Notatka
Dostęp do tej strony wymaga autoryzacji. Może spróbować zalogować się lub zmienić katalogi.
Dostęp do tej strony wymaga autoryzacji. Możesz spróbować zmienić katalogi.
Ważne
Eksplorator danych usługi Azure Synapse Analytics (wersja zapoznawcza) zostanie wycofany 7 października 2025 r. Po tej dacie obciążenia uruchomione w usłudze Synapse Data Explorer zostaną usunięte, a skojarzone dane aplikacji zostaną utracone. Zdecydowanie zalecamy migrację do usługi Eventhouse w usłudze Microsoft Fabric.
Program Microsoft Cloud Migration Factory (CMF) ma na celu pomoc klientom w migracji do sieci szkieletowej. Program oferuje praktyczne zasoby klawiaturowe bez ponoszenia kosztów dla klienta. Te zasoby są przypisywane przez okres 6–8 tygodni ze wstępnie zdefiniowanym i uzgodnionym zakresem. Nominacje klientów są akceptowane przez zespół ds. kont Microsoft lub bezpośrednio, przesyłając wniosek o pomoc zespołowi CMF.
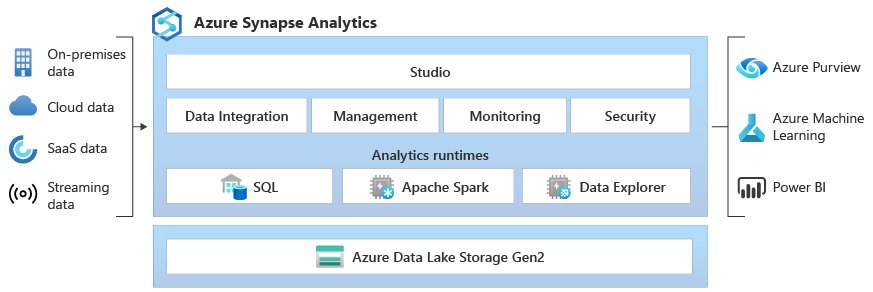
Usługa Azure Synapse Data Explorer udostępnia klientom interaktywne środowisko zapytań w celu odblokowania szczegółowych informacji z danych dzienników i danych telemetrycznych. Aby uzupełnić istniejące aparaty środowiska uruchomieniowego SQL i Apache Spark Analytics, środowisko uruchomieniowe analityki Data Explorer jest zoptymalizowane pod kątem wydajnej analizy dzienników przy użyciu zaawansowanych technologii indeksowania w celu automatycznego indeksowania danych z tekstu swobodnego i półustrukturyzowanych, często występujących w danych telemetrycznych.
Aby dowiedzieć się więcej, zobacz następujący film wideo:
Co sprawia, że usługa Azure Synapse Data Explorer jest unikatowa?
Łatwe pozyskiwanie — Eksplorator danych oferuje wbudowane integracje do bezkodowego/niskoprogowego, dużej przepustowości pozyskiwania danych oraz buforowania danych z źródeł czasu rzeczywistego. Dane mogą być pozyskiwane ze źródeł, takich jak Azure Event Hubs, Kafka, Azure Data Lake, agenci typu open source, tacy jak Fluentd/Fluent Bit, oraz szeroką gamę źródeł danych w chmurze i lokalnych.
Brak złożonego modelowania danych — w Eksploratorze danych nie ma potrzeby kompilowania złożonych modeli danych i nie ma potrzeby tworzenia złożonych skryptów w celu przekształcania danych przed ich użyciem.
Brak konserwacji indeksu — nie ma potrzeby wykonywania zadań konserwacji w celu zoptymalizowania danych pod kątem wydajności zapytań i nie ma potrzeby konserwacji indeksu. Dzięki Eksploratorowi danych wszystkie nieprzetworzone dane są natychmiast dostępne, co pozwala na uruchamianie zapytań o wysoką wydajność i wysoką współbieżność na danych przesyłanych strumieniowo i trwałych. Za pomocą tych zapytań można tworzyć pulpity nawigacyjne i alerty niemal w czasie rzeczywistym oraz łączyć dane analizy operacyjnej z pozostałą częścią platformy analizy danych.
