, aby pobrać jednostkę i jedną, aby pobrać dane obiektu blob.
Kiedy używać tego wzorca
Użyj tego wzorca, gdy musisz przechowywać jednostki, których rozmiar przekracza limity dla pojedynczej jednostki w usłudze Table Service.
Powiązane wzorce i wskazówki
Podczas implementowania tego wzorca mogą być istotne następujące wzorce i wskazówki:
Prepend/append anti-pattern
Zwiększ skalowalność, gdy masz dużą liczbę wstawiania, rozkładając wstawki między wiele partycji.
Kontekst i problem
Wstępne lub dołączanie jednostek do przechowywanych jednostek zwykle powoduje dodanie nowych jednostek do pierwszej lub ostatniej partycji sekwencji partycji przez aplikację. W takim przypadku wszystkie wstawki w dowolnym momencie odbywają się w tej samej partycji, tworząc hotspot, który uniemożliwia usłudze tabel wstawiania równoważenia obciążenia między wieloma węzłami, a może spowodować, że aplikacja osiągnie cele skalowalności partycji. Jeśli na przykład masz aplikację, która rejestruje dostęp do sieci i zasobów przez pracowników, struktura jednostki, jak pokazano poniżej, może spowodować, że partycja bieżącej godziny stanie się hotspotem, jeśli liczba transakcji osiągnie cel skalowalności dla pojedynczej partycji:

Rozwiązanie
Następująca alternatywna struktura jednostki pozwala uniknąć hotspotu na dowolnej partycji, ponieważ aplikacja rejestruje zdarzenia:
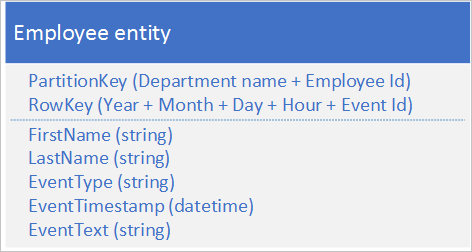
Zwróć uwagę, że w tym przykładzie klucze złożone są zarówno kluczami PartitionKey , jak i RowKey . Klucz PartitionKey używa zarówno identyfikatora działu, jak i pracownika do dystrybucji rejestrowania między wieloma partycjami.
Problemy i kwestie do rozważenia
Podczas podejmowania decyzji o sposobie wdrożenia tego wzorca należy rozważyć następujące punkty:
- Czy alternatywna struktura klucza, która pozwala uniknąć tworzenia gorących partycji na wstawkach, efektywnie obsługuje zapytania tworzone przez aplikację kliencką?
- Czy oczekiwana liczba transakcji oznacza, że prawdopodobnie osiągniesz cele skalowalności dla pojedynczej partycji i zostanie ograniczona przez usługę magazynu?
Kiedy używać tego wzorca
Unikaj wstępnego/dołączania wzorca antywłaszowego, gdy wolumin transakcji może spowodować ograniczenie przepustowości przez usługę magazynu podczas uzyskiwania dostępu do gorącej partycji.
Powiązane wzorce i wskazówki
Podczas implementowania tego wzorca mogą być istotne następujące wzorce i wskazówki:
Antywzór danych dziennika
Zazwyczaj należy użyć usługi Blob Service zamiast usługi Table Service do przechowywania danych dziennika.
Kontekst i problem
Typowym przypadkiem użycia danych dziennika jest pobranie wybranych wpisów dziennika dla określonego zakresu daty/godziny: na przykład chcesz znaleźć wszystkie komunikaty o błędach i krytycznych zarejestrowanych przez aplikację z zakresu od 15:04 do 15:06 w określonej dacie. Nie chcesz używać daty i godziny komunikatu dziennika do określenia partycji, w której są zapisywane jednostki dziennika: powoduje to gorącą partycję, ponieważ w danym momencie wszystkie jednostki dziennika będą współużytkować tę samą wartość PartitionKey (zobacz sekcję Prepend/append anti-pattern). Na przykład następujący schemat jednostki dla komunikatu dziennika powoduje gorącą partycję, ponieważ aplikacja zapisuje wszystkie komunikaty dziennika w partycji dla bieżącej daty i godziny:
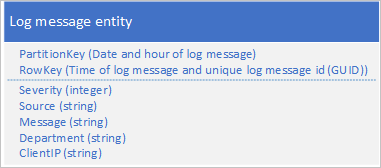
W tym przykładzie klucz RowKey zawiera datę i godzinę komunikatu dziennika, aby upewnić się, że komunikaty dziennika są sortowane w kolejności daty/godziny i zawierają identyfikator komunikatu w przypadku, gdy wiele komunikatów dziennika współużytkuje tę samą datę i godzinę.
Innym podejściem jest użycie klucza PartitionKey , który zapewnia, że aplikacja zapisuje komunikaty w wielu partycjach. Jeśli na przykład źródło komunikatu dziennika umożliwia dystrybucję komunikatów między wieloma partycjami, można użyć następującego schematu jednostki:
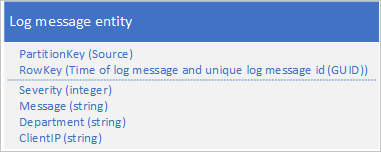
Jednak problem z tym schematem polega na tym, że aby pobrać wszystkie komunikaty dziennika dla określonego przedziału czasu, należy przeszukać każdą partycję w tabeli.
Rozwiązanie
W poprzedniej sekcji wyróżniono problem z próbą użycia usługi Table Service do przechowywania wpisów dziennika i sugerowane dwa, niezadowalające, projekty. Jedno rozwiązanie doprowadziło do gorącej partycji z ryzykiem niskiej wydajności zapisywania komunikatów dziennika; inne rozwiązanie spowodowało niską wydajność zapytań ze względu na wymóg skanowania każdej partycji w tabeli w celu pobrania komunikatów dziennika dla określonego przedziału czasu. Usługa Blob Storage oferuje lepsze rozwiązanie dla tego typu scenariusza. W ten sposób usługa Azure analityka magazynu przechowuje zbierane dane dziennika.
W tej sekcji opisano, jak analityka magazynu przechowuje dane dziennika w magazynie obiektów blob jako ilustrację tego podejścia do przechowywania danych, które zwykle są wykonywane według zakresu.
analityka magazynu przechowuje komunikaty dziennika w formacie rozdzielonym w wielu obiektach blob. Format rozdzielany ułatwia aplikacji klienckiej analizowanie danych w komunikacie dziennika.
analityka magazynu używa konwencji nazewnictwa obiektów blob, która umożliwia lokalizowanie obiektów blob (lub obiektów blob) zawierających wyszukiwane komunikaty dziennika. Na przykład obiekt blob o nazwie "queue/2014/07/31/1800/000001.log" zawiera komunikaty dziennika, które odnoszą się do usługi kolejki przez godzinę rozpoczynającą się o godzinie 18:00 w dniu 31 lipca 2014 r. Wartość "000001" wskazuje, że jest to pierwszy plik dziennika dla tego okresu. analityka magazynu również rejestruje znaczniki czasu pierwszych i ostatnich komunikatów dziennika przechowywanych w pliku w ramach metadanych obiektu blob. Interfejs API dla magazynu obiektów blob umożliwia lokalizowanie obiektów blob w kontenerze na podstawie prefiksu nazwy: w celu zlokalizowania wszystkich obiektów blob zawierających dane dziennika kolejki przez godzinę rozpoczynającą się od 18:00, można użyć prefiksu "queue/2014/07/31/1800".
analityka magazynu buforuje komunikaty dziennika wewnętrznie, a następnie okresowo aktualizuje odpowiedni obiekt blob lub tworzy nowy z najnowszą partią wpisów dziennika. Zmniejsza to liczbę operacji zapisu, które musi wykonać w usłudze obiektów blob.
Jeśli wdrażasz podobne rozwiązanie we własnej aplikacji, musisz rozważyć sposób zarządzania kompromisem między niezawodnością (zapisywanie każdego wpisu dziennika w magazynie obiektów blob w taki sposób) oraz kosztami i skalowalnością (buforowanie aktualizacji w aplikacji i zapisywanie ich w magazynach obiektów blob w partiach).
Problemy i kwestie do rozważenia
Podczas podejmowania decyzji o sposobie przechowywania danych dziennika należy wziąć pod uwagę następujące kwestie:
- Jeśli tworzysz projekt tabeli, który pozwala uniknąć potencjalnych gorących partycji, może się okazać, że nie możesz efektywnie uzyskać dostępu do danych dziennika.
- Aby przetwarzać dane dziennika, klient często musi załadować wiele rekordów.
- Chociaż dane dziennika są często ustrukturyzowane, magazyn obiektów blob może być lepszym rozwiązaniem.
Uwagi dotyczące implementacji
W tej sekcji omówiono niektóre zagadnienia, które należy wziąć pod uwagę podczas implementowania wzorców opisanych w poprzednich sekcjach. Większość tej sekcji używa przykładów napisanych w języku C#, które używają biblioteki klienta usługi Storage (wersja 4.3.0 w momencie pisania).
Pobieranie jednostek
Jak opisano w sekcji Projektowanie zapytań, najbardziej wydajne zapytanie jest zapytaniem punktowym. Jednak w niektórych scenariuszach może być konieczne pobranie wielu jednostek. W tej sekcji opisano niektóre typowe podejścia do pobierania jednostek przy użyciu biblioteki klienta usługi Storage.
Wykonywanie zapytania punktu przy użyciu biblioteki klienta usługi Storage
Najprostszym sposobem wykonania zapytania punktu jest użycie metody GetEntityAsync , jak pokazano w poniższym fragmencie kodu języka C#, który pobiera jednostkę z kluczem PartitionKey wartości "Sales" i RowKey wartości "212":
EmployeeEntity employee = await employeeTable.GetEntityAsync<EmployeeEntity>("Sales", "212");
Zwróć uwagę, że ten przykład oczekuje, że jednostka, która zostanie pobrana, będzie typu EmployeeEntity.
Pobieranie wielu jednostek przy użyciu LINQ
LinQ służy do pobierania wielu jednostek z usługi Table Service podczas pracy z biblioteką Standardowa tabel usługi Microsoft Azure Cosmos DB.
dotnet add package Azure.Data.Tables
Aby wykonać poniższe przykłady, należy uwzględnić przestrzenie nazw:
using System.Linq;
using Azure.Data.Tables
Pobieranie wielu jednostek można osiągnąć, określając zapytanie z klauzulą filtru. Aby uniknąć skanowania tabeli, zawsze należy uwzględnić wartość PartitionKey w klauzuli filtru i, jeśli to możliwe , wartość RowKey , aby uniknąć skanowania tabel i partycji. Usługa tabel obsługuje ograniczony zestaw operatorów porównania (większe niż, większe lub równe, mniejsze niż, mniejsze niż lub równe, równe i nie równe) do użycia w klauzuli filtru.
W poniższym przykładzie employeeTable jest obiektem TableClient . W tym przykładzie znajdują wszystkich pracowników, których nazwisko zaczyna się od "B" (przy założeniu, że klucz RowKey przechowuje nazwisko) w dziale sprzedaży (przy założeniu, że partitionKey przechowuje nazwę działu):
var employees = employeeTable.Query<EmployeeEntity>(e => (e.PartitionKey == "Sales" && e.RowKey.CompareTo("B") >= 0 && e.RowKey.CompareTo("C") < 0));
Zwróć uwagę, że zapytanie określa zarówno klucz wiersza, jak i klucz partycji, aby zapewnić lepszą wydajność.
Poniższy przykładowy kod pokazuje równoważne funkcje bez używania składni LINQ:
var employees = employeeTable.Query<EmployeeEntity>(filter: $"PartitionKey eq 'Sales' and RowKey ge 'B' and RowKey lt 'C'");
Uwaga
Przykładowe metody zapytania obejmują trzy warunki filtrowania.
Pobieranie dużej liczby jednostek z zapytania
Zapytanie optymalne zwraca pojedynczą jednostkę na podstawie wartości PartitionKey i wartości RowKey . Jednak w niektórych scenariuszach może być wymagane zwrócenie wielu jednostek z tej samej partycji, a nawet z wielu partycji.
Zawsze należy w pełni przetestować wydajność aplikacji w takich scenariuszach.
Zapytanie względem usługi tabel może zwrócić maksymalnie 1000 jednostek jednocześnie i może zostać wykonane przez maksymalnie pięć sekund. Jeśli zestaw wyników zawiera więcej niż 1000 jednostek, jeśli zapytanie nie zostało ukończone w ciągu pięciu sekund lub jeśli zapytanie przekracza granicę partycji, usługa Table zwraca token kontynuacji, aby umożliwić aplikacji klienckiej żądanie następnego zestawu jednostek. Aby uzyskać więcej informacji na temat sposobu działania tokenów kontynuacji, zobacz Limit czasu zapytań i stronicowanie.
Jeśli używasz biblioteki klienta tabel platformy Azure, może automatycznie obsługiwać tokeny kontynuacji podczas zwracania jednostek z usługi Table Service. Poniższy przykładowy kod języka C# korzystający z biblioteki klienta automatycznie obsługuje tokeny kontynuacji, jeśli usługa tabeli zwróci je w odpowiedzi:
var employees = employeeTable.Query<EmployeeEntity>("PartitionKey eq 'Sales'")
foreach (var emp in employees)
{
// ...
}
Można również określić maksymalną liczbę jednostek zwracanych na stronę. W poniższym przykładzie pokazano, jak wykonywać zapytania dotyczące jednostek za pomocą polecenia maxPerPage:
var employees = employeeTable.Query<EmployeeEntity>(maxPerPage: 10);
// Iterate the Pageable object by page
foreach (var page in employees.AsPages())
{
// Iterate the entities returned for this page
foreach (var emp in page.Values)
{
// ...
}
}
W bardziej zaawansowanych scenariuszach możesz przechowywać token kontynuacji zwrócony z usługi, aby kod był kontrolowany dokładnie po pobraniu następnych stron. Poniższy przykład przedstawia podstawowy scenariusz pobierania i stosowania tokenu do wyników podzielonych na strony:
string continuationToken = null;
bool moreResultsAvailable = true;
while (moreResultsAvailable)
{
var page = employeeTable
.Query<EmployeeEntity>()
.AsPages(continuationToken, pageSizeHint: 10)
.FirstOrDefault(); // pageSizeHint limits the number of results in a single page, so we only enumerate the first page
if (page == null)
break;
// Get the continuation token from the page
// Note: This value can be stored so that the next page query can be executed later
continuationToken = page.ContinuationToken;
var pageResults = page.Values;
moreResultsAvailable = pageResults.Any() && continuationToken != null;
// Iterate the results for this page
foreach (var result in pageResults)
{
// ...
}
}
Korzystając jawnie z tokenów kontynuacji, możesz kontrolować, kiedy aplikacja pobiera następny segment danych. Jeśli na przykład aplikacja kliencka umożliwia użytkownikom stronicowanie za pośrednictwem jednostek przechowywanych w tabeli, użytkownik może zdecydować się nie stronicować za pośrednictwem wszystkich jednostek pobranych przez zapytanie, aby aplikacja korzystała tylko z tokenu kontynuacji w celu pobrania następnego segmentu, gdy użytkownik zakończył stronicowanie za pośrednictwem wszystkich jednostek w bieżącym segmencie. Takie podejście ma kilka korzyści:
- Dzięki temu można ograniczyć ilość danych pobieranych z usługi Table Service i przenoszonej przez sieć.
- Umożliwia wykonywanie asynchronicznych operacji we/wy na platformie .NET.
- Umożliwia serializowanie tokenu kontynuacji do magazynu trwałego, dzięki czemu można kontynuować w przypadku awarii aplikacji.
Uwaga
Token kontynuacji zwykle zwraca segment zawierający 1000 jednostek, chociaż może być mniej. Jest to również przypadek, jeśli ograniczysz liczbę wpisów zwracanych przez zapytanie za pomocą polecenia Take , aby zwrócić pierwsze n jednostek spełniających kryteria wyszukiwania: usługa tabeli może zwrócić segment zawierający mniej niż n jednostek wraz z tokenem kontynuacji, aby umożliwić pobranie pozostałych jednostek.
Projekcja po stronie serwera
Pojedyncza jednostka może mieć maksymalnie 255 właściwości i mieć rozmiar do 1 MB. Podczas wykonywania zapytań dotyczących tabeli i pobierania jednostek może nie być potrzebne wszystkie właściwości i uniknąć niepotrzebnego przesyłania danych (aby zmniejszyć opóźnienia i koszty). Projekcję po stronie serwera można użyć do przeniesienia tylko potrzebnych właściwości. Poniższy przykład pobiera tylko właściwość Email (wraz z elementami PartitionKey, RowKey, Timestamp i ETag) z jednostek wybranych przez zapytanie.
var subsetResults = query{
for employee in employeeTable.Query<EmployeeEntity>("PartitionKey eq 'Sales'") do
select employee.Email
}
foreach (var e in subsetResults)
{
Console.WriteLine("RowKey: {0}, EmployeeEmail: {1}", e.RowKey, e.Email);
}
Zwróć uwagę, że wartość RowKey jest dostępna, mimo że nie została ona uwzględniona na liście właściwości do pobrania.
Modyfikowanie jednostek
Biblioteka klienta usługi Storage umożliwia modyfikowanie jednostek przechowywanych w usłudze tabel przez wstawianie, usuwanie i aktualizowanie jednostek. Przy użyciu egt można wsadować wiele operacji wstawiania, aktualizowania i usuwania, aby zmniejszyć wymaganą liczbę rund i zwiększyć wydajność rozwiązania.
Wyjątki zgłaszane, gdy biblioteka klienta usługi Storage wykonuje EGT, zazwyczaj obejmują indeks jednostki, która spowodowała niepowodzenie partii. Jest to przydatne podczas debugowania kodu korzystającego z egt.
Należy również rozważyć, jak projekt wpływa na sposób, w jaki aplikacja kliencka obsługuje współbieżność i operacje aktualizacji.
Zarządzanie współbieżnością
Domyślnie usługa tabel implementuje optymistyczne kontrole współbieżności na poziomie poszczególnych jednostek dla operacji Wstawianie, Scalanie i Usuwanie , chociaż klient może wymusić obejście tych testów przez usługę tabel. Aby uzyskać więcej informacji na temat zarządzania współbieżnością usługi tabel, zobacz Zarządzanie współbieżnością w usłudze Microsoft Azure Storage.
Scal lub zastąp
Metoda Replace klasy TableOperation zawsze zastępuje pełną jednostkę w usłudze Table Service. Jeśli nie dołączysz właściwości do żądania, gdy ta właściwość istnieje w przechowywanej jednostce, żądanie usunie właściwość z przechowywanej jednostki. Jeśli nie chcesz jawnie usunąć właściwości z przechowywanej jednostki, musisz uwzględnić każdą właściwość w żądaniu.
Możesz użyć metody Merge klasy TableOperation, aby zmniejszyć ilość danych wysyłanych do usługi Table Service, gdy chcesz zaktualizować jednostkę. Metoda scalania zastępuje wszystkie właściwości przechowywanej jednostki wartościami właściwości z jednostki zawartej w żądaniu, ale pozostawia nienaruszone wszelkie właściwości w przechowywanej jednostce, które nie są uwzględnione w żądaniu. Jest to przydatne, jeśli masz duże jednostki i musisz zaktualizować tylko niewielką liczbę właściwości w żądaniu.
Uwaga
Metody Replace i Merge kończą się niepowodzeniem, jeśli jednostka nie istnieje. Alternatywnie można użyć metod InsertOrReplace i InsertOrMerge , które tworzą nową jednostkę, jeśli nie istnieje.
Praca z typami jednostek heterogenicznych
Usługa Table Service jest magazynem tabel bez schematu, co oznacza, że jedna tabela może przechowywać jednostki wielu typów, co zapewnia dużą elastyczność w projekcie. Poniższy przykład ilustruje tabelę przechowującą zarówno jednostki pracowników, jak i działów:
| PartitionKey | RowKey | Sygnatura czasowa | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||
| |||||||||||
|
|||||||||||
|
Każda jednostka musi nadal mieć wartości PartitionKey, RowKey i Timestamp , ale mogą mieć dowolny zestaw właściwości. Ponadto nie ma nic do wskazania typu jednostki, chyba że zdecydujesz się przechowywać te informacje gdzieś. Istnieją dwie opcje identyfikowania typu jednostki:
- Typ jednostki jest poprzedzany kluczem RowKey (lub ewentualnie kluczem partycji). Na przykład EMPLOYEE_000123 lub DEPARTMENT_SALES jako wartości RowKey .
- Użyj oddzielnej właściwości, aby zarejestrować typ jednostki, jak pokazano w poniższej tabeli.
| PartitionKey | RowKey | Sygnatura czasowa | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||
| |||||||||||||
|
|||||||||||||
|
Pierwsza opcja, poprzedzając typ jednostki kluczem RowKey, jest przydatna, jeśli istnieje możliwość, że dwie jednostki różnych typów mogą mieć tę samą wartość klucza. Grupuje również jednostki tego samego typu w partycji.
Techniki omówione w tej sekcji są szczególnie istotne dla dyskusji Relacje dziedziczenia we wcześniejszej części tego przewodnika w artykule Modelowanie relacji.
Uwaga
Należy rozważyć uwzględnienie numeru wersji w wartości typu jednostki, aby umożliwić aplikacjom klienckim rozwijanie obiektów POCO i pracę z różnymi wersjami.
W pozostałej części tej sekcji opisano niektóre funkcje w bibliotece klienta usługi Storage, które ułatwiają pracę z wieloma typami jednostek w tej samej tabeli.
Pobieranie typów jednostek heterogenicznych
Jeśli używasz biblioteki klienta tabel, masz trzy opcje pracy z wieloma typami jednostek.
Jeśli znasz typ jednostki przechowywanej z określonymi wartościami RowKey i PartitionKey , możesz określić typ jednostki podczas pobierania jednostki, jak pokazano w dwóch poprzednich przykładach, które pobierają jednostki typu EmployeeEntity: wykonywanie zapytania punktowego przy użyciu biblioteki klienta usługi Storage i pobieranie wielu jednostek przy użyciu linQ.
Drugą opcją jest użycie typu TableEntity (torby właściwości) zamiast konkretnego typu jednostki POCO (ta opcja może również poprawić wydajność, ponieważ nie ma potrzeby serializacji i deserializacji jednostki do typów platformy .NET). Poniższy kod języka C# potencjalnie pobiera wiele jednostek różnych typów z tabeli, ale zwraca wszystkie jednostki jako wystąpienia TableEntity . Następnie używa właściwości EntityType do określenia typu każdej jednostki:
Pageable<TableEntity> entities = employeeTable.Query<TableEntity>(x =>
x.PartitionKey == "Sales" && x.RowKey.CompareTo("B") >= 0 && x.RowKey.CompareTo("F") <= 0)
foreach (var entity in entities)
{
if (entity.GetString("EntityType") == "Employee")
{
// use entityTypeProperty, RowKey, PartitionKey, Etag, and Timestamp
}
}
Aby pobrać inne właściwości, należy użyć metody GetString w jednostce klasy TableEntity .
Modyfikowanie typów jednostek heterogenicznych
Nie musisz znać typu jednostki, aby ją usunąć i zawsze znasz typ jednostki podczas wstawiania. Można jednak użyć typu TableEntity , aby zaktualizować jednostkę bez znajomości jej typu i bez używania klasy jednostki POCO. Poniższy przykładowy kod pobiera pojedynczą jednostkę i sprawdza, czy właściwość EmployeeCount istnieje przed zaktualizowaniem.
var result = employeeTable.GetEntity<TableEntity>(partitionKey, rowKey);
TableEntity department = result.Value;
if (department.GetInt32("EmployeeCount") == null)
{
throw new InvalidOperationException("Invalid entity, EmployeeCount property not found.");
}
employeeTable.UpdateEntity(department, ETag.All, TableUpdateMode.Merge);
Kontrolowanie dostępu za pomocą sygnatur dostępu współdzielonego
Tokeny sygnatury dostępu współdzielonego (SAS) umożliwiają aplikacjom klienckim modyfikowanie (i wykonywanie zapytań) jednostek tabeli bez konieczności dołączania klucza konta magazynu do kodu. Zazwyczaj istnieją trzy główne korzyści wynikające z używania sygnatury dostępu współdzielonego w aplikacji:
- Nie musisz dystrybuować klucza konta magazynu do niezabezpieczonej platformy (takiej jak urządzenie przenośne), aby umożliwić urządzeniu dostęp do jednostek i ich modyfikowanie w usłudze Table Service.
- Można odciążyć niektóre zadania wykonywane przez role sieci Web i procesu roboczego w zarządzaniu jednostkami na urządzeniach klienckich, takich jak komputery użytkowników końcowych i urządzenia przenośne.
- Można przypisać ograniczony i ograniczony czas zestaw uprawnień do klienta (na przykład zezwalanie na dostęp tylko do odczytu do określonych zasobów).
Aby uzyskać więcej informacji na temat używania tokenów SAS w usłudze Table Service, zobacz Korzystanie z sygnatur dostępu współdzielonego (SAS).
Jednak nadal musisz wygenerować tokeny SAS, które przyznają aplikację kliencką do jednostek w usłudze tabel: należy to zrobić w środowisku, które ma bezpieczny dostęp do kluczy konta magazynu. Zazwyczaj używasz roli sieci Web lub procesu roboczego do generowania tokenów SAS i dostarczania ich do aplikacji klienckich, które wymagają dostępu do jednostek. Ponieważ nadal istnieje obciążenie związane z generowaniem i dostarczaniem tokenów SAS do klientów, należy rozważyć, jak najlepiej zmniejszyć to obciążenie, zwłaszcza w scenariuszach o dużej ilości.
Istnieje możliwość wygenerowania tokenu SAS, który udziela dostępu do podzestawu jednostek w tabeli. Domyślnie tworzysz token SYGNATURy dostępu współdzielonego dla całej tabeli, ale można również określić, że token SAS udziela dostępu do zakresu wartości PartitionKey lub zakresu wartości PartitionKey i RowKey. Możesz wygenerować tokeny SAS dla poszczególnych użytkowników systemu, tak aby token SAS każdego użytkownika zezwalał tylko na dostęp do własnych jednostek w usłudze tabel.
Operacje asynchroniczne i równoległe
Pod warunkiem, że rozdzielasz żądania na wiele partycji, możesz zwiększyć przepływność i czas odpowiedzi klienta przy użyciu asynchronicznych lub równoległych zapytań. Na przykład może istnieć co najmniej dwa wystąpienia roli procesu roboczego, które uzyskują dostęp do tabel równolegle. Poszczególne role procesów roboczych mogą być odpowiedzialne za określone zestawy partycji lub po prostu mieć wiele wystąpień roli procesu roboczego, z których każdy może uzyskiwać dostęp do wszystkich partycji w tabeli.
W ramach wystąpienia klienta można zwiększyć przepływność, wykonując operacje magazynu asynchronicznie. Biblioteka klienta usługi Storage ułatwia pisanie asynchronicznych zapytań i modyfikacji. Na przykład można rozpocząć od metody synchronicznej, która pobiera wszystkie jednostki w partycji, jak pokazano w poniższym kodzie języka C#:
private static void ManyEntitiesQuery(TableClient employeeTable, string department)
{
TableContinuationToken continuationToken = null;
do
{
var employees = employeeTable.Query<EmployeeEntity>($"PartitionKey eq {department}");
foreach (var emp in employees.AsPages())
{
// ...
continuationToken = emp.ContinuationToken;
}
} while (continuationToken != null);
}
Ten kod można łatwo zmodyfikować tak, aby zapytanie było uruchamiane asynchronicznie w następujący sposób:
private static async Task ManyEntitiesQueryAsync(TableClient employeeTable, string department)
{
TableContinuationToken continuationToken = null;
do
{
var employees = await employeeTable.QueryAsync<EmployeeEntity>($"PartitionKey eq {department}");
foreach (var emp in employees.AsPages())
{
// ...
continuationToken = emp.ContinuationToken;
}
} while (continuationToken != null);
}
W tym przykładzie asynchronicznym można zobaczyć następujące zmiany z wersji synchronicznej:
- Sygnatura metody zawiera teraz modyfikator asynchroniczny i zwraca wystąpienie zadania .
- Zamiast wywoływać metodę Query w celu pobrania wyników, metoda wywołuje teraz metodę QueryAsync i używa modyfikatora await w celu asynchronicznego pobierania wyników.
Aplikacja kliencka może wywołać tę metodę wiele razy (z różnymi wartościami parametru działu ), a każde zapytanie zostanie uruchomione w osobnym wątku.
Można również wstawiać, aktualizować i usuwać jednostki asynchronicznie. Poniższy przykład w języku C# przedstawia prostą, synchroniczną metodę wstawiania lub zastępowania jednostki pracownika:
private static void SimpleEmployeeUpsert(
TableClient employeeTable,
EmployeeEntity employee)
{
var result = employeeTable.UpdateEntity(employee, Azure.ETag.All, TableUpdateMode.Replace);
Console.WriteLine("HTTP Status: {0}", result.Status);
}
Ten kod można łatwo zmodyfikować tak, aby aktualizacja przebiegała asynchronicznie w następujący sposób:
private static async Task SimpleEmployeeUpsertAsync(
TableClient employeeTable,
EmployeeEntity employee)
{
var result = await employeeTable.UpdateEntityAsync(employee, Azure.ETag.All, TableUpdateMode.Replace);
Console.WriteLine("HTTP Status: {0}", result.Result.Status);
}
W tym przykładzie asynchronicznym można zobaczyć następujące zmiany z wersji synchronicznej:
- Sygnatura metody zawiera teraz modyfikator asynchroniczny i zwraca wystąpienie zadania .
- Zamiast wywoływać metodę Execute w celu zaktualizowania jednostki, metoda wywołuje teraz metodę ExecuteAsync i używa modyfikatora await w celu asynchronicznego pobierania wyników.
Aplikacja kliencka może wywoływać wiele metod asynchronicznych, takich jak ta, a każda wywołanie metody zostanie uruchomione w osobnym wątku.