Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
W tym artykule opisano opcję poziomu zgodności w usłudze Azure Stream Analytics.
Stream Analytics to usługa zarządzana z regularnymi aktualizacjami funkcji i stałymi ulepszeniami wydajności. Większość aktualizacji środowiska uruchomieniowego usługi jest automatycznie udostępniana użytkownikom końcowym niezależnie od poziomu zgodności. Jednak gdy nowa funkcja wprowadza zmianę zachowania istniejących zadań lub zmianę sposobu, w jaki dane są używane w uruchomionych zadaniach, wprowadzamy tę zmianę na nowym poziomie zgodności. Istniejące zadania usługi Stream Analytics można zachować bez istotnych zmian, pozostawiając ustawienie poziomu zgodności niższe. Gdy wszystko będzie gotowe do najnowszych zachowań środowiska uruchomieniowego, możesz wyrazić zgodę, podnosząc poziom zgodności.
Wybieranie poziomu zgodności
Poziom zgodności kontroluje zachowanie środowiska uruchomieniowego zadania usługi Stream Analytics.
Usługa Azure Stream Analytics obecnie obsługuje trzy poziomy zgodności:
- 1.2 — najnowsze zachowanie z najnowszymi ulepszeniami
- 1.1 — Poprzednie zachowanie
- 1.0 — Oryginalny poziom zgodności wprowadzony w czasie ogólnej dostępności usługi Azure Stream Analytics kilka lat temu.
Podczas tworzenia nowego zadania usługi Stream Analytics najlepszym rozwiązaniem jest utworzenie go przy użyciu najnowszego poziomu zgodności. Rozpocznij projekt zadania, opierając się na najnowszych zachowaniach, aby uniknąć dodatkowej zmiany i złożoności później.
Ustawianie poziomu zgodności
Poziom zgodności zadania usługi Stream Analytics można ustawić w Azure portal lub za pomocą wywołania interfejsu API REST tworzenia zadania.
Aby zaktualizować poziom zgodności zadania w portalu Azure:
- Użyj witryny Azure Portal , aby zlokalizować zadanie usługi Stream Analytics.
- Zatrzymaj zadanie przed zaktualizowaniem poziomu zgodności. Nie można zaktualizować poziomu zgodności, jeśli zadanie jest w trakcie wykonywania.
- Pod nagłówkiem Konfiguracja wybierz Poziom zgodności.
- Wybierz odpowiednią wartość poziomu zgodności.
- Wybierz pozycję Zapisz w dolnej części strony.
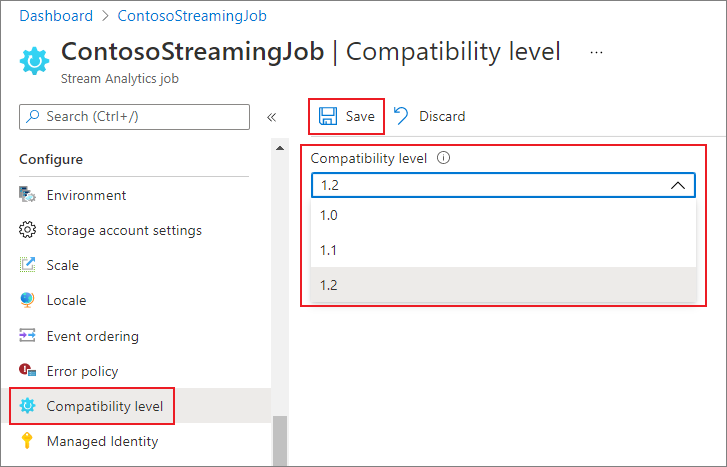
Po zaktualizowaniu poziomu zgodności kompilator T weryfikuje zadanie przy użyciu składni odpowiadającej wybranemu poziomowi zgodności.
Poziom zgodności 1.2
Następujące istotne zmiany są wprowadzane na poziomie zgodności 1.2:
Protokół wiadomości AMQP
Poziom 1.2: Usługa Azure Stream Analytics używa protokołu komunikatów Advanced Message Queueing Protocol (AMQP) do zapisywania w kolejkach i tematach Service Bus. Protokół AMQP umożliwia tworzenie międzyplatformowych aplikacji hybrydowych przy użyciu otwartego standardowego protokołu.
Funkcje geoprzestrzenne
Poprzednie poziomy: Usługa Azure Stream Analytics użyła obliczeń geografii.
1.2 poziom: Usługa Azure Stream Analytics umożliwia obliczanie rzutowanych współrzędnych geograficznych geometrycznych. Nie ma żadnych zmian w sygnaturze funkcji geoprzestrzennych. Jednak ich semantyka jest nieco inna, umożliwiając dokładniejsze obliczanie niż wcześniej.
Usługa Azure Stream Analytics obsługuje indeksowanie danych referencyjnych geoprzestrzennych. Dane referencyjne zawierające elementy geoprzestrzenne można indeksować w celu szybszego obliczania sprzężenia.
Zaktualizowane funkcje geoprzestrzenne oferują pełne możliwości wyrażenia formatu geoprzestrzennego Well Known Text (WKT). Możesz określić inne składniki geoprzestrzenne, które nie były wcześniej obsługiwane w formacie GeoJson.
Aby uzyskać więcej informacji, zobacz Aktualizacje funkcji geoprzestrzennych w usłudze Azure Stream Analytics — Cloud i IoT Edge.
Równoległe wykonywanie zapytań dla źródeł wejściowych z wieloma partycjami
Poprzednie poziomy: zapytania usługi Azure Stream Analytics wymagały użycia klauzuli PARTITION BY w celu równoległego przetwarzania zapytań między partycjami źródłowymi danych wejściowych.
1.2 poziom: Jeśli logika zapytań może być równoległa w partycjach źródłowych danych wejściowych, usługa Azure Stream Analytics tworzy oddzielne wystąpienia zapytań i uruchamia obliczenia równolegle.
Natywna integracja Bulk API z danymi wyjściowymi usługi Azure Cosmos DB
Poprzednie poziomy: zachowanie operacji upsert polegało na wstawianiu lub scalaniu.
1.2 poziom: Natywna integracja interfejsu API zbiorczego z danymi wyjściowymi usługi Azure Cosmos DB maksymalizuje przepływność i efektywnie obsługuje żądania ograniczania przepustowości. Aby uzyskać więcej informacji, zobacz stronę wyników analizy danych usługi Azure Stream Analytics do Azure Cosmos DB.
Zachowanie operacji upsert polega na wstawianiu lub zastępowaniu.
DateTimeOffset podczas zapisywania w danych wyjściowych SQL
Poprzednie poziomy:typy DateTimeOffset zostały dostosowane do czasu UTC.
1.2 poziom: DateTimeOffset nie jest już dostosowywany.
Długi proces podczas zapisywania do danych wyjściowych SQL
Poprzednie poziomy: Wartości zostały obcięte na podstawie typu docelowego.
1.2 poziom: Wartości, które nie mieszczą się w typie docelowym, są obsługiwane zgodnie z polityką błędów wyjściowych.
Serializacja rekordów i tablic podczas zapisywania wyników w SQL
Poprzednie poziomy: Rekordy zostały zapisane jako "Rekord", a tablice zostały zapisane jako "Array".
1.2 poziom: Rekordy i tablice są serializowane w formacie JSON.
Ścisła walidacja prefiksu funkcji
Poprzednie poziomy: Nie było ścisłej walidacji prefiksów funkcji.
1.2 poziom: Usługa Azure Stream Analytics ma ścisłą walidację prefiksów funkcji. Dodanie prefiksu do wbudowanej funkcji powoduje błąd. Na przykład nie jest obsługiwany element myprefix.ABS(…).
Dodanie prefiksu do wbudowanych agregacji powoduje również błąd. Na przykład nie jest obsługiwany element myprefix.SUM(…).
Użycie prefiksu "system" dla wszystkich funkcji zdefiniowanych przez użytkownika powoduje błąd.
Nie zezwalaj na użycie tablic i obiektów jako właściwości klucza w adapterze wyjściowym Azure Cosmos DB
Poprzednie poziomy: Typy tablic i obiektów były obsługiwane jako właściwość klucza.
1.2 poziom: Typy tablic i obiektów nie są już obsługiwane jako kluczowa właściwość.
Deserializowanie typu logicznego w formatach JSON, AVRO i PARQUET
Poprzednie poziomy: Usługa Azure Stream Analytics deserializuje wartość logiczną do typu BIGINT — false jest mapowany na 0, a true na 1. Dane wyjściowe tworzą tylko wartości logiczne w formatach JSON, AVRO i PARQUET, jeśli jawnie konwertujesz zdarzenia na BIT.
Na przykład zapytanie przekazywane, takie jak SELECT value INTO output1 FROM input1 odczytywanie JSON { "value": true } z input1, spowoduje zapisanie do output1 wartości JSON { "value": 1 }.
1.2 poziom: Azure Stream Analytics deserializuje wartość logiczną do typu BIT. Fałsz odpowiada 0, a prawda odpowiada 1. Zapytanie przekazujące, takie jak SELECT value INTO output1 FROM input1 odczytywanie JSON { "value": true } z Input1, spowoduje zapisanie w output1 wartości JSON { "value": true }. Możesz rzutować wartość na typ BIT w zapytaniu, aby upewnić się, że są wyświetlane jako true i false w danych wyjściowych dla formatów obsługujących typ logiczny.
Poziom zgodności 1.1
Następujące istotne zmiany są wprowadzane na poziomie zgodności 1.1:
Format XML usługi Service Bus
Poziom 1.0: usługa Azure Stream Analytics używała elementu DataContractSerializer, więc zawartość komunikatu zawierała tagi XML. Na przykład:
@\u0006string\b3http://schemas.microsoft.com/2003/10/Serialization/\u0001{ "SensorId":"1", "Temperature":64\}\u0001
1.1 poziom: Zawartość wiadomości zawiera strumień danych bez dodatkowych tagów. Na przykład: { "SensorId":"1", "Temperature":64}.
Utrwalanie rozróżniania wielkości liter dla nazw pól
Poziom 1.0: Nazwy pól zostały zmienione na małe litery podczas przetwarzania przez aparat usługi Azure Stream Analytics.
1.1 poziom: rozróżnianie wielkości liter jest zachowane dla nazw pól podczas ich przetwarzania przez silnik Azure Stream Analytics.
Uwaga
Trwałość rozróżniania wielkości liter nie jest jeszcze dostępna dla zadań Stream Analytics działających w środowisku Edge. W związku z tym wszystkie nazwy pól są konwertowane na małe litery, jeśli zadanie jest hostowane w przeglądarce Edge.
DezaktywacjaDeserializacjiFloatNaN
1.0 poziom: polecenie CREATE TABLE nie filtrowało zdarzeń z wartościami NaN (Not-a-Number, na przykład Infinity, -Infinity) w kolumnie typu FLOAT, ponieważ są one poza udokumentowanym zakresem dla takich liczb.
1.1 poziom: CREATE TABLE umożliwia określenie silnego schematu. Aparat usługi Stream Analytics sprawdza, czy dane są zgodne z tym schematem. Za pomocą tego modelu polecenie może filtrować zdarzenia za pomocą wartości NaN.
Wyłącz automatyczną konwersję ciągów daty/godziny na typ DateTime w ruchu przychodzącym dla formatu JSON
Poziom 1.0: Analizator JSON automatycznie konwertuje wartości ciągów z informacjami o dacie/godziny/strefie na typ DATETIME w ruchu przychodzącym, dzięki czemu wartość natychmiast traci oryginalne formatowanie i informacje o strefie czasowej. Ponieważ odbywa się to na etapie wejściowym, nawet jeśli to pole nie zostało użyte w zapytaniu, jest konwertowane na czas w formacie DateTime UTC.
1.1 poziom: Nie ma automatycznej konwersji wartości ciągu z informacjami o dacie/godzinie/strefie do typu DATETIME. W związku z tym informacje o strefie czasowej i oryginalne formatowanie są przechowywane. Jeśli jednak pole NVARCHAR(MAX) jest używane w zapytaniu w ramach wyrażenia DATETIME (na przykład funkcji DATEADD), jest konwertowane na typ DATETIME w celu wykonania obliczeń i traci oryginalny formularz.