Demokratyzacja analizy danych — Eksplorator danych demokratyzuje samoobsługową analizę danych big data za pomocą intuicyjnego języka Kusto Query Language (KQL), który zapewnia ekspresyjność i moc języka SQL z prostotą programu Excel. Język KQL jest wysoce zoptymalizowany pod kątem eksplorowania nieprzetworzonych danych telemetrycznych i danych szeregów czasowych dzięki wykorzystaniu najlepszej w klasie technologii indeksowania tekstu w usłudze Data Explorer w celu wydajnego wyszukiwania bez tekstu i wyrażeń regularnych oraz kompleksowych możliwości analizowania danych śledzenia\danych tekstowych i częściowo ustrukturyzowanych danych JSON, w tym tablic i zagnieżdżonych struktur. KQL oferuje zaawansowaną obsługę szeregów czasowych na potrzeby tworzenia, manipulowania i analizowania wielu szeregów czasowych, z wbudowaną obsługą wykonania w Pythonie na potrzeby oceniania modeli.
Sprawdzona technologia w skali petabajtów — Eksplorator danych to rozproszony system z zasobami obliczeniowymi i magazynem, który można skalować niezależnie, umożliwiając analizę w gigabajtach lub petabajtach danych.
Zintegrowane — usługa Azure Synapse Analytics zapewnia współdziałanie między danymi między eksploratorem danych, platformą Apache Spark i aparatami SQL, co umożliwia inżynierom danych, analitykom danych i analitykom danych łatwe i bezpieczne uzyskiwanie dostępu do tych samych danych w usłudze Data Lake oraz współpracę nad nimi.
Kiedy używać usługi Azure Synapse Data Explorer?
Użyj Eksploratora danych jako platformy danych do tworzenia rozwiązań analizy dzienników niemal w czasie rzeczywistym i analizy IoT, aby:
Skonsoliduj i skoreluj dzienniki i dane zdarzeń w źródłach danych lokalnych, w chmurze i innych firm.
Przyspiesz swoją podróż z AI Ops (rozpoznawanie wzorców, wykrywanie anomalii, prognozowanie i wiele więcej).
Zastąp rozwiązania do wyszukiwania dzienników oparte na infrastrukturze, aby zmniejszyć koszty i zwiększyć produktywność.
Zbuduj rozwiązania analityczne IoT dla swoich danych IoT.
Tworzenie rozwiązań SaaS do analizy w celu oferowania usług klientom wewnętrznym i zewnętrznym.
Architektura puli eksploratora danych
Pule Data Explorer implementują architekturę skalowania w poziomie, oddzielając zasoby obliczeniowe i przechowywania. Dzięki temu można niezależnie skalować każdy zasób, a na przykład uruchamiać wiele obliczeń tylko do odczytu na tych samych danych. Pule Eksploratora Danych składają się z zestawu zasobów obliczeniowych z uruchomionym silnikiem odpowiedzialnym za automatyczne indeksowanie, kompresowanie, buforowanie oraz przetwarzanie zapytań rozproszonych. Mają również drugi zestaw zasobów obliczeniowych z uruchomioną usługą zarządzania danymi odpowiedzialną za zadania systemu w tle oraz zarządzane i kolejkowane pozyskiwanie danych. Wszystkie dane są utrwalane na zarządzanych przez usługę kontach magazynu BLOB w użyciu skompresowanego formatu kolumnowego.
Pule eksploratora danych obsługują bogaty ekosystem do pozyskiwania danych przy użyciu łączników, zestawów SDK, interfejsów API REST i innych funkcji zarządzanych. Oferuje różne sposoby korzystania z danych na potrzeby zapytań ad hoc, raportów, pulpitów nawigacyjnych, alertów, interfejsów API REST i zestawów SDK.
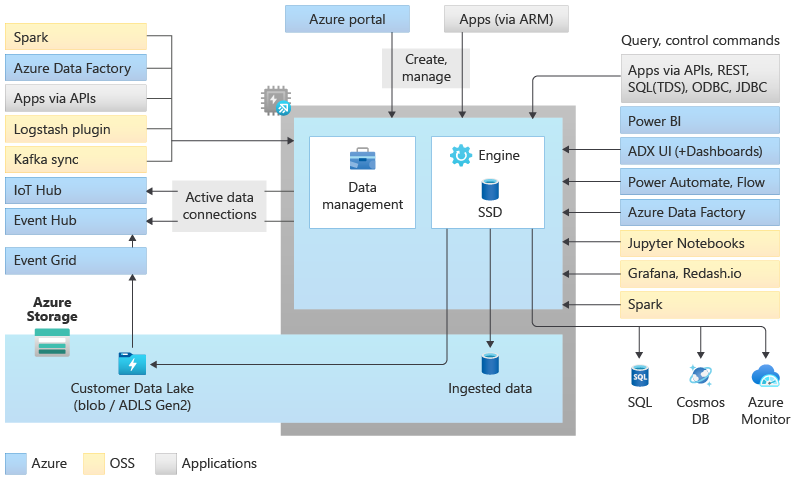
Istnieje wiele unikatowych możliwości, które sprawiają, że narzędzie Data Explore jest najlepszym aparatem analitycznym do analizy dzienników i szeregów czasowych na platformie Azure.
W poniższych sekcjach wyróżniono kluczowe różnice.
Indeksowanie danych w formie wolnego tekstu i częściowo ustrukturyzowanych umożliwia niemal w czasie rzeczywistym wysoką wydajność i wysoką równoczesność zapytań.
Eksplorator danych indeksuje dane częściowo ustrukturyzowane (JSON) i dane bez struktury (dowolny tekst), co sprawia, że uruchomione zapytania działają dobrze na danych tego typu. Domyślnie każde pole jest indeksowane podczas pozyskiwania danych z opcją używania zasad kodowania niskiego poziomu w celu dostosowania lub wyłączenia indeksu dla określonych pól. Zakres indeksu to pojedynczy fragment danych.
Implementacja indeksu zależy od typu pola w następujący sposób:
| Typ pola | Implementacja indeksowania |
|---|---|
| String | Silnik tworzy odwrócony indeks terminów dla wartości kolumn tekstowych. Każda wartość ciągu jest analizowana i dzielona na znormalizowane pojęcia, a dla każdego pojęcia rejestrowana jest uporządkowana lista pozycji logicznych, zawierająca porządkowe numery rekordów. Wynikowa posortowana lista terminów i skojarzone z nimi pozycje są przechowywane jako niezmienne drzewo B-tree. |
|
Numeryczny Data i czas TimeSpan |
Silnik tworzy prosty indeks przesuwny oparty na zakresie. Indeks rejestruje wartości minimalne/maksymalne dla każdego bloku, dla grupy bloków i całej kolumny w ramach fragmentu danych. |
| Dynamic | Proces wczytywania wylicza wszystkie "niepodzielne" elementy w wartości dynamicznej, takie jak nazwy właściwości, wartości i elementy tablicy, i przekazuje je do budowniczego indeksów. Pola dynamiczne mają ten sam odwrócony indeks terminów co pola ciągu. |
Te wydajne funkcje indeksowania umożliwiają eksplorowanie danych w celu udostępnienia danych niemal w czasie rzeczywistym na potrzeby zapytań o wysokiej wydajności i wysokiej współbieżności. System automatycznie optymalizuje fragmenty danych, aby zwiększyć wydajność.
język zapytań Kusto
KQL ma dużą, rosnącą społeczność dzięki szybkiemu wdrożeniu usług Azure Monitor Log Analytics i Application Insights, Microsoft Sentinel, Azure Data Explorer i innych ofert firmy Microsoft. Język jest dobrze zaprojektowany z łatwą do odczytania składnią i zapewnia płynne przejście od prostego jednego wiersza do złożonych zapytań przetwarzania danych. Dzięki temu Eksplorator danych zapewnia bogatą obsługę funkcji IntelliSense oraz bogaty zestaw konstrukcji językowych i wbudowanych funkcji agregacji, szeregów czasowych i analiz użytkowników, które nie są dostępne w języku SQL w celu szybkiego eksplorowania danych telemetrycznych